
大家好,我是子昕。
这两天我花时间看了一下 Claude Code 新出的 Dynamic Workflows。
先说清楚,这篇不是一次完整的极限压测。
真正适合 workflows 的任务,往往是代码库审计、大规模迁移、复杂方案交叉验证。
这些场景当然更能体现它的上限,但不适合拿来写文章演示。
一是过程太长。
二是上下文太依赖具体项目。
三是读者很难从截图里看出重点。
所以我这次选了一个相对容易展示的任务:
先做一次技术调研,再基于调研结果生成下一步 workflow。
它不算最复杂,但足够看清 Dynamic Workflows 的核心机制。
我一开始以为,它只是 Claude Code 又多开几个 Agent。
但跑完之后我发现,重点不是 Agent 数量。
重点是:
它把复杂任务的中间过程,从主对话里搬了出去。
先说结论:
这个功能不是拿来改小 bug 的。
如果只是改一个函数、修一个具体报错、问一个小问题,直接让 Claude Code 做就行,没必要上 workflows。
Dynamic Workflows 真正适合的是另一类活:
任务很大,过程很长,中间资料很多,还需要多个角度互相验证。
比如:
- 技术调研
- 代码库审计
- 大规模迁移
- 复杂方案设计
- 发布前检查
- 多角度交叉验证
我这次用来演示的路径是这样的:
先用 /deep-research 做了一份 Java 虚拟线程在 Spring Boot 生产系统里的研究报告。
然后基于这份报告,继续让 Claude Code 生成一个 Spring Boot 虚拟线程实验项目的 workflow。
跑完之后我最大的感受不是"它开了多少个 Agent"。
而是:
它把一个复杂任务的流程,写成了可以运行、可以观察、可以保存的 JS 脚本。
这件事比"多开几个 Agent"重要得多。
为什么已经有 Subagent、Skills、Agent Teams,还要 Workflows?
这个问题很关键。
因为 Claude Code 之前已经有 Subagent 和 Agent Teams,我自己也写过一篇文章讲它们。
很多人第一次看到 Dynamic Workflows,可能会觉得:
这不就是又多开几个 Agent 吗?
不是。
它们解决的问题不一样。
可以简单这么理解:
| 能力 | 像什么 | 适合什么 |
|---|---|---|
| Subagent | 临时派一个人出去查 | 搜一块代码、审一个模块、做一个旁路任务 |
| Skills | 固化下来的做事方法 | 写文章流程、代码规范、项目启动步骤 |
| Agent Teams | 多角色协作小组 | 多模块任务、多人分工、互相反馈 |
| Dynamic Workflows | 写成脚本的任务编排 | 调研、审计、迁移、交叉验证、可复跑流程 |
再压缩成一句话:
Subagent 解决的是"派谁干一小块";Skills 解决的是"以后按什么方法干";Agent Teams 解决的是"多个角色怎么协作";Dynamic Workflows 解决的是"整个复杂任务怎么被编排、保存和复跑"。

Subagent 的价值,是让一个子任务不要污染主对话。
比如你让它去搜支付模块相关代码,它自己读文件、跑命令、整理结果,最后把摘要带回来。
Skills 的价值,是把一套固定做法沉淀下来。
比如我现在写公众号文章,就有自己的写作 skill。里面规定了先检索、再出大纲、再写初稿、再多角色审阅。
Agent Teams 的价值,是让多个角色协作。
比如一个 Agent 看后端,一个 Agent 看前端,一个 Agent 看测试,一个 Agent 负责汇总。
它更像一个小团队,重点是角色分工和互相反馈。
而 Dynamic Workflows 往前走了一步。
它不是只派一个 Agent,也不是只给 Claude 一份说明书,更不是单纯让几个 Agent 互相协作。
它是把流程本身写进 JS 脚本里。
脚本负责:
- 分几个阶段
- 每个阶段派哪些 Agent
- 哪些任务可以并行
- 哪些任务必须等待前置结果
- 每一步结果怎么传给下一步
- 最后怎么汇总
这就是 workflows 的新价值。
不是"又多一个 Agent",而是"流程本身可以被执行"。
它真正解决的,是主对话扛不住的问题
Dynamic Workflows 最值得单独讲的,是上下文。
以前做复杂任务,一个很常见的问题是:
Claude Code 一路搜索、读文件、分析、总结,所有中间过程都往当前对话里堆。
刚开始还挺清楚。
越往后信息越多,上下文越来越脏。
后面你再追问,它可能已经开始混乱了。
Dynamic Workflows 的机制不一样。
它生成的是一个 JS 脚本。
这个脚本在隔离的运行环境里执行。
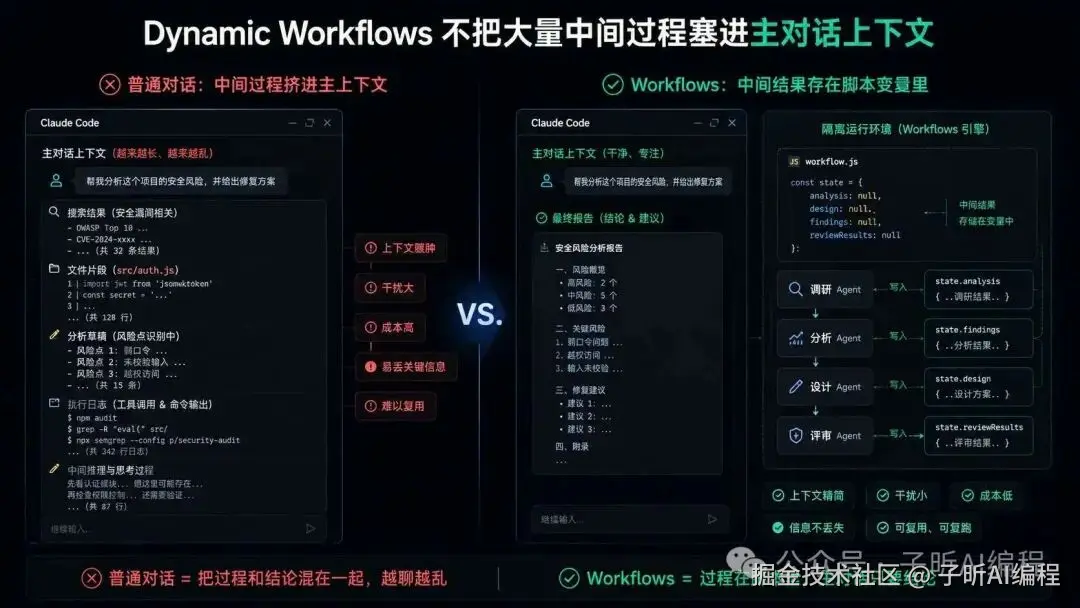
中间结果放在脚本变量里,而不是把大量中间过程塞进 Claude Code 当前主对话。
也就是说:
每个 Agent 搜到的资料、阶段分析结果、交叉验证结果、临时 JSON 数据,不需要一股脑进入你的主对话。
主对话最后只需要接收收敛后的结果。
普通对话是在不断消耗主上下文。
workflow 是把中间结果存在脚本变量里。
这就是它适合重活的原因。
因为很多复杂任务真正难的,不是"模型不会想",而是:
中间过程太多,把上下文挤爆了。
Workflows 解决的不只是并行问题,还有上下文污染问题。
这不是说 workflow 不消耗 token。
每个 Agent 自己仍然会消耗上下文和 token。
区别在于,它不会把所有中间过程都倒回你的当前主对话里。
这里也要理解一个边界:
workflow 脚本本身不直接读写文件,也不直接执行 shell。
它主要负责调度。
真正读文件、改代码、跑命令的是被它派出去的 Agent。
你可以把 workflow 理解成一个在隔离环境里运行的项目计划。
它不亲自执行每个动作,但它决定谁先做、谁后做、谁等谁、结果放哪里。
怎么触发它,不是重点,但要先知道
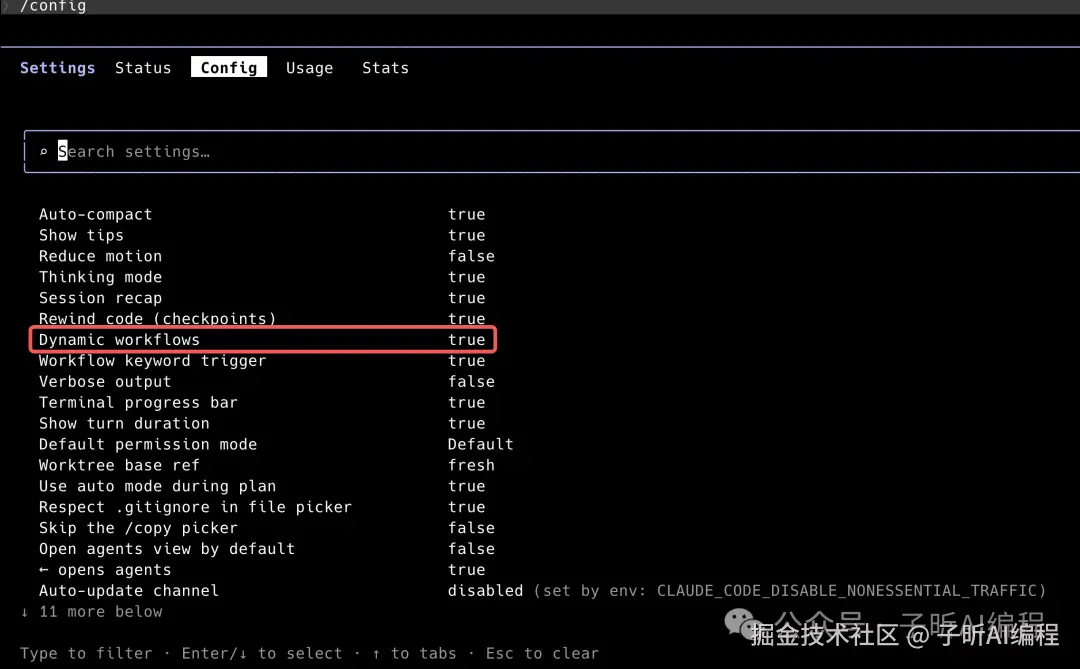
在 Claude Code 里输入:
arduino
/config找到 Dynamic workflows。
只要这里是 true,就代表可以使用动态工作流。
然后可以执行:
bash
/effort ultracode开启后,Claude Code 会根据你的任务自动判断要不要用 workflow。

除了 ultracode,还有一个更直接的触发方式:
你在提示词里输入 workflow 或 workflows。
只要这个词变成彩色,就说明这次请求会触发 workflow。

第一类适合 workflows 的活:复杂技术调研
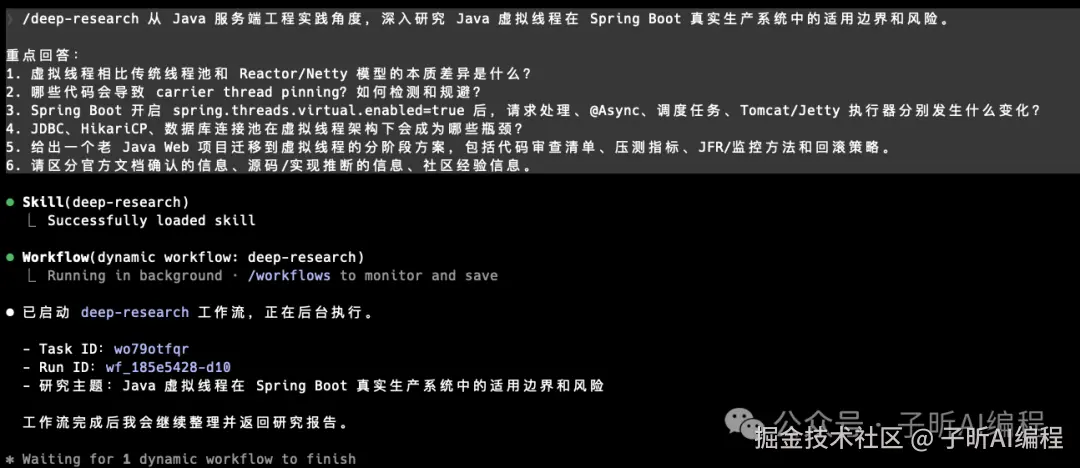
Claude Code 里内置了一个 workflow:
bash
/deep-research我用它研究了一个比较工程化的问题:
Java 虚拟线程在 Spring Boot 生产系统里的适用边界和风险。
启动后,它会自动进入 workflow。
这份报告超过 1000 行。
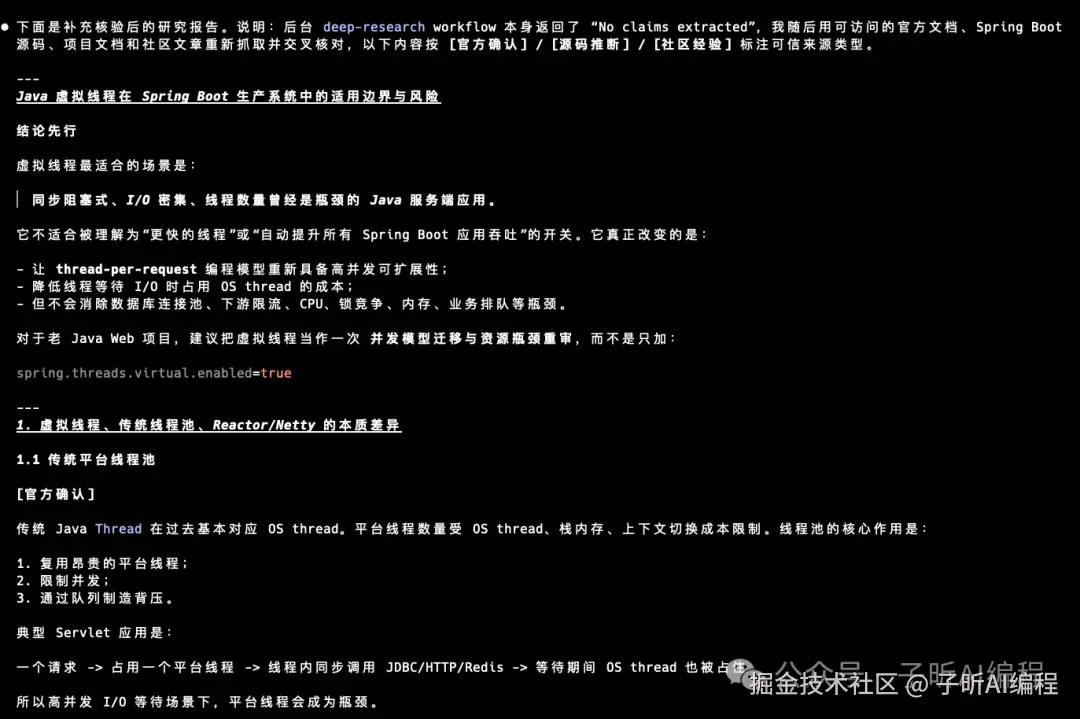
我看完之后,觉得它不是那种泛泛而谈的科普。
我判断 /deep-research 有没有用,不看它写了多少字。
而是看它有没有把真实工程里会踩坑的地方挖出来。
它覆盖了这些点:
- 虚拟线程、传统线程池、Reactor/Netty 的差异
- Java 21 和 Java 24 在 pinning 上的关键差异
spring.threads.virtual.enabled=true开启后对 Spring Boot 的影响- Tomcat、Jetty、
@Async、@Scheduled的执行变化 - JDBC 和 HikariCP 在虚拟线程下的瓶颈
- JFR 怎么看
jdk.VirtualThreadPinned - 老 Java Web 项目怎么分阶段迁移
- 灰度和回滚策略
其中有个判断很关键:
虚拟线程不等于数据库能处理更多查询。
如果请求线程不再是瓶颈,HikariCP、数据库连接数、下游服务限流反而会变成更明显的闸门。
这类结论对 Java 后端读者是有用的。
我对 /deep-research 的评价是:
它很适合做高质量调研底稿。
特别是那种资料分散、需要分角度搜索、还要互相校验的主题。
以前你让一个 Agent 做这类调研,很容易出现两个问题:
一是资料搜得多,主对话被撑满。
二是前面搜到的内容,后面未必还能被很好地组织起来。
/deep-research 这种 workflow 更适合这类活。
因为它天然就是:
先分角度搜索。
再交叉验证。
再过滤掉不可靠的说法。
最后给你一份收敛报告。
但我也不会把它当成最终结论。
比如虚拟线程这种问题,报告可以告诉你风险点在哪里、应该怎么压测、应该看哪些指标。
但性能结论、连接池瓶颈、生产风险,最后还是要靠自己的实验验证。
所以我会把 /deep-research 当成研究助理。
不是当成拍板的人。
长任务最怕黑盒,/workflows 解决这个问题
workflow 跑起来后,可以输入:
bash
/workflows查看当前和历史 workflow。
多 Agent 不可怕。
看不见多 Agent 在干什么,才可怕。

进入具体 workflow 后,可以看到不同阶段。
每个阶段里有多少 Agent、用了多少 token、跑了多久,都能看到。
这里顺带交代一下,我截图里能看到当时是在 Claude Code 里接入 GPT 模型测试。
这个只是测试环境,不是这篇文章的重点。
真正要看的,是 Dynamic Workflows 这套任务编排机制。
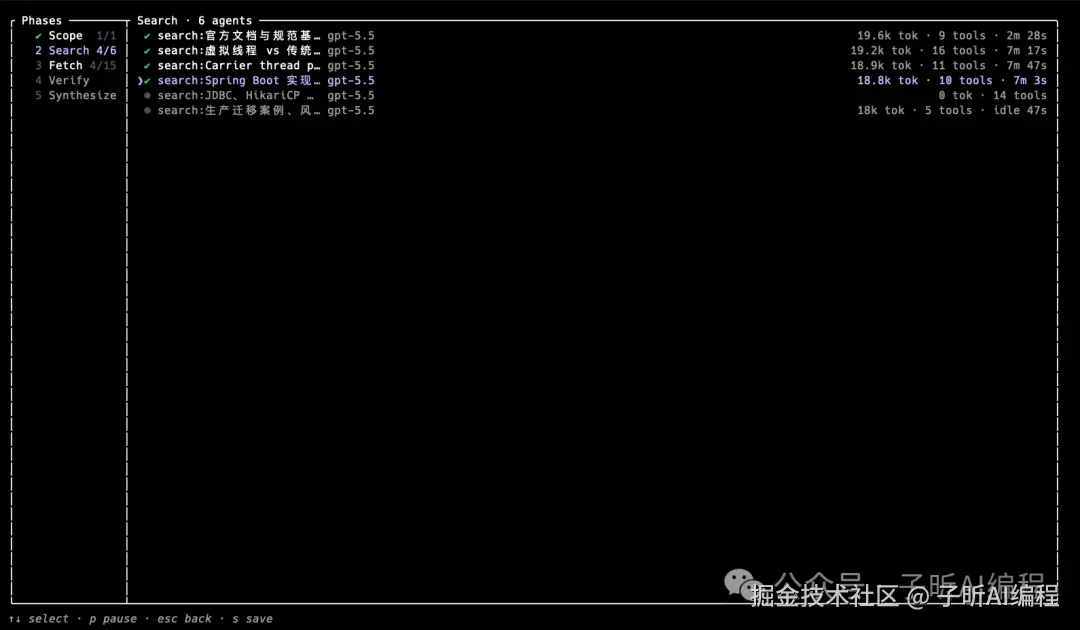
可以用键盘上下左右方向键选择不同阶段或不同 Agent。
进入某个 Agent 后,可以看到它的运行详情。
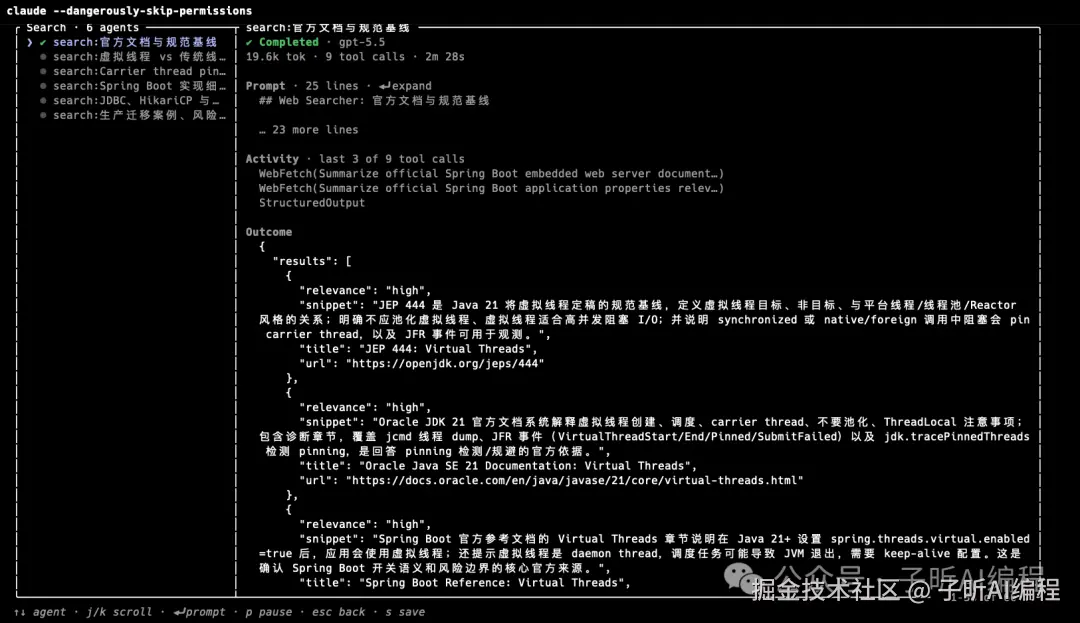
某个agent运行详情
如果某个 Agent 还没开始,也能看到它处在等待状态。

还没开始的agent
有些内容默认会折叠。
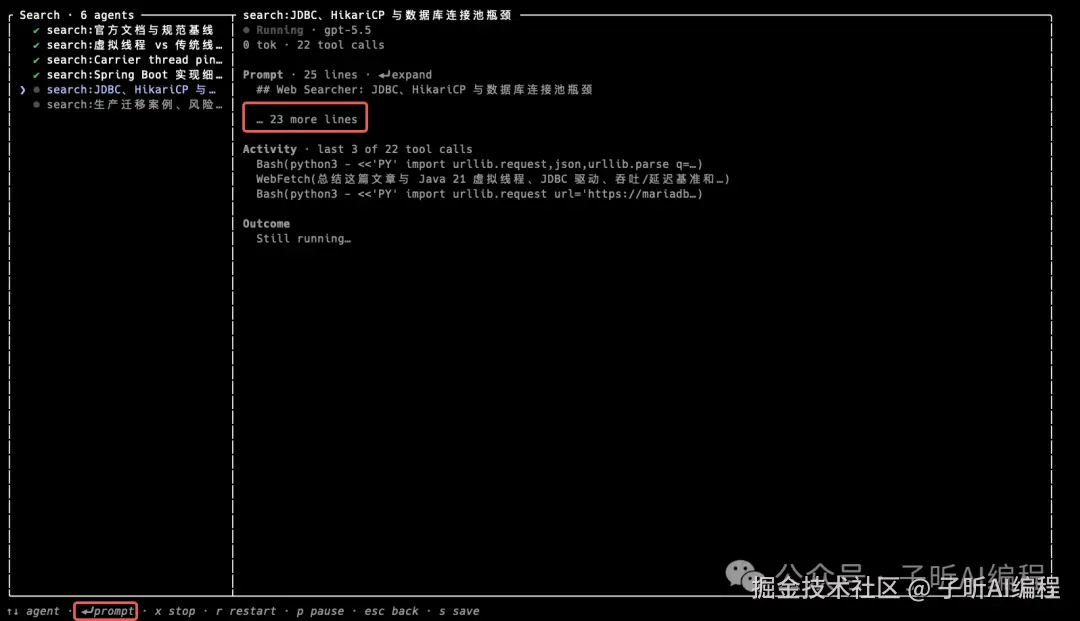
查看agent运行详情,内容被折叠
按回车可以展开。
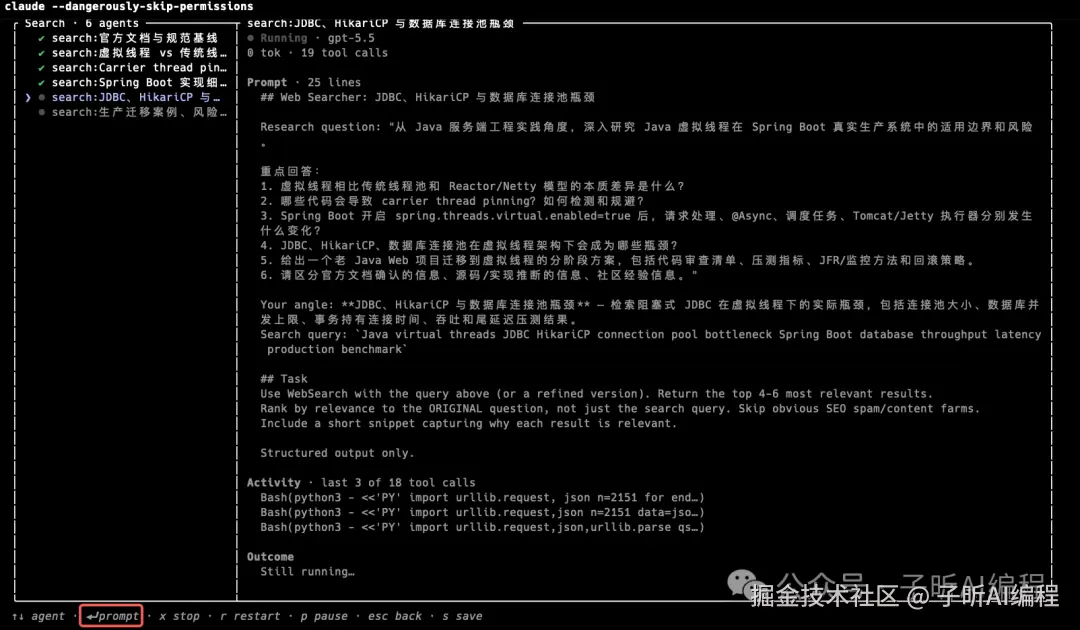
回车按键,展开折叠的内容
这部分体验很关键。
因为多 Agent 最怕的就是黑盒。
你只看到它在跑,但不知道谁在干什么。
/workflows 至少让你能看到:
- 现在跑到哪个阶段
- 哪些 Agent 已经完成
- 哪些 Agent 还在等待
- 某个 Agent 具体拿到了什么任务
- 它最后返回了什么结果
这对长任务很重要。
以前你只能相信"它正在忙"。
现在你至少能看见"它到底在忙什么"。
第二类适合 workflows 的活:把一次经验沉淀成流程
做完 Java 虚拟线程研究报告后,我继续测试:
能不能基于刚才的报告,再生成一个实验项目设计 workflow?
我在提示词里带上了 workflow。
关键词变色后,它就开始创建新的 workflow。
进入详情后,可以看到新的工作流阶段。
继续保存 workflow 后,项目路径下多了两个 JS 脚本文件。
我打开其中一个比较简单的脚本看了一下。
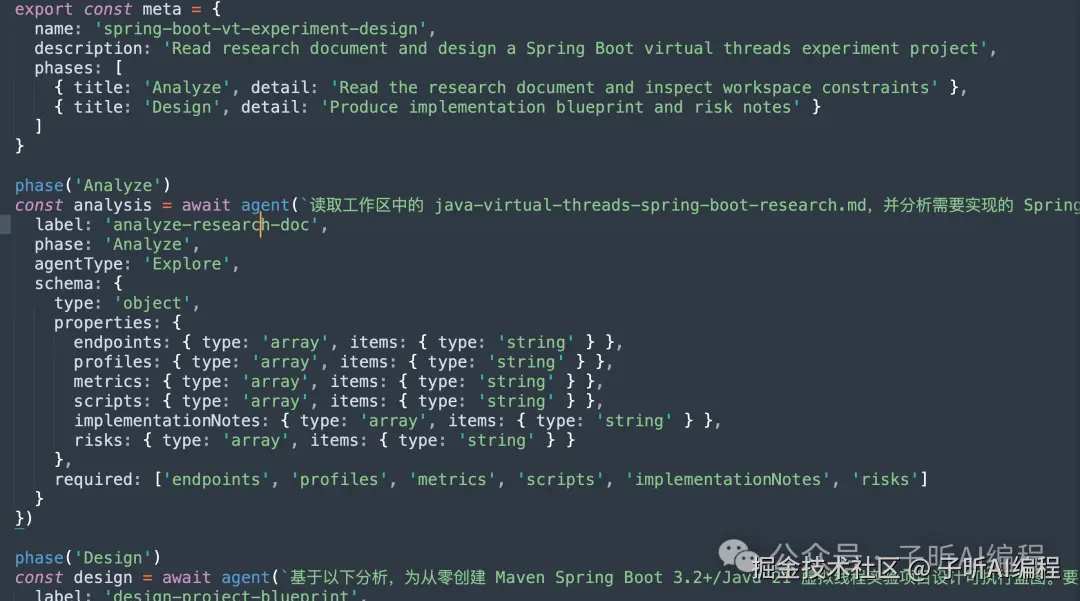
大概结构是这样的:
php
phase('Analyze')
const analysis = await agent(`读取研究文档,并分析要实现的 Spring Boot 虚拟线程实验项目需求`, {
label: 'analyze-research-doc',
phase: 'Analyze',
agentType: 'Explore',
schema: {
type: 'object',
properties: {
endpoints: { type: 'array', items: { type: 'string' } },
profiles: { type: 'array', items: { type: 'string' } },
metrics: { type: 'array', items: { type: 'string' } },
scripts: { type: 'array', items: { type: 'string' } },
implementationNotes: { type: 'array', items: { type: 'string' } },
risks: { type: 'array', items: { type: 'string' } }
}
}
})
phase('Design')
const design = await agent(`基于上面的分析,设计一个可执行的项目蓝图`, {
label: 'design-project-blueprint',
phase: 'Design'
})
return { analysis, design }这个脚本很有意思。
第一阶段叫 Analyze。
它会派一个 Agent 去读刚才的研究报告,提炼端点、profiles、指标、脚本、实现建议和风险。
第二阶段叫 Design。
它会基于第一阶段的 analysis 变量,继续派另一个 Agent 设计项目蓝图。
注意这里的关键:
analysis 不是塞进主对话里。
它是 workflow 脚本里的变量。
第二个 Agent 可以直接使用这个变量继续工作。
最后再统一 return { analysis, design }。
这就是我前面说的,Dynamic Workflows 真正重要的是:
中间结果被脚本接住了。
不是每一步都往主对话里倒。
所以它很适合"步骤多、中间产物多、最后只要一个结果"的任务。
真正值钱的是:它可以保存成项目资产
进入 /workflows 后,可以按 s 保存 workflow。
默认保存到项目 scope。
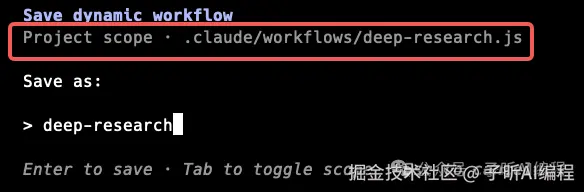
按 Tab 可以切换保存位置。
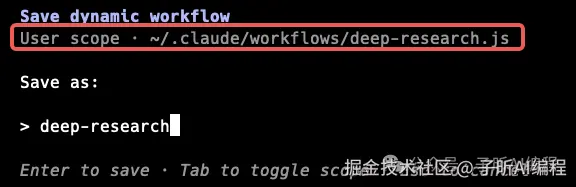
项目 scope 适合团队共享。
比如某个仓库里经常要做发布前检查,就可以保存一个项目 workflow。
个人 scope 适合自己跨项目复用。
比如你经常做技术调研、代码审计、迁移评估,就可以保存成自己的 workflow。
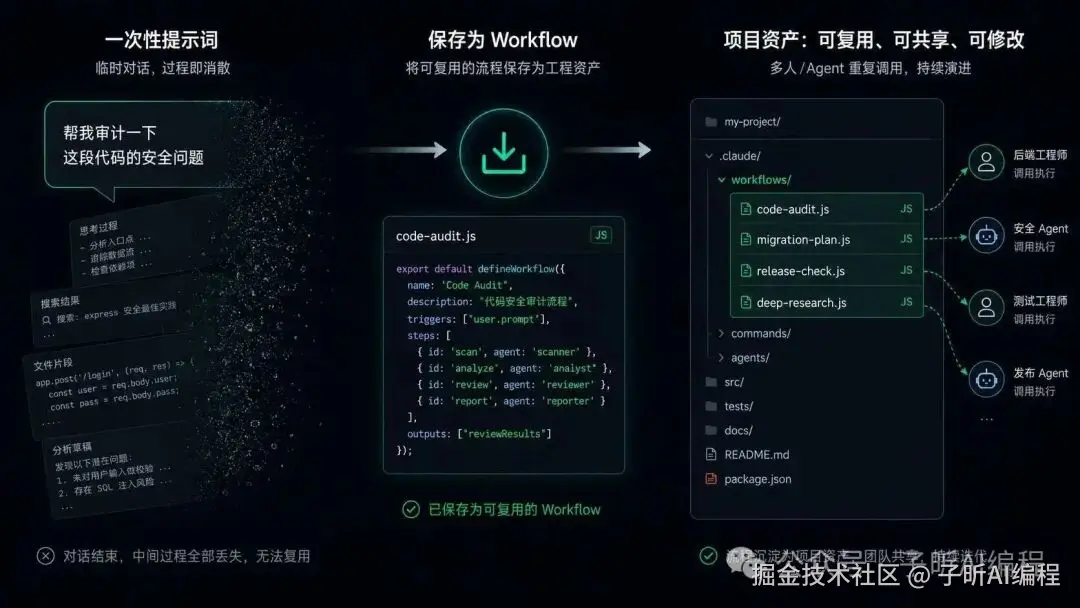
这一步很关键。
因为 prompt 最大的问题是一次性的。
你这次写得很好,下次可能就忘了怎么写。
而 workflow 保存下来之后,它更像一个可复用脚本。
以后可以直接运行,也可以打开改。
这就从"对话技巧"变成了"流程资产"。
到底该用来干什么?
回到标题。
Claude Code 新出的 Dynamic Workflows,到底该用来干什么?
我的判断是:
用来处理那些主对话扛不住的重活。
什么叫主对话扛不住?
第一,中间过程太多。
比如调研一个复杂技术主题,需要查很多资料,分很多角度,还要互相校验。
第二,任务可以拆。
比如代码库审计,可以按模块拆;迁移评估,可以按入口、数据、任务、测试拆;实验设计,可以按需求、架构、配置、脚本、验证拆。
第三,结果需要复核。
比如安全审计、性能风险、生产迁移方案,都不适合单 Agent 一遍过。
第四,流程值得复用。
比如每个项目都要做发布前检查,每次大改动都要做风险扫描,每次技术选型都要做资料交叉验证。
这种任务就适合 workflows。
反过来,这些任务不适合:
- 改一个小 bug
- 问一个小问题
- 调整一段文案
- 改一个具体函数
- 需要你每一步都拍板的任务
一个简单判断标准:
任务越能拆、过程越长、结果越需要校验、流程越值得复用,越适合 Dynamic Workflows。
最后
所以 Dynamic Workflows 到底该用来干什么?
我的答案很简单:
别拿它处理小活。
拿它处理那些上下文会爆、步骤会乱、结果需要复核、流程还值得下次复用的重活。
小活别用 workflows。
重活别再手搓提示词。

这也是我这次实测之后,觉得它值得单独写一篇的原因。
更多内容,欢迎关注微信公众号【子昕AI编程】~