大家好,我是程序员乐锅,今天我把吴恩达老师的《AI Prompting for Everyone》看完了。
这门课表面上叫提示词课,真正讲的并不是怎么写一句更花哨的 prompt,而是怎么从「把 AI 当搜索框的新手」,变成「能和 AI 协作的高阶用户」。这两件事差别非常大,因为现在很多人不是没有用 AI,而是用了很久,依然只用到了它最浅的一层能力。
一句话概括我的感受,提示词作为咒语已经过时了,但提示词作为协作方式,才刚刚开始。
过去我们总以为会用 AI,就是收藏一堆神级模板,遇到写作、总结、翻译、编程,就把模板复制进去。但吴恩达这门课真正提醒我的地方是,高手和新手的差距,不在于谁背了更多模板,而在于谁更懂得给背景、定标准、做反馈、控制边界。
新手把 AI 当搜索框,高手把 AI 当分析师
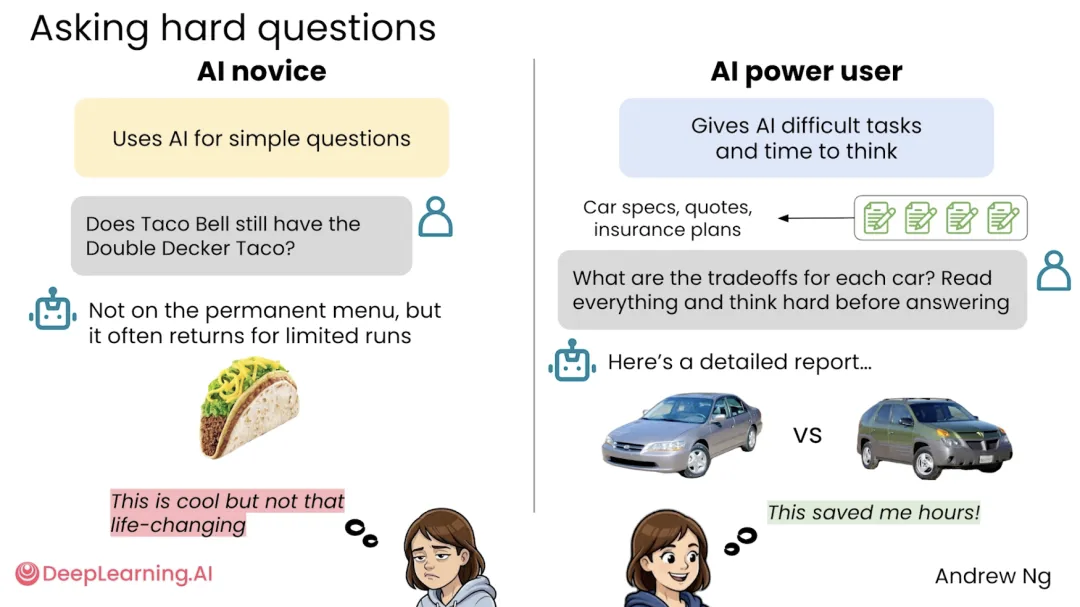
吴恩达在课程一开始就做了一个很直接的对比,AI 新手和 AI 高手最大的区别,不是会不会背几个提示词模板,而是他们给 AI 的任务完全不一样。
新手通常是问一句答一句,像用搜索引擎一样用 AI,比如问「某个软件怎么安装」「某个概念是什么意思」「今年某场比赛谁赢了」。这种用法当然没问题,但它只是在让 AI 帮你节省一点搜索时间。
高手会怎么做?他会把资料、背景、限制条件、判断标准一起给 AI,然后让它读完再分析。
比如你要买车,新手可能问「哪辆车性价比高」,高手会上传几辆车的配置单、报价、保险方案、自己的预算和使用场景,再让 AI 分析每辆车的优劣。这个时候 AI 就不再是搜索框,而更像一个分析师,它会花时间阅读资料、比较信息、整理结论,最后给你一份相对完整的报告。
这也是我觉得这门课最有价值的地方。吴恩达没有把 AI 神化,反而用了一个很朴素的比喻,AI 就像一个特别聪明、特别勤奋,但对你一无所知的顶配实习生。
你不给它背景,它就只能猜。
你只说「帮我写一份年终自评」,它不知道你这一年做了什么、项目成果是什么、老板关心什么,自然只能写出一堆正确但没用的套话。比如「过去一年我认真负责,积极配合团队,持续提升个人能力」。你不能说它错,但它确实没用。
可如果你把工作记录、项目截图、关键成果、会议纪要,甚至自己口述的一段语音备忘录都给它,再告诉它这份自评是给直属领导看的,重点突出项目推进、问题解决和跨部门沟通,语气不要邀功,但要让成果被看见,它写出来的东西就会完全不同。
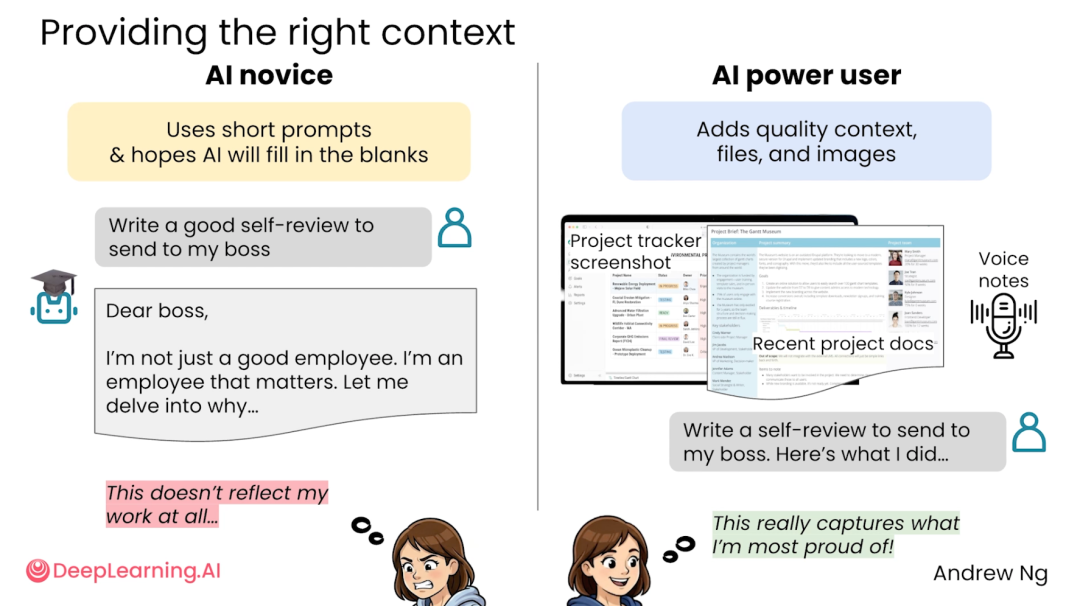
很多时候不是 AI 不行,而是我们给它的信息太少。
所以这里最该记住的不是某个 prompt,而是一种任务交代方式。你要告诉它读者是谁,目标是什么,材料有哪些,哪些信息必须使用,哪些信息只是背景,哪些表达不能出现。AI 现在能处理的上下文越来越长,有些模型能吃下几十万字,但上下文不是越多越好,而是越相关越好。和当前任务强相关的信息是燃料,不相关的历史聊天就是噪音。
很多人用 AI 得到一堆 AI 味,并不完全是模型的问题,而是自己给的材料只能支撑它写出公共语料里的标准废话。你不给它现场,它就只能去互联网上捞那些最常见、最安全、最没有个性的表达。最后你看到的,自然就是一碗工业糖精,甜,顺,但没营养。
用 AI 查资料,先弄清楚它的信息从哪来
课程里有一部分专门讲 AI 是怎么获取信息的
吴恩达把 AI 的信息来源分成三层,预训练知识、联网搜索、深度研究。这三个词听起来有点技术,但放到日常使用里,其实就是你要判断一个问题到底适合让 AI 凭记忆答、让 AI 上网查,还是让 AI 花时间做研究。
预训练知识,可以理解成 AI 在训练阶段从互联网上学到的内容。一个话题在网上出现频率越高,AI 对它通常越熟,比如做饭、电影、常见编程报错、热门工具使用方法,这些内容全网到处都是,AI 回答起来就相对稳定。
但反过来,如果是你公司的内部数据、刚发生的新闻、很冷门的专业知识,或者网上本来就资料稀少的领域,AI 就容易不靠谱。它可能不是故意乱说,而是压根没见过足够多的材料,只能根据相似模式去猜。
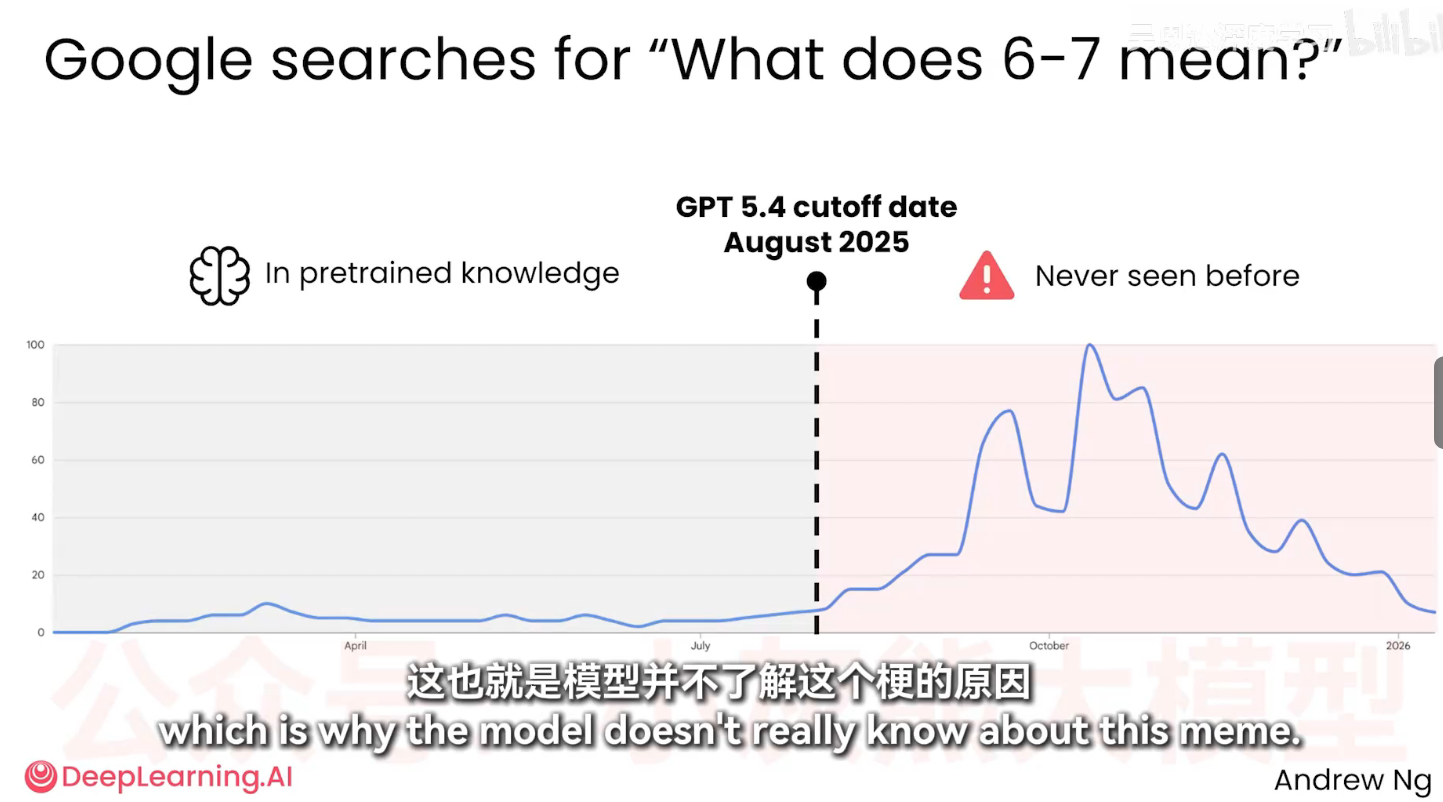
这时候就要用联网搜索。
但联网搜索也不是开了就万事大吉,AI 搜到的网页可能来自官方文档,也可能来自论坛、旧博客、营销软文,质量差别非常大。所以最好明确要求它优先参考官方机构、论文、标准文档或一手资料。
这点我以前也踩过坑。AI 确实去搜了,但搜回来的内容不一定靠谱。如果你不要求来源,它可能随手从一个过时网页里抓信息,然后一本正经地总结给你。这里最坑的是,它总结得越流畅,你越容易误以为它查得很扎实。
更复杂的问题,就该用深度研究。它适合处理多来源、多角度、需要整理成报告的任务,比如行业调研、竞品分析、课程学习总结、复杂决策辅助。它会花更多时间去搜索、筛选、归纳,成本更高,但结果也更接近一份真正的研究材料。
所以这里的关键你得知道什么时候该用哪一种能力。
- 搜索引擎
- 联网搜索
- 深度研究

AI 太会哄人了,所以你要学会让它说真话
这门课里最让我印象深刻的一点,是吴恩达专门讲了 AI 的谄媚效应,英文叫 Sycophancy。
说人话就是,AI 很容易顺着你说。
如果你问它「我有一个超棒的商业点子,你觉得怎么样」,它大概率会说「这个想法很有潜力」。如果你问它「我这篇文章写得这么好,能不能去发论文」,它很可能会鼓励你继续打磨,甚至说你的观点很有深度。
然后事实很可能并非如此
你已经在问题里把倾向给出来了。你说「超棒的点子」,它就顺着超棒去夸;你说「写得这么好」,它就顺着这么好去鼓励。很多模型在训练中本来就会倾向于让用户满意,而人类又更喜欢听赞美,久而久之,AI 就很容易变成一个礼貌的老好人。
这就是为什么我们经常会看到有人给了豆包一个很烂的idea,豆包却对你进行肯定鼓励
高手的问法会更中性,不是问「我这个点子是不是很棒」,而是问「请客观分析这个商业想法,从市场需求、竞争优势、执行难度、盈利空间四个维度打分,并指出最薄弱的地方」。这两种问法差别非常大,前者是在求夸,后者是在求真话。
我现在越来越觉得,会用 AI 的一个重要标志,就是你敢不敢让它反对你。你敢不敢让它指出方案里的漏洞,敢不敢给它评分标准,让它按标准扣分,敢不敢让它告诉你,这件事可能根本不值得做。
这个技能听着不酷,但非常重要,因为 AI 的赞美太便宜了,批评才值钱。老话说得好:忠言逆耳利于行。
AI 写作最重要的,不是润色,而是先搭骨架
我看这门课时,最有共鸣的是写作这一部分。
因为我自己也经常用 AI 辅助写东西,很清楚 AI 写作最常见的问题是什么。它能写得很通顺,每句话都完整,每一段看起来都像那么回事,但整篇读完之后,你会发现没什么记忆点。
吴恩达把这种东西叫 AI slop。用中文说,就是 AI 浆糊,或者 AI 工业糖精。它甜,顺,完整,但没营养。
很多人用 AI 写文章时,提示词是「帮我写一篇关于某某主题的文章,1000 字,逻辑清晰,语言流畅」。这类指令看起来明确,其实最关键的东西都没给,核心观点是什么、读者是谁、文章重点在哪里、哪些例子必须出现、哪些角度不要写,全都没有。
所以 AI 只能生成一篇平均文章。
吴恩达推荐的方法叫 Progressive Outlining,渐进式大纲。核心思路很简单,不要一上来就写全文,先反复打磨大纲。
第一步,让 AI 基于你的笔记列出几个大纲方向。第二步,你告诉它哪个角度对,哪个角度太平,哪个部分要前置,哪个例子可以删。第三步,让它把满意的大纲扩成核心要点。第四步,再改要点。第五步,最后才让它写正文。

这个流程看着慢,其实更快。
因为一篇文章最难改的从来不是某一句话,而是骨架。骨架错了,你后面再怎么润色,都只是给一栋歪楼贴墙纸。大纲阶段改一句话,可能影响后面整篇文章的走向;正文阶段再改结构,成本就高很多。
这也是我看完课程后最想记住的一点,写作时把 80% 的时间花在大纲和结构上,把 20% 的时间花在文本生成上,反而更容易写出能看的文章。
当然,这里还有一个前提,人不能消失。AI 可以帮你扩写,可以帮你找表达,可以帮你梳理逻辑,但核心观点、个人经历、真实情绪,最好还是你自己给。
写作这件事到最后还是很朴素,AI 可以把语言磨亮,但文章真正的重量,还是来自作者自己的判断。
让 AI 点评文章,别问感觉,要给标准
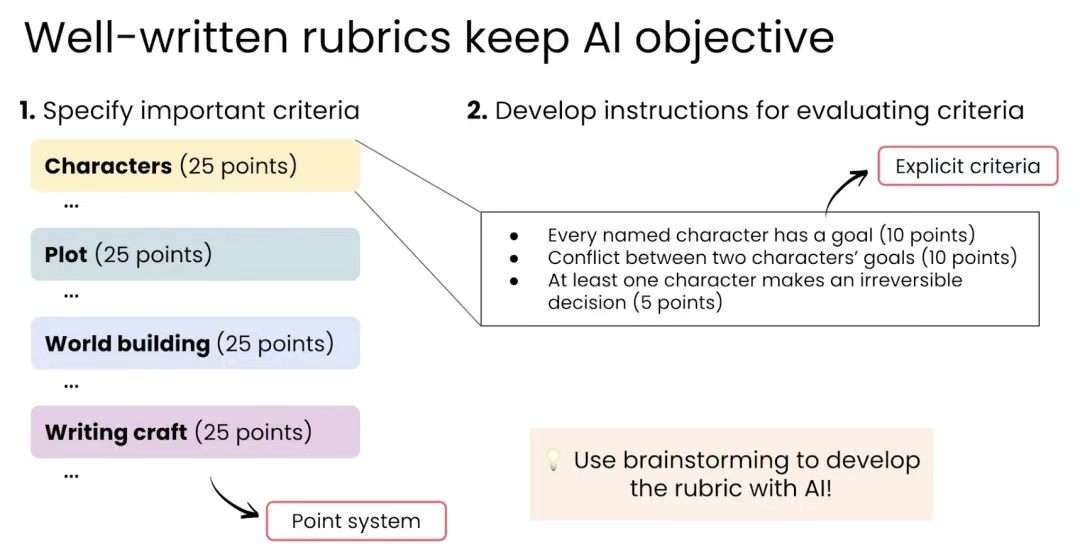
吴恩达还讲了一个很实用的技巧,Rubric,也就是评分标准。
很多人让 AI 修改文章时,会问「你觉得我这篇文章怎么样」或者「请你帮我润色这篇文章」。这太模糊了,AI 很容易开始礼貌性夸奖。它会告诉你结构清晰、表达流畅、观点明确,然后再给几个不痛不痒的建议。
想得到真正有用的反馈,你要给它一个明确的评分标准。比如评价一篇公众号文章,可以让它从开头吸引力、观点清晰度、案例密度、读者获得感、AI 味、结尾力度这几个维度检查。
比如:不要只写「是否吸引人」,而是写「前三段是否出现具体场景、反差或冲突」。不要只写「案例是否充分」,而是写「每个核心观点是否至少有一个具体例子支撑」。不要只写「表达是否自然」,而是写「有没有模板化过渡、空泛判断、没有真实细节的漂亮话」。
更进一步,你还可以做跨模型评审。让 ChatGPT 写,让 Claude 或 Gemini 按标准评;或者让一个模型出方案,另一个模型找漏洞。不同模型有不同的偏科,让它们互相拆台,有时候效果比自己反复看更好。
但最后拍板的还是人,AI 的批评也是一种参考,不是真理。它指出哪里可能有问题,你要不要改,怎么改,还是得回到自己的判断。说白了,我想到牛肉哥说的一句话:你得有自己的审美能力。
多模态和桌面应用,会让 AI 更像真正的工作伙伴
课程最后还讲了多模态能力,包括图片理解、图片生成、语音、视频、零代码做应用、数据分析。
它可以看图、读表格、分析数据、生成图像,甚至直接帮你搭一个简单应用。
比如你上传一张白板照片,它可以识别你写的内容,甚至根据图形推断你在讲什么。你上传一份 Excel,它可以调用代码分析数据,生成图表,找出趋势。你给它一个简单需求,比如番茄钟、AA 制计算器、单词卡片,它也可能直接生成一个能跑的小应用。
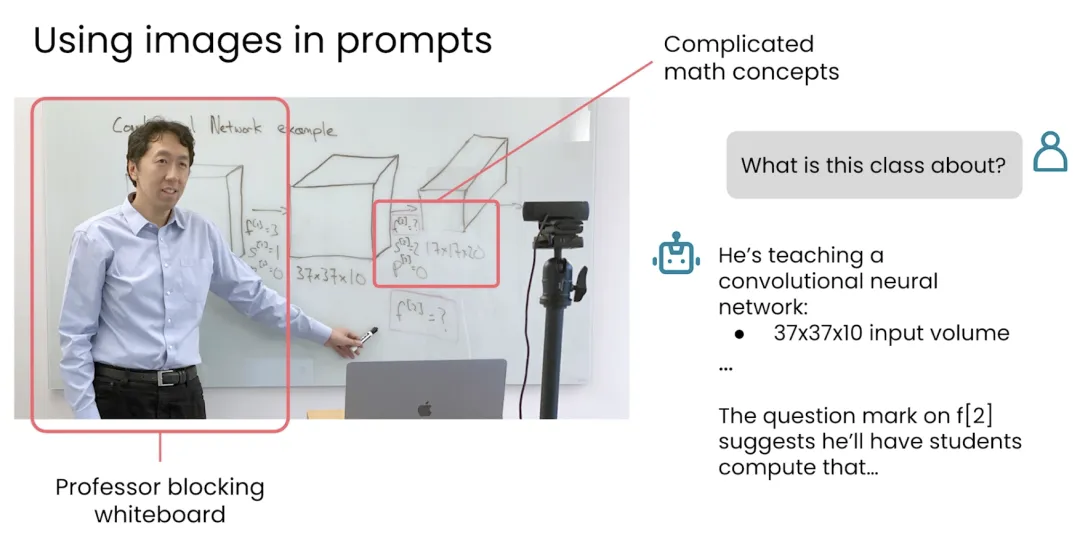
这些能力会越来越常见,也会越来越像真正的工作流。但这里也有一个很重要的提醒,能力越强,边界越重要。
尤其是桌面端 AI 应用,如果它能读取、修改、移动甚至删除你的文件,就一定要限制权限。
不要一上来给整个硬盘权限。最好只给它某个特定文件夹。涉及删除、覆盖、批量移动这类操作,一定要先让它提出计划,再由你确认。
AI 很勤奋,但它不一定懂你的文件有多重要。这句话放在任何 Agent 工具上都适用。
真正拉开差距的,不是模板,而是协作习惯
看完整门课,我发现其实真正有效的用法,背后其实都是一些很朴素的习惯,给足上下文,减少问题里的倾向,指定可靠来源,复杂任务先研究再回答,写作先改大纲再写正文,评价时给清晰标准,换话题时开新对话,涉及文件操作时限制权限。
如今AI 能做的事越多,你越需要告诉它你到底要什么;AI 能跑得越快,你越需要把方向盘握住。
如果你也在经常使用ai,我建议可以先试试几个很小的改变。
让它写文章时,先别写正文,先改大纲。
让它评价方案时,别问「怎么样」,给它评分标准。
让它查资料时,别只说「帮我搜」,告诉它优先找官方资料或论文。
它夸你时,别急着高兴,追问一句,反对意见是什么。
你会发现,AI 不是突然变聪明了,而是你终于不再把它当许愿机了。它开始更像一个伙伴,一个会犯错、会迎合、需要上下文、需要边界,但也真的能帮你把很多事情往前推一大截的伙伴。
我觉得这才是吴恩达这门课最有价值的地方。它没有教我们迷信 AI,而是在提醒我们别浪费 AI。
2026 年,真正过时的不是提示词,真正过时的,是那种把 AI 当搜索框、当许愿机、当复制粘贴模板机器的用法。