索引是任何 RAG 系统的基础,因为它们决定了信息能够被多高效、多有效地检索和使用。本章将深入介绍 LlamaIndex 中可用的不同索引类型。它会解释索引如何工作,以及它们的关键能力、定制选项、底层架构和使用场景。总体而言,本章可以作为一份指南,帮助你利用 LlamaIndex 中的索引功能,构建高性能且可扩展的 RAG 系统。
让我们开始吧!
在本章中,我们将覆盖以下主题:
- 索引数据------鸟瞰视角
- 理解
VectorStoreIndex - 理解 embeddings
- 持久化和复用索引
- 探索 LlamaIndex 中的其他索引类型
- 使用
ComposableGraph在索引之上构建索引 - 管理索引的生命周期
- 构建和查询索引时的成本考虑
技术要求
本章需要在环境中安装以下包:
- ChromaDB:www.trychroma.com/
此外,示例代码还需要两个集成包:
- Chroma Vector Store:pypi.org/project/lla...
- Hugging Face embeddings:pypi.org/project/lla...
本章的所有代码示例,都可以在本书 GitHub 仓库的 ch5 子文件夹中找到:
索引数据------鸟瞰视角
我们已经在第 3 章的"揭开 LlamaIndex 的核心构建块:文档、节点和索引"一节中,简要讨论过索引在 RAG 应用中的重要性和基本工作方式。在这里,我们将更仔细地看看 LlamaIndex 中可用的不同索引方法,以及它们的优势、劣势和具体使用场景。
原则上,即使没有索引,数据也仍然可以被访问。但这就像读一本没有目录的书。只要它讲的是一个具有连续性的故事,可以一节一节、一章一章地顺序读下去,阅读会是一种享受。然而,当我们需要在那本书中快速搜索某个特定主题时,情况就变了。没有目录,搜索过程会变得缓慢而笨重。
在 LlamaIndex 中,索引(indexes)代表的不只是一个简单目录。索引不仅提供导航所需的结构,还提供更新或访问它的具体机制。这包括 retriever 的逻辑,以及用于获取数据的机制。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中详细讨论这些内容。
在本书中,我会保持内容简单,给你介绍索引如何工作的基础,并提供一些示例来帮助你理解它们的用法。探索这些索引的所有可能用法和组合方式,会是一项巨大的任务,也超出了本书范围。
我们稍后会谈到每种索引类型的独特之处,但首先,让我们看看它们共同具备哪些特性。
LlamaIndex 中每种索引类型都有自己的特点和功能,但因为它们都继承自 BaseIndex 类,所以存在一些所有索引共享的特性和参数,可以针对任意类型的索引进行定制:
Nodes :所有索引都基于节点,我们可以选择哪些节点被包含在索引中。此外,大多数索引类型都提供插入新节点或删除现有节点的方法,使索引能够随着数据变化而动态更新。我们既可以通过将节点直接传给索引构造函数,基于已有节点构建索引,例如 vector_index = VectorStoreIndex(nodes),也可以使用 from_documents() 将文档列表作为输入,让索引自行提取节点。请记住,在真正构建索引之前,我们可以使用 Settings 来定制其底层机制。正如第 3 章"定制 LlamaIndex 使用的 AI 模型"一节中讨论过的,这个简单类允许调整不同设置,例如更改索引使用的 LLM、嵌入模型或默认节点解析器。
storage context:storage context 定义索引的数据,也就是文档和节点,如何以及存储在哪里。根据应用需求,高效管理数据存储时,这种定制非常关键。
进度显示 :show_progress 选项允许我们选择,在构建索引等长时间运行操作中是否显示进度条。这个功能基于 tqdm Python 库实现,对于监控大型索引任务的进度非常有用。
不同检索模式:每种索引都允许使用不同的预定义检索模式,这些模式可以根据应用的具体需求进行设置。你也可以定制或扩展 retriever 类,以改变查询如何被处理,以及结果如何从索引中被检索出来。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中进一步讨论。
异步操作 :对于某些索引,use_async 参数用于确定某些操作是否应该异步执行。异步处理允许系统并发管理多个操作,而不是等待每个操作按顺序完成。这对于性能优化可能很重要,尤其是在处理大型数据集或复杂操作时。
在进一步深入并开始折腾示例代码之前,有一件重要事情需要考虑:索引通常会依赖 LLM 调用来进行摘要或 embedding。就像第 4 章《将数据摄取到我们的 RAG 工作流中》中讨论的元数据提取一样,LlamaIndex 中的索引也可能引发成本和隐私方面的担忧。在运行任何大规模实验来测试想法之前,请务必阅读本章末尾与成本相关的部分。
由于向量存储索引大约出现在 80% 的真实世界 RAG 使用场景中,我们会花更多时间探索它如何工作,并理解它为什么被如此广泛采用。因为如果你只打算把一种索引类型学深学透,那么这就是实践中最有用的一种。所以,让我们从第一个,也是最常用的索引类型开始。
理解 VectorStoreIndex
在 LlamaIndex 中,向量存储索引是一种主力索引,也是最常用的索引类型。
对于大多数 RAG 应用来说,VectorStoreIndex 可能是最佳解决方案,因为它便于在文档集合上构建索引,其中输入文本 chunk 的 embeddings 会被存储在索引的向量存储中。构建完成后,这个索引可以用于高效查询,因为它允许在文本的嵌入表示上进行相似性搜索,因此非常适合那些需要从大型数据集合中快速检索相关信息的应用。LlamaIndex 中的 VectorStoreIndex 类默认支持这些操作,也支持异步调用和进度跟踪,这可以在典型 RAG 场景中改善性能和用户体验。如果你还不熟悉 embeddings、vector store 或 similarity searching 这些术语,也不用担心,因为我们将在接下来的几节中介绍它们。
构建向量存储索引
下面是构建 VectorStoreIndex 最基础的方式:
python
import models_config
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("files").load_data()
index = VectorStoreIndex.from_documents(documents)
print("Index created successfully!")和前几章一样,我们导入 models_config,以便配置 LlamaIndex 使用我们本地托管的 embedding 模型。正如你所看到的,只用几行代码,我们就通过 SimpleDirectoryReader 摄取了文档,而 VectorStoreIndex 对象负责处理所有事情:它自动将文档解析成节点,使用配置好的模型为每个节点生成 embedding,将它们存储到向量数据库中,并为后续查询连接好检索逻辑。通过这种方法,我们完全跳过了节点解析步骤,因为索引通过 from_documents() 方法自己完成了这个过程。
VectorStoreIndex 有几个可以定制的参数:
use_async :这个参数启用异步调用。默认设置为 False。
show_progress :这个参数会在索引构建过程中显示进度条。默认值为 False。
store_nodes_override :这个参数会强制 LlamaIndex 将节点对象存储到 index store 和 document store 中,即使 vector store 已经保存了文本。这在某些场景中很有用,例如即使节点内容已经存储在 vector store 中,你仍然需要直接访问节点对象。我们将在本章后面更详细讨论 index store、document store 和 vector store。这个参数默认设置为 False。
insert_batch_size :这个参数控制索引过程中单个批次处理多少节点。默认值为 2048,在大多数环境中,它在速度和内存使用之间取得了较好平衡。不过,如果你在内存有限的机器上处理大型数据集,或者你使用的是有速率限制或大小约束的远程 vector store,可能需要降低这个值。
值得一提的是,use_async 标志并不局限于索引构建。你也可以在后续将索引转换为 Query Engine 或 retriever 时激活异步处理。只需要向方法调用传入 use_async=True,例如:
ini
index.as_query_engine(use_async=True)这让你可以根据实际运行查询的上下文,灵活控制异步行为。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中更多讨论 Query Engine 和其他索引查询方法。
你还会发现,VectorStoreIndex 支持在数据被索引后删除数据。主要有两种方式。第一种是通过 delete_nodes() 方法指定节点 ID,删除单个 chunk。当你想精准移除数据集中的小部分内容时,这很有用。第二种是,如果你想删除整篇文档以及它关联的所有节点,可以使用 delete_ref_doc(),并传入该文档的 reference ID。
让我们看一下图 5.1,它用视觉方式展示了向量存储索引:
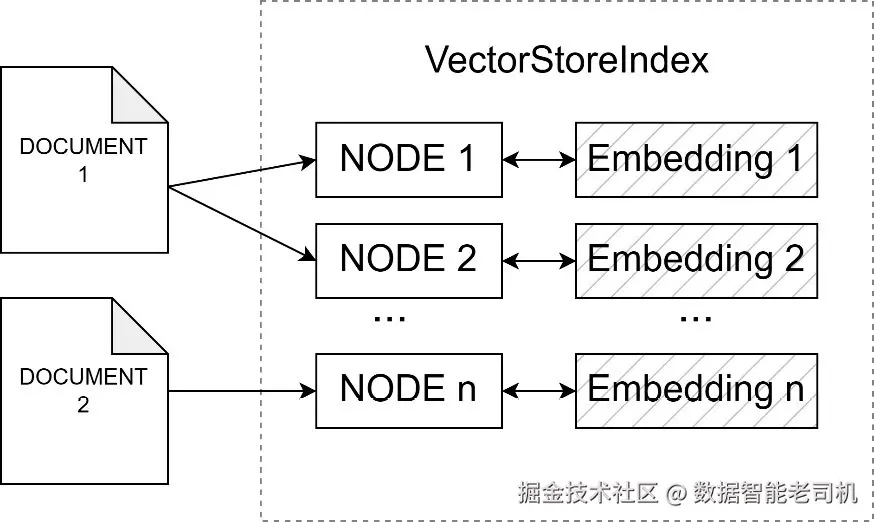
图 5.1 ------ VectorStoreIndex 的结构
VectorStoreIndex 接收摄取进来的文档,并将它们拆分成节点。它使用默认参数进行文本拆分、chunk size、chunk overlap 等操作。当然,如果我们愿意,也可以定制所有这些参数。
固定大小分块只是简单地将文本拆分成相同大小的 chunk,并可选择带有一定重叠。虽然这种简单分块计算成本低、实现简单,但它未必总是最佳方法。测试不同 chunk size 的性能,是针对应用具体需求进行优化的关键。
包含原始文本 chunk 的节点随后会使用语言模型被嵌入到高维向量空间中。嵌入后的向量会被存储在索引的 vector store 组件中。现在,当发起一个查询时,查询文本也会以类似方式被嵌入,并使用一种叫做余弦相似度(cosine similarity)的方法,与已存储向量进行比较。最相似的向量,也就是最相关的文档 chunk,会作为查询结果被返回。这个过程利用向量空间的数学属性,找到最能回答用户查询的文档,从而实现快速且具备语义感知能力的信息检索。
听起来有点困惑?我们会在下一节一起走过这些概念。
理解 embeddings
简单来说,向量 embeddings 表示一种机器可以理解的数据格式。它们捕捉含义,并且从概念上可以表示一个词、一整篇文档,甚至是图像和声音等非文本信息。从某种角度看,embeddings 代表了 LLM 的一种标准化思维语言。在 LLM 的上下文中,向量 embeddings 是模型理解和处理信息的基础表示。它们将多样且复杂的数据转换成统一的高维空间,LLM 可以在这个空间中更有效地执行比较、关联和预测等操作。
值得注意的是,embedding 模型和 LLM 服务于非常不同的目的。embedding 模型,例如 nomic-embed-text,会将文本转换成数值向量。它的工作是以一种可以进行相似性比较的格式捕捉含义,我们会在本节讨论这一点。而 LLM,例如 Gemma,则生成文本。它读取 prompt 并生成响应。在 RAG 流水线中,二者互相补充:embedding 模型帮助找到正确的信息,LLM 使用这些信息来组织答案。embedding 模型通常也比 LLM 小得多,运行速度也更快,这使得检索步骤即使在大规模场景下也能保持高效。
图 5.2 展示了数据 embedding 过程:
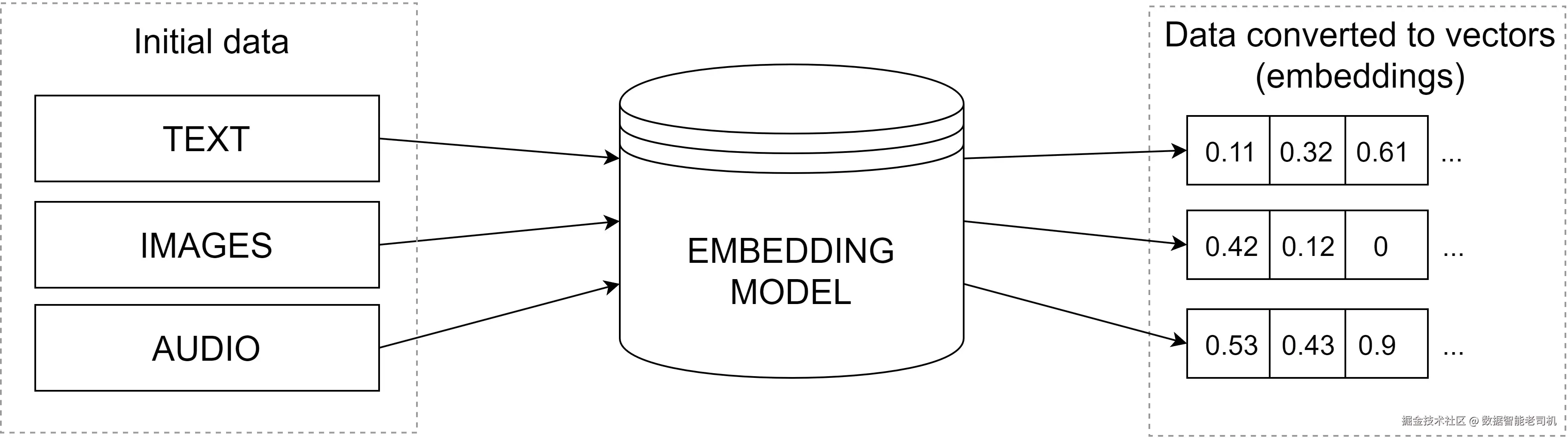
图 5.2 ------ embedding 模型如何将数据转换成数值表示
底层全是数学。而数学擅长处理数字------更准确地说,是大型浮点数列表,其中每个数字代表假想向量空间中的一个维度。LLM 可以处理这些数字数组,基于它接收到的输入来理解、解释并生成响应。本质上,向量 embeddings 中的这些数字让 LLM 能够以一种有意义且结构化的方式"看见"和"思考"数据。
这个系统的美妙之处,在于它能够处理模糊性和复杂性。模型可以理解词语之间的语义关系,例如同义词、反义词,以及更复杂的语言模式。对于多义词,同一个词在不同上下文中可能具有不同含义。例如,bank 这个词可以指河岸,也可以指金融机构。向量 embeddings 通过提供上下文敏感的表示,帮助 LLM 理解这些细微差别。因此,在一种情境中,bank 可能与 river 和 shore 等词紧密关联;而在另一种情境中,它会更接近 money 和 account。
一个需要考虑的重要因素是,被嵌入的文本 chunk 大小会影响精度------太小会丢失上下文;太大则可能因为包含太多额外细节而稀释含义。
如果你还不太熟悉 embeddings,下面这个示例可以帮助你更好地把握这个概念。让我们为三个随机选择的句子分配一些任意向量 embeddings:
Sentence 1 :The quick brown fox jumps over the lazy dog
Sentence 2 :A fast dark-colored fox leaps above a sleepy canine
Sentence 3:Apples are sweet and crunchy
在真实场景中,与每个句子关联的 embeddings 会通过 embedding 模型自动计算出来。embedding 模型是一种专门的 AI 模型,用于将文本、图像或图等复杂数据转换成数值格式。embeddings 通常也是高维的,但为了说明方便,我会使用简单的三维任意向量。下面是这三个句子的假想 embeddings:
Sentence 1 Embedding :[0.8, 0.1, 0.3]
Sentence 2 Embedding :[0.79, 0.14, 0.32]
Sentence 3 Embedding :[0.2, 0.9, 0.5]
这些数字纯粹是概念性的,目的是展示句子 1 和句子 2 含义相似,因此它们在向量空间中的 embeddings 更接近。句子 3 含义不同,因此它的 embedding 距离前两个更远。请看图 5.3,它对三个 embeddings 做了直观视觉比较:
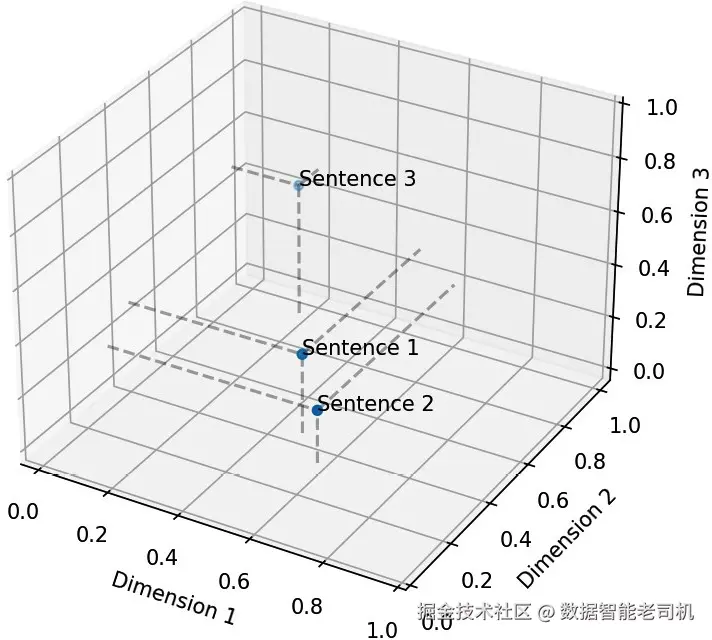
图 5.3 ------ 三个嵌入句子在 3D 空间中的比较
当我们在三维空间中可视化它们时,句子 1 和句子 2 会被绘制在彼此附近,而句子 3 则被绘制在较远的位置。这种空间表示,使机器学习模型能够判断语义相似性。
当你在 vector store index 上使用查询来检索有用上下文时,LlamaIndex 会将你的搜索词转换成类似 embedding,然后在文本 chunk 的预计算 embeddings 中找到最接近的匹配项。
我们称这个过程为相似性搜索或距离搜索。所以,当你遇到 top-k similarity search 这个术语时,你应该知道,它依赖一种计算向量 embeddings 之间相似度的算法。它接收一个向量 embedding 作为输入,并返回 vector store 中找到的最相似的 k 个向量。由于初始向量和返回的 top-k 邻居彼此相似,我们可以认为它们的含义在概念上也是相似的。现在你应该明白,为什么我之前把 embeddings 称为 LLM 的标准思维语言。它们究竟代表文本、图像,还是任何其他类型的信息,已经不再重要。我们用数字来衡量它们的相似性。
唯一可能根据使用场景不同而有差异的,是定义距离或相似度的实际公式。
剧透提醒:接下来会有一点数学概念。
理解相似性搜索
在机器学习和深度学习领域,相似性搜索这个概念非常重要。它构成了许多应用的支柱,从推荐系统和信息检索,到聚类和分类任务都是如此。当模型和系统与高维数据交互时,识别数据点之间的模式和关系就变得至关重要。这涉及衡量数据元素有多接近或多相似,而这项任务通常发生在向量空间中,其中每个 item 都表示为一个向量。
在这个空间中定位彼此接近的点,使机器能够评估相似性,并进一步基于这种接近性做出决策、进行推断,或者在我们的场景中检索信息。随着深度学习中 embeddings 的出现,对有效相似性搜索的需求也不断增长。由于 embeddings 捕捉了它们所表示数据的语义含义,对这些向量执行相似性搜索,可以让机器以接近人类认知的层面理解内容。
让我们探索 LlamaIndex 当前用于衡量向量相似度的方法,每种方法都有自己独特的优势和适用性。
余弦相似度
这种方法衡量两个向量之间夹角的余弦值。想象两支箭头指向不同方向;它们之间的角度越小,它们就越相似。
请看图 5.4,它描绘了两个向量之间的余弦相似度比较:
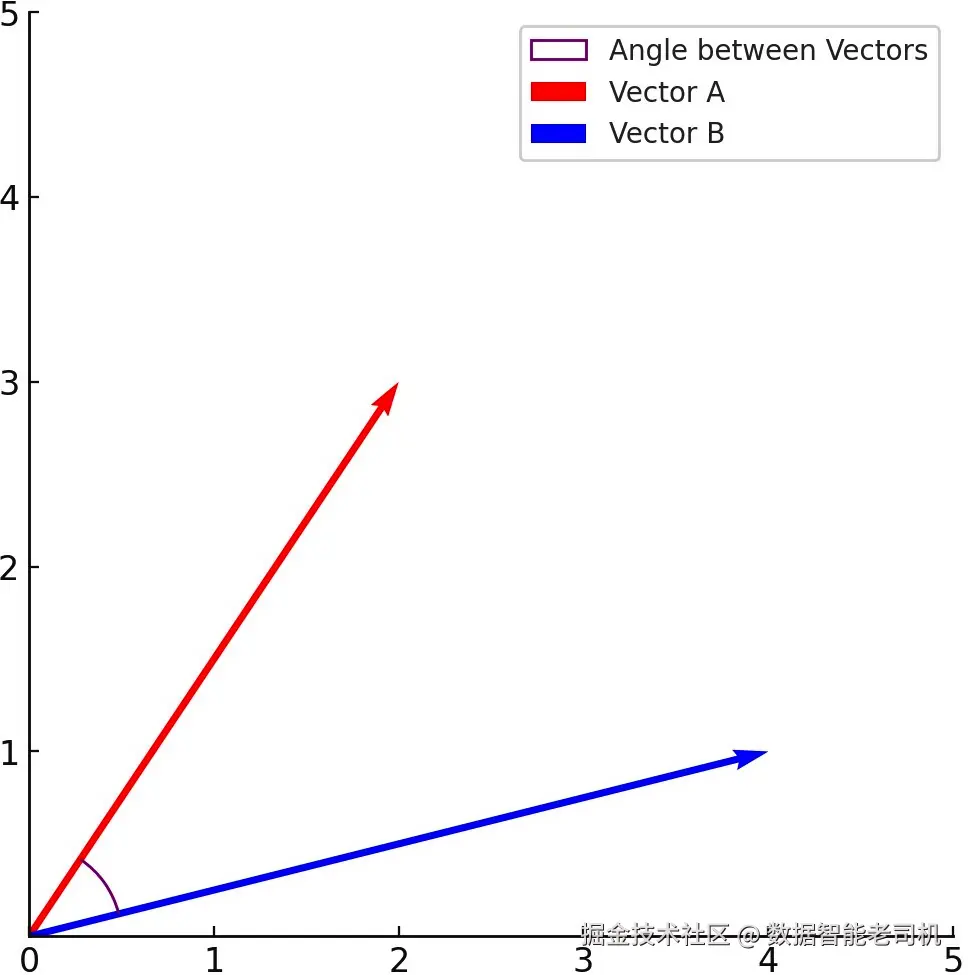
图 5.4 ------ 余弦相似度比较的样子
就 embeddings 而言,一个小角度,或者说一个较高的余弦相似度分数,接近 1,表示它们所代表的内容相似。这个方法在文本分析中特别有用,因为它受文档长度影响较小,更关注它们在向量空间中的方向或朝向。
余弦相似度也是 LlamaIndex 在其内存 vector store 中计算 embeddings 之间相似度时使用的默认方法。对于 Pinecone 或 Weaviate 等其他 vector store,相似度指标可能默认是点积或欧氏距离,具体取决于后端配置。
点积
点积是另一种计算两个向量对齐程度的方法。它也被称为标量积,因为它由单个值表示。为了计算两个向量的标量积,算法会将向量中对应元素相乘,然后将这些乘积求和。
让我们看一个简单例子,向量 A 为 [2,3],向量 B 为 [4,1]。点积的计算方式是将对应元素相乘,也就是 (2×4) + (3×1),结果为 8 + 3 = 11。因此,这两个向量的点积为 11。
图 5.5 举例说明了这个概念:
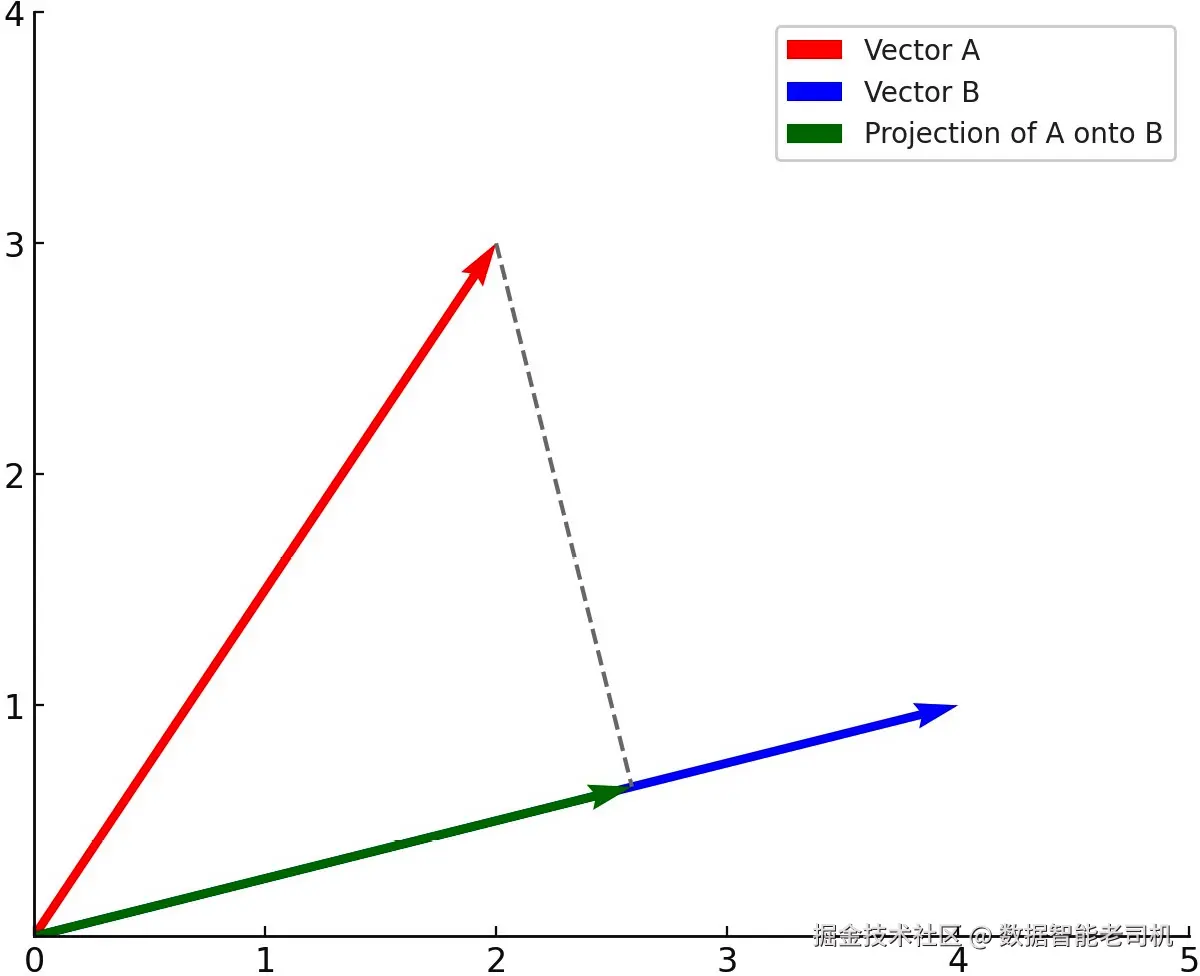
图 5.5 ------ 使用点积方法计算相似度
在前面的图中,点积通过将一个向量投影到另一个向量上来可视化。这种投影展示了点积的几何解释。它通过将一个向量的组成部分投影到另一个向量的方向上,然后将这些投影组成部分与第二个向量的对应组成部分相乘来计算。这些乘积的和就是点积。这种可视化帮助我们理解,点积不仅仅衡量向量是否指向同一方向,也会纳入它们的长度。
点积值越高,意味着向量之间的相似度越高。与余弦方法相比,点积同时对被比较的两个向量的长度和相对方向敏感。不同于点积,余弦相似度会用向量的模长对点积进行归一化。这种归一化使余弦相似度仅仅衡量向量之间的方向对齐程度,而不受它们长度影响。
向量越长,结果就越高,而这在 RAG 场景中是需要考虑的重要事项。较长向量可能代表较长文档或更详细的信息,由于它们天然拥有更大的点积值,可能会主导检索结果。这可能使系统偏向检索较长文档,即使它们并不是最相关的。
欧氏距离
这种方法不同于点积和余弦相似度。后两者关注向量之间的角度或对齐程度,而欧氏距离关注的是向量实际值之间有多接近。你可以把它想象成两点之间的直线距离。当向量中的值表示实际计数或测量值时,尤其是向量维度具有真实世界物理解释时,这种方法可能特别有用。
对于两个向量 A 和 B,欧氏距离计算方式如下:
scss
distance(A, B) = sqrt(Σ(A_i - B_i)^2)图 5.6 完美说明了这一点:向量 A 和 B 向两个不同方向延伸,而欧氏距离就是连接它们端点的紫色线段长度。它是空间中两点之间可能的最短路径:
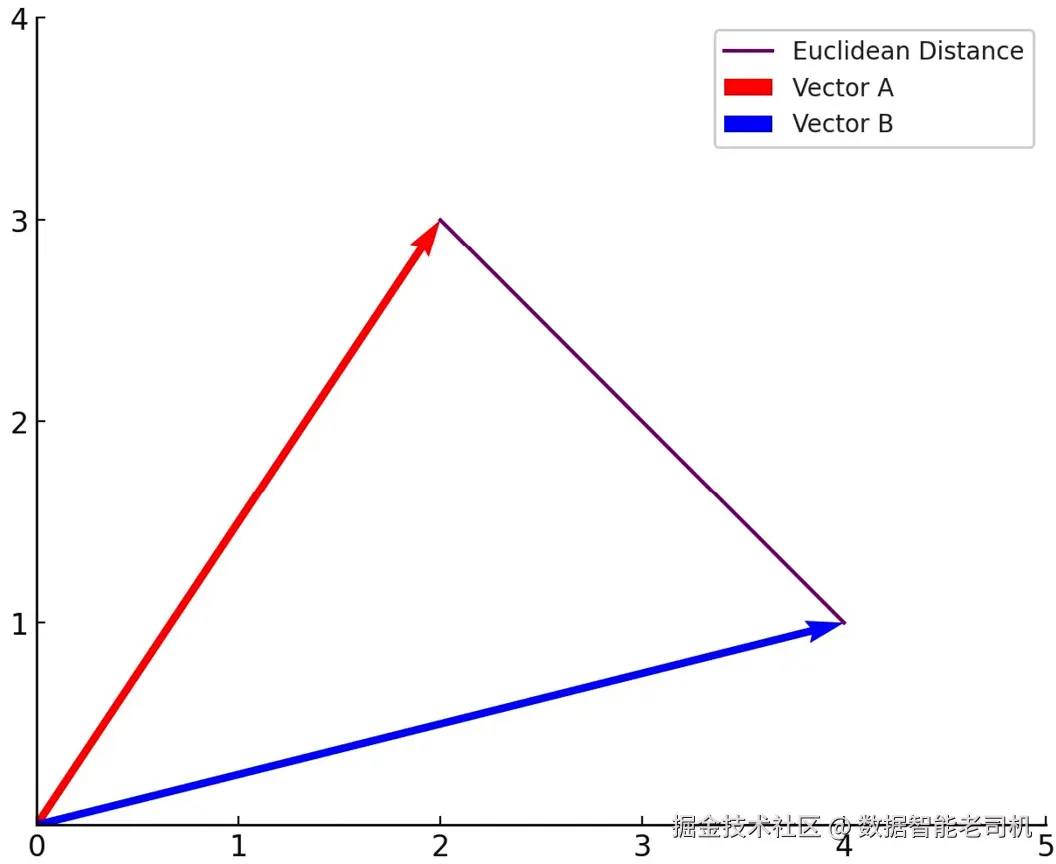
图 5.6 ------ 两个向量之间的欧氏距离
在我们的例子中,向量 A 是 [2,3],向量 B 是 [4,1]。它们之间的欧氏距离为:
scss
sqrt((2 - 4)^2 + (3 - 1)^2) = sqrt(4 + 4) = sqrt(8)现在,你应该已经对 embeddings 以及向量相似性如何工作有了基础理解。如果你想进一步熟悉这个概念,可以在网上找到更多信息。
这里有一个建议的额外阅读资源,你可以从这里开始:
developers.google.com/machine-lea...
理解 embeddings 如何集成到 LlamaIndex 中
正如我们已经在第 3 章《开启你的 LlamaIndex 之旅》中讨论过的,你可以通过设置 Settings.embed_model 属性,将默认 embedding 模型改成你偏好的模型标识符。它可以是通过 Ollama 运行的本地模型、Hugging Face 模型,或来自 Cohere、Azure 等外部提供商的模型。
在本章中,我不会重点讲如何配置 embedding 模型,因为你已经做过这件事了,而是会解释 embeddings 在你的 RAG 应用中扮演的角色,以及模型选择如何影响检索质量、成本、速度和隐私。
默认情况下,LlamaIndex 使用 OpenAI 的 text-embedding-ada-002 模型。这个模型在语义精度、成本和性能之间取得了很强的平衡。它既用于索引构建期间对文档进行 embedding,也用于检索期间将查询转换为向量。但根据你的目标和约束,这个默认模型并不总是最合适的。有时,当你想索引大量数据时,使用这种托管模型带来的成本可能会超出预算。还有些时候,你可能担心专有数据隐私,更倾向于使用本地模型。或者,在某些情况下,你可能想针对某个特定主题或技术领域使用更专业的模型。运行本地 embeddings 的一个很棒选择是 Hugging Face。
正如你可能还记得的,在第 3 章中,我演示了如何使用 llama-index-embeddings-huggingface 集成来加载 nomic-embed-text 这类模型。我们也通过 Ollama 使用它,在本地运行本书中的所有示例。
在运行下一个示例之前,请确保安装所需集成:
perl
pip install llama-index-embeddings-huggingface下面是一个快速复习,展示如何在 LlamaIndex 中使用自定义 embedding 模型,而不是依赖全局配置的默认模型:
ini
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embedding_model = HuggingFaceEmbedding(
model_name="WhereIsAI/UAE-Large-V1"
)
embeddings = embedding_model.get_text_embedding(
"The quick brown fox jumps over the lazy cat!"
)
print(embeddings[:15])第一次运行这段代码时,Universal AnglE Embedding 模型会自动从 Hugging Face 下载。它被广泛认为是当前表现最好的 embedding 模型之一,整体性能和质量平衡都很好。代码输出会是一组浮点数列表,也就是捕捉输入语义含义的向量 embedding。
关于这个模型的更多信息可以在这里找到:
对于高级用户或特定应用,LlamaIndex 让集成自定义 embedding 模型变得很容易。你只需扩展 LlamaIndex 提供的 BaseEmbedding 类,并实现自己的 embedding 生成逻辑。
这里可以找到如何定义自定义 embedding 类的示例:
docs.llamaindex.ai/en/stable/e...
除了 OpenAI 和本地模型之外,LlamaIndex 还提供与 LangChain 的集成,使你可以使用 LangChain 提供的任何 embedding 模型。你也可以通过 LlamaIndex 提供的额外集成,使用来自 Azure、CohereAI 和其他提供商的 embedding 模型。这种灵活性确保了无论你的需求或约束是什么,都可以配置 LlamaIndex 使用适合应用的 embedding 模型。这也引出了下一个问题。
我如何决定使用哪个 embedding 模型?
embedding 模型的选择会显著影响 RAG 应用的性能、质量和成本。选择特定模型时,可以考虑以下关键点:
定性性能:不同 embedding 模型可能会以不同方式编码文本语义。像 OpenAI Ada 这样的模型,其 embeddings 被设计为对文本有广泛理解;而其他模型可能针对特定领域或任务进行了微调,并在这些场景中表现更好。领域专用模型可能会对专业主题给出更准确的表示。
定量性能:这包括模型捕捉语义相似度的能力、在 benchmark 上的表现,以及对未见数据的泛化能力。不同模型和应用领域之间,这些表现可能差异很大。如果你想了解最流行模型的一般 benchmark,可以查阅 Hugging Face 网站上的 Massive Text Embedding Benchmark(MTEB)Leaderboard:
延迟和吞吐量:对于有实时约束或大量数据的应用,embedding 模型的速度可能是决定性因素。此外,我们还需要考虑模型能够处理的最大输入 chunk size,这会影响文本如何被拆分以进行 embedding。请记住,你的节点会在摄取期间计算 embeddings,因此这不会影响整体应用性能。不过,在检索期间,每个查询都必须实时嵌入,以便测量相似度并检索相关节点。这就是延迟和吞吐量变得重要的地方。想了解不同 embedding 模型可能的表现,可以看看这篇文章:
blog.getzep.com/text-embedd...
多语言支持:embedding 模型可以是多语言模型,也可以针对特定语言训练。根据你的使用场景,这也可能成为重要决策因素。例如,像 Mistral 这样较小的模型,可能在英文数据上提供与 GPT-4o 这类托管模型相当的优秀结果,但它们在其他语言上的表现明显较弱。
资源需求:embedding 模型在大小和计算成本方面可能差异很大。大型模型可能提供更准确的 embeddings,但可能需要更多计算资源,从而导致更高成本。
可用性:某些 embedding 模型可能只能通过特定 API 使用,或要求安装特定软件,这会影响集成和使用的便利性。幸运的是,LlamaIndex 提供了很高的定制程度。
设备端或本地使用:当数据隐私是一个关注点,或者运行环境互联网访问有限甚至没有互联网访问时,你可能更倾向于使用本地模型。
使用成本:需要考虑基于云的托管 embedding 模型 API 调用成本,与本地 embedding 模型的计算和存储成本之间的差异。
好消息是,LlamaIndex 开箱即用支持许多 embedding 模型,并提供使用各种 embeddings 的灵活性。
顺便说一句,支持模型的完整列表可以在这里找到:
docs.llamaindex.ai/en/stable/m...
不过,对于大多数使用场景来说,OpenAI 的默认 embedding 模型 text-embedding-ada-002 会在我们讨论过的所有参数之间提供不错的平衡。然而,如果你有特定需求或约束,探索并 benchmark 不同模型,看看哪个最适合你的特定应用,可能会很有帮助。
现在我们了解了 embeddings,让我们把注意力转向如何存储和复用它们。
持久化和复用索引
一个重要问题是:索引过程中生成的向量 embeddings 到底可以存放在哪里?
存储它们很重要,原因有很多:
避免每个会话中重新 embedding 文档和重建索引带来的计算成本:为大型文档集合生成高质量 embeddings 需要大量处理,长期来看可能变得成本高昂。持久化索引可以保留这些预计算产物。
支持低延迟处理:通过加载已经计算好的 embeddings,避免运行时 embedding 和 indexing,可以让应用启动和运行得更快。
保持查询一致性和准确性:重新加载索引可以确保我们复用与前一次会话相同的向量和结构。这有助于保证查询执行的一致性和准确性。
如果我们想避免每次运行都重新生成这些向量 embeddings,那么它们就需要被放在某个地方------你可以把它看作一个仓库------从而支持高效存储和检索。
这就是 LlamaIndex 中 vector store 的工作。
vector store 是一种专门的存储层,用于保存从文档中生成的高维向量表示,也就是 embeddings。你可以把它想象成一个可搜索数据库,只不过它存储的不是纯文本或表格,而是数值向量。
默认情况下,LlamaIndex 使用内存 vector store,但为了支持持久化,它提供了一种通过 .persist() 方法实现的直接方式。这个方法会将所有 StorageContext 数据写入磁盘上的指定位置,从而确保持久化。
虽然我们已经在第 4 章《将数据摄取到我们的 RAG 工作流中》中快速看过如何持久化索引,但这一次我们会更仔细地看看如何以更结构化的方式实现这种持久化。让我们看看如何持久化并加载一些向量 embeddings。
首先,我们创建索引,它会负责对文档进行 embedding:
ini
import models_config
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)正如你所看到的,我们使用 SimpleDirectoryReader 从仓库 ch5/data 文件夹中应该可用的示例文件生成文档对象列表。然后,我们从这些文档创建索引。接下来,为了持久化这个索引,我们使用 persist() 方法:
bash
index.storage_context.persist(persist_dir="index_cache")
print("Index persisted to disk.")这会将索引数据保存到磁盘。
持久化一个索引实际保存了什么?
当你调用 storage_context.persist() 时,你保存的不是索引对象本身。相反,LlamaIndex 会保存之后重建索引所需的所有组件,包括文档、节点、索引结构、向量 embeddings,以及任何可选图边。当你重新加载索引时,它会使用 load_index_from_storage() 从这些组件中重建。这个方法确保了灵活性和模块化,同时让序列化后的数据保持可移植,并且不依赖特定后端。
现在,在未来会话中,我们可以轻松重新加载数据:
ini
from llama_index.core import StorageContext, load_index_from_storage
storage_context = StorageContext.from_defaults(
persist_dir="index_cache"
)
index = load_index_from_storage(storage_context)
print("Index loaded successfully!")通过从持久化目录重建 storage context,并使用 load_index_from_storage,我们可以有效重构索引,而不需要重新索引数据。
理解 StorageContext
StorageContext 充当索引和查询过程中使用的可配置存储组件的统一管理者。它的关键组件如下:
document store(docstore) :管理文档存储。数据会本地存储在名为 docstore.json 的文件中。
index store(index_store) :管理索引结构的存储。索引会本地存储在名为 index_store.json 的文件中。
vector stores(vector_stores) :这是一个字典,用来管理多个 vector store,每个 vector store 与不同 namespace 关联。向量 embeddings 会保存到磁盘上的带 namespace 的文件中,例如 default__vector_store.json 或 image__vector_store.json,具体取决于被索引的数据类型。如果你使用 Pinecone 或 Weaviate 这样的远程后端,向量数据会被存储在外部,不会写入本地 vector store 文件。
graph store(graph_store) :管理基于图的数据结构存储。LlamaIndex 会自动创建名为 graph_store.json 的文件,用于存储图。
StorageContext 类将 document、vector、index 和 graph 数据存储封装在同一把伞下。前面列表中提到的本地存储数据文件,会在我们调用 persist() 方法时由 LlamaIndex 自动创建。如果我们不希望它们保存在当前文件夹中,可以提供一个特定持久化位置,以便未来会话从那里加载。
开箱即用时,LlamaIndex 提供基础本地存储,但我们也可以将它们替换为更强大的持久化解决方案,例如 AWS S3、Pinecone、MongoDB 等。
作为示例,让我们探索如何使用 ChromaDB 定制向量存储。ChromaDB 是一个高效的开源向量引擎。
首先,请确保使用 pip 安装 chromadb 和 LlamaIndex ChromaDB 集成:
arduino
pip install chromadb
pip install llama-index-vector-stores-chroma然后,我们添加必要导入:
javascript
import models_config
import chromadb
from llama_index.vector_stores.chroma import ChromaVectorStore
from llama_index.core import (
VectorStoreIndex, SimpleDirectoryReader, StorageContext
)接下来,我们初始化 Chroma client,并在 Chroma 中创建一个 collection 来存储数据:
ini
db = chromadb.PersistentClient(path="chroma_database")
chroma_collection = db.get_or_create_collection(
"my_chroma_store"
)在 ChromaDB 中,我们创建 collections 来存储数据。它们类似于关系型数据库中的表。my_chroma_store collection 会保存我们的 embeddings。
接下来,我们使用 ChromaVectorStore 初始化一个定制 vector store,并将其接入 StorageContext:
ini
vector_store = ChromaVectorStore(
chroma_collection=chroma_collection
)
storage_context = StorageContext.from_defaults(
vector_store=vector_store
)现在,我们已经准备好摄取文档并构建索引:
ini
documents = SimpleDirectoryReader("files").load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
storage_context=storage_context
)现在可以使用 get() 方法显示 Chroma collection 的完整内容:
scss
results = chroma_collection.get()
print(results)随后,在未来会话中恢复这个索引也非常简单:
ini
index = VectorStoreIndex.from_vector_store(
vector_store=vector_store,
storage_context=storage_context
)我们刚刚重新初始化了原始索引。
通过包装 ChromaDB 这样的向量数据库,LlamaIndex 让企业级向量存储可以通过简单的存储抽象访问。复杂性被隐藏起来,使你能够专注于应用逻辑,同时仍然利用工业级数据基础设施。
总结一下,LlamaIndex 在向量存储方面提供了灵活性------从用于测试的简单内存存储,到用于大型真实部署的云托管数据库。通过存储集成,替换任何组件都轻而易举!
vector store 和 vector database 之间的区别
vector store 和 vector database 这两个术语,经常出现在管理和查询大量向量的上下文中。这些向量常用于机器学习,尤其是在涉及 NLP、图像识别和类似任务的应用中。随着我们进一步深入索引,你会频繁遇到 vector store 和 vector database 这两个术语,有时它们还会被交替使用。不过,二者之间存在细微区别:
Vector store:这通常指一个用于存储向量的存储系统或仓库。这些向量是高维的,代表文本、图像或音频等复杂数据,并采用可以被机器学习模型处理的格式。vector store 主要关注这些向量的高效存储。它可能不具备高级的数据查询或分析能力,其主要目的,是维护一个大型向量仓库,以便它们可以被检索并用于各种机器学习任务。
Vector database:vector database 则是一个更复杂的系统,它不仅存储向量,还提供用于查询和分析这些向量的高级功能。这包括执行相似性搜索以及其他对机器学习和数据分析有用的复杂操作。vector database 被设计用于处理向量数据的细微特点,例如高维度,以及需要专门索引技术来支持高效搜索和检索。简而言之,vector store 更偏向存储层面,而 vector database 同时涵盖存储和向量数据所需的复杂查询能力。这使 vector database 在需要快速且准确搜索大量向量化数据的应用中特别重要。
vector database 通常具备,而 vector store 较少提供的一个区别性特征,是对 CRUD,也就是 create、read、update、delete 功能的支持。一个 vector store 是否提供 CRUD 功能,取决于具体实现和设计。不过,一般来说,vector store,尤其是简化或基础形式的向量数据存储,可能不会像传统数据库系统那样支持所有 CRUD 操作。让我们拆解一下典型操作:
Create:向 store 中添加新向量的能力通常是基础功能。这对于构建向量仓库至关重要。
Read:基于某种标识符或条件读取或检索向量,也是常见功能。在基础 vector store 中,这可能仅限于简单检索,而不是复杂查询。
Update:在 vector store 中更新现有向量,可能不像传统数据库中那样直接或普遍支持。这是因为向量数据通常用于机器学习和类似应用,往往以固定形式生成,并且不常被更新。
Delete:删除向量的能力可能受到支持,但和更新一样,它未必是主要功能;delete 操作是否可用取决于 vector store 的使用场景。
在许多机器学习和 AI 应用中,向量一旦创建和存储,就不常被更新或删除。因此,一些 vector store 更关注高效存储和检索,也就是 create 和 read 操作,而不是完整 CRUD 功能。
相比简单 vector store,更复杂的 vector database 更可能提供完整 CRUD 能力,从而支持更动态、更灵活地管理向量数据。此外,vector database 通常会使用近似最近邻搜索(ANN)等专门算法进行高效相似性匹配,支持元数据过滤以基于向量相似度之外的属性缩小结果范围,并且通常采用分布式架构,以便扩展到大型数据集。
这里有一个不错的起点,可以帮助你更好地理解 vector database:
www.pinecone.io/learn/vecto...
现在你已经看到,为什么 VectorStoreIndex 往往是默认选择:它灵活、强大,并且开箱即用适配大多数 RAG 工作流。但它并不是唯一选择。LlamaIndex 给了我们一整套不同索引类型的工具箱,每一种都被设计用于略有不同的任务。接下来我们看看这些索引。
探索 LlamaIndex 中的其他索引类型
虽然 VectorStoreIndex 可能是大多数 RAG 场景中的明星,但 LlamaIndex 还提供了许多其他有用的索引类型。它们都有具体特性和使用场景,下面这一节将更详细地探索它们。
SummaryIndex
Summary index 提供了一种直接但强大的数据索引方式,用于检索目的。不同于关注 vector store 中 embeddings 的 VectorStoreIndex,SummaryIndex 基于一种简单数据结构,其中节点按顺序存储。你可以在图 5.7 中看到 SummaryIndex 结构的简单描绘:
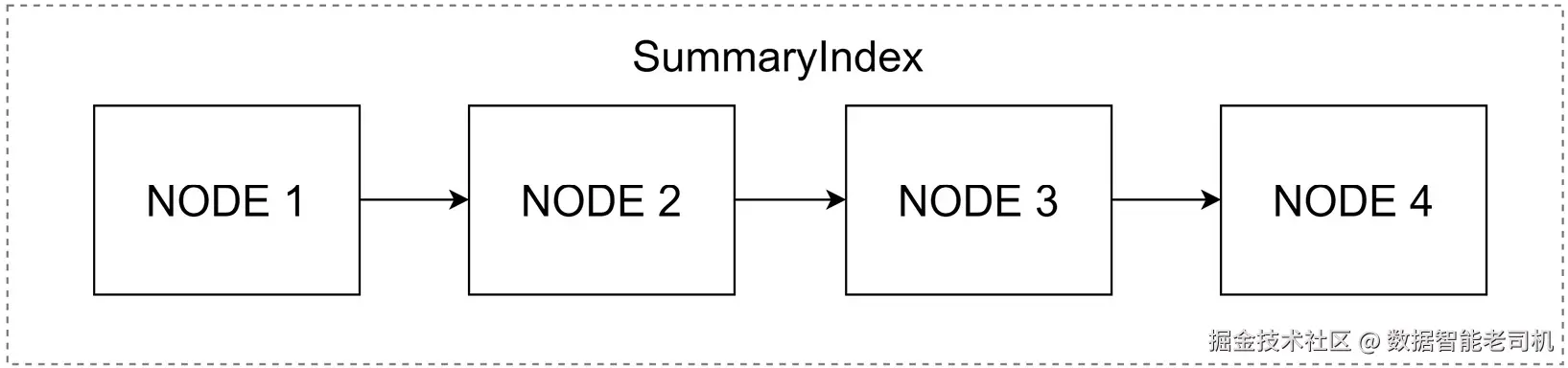
图 5.7 ------ SummaryIndex 的结构
构建索引时,它会摄取一组文档,将它们拆成更小 chunk,然后将这些 chunk 编译成一个顺序列表。索引构建期间,一切都在本地运行,不使用任何 LLM 或 embedding 模型。
接下来,我们将探索这个索引实际如何工作、如何创建它,以及它有哪些实际使用场景。
理解 SummaryIndex 的内部工作机制
在内部,SummaryIndex 通过类似列表的结构存储每个节点。当使用默认 retriever 执行查询时,索引会将所有节点传给 response synthesizer,后者会按顺序处理它们,以构建完整答案。虽然这个过程不如 VectorStoreIndex 中基于 embedding 的搜索复杂,但它对许多应用仍然有效。
这个索引可以与多种 retriever 一起使用,例如 SummaryIndexRetriever、SummaryIndexEmbeddingRetriever 和 SummaryIndexLLMRetriever,它们分别提供不同的数据搜索和检索机制。在查询过程中,SummaryIndex 使用 create and refine 方法来形成响应。最初,它会基于第一段文本 chunk 组装一个初步答案。随后,这个初始响应会通过纳入额外文本 chunk 作为上下文信息而被逐步 refine。refinement 过程可能会保持初始答案不变、轻微修改它,或者完全重写原始响应。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中详细介绍检索部分。
构建 summary index
创建 SummaryIndex 是一个直接的过程:
ini
import models_config
from llama_index.core import SummaryIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("files").load_data()
index = SummaryIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("How many documents have you loaded?")
print(response)这里,节点会从我们的示例文件中创建出来,并用这些节点实例化 SummaryIndex。这个简单模型支持快速设置,不需要 embedding 或使用 vector storage 的复杂性。
如果你已经正确克隆本书 GitHub 仓库结构,并且有一个包含两个文本文件的 files 子文件夹,前面代码片段的输出应该如下:
css
I have loaded two documents.实际使用场景
软件项目通常会随着时间积累大量文档。当团队负责人需要一个广泛概览,例如 "What are the key architectural decisions documented in this project?",或者要求 "Summarize the main changes introduced in the last three sprints" 时,SummaryIndex 就很有价值。因为它会按顺序处理所有节点,所以可以从整个文档集合中综合出一个整体答案。这让它非常适合摘要式问题,因为答案不是位于某个特定段落,而是分散在整个语料中。对于需要查找特定细节的定向搜索,VectorStoreIndex 会是更好的选择。
当你需要从所有数据中综合出全面答案,同时不希望承担设置 embeddings 或 vector store 的开销时,SummaryIndex 特别有效。它配置更简单,但请记住,在查询时处理所有节点,意味着当文档集合很大时,LLM 成本会更高。
DocumentSummaryIndex
LlamaIndex 的索引工具库并不止于广受好评的 VectorStoreIndex,它还包含多种面向不同应用的专门索引。在这些索引中,DocumentSummaryIndex 因其独特的文档管理和检索方式而非常突出。
从核心来看,DocumentSummaryIndex 旨在通过总结文档,并将这些摘要映射到索引中对应节点,来优化信息检索。这个过程使用摘要快速识别相关文档,从而支持高效数据检索。
图 5.8 展示了这个机制的视觉表示:
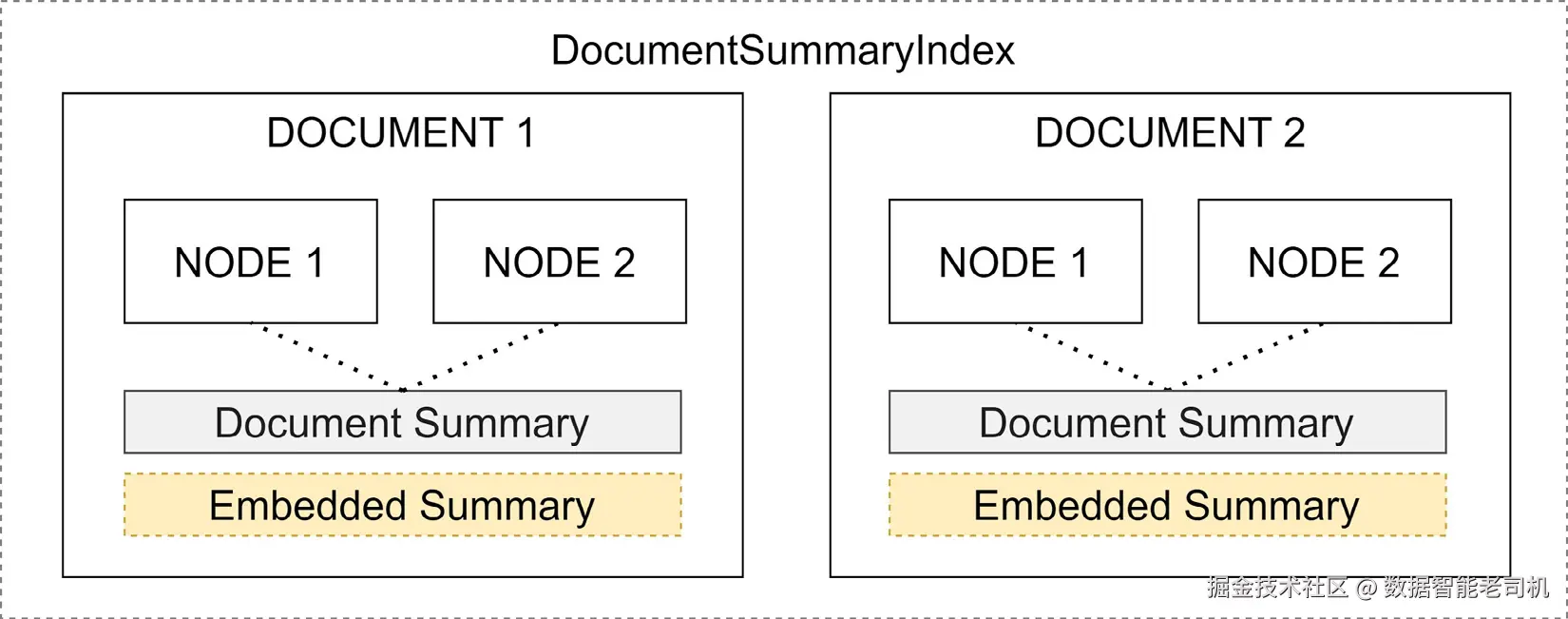
图 5.8 ------ DocumentSummaryIndex
让我们探索这个索引实际如何工作、如何创建它,以及它有哪些实际使用场景。
理解 DocumentSummaryIndex 的内部工作机制
这个索引首先会为每个摄取文档创建一个摘要。然后,这些摘要会链接到文档的节点上,形成一个结构化索引,支持快速且准确的数据检索。
在内部,DocumentSummaryIndex 同时支持基于 embedding 的 retriever 和基于 LLM 的 retriever,从而提供适应不同需求的灵活检索机制。默认情况下,该索引还会为每个摘要生成 embeddings,以支持基于 embedding 的检索,这对于相似性搜索特别有用。
构建 document summary index
创建 DocumentSummaryIndex 涉及一系列步骤,从聚合文档开始,然后进行摘要。下面的代码片段展示了创建这个索引的基础设置:
ini
import models_config
from llama_index.core import (
DocumentSummaryIndex, SimpleDirectoryReader
)
documents = SimpleDirectoryReader("files").load_data()
index = DocumentSummaryIndex.from_documents(
documents,
show_progress=True
)这个过程包括从目录中读取文档、将它们解析成节点、总结文档,然后将对应节点与这些摘要关联起来,以便快速检索。接下来,让我们观察这个过程中生成的摘要:
scss
summary1 = index.get_document_summary(documents[0].doc_id)
summary2 = index.get_document_summary(documents[1].doc_id)
print("\n Summary of the first document: " + summary1)
print("\n Summary of the second document: " + summary2)这部分代码示例会显示为每个文档生成的摘要。这些摘要会与每个文档底层节点关联。在检索过程中,这种关联将允许系统基于用户查询和每个文档摘要,只提取相关节点。
这个特定索引有几个可以定制的参数:
response_synthesizer :这个参数允许你指定索引构建期间用于生成文档摘要的 response synthesizer。默认情况下,它使用 tree_summarize 方法,但你可以定制它,以控制 LLM 如何将每个文档压缩成摘要。
summary_query :这个参数用于定义指导摘要过程的查询。本质上,它告诉 response synthesizer 为每个文档生成什么类型的摘要。默认查询要求摘要描述文档讲什么,以及它可以回答哪些问题。调整这个查询,可以定制摘要的重点和风格,使其更契合索引的具体使用场景。例如,你可以将 summary_query 设置成类似:Summarize this document by highlighting the sections that describe error handling, exceptions, and recovery strategies。在这种情况下,这些摘要会在 RAG 流水线中充当过滤器:只有涉及错误处理的文档,才会在该领域相关查询中浮现出来,从而减少那些包含无关但语义相似 chunk 的文档噪音。
show_progress :这个布尔参数决定是否在耗时较长的操作中显示进度条。设置为 True 可以为这些操作提供可视化进度反馈。
embed_summaries :当设置为 True 时,也就是默认值,这个参数表示应该对摘要进行 embedding。嵌入后的摘要随后可以用于基于 embedding 的搜索中的相似性比较和检索。当你希望基于文档摘要内容和用户查询之间的相似度来检索节点时,这特别有用。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中更详细介绍。
让我们探索这个索引的一些实际用途。
实际使用场景
DocumentSummaryIndex 特别适合处理这样一类查询:对文档内容的简洁概览可以显著缩小搜索空间。因此,它非常适合那些需要在大型且多样化数据集中快速访问特定文档的应用。
例如,DocumentSummaryIndex 的一个实际使用场景,是在大型组织内部开发知识管理系统。在这样的环境中,员工常常需要快速访问大量文档,包括报告、研究论文、政策文档和技术手册。这些文档通常存储在不同部门中,并且篇幅可能很长,因此很难快速找到与用户查询相关的特定信息。此外,多篇文档可能包含相似的文本 chunk,使得在整个数据集上进行简单的基于 embedding 的检索变得不实际。这是因为 embeddings 工作在节点层面,所以如果许多文档共享几乎相同的节点,例如重复的样板文本、免责声明或常见定义,检索系统可能会不断返回这些节点,而不是引导你找到真正包含独特且相关信息的文档。
KeywordTableIndex
LlamaIndex 中的 keyword table index 实现了一种聪明的架构,类似术语表,可以基于重要术语快速将查询匹配到相关节点。不同于复杂 embedding 空间,这种结构依赖直接的关键词表,但对于定向事实查找非常有效。这个索引从文档中提取关键词,并构建关键词到节点的映射,提供一种高效搜索机制。
在精确关键词匹配对于检索相关信息至关重要的场景中,它特别有用。这些关键词会成为中央查找表中的 reference keys,每一个都指向关联节点,就像术语表中的定义一样。在检索期间,就像扫描术语表中感兴趣的条目一样,包含特定关键词的相关节点会被识别并返回。请看图 5.9 的视觉表示:
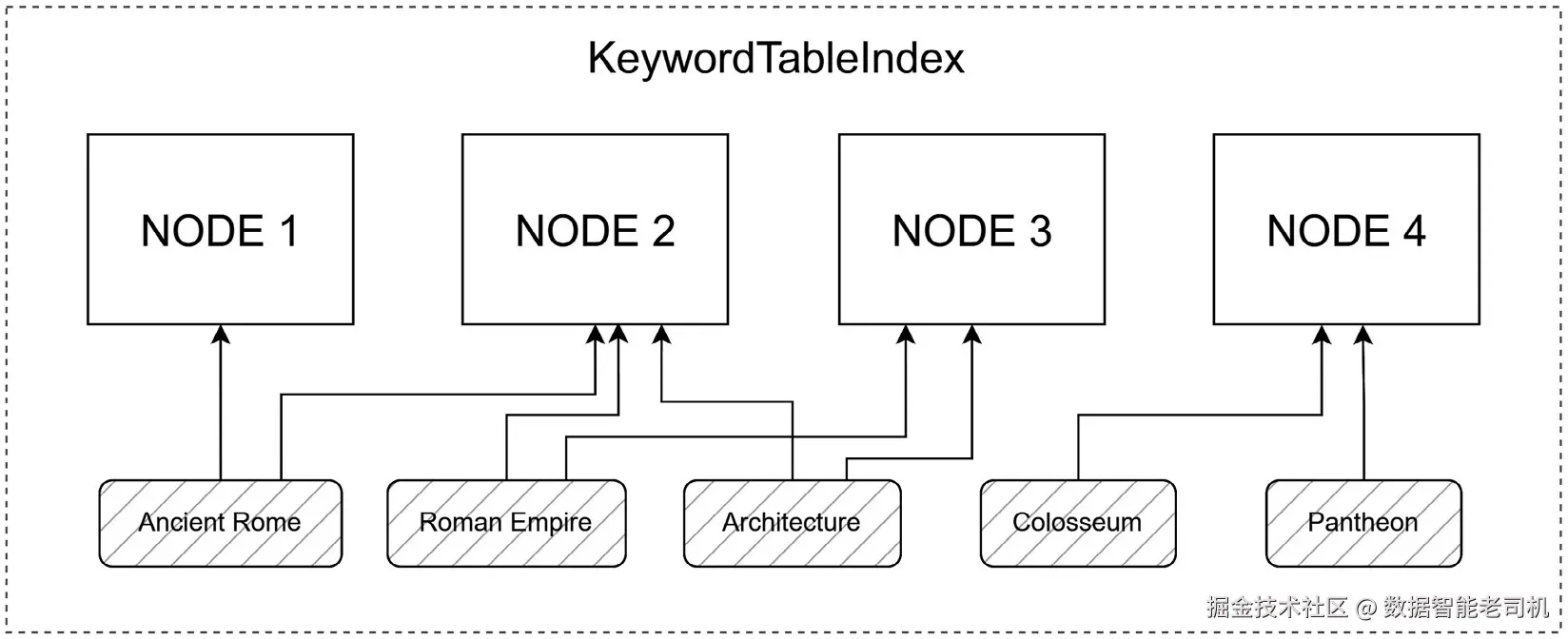
图 5.9 ------ KeywordTableIndex 的结构
让我们看看这个索引如何工作、如何创建,以及它可能有哪些实际使用场景。
理解 KeywordTableIndex 的内部工作机制
KeywordTableIndex 构建并操作一个关键词表,类似术语表,其中每个关键词都链接到相关节点。索引首先处理一组文档,将它们拆成更小 chunk。对于每个 chunk,索引使用 LLM 和专门设计的 prompt 来识别并提取相关关键词。这些关键词可能从简单术语到短语不等,随后会被编入关键词表中。表中的每个关键词都直接链接到它来源的那段文本 chunk。
当收到查询时,索引会识别其中的关键词,并将它们与表条目匹配,从而快速且准确地检索包含这些关键词的相关 chunk。它支持多种检索模式,包括简单关键词匹配,以及 Rapid Automatic Keyword Extraction(RAKE)等高级技术,或基于 LLM 的关键词提取和匹配。
RAKE 方法特别擅长识别文本主体中重要的短语或关键词。RAKE 背后的关键思想是,关键词通常由多个词组成,但很少包含标点符号、停用词,或词汇意义很弱的词。KeywordTableIndex 支持不同检索模式,这些模式控制如何从用户查询中提取关键词:默认模式使用 LLM,simple 模式使用 regex,rake 模式则使用基于 rake_nltk,也就是 Natural Language Toolkit 的 RAKE 关键词 extractor。这些模式在创建 retriever 时通过 retriever_mode 参数设置。注意,这与索引阶段的提取不同。你也可以选择不同的索引类,例如 RAKEKeywordTableIndex 或 SimpleKeywordTableIndex,以改变索引构建期间如何从文档中提取关键词。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中更多讨论这些检索模式。
接下来,我们将创建一个 keyword table index。
构建 keyword table index
创建 KeywordTableIndex 非常直接:
ini
import models_config
from llama_index.core import KeywordTableIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("files").load_data()
index = KeywordTableIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query(
"What famous buildings were in ancient Rome?"
)
print(response)这里,索引会自动从数据中提取关键词,并设置关键词表,从而简化建立基于关键词检索系统的过程。
和前一个示例一样,如果你已经正确克隆 GitHub 仓库结构,并且有一个包含两个文本文件的 files 子文件夹,前面代码片段的输出应该大致类似:
erlang
The Colosseum and the Pantheon were famous buildings in ancient Rome.KeywordTableIndex 可定制参数如下:
keyword_extract_template:这是一个可选 prompt 模板,用于关键词提取。可以指定自定义 prompts 来改变如何从文本中提取关键词,从而支持定制化关键词提取策略。我们将在第 13 章进一步讨论 prompt 定制。
max_keywords_per_chunk :设置应该从每个文本节点中提取的最大关键词数量。通过使用这个参数,我们可以确保关键词表保持可管理,并聚焦于最相关关键词。默认值是 10。
use_async :决定是否使用异步调用。尤其是在处理大型数据集或复杂操作时,这可以提升性能。默认设置为 False。
KeywordTableIndex 的适应性使它成为一个通用工具,适用于关键词精确性至关重要的各种应用。
实际使用场景
想象一个内部开发者支持门户,工程师经常搜索类似 E1234、AUTH_INVALID_SCOPE、--enable-sharded-ingest 或 X-Org-Token 这样的内容。这些都是高精度 token,例如错误代码、CLI flag、header 名、feature flag 等,你希望它们被精确匹配,而不是被语义匹配。KeywordTableIndex 在这里就很出色:摄取期间,它会提取这些 token 并构建 keyword-node map,因此像 "Why am I getting E1234 on webhook retries?" 这样的查询,会直接跳到提到 E1234 的 runbook 部分或 API 文档节点,而不是漂移到语义相似但无关的文本。这种设置在 RAG 流水线中快速、便宜且稳健,因为它保证当许多文档共享相似文本时噪声很低,只有包含精确关键词的节点会被检索出来;对于代码、flag、header 等编码标识符来说,精确性胜过语义。
TreeIndex
tree index 引入了一种层级化的信息组织与检索方法。不同于简单列表,这种结构以层级树格式组织数据。
请看图 5.10,其中描绘了 TreeIndex 的结构:
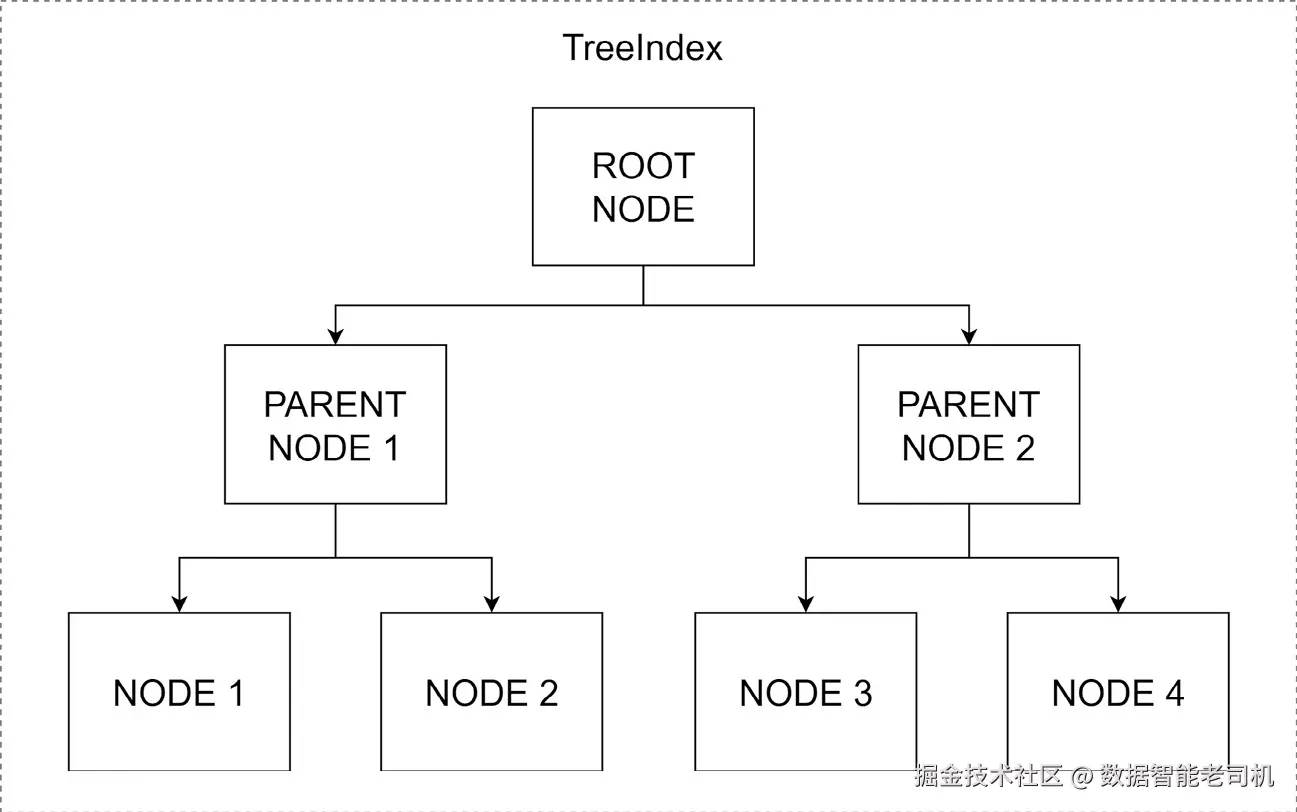
图 5.10 ------ TreeIndex 的结构
这棵树中的每个节点都可以表示一段数据或信息,类似真实树上的枝干或叶子。这种结构形式支持高效处理和查询数据。
理解 TreeIndex 的内部工作机制
TreeIndex 首先接收一组文档作为输入。然后,它以自底向上的方式构建一棵树;每个父节点都能够使用通用摘要 prompt 对子节点进行摘要,每个中间节点都包含对其下方组件的文本摘要。这个摘要使用 LLM 基于可通过 summary_prompt 参数定制的 prompt 模板生成。TreeIndex 就像一个组织者和摘要器,接收大量独立数据片段,将它们组合在一起,并创建一个捕捉它们核心内容的摘要。
索引构建过程是递归的。创建第一层父节点之后,构建器会重复这个过程,将这些父节点总结为更高层节点,如此继续。这会在树中创建多层,每一层都抽象并总结其下方一层的信息。此外,对于大型数据集,索引可以通过 use_async 异步处理数据。这意味着它可以同时处理数据的多个部分,使构建过程更快、更高效。
通过使用 LLM 生成摘要,TreeIndex 可以封装对数据的细腻理解。这对关系和上下文很重要的复杂数据集尤其有用。
这个索引支持几种检索模式:
TreeSelectLeafRetriever:遍历树以找到最能回答查询的叶节点。它涉及在每一层选择特定数量的子节点继续遍历。
TreeSelectLeafEmbeddingRetriever:利用查询与节点文本之间的 embedding 相似度来遍历树,并基于这种相似性选择叶节点。
TreeRootRetriever:直接从树的根节点检索答案。这个方法假设图中已经存储了答案,因此不会沿树向下解析信息。
TreeAllLeafRetriever:从所有叶节点构建一个特定查询相关的树来返回响应。它会为每个查询重建树,因此适用于不需要在初始化阶段构建树结构的场景。
查询期间,tree index retriever 的运行方式如下:
- 从根节点开始,retriever 将查询与子节点摘要一起展示给 LLM
- LLM 根据摘要选择最相关的子节点
- retriever 移动到被选择的子节点,并重复这个过程
- 这个过程持续进行,直到抵达叶节点
- 抵达的叶节点代表最可能与查询相关的上下文
我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中更详细介绍 retrievers。
接下来,让我们创建一个简单的 TreeIndex。
构建 tree index
要实现 TreeIndex,你可以参考下面这个简单示例:
ini
import models_config
from llama_index.core import TreeIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("files").load_data()
index = TreeIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Tell me about dogs")
print(response)这个过程包括 TreeIndex 接收文档,将其层级化组织,然后允许查询利用这种结构进行高效数据检索。
除了从 BaseIndex 类继承的一般定制能力之外,TreeIndex 还提供以下参数:
summary_template:这是索引构建期间用于摘要的 prompt。这个 prompt 可以被定制,以更好地控制摘要过程。
insert_prompt:这是索引用于树插入的 prompt,辅助索引构建。这个 prompt 促进节点插入树中。它指导新信息如何被整合到现有树结构中。我们将在第 13 章《提示工程指南与最佳实践》中介绍 prompt 定制的细节。
num_children :定义每个节点应该拥有的最大子节点数量。这个参数控制树的宽度,影响每个节点的详细程度。默认设置为 10。
build_tree :这是一个布尔参数,表示是否在索引构建期间构建树。如果我们不使用默认值,也就是 True,索引会在查询期间构建树,而不是在索引构建期间构建。将 build_tree 参数设置为 False,在某些场景中可能有用,例如你想手动控制树构建过程,或者在初始构建后修改树结构。
use_async:决定是否应使用异步操作模式。
实际使用场景
大型组织通常会管理数千页政策、流程和审计证据,覆盖安全、隐私和风险等领域。tree index 可以将这些内容层级化组织:顶部是政策,中间是流程,叶子节点是证据。当有人问 "What evidence is required for annual vendor penetration tests?" 时,查询会被引导到 Vendor Risk -> Testing 分支,而不是扫描每个节点。每一层的摘要都会剪除无关路径,使检索更快且更精确。
这种方法在合规或审计场景中特别强大,因为可解释性很重要:高层摘要展示推理路径,而叶节点提供精确支持细节。
使用 TreeIndex 的潜在缺点
在 RAG 工作流中使用 tree index,相比更简单的索引方法,可能潜在不那么有利。下面是几个原因:
增加计算量:构建和维护 tree index 需要额外计算资源。在索引构建阶段,需要通过递归摘要和组织节点来创建树结构。这个过程涉及使用 LLM 调用进行摘要,并构建层级结构,尤其是对于大型数据集,计算可能很密集。
递归检索:查询索引时,检索过程涉及从根节点向下遍历树结构,直到相关叶节点。这个递归遍历可能需要多个步骤和计算,尤其是当树很深,或者需要探索多个分支时。遍历中的每一步都可能涉及将查询与节点摘要比较,并决定跟随哪些分支。相比从扁平索引中检索,这个递归过程计算成本可能更高。
摘要开销:这个索引依赖对每个节点内容进行摘要,以提供对其子节点的简洁表示。摘要过程需要在索引构建期间执行,也可能需要在更新或插入期间执行,从而增加整体计算开销。
存储需求:存储 tree index 相比扁平索引需要更多存储。索引需要存储树结构、节点摘要,以及与每个节点关联的元数据。对于大规模数据集,这种额外存储开销可能会增加存储成本。
维护和更新 :维护 TreeIndex 需要在添加新数据或修改已有数据时定期更新和重新组织。在树结构中插入新节点或更新现有节点,可能产生级联影响,需要更新父节点及其摘要。与其他索引相比,这种维护过程可能更复杂、更耗时。
不过,需要注意的是,在某些场景中,使用 tree index 所带来的更高成本是可以被证明合理的。如果 RAG 应用处理的是大规模数据集,并且需要高效且上下文感知的检索,那么使用这种索引的收益可能超过额外成本。它的层级结构和摘要能力可以带来更好的检索性能、更小的搜索空间和更高质量的响应生成。通过从根节点开始遍历树,并选择性探索相关分支,模型可以快速将搜索范围缩小到最有希望的节点。这相比搜索扁平索引结构,可能带来更快的检索时间和更高效率。
关键在于评估 RAG 场景中的具体需求、规模和约束,以判断使用 tree index 的收益是否能证明潜在成本增加是合理的。仔细评估和 benchmarking 可以帮助你在检索效率、生成质量、计算成本和存储成本之间做出明智决策。
PropertyGraphIndex
property graph index 通过从提取出来的 triplets 构建知识图谱(KG),增强查询处理。它取代了现在已经废弃的 KnowledgeGraphIndex,并提供了一个更加模块化且可扩展的架构,用于构建和查询 KG。
property graph 是一种图,其中每个节点和边都可以保存 key-value 属性,从而支持实体之间更丰富的语义关系。
这种索引类型主要依赖 LLM 从文本中提取 triplets,也称为 paths,但也提供了在需要时使用自定义提取函数的灵活性。
当理解复杂的相互连接关系和上下文信息很重要时,KG index 很擅长这类场景。它们非常适合捕捉实体和概念之间的连接,从而为查询提供更好的洞察和上下文感知回答。在其他使用场景中,KG 很适合回答需要理解不同实体之间关系的多方面问题。例如,如果你问 "Which authors collaborated with researchers at MIT on climate change studies?",property graph 可以连接 authors -> institutions -> research topics,让系统追踪这些关系,而不是只匹配关键词。
让我们通过图 5.11 直观看看这些图如何工作:
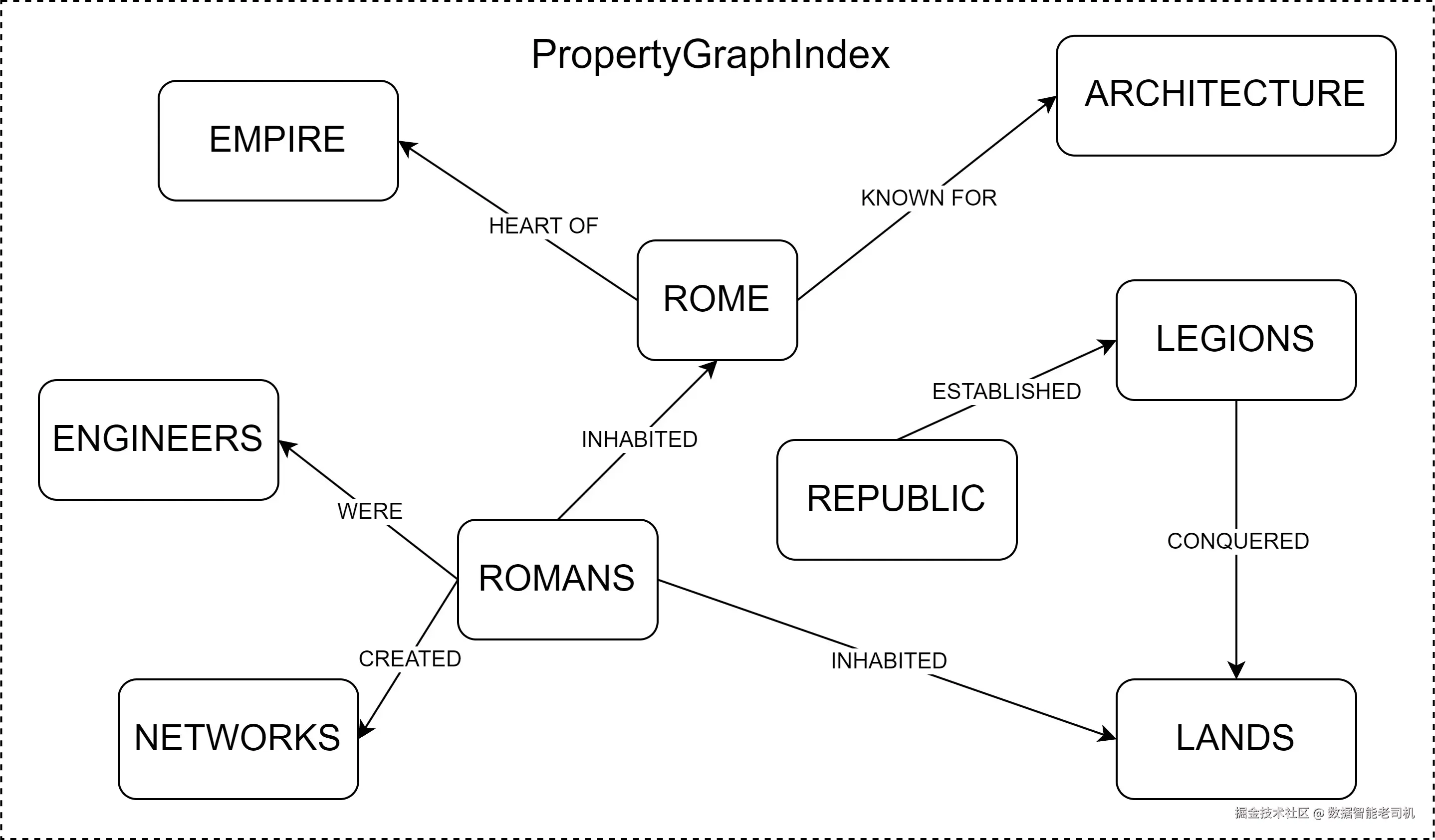
图 5.11 ------ PropertyGraphIndex 的结构
让我们看看这个索引如何工作、如何创建,以及它可能有哪些实际使用场景。
理解 PropertyGraphIndex 的内部工作机制
PropertyGraphIndex 通过从文本数据中提取 subject--predicate--object 关系,也就是 triplets,来形成 property graph。
注意,LlamaIndex 在其代码库中笼统地将这些 triplets 称为 paths,例如 SimpleLLMPathExtractor。不过在图论中,path 更常指跨多个连接关系的多跳遍历。
这个索引构建其结构主要有两种方式:
默认内置方法 :默认情况下,PropertyGraphIndex 使用一系列 path extractors,从每个节点文本中提取 subject--predicate--object 关系。这些 extractor 包括 SimpleLLMPathExtractor,它使用 LLM 和 prompt 来识别关系路径,以及 ImplicitPathExtractor,它不调用 LLM,而是捕捉简单的基于名词的关系。你可以通过指定 kg_extractors 参数传入自己的自定义 extractors。每个 extractor 都负责分析文本,并返回构成图基础的一组结构化 paths,也就是 triplets。
高级方法------自定义 extractors :如果想获得更多控制,可以通过继承 BasePathExtractor 或修改像 SimpleLLMPathExtractor 这样的内置 extractor 来定义自定义 path extractor。然后,你的自定义 extractor 可以通过 kg_extractors 列表传入,在索引过程中应用领域特定提取逻辑。
无论使用哪些 extractors,索引都会遍历每个节点,应用 extractors,并将生成的 paths 添加到图结构中。
由于索引可能使用 LLM 来提取关系路径,因此成本和延迟方面的考虑可能会根据数据集规模和你选择的 extractor 而出现。
如果 embed_kg_nodes 标志设置为 True,也就是默认值,索引还会使用配置好的 embedding 模型为每个实体节点生成 embeddings。这些 embeddings 支持在需要时进行基于相似度的检索。你仍然可以通过底层 graph store 的 add_node() 和 upsert_triplet() helpers 手动丰富图,或者通过调用 index.insert_nodes() 来实现。
在查询时,索引使用一种或多种检索策略。默认情况下,它使用 LLMSynonymRetriever,该 retriever 会使用 LLM 辅助的同义词扩展,将查询与图进行匹配。如果提供了 vector_store,也可以使用 VectorContextRetriever。
和 LlamaIndex 中其他索引一样,PropertyGraphIndex 支持通过 storage_context.persist() 进行持久化,使你可以跨会话保存和重新加载图。
对于更结构化的查询,索引支持 TextToCypherRetriever 和 CypherTemplateRetriever,它们会基于预定义规则将查询转换为图查询。关于这些检索能力的更多细节,将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中探索。
构建 property graph index
下面是构建和查询 property graph 的一种简单方式:
ini
import models_config
from llama_index.core import (
PropertyGraphIndex, SimpleDirectoryReader
)
documents = SimpleDirectoryReader("files").load_data()
index = PropertyGraphIndex.from_documents(
documents, use_async=False
)
query_engine = index.as_query_engine()
response = query_engine.query("Tell me about dogs.")
print(response)在这个设置中,索引会通过从文档中提取 triplets 来构建 KG,从而支持复杂关系查询。注意,我们通过将 use_async 设置为 False,配置索引以同步模式运行构建过程。当然,考虑到我们作为示例使用的两个示例文档,也就是 files 子文件夹中的文档,规模很小,这不会对总执行时间产生太大影响。不过,当处理大型数据集时,为这个索引启用异步操作可能会带来重要性能提升。
实际使用场景
PropertyGraphIndex 的一个有趣使用场景,可以是新闻聚合应用。在这个应用中,每天会从报纸、博客和社交媒体平台等各种来源摄取大量文本。在这种场景中,KG 可以用于表示人物、组织、地点等实体,以及它们随时间变化的关系。这会允许用户基于图结构和遍历算法,探索历史趋势、突发新闻事件以及相关实体。
听起来不错,对吧?现在我们来看一下如何使用 PropertyGraphIndex。
你可以定制 PropertyGraphIndex 的以下参数:
kg_extractors :接收一个 path extractor 列表,用于从文本中提取 (subject, predicate, object) 关系。默认情况下,它包含 SimpleLLMPathExtractor 和 ImplicitPathExtractor。SimpleLLMPathExtractor 使用 LLM 直接从文本中识别 subject--predicate--object 关系,而 ImplicitPathExtractor 专注于提取更简单的基于名词的连接,不依赖 LLM。或者,你也可以提供自定义 extractors,用于专门逻辑。
property_graph_store :定义要使用的 graph store 后端。LlamaIndex 默认提供内存 store,但也可以接入其他后端。默认情况下,它使用名为 SimplePropertyGraphStore 的内存实现。
vector_store :可选。允许你附加 vector store,使 VectorContextRetriever 能够将图感知结果与 embedding 相似度结合起来。
embed_kg_nodes :设置为 True 时,也就是默认值,索引会为每个实体节点生成并存储 embeddings。
use_async :允许你选择是否异步运行 path extraction,默认值为 True。
show_progress :一个布尔标志,用于在索引过程中显示进度条,默认值为 False。
MultiModalVectorStoreIndex
多模态向量存储索引更进一步,它允许我们不只处理文本,还能处理图像,并且都在一个统一索引中完成。它被设计用于文本和视觉数据都发挥作用,并且检索相关上下文依赖于联合理解它们的场景。
标准 VectorStoreIndex 专注于对文本 chunk 进行 embedding 和检索,而 MultiModalVectorStoreIndex 会并排处理多种数据模态。它会为不同内容类型维护独立的 vector store,通常一个用于文本,一个用于图像,但允许通过共享接口查询它们。这种设置使跨模态查询成为可能,其中,文本和图像内容可以互相补充。
图 5.12 展示了 MultiModalVectorStoreIndex 的整体结构:
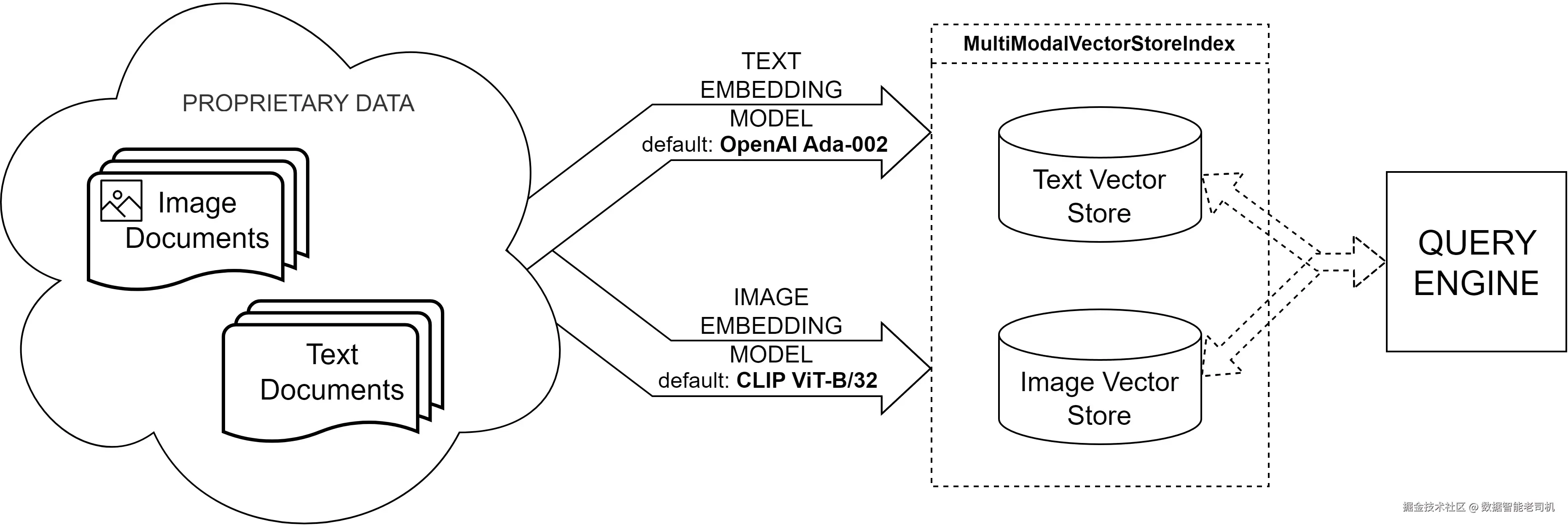
图 5.12 ------ MultiModalVectorStoreIndex 的结构
这个索引首先会处理每个文档,识别文本部分和任何嵌入图像。然后,它使用语言模型为文本内容生成 embeddings,并使用像 CLIP 这样的视觉语言模型处理和嵌入图像。这些 embeddings 会被分开存储,但索引能够在同一个查询中检索并组合它们。
CLIP,也就是 Contrastive Language--Image Pre-training,是 OpenAI 开发的一种视觉语言模型。它能够通过将图像和文本映射到共享 embedding 空间,同时理解图像和文本,从而直接比较和关联二者。这使它在多模态应用中特别有用,例如你想基于文本查询检索图像,或者反过来。
构建 multimodal vector store index
这个过程与 VectorStoreIndex 等其他索引类型非常相似,但有一个重要区别:当你针对 MultiModalVectorStoreIndex 运行查询时,需要使用具备视觉能力的 LLM;否则,就无法使用这个索引的完整能力。因此,在运行下一个示例之前,请确保你有额外 7GB 可用磁盘空间,并在 Ollama 中安装这个模型:
ollama pull llava:7b安装好 LLaVA 视觉模型之后,你可以在这里查看它的描述:ollama.com/library/lla...。下面是一个构建并查询MultiModalVectorStoreIndex 的简单示例:
ini
from llama_index.core.indices import MultiModalVectorStoreIndex
from llama_index.core import SimpleDirectoryReader
from llama_index.llms.ollama import Ollama
documents = SimpleDirectoryReader("multimodal_files").load_data()
index = MultiModalVectorStoreIndex.from_documents(documents)
llm = Ollama(
model="llava:7b"
)
query_engine = index.as_query_engine(llm=llm)
response = query_engine.query("What can you see in the pictures?")
print("Query response:\n", response)注意,我们没有使用常规的 models_config 结构来定制 LLM,而是直接定义了一个自定义 llm 对象,并将其传入 query engine。
在创建或微调这个索引时,可以调整几个重要参数:
image_embed_model :定义用于处理图像的 embedding 模型。默认情况下,它使用 clip:ViT-B/32,这是一个视觉语言模型,可以为图像生成与基于文本比较兼容的 embeddings。
is_image_to_text :当设置为 True 时,索引会尝试提取并嵌入图像中发现的任何文本内容,例如扫描文档或截图中的文本。这些文本会使用文本模型进行 embedding,使其能够和主要图像及文本内容一起被检索。默认值为 False。
image_vector_store :已废弃,仅为向后兼容保留。指定图像的自定义 embedding store。现在推荐的方法是通过 StorageContext 同时传入文本和图像 store。
is_image_vector_store_empty:表示图像 vector store 是否应该从空开始。当你从纯文本索引开始,并计划稍后添加图像 embeddings 时,这很有用。
is_text_vector_store_empty:表示文本 vector store 是否应该从空开始。当初始阶段只关注基于图像的内容时,这很有用。
这个索引也支持从基础 VectorStoreIndex 继承的标准选项,包括 use_async、show_progress 和 store_nodes_override。它们的工作方式与在 VectorStoreIndex 中完全相同。
该索引通过标准 storage_context.persist() 方法支持持久化,会保存文本和图像 embeddings 及其关联元数据。重新加载时,索引会重建两个 vector store,并保持正确的 namespace 分离。
检索过程会将查询文本进行 embedding,并将其与各自 vector store 中存储的文本和图像 embeddings 进行比较。对于图像查询,系统可以通过 CLIP 等多模态模型创建的共享 embedding 空间,将文本描述与图像内容匹配起来。
实际使用场景
这种索引类型在医学研究、电子商务、技术文档或教育等领域特别有用。在这些领域中,图像、图表和视觉元素通常与周围文本一样承载重要含义。通过允许这两类内容一起被索引和查询,MultiModalVectorStoreIndex 相比纯文本系统,提供了更完整且上下文感知更强的检索体验。
假设你正在为一家医疗机构构建研究助手。相关文档通常同时包含描述性文本,以及 X 光片、MRI 扫描、带注释图表等支持性视觉内容。一个只处理文本的传统 RAG 系统会忽略大量有价值信息。
使用 MultiModalVectorStoreIndex,用户可以问类似这样的问题:What studies include MRI scans showing signs of brain injury? 或 Which cardiac procedures are associated with X-ray imagery of the thoracic cavity?
这个索引会通过同时搜索文档文本和嵌入后的视觉数据来返回答案,提供更完整且基于所有可用模态的响应。
想查看如何在实践中使用这个索引的完整端到端示例,包括使用 OpenAI 视觉模型进行多模态检索,可以查看:
docs.llamaindex.ai/en/stable/e...
现在我们已经探索了如何索引和检索多模态内容,接下来看看 LlamaIndex 如何让你将多个索引组合成统一结构,这非常适合跨大量文档组织大型或复杂数据集。
为你的使用场景选择正确索引
现在我们已经探索了 LlamaIndex 中可用的不同索引类型,下面是一个快速参考,帮助你决定哪一种适合你的场景。表 5.1 对每种索引类型进行了比较,包括它们在索引和查询阶段对 LLM 和 embedding 的要求,以及你应该考虑不同选项的情况。请记住,任何在查询阶段使用 LLM 的索引,都会带来额外成本和延迟,因此提前理解这些权衡,可以为你后续节省时间和金钱。
| 索引类型 | 索引阶段使用 LLM | 索引阶段使用 embedding 模型 | 查询阶段使用 LLM | 避免使用的情况 |
|---|---|---|---|---|
VectorStoreIndex |
否 | 是 | 是 | 你需要跨整个文档集合进行推理,或数据变化过于频繁,不适合反复 re-embedding |
SummaryIndex |
否 | 否 | 是 | 大型文档集合,查询阶段 LLM 成本高,或定向查找场景 |
DocumentSummaryIndex |
是 | 是,默认 | 是 | 单文档使用场景,或索引成本是关注点 |
TreeIndex |
是 | 否,除非使用 embedding retriever | 是 | 没有自然层级的扁平数据;频繁数据更新,树重建成本高 |
KeywordTableIndex |
是 | 否 | 是,默认 retriever | 语义或模糊查询,即用户措辞可能与源文本不同 |
SimpleKeywordTableIndex |
否 | 否 | 否 | 同上 |
RAKEKeywordTableIndex |
否 | 否 | 否 | 同上 |
PropertyGraphIndex |
是 | 是 | 是 | 简单非结构化文本问答,当使用图的复杂性无法被场景证明合理时 |
表 5.1 ------ 不同索引类型及其要求概览
到目前为止,我们一直在单独看每种索引类型。但如果单一索引类型无法满足你的使用场景怎么办?LlamaIndex 允许你使用 ComposableGraph 将多个索引组合成统一结构。
使用 ComposableGraph 在索引之上构建索引
LlamaIndex 中的 ComposableGraph 表示一种复杂的信息结构化方式,它通过将索引堆叠在彼此之上来实现。
图 5.13 提供了 ComposableGraph 的概览:
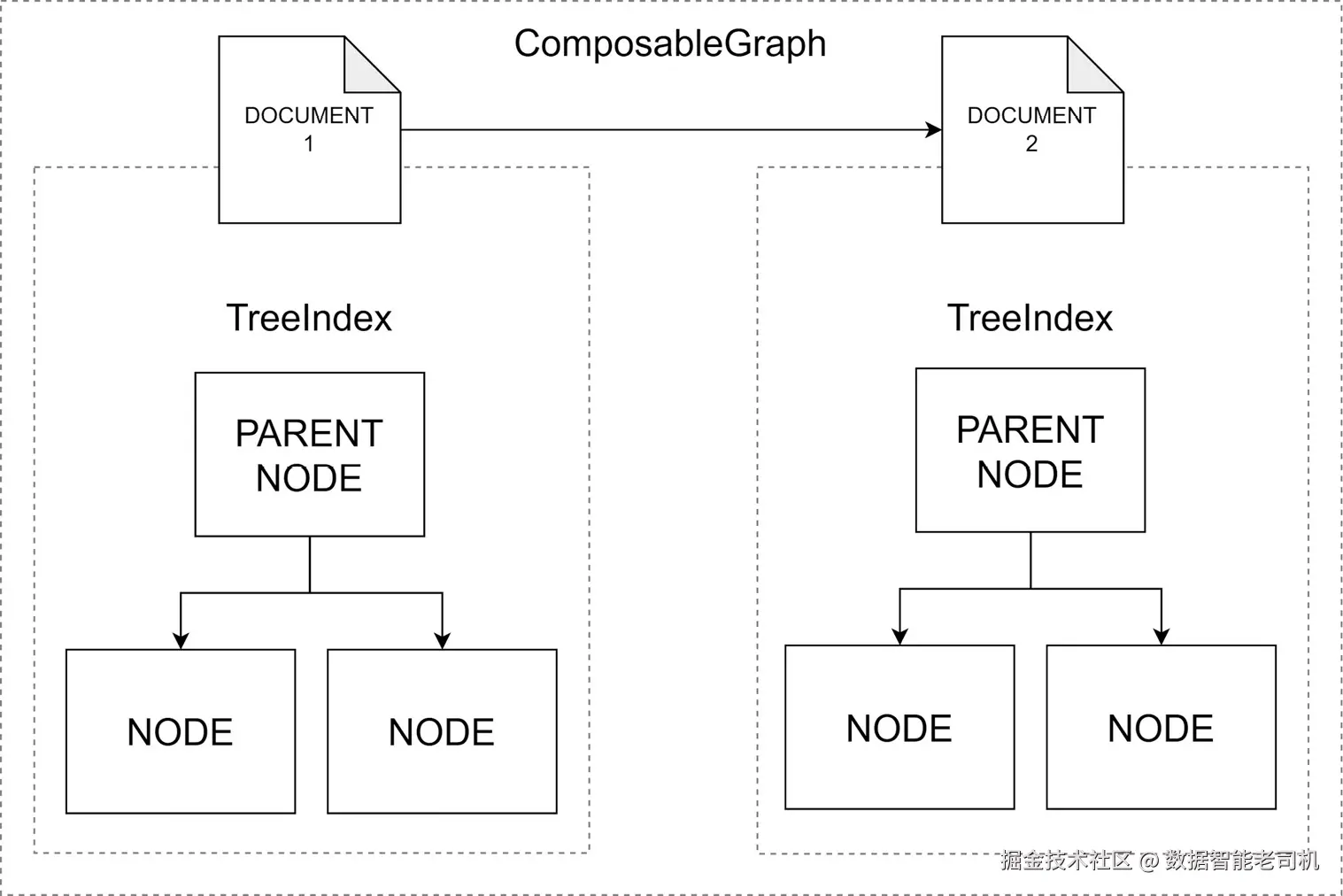
图 5.13 ------ ComposableGraph 的结构
这种方法允许在单个文档内部构建索引,也就是低层索引,并将这些索引聚合到文档集合之上的更高阶索引中。例如,你可以为每篇文档内的文本构建 tree index,然后构建一个 summary index,覆盖集合中的每个 TreeIndex。
如何使用 ComposableGraph
下面是一个展示 ComposableGraph 用法的简单代码示例:
ini
import models_config
from llama_index.core import (
ComposableGraph, SimpleDirectoryReader,
TreeIndex, SummaryIndex
)
documents = SimpleDirectoryReader("files").load_data()
index1 = TreeIndex.from_documents([documents[0]])
index2 = TreeIndex.from_documents([documents[1]])
summary1 = "A short introduction to ancient Rome"
summary2 = "Some facts about dogs"
graph = ComposableGraph.from_indices(
SummaryIndex, [index1, index2],
index_summaries=[summary1, summary2]
)
query_engine = graph.as_query_engine()
response = query_engine.query("What can you tell me?")
print(response)在这个示例中,ComposableGraph 支持组织文档内部的详细信息,并跨文档进行总结。
我们首先加载两个测试文档:一个与古罗马相关,另一个描述狗。你可以在代码仓库的 ch5/files 下找到这两个文件。然后,我们为每个文档创建一个 tree index。
我们还定义了两个文档的摘要。
作为手动定义摘要的替代方案,我们也可以查询每个单独索引来自动生成内容摘要,或者使用 SummaryExtractor 达到同样目的。
下一步,我们构建一个包含两个 tree indexes 及其摘要的 composable graph。对于这个示例,代码输出应该类似如下:
css
I can tell you about the ancient Roman civilization and dogs and their various breeds, traits, and personalities.一旦 composable graph 构建完成,根 SummaryIndex 就会拥有每个文档对应单独索引内容的概览。
对这个概念的更详细描述
在底层,ComposableGraph 通过将索引堆叠在彼此之上,支持创建层级结构。这允许使用低层索引组织单个文档内部的详细信息,并在文档集合之上将这些索引聚合为更高阶索引。
过程首先会为每个文档创建单独索引,以捕捉文档中的详细信息。此外,还会为每个文档定义摘要。
然后,使用 from_indices() 类方法构建 composable graph。它接收根索引类,在我们的示例中是 SummaryIndex;子索引,在我们的示例中是两个 TreeIndex 实例;以及它们对应的摘要作为输入。这个方法会为每个子索引创建 IndexNodes 实例,并将摘要与对应索引关联起来。然后,这些 IndexNodes 实例被用于构建根索引。
查询期间,ComposableGraph 从顶层 summary index 开始,其中每个节点对应一个底层低层索引。查询会递归执行,从根索引开始,并遍历子索引。ComposableGraphQueryEngine 负责这个递归查询过程。
query engine 会基于查询从根索引中检索相关节点。对于每个相关节点,它会使用存储在节点关系中的 index_id 识别对应子索引。然后,它会用原始查询查询子索引,以获取更详细信息。这个过程会递归继续,直到所有相关子索引都被查询过。
可以为 composable graph 中的每个索引配置自定义 query engine,从而在不同层级使用定制检索策略。这支持对复杂数据集形成深层级、层次化理解,并能无缝整合来自不同索引层级的信息。
虽然 ComposableGraph 在 LlamaIndex 中仍然受到完整支持,但它不再是多索引编排的首选推荐方法。更新的方法,例如 RouterQueryEngine 或 sub_question_query_engine,提供了更灵活且动态的方式,可以跨多个数据源路由查询。这些新工具支持基于语义或元数据的路由,通常更适合复杂或持续演进的 RAG 工作流。不过,ComposableGraph 仍然是静态、层级化文档结构的有价值选择,并且当你希望明确不同索引之间如何关联时,它非常理想。
构建索引只是故事的一部分。在实践中,随着文档演进,你还需要维护索引,这正是我们接下来要探索的内容。
管理索引的生命周期
到目前为止,我们一直关注如何从零构建索引。但在真实世界中,数据不会保持静止。文档会被添加,已有文档会被修订,过时内容需要被移除。如果每次发生变化都要重建整个索引,那么时间、计算和 LLM 调用成本很快就会变得不切实际。
好消息是,LlamaIndex 内置支持以增量方式管理这些变化。让我们走过几个关键操作。
为高效索引更新设置一切
在我们更新任何内容之前,LlamaIndex 需要一种方式来跟踪哪些文档已经在索引中,以及它们是否发生变化。这是通过文档 ID 完成的。正如我们在第 3 章《开启你的 LlamaIndex 之旅》中已经讨论过的,每个 document 对象都有一个 id_ 属性。LlamaIndex 会将它与文档内容的内部 hash 一起使用,以确定文档是新的、已修改的,还是未变化的。refresh 逻辑会检查是否已经存在相同 ID 的文档,以及它的 hash 是否发生变化。但这种比较并不局限于纯文本:文本或元数据的变化也可能触发 refresh。这就是为什么稳定文档 ID 对增量更新如此重要。
如果你从目录加载文件,最简单的方法是让 SimpleDirectoryReader 自动基于文件名分配稳定 ID,如下面示例所示:
ini
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader("files", filename_as_id=True)
documents = reader.load_data()
for doc in documents:
print(doc.id_)这个示例的输出会显示 files 子文件夹中两个示例文件的名称:
sample_document1.txt
sample_document2.txt使用 filename_as_id=True 时,每个文档都会获得一个从文件路径派生出来的 ID。这意味着,如果你稍后重新加载同一个目录,LlamaIndex 可以识别它已经见过哪些文件。没有稳定 ID 时,每次重新加载都会把每个文档视为全新文档,你也会失去执行增量更新的能力。
正如第 3 章解释过的,你也可以在创建文档时手动设置 ID:
python
from llama_index.core import Document
doc = Document(text="Some content", id_="my_custom_id")
print(doc)这部分输出会是:
yaml
Doc ID: my_custom_id
Text: Some content当你的文档来自数据库、API 或任何不适用文件名的来源时,这很有用。那么,当我们需要向索引中插入新文档时,会发生什么?
将新文档插入索引
向现有索引添加新文档也很直接。我们不需要重建整个索引。下面的示例先通过 Ollama 设置我们的 Gemma3:4B 模型,然后手动创建一个文档。
arduino
import models_config
from llama_index.core import Document, VectorStoreIndex
index = VectorStoreIndex.from_documents(
[Document(text="Original text with code ALPHA123.", id_="doc_1")]
)接下来,我们插入新文档,并检查新的索引内容。
arduino
from llama_index.core import Document, VectorStoreIndex
index = VectorStoreIndex.from_documents(
[Document(text="Original code ALPHA123.", id_="doc_1")]
)
index.insert(Document(text="Inserted code BETA999.", id_="doc_2"))
response = index.as_query_engine().query("What's in the documents?")
print("After insert:")
for node in response.source_nodes:
print(node.node.text)当我们运行 index.insert(new_doc) 时,新文档会被拆分成节点并摄取到索引中。
输出应该类似如下:
less
After insert:
Original code ALPHA123.正如本章前几节讨论过的,具体插入机制取决于索引类型:对于 VectorStoreIndex,这意味着生成 embeddings 并将它们添加到 vector store;而对于 SummaryIndex,新节点只是简单追加到列表中。
更新已有文档
当现有文档内容发生变化时,你可以更新它,而不必手动删除并重新插入。在这种情况下,文档拥有与已有文档相同的 id:
vbscript
index.update_ref_doc(Document(text="Updated code GAMMA777.", id_="doc_2"))
response = index.as_query_engine().query("What's in the documents?")
print("\nAfter update:")
for node in response.source_nodes:
print(node.node.text)这应该会产生下面的输出:
less
After update:
Updated code GAMMA777.在内部,这等价于删除旧版本并插入新版本。LlamaIndex 会通过 id_ 匹配文档,移除旧节点,并处理更新后的内容。这对于经常被修订的文档特别有用,例如政策、技术规范或知识库文章。
从索引中删除文档
从索引中移除文档和我们目前介绍的其他操作一样简单:
vbscript
index.delete_ref_doc("doc_2" , delete_from_docstore=True)
response = index.as_query_engine().query("What's in the documents?")
print("\nAfter delete:")
for node in response.source_nodes:
print(node.node.text)现在输出如下:
arduino
After delete:
Original code ALPHA123.这会从索引中移除与该文档关联的所有节点。delete_from_docstore 参数值得快速解释一下:默认情况下,它被设置为 False。这是一个安全措施,适用于你可能在多个索引之间共享同一个 docstore 的场景。将它设置为 False 会从索引结构中移除文档,使它不会出现在查询中,但会保留 docstore 中的底层节点,以防另一个索引仍然引用它们。如果你使用的是单个索引,并希望干净移除,就将它设置为 True。
目前 TreeIndex 不支持删除。如果你正在使用 TreeIndex 并需要移除文档,就需要重建索引。
自动刷新索引
保持索引更新的最实用方法是 refresh_ref_docs()。这很可能是你最常使用的操作,尤其是当你的数据源是一个会定期更新的目录时。它的工作方式如下。
首先,我们从来源重新加载文档:
ini
import models_config
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
reader = SimpleDirectoryReader("files", filename_as_id=True)
documents = reader.load_data()
index = VectorStoreIndex.from_documents(documents)接下来,我们刷新索引:
scss
refreshed = index.refresh_ref_docs(documents)
print(refreshed)在这个例子中,因为文件没有变化,输出如下:
python
[False, False]如果你想做一个小实验,可以修改脚本,让它在刷新前实际改变文件内容,然后你会看到刷新反映在新的输出中。
这个方法会比较每个文档的内容 hash 与重新加载文档的 hash。如果还不存在拥有该 ID 的文档,就会插入它。如果 ID 已经存在,但文本或元数据发生变化,就会更新文档。如果没有任何变化,就会跳过。返回的布尔列表会准确告诉你哪些输入文档被插入或刷新了。True 表示文档被更新或插入,False 表示文档未变化。
顺便说一句,这正是设置 filename_as_id=True 真正发挥价值的地方。当你从同一个目录重新加载文档时,ID 会保持一致,refresh_ref_docs() 可以准确检测变化。没有稳定 ID 时,每个文档都会看起来像新文档,整个索引都会被重新处理,从而违背了整个目的。
请记住,refresh_ref_docs() 依赖内部 docstore 来比较文档 hash。它与默认内存存储配合良好。不过,如果你使用的是外部 vector store 集成,例如 Pinecone 或 Elasticsearch,但没有单独的 docstore,hash 比较可能无法按预期工作。在某些情况下,所有文档都会被视为新文档。如果遇到这种情况,可以退回到使用 vector store 原生 API 手动执行 delete 和 insert 操作。
实现版本控制
对于生产系统,你可能还需要考虑版本控制。LlamaIndex 并没有提供内置版本控制机制,但可以采用几种策略:
最简单的方法是在进行更改之前,将索引持久化到不同目录。这会给你一个快照,如果出现问题可以回滚。你可以把它看作一个手动 checkpoint。
另一个选项是在摄取期间使用元数据为文档标记版本号或时间戳。例如,你可以在文档元数据中添加一个 version 字段,并在检索期间使用元数据过滤器,以确保始终查询最新版本。我们已经在第 4 章《将数据摄取到我们的 RAG 工作流中》中讨论过元数据,并将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中介绍元数据过滤。
最后,如果你设置了带缓存的摄取流水线,正如第 4 章中讨论过的,IngestionCache 已经提供了一种去重形式,因为它会跟踪哪些文档已经被处理过,并在后续运行中跳过它们。这与 refresh 机制很好互补:cache 处理摄取流水线,而 refresh_ref_docs() 处理索引本身。
最佳实践
在继续之前,下面是一个关于长期管理索引的最佳实践快速总结:
- 始终分配稳定文档 ID。对于基于文件的来源,使用
filename_as_id=True;对于其他来源,手动设置doc_id或id_。没有稳定 ID,增量更新就无法正确工作。 - 在可能时,优先使用
refresh_ref_docs(),而不是手动 insert/update。它会为你处理比较逻辑,并最小化不必要的 LLM 和 embedding 调用。 - 每批更改后都持久化索引。不管你使用简单的基于文件的存储,还是 vector database,保存索引状态都能确保你不会丢失工作。
- 对于生产部署,考虑使用具备原生 CRUD 支持的 vector database,而不是默认内存 store。ChromaDB、Pinecone 或 Qdrant 这样的数据库,比基于文件的存储更优雅地处理并发更新、持久化和扩展。
- 保持摄取流水线和索引管理同步。如果你在流水线中使用
IngestionCache,并在索引中使用refresh_ref_docs(),请确保二者都感知相同的文档 ID。
现在我们已经介绍了不同索引以及如何管理它们的生命周期,是时候处理那个"房间里的大象"了------成本。
构建和查询索引时的成本考虑
就像元数据 extractor 一样,索引也会带来与成本和数据隐私相关的问题。这是因为,正如我们在本章看到的,大多数索引都会在某种程度上依赖 LLM------在构建阶段和/或查询阶段。
如果你没有注意潜在成本,反复调用 LLM 来处理大量文本,很快就可能突破预算。例如,如果你从数千篇文档构建 TreeIndex 或 KeywordTableIndex,索引构建期间持续不断的 LLM 调用会带来显著成本。Embeddings 也可能依赖对外部模型的调用,因此 VectorStoreIndex 是另一个重要成本来源。根据我的经验,预防和预测是避免糟糕惊喜并保持低成本的最佳方式。
和元数据提取一样,我们先观察并应用一些最佳实践:
- 尽可能使用构建期间不需要 LLM 调用的索引,例如
SummaryIndex或SimpleKeywordTableIndex。这可以消除索引构建成本。 - 使用更便宜的 LLM 模型。如果不需要完整准确性,可以使用计算需求更低、更便宜的 LLM 模型;不过,要注意可能存在质量权衡。
- 缓存并复用索引。在可能时,通过缓存和复用之前构建好的索引,避免重建索引。
- 优化查询参数,以在搜索过程中最小化 LLM 调用。例如,降低
VectorStoreIndex中的similarity_top_k会减少查询成本。 - 使用本地模型。为了进一步管理成本,并在使用 LlamaIndex 索引时保持数据隐私,可以考虑使用本地 LLM 和 embedding 模型,而不是依赖托管服务。这种方法不仅能提供更多数据隐私控制,也有助于降低对外部服务的依赖,而外部服务可能成本高昂。使用本地模型可以显著降低支出,尤其是在处理大量数据,或在严格预算约束下运行时。
请始终记住,RAG 会将额外知识和上下文信息引入模型处理过程,实际上弥合了较小训练数据集造成的差距。因此,即使某些模型没有在广泛或多样化数据上训练,RAG 也允许它们访问超出初始训练集的更大范围信息,从而增强其性能和输出质量。
这些指南肯定会帮助你降低成本,但在索引较大数据集之前,提前估算仍然是一个好主意。
下面是一个基础示例,展示如何使用 MockLLM 估算构建 tree index 的 LLM 成本。首先,让我们处理必要导入:
javascript
import tiktoken
from llama_index.core import (
TreeIndex, SimpleDirectoryReader, Settings
)
from llama_index.core.llms.mock import MockLLM
from llama_index.core.callbacks import (
CallbackManager, TokenCountingHandler
)这里我们使用了 tiktoken tokenizer 库。如果你不熟悉为什么要使用 tokenizer,可以回到第 4 章《将数据摄取到我们的 RAG 工作流中》,那里我们讨论过估算使用元数据 extractor 潜在成本的问题。
tiktoken 是 OpenAI 的 tokenizer 库。tokenizer 会将文本拆分成 LLM 实际处理的微小单元,也就是 tokens。由于成本通常以 tokens 衡量,而不是单词或字符,所以 tiktoken 可以让你估算一段文本对于特定模型会消耗多少 tokens。例如,当你调用 tiktoken.encoding_for_model("gpt-3.5-turbo").encode 时,底层会使用 CL100K tokenizer,这是 GPT-3.5 和 GPT-4 模型使用的特定 tokenization 方案,词汇表约有 100,000 个 tokens。这样,你就可以在不真正调用模型、也不付费的情况下,估算一次真实 API 调用在 token 上会有多贵。
接下来设置 MockLLM:
ini
llm = MockLLM(max_tokens=256)
token_counter = TokenCountingHandler(
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
callback_manager = CallbackManager([token_counter])
Settings.callback_manager=callback_manager
Settings.llm=llm我们刚刚创建了一个 MockLLM 实例,并指定最大 token 限制,以作为最坏情况下的最大成本。现在,我们用下面这行代码,用与真实 LLM 模型匹配的 tokenizer 初始化 TokenCountingHandler:
arduino
tiktoken.encoding_for_model("gpt-3.5-turbo").encode这个 handler 会跟踪 token 使用量。这个结构会模拟一个 LLM,而不会真正调用 gpt-3.5-turbo API。接下来,我们摄取数据:
scss
documents = SimpleDirectoryReader(
"cost_prediction_samples"
).load_data()现在我们已经加载好文档,可以构建 tree index:
ini
index = TreeIndex.from_documents(
documents=documents,
num_children=2,
show_progress=True
)
print("Total LLM Token Count:", token_counter.total_llm_token_count)构建索引之后,脚本会显示存储在 TokenCountingHandler 中的 total_llm_token_count 值。
在这个示例中,我们只使用 MockLLM 类,因为构建 TreeIndex 不使用 embeddings。这允许我们在真正构建索引并调用真实 LLM 之前,估算最坏情况下的 LLM token 成本。同样的方法也可以用于估算查询成本。
这里最主要的教训是什么?
虽然索引解锁了许多能力,但如果缺乏优化地过度使用,会极大影响成本。在索引大型数据集之前,请始终估算 token 使用量。
下面是第二个示例。它与前一个类似,但这一次,我们先估算构建 vector store index 的 embedding 成本,然后估算查询索引的总成本。首先,让我们处理导入:
javascript
import tiktoken
from llama_index.core import (
MockEmbedding, VectorStoreIndex,
SimpleDirectoryReader, Settings
)
from llama_index.core.callbacks import (
CallbackManager, TokenCountingHandler
)
from llama_index.core.llms.mock import MockLLM接下来,我们设置 MockEmbedding 和 MockLLM 对象:
ini
embed_model = MockEmbedding(embed_dim=1536)
llm = MockLLM(max_tokens=256)
token_counter = TokenCountingHandler(
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
callback_manager = CallbackManager([token_counter])
Settings.embed_model=embed_model
Settings.llm=llm
Settings.callback_manager=callback_manager初始化 MockEmbedding 和 MockLLM 对象之后,我们定义了 TokenCountingHandler 和 CallbackManager,并将它们包装进自定义 Settings 中。现在,是时候加载示例文档,并使用自定义 Settings 构建 vector store index 了:
ini
documents = SimpleDirectoryReader(
"cost_prediction_samples"
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
show_progress=True
)
print("Embedding Token Count:",
token_counter.total_embedding_token_count)如果你已经成功克隆本书 GitHub 仓库,ch5 文件夹中的 cost_prediction_samples 子文件夹应该包含一个关于猫 Fluffy 的虚构故事文件。VectorStoreIndex 在索引期间使用 embedding 模型将文档文本编码为向量。
在当前示例中,我们通过使用 MockEmbedding 和 TokenCountingHandler,估算了这些 embedding 调用的 token 成本。embedding token count 可以基于文本长度,指出为每篇文档构建这个索引大概会有多贵。
为了获得完整视图,我们还可以进一步估算搜索成本:
scss
query_engine = index.as_query_engine(service_context=service_context)
response = query_engine.query("What's the cat's name?")
print("Query LLM Token Count:", token_counter.total_llm_token_count)
print("Query Embedding Token Count:",
token_counter.total_embedding_token_count)前面的代码展示了 embedding 查找和响应合成的潜在 token 成本。我们还必须使用 MockLLM 来捕捉响应合成过程中假设消耗的 LLM tokens。当使用托管商业模型时,这些计数随后可以用来估算实际费用。
所以,总结一下:遵循预防性最佳实践,并且在把索引构建和查询扩展到完整文档集合之前,始终预测相关开销!
暂时就到这里。我们将在第 6 章《查询我们的数据,第 1 部分------上下文检索》中继续下一步。
总结
在本章中,我们探索了 LlamaIndex 中的各种索引策略和架构。索引为构建高性能 RAG 系统提供了核心能力。我们介绍了最常用的索引类型------vector store index,并理解了 embeddings、vector stores、similarity search 和 storage contexts。这些都是与 vector store index 相关的关键概念。
我们还覆盖了其他索引类型,例如用于文档级综合的 SummaryIndex、用于关键词搜索的 KeywordTableIndex、用于层级数据的 TreeIndex、用于基于摘要的文档检索的 DocumentSummaryIndex,以及用于基于关系查询的 PropertyGraphIndex。本章提供了一个对比表,帮助你为使用场景选择合适索引。我们介绍了 ComposableGraph,它是一种用于构建多层索引的工具;并介绍了如何管理索引生命周期,包括增量插入、更新、删除和刷新文档。最后,我们讨论了成本估算技术和最佳实践。
总体而言,本章对 LlamaIndex 中的索引能力进行了概览,为构建复杂且高效的 RAG 应用奠定了基础。
第 6 章见,我们将在那里讨论在 LlamaIndex 中查询数据的方法。