多Agent交互设计
多Agent系统(Multi-Agent Systems, MAS)的交互设计是当前AI工程领域最具挑战性的课题之一。与单Agent系统不同,多Agent系统需要解决架构模式选择 、通信协议标准化 、协调与调度机制 、状态与记忆共享 、安全权限控制 、容错与可观测性 等一系列分布式系统级别的复杂问题。研究表明,36.9%的多Agent系统故障源于Agent间的状态不一致 (The Memory layer for your AI apps) ,而非模型本身的质量问题。本报告从架构模式、通信协议、协调机制、状态管理、安全设计、容错策略、性能优化、可观测性和框架选型九个维度,对多Agent交互设计进行全面系统的深度分析。
1. 多Agent架构模式
多Agent系统的架构模式决定了Agent之间的组织关系、控制流和信息传递方式。不同的架构模式适用于不同的业务场景,选择错误的架构模式往往导致系统难以扩展、调试困难或性能瓶颈。
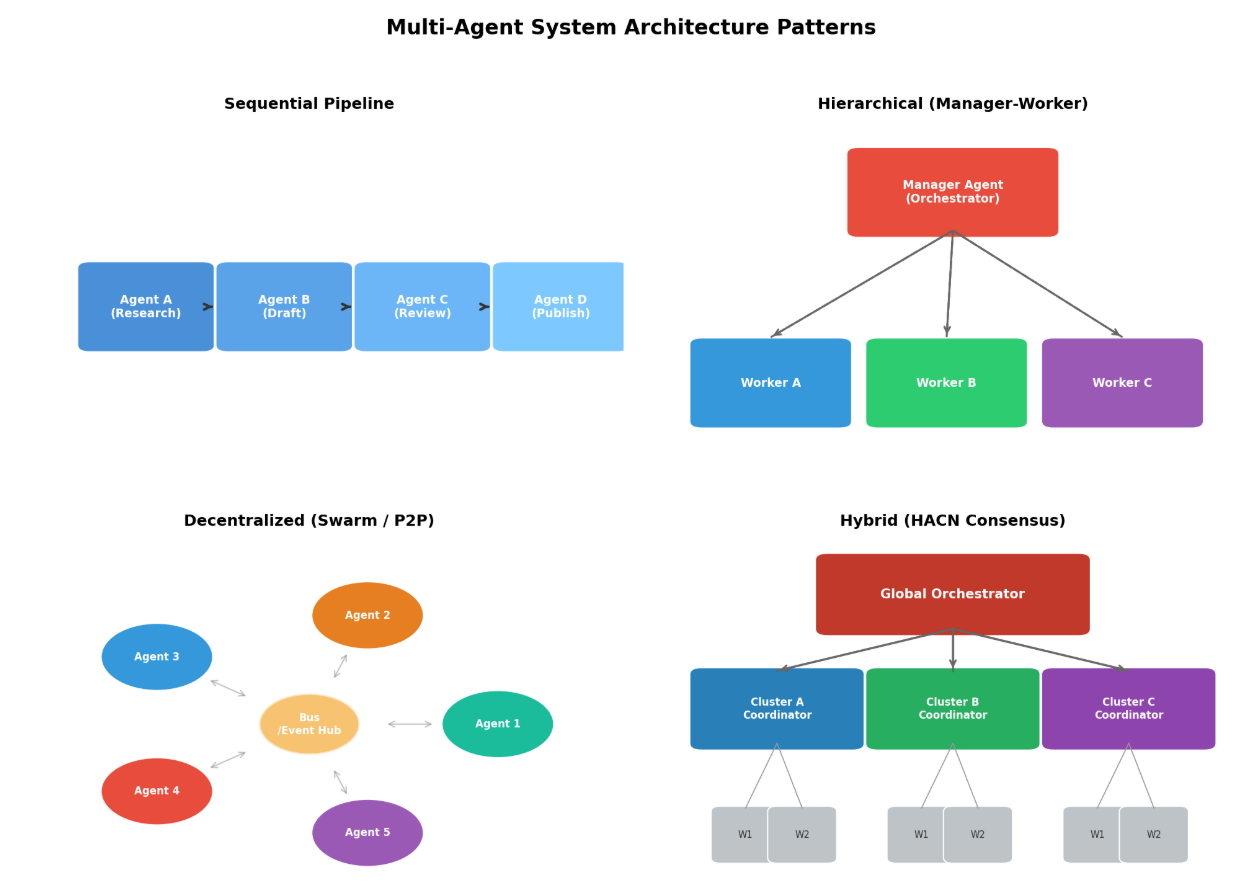
1.1 顺序流水线模式(Sequential Pipeline)
顺序流水线是最直观的多Agent交互模式,Agent按照预定义的顺序依次执行,每个Agent的输出作为下一个Agent的输入。CrewAI的sequential流程和LangGraph的线性链都实现了这一模式 (latenode.com) 。这种模式适用于任务可以清晰分解为线性依赖阶段的场景,例如内容创作流程(研究 → 起草 → 审核 → 发布)。
顺序流水线的核心优势在于简单性和可预测性 ------执行路径是确定的,调试时只需按顺序检查每个节点的输出。然而,其缺点也同样明显:缺乏并行能力,整体延迟等于各阶段延迟之和,且任何中间节点的失败都会导致整个流程中断 (Lushbinary) 。在生产环境中,建议为每个阶段设置超时和重试机制,并在Agent之间传递结构化的中间状态,而非纯文本输出,以降低上下文污染的风险。
1.2 层级管理模式(Hierarchical / Manager-Worker)
层级架构是当前生产环境中最广泛采用的多Agent模式。一个中央Manager Agent负责任务分解 、子任务分配 和结果聚合 ,多个Worker Agent各自负责具体的执行工作 (arXiv.org) 。研究表明,中心化协调在可并行任务上能带来80.9%的性能提升 ,且独立Agent的错误放大效应(17.2×)远高于中心化系统(4.4×) (arXiv.org) 。
层级架构的关键设计在于Manager与Worker之间的职责边界。Manager应当专注于高层决策 (what to do)而非微观控制(how to do),Worker则应当拥有足够的自主权来完成分配到的子任务 (arXiv.org) 。一个优秀的层级设计需要明确 authority paths:否决权(veto authority)向上流动------当Critic拒绝输出时,权限返回内部团队重试;批准权(approval)向上流动------当Critic批准后,结果提升到下一个决策点 (arXiv.org) 。这种不对称设计确保拒绝在团队边界内本地处理,而批准推动工作向前进展。
Moore(2025)的层级多Agent系统分类学提出了五个设计维度:控制层级 、信息流 、角色委托 、时序分层 和通信结构 (arXiv.org) 。实践中,MegaAgent展示了多达590个Agent 的自主协作能力,通过多级任务分解实现;AgentOrchestra则在GAIA基准上达到了SOTA性能,使用中央规划Agent和专业子Agent的架构 (arXiv.org) 。
1.3 去中心化/Swarm模式(Decentralized / Swarm)
去中心化架构中,Agent之间通过点对点通信 直接协作,没有中央控制节点。这种模式借鉴了自然界中的群体智能(swarm intelligence),适用于需要高容错性和动态适应的场景 (arXiv.org) 。OpenAI的Swarm框架是这一模式的典型代表 (gurusup.com) 。
去中心化架构的核心通信机制包括黑板架构 (Blackboard Architecture)和发布-订阅模式 (Publish-Subscribe)。黑板架构提供一个共享内存空间,Agent可以发布部分解决方案,其他Agent在此基础上构建 (arXiv.org) 。发布-订阅模式允许Agent订阅感兴趣的主题,发布者向所有订阅者广播更新,适用于监控和通知场景。Contract Net Protocol是另一种经典协调机制:Manager广播任务公告 → Agent提交投标(成本、时间、能力) → Manager将合同授予最佳投标者 → 获胜Agent执行任务并报告结果 (arXiv.org) 。
去中心化架构的优势在于无单点故障 和天然的可扩展性 ,但协调开销随Agent数量呈**O(N²)**增长,且共识达成更为困难 (arXiv.org) 。实际部署中通常采用稀疏通信拓扑(链式/树状结构)和异步消息传递来缓解这些问题。
1.4 混合模式(Hybrid)
生产环境中的复杂系统往往采用混合架构,结合多种模式的优点。Hierarchical Adaptive Consensus Network(HACN)是一个典型例子,它在三层结构中实现共识:本地集群共识 (Tier-1)→ 跨集群协调 (Tier-2)→ 全局编排 (Tier-3) (arXiv.org) 。每一层使用置信度加权投票和自适应阈值,当技术评估无法区分解决方案时,系统切换到多数投票,并在平局时应用基于解决方案复杂度、资源需求和集群历史性能的预定义决胜规则 (arXiv.org) 。
| 架构模式 | 控制方式 | 通信复杂度 | 容错性 | 适用场景 |
|---|---|---|---|---|
| 顺序流水线 | 完全预设 | O(N) | 低(单点故障) | 内容创作、审批流程 (latenode.com) |
| 层级管理 | 中央协调 | O(N) | 中(Manager单点) | 复杂任务分解、企业服务 (arXiv.org) |
| 去中心化/Swarm | 自主协商 | O(N²) | 高 | 动态环境、探索性任务 (arXiv.org) |
| 混合/HACN | 分层共识 | O(N log N) | 高 | 大规模分布式决策 (arXiv.org) |
2. Agent通信协议
随着多Agent系统的普及,Agent之间的通信标准化变得至关重要。2024-2025年间,多个重要的通信协议相继出现,它们在不同层级上解决了Agent互操作性问题 (arXiv.org) 。
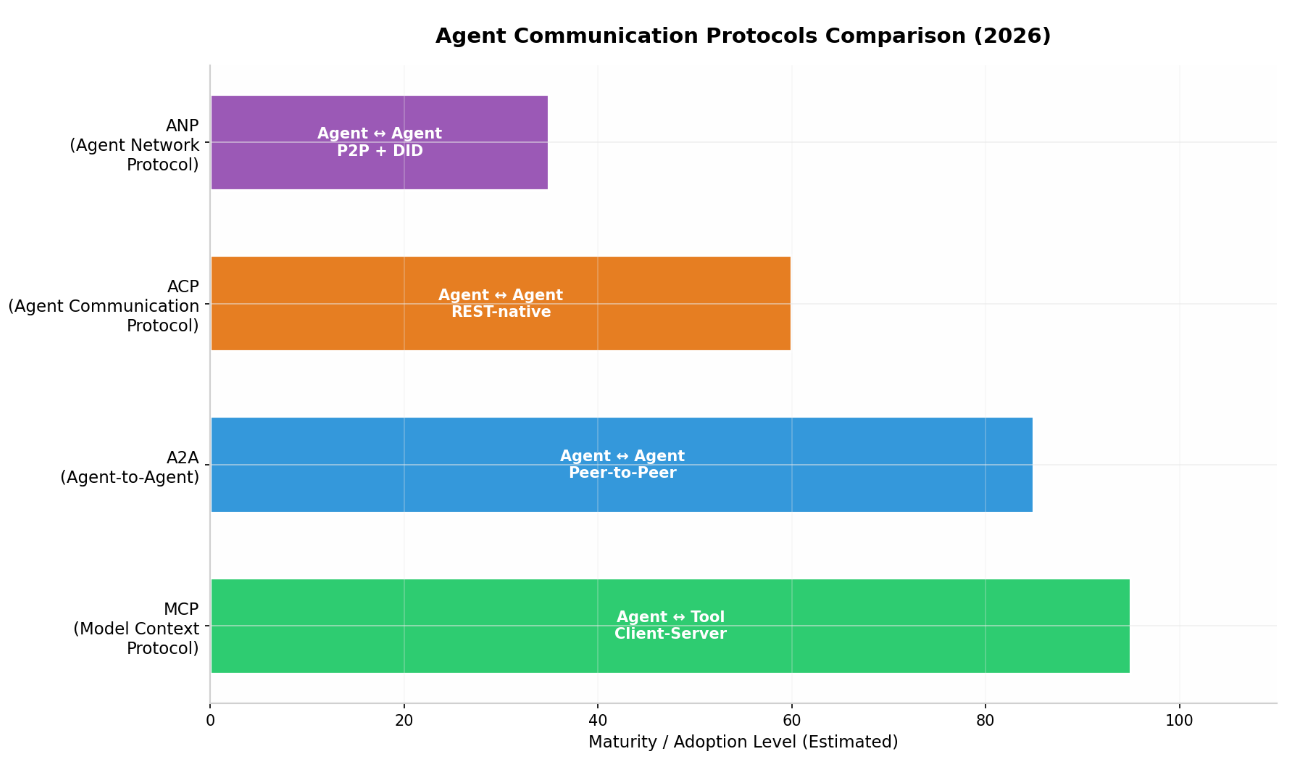
2.1 Model Context Protocol(MCP)
MCP由Anthropic开发,是一个JSON-RPC客户端-服务器接口 ,用于标准化LLM与外部工具、数据源之间的交互 (arXiv.org) 。MCP采用"AI的USB-C"设计理念,使AI模型能够像插入USB设备一样无缝连接各种外部服务 (arXiv.org) 。截至2025年3月,MCP的SDK月下载量已超过9700万次 (arXiv.org) 。
MCP的核心组件包括工具 (Tools)、资源 (Resources)和提示 (Prompts)。工具是Agent可调用的函数,资源是可供读取的数据,提示是可复用的提示模板。MCP服务器暴露这些能力,MCP客户端(嵌入在Agent中)支持动态发现和调用 (arXiv.org) 。这种设计强制实现了Agent智能(推理、规划、决策)与物理系统执行(模拟和基于模型的计算)之间的清晰分离 ,提高了模块化和可复现性 (arXiv.org) 。
在安全性方面,MCP支持OAuth 2.0/2.1 身份验证,服务器端实现细粒度访问控制和数据脱敏 (arXiv.org) 。然而,当前MCP规范仍存在一些安全空白:服务器"必须"清理工具输出但参考SDK尚未实现,缺乏会话关闭时的凭证撤销机制,以及对敏感工具缺少强制同意门控 (arXiv.org) 。
2.2 Agent-to-Agent Protocol(A2A)
A2A由Google主导开发,于2026年3月达到v1.0.0 稳定版本,是首个跨框架、跨厂商的Agent协作开放标准 (authzed.com) 。该协议与50多家技术合作伙伴(包括Atlassian、Salesforce、SAP、MongoDB等)共同设计,现由Linux Foundation托管 (arXiv.org) 。
A2A的核心设计围绕四个概念展开:Agent Card (能力发现)、Task (任务生命周期)、Message (通信载体)和Artifact (执行成果) (arXiv.org) 。Agent Card是一个JSON格式的机器可读文档,声明Agent的端点URL、支持协议绑定、可用技能和认证要求。Task定义了任务的原子工作单位,包含状态机(submitted → working → completed/failed/canceled)。Message支持多部分消息(文本、结构化数据、文件引用),Artifact承载技能执行的有形输出 (arXiv.org) 。
A2A在传输层支持多种机制:基于JSON-RPC 2.0 的核心任务通信、Server-Sent Events (SSE)用于实时流式更新、以及Push Notifications 用于移动和分布式部署场景 (arXiv.org) 。A2A与MCP的关系是互补而非竞争:A2A处理Agent之间的协作和任务委托,MCP处理Agent与工具的连接 (arXiv.org) 。
| 协议 | 主要用途 | 交互模式 | 核心机制 | 生态成熟度 |
|---|---|---|---|---|
| MCP (arXiv.org) | Agent ↔ 工具/资源 | Client-Server | Tools, Resources, Prompts | 高(9700万+月下载) |
| A2A (authzed.com) | Agent ↔ Agent | Peer-to-Peer | Agent Card, Task, Artifact | 高(v1.0.0稳定版) |
| ACP (arXiv.org) | 框架集成 | REST-native | 多部分消息, 异步流 | 中 |
| ANP (arXiv.org) | 开放网络发现 | P2P + DID | 去中心化标识, JSON-LD | 低(白皮书阶段) |
2.3 协议的分阶段采用路线图
Singh等人(2025)提出了一个务实的四阶段采用策略 (arXiv.org) :第一阶段 采用MCP实现工具调用能力;第二阶段 引入ACP支持异步多模态消息传递;第三阶段 使用A2A实现企业级多Agent工作流和任务编排;第四阶段通过ANP将互操作性扩展到开放互联网,支持去中心化Agent市场。这种渐进式方法使组织能够在每个阶段最大化互操作性,同时最小化集成复杂度。
3. 交互模式设计
Agent之间的交互模式定义了信息交换的具体方式,直接影响系统的耦合度、可调试性和性能。
3.1 Handoff(交接)模式
Handoff是一个Agent将控制权、上下文或正在进行的任务转移给另一个Agent的过程,同时保持连续性 (Zylos) 。这是当前最主流的Agent协作模式,OpenAI Agents SDK、LangGraph和Google ADK都以不同方式实现了这一模式。
Handoff的实现方式主要有四种:基于工具的Handoff (LLM调用transfer_to_XXX函数,OpenAI Swarm采用)、命令/图Handoff (Router节点返回带状态更新的Command,LangGraph采用)、层级Handoff (父Agent通过transfer_to_agent委托,Google ADK采用)、以及事件驱动Handoff (Handoff事件发布到消息总线,CrewAI with Kafka采用) (Zylos) 。
Handoff状态转移的最佳实践包括五个方面 (Zylos) :显式、结构化、版本化 (将Handoff视为API合约)、完整上下文转移 (新Agent接收完整对话历史)、JSON Schema验证 (禁止自由文本Handoff)、边界验证 (确认Handoff完整性后再继续)、以及最小上下文传递 (仅传递必要内容以减少延迟)。研究表明,有状态Handoff模式可以在重复请求上节省**40-50%**的API调用 (Zylos) 。
在客服系统等场景中,Handoff规则需要特别关注:绝不丢失上下文、总结而非转储、跟踪Handoff链(超过3次转接则标记审查)、以及向用户宣布过渡 (Jagodana LLC) 。
3.2 消息传递模式(Message Passing)
消息传递是Agent通过结构化消息进行通信的模式,每条消息包含发送者、接收者、行为类型(performative)和内容 (arXiv.org) 。与Handoff不同,消息传递更强调异步性 和松耦合------Agent发送消息后无需等待响应即可继续执行。
消息传递的关键设计决策包括消息格式 和可见性控制 。研究表明,使用Pydantic验证的结构化消息而非纯文本token进行Agent间通信,可以实现类型安全并消除解析歧义 (arXiv.org) 。消息可见性应基于FSM(有限状态机)状态进行过滤,确保Agent只接收与其角色和阶段相关的消息。这种模式类似于操作系统中的进程间通信,结构化协议取代了临时文本格式 (arXiv.org) 。
3.3 共享内存模式(Shared Memory)
共享内存提供一个所有Agent都可以读写的公共数据空间,实现强一致性 的状态共享 (The Memory layer for your AI apps) 。LangGraph的GraphState是这一模式的典型实现------所有节点(Agent)共享同一个类型化的状态字典,读写通过图执行器协调 (Lushbinary) 。
共享内存有三种架构变体 (The Memory layer for your AI apps) :集中式内存 (所有Agent读写单一存储,适合5个以下Agent的小团队)、分布式内存 (每个Agent拥有私有内存,选择性同步,适合大规模隐私敏感场景)、以及混合内存 (私有和共享层级的组合,是大多数生产系统的选择)。Mem0实现了四维度的内存作用域隔离:user_id(个人记忆)、agent_id(Agent特定上下文)、run_id(会话隔离)和app_id(应用级默认值) (The Memory layer for your AI apps) 。
共享内存的设计需要在延迟、一致性和成本 的三角关系中做出权衡。优化一致性通常以增加延迟和成本为代价;优化延迟则通过缓存或最终同步来放松一致性,可能导致Agent读到过期状态;优化成本则通过压缩或剪枝内存,可能损害检索质量并迫使Agent"重新推导"之前已知的信息 (The Memory layer for your AI apps) 。
3.4 黑板模式(Blackboard Pattern)
黑板模式提供一个共享的"黑板"空间,Agent可以在上面发布信息并读取他人的贡献,实现松耦合 的异步协作 (arXiv.org) 。AgentVerse使用黑板进行动态任务协调:Agent发布部分解决方案,其他Agent在此基础上构建。黑板模式的优势在于Agent之间不需要直接通信,发布者和订阅者完全解耦。
| 交互模式 | 耦合度 | 一致性 | 扩展性 | 适用场景 |
|---|---|---|---|---|
| Handoff (CallSphere) | 紧耦合 | 强一致 | 有限 | 线性工作流、客服路由 |
| 消息传递 (arXiv.org) | 松耦合 | 最终一致 | 良好 | 异步通知、事件驱动 |
| 共享内存 (The Memory layer for your AI apps) | 中耦合 | 强一致 | 有限 | 增量数据构建、状态同步 |
| 黑板模式 (arXiv.org) | 松耦合 | 最终一致 | 良好 | 迭代求精、多视角协作 |
4. 协调与调度机制
多Agent系统的协调机制决定了Agent如何协同工作以达成共同目标,包括任务分解、路由、共识达成和冲突解决。
4.1 任务分解与分配
任务分解是多Agent协作的首要步骤。层级架构中,上层Agent将高层指令分解为子任务并分配给下层Agent (arXiv.org) 。NEC的研究展示了一个三层层次化规划框架:全局规划层解释用户指令,类型层根据技能将子任务分配给机器人类别,机器人层为单个机器人生成PDDL问题 (arXiv.org) 。在MAT-THOR基准上,该方法在复合任务上达到**95%**的成功率,在复杂任务上达到84%,相比之前SOTA的LaMMA-P分别提升了2、7和15个百分点。
任务分配策略主要有三种 (arXiv.org) :基于能力的分配 (根据专业技能路由任务,如将收益分析路由给基本面分析师)、基于工作负载的分配 (考虑当前负载防止瓶颈)、以及混合方法 (结合两者因素,确保紧急但非专业任务可由任何可用Agent处理)。分配可以是集中式 (监督Agent分配工作)或去中心化(Agent基于能力和可用性自我分配)。动态重新分配使系统能够在Agent失败或过载时自适应调整,提高鲁棒性。
4.2 路由与调度
路由机制决定任务应该由哪个Agent处理。在客服场景中,Classifier Agent首先对用户查询进行分类(技术问题、账单问题、一般咨询),然后路由到相应的 specialist Agent (Jagodana LLC) 。更复杂的路由可以基于能力匹配(capability matching)------Agent发布能力卡片,路由器将任务与最匹配的技能对齐。
调度策略需要考虑优先级 、依赖关系 和并行性 。显式依赖的执行计划允许独立任务并行执行,依赖任务顺序执行 (arXiv.org) 。LangGraph通过条件边(conditional edges)实现动态路由------根据当前状态决定下一个执行节点,支持循环和分支 (Lushbinary) 。
4.3 共识机制
当专业Agent之间出现分歧时,共识机制将多样化意见聚合为一致的决策 (arXiv.org) 。主要共识机制包括:
投票机制 (Voting):所有Agent平等对待,多数或相对多数决定最终行动。优点是速度快,缺点是所有Agent被赋予相同权重,不考虑专业水平差异 (arXiv.org) 。
辩论机制 (Debate):Agent提出论据和反驳,通过讨论收敛。FINCON提供了结构化这种讨论的概念语言 (arXiv.org) 。辩论可以揭示盲点但耗时更长,适合高质量要求但时间压力较小的场景。
专家加权机制 (Expert Weights):根据历史准确率或领域专业知识分配不同影响力,允许分析师主导股票选择而风险经理影响仓位规模 (arXiv.org) 。HACN框架进一步引入置信度加权投票 (confidence-weighted voting),每个Agent的投票权重 w i = c i × h i w_i = c_i \times h_i wi=ci×hi,其中 c i c_i ci 是Agent置信度, h i h_i hi 是历史准确率 (arXiv.org) 。
5. 状态与记忆管理
多Agent系统的状态管理是确保所有Agent基于一致信息行动的核心基础设施。
5.1 集中式状态管理
所有Agent读写单一共享存储,如同会议室中的白板 (The Memory layer for your AI apps) 。集中式管理的优势在于强一致性 和简单实现 ------所有状态存在于一个地方,调试极为直接。一个三Agent内容管道(研究、起草、编辑)使用共享JSON存储跟踪已收集的来源、已起草的章节和待处理的编辑,设置仅需约一小时 (The Memory layer for your AI apps) 。
医疗AI系统如MedAgents采用相同方法:放射学、遗传学和临床历史Agent通过统一的患者记录同步,每个Agent将其分析贡献给共享存储,后续Agent都能看到完整图景 (The Memory layer for your AI apps) 。集中式状态的权衡是瓶颈问题 ------随着Agent数量增加,单一共享存储成为争用点和单点故障。建议在Agent数量少于5个 且能容忍该瓶颈时采用此模式 (The Memory layer for your AI apps) 。
5.2 分布式状态管理
每个Agent拥有独立的私有内存存储,通过同步协议在Agent之间传递状态更新 (The Memory layer for your AI apps) 。这种模式适合大规模系统和隐私敏感场景,例如跨组织的Agent协作中,每个组织不希望暴露内部状态。
分布式状态管理的核心挑战是一致性维护 。解决方案包括事件溯源 (Event Sourcing)------将状态变更记录为不可变事件序列,Agent通过重放事件重建状态;以及CRDT(Conflict-free Replicated Data Types)------保证最终一致性的数据结构,允许Agent在任何副本上独立更新并自动解决冲突。
5.3 混合状态架构
生产环境中大多数多Agent系统采用混合架构,结合私有和共享层级 (The Memory layer for your AI apps) 。例如,Agent的工作记忆(短期上下文)保持私有,而项目级状态(任务进度、共享知识)存储在共享层。访问控制确保Agent只能读写其授权范围内的状态。
在LangGraph中,状态通过显式的图状态模式 (Graph State Schema)定义,所有节点共享同一个类型化状态对象 (Lushbinary) 。OpenAI Agents SDK使用上下文变量 (context variables)传递状态,默认是短暂的但可以通过检查点持久化 (gurusup.com) 。Google ADK提供会话状态 与会话后端插件,支持状态持久化 (gurusup.com) 。
| 状态模式 | 一致性 | 延迟 | 成本 | 适用规模 |
|---|---|---|---|---|
| 集中式 (The Memory layer for your AI apps) | 强一致 | 中(争用) | 低 | < 5 Agent |
| 分布式 (The Memory layer for your AI apps) | 最终一致 | 低 | 高(同步开销) | 大规模 |
| 混合 (The Memory layer for your AI apps) | 可配置 | 可配置 | 中 | 生产通用 |
6. 安全与权限设计
多Agent系统创造了新的攻击面和授权挑战,每个Agent都成为潜在的安全主体。
6.1 授权传播问题
Tallam(2026)提出了授权传播 (Authorization Propagation)问题:在多Agent系统中,当非人类主体(Agent)检索数据、委托任务和跨边界综合结果时,如何维持授权不变性 (arXiv.org) 。这个问题不能归约为提示注入,也无法通过经典的RBAC、ABAC或ReBAC模型完全解决。
授权传播包含三个子问题 (arXiv.org) :传递性委托 (Transitive Delegation)------Agent代表另一Agent或人类主体行动时继承什么权限;聚合推断 (Aggregation Inference)------来自单独授权数据源的合成结果是否对请求主体授权;以及时间有效性(Temporal Validity)------确保授权决策在多步骤自主工作流的整个持续时间内保持有效。
6.2 访问控制模型
传统访问控制模型需要针对Agent场景进行扩展:
RBAC(基于角色的访问控制) :为Agent分配预定义角色(系统管理员、编排器、工作Agent、专家Agent),每个角色附带权限列表和约束条件 (agentplace.io) 。例如,编排器角色可以读取所有Agent状态、执行所有Agent、协调多Agent交互和监控系统,但约束最多并发100个Agent且只允许worker和specialist类型 (agentplace.io) 。
ABAC(基于属性的访问控制) :根据Agent属性、资源属性、环境属性和请求上下文动态评估策略 (agentplace.io) 。策略可以包含时间条件(如仅在工作时间允许访问)、环境条件(如威胁级别低于medium时允许)和关系条件(如目标Agent在信任列表中)。
TBAC(基于工具的访问控制) :新兴的Agent专用授权模型,在工具或任务级别授予权限,而非授予广泛的系统或API访问权限 (Github) 。Agent仅接收完成特定任务所需的特定工具或操作的权限,实现更安全的自动化。AGNTCY Identity Service项目(Linux Foundation)正在探索TBAC的开源实现。
6.3 最少Agent原则(Least Agency)
最少权限是必要但不充分的原则。最少Agent原则进一步要求最小化Agent自主做出授权决策的能力 ,因为这些决策实际上是LLM在非确定性条件下做出的,相同输入在不同调用中可能产生不同的权限假设 (tianpan.co) 。
一个实用的四级自治模型 (tianpan.co) :
| 层级 | 权限 | 适用场景 |
|---|---|---|
| 只读(Read-only) | 观察状态、展示信息、生成建议 | 所有新Agent起始级别 |
| 提议(Propose) | 发起行动但需人类确认后执行 | 已证明安全行为的Agent |
| 执行(Execute) | 在策略边界内自主执行预批准操作 | 高信任度Agent |
| 委托(Delegate) | 生成子Agent,必须明确限定和审计其能力 | 编排器Agent |
7. 容错与可靠性设计
多Agent系统的可靠性不能依赖于单个组件的永不失败,而必须通过架构设计确保系统在部分失败时仍能继续运行。
7.1 冗余与故障转移
多Agent架构通过Agent独立性和冗余提供内在容错能力 。单个Agent的失败不影响其他Agent,系统可以以降级功能继续运行 (arXiv.org) 。冗余机制包括关键Agent的多个实例和自动故障转移 能力------系统监控Agent健康状态,当主Agent失败时自动切换到备份实例 (arXiv.org) 。
冗余策略分为主动复制 (Active Replication,多个Agent同时执行相同任务)和被动复制 (Passive Replication,备份Agent保持空闲直到故障发生) (Milvus) 。在云系统中,虚拟机和容器跨服务器复制以处理节点故障。研究表明,采用综合容错策略的组织能将生产事件减少10倍 ,恢复时间加快95% (agentplace.io) 。
7.2 熔断与降级
熔断器模式(Circuit Breaker)防止故障级联。当某个Agent或外部服务连续失败时,熔断器打开,后续请求直接返回降级响应而非继续尝试。在LangGraph中,条件边(conditional edges)和重试机制支持这一模式------如果某步骤出错,执行可以重新路由到错误处理节点 (latenode.com) 。
优雅降级(Graceful Degradation)确保系统在部分功能不可用时仍能提供核心价值。例如,如果专业分析Agent不可用,系统可以回退到通用Agent提供基础分析能力,同时通知用户功能受限。
7.3 自愈机制
自愈系统通过心跳信号 和任务完成检查 持续监控彼此状态。如果Agent未能响应,其他Agent触发恢复动作,如重启Agent或重新分配其任务 (Milvus) 。检查点(Checkpointing)定期保存系统状态,故障发生时回滚到最后稳定检查点并恢复操作。
Puppeteer系统展示了协调策略进化的方法:采用中央编排器通过强化学习进化其决策策略,动态选择每步激活哪些Agent,同时平衡任务性能和计算成本 (arXiv.org) 。这种"木偶师-木偶"范式展示了架构进化如何在协调层面发生,发现核心Agent之间更紧密协调的涌现行为。
8. 可观测性设计
多Agent系统的调试复杂度远超单Agent系统,因为失败可能源于任何Agent、任何交互或任何状态转换。
8.1 分布式追踪
分布式追踪是理解多Agent系统的核心工具。每个Agent步骤------LLM调用、工具调用、检索、推理------成为父trace中的一个span,揭示完整执行树 (JobsByCulture) 。OpenTelemetry GenAI语义约定已于2026年稳定化,traceAI等库支持15+框架的自动检测 (futureagi.com) 。
一个典型的多Agent追踪包含以下信息 (agentplace.io) :
- 编排和路由决策:为什么编排器将这个任务发送给这个Agent?
- Agent间数据流:Agent之间传递了什么,是否完整到达?
- 每步延迟:哪个Agent或工具是瓶颈?
MLflow Tracing通过捕获Orchestrator和Worker之间的父子关系来重建图结构,将黑盒执行转换为可导航的状态转换图 (MLflow) 。
8.2 结构化日志与监控
结构化日志为每个日志条目添加上下文信息(Agent ID、Agent类型、Trace ID、Span ID),使日志可查询和关联 (agentplace.io) 。监控成熟度模型分为四个级别:基础监控(Agent上下状态)、结构化监控(详细指标和分布式追踪)、高级可观测性(全面指标和智能告警)、以及预测性监控(ML异常检测和自动化根因分析) (agentplace.io) 。
研究表明,缺乏分布式追踪时多Agent错误的排查时间增加3倍 (fast.io) 。Gartner预测,到2027年超过**40%**的Agentic AI项目将因成本飙升和风险管控不足而取消 (fast.io) 。
8.3 评估与质量监控
多Agent系统需要专门的评估框架来监控质量退化。fi.evals提供50+即用型评估模板:任务完成度、忠实度、工具使用正确性、上下文相关性、毒性检测等 (futureagi.com) 。在线评估持续为真实用户交互评分,支持基于阈值的告警和趋势分析。
Agent交互分析工具可以构建Agent交互图,计算图指标,识别通信模式,并检测异常 (agentplace.io) 。Maxim AI的Agent Compass功能自动聚类错误、使用内置错误分类法识别根因并提出修复建议,无需手动筛选数千条trace (futureagi.com) 。
9. 性能优化策略
多Agent系统的token成本随Agent数量和交互轮次呈超线性增长,需要专门的优化策略。
9.1 多模型路由
多模型路由根据任务特性将不同子任务分配给不同层级的模型,而非所有任务都使用最强大(最昂贵)的模型 (mindstudio.ai) 。一个典型的三级模型分层:
| 层级 | 模型类型 | 适用任务 | 成本比例 |
|---|---|---|---|
| Tier 1(前沿模型) | GPT-4o, Claude 4 | 复杂推理、最终合成、编排规划 | 100% |
| Tier 2(中端模型) | GPT-4o-mini, Gemini Flash | 分类、提取、简单总结、格式化 | 20-30% |
| Tier 3(轻量模型) | 专用小模型 | 路由决策、简单判断、上下文压缩 | 5-10% |
前沿编排器 + 廉价子Agent模式 是最具成本效益的策略:编排器使用前沿模型进行规划,子Agent执行具体、范围明确的任务,可使用Tier 2或Tier 3模型 (mindstudio.ai) 。这一模式单独即可将典型多Agent工作流的总token成本削减40-60%。
级联模式 (Cascade Pattern)从可能工作的最便宜模型开始,如果它发出低置信度信号或输出未通过质量检查,则升级到更有能力的模型 (mindstudio.ai) 。对于分类和路由任务,小模型可以处理70-80%的简单情况,只有困难案例需要升级。
9.2 上下文压缩
在将大上下文发送到Tier 1模型之前,使用Tier 2模型压缩或总结内容,然后将压缩版本传递给昂贵模型 (mindstudio.ai) 。这样以Tier 2价格支付压缩费用,以Tier 1价格支付更短输入的费用,净成本通常更低,且质量可能更好------因为昂贵模型不再处理无关内容。
Codified Prompting方法将Agent组件之间的自然语言通信替换为结构化类型化伪代码,使Agent推理更精确且token高效,输入token减少55-87% ,输出token减少41-70% (arXiv.org) 。
9.3 成本监控
建立每任务类型的模型使用日志,跟踪:每次工作流运行的成本(按模型细分)、质量指标(人类评分、下游任务成功率、错误率)、以及路由决策是否正确命中目标层级 (mindstudio.ai) 。季度审查路由表,因为模型能力和定价频繁变化------去年需要Tier 1的任务今年可能Tier 2就足够了。
10. 主流开发框架对比
2025-2026年,多Agent开发框架生态快速演进,各框架在编排模型、状态管理和通信模式上有根本性差异。
| 维度 | LangGraph | CrewAI | AutoGen / AG2 | OpenAI SDK | Google ADK |
|---|---|---|---|---|---|
| 编排模型 | 有向图 + 条件边 (Lushbinary) | 角色制 + 流程类型 (latenode.com) | 对话式 GroupChat (latenode.com) | 显式 Handoff (gurusup.com) | 层级Agent树 (gurusup.com) |
| 状态管理 | 显式图状态 + 检查点 (Lushbinary) | Crew上下文传递 (gurusup.com) | 对话历史 (gurusup.com) | 上下文变量 (gurusup.com) | 会话状态 + 插件后端 (gurusup.com) |
| 通信模式 | 图边消息传递 | 顺序/层级任务交接 | 多轮对话协商 | 工具函数Handoff | A2A协议 + 多模态 (gurusup.com) |
| 模型依赖 | 完全无关 (gurusup.com) | 完全无关 (gurusup.com) | 完全无关 (gurusup.com) | 仅OpenAI (gurusup.com) | 优化Gemini (gurusup.com) |
| 学习曲线 | 高(图论概念) (pecollective.com) | 低(声明式DSL) (pecollective.com) | 中(对话模式) (pecollective.com) | 低(简洁API) (gurusup.com) | 中(GCP生态) (gurusup.com) |
| 生产就绪度 | 最高(LangSmith, 检查点, 流式) (gurusup.com) | 中(增长中, 有限检查点) (gurusup.com) | 中(AG2重写中) (jetthoughts.com) | 高(内置追踪和护栏) (gurusup.com) | 早期(Vertex AI支持) (gurusup.com) |
| 每任务LLM调用 | 2-8次 (Lushbinary) | 3-10次 (Lushbinary) | 20+次 (Lushbinary) | 3-8次 | 5-12次 |
| 流式支持 | 原生(每节点) (gurusup.com) | 有限 (gurusup.com) | 有限 (gurusup.com) | 完整 (gurusup.com) | 通过Vertex (gurusup.com) |
10.1 框架选型决策树
选择LangGraph当 :工作流具有复杂条件逻辑、错误恢复或human-in-the-loop需求;需要生产级监控、持久化和流式处理;已经在使用LangChain生态 (pecollective.com) 。
选择CrewAI当 :任务自然分解为专业角色;需要快速原型和迭代Agent设计;团队包含需要理解Agent架构的非工程师;重视代码可读性和简洁性胜过细粒度控制 (pecollective.com) 。
选择AutoGen/AG2当 :Agent需要编写和执行代码;需要人类参与者加入Agent循环;工作流最好建模为参与者之间的结构化对话;在Microsoft Azure环境中运行 (pecollective.com) 。
选择OpenAI SDK当 :需要最简洁的Handoff模型;主要使用OpenAI模型;重视内置追踪和护栏 (gurusup.com) 。
10.2 框架的关键权衡
LangGraph提供最大的控制和最佳生产特性(检查点、流式、确定性执行),但学习曲线最陡 (Lushbinary) 。CrewAI提供最快的原型路径,但在超过5个Agent时协调开销增长,且缺乏内置检查点机制 (Lushbinary) 。AutoGen提供最深的协作推理能力,但每次任务通常需要20+次LLM调用 ,成本显著更高,且执行最不可预测 (Lushbinary) 。
一个诚实的工程建议是:大多数应用不需要多Agent系统 。一个具有良好工具和清晰系统提示的单Agent可以处理**80%**的真实用例。多Agent系统增加成本、复杂性和不可预测性,仅在任务真正需要多个专业视角时才使用 (pecollective.com) 。
11. 综合设计原则与最佳实践
11.1 核心设计原则
基于前述分析,多Agent交互设计应遵循以下核心原则:
为失败设计 (Design for Failure):假设组件会失败并据此设计。结合冗余、熔断器和自愈机制实现纵深防御 (agentplace.io) 。分层保护 :组合多种韧性模式。自动化恢复 :最小化恢复过程中的人工干预。持续测试 :定期测试故障场景和恢复流程。全面监控:全面的可见性实现快速故障检测和响应。
身份治理即基础设施 (Identity Governance as Infrastructure):身份治理必须被视为基础设施------在每个交互边界持续评估和强制执行,在编排逻辑允许扩展之前设计进系统 (arXiv.org) 。每个Agent必须有唯一身份、认证凭证、定义的授权范围和生命周期管理策略 (LoginRadius) 。
渐进式自治 (Progressive Autonomy):新Agent从最低自治层级(只读)开始,基于观察到的安全行为逐步提升权限 (tianpan.co) 。二进制的访问控制------Agent要么能做某事要么不能------不符合复杂系统中信任实际发展的方式。
11.2 实施路径建议
多Agent系统的实施应遵循渐进式路径:
- 从单Agent开始 :一个Agent、一两个工具、一个任务。在添加复杂性之前确保其可靠运行 (pecollective.com) 。
- 添加评估:定义指标并构建测试套件,在扩展之前知道Agent表现如何。
- 增量添加Agent :当单Agent遇到明确限制时,添加第二个Agent处理该特定限制。不要在第一天就设计五Agent团队 (pecollective.com) 。
- 监控token使用:多Agent系统可能快速消耗API额度,从第一天起设置预算和告警。
- 保持核心逻辑可移植 :所有框架都定期发布破坏性变更,不要过度投资框架特定模式。保持核心逻辑(提示、工具、评估)可移植,以便在需要时切换框架 (pecollective.com) 。
11.3 关键度量指标
生产环境中应持续监控以下指标 (JobsByCulture) :
| 类别 | 关键指标 |
|---|---|
| 运营指标 | 延迟分位数(P50/P95/P99)、首token时间、错误率(按类型)、工具调用成功率 |
| 质量指标 | 幻觉率、检索精确率/召回率(RAG)、用户满意度信号、语义漂移分数 |
| 经济指标 | 每请求token用量(输入vs输出)、每次对话成本、按产品功能的成本归因 |
研究表明,大多数团队在获得这些指标的可见性后发现了**20-40%**的token浪费 (JobsByCulture) 。
12. 前沿趋势与未来方向
12.1 协议标准化趋势
Agent通信协议正在快速收敛。MCP和A2A作为两大主流协议,形成了互补的生态系统:MCP解决Agent-工具互操作,A2A解决Agent-Agent协作 (arXiv.org) 。2026年的重要进展包括A2A达到v1.0.0稳定版本、MCP添加OAuth 2.0支持、以及Linux Foundation对A2A的托管 (authzed.com) 。
未来的协议演进方向包括:会话生命周期操作(挂起/恢复)、部分同意门控、审计要求和故障安全默认值的标准化 (arXiv.org) 。ANP协议探索去中心化标识(W3C DID)和JSON-LD图谱,为开放互联网Agent市场奠定基础 (arXiv.org) 。
12.2 架构演进方向
系统架构进化方面,EvoMAC框架引入"文本反向传播"机制,将编译错误和测试失败作为损失信号驱动Agent团队组合和个体提示的迭代修改 (arXiv.org) 。FELA框架应用多Agent系统生成高性能特征,结合强化学习和遗传算法原则 (arXiv.org) 。
自适应架构是另一个重要方向。固定层级架构虽然有效但降低了适应性 (arXiv.org) 。未来研究将探索自适应层级、与部分可观察设置中的感知集成、以及更稳健的优化方法。HACN框架的自适应阈值和动态重新配置代表了这一方向的早期探索 (arXiv.org) 。
12.3 安全性演进
多Agent安全的关注点正从提示注入防御扩展到全面的授权架构 。TBAC(基于工具的访问控制)作为新兴范式,正在Linux Foundation的AGNTCY项目中得到探索 (Github) 。执行计数撤销(execution-count revocation)、依赖图策略执行和调用绑定能力令牌等机制正在被提出以解决授权传播问题 (arXiv.org) 。
AWS提出的六维安全框架(身份上下文、数据与记忆保护、Agent与基础模型控制、代理边界与策略等)为企业级部署提供了渐进式实施路径 (GovExec.com) 。安全与功能发展的平衡将是未来多Agent系统成功部署的关键。