一、背景
紧跟 AI 发展热潮,计划向 AI 应用工程师方向发力:

AI建议:Python 完整语法 + 实操练习 NumPy + Pandas + EDA 数据分析, 由此计划了五月的学习提升计划
五一假期啃完了廖雪峰的 Python3 入门教程,复工后利用每晚和周末的碎片时间,接着学习尚硅谷、黑马的 Python 系列课程,从基础语法一路学到数据分析。期间还借助 AI 出题刷题巩固知识点,不得不说,AI 加持下学习效率提升了不少,还能给提供情绪价值,动力满满。学习结束后,偶然从掘金上发现了
Kaggle泰坦尼克号数据集的入门竞赛练习题,内容十分贴合现阶段所学,便决定将它作为第一阶段学习的结业实战项目。
二、原始数据解读
1912 年 4 月 15 日,号称"永不沉没"的泰坦尼克号与冰山相撞后沉没,2224 名乘客和船员中,1502 人遇难。
其包含的变量如下:
| 字段 | 含义 | 取值 |
|---|---|---|
PassengerId |
乘客唯一编号 | 整数 |
Survived |
是否存活(预测目标) | 0=死亡,1=幸存 |
Pclass |
票舱等级(社会地位代理变量) | 1=头等舱,2=二等舱,3=三等舱 |
Name |
姓名(含头衔信息) | 字符串 |
Sex |
性别 | male / female |
Age |
年龄 | 数值(含缺失值,以 .5 结尾表示估算值) |
SibSp |
同行的兄弟姐妹/配偶人数 | 整数 |
Parch |
同行的父母/子女人数 | 整数 |
Ticket |
票号 | 字符串 |
Fare |
票价 | 数值 |
Cabin |
客舱号 | 字符串(77% 缺失) |
Embarked |
登船港口 | C=Cherbourg,Q=Queenstown,S=Southampton |
三、Step 1:数据导入与总览
导入相关库,导入训练集和测试集
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
print(train.head())
print(test.head())
print(train.shape, test.shape) # ((891, 12), (418, 11))
print(train.isnull().sum(),test.isnull().sum())总览一下数据
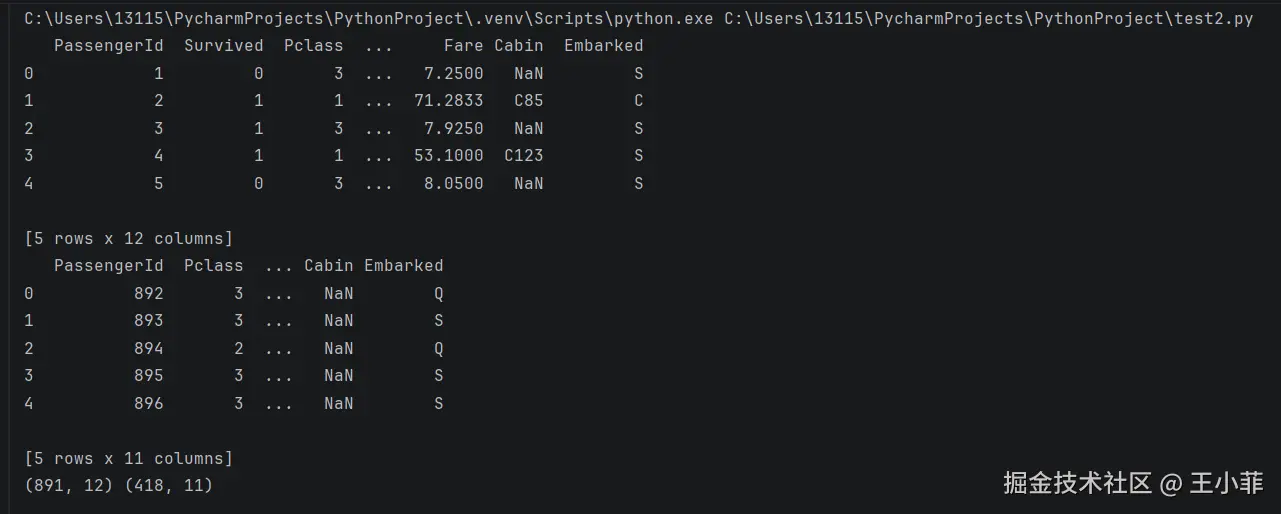
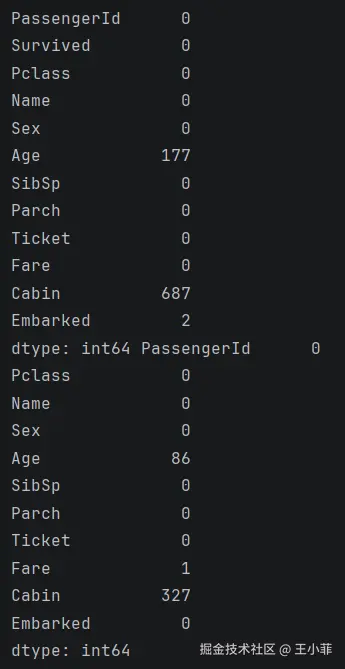
第一眼结论:
- 训练集:891 行 × 12 列
- 测试集:418 行 × 11 列(
Survived列正是我们要预测的) - 训练集中age,cabin,embarked有缺失值,测试集中age,cabin,Cabin有缺失值,我们待会儿对其进行相应处理
四、Step 2:缺失值可视化和清洗
ini
# 缺失值热力图(直观查看缺失分布)
plt.figure(figsize=(14, 5))
sns.heatmap(train.isnull(), cbar=False, cmap="YlOrRd")
plt.title("缺失值分布热力图")
plt.show()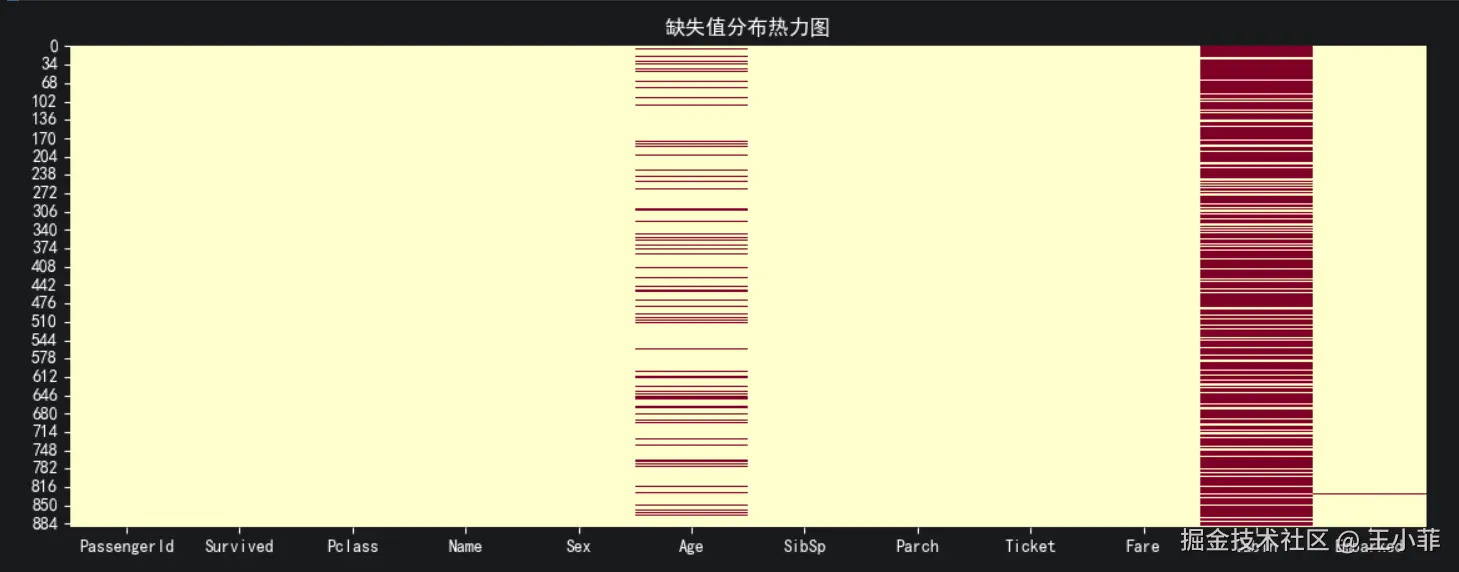
less
#Age 用中位数填充
train["Age"] = train["Age"].fillna(train["Age"].median())
# Embarked 用众数填充(仅2个缺失)
train["Embarked"] = train["Embarked"].fillna(train["Embarked"].mode()[0])
# Cabin 缺失极多,统一标记为 Unknown
train["Cabin"] = train["Cabin"].fillna("Unknown")
print("\n===== 清洗后缺失值检查 =====")
print(train.isnull().sum())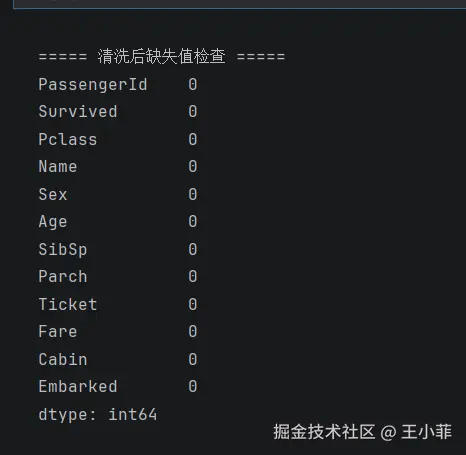
五、Step 3:探索性数据分析(EDA)
5.1 整体存活率
先看一下存活率:
ini
f,ax=plt.subplots(1,2,figsize=(18,8))
train['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True)
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot(x='Survived', data=train, ax=ax[1])
ax[1].set_title('Survived')
plt.show()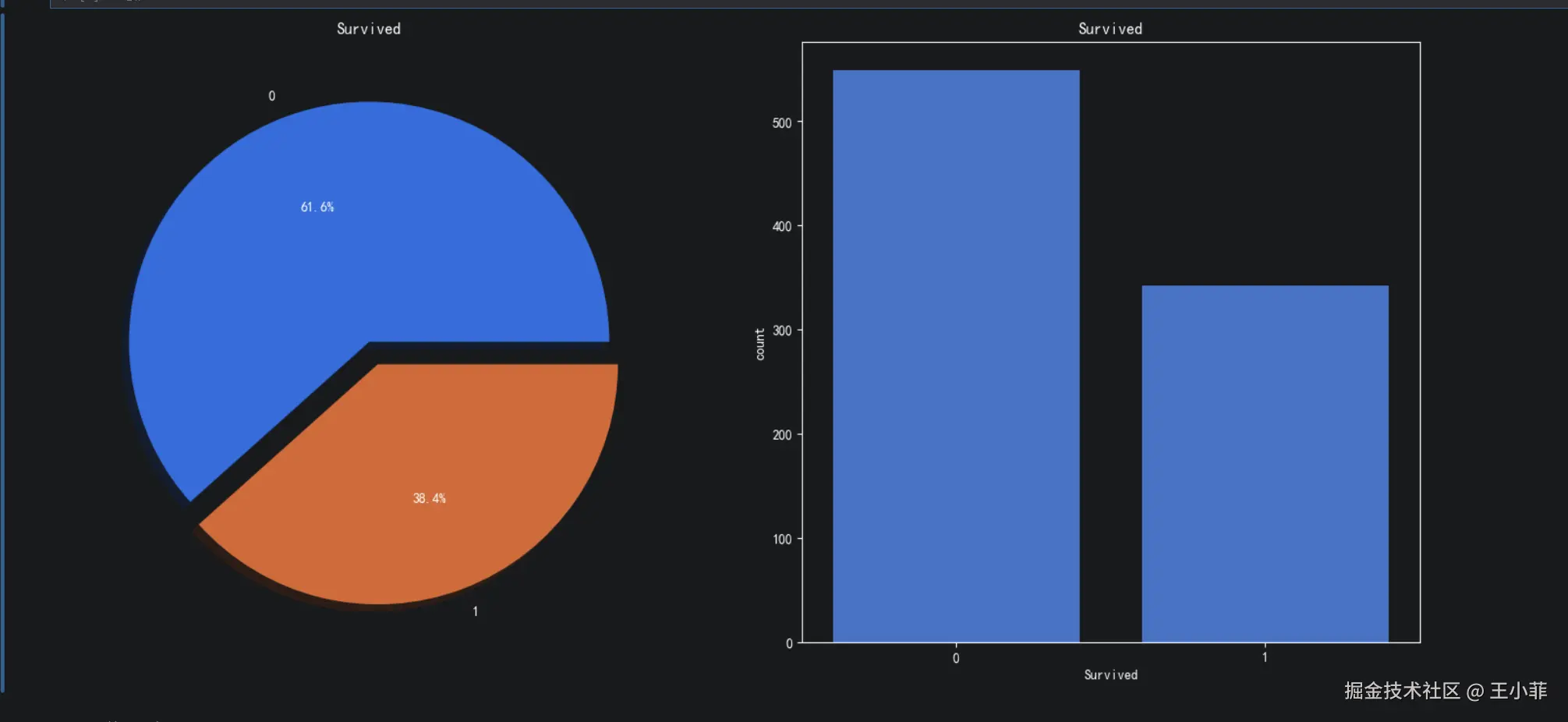
这批数据里一共 891 名乘客,只有约 350 人活了下来,存活率仅 38.4%,存活和遇难的人数差距很大。接下来我们会分析哪类乘客更容易活下来,现在先把 38.4% 当作整体的基础存活率来看,这是一个不平衡的分类问题。
5.2 性别 vs 存活(最重要的特征!)
ini
font = FontProperties(fname=r"C:\Windows\Fonts\msyh.ttc", size=12)
sns.set(style="whitegrid")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
# 柱状图:不同性别的存活/死亡人数
sns.countplot(data=train, x='Survived', hue='Sex', ax=ax1)
ax1.set_title('不同性别的存活人数', fontproperties=font)
# 柱状图:不同性别的存活率
train.groupby('Sex')['Survived'].mean().plot.bar(ax=ax2)
ax2.set_title('不同性别的存活率', fontproperties=font)
ax2.set_ylabel('存活率', fontproperties=font)
plt.tight_layout()
plt.show()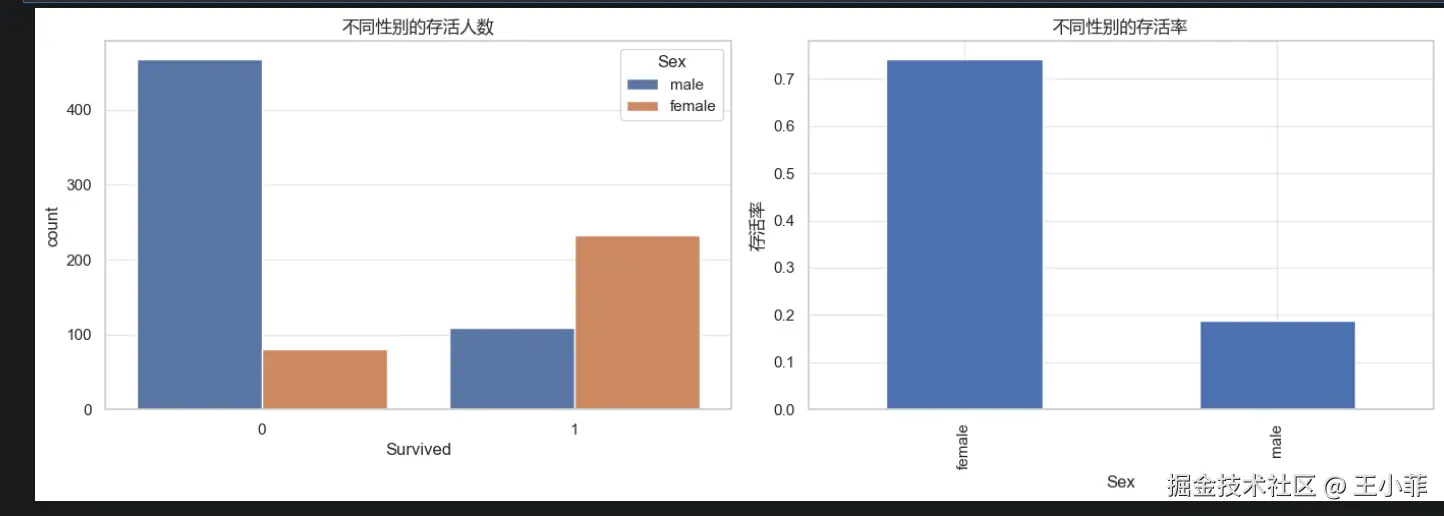
震撼的结论:
| 性别 | 存活率 |
|---|---|
| 女性 | 约 74% |
| 男性 | 约 19% |
"妇女儿童优先" 不是传说------在数据面前,这是铁一般的事实。 如果你是男性,在泰坦尼克号上的存活概率不到 1/5。
5.3 舱位等级 vs 存活
ini
# 柱状图:不同舱位的存活/死亡人数
sns.countplot(data=train, x='Survived', hue='Pclass', ax=ax1)
ax1.set_title('不同舱位的存活人数', fontproperties=font)
# 先计算不同舱位的存活率
survival_rate = train.groupby('Pclass')['Survived'].mean()
survival_rate.plot.bar(ax=ax2, color='skyblue')
ax2.set_title('不同舱位的存活率', fontproperties=font)
ax2.set_ylabel('存活率', fontproperties=font)
plt.tight_layout()
plt.show()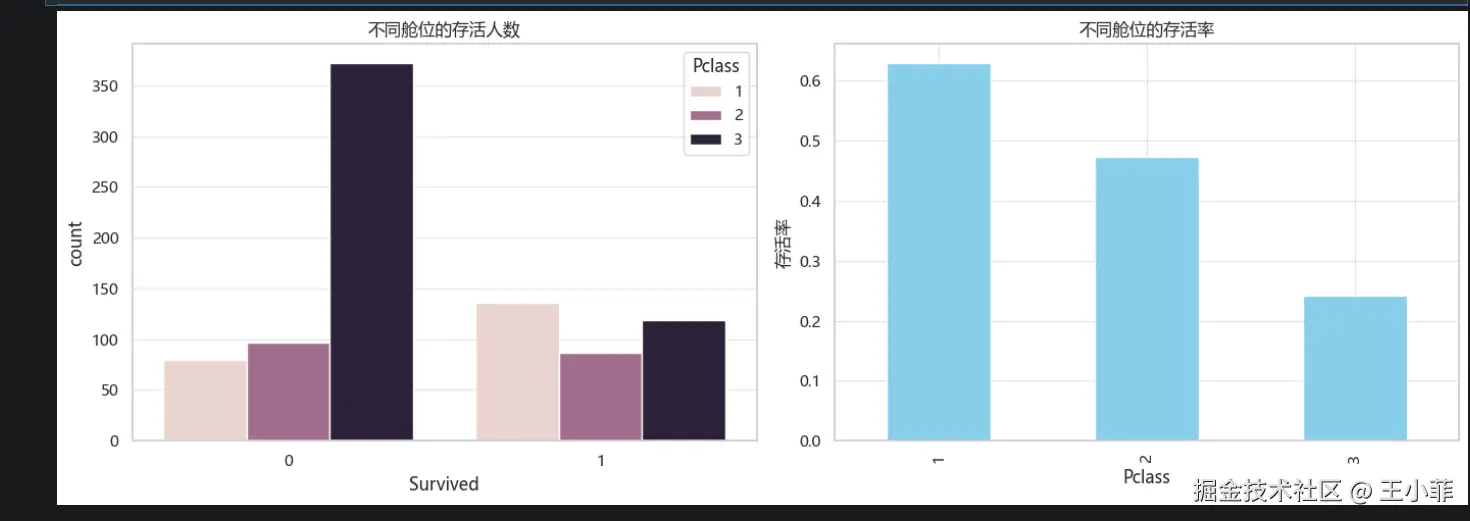
| 舱位 | 存活率 |
|---|---|
| 头等舱(1) | 约 63% |
| 二等舱(2) | 约 48% |
| 三等舱(3) | 约 24% |
金钱买不到一切,但能买到救生艇座位。 头等舱乘客的存活率是三等舱的 2.6 倍。
5.4 性别 + 舱位交叉分析
ini
sns.catplot(x='Pclass', y='Survived', hue='Sex', data=train, kind='bar')
plt.title('舱位 + 性别 对存活率的影响')
plt.show()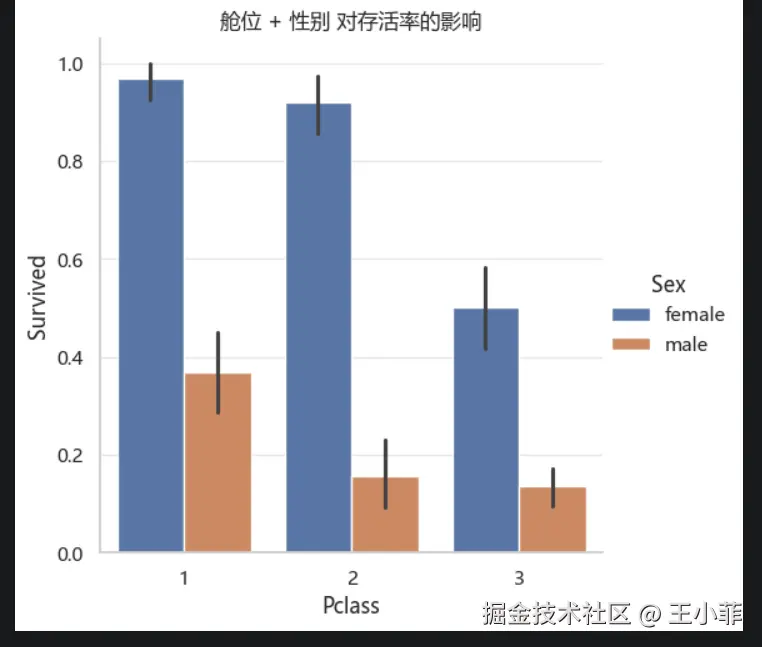
最惊人的发现:
- 头等舱女性:约 96% 存活(91/94,仅 3 人不幸遇难)
- 三等舱男性:约 12% 存活
你的命运,在登船那一刻就已经被舱位和性别决定了大半。
5.5 年龄 vs 存活
ini
fig, ax = plt.subplots(figsize=(12, 5))
sns.histplot(data=train, x='Age', hue='Survived', bins=20,
multiple='stack', kde=True, palette='Set1', ax=ax)
ax.set_title('年龄分布与存活的关系')
plt.show()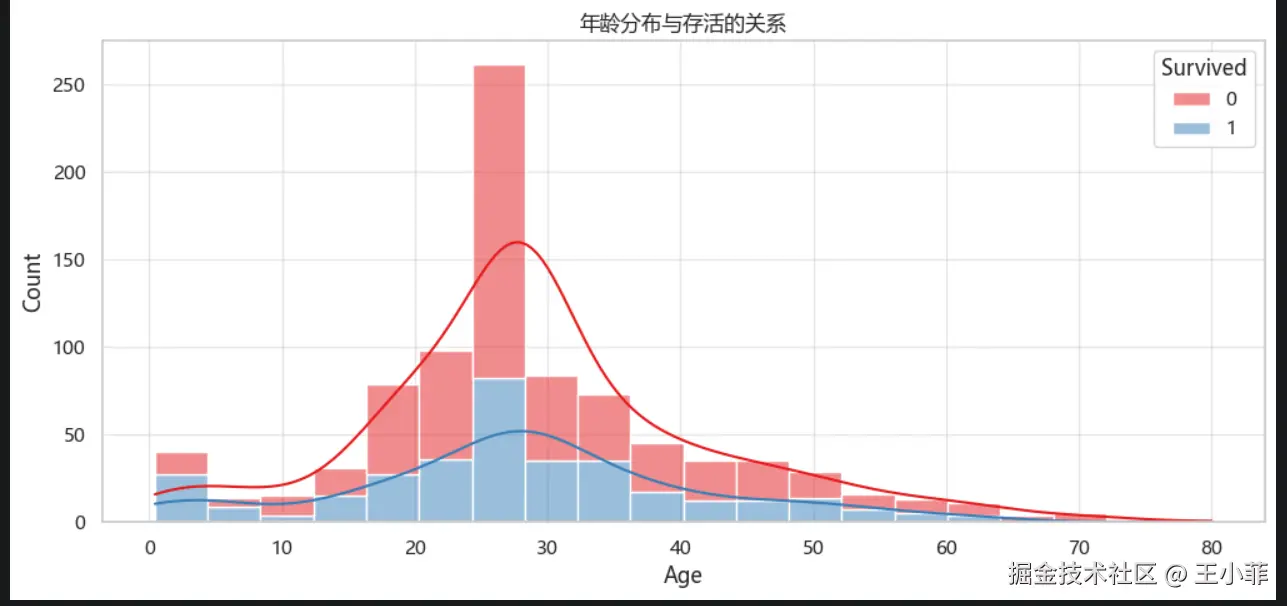
观察结论:
- 儿童(低龄段)存活率明显更高 → 再次验证"儿童优先"
- 20-40 岁死亡率最高
- 高龄乘客(>60 岁)存活率较低
5.6 登船港口 vs 存活
ini
sns.countplot(data=train, x='Embarked', hue='Survived')
plt.title('登船港口 vs 存活')
plt.show()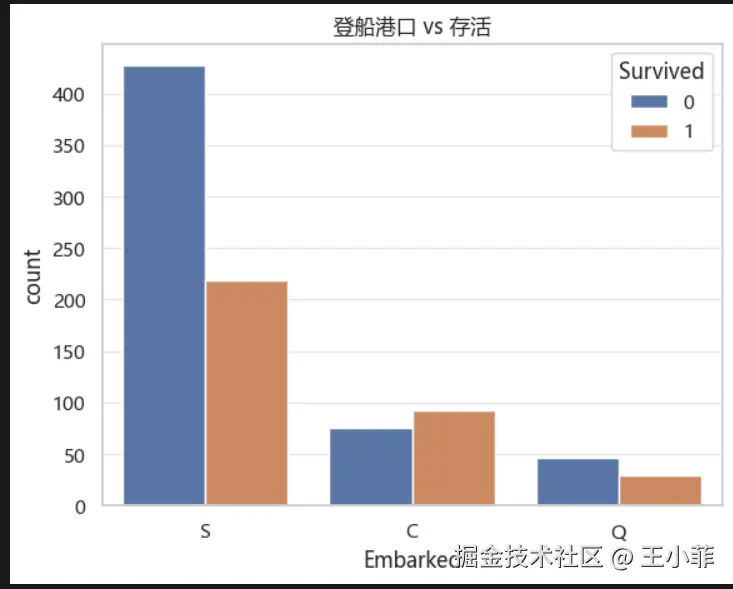
| 港口 | 含义 | 存活率特点 |
|---|---|---|
| C(Cherbourg,法国瑟堡) | 最多头等舱乘客上船 | 存活率最高 |
| S(Southampton,英国南安普敦) | 大多数三等舱乘客上船 | 存活率最低 |
| Q(Queenstown,爱尔兰皇后镇) | 中等 | 介于两者之间 |
S 港存活率最低,并不是因为港口本身,而是因为从 S 港上船的三等舱乘客最多,看起来是港口的影响,实际是舱位等级在起作用。
5.7 票价 vs 存活
ini
sns.histplot(data=train, x='Fare', hue='Survived', bins=30,
multiple='stack', kde=True)
plt.title('票价分布与存活的关系')
plt.show()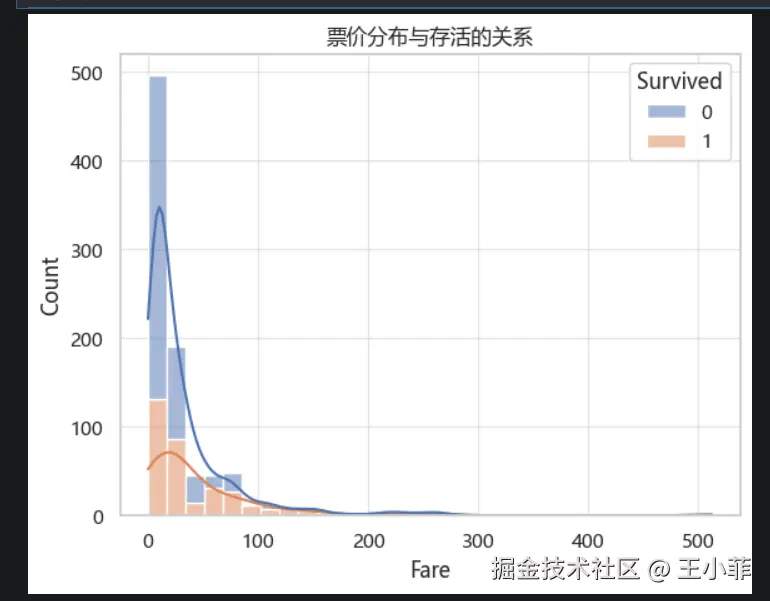
- 高价票乘客存活率明显更高
- 低票价乘客大规模遇难
5.8 相关性热力图
ini
plt.figure(figsize=(10, 8))
sns.heatmap(train.corr(numeric_only=True),
annot=True, cmap='RdBu_r', center=0)
plt.title('特征相关性热力图')
plt.show()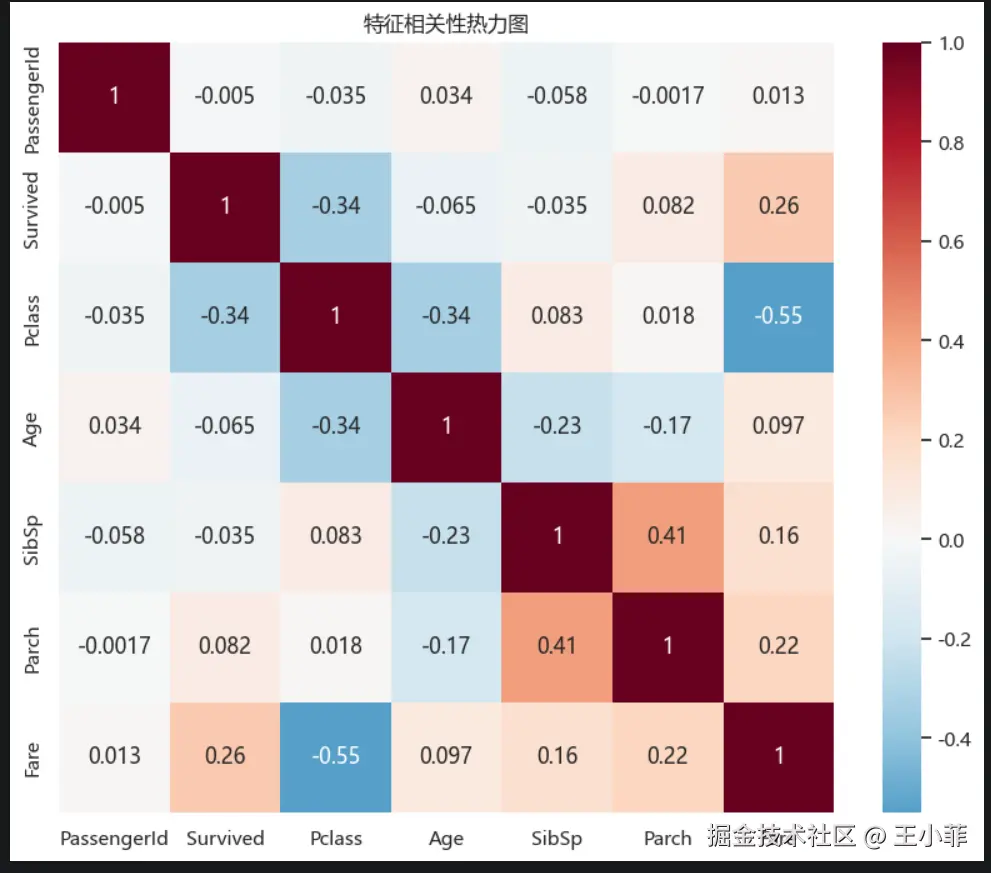
关键相关性:
| 特征 | 与 Survived 的相关系数 | 解读 |
|---|---|---|
Pclass |
约 -0.34 | 舱位等级越高(数字越小)越容易存活 |
Fare |
约 0.26 | 票价越高越容易存活 |
Age |
约 -0.0065 | 年龄影响较弱(单独看) |
SibSp / Parch |
接近 0 | 单独看影响不明显 |
六、Step 4:特征工程(让模型更懂数据)
6.1 从姓名中提取头衔(Title)
bash
# 从姓名中提取头衔,如 "Mr.", "Mrs.", "Miss." 等
for df in [train, test]:
df['Title'] = df['Name'].str.extract('([A-Za-z]+).', expand=False)
print(train['Title'].value_counts())原始数据有 17 种头衔,需要合并:
bash
for df in [train, test]:
df['Title'] = df['Name'].str.extract('([A-Za-z]+).', expand=False)
title_mapping = {
'Lady': 'Rare', 'Countess': 'Rare', 'Capt': 'Rare',
'Col': 'Rare', 'Don': 'Rare', 'Dr': 'Rare',
'Major': 'Rare', 'Rev': 'Rare', 'Sir': 'Rare',
'Jonkheer': 'Rare', 'Dona': 'Rare',
'Mlle': 'Miss', 'Ms': 'Miss', 'Mme': 'Mrs'
}
for df in [train, test]:
df['Title'] = df['Title'].replace(title_mapping)
# 按头衔分组,计算存活率
title_survive = train.groupby('Title')['Survived'].agg(['count', 'mean'])
title_survive.columns = ['总人数', '存活率']
title_survive['存活率'] = title_survive['存活率'].apply(lambda x: f"{x:.2%}")
print(title_survive)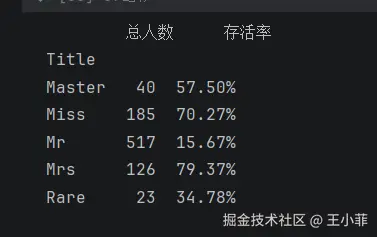
各头衔的存活率:
| 头衔 | 存活率 | 解读 |
|---|---|---|
| Master(未成年男孩) | 约 57.5% | 儿童优先 |
| Miss(未婚女性) | 约 70.27% | 女性优先 |
| Mrs(已婚女性) | 约 79.37% | 女性优先 |
| Mr(成年男性) | 约 15.67% | 最危险群体 |
| Rare(特殊身份) | 约 34.78% | 军官/牧师等,情况复杂 |
6.2 构建家庭大小特征
bash
for df in [train, test]:
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df['IsAlone'] = (df['FamilySize'] == 1).astype(int)
train[['FamilySize', 'Survived']].groupby('FamilySize').mean().plot.bar()
plt.title('家庭人数 vs 存活率')
plt.show()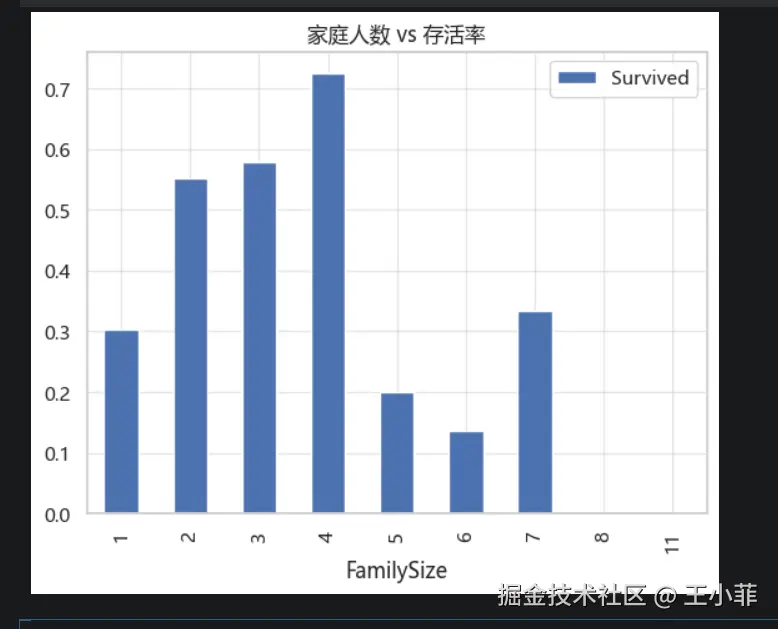
有趣的模式:
- 独自旅行的人存活率最低(约 30%)
- 中等家庭(2-4 人)存活率最高(约 50-60%)
- 超大家庭(>4 人)反而存活率下降(可能因为行动不便)
七、关键结论:你能活下来吗
基于数据分析,你的存活概率可以这样估算:
| 你的情况 | 预估存活率 | 建议 |
|---|---|---|
| 头等舱 + 女性 | > 95% | 基本稳了,喝杯茶等救援 |
| 头等舱 + 男性 | ~35% | 有点悬,看运气 |
| 三等舱 + 女性 | ~50% | 还有机会,跟着人群走 |
| 三等舱 + 男性 | < 15% | 😬 自求多福...... |
| 儿童(任何舱位) | ~60% | 儿童优先,好好跟着大人 |
| 独自旅行 + 男性 | ~18% | 最危险的群体 |
数据告诉我们一个残酷的事实: 在泰坦尼克号上,你的性别和钱包,比其他重要得多。
八、总结
最重要的收获不是模型,而是 EDA 的思维 : 在盲目跑模型之前,先问数据几个问题------你会发现, 数据自己就会告诉你答案。