一个 IoT 架构师开始学 AI Agent
做了 10 年物联网(智能家居 → 泛在物联网 → 工业物联网),面对 AI Agent 浪潮,我选择从 Java 生态切入,用工业场景验证。

为什么是现在
我在物联网领域做了十年,横跨智能家居、泛在物联网和工业物联网。搞过边缘网关,搭过云端的设备管理平台,也做过设备数据的全链路处理。这套「采集、传输、存储、分析、展示」的五层模型,在不同行业换过好几套皮,但底层的认知是通的。
但 2025 年之后,事情变了。不是工业场景变了,而是大模型让「自动决策」这件事的成本断崖式下降。
以前要实现「设备温度异常→自动诊断→给出维修建议」这个链路,你需要:1)建故障知识库,2)写大量 if-else 规则或训练分类模型,3)开发诊断引擎,4)维护规则迭代。每一步都要花钱花人。
现在呢?给 LLM 配上查询设备数据的工具,一句话就够了:
「CNC-001 告警了,查一下它的电流和历史数据,帮我分析一下可能原因。」
AI Agent 不是替代 SCADA 或 MES,而是给工业系统加了一层会推理的中间件。这层中间件能做我以前一直想做但成本太高的事情:自动诊断、自然语言交互、跨系统编排。
所以今年 5 月,我决定系统性地补齐 AI Agent 的能力,并用一个完整的工业项目来验证------industrial-agent-long。
技术选型:Java 人的 AI 路线
为什么不用 Python
一般提到 AI Agent 开发,所有人第一反应都是 Python + LangChain。教程、课程、开源项目全是 Python。
但我选了 Java + LangChain4j。
几个很实际的原因:
1. 工业软件生态是 Java 的天下。
工厂里的 MES、WMS、SCADA 后端,企业级的 Spring Boot 微服务,设备管理平台------Java 是工业互联网的事实标准。如果一个工业 AI Agent 最终要嵌入到现有系统中,用 Java 写的 Agent 可以零成本集成。没有 gRPC 跨语言调用,没有 REST 延迟,没有运维双栈。
2. Spring Boot 生态本身就是 Agent 基础设施。
LangChain4j 的 Spring Boot Starter 能做到什么程度?@Tool 注解一个 Bean 方法,AiServices.builder() 声明式组装,连 ChatMemory 都是自动注入的。这种开发体验,我觉得比 Python LangChain 舒服太多。
3. AI Agent 的壁垒在场景,不在语言。
LLM 是远程 API 调用,Agent 是编排逻辑,真正的差异化在于你对设备场景的理解和工具链的设计------这些跟语言无关。
技术栈清单
| 组件 | 选型 | 理由 |
|---|---|---|
| 框架 | Spring Boot 3.3 + Java 21 | 工业级标准,生态完备 |
| Agent | LangChain4j 0.35.0 | Java 原生 Agent 框架,@Tool 注解式声明 |
| LLM | DeepSeek (OpenAI 兼容) | 性价比高,中文能力强 |
| 通信 | MQTT (Eclipse Paho) | 工业设备事实标准 |
| 模拟器 | EMQX 5.7 + Java 定时任务 | 本地开发零成本 |
架构设计:工业设备智能运维 Agent
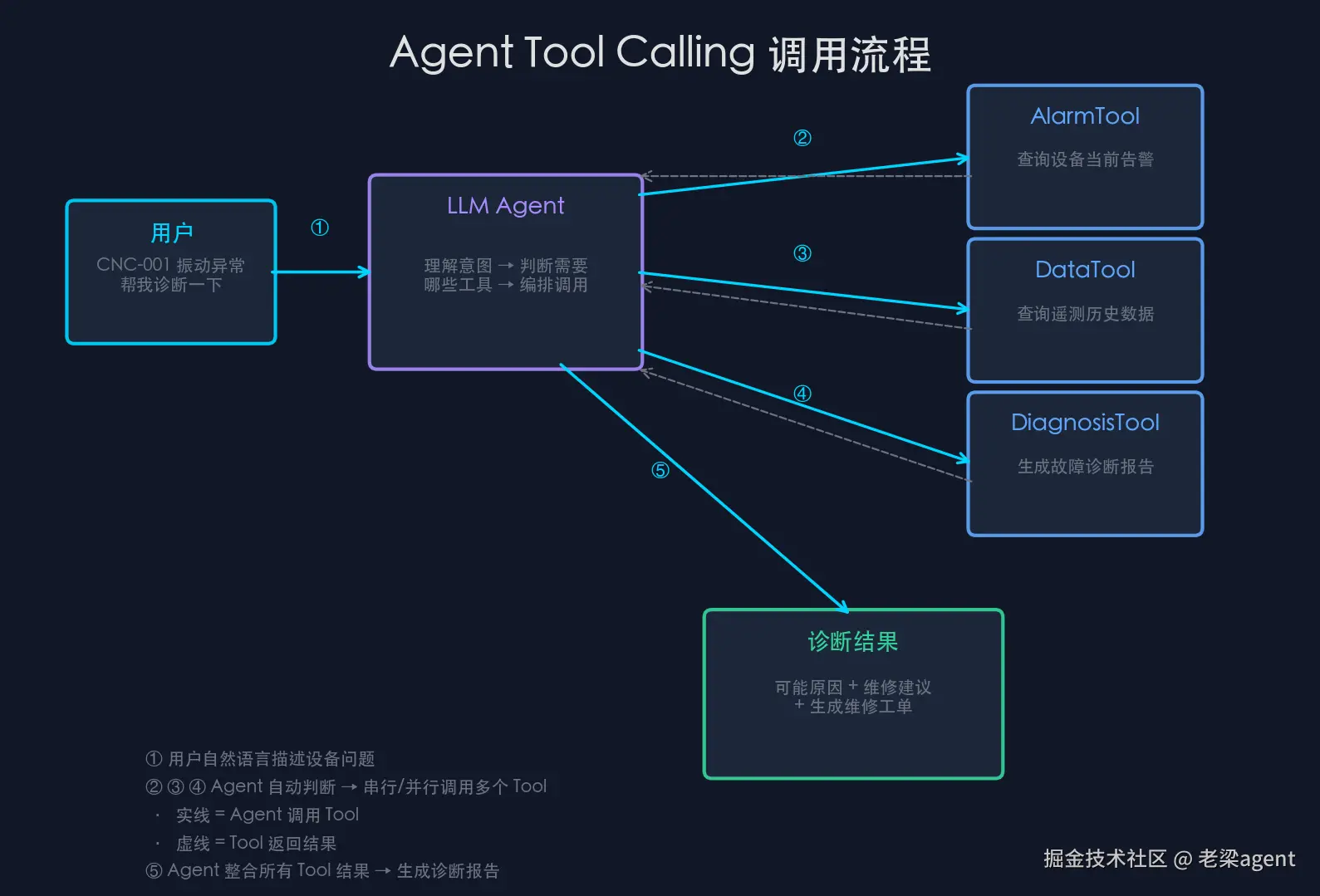
 项目的核心场景是:产线设备异常振动 → Agent 接收告警 → 查询历史数据 → 知识库诊断 → 给出维修建议。
项目的核心场景是:产线设备异常振动 → Agent 接收告警 → 查询历史数据 → 知识库诊断 → 给出维修建议。
scss
┌─────────────────────────────────────┐
│ REST API (POST /api/agent/chat) │ ← 用户/上层系统
├─────────────────────────────────────┤
│ DeviceAgent │ ← Agent 编排
│ - AiServices.builder() │
│ - Memory: MessageWindowChat │
├──────────┬──────────┬───────────────┤
│ Alarm │ Data │ Diagnosis │ ← Tool 层
│ Tool │ Tool │ Tool │
├──────────┴──────────┴───────────────┤
│ Device Simulator (MQTT) │ ← 设备模拟
└─────────────────────────────────────┘项目结构很简洁,五个核心文件:
bash
src/main/java/com/industrial/agent/
├── AgentApplication.java # Spring Boot 入口
├── config/AgentConfig.java # LLM 和 Memory 配置
├── agent/
│ ├── DeviceAgent.java # Agent 主逻辑
│ └── tools/
│ ├── DeviceAlarmTool.java # 查询设备告警
│ ├── DeviceDataTool.java # 查询历史遥测
│ └── DiagnosisTool.java # 故障诊断
├── controller/AgentController.java # REST API
└── simulator/DeviceSimulator.java # MQTT 设备模拟器设计的几个关键决策
1. Tool 是模拟数据,但接口是真实的生产形态。
三个 Tool 现在返回的是随机数+规则诊断,但它们的入参/出参设计直接对齐真实数据源------TDEngine 的时序查询、Elasticsearch 的日志检索、Milvus 的向量检索。后续换成真实数据源,接口不变。
2. 一个 Agent,三个 Tool,够用就好。
很多教程一上来就是多 Agent 编排、Supervisor 模式、LangGraph 状态机。第一阶段不需要。一个 Agent 配上正确设计的 Tool,已经能解决 80% 的工业诊断场景。等 Tool 数量超过 7-8 个,或者需要多轮自主决策时,再引入多 Agent 不迟。
3. MQTT 不是必须的,但它是工业味的来源。
不用 MQTT 也能跑通 Agent,但加上设备模拟器之后,整个项目的「工业感」立刻不一样。后续接真实的 EMQX 集群、TDEngine 时序库,架构不需要改。
核心实现:Agent 是怎么「学会」调用工具的
Step 1: 配置 LLM 和 Memory
java
// AgentConfig.java
@Configuration
public class AgentConfig {
@Bean
public OpenAiChatModel chatModel() {
return OpenAiChatModel.builder()
.baseUrl("https://api.deepseek.com") // DeepSeek 兼容 OpenAI 格式
.apiKey(apiKey)
.modelName("deepseek-chat")
.temperature(0.3) // 低温度,工业场景需要确定性
.maxTokens(2048)
.timeout(Duration.ofSeconds(60))
.build();
}
@Bean
public ChatMemory chatMemory() {
return MessageWindowChatMemory.withMaxMessages(20); // 保留最近 20 轮对话
}
}两点说明:
- temperature=0.3:工业场景要确定性,不能让 Agent 瞎编故障原因。0.3 是实践下来比较合适的值------既有推理空间,又不会太「放飞」。
- maxTokens=2048:单次诊断报告加上上下文,2048 够用。节省 token 就是节省成本。
Step 2: 声明 Tool
LangChain4j 的 Tool 声明极其简洁:在方法上加 @Tool 注解,注解里的字符串就是给 LLM 看的工具描述。
java
// DeviceAlarmTool.java
@Component
public class DeviceAlarmTool {
@Tool("查询指定设备的当前告警信息。输入设备ID,返回该设备的所有活跃告警。")
public String queryDeviceAlarms(String deviceId) {
// ... 告警查询逻辑
}
}LLM 会根据 @Tool 中的描述文本,在对话中自动判断「用户这句话需要用哪个工具」。这是 Tool Calling 的核心------不需要你写 if-else 判断意图,LLM 自己决定什么时候调用哪个工具。
三个工具各司其职:
| Tool | 职责 | 对应真实数据源 |
|---|---|---|
| DeviceAlarmTool | 查询设备当前活跃告警 | TDEngine / InfluxDB |
| DeviceDataTool | 查询遥测历史数据(温振压流) | TDEngine |
| DiagnosisTool | 基于告警+数据生成诊断 | Milvus 知识库检索 + LLM |
Step 3: 组装 Agent
java
// DeviceAgent.java
@Service
@RequiredArgsConstructor
public class DeviceAgent {
private final OpenAiChatModel chatModel;
private final ChatMemory chatMemory;
private final DeviceAlarmTool alarmTool;
private final DeviceDataTool dataTool;
private final DiagnosisTool diagnosisTool;
public String chat(String userMessage) {
IndustrialAssistant assistant = AiServices.builder(IndustrialAssistant.class)
.chatLanguageModel(chatModel)
.chatMemory(chatMemory)
.tools(alarmTool, dataTool, diagnosisTool)
.build();
return assistant.chat(userMessage);
}
interface IndustrialAssistant {
String chat(String message);
}
}AiServices.builder() 是 LangChain4j 的精华。你只需要声明一个接口(IndustrialAssistant),把 LLM、Memory、Tools 注册进去,框架自动生成实现类。背后做的事情:
- 把 Tool 的
@Tool描述转成 OpenAI Function Calling 的 JSON Schema - 每次调用
chat()时,框架把用户消息+对话历史+工具描述一起发给 LLM - LLM 返回
tool_call→ 框架自动调用对应的 Java 方法 → 把结果再发给 LLM → LLM 生成最终回复
**整个过程对开发者透明。**你不需要写任何 JSON 解析、工具路由、结果拼接的逻辑。
实测效果
用 curl 测试单个工具调用:
bash
curl -X POST http://localhost:8080/api/agent/chat \
-H "Content-Type: application/json" \
-d '{"message": "CNC-001 现在有什么告警?"}'Agent 自动识别「查告警」意图 → 调用 queryDeviceAlarms("CNC-001") → 返回:
json
{
"deviceId": "CNC-001",
"status": "warning",
"activeAlarms": [{"type": "振动异常", "severity": "HIGH", "timestamp": "..."}]
}复杂场景测试------一句话触发三个工具:
bash
curl -X POST http://localhost:8080/api/agent/chat \
-H "Content-Type: application/json" \
-d '{"message": "CNC-001 刚报了振动异常告警,查一下它最近的数据,帮我诊断一下。"}'Agent 的执行链路:
markdown
1. LLM 理解意图 → 需要先查告警 + 查数据
2. 调用 queryDeviceAlarms("CNC-001") → 返回告警信息
3. 调用 queryDeviceHistory("CNC-001") → 返回遥测数据
4. LLM 分析结果 → 发现振动值超标,需要诊断
5. 调用 generateDiagnosis("振动异常", "vibration=4.8mm/s>2.8")
6. LLM 整合所有信息 → 生成完整诊断报告这才是 AI Agent 的真正价值:LLM 自己决定「先做什么、后做什么、什么时候够了」。 这不是工作流引擎里的固定 DAG,而是动态推理。
踩过的几个坑
1. DeepSeek API 鉴权失败
DeepSeek 的 API 是 OpenAI 兼容的,但 api-key 不能直接写占位符。最开始我在 application.yml 里留了 your-api-key-here,结果 401 错误排查了半小时。
教训 :把 API Key 放在 application-local.yml(加入 .gitignore),用 Spring 的 spring.config.import: optional:classpath:application-local.yml 自动覆盖。本地开发方便,git push 不会泄露。
2. LangChain4j 版本升级的 API 变化
0.35.0 版本的 ToolSpecifications.toolSpecificationsFrom() 方法签名变了,不再接受多个 Object 参数。花了一些时间查源码才发现------其实根本不需要手动构造 ToolSpecification,AiServices.builder().tools() 直接把 Bean 丢进去就行,框架自己处理。
教训:框架的「魔法」往往比你手写的代码更正确。先信任框架默认行为,不行再深究。
3. 调试 Agent 调用链
Agent 的 Tool Calling 是黑盒------你调用 chat(),得到一个回复,但中间 LLM 调用了几个工具、传了什么参数、结果是什么,全部不可见。
解决方案:打开 LangChain4j 的请求/响应日志:
yaml
langchain4j:
open-ai:
chat-model:
log-requests: true # 打印发给 LLM 的完整请求
log-responses: true # 打印 LLM 返回的完整响应(含 tool_calls)这样控制台能看到完整的 tool_calls JSON,调试效率提升巨大。
4. EMQX 没启动的时候别慌
设备模拟器在应用启动时连接 MQTT broker,如果本地没启动 EMQX,会抛 MqttException。加了 try-catch,连不上就优雅跳过,不影响 Agent 功能。
java
try {
client.connect(options);
} catch (MqttException e) {
log.warn("[Simulator] MQTT broker not available --- running without device simulation.");
}下一步
第一周跑通了基础 Agent 循环,接下来的方向:
短期:补齐 LLM 理论基础(Attention 机制、RAG 原理、Agent 记忆管理),同时做一个 ROS2 架构概览的学习------为后续 Agent + 机器人做准备。
中期:升级到完整的工业设备运维 Agent MVP------接入 TDEngine 真实时序库、Milvus 向量知识库做 RAG 检索、多 Agent 协作。
长期:边缘推理 + 实时控制------把 Agent 从云端推到工厂现场。
最后
如果你也是一个后端/物联网工程师,想进入 AI Agent 方向但被 Python 生态劝退------我的建议是:用你最熟悉的语言,从你最熟悉的场景切入。AI Agent 的门槛不在于语言,而在于你能否把一个真实场景拆解成 LLM 能理解和调用的一套工具。
工业 + AI Agent 这个交叉领域,目前做的人不多。但工厂里有成千上万的设备、海量的告警、大量的诊断工单------这些都是 Agent 的天然战场。
项目地址:github.com/LaoLiang-ag...
下一篇预告:「LangChain4j + DeepSeek:Java 开发者构建第一个 Agent 的完整指南」
本文由 LaoLiang 原创,首发于掘金/知乎/微信公众号。转载请联系作者。