价格没变。大多数人换个模型就完事了,其他东西全错过。

跟 Opus 4.8 一起出的还有三样东西,它们对你在 Claude Code 里干活的影响,比那些跑分数字大得多:effort 控制、动态工作流、更便宜的 fast mode。会配置的人活干得更好,钱花得更少。下面是详细拆解。
唯一真正重要的那个数字
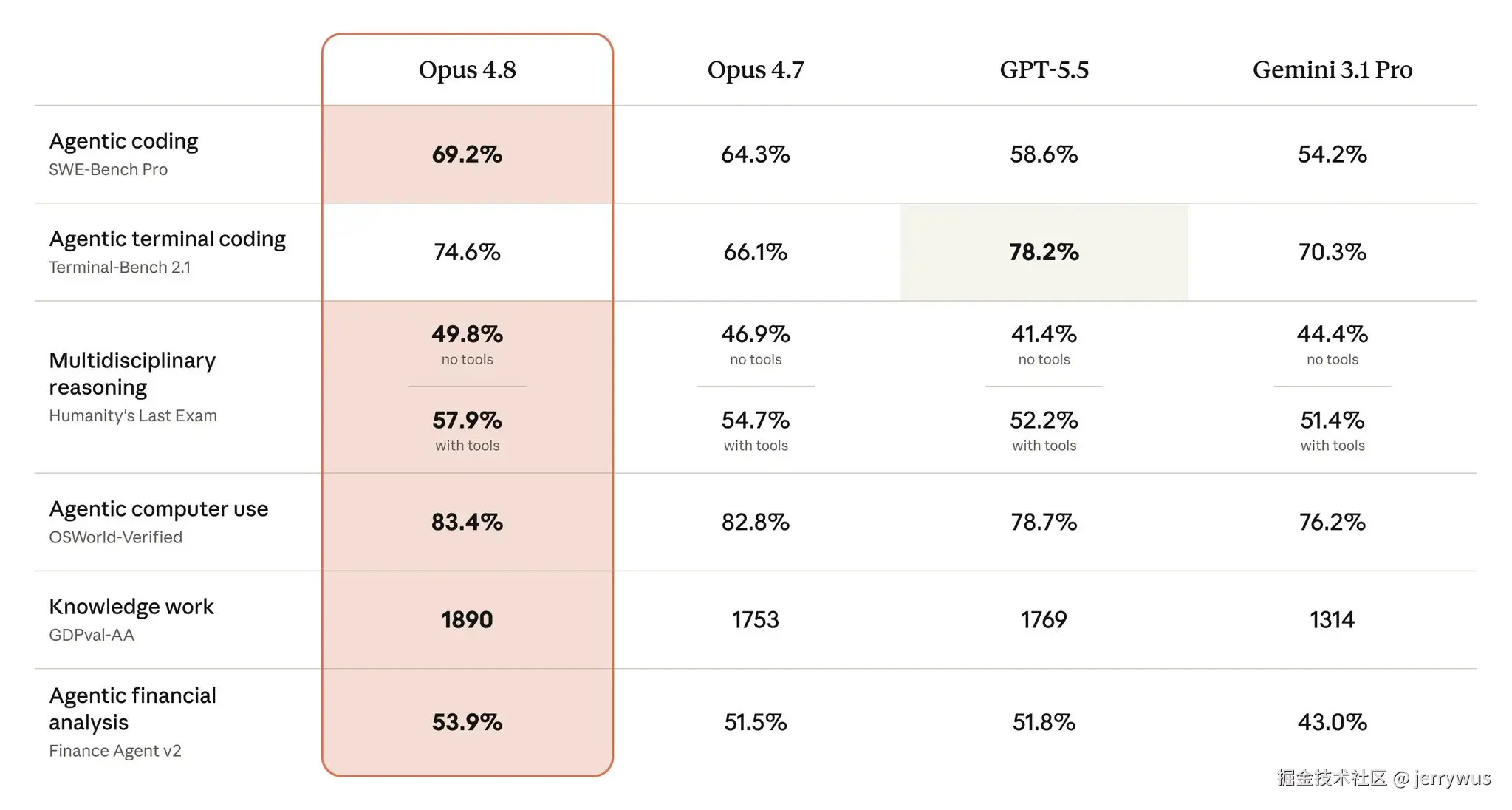
不是 coding 那个 69.2%。是 4.8 在自己写的代码里漏 bug 的概率,比之前低了大概 4 倍。
老模型有个毛病:证据不足也敢拍胸脯说"搞定了,bug 修好了"。这次 Anthropic 在诚实度上下了功夫,4.8 更愿意慢一点,遇到不确定的地方主动标出来,而不是憋出一段看着挺像那么回事、但悄悄把边界条件搞挂的代码。一个长会话下来,这事儿是会累积的。一个模型在第 15 轮老老实实承认"我没把握",能帮你省下第 40 轮 debug 的两小时。
改了啥:长话短说
Coding。
SWE-bench Verified:87.6% → 88.6%(已经摸到天花板)。SWE-bench Pro(更难、污染更少):64.3% → 69.2%,比 GPT-5.5 高 10 多个点。这是 coding 跑分里最值得看的一行。
Terminal。
Terminal-Bench 2.1:66.1% → 74.6%(+8.5),但 GPT-5.5 还领先(78.2%)。七个 benchmark 里,4.8 唯一输的就是这个。
知识工作。
GDPval-AA:1890 Elo,对比 GPT-5.5 的 1769。整张表里差距最大的一项。
Computer use。
OSWorld-Verified:83.4%(一部分提升来自 harness 升级,Anthropic 自己也大方说了)。
科学。
GPQA Diamond:93.6%,基本没动(两个模型都在 93% 以上,这叫饱和,不叫退步)。
Anthropic 自己给这次发布的定性是"有限但实在的提升"。跑分算是加分项,下面这几个改动才是真正值得关注的。
特性 1:effort 控制(最被低估的一个)
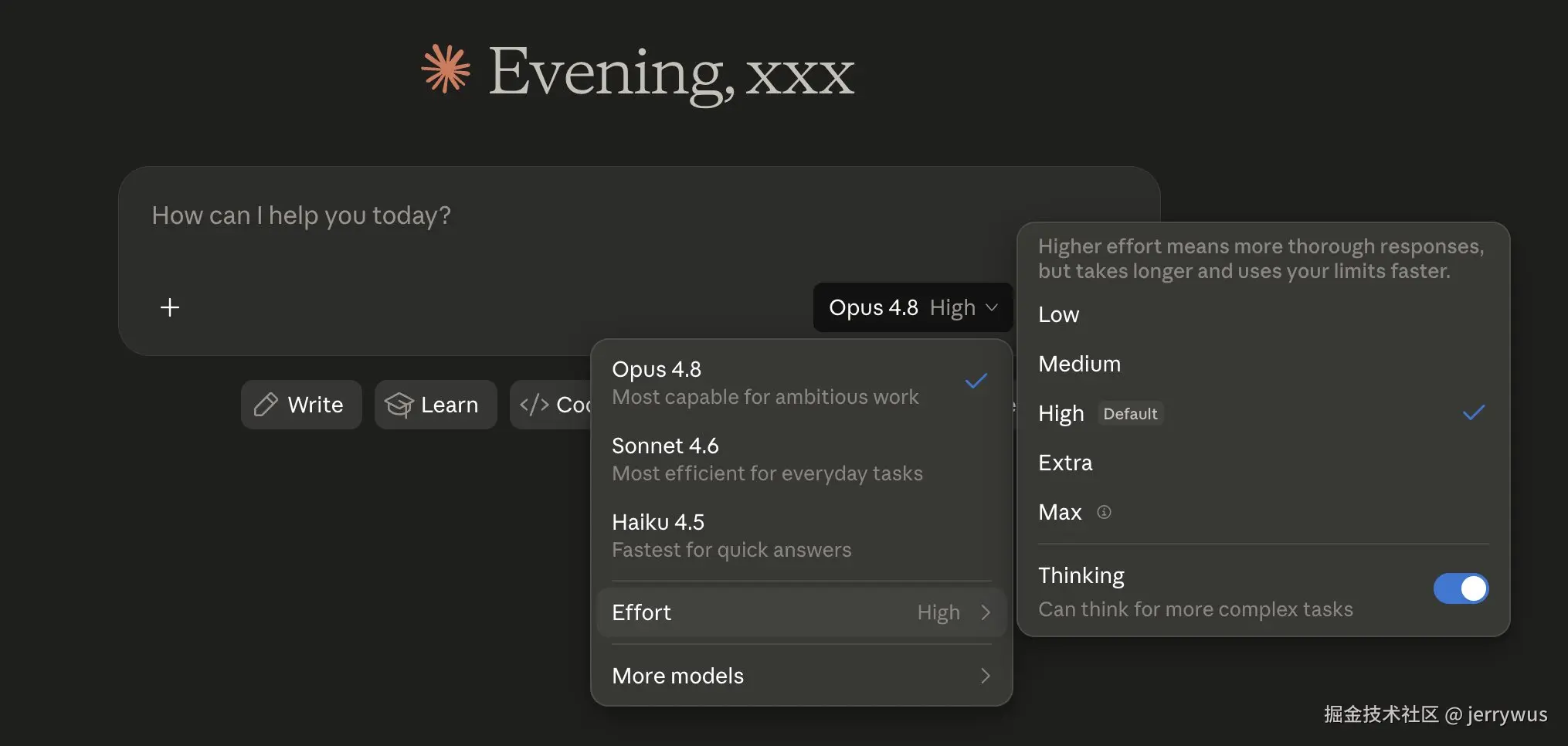
Opus 4.8 默认走 High effort。但现在思考的深度你说了算。把它想成推理的手动挡。
在 claude.ai 和 Cowork 里,滑块就在模型选择旁边,五档:Low、Medium、High(默认)、Extra、Max ,外加一个独立的 Thinking 开关。Claude Code 里档位一样,名字略有不同,还多了个 auto 模式:
text
/effort low # 简单问题、排版,token 用得最少
/effort medium # 日常 coding,平衡型
/effort high # 默认,推理稳
/effort xhigh # 对应 claude.ai 的 "Extra":更深,写代码和 agent 用
/effort max # 最大档,当前会话不限 token
/effort auto # 让模型自己决定(自适应思考)注意:claude.ai 里的 "Extra" 和 Claude Code 里的 xhigh 是同一档,只是不同界面叫法不一样。
钱怎么算,说清楚免得有人误会。 不同档位之间没有额外加价。每档单价都一样:输入 1M token 5,输出1Mtoken25。差的不是单价,是模型花的 token 数量。Low 回答简短、思考少,Max 思考长、烧的 token 是几倍。所以 Max "贵"是因为量大,不是单价高。
同一个任务在不同档下花销的大致比例(数字只是给你个感觉,不是精确值):
text
档位 深度 token 用量 什么时候用
Low 最少 ~0.1x 小事、排版、简单问题
Medium 适中 ~0.4x 日常改动、初稿、总结
High 稳 1x(基准) 日常 coding、code review(默认)
Extra 更深 ~2-3x 复杂代码、agent、长任务
Max 最大 ~4-8x 大型架构、最难的那种活举个钱的例子。假设一次 High 回答花 ~ 0.05,同一个请求走Low大概 0.005,走 Max 轻松到 ~$0.20-0.40。如果你 60% 的 prompt 都是小问题("这个函数返回什么?"),把它们从 High 调到 Low,日均花销直接砍掉一大截,关键场景的质量也不受影响。
为啥这事儿对账单影响最大。 大部分人会让所有任务都跑在 High(或者图省事直接拉到 Max),滑块根本不动。会按任务分配 effort 的人,效果一样,钱明显少花。我觉得这次发布里最被低估的就是这个。
特性 2:fast mode(便宜了 3 倍)
Fast mode 让 Opus 跑出 2.5 倍速度,质量不变,价格还比之前便宜 3 倍。
text
标准 Opus 4.8: $5 / $25 每 1M token
Fast mode 4.8: $10 / $50 每 1M token(2.5x 速度)
之前: $30 / $150Claude Code 里 /fast 切换(开启的会话会有个 ↯ 图标)。API 现在还要排队(候补在 claude.com/fast-mode)。
fast mode 适合: 多文件大重构、从 spec 生成代码、写文档、生成测试。凡是速度比深度重要的活。继续用标准模式: 复杂 debug、架构决策、安全 review。凡是思考质量比速度重要的活。
特性 3:动态工作流(重头戏)
Claude Code 现在会给你的任务写一个 JavaScript 编排脚本,丢后台跑,你的会话窗口照常响应。计划写在代码里,不占模型 context,只有最终结果回到你这边。
官方文档里要点:
- 最多 16 个 subagent 并发 ,单次运行总共硬上限 1000 个。
- 可恢复: 笔记本死机、终端关了,下次接着跑。
- 需要 Claude Code v2.1.154+。Research preview 阶段。
- Max、Team、Enterprise 默认开。Pro 用户去 /config 里手动打开(先切到 Opus 4.8)。
- Subagent 跑在 acceptEdits 模式下,继承你的工具白名单。
触发方式:/effort ultracode(Claude Code 的一个设置:xhigh 加自动工作流编排),或者直接用大白话描述一个大任务:
text
/effort ultracode
"审计 src/routes/ 下每个 endpoint,看缺没缺权限检查"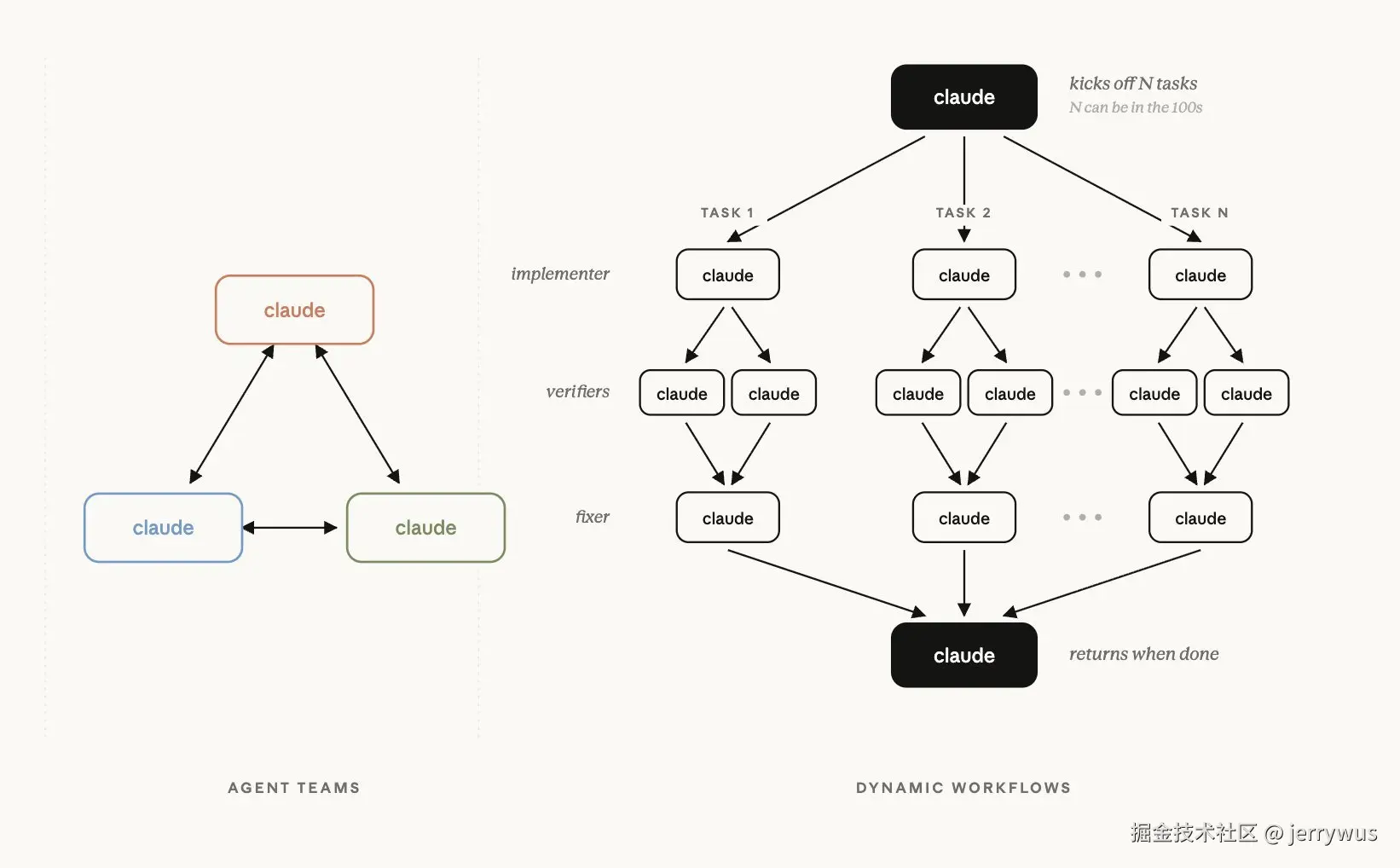
适合干: 200+ 文件的迁移、全代码库安全审计、全项目测试生成、大重构、跨多个仓库的调研。不适合干: 修小 bug、单文件改动、问个小问题。属于杀鸡用牛刀。
关于成本。 工作流烧的 token 比普通会话多得多。官方建议的省钱办法是缩范围:先在一个文件夹上跑一次审计,看它开了多少 subagent,再据此推算大任务的开销。
完全关掉工作流:
text
CLAUDE_CODE_DISABLE_WORKFLOWS=1.Claude Code 配置示例(起手模板)
环境变量(写在 ~/.zshrc 或 ~/.bashrc 里):
text
export ANTHROPIC_MODEL="claude-opus-4-8"
export CLAUDE_CODE_EFFORT_LEVEL=high # 持久默认 effort;要最深就改 max
# 完全关掉动态工作流:
# export CLAUDE_CODE_DISABLE_WORKFLOWS=1然后是真正有用的部分:一份带安全权限的 settings.json。它允许模型读改代码、跑测试、提交,但硬性禁掉危险操作:读 .env 和 SSH key、rm -rf、sudo、git push。Agent 该干啥干啥,搞不出事,也漏不了东西。
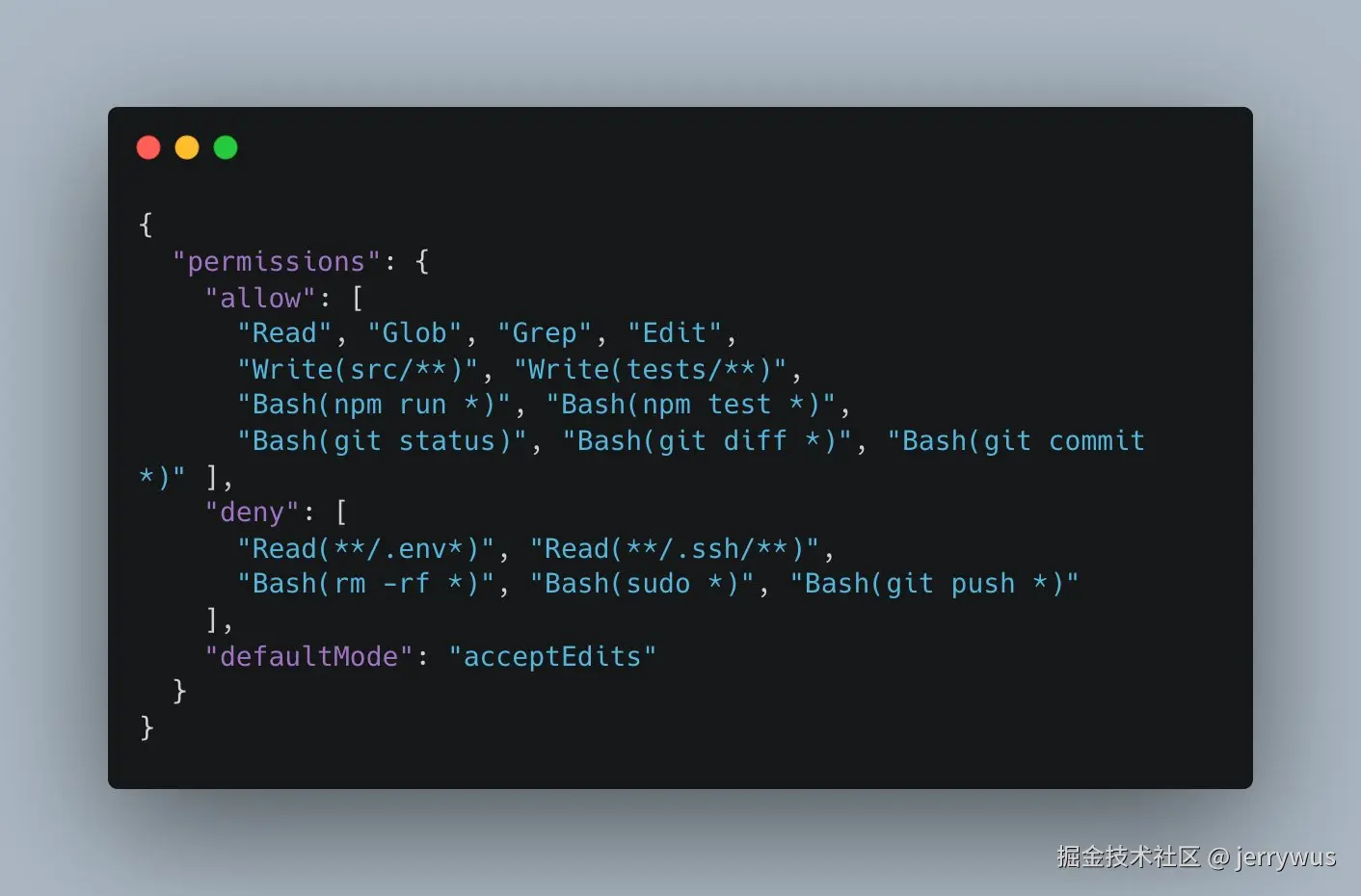
可以直接复制粘贴的 settings.json 在我的 Telegram 频道里(格式太长,这里读起来不方便):t.me/+JmDeelv5UC...
日常命令速查
text
/effort high # 一天开始,默认
/effort low # "这个函数返回啥?"
/fast # 速度优先的大重构
/effort ultracode # 全代码库审计、工作流
/model opus # 复杂任务
/model sonnet # 简单任务
/model haiku # 一次性的小问题装 Opus 4.8:三种方式
A. 浏览器或 App。 在 claude.ai 模型列表里选 Claude Opus 4.8,设好 effort 滑块。不用装东西。
B. API。 Model ID 是 claude-opus-4-8。价格 5/25 每 1M。Context 最大 1M(Microsoft Foundry 上是 200k),输出最大 128k。不再支持固定预算的 extended thinking:用自适应思考(thinking: {type: "adaptive"})配 effort 参数。
C. Claude Code(终端)。 现在官方推荐用原生安装方式(npm 是老路子):
text
# macOS / Linux
curl -fsSL https://claude.ai/install.sh | bash
# Windows(PowerShell,不是 CMD)
irm https://claude.ai/install.ps1 | iex
# Homebrew
brew install --cask claude-code
# 检查版本
claude --version
# 从 npm 迁移到原生
claude install然后跑 claude,浏览器登录,/model 选 Opus 4.8。
迁移清单:4.7 到 4.8
- 把 model ID 改成 claude-opus-4-8
- 拿你日常的 10-20 个真实任务,用一模一样的 prompt 在 4.7 和 4.8 各跑一遍
- 比对:完成率、步数、token、测试通过率
- 检查那些为 4.7 行为调过的 prompt
- 按任务类型分配 effort 档位
- 速度优先的场景试 fast mode
- Claude Code 升到 v2.1.154+(为了工作流)
- 第一周结束后再看一遍 API 账单
卡片:一图流
Model: claude-opus-4-8 · 2026-05-28 发布
价格: 5/25 每 1M · fast mode 10/50
Context: 最大 1M · 输出最大 128k
关键数字: SWE-bench Pro 64.3% → 69.2%(比 GPT-5.5 高 10 个点)· SWE-bench Verified 88.6% · 漏 bug 少 4 倍 · GDPval-AA 1890 Elo
新东西: effort 控制 · fast mode 便宜 3 倍 · 动态工作流(16 并发 / 单次 1000)
安装: curl -fsSL claude.ai/install.sh | bash
谢谢看到这里。如果只能从这篇里带走一句话,就带这句:"按任务分配 effort"。
【翻译声明】 原文链接:Opus 4.8: same price, you pay double
翻译人:@jerrywu185(如有不准欢迎指正)