查壳分析
按例查壳,Python Nuitka打包的,所以可以提取Python字节码。
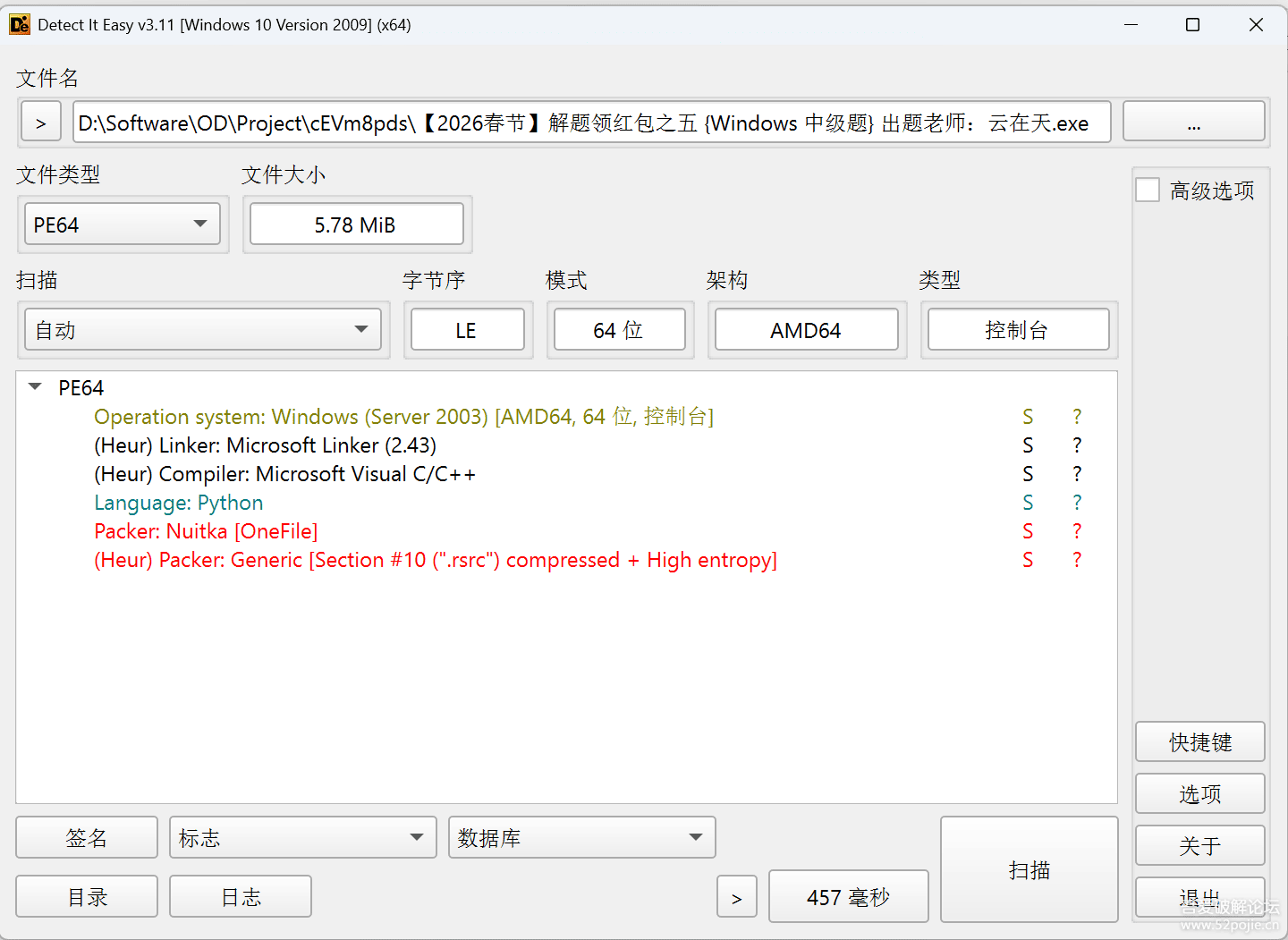
nuitka-extractor.exe 提取工具可以提取Python Bytecode
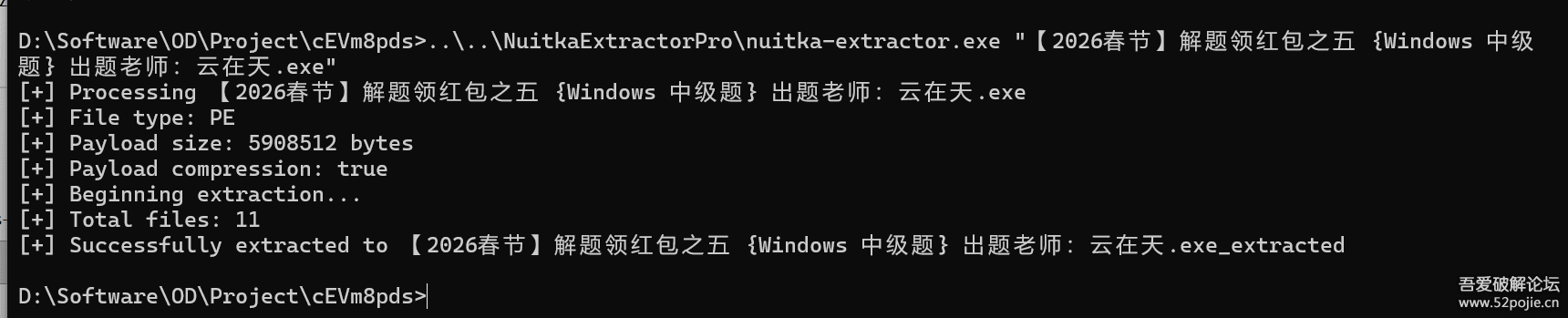
可以看到crack_me dll
基本都是Python处理,没什么头绪处理,然后看到run code,推测是相关的处理逻辑。

Python Bytecode解析
然后双击进去该代码区域,看到了对Bytecode的解析函数,
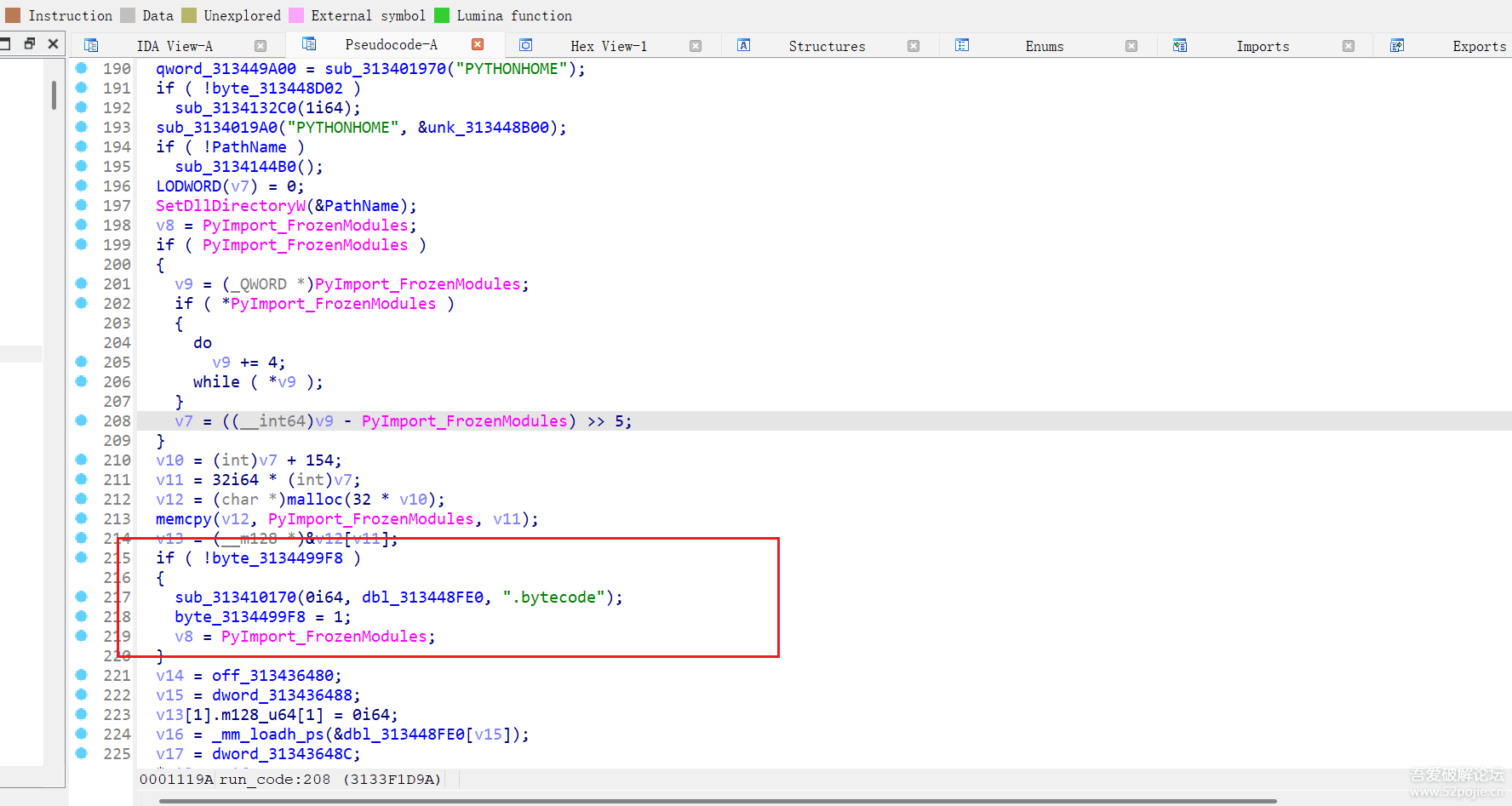
提取资源id为3的数据,然后进行解析
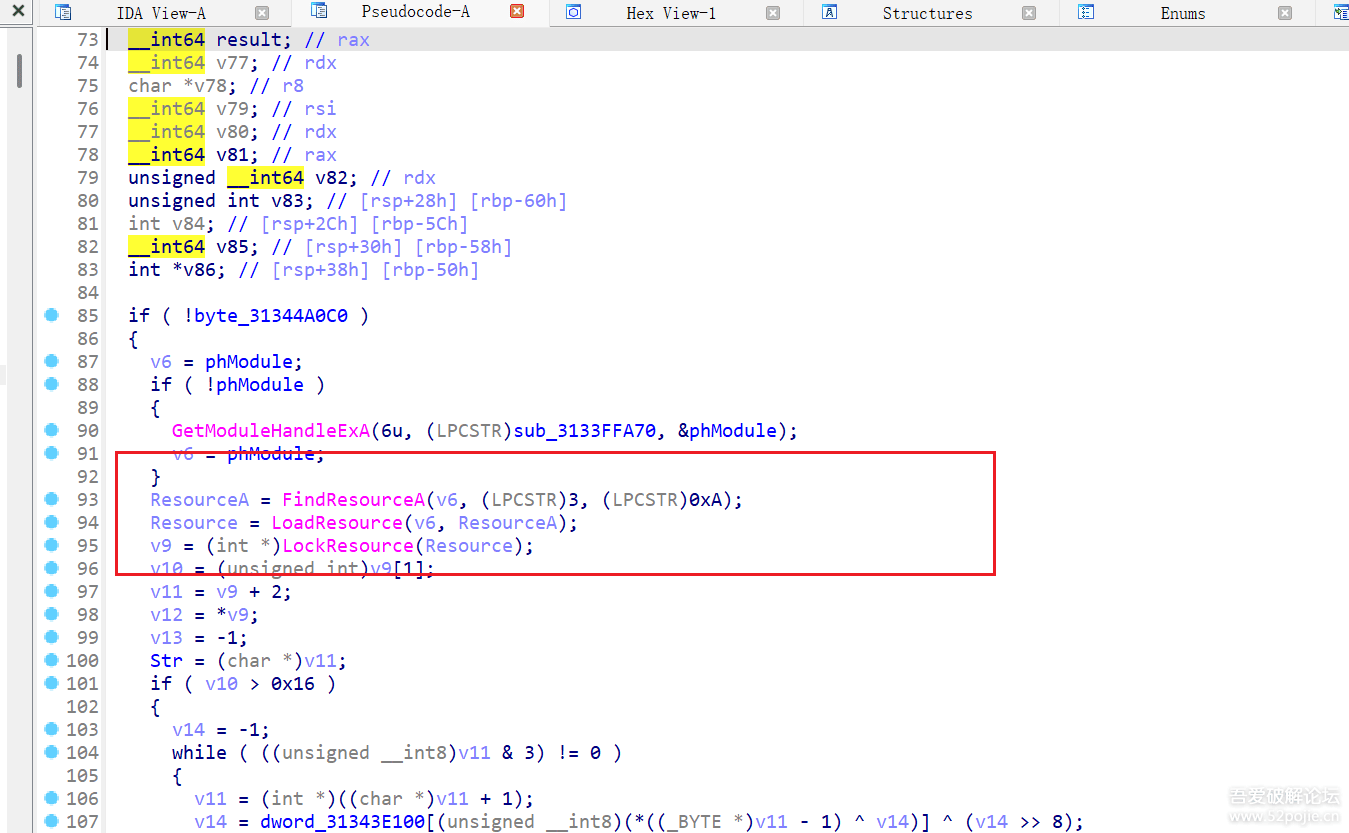
然后对id为3的资源进行解析,解析流程如下:
c
if ( (_WORD)v77 )
{
do
{
v80 = a2;
a2 += 8i64;
result = sub_31340ECE0(a1, v80, v78);
v78 = (char *)result;
}
while ( a2 != v79 );
}然后可以sub_31340ECE0 该函数对Bytecode进行了解析,通过大量的switch case处理了各种情况,这里可以使用AI生成相应的Python脚本。提取id为3的资源数据,可以使用Resource Hacker进行提取,保存为bin,然后利用Python进行解析。
python
import struct
import sys
from typing import Any, Dict, List, Optional, Tuple, Union
import io
class NuitkaBinaryParser:
"""解析Nuitka编译的二进制bin文件"""
def __init__(self, data: bytes):
self.data = data
self.pos = 0
self.result_stack = [] # 用于p类型引用
self.global_objects: Dict[int, Any] = {} # 全局对象缓存
# 预定义对象(模拟C代码中的Py_NoneStruct等)
self.Py_None = None
self.Py_True = True
self.Py_False = False
self.Py_Ellipsis = Ellipsis
self.Py_NotImplemented = NotImplemented
# 模拟C代码中的全局字典(qword_31344Axxx)
self.global_dicts = {
'integers': {}, # qword_31344A108
'bytes': {}, # qword_31344A0F8
'floats': {}, # qword_31344A100
'frozenset': None, # qword_31344A120
'set': None, # qword_31344A118
'list': None, # qword_31344A130
'tuple': None, # qword_31344A138
'module_cache': {}, # qword_31344A128?
}
# 预定义浮点数常量(Z类型)
self.predefined_floats: List[Optional[float]] = [None] * 256
# 运行时状态(模拟PyRuntime)
self.PyRuntime = {
'refcounts': {}, # 引用计数
'thread_state': None, # 线程状态
}
def read_uint8(self) -> int:
"""读取1字节无符号整数"""
if self.pos >= len(self.data):
raise EOFError("Unexpected end of data")
val = self.data[self.pos]
self.pos += 1
return val
def read_uint16(self) -> int:
"""读取2字节无符号整数"""
if self.pos + 2 > len(self.data):
raise EOFError("Unexpected end of data")
val = struct.unpack('<H', self.data[self.pos:self.pos + 2])[0]
self.pos += 2
return val
def read_uint32(self) -> int:
"""读取4字节无符号整数"""
if self.pos + 4 > len(self.data):
raise EOFError("Unexpected end of data")
val = struct.unpack('<I', self.data[self.pos:self.pos + 4])[0]
self.pos += 4
return val
def read_uint64(self) -> int:
"""读取8字节无符号整数"""
if self.pos + 8 > len(self.data):
raise EOFError("Unexpected end of data")
val = struct.unpack('<Q', self.data[self.pos:self.pos + 8])[0]
self.pos += 8
return val
def read_leb128(self) -> int:
"""读取LEB128编码的无符号整数"""
result = 0
shift = 0
while True:
byte_val = self.read_uint8()
result |= (byte_val & 0x7F) << shift
if not (byte_val & 0x80):
break
shift += 7
return result
def read_c_string(self) -> bytes:
"""读取以空字节结尾的C风格字符串"""
start = self.pos
while self.pos < len(self.data) and self.data[self.pos] != 0:
self.pos += 1
if self.pos >= len(self.data):
raise EOFError("Unexpected end of data while reading C string")
result = self.data[start:self.pos]
self.pos += 1 # 跳过null
return result
def read_bytes(self, length: int) -> bytes:
"""读取指定长度的字节"""
if self.pos + length > len(self.data):
raise EOFError(f"Unexpected end of data, need {length} bytes")
result = self.data[self.pos:self.pos + length]
self.pos += length
return result
def read_double(self) -> float:
"""读取8字节双精度浮点数"""
return struct.unpack('<d', self.read_bytes(8))[0]
def parse_blob(self) -> Any:
"""解析一个blob对象 - 对应 sub_31340ECE0 函数"""
if self.pos >= len(self.data):
return None
# 保存当前位置用于调试
start_pos = self.pos
# 读取类型字节
type_byte = self.read_uint8()
type_char = chr(type_byte)
# 根据类型进行解析
if type_char == '.':
# 错误情况
# raise ValueError("Missing blob values")
obj = ""
pass
elif type_char == ':':
# 切片对象 - 读取3个对象
items = []
for _ in range(3):
items.append(self.parse_blob())
# 模拟 PySlice_Type 创建
obj = slice(items[0], items[1], items[2])
# TO DO: 处理引用计数和线程状态
# v160 = *(_QWORD *)(a1 + 16); // 当前线程状态
# 复杂的引用计数处理...
elif type_char == ';':
# range对象 - 读取3个对象
items = []
for _ in range(3):
items.append(self.parse_blob())
# 模拟 PyRange_Type 创建
if all(item is not None for item in items):
obj = range(items[0], items[1], items[2])
else:
obj = None
elif type_char == 'A':
# 泛型别名 - 读取2个对象
obj1 = self.parse_blob()
obj2 = self.parse_blob()
# TO DO: Py_GenericAlias
obj = f"<GENERIC_ALIAS {obj1}[{obj2}]>"
elif type_char == 'B':
# 字节数组
length = self.read_leb128()
data = self.read_bytes(length)
obj = bytearray(data)
elif type_char == 'C':
# 代码对象 - 复杂结构
flags = self.read_leb128()
# 读取基本字段
pos = self.pos
# 根据C代码解析
if flags & 0x80: # 检查是否有额外标志
# TO DO: 解析复杂代码对象
pass
obj1 = self.parse_blob() # 第一个对象
# 读取更多字段...
obj2 = self.parse_blob()
# TO DO: 完整解析PyCodeObject
obj = f"<CODE_OBJECT flags={flags}>"
elif type_char == 'D':
# 字典
count = self.read_leb128()
d = {}
if count > 0:
# 先读取所有key
keys = []
for _ in range(count):
keys.append(self.parse_blob())
# 再读取所有value
values = []
for _ in range(count):
values.append(self.parse_blob())
# 组合成字典
for k, v in zip(keys, values):
d[k] = v
obj = d
elif type_char == 'E':
# 跳过字符串
while self.pos < len(self.data) and self.data[self.pos] != 0:
self.pos += 1
obj = None
elif type_char == 'F':
# False
obj = False
elif type_char in ('G', 'g'):
# 特殊处理 - 读取计数
count = self.read_leb128()
# TO DO: 处理G/g类型
if type_char == 'G':
obj = f"<G_TYPE:{count}>"
else:
obj = f"<g_TYPE:{count}>"
elif type_char == 'H':
# 位运算操作
obj1 = self.parse_blob()
obj2 = self.parse_blob()
if isinstance(obj1, int) and isinstance(obj2, int):
obj = obj1 | obj2
else:
obj = f"<OR:{obj1}|{obj2}>"
elif type_char == 'J':
# 复数 - 读取两个双精度浮点数
real = self.read_double()
imag = self.read_double()
obj = complex(real, imag)
elif type_char == 'L':
# 列表
count = self.read_leb128()
items = []
for _ in range(count):
items.append(self.parse_blob())
obj = items
elif type_char == 'M':
# 匿名对象
anon_type = self.read_uint8()
if anon_type == 0:
obj = None
elif anon_type == 1:
obj = Ellipsis
elif anon_type == 2:
obj = NotImplemented
elif anon_type == 3:
obj = "<PyFunction_Type>"
elif anon_type == 4:
obj = "<PyGen_Type>"
elif anon_type == 5:
obj = "<PyCFunction_Type>"
elif anon_type == 6:
obj = "<PyCode_Type>"
elif anon_type == 7:
obj = "<PyModule_Type>"
elif anon_type == 10:
obj = "<qword_3134488C8>"
else:
obj = f"<ANON_TYPE_{anon_type}>"
elif type_char == 'O':
# 动态属性获取
attr_name = self.read_c_string().decode('utf-8', errors='replace')
# TO DO: PyObject_GetAttrString
obj = f"<DYNAMIC_ATTR_GET:{attr_name}>"
elif type_char in ('P', 'S'):
# 集合/冻结集合
count = self.read_leb128()
items = []
for _ in range(count):
items.append(self.parse_blob())
if type_char == 'S':
obj = set(items)
else: # 'P'
obj = frozenset(items)
elif type_char == 'Q':
# 特殊值
special_type = self.read_uint8()
if special_type == 0:
obj = Ellipsis
elif special_type == 1:
obj = NotImplemented
elif special_type == 2:
obj = "<SELF_REFERENCE>"
else:
obj = f"<SPECIAL_VALUE_{special_type}>"
elif type_char == 'T':
# 元组
count = self.read_leb128()
items = []
for _ in range(count):
items.append(self.parse_blob())
obj = tuple(items)
elif type_char == 'X':
# 跳过指定长度
skip_length = self.read_leb128()
self.pos += skip_length
return None
elif type_char == 'Z':
# 预定义浮点数
index = self.read_uint8()
# TO DO: 从预定义浮点数表中获取
if index < len(self.predefined_floats):
if self.predefined_floats[index] is None:
# 根据C代码中的case创建不同浮点数
if index == 0:
self.predefined_floats[index] = 0.0
elif index == 1:
self.predefined_floats[index] = 1.0
elif index == 2:
self.predefined_floats[index] = -1.0
elif index == 3:
self.predefined_floats[index] = 2.0
elif index == 4:
self.predefined_floats[index] = -2.0
elif index == 5:
self.predefined_floats[index] = 0.5
else:
self.predefined_floats[index] = float(index)
obj = self.predefined_floats[index]
else:
obj = f"<PREDEFINED_FLOAT_INDEX_{index}>"
elif type_char in ('a', 'u'):
# UTF-8字符串
s_bytes = self.read_c_string()
obj = s_bytes.decode('utf-8', errors='replace')
if type_char == 'a': # interned
obj = sys.intern(obj)
elif type_char == 'b':
# 字节串
length = self.read_leb128()
data = self.read_bytes(length)
# 缓存到全局字典
if data not in self.global_dicts['bytes']:
self.global_dicts['bytes'][data] = data
obj = self.global_dicts['bytes'][data]
elif type_char == 'c':
# 字节串 (interned)
s_bytes = self.read_c_string()
if len(s_bytes) > 1:
if s_bytes not in self.global_dicts['bytes']:
self.global_dicts['bytes'][s_bytes] = s_bytes
obj = self.global_dicts['bytes'][s_bytes]
else:
obj = s_bytes
elif type_char == 'd':
# 预定义浮点数索引
index = self.read_uint8()
# TO DO: 从浮点数常量表中获取
obj = f"<PREDEFINED_FLOAT_INDEX_{index}>"
elif type_char == 'f':
# 双精度浮点数
value = self.read_double()
# 缓存浮点数
if value not in self.global_dicts['floats']:
self.global_dicts['floats'][value] = value
obj = self.global_dicts['floats'][value]
elif type_char == 'j':
# 复数 - 读取16字节
real = self.read_double()
imag = self.read_double()
obj = complex(real, imag)
elif type_char in ('l', 'q'):
# 有符号整数
value = self.read_leb128()
if type_char == 'q':
value = -value
# 缓存整数
if value not in self.global_dicts['integers']:
self.global_dicts['integers'][value] = value
obj = self.global_dicts['integers'][value]
elif type_char == 'n':
# None
obj = None
elif type_char == 'p':
# 引用前面的对象
if self.result_stack:
obj = self.result_stack[-1]
else:
obj = "<STACK_REFERENCE>"
elif type_char == 's':
# interned字符串
length = self.read_leb128()
s_bytes = self.read_bytes(length)
obj = sys.intern(s_bytes.decode('utf-8', errors='replace'))
elif type_char == 't':
# True
obj = True
elif type_char == 'v':
# 长度可变的UTF-8字符串
length = self.read_leb128()
s_bytes = self.read_bytes(length)
obj = s_bytes.decode('utf-8', errors='replace')
elif type_char == 'w':
# 单字符字符串
char_bytes = self.read_bytes(1)
obj = char_bytes.decode('utf-8', errors='replace')
else:
# 未知类型
obj = f"<UNKNOWN_TYPE_{type_char}>"
print(f"Warning: Unknown type '{type_char}' (0x{type_byte:02X}) at {start_pos}")
# 保存到结果栈
if obj is not None:
self.result_stack.append(obj)
return obj
def parse_blob_with_count(self, count: int) -> List[Any]:
"""解析指定数量的blob对象"""
results = []
for _ in range(count):
obj = self.parse_blob()
if obj is not None:
results.append(obj)
return results
def parse_nuitka_bin_file(filepath: str) -> Optional[List[Any]]:
"""解析Nuitka编译的bin文件"""
try:
with open(filepath, 'rb') as f:
data = f.read()
except Exception as e:
print(f"Error reading file: {e}")
return None
print(f"File size: {len(data)} bytes")
print("-" * 60)
# 读取文件头
if len(data) < 8:
print("Error: File too small")
return None
pos = 0
hash_val = struct.unpack('<I', data[0:4])[0]
total_size = struct.unpack('<I', data[4:8])[0]
pos = 8
print(f"Header: hash=0x{hash_val:08X}, total_size={total_size} bytes")
# 遍历所有blob
while pos < len(data) and pos < total_size:
# 读取blob名称
name_start = pos
while pos < len(data) and data[pos] != 0:
pos += 1
if pos >= len(data):
break
blob_name = data[name_start:pos].decode('utf-8', errors='replace')
pos += 1
# 读取blob大小和数量
if pos + 6 > len(data):
break
blob_size = struct.unpack('<I', data[pos:pos + 4])[0]
blob_count = struct.unpack('<H', data[pos + 4:pos + 6])[0]
pos += 6
print(f"\nFound blob: '{blob_name}' at {name_start}")
print(f" Size: {blob_size}, Count: {blob_count}")
if blob_name == "__main__":
print(f"\n{'=' * 60}")
print(f"Decoding '__main__' blob...")
print(f"{'=' * 60}")
# 解析blob数据
blob_data = data[pos:pos + blob_size - 2]
parser = NuitkaBinaryParser(blob_data)
results = parser.parse_blob_with_count(blob_count)
# 输出结果
print(f"\nDecoded {len(results)} objects:")
print(f"{'-' * 60}")
for i, obj in enumerate(results):
if isinstance(obj, bytes):
ascii_str = ''.join(chr(b) if 32 <= b < 127 else '.' for b in obj[:50])
if len(obj) > 50:
ascii_str += "..."
print(f"{i:3d}: {obj!r} (ASCII: {ascii_str})")
else:
print(f"{i:3d}: {obj!r}")
print(f"{'-' * 60}")
return results
else:
# 跳过其他blob
print(f" Skipping blob '{blob_name}'")
pos += blob_size - 2
return None
def main():
"""主函数"""
if len(sys.argv) < 2:
print("Usage: python nuitka_parser.py <main.bin>")
return
filepath = sys.argv[1]
results = parse_nuitka_bin_file(filepath)
if results:
print(f"\nSuccessfully decoded {len(results)} objects from __main__ blob")
# 特别处理:查找加密数据
if results and isinstance(results[0], list):
print(f"\n{'=' * 60}")
print("Encrypted data parts:")
encrypted_parts = []
for i, item in enumerate(results[0]):
if isinstance(item, bytes):
print(f" Part {i}: {item!r} (len={len(item)})")
encrypted_parts.append(item)
else:
print(f" Part {i}: {item}")
# 尝试解密
if encrypted_parts:
encrypted_data = b''.join(encrypted_parts)
print(f"\nTotal encrypted data length: {len(encrypted_data)} bytes")
# TO DO: 查找密钥(可能在results中)
key = 81 # 根据之前分析
decrypted = bytes([b ^ key for b in encrypted_data])
try:
flag = decrypted.decode('ascii')
print(f"\nPotential flag (key={key}): {flag}")
except:
print(f"\nDecrypted bytes (hex): {decrypted.hex()}")
else:
print("Failed to decode __main__ blob")
if __name__ == "__main__":
main()[/mw_shl_code]运行的结果分析
C:\Users\WNN\PyCharmMiscProject\.venv\Scripts\python.exe C:\Users\WNN\PyCharmMiscProject\555.py "D:\Software\OD\Project\cEVm8pds\【2026春节】解题领红包之五 {Windows 中级题} 出题老师:云在天.exe_extracted\main.bin"File size: 5635506 bytes
------------------------------------------------------------
Header: hash=0xDCAA9D4E, total_size=5635498 bytes
Found blob: '.bytecode' at 8
Size: 5633009, Count: 323
Skipping blob '.bytecode'
Found blob: '' at 5633031
Size: 878, Count: 107
Skipping blob ''
Found blob: '__main__' at 5633914
Size: 1579, Count: 83
============================================================
Decoding '__main__' blob...
============================================================
Warning: Unknown type '¬' (0xAC) at 323
Warning: Unknown type 'Ñ' (0xD1) at 324
Warning: Unknown type '•' (0x91) at 325
Warning: Unknown type '•' (0x01) at 326
Warning: Unknown type '•' (0x01) at 329
Warning: Unknown type '•' (0x81) at 330
Warning: Unknown type 'Þ' (0xDE) at 331
Warning: Unknown type '·' (0xB7) at 332
Warning: Unknown type 'Þ' (0xDE) at 333
Warning: Unknown type '•' (0x02) at 334
Decoded 83 objects:
------------------------------------------------------------
0: [b'dc!a;`b', '<PREDEFINED_FLOAT_INDEX_17>', b'cacg', '<PREDEFINED_FLOAT_INDEX_47>', b'\x19e!!(', '<PREDEFINED_FLOAT_INDEX_14>', b'\x1fb&', '<PREDEFINED_FLOAT_INDEX_14>', b'\x08be#', b'ppp']
1: '_parts'
2: 81
3: '_key'
4: 30
5: '_total_len'
6: '解密单个字符'
7: 'current'
8: '_decrypt_char'
9: '获取指定位置的字符'
10: 'self'
11: '_get_char_at_position'
12: '验证用户输入'
13: 'total'
14: '计算校验和'
15: 'flag\x00achecksum\x00u获取目标校验和\x00ahashlib\x00asha256\x00aencode\x00ahexdigest\x00:nl\x08nl\x10u哈希函数\x00l�'
16: '<UNKNOWN_TYPE_¬>'
17: '<UNKNOWN_TYPE_Ñ>'
18: '<UNKNOWN_TYPE_\x91>'
19: '<UNKNOWN_TYPE_\x01>'
20: '<g_TYPE:2>'
21: '<UNKNOWN_TYPE_\x01>'
22: '<UNKNOWN_TYPE_\x81>'
23: '<UNKNOWN_TYPE_Þ>'
24: '<UNKNOWN_TYPE_·>'
25: '<UNKNOWN_TYPE_Þ>'
26: '<UNKNOWN_TYPE_\x02>'
27: 1380994890
28: 'hash_input'
29: '假检查'
30: 'print'
31: ('==================================================',)
32: (' CrackMe Challenge - Binary Edition',)
33: ('Keywords: 52pojie, 2026, Happy New Year',)
34: ('Hint: 1337 5p34k & 5ymb0l5!',)
35: (' Try to decompile this in IDA!',)
36: ('--------------------------------------------------',)
37: 'CrackMeCore'
38: '\n[?] Enter the password: '
39: 'fake_check'
40: ('\n[!] Close, but not quite there...',)
41: '\nPress Enter to exit...'
42: 'verify'
43: 'get_target_checksum'
44: ('\n==================================================',)
45: (' *** SUCCESS! ***',)
46: ('[+] L33T H4X0R!',)
47: '[+] Your answer: '
48: '\n[!] Checksum mismatch: '
49: ' != '
50: ('\n[X] Access Denied!',)
51: ('[X] Wrong password!',)
52: '主函数'
53: '__doc__'
54: '__file__'
55: '__cached__'
56: '__annotations__'
57: 'sys'
58: '__main__'
59: '__module__'
60: '核心验证类 - 将被编译成二进制'
61: '__qualname__'
62: '__init__'
63: 'CrackMeCore.__init__'
64: 'CrackMeCore._decrypt_char'
65: 'CrackMeCore._get_char_at_position'
66: 'CrackMeCore.verify'
67: 'CrackMeCore.checksum'
68: 'CrackMeCore.get_target_checksum'
69: 'main'
70: ('\n\n[!] Interrupted',)
71: 'crackme_hard.py'
72: '<module>'
73: ('self',)
74: ('self', 'part_idx', 'char_idx', 'encrypted_byte')
75: ('self', 'pos', 'current', 'part_idx', 'part')
76: ('self', 's', 'total', 'i', 'c')
77: ('user_input', 'fake_hashes', 'user_hash')
78: ('self', 'flag', 'i')
79: ('s',)
80: ('core', 'user_input', 'cs', 'target')
81: ('self', 'user_input', 'i', 'expected')
82: ''
------------------------------------------------------------
Successfully decoded 83 objects from __main__ blob
============================================================
Encrypted data parts:
Part 0: b'dc!a;`b' (len=7)
Part 1: <PREDEFINED_FLOAT_INDEX_17>
Part 2: b'cacg' (len=4)
Part 3: <PREDEFINED_FLOAT_INDEX_47>
Part 4: b'\x19e!!(' (len=5)
Part 5: <PREDEFINED_FLOAT_INDEX_14>
Part 6: b'\x1fb&' (len=3)
Part 7: <PREDEFINED_FLOAT_INDEX_14>
Part 8: b'\x08be#' (len=4)
Part 9: b'ppp' (len=3)
Total encrypted data length: 26 bytes
Potential flag (key=81): 52p0j132026H4ppyN3wY34r!!!
进程已结束,退出代码为 0[/mw_shl_code]关键信息如下:字符串如下,key :81,长度为30
b'dc!a;`b', '<PREDEFINED_FLOAT_INDEX_17>', b'cacg', '<PREDEFINED_FLOAT_INDEX_47>', b'\x19e!!(', '<PREDEFINED_FLOAT_INDEX_14>', b'\x1fb&', '<PREDEFINED_FLOAT_INDEX_14>', b'\x08be#', b'ppp']
1: '_parts'
2: 81
3: '_key'
4: 30让AI解析Python的这段部分字符串,可以生成完整的Python代码,
python
import hashlib
import sys
class CrackMeCore:
"""核心验证类 - 将被编译成二进制"""
def __init__(self):
# 加密的数据部分
self._parts = [
b'dc!a;`b', # 第0部分
b'\x11', # 浮点数占位符
b'cacg', # 第2部分
b'\x2F', # 浮点数占位符
b'\x19e!!(', # 第4部分
b'\x0E', # 浮点数占位符
b'\x1fb&', # 第6部分
b'\x0E', # 浮点数占位符
b'\x08be#', # 第8部分
b'ppp' # 第9部分
]
self._key = 81 # 解密密钥
self._total_len = 30 # 总长度
def _get_char_at_position(self, pos):
"""获取指定位置的字符(加密数据)"""
current = 0
for part in self._parts:
# 跳过浮点数占位符
# if not isinstance(part, bytes):
# continue
part_len = len(part)
if current + part_len > pos:
# 找到目标位置
char_idx = pos - current
encrypted_byte = part[char_idx]
return encrypted_byte
current += part_len
return None
def _decrypt_char(self, encrypted_byte):
"""解密单个字符"""
# 使用密钥进行异或解密
return encrypted_byte ^ self._key
def checksum(self, s):
"""计算校验和"""
total = 0
for i, c in enumerate(s):
# 使用位置和字符值计算校验和
total += (i + 1) * ord(c)
return total
def get_target_checksum(self):
"""获取目标校验和"""
flag = ""
for i in range(self._total_len):
encrypted_byte = self._get_char_at_position(i)
if encrypted_byte is not None:
decrypted_char = self._decrypt_char(encrypted_byte)
flag += chr(decrypted_char)
# 计算目标校验和
target = self.checksum(flag)
return target, flag
def leet_to_text(leet_str):
"""将Leet语转换为正常文本"""
leet_map = {
'1': 'L', '3': 'E', '4': 'A', '5': 'S', '0': 'O',
'7': 'T', '8': 'B', '9': 'G', '2': 'Z', '6': 'G',
# 小写版本
'l': 'l', 'e': 'e', 'a': 'a', 's': 's', 'o': 'o',
't': 't', 'b': 'b', 'g': 'g', 'z': 'z',
}
result = ""
for c in leet_str:
if c in leet_map:
result += leet_map[c]
else:
result += c
return result
def verify(self, user_input):
"""验证用户输入"""
# 假的验证(混淆用)
fake_hashes = [
hashlib.sha256("fake".encode()).hexdigest(),
hashlib.sha256("check".encode()).hexdigest()
]
user_hash = hashlib.sha256(user_input.encode()).hexdigest()
# 实际验证:计算用户输入的校验和
cs = self.checksum(user_input)
# 获取目标校验和和标志
target, flag = self.get_target_checksum()
# flag = self.leet_to_text(flag)
print(flag)
# 比较校验和
if cs == target:
return True, flag
else:
return False, None
def fake_check(self, user_input):
"""假检查函数(混淆用)"""
expected = "fake_flag_123"
if len(user_input) == len(expected):
return True
return False
def main():
"""主函数"""
try:
# 显示欢迎信息
print("==================================================")
print(" CrackMe Challenge - Binary Edition")
print("Keywords: 52pojie, 2026, Happy New Year")
print("Hint: 1337 5p34k & 5ymb0l5!")
print(" Try to decompile this in IDA!")
print("--------------------------------------------------")
# 创建核心验证对象
core = CrackMeCore()
# 获取用户输入
user_input = input("\n[?] Enter the password: ")
# 验证输入
success, flag = core.verify(user_input)
if success:
print("\n==================================================")
print(" *** SUCCESS! ***")
print("[+] L33T H4X0R!")
print(f"[+] Your answer: {flag}")
else:
print("\n[X] Access Denied!")
print("[X] Wrong password!")
# 获取目标校验和用于调试
target, flag = core.get_target_checksum()
user_cs = core.checksum(user_input)
print(f"\n[!] Checksum mismatch: {user_cs} != {target}")
except KeyboardInterrupt:
print("\n\n[!] Interrupted")
input("\nPress Enter to exit...")
if __name__ == "__main__":
# 模块级变量
__doc__ = None
__file__ = "crackme_hard.py"
__cached__ = None
__annotations__ = {}
# 主函数执行
main()然后运行,可以生成flag,
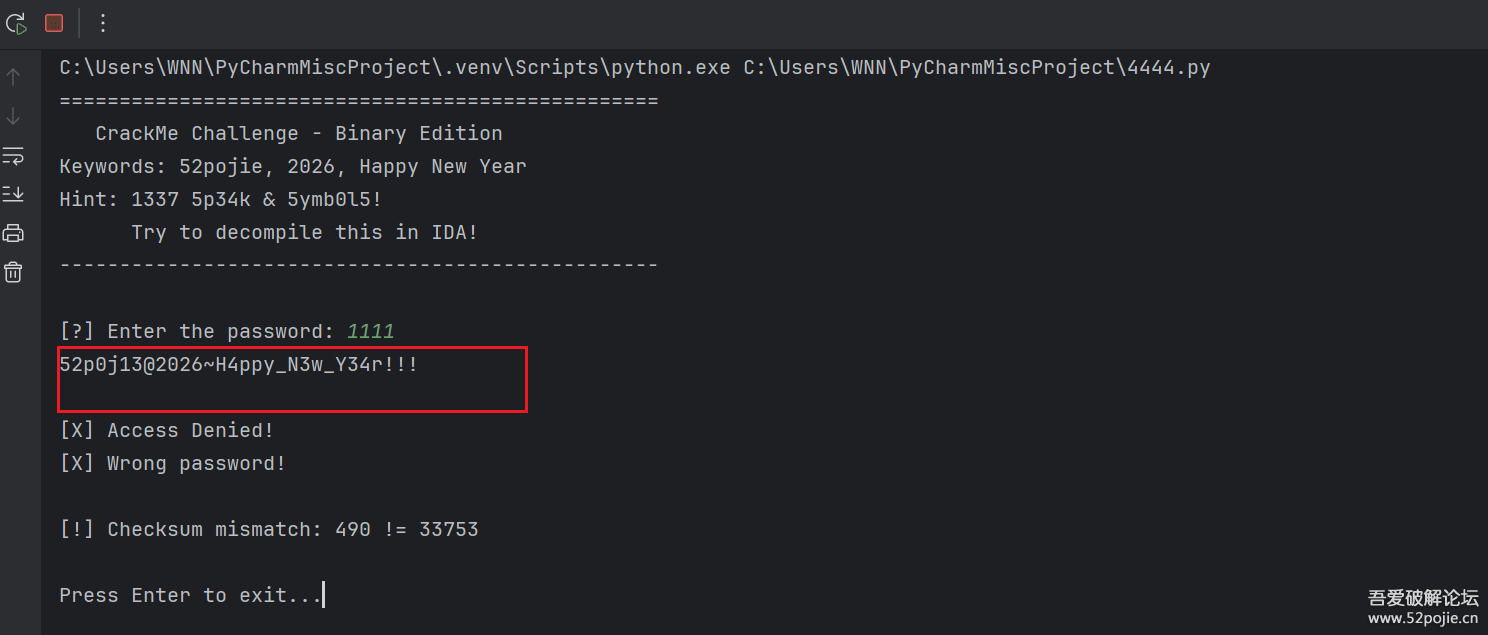
这里注意一个点,就是部分字符串没有解析出来,而是<PREDEFINED_FLOAT_INDEX_17>,<PREDEFINED_FLOAT_INDEX_47>,<PREDEFINED_FLOAT_INDEX_14>,<PREDEFINED_FLOAT_INDEX_14>
- 什么float index,17,14,14,没有理解,
- 所以刚开始就跳过了这些字符串,然后得到了如下字符串,
- 然后看起来是对的,实际不对, 少了那几个字符,
- 最后才知道,直接替换成对应的数字就可以
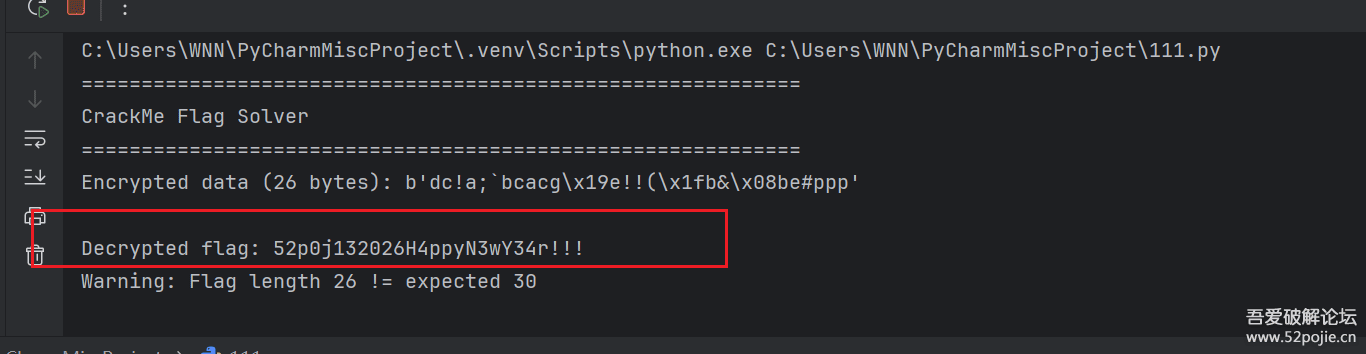
测试成功,
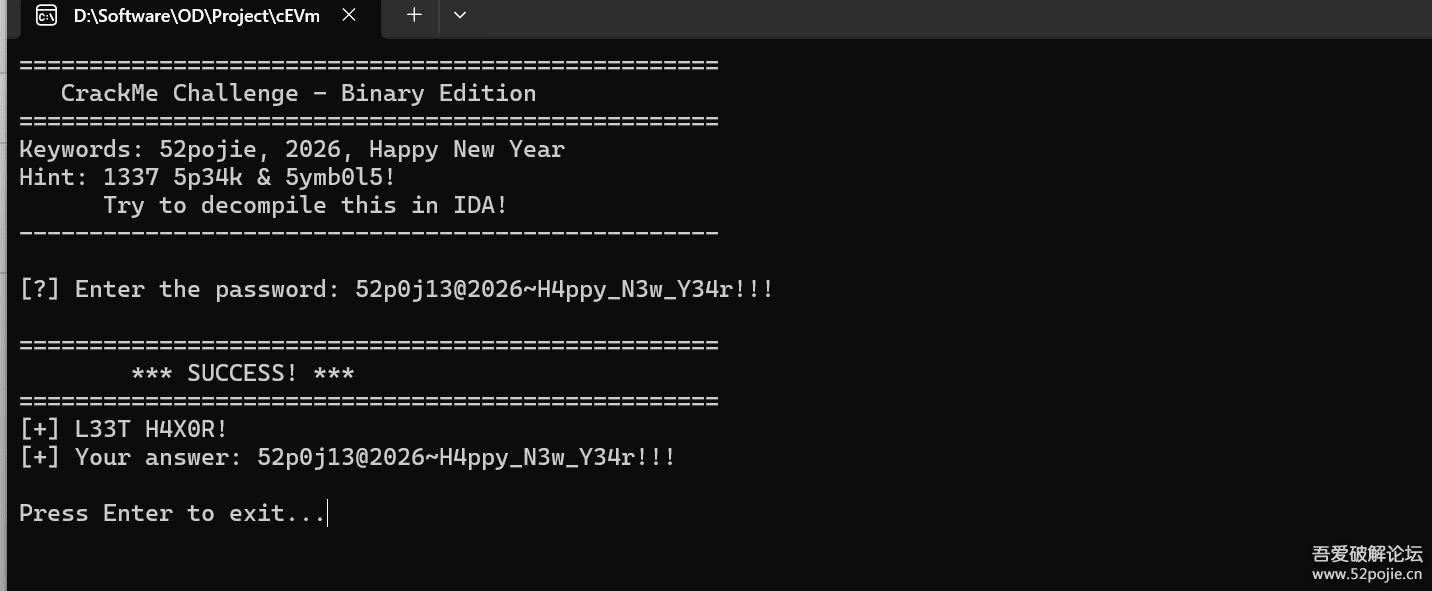
- 注意到,1337,5p34k,这是一种古老的加密方式,让数字代替字母,提示flag里面也是这样的情形,
- 如果加密flag为,flag{52pojie_2026_Happy_New_Year!_>w<},
- 那么替换后的flag可能为:fl4g{52p0j13_2026_H4ppy_N3w_Y34r!_>w<}做一个小小的改变,
+那么就和本题目的flag对应起来了。