一、概述
本期开发围绕法律文书智能摘要系统进行了两大核心升级:一是新增知识图谱功能模块,实现跨案件关联分析与可视化探索;二是对长程记忆系统进行分层优化,引入HNSW风格导航图,使记忆检索具备可解释性。同时完成了前端风格统一、文书对比逻辑整合、登录状态优化等多项工程改进。系统整体稳定性、用户体验与可解释性均有显著提升。
二、知识图谱功能模块
2.1 功能定位与价值
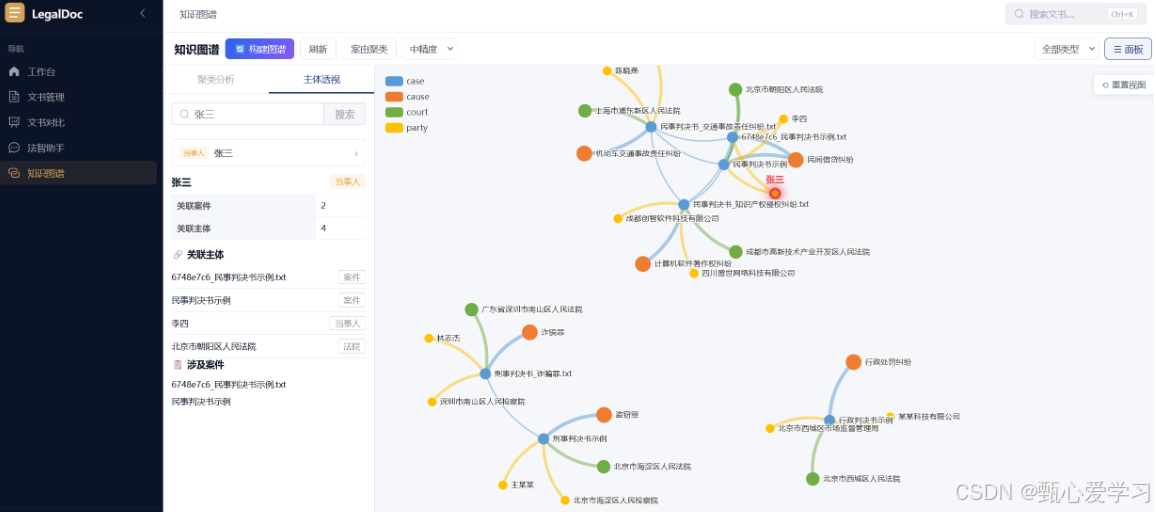
当文书数量达到几百份以上时,单份文书的卡片模式难以呈现宏观规律。知识图谱页面支持缩放、过滤、搜索,能够帮助用户发现跨案件的关联,适用于法学实证研究场景。
2.2 图数据结构
构建了包含四类节点、五种关系边的知识图谱:
节点类型:
-
🟠 案由节点(橙色)- 案件分类标识,如"民间借贷纠纷"
-
🔵 案件节点(蓝色)- 每份文书对应一个节点
-
🟢 法院节点(绿色)- 审理法院
-
🟡 当事人节点(黄色)- 原告与被告
关系边:
-
cause_rel:案件属于某案由(案件→案由) -
judge_rel:法院判决案件(法院→案件) -
party_rel:当事人参与案件(当事人→案件) -
similar:同案由案件相似(案件↔案件) -
cite:案件引用关系(案件→案件)
2.3 核心功能
-
案由聚类:自动将相似案例通过案由节点关联,支持低/中/高三档聚类精度
-
主体透视:点击特定当事人(如某保险公司),可查看其涉及的所有诉讼及常见抗辩理由
-
学术检索:通过图谱搜索,如"寻找所有涉及合同诈骗且证据不足被驳回的案件"
-
多维度过滤:支持按案由、法院、当事人等条件筛选
-
关键词搜索与节点高亮联动:搜索结果按类型显示不同颜色标签,点击后主画布对应节点高亮(红色边框+阴影)
-
图谱自由缩放:力导向布局参数优化,提供"重置视图"按钮
2.4 后端实现
新增以下核心模块:
-
graph_builder.py- 图谱构建引擎 -
clustering.py- 聚类算法(完全重写,基于案件类型分组) -
cause_extractor.py- 多策略案由提取(关键词匹配、文件名推断、行政案件处理、人名前缀清理) -
entity_extractor.py- 实体搜索扩展 -
knowledge_graph.py- API路由
案由提取已改为后台自动化流程,无需用户手动触发。
2.5 前端实现
新增页面与组件:
-
KnowledgeGraph.vue- 主页面 -
GraphCanvas.vue- 图谱画布(ECharts力导向图) -
ClusterPanel.vue- 聚类面板 -
EntityPanel.vue- 主体透视面板 -
graph.ts- API客户端
2.6 关键问题修复
| 问题 | 解决方案 |
|---|---|
| 数据库字段映射错误(no such column: meta_json) | 改用LEFT JOIN extracted_fields及正确列名 |
| sqlite3.Row不支持.get() | 改为下标访问 row["key"] or default |
| 节点过度集中超出屏幕 | 调整力导向参数(repulsion 1500,edgeLength 120,250,gravity 0.06);容器溢出隐藏 |
| 案由字段显示无意义文本 | 新建cause_extractor.py多策略提取;更新LLM提示词 |
| 聚类算法依赖不存在的similar边 | 重写算法,基于案件类型分组,支持三档精度 |
| 前端组件typeLabel未定义 | 添加映射函数,合并script块 |
| 搜索无引导、无加载反馈、无联动 | 添加空状态引导、spinner动画;后端搜索扩展至party+court+cause |
| 聚类按钮无响应、高亮无法清除 | 添加错误提示与loading状态;增加"清除筛选"UI(✕按钮) |
共修复13项关键问题。
三、长程记忆系统分层优化(A-Mem → 分层记忆图谱)
3.1 第一版存在的问题
初期接入A-Mem后,系统解决了"AI助手没有长期记忆"的问题,能够从对话中抽取知识点并召回。但法律场景中的记忆不是平铺的------用户画像、当前案件事实、历史案件经验、通用法律规则、全局办案流程的作用完全不同。单一向量检索池容易将语义相似但层级不合适的内容混入回答。
3.2 记忆分层设计
引入 memory_scope 字段,将记忆分为五类:
| 层级 | 含义 | 示例 |
|---|---|---|
| 用户画像 | 用户长期偏好和习惯 | "用户希望先给结论,再列证据清单" |
| 全局记忆 | 通用办案流程或系统级经验 | "先固定事实,再补证据,再匹配法条" |
| 跨案经验 | 从多个案件中沉淀的模式 | "押金扣减案件中交接照片权重高" |
| 通用法律 | 法条、规则、一般法律依据 | "消费者可就质量问题主张退换修" |
| 历史案件 | 具体案件事实和证据 | "某次电脑花屏纠纷缺少检测报告" |
检索时不再只做向量相似度匹配,而是:判断需要哪些记忆层 → 按层检索候选 → 结合语义相似度、关键词重叠、importance、confidence加权 → 合并去重后注入上下文。
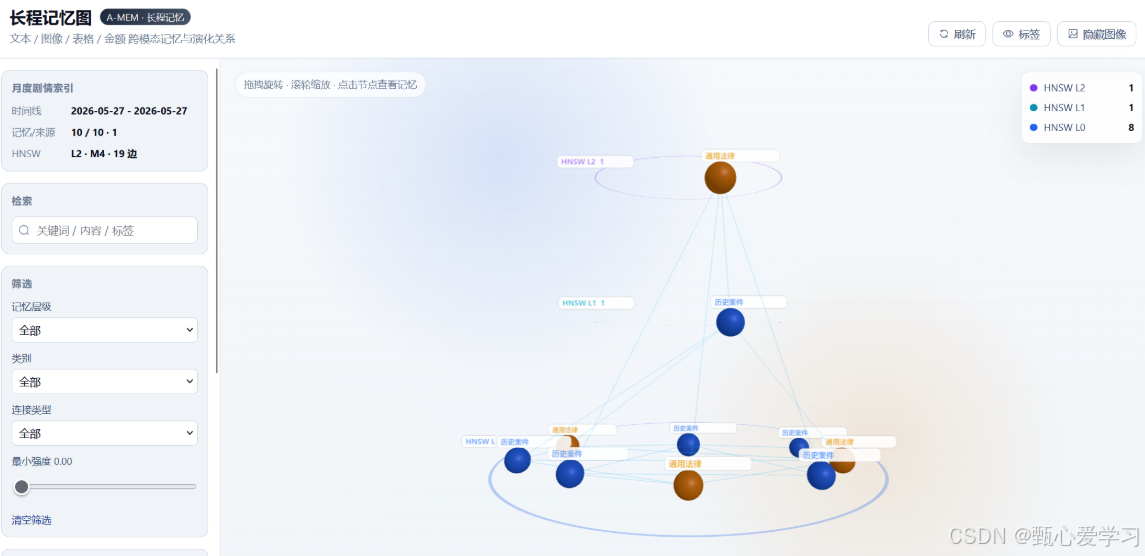
3.3 HNSW风格导航图
为了让记忆检索过程可解释,引入了HNSW(Hierarchical Navigable Small World)风格的导航图。
设计目标:当用户点击一个具体记忆节点时,前端能展示"入口点 → 高层索引 → 中间跳转 → L0具体记忆"的完整路径。
实现要点:
-
为每条note通过SHA1哈希确定性分配hnsw_level,高层节点少、底层节点多
-
每层只连接该层可见节点的近邻,并限制度数(M=4)
-
搜索时从最高层入口点开始,高层greedy下降,L0层做beam search扩展
-
后端提供真实检索路径(
/nav-path/{note_id}),前端高亮显示,而非前端编造路径
说明:当前实现是面向可视化和解释的工程化方案,并非完整替代ChromaDB的工业级HNSW索引,主要服务于小规模记忆图的解释和调试(几十到几百条note)。
3.4 真实数据抽取链路
为避免前端展示手写demo造成的虚假感,建立了完整的真实生成和抽取链路:
-
让大模型生成同一用户、多事件的法律咨询剧本(电脑花屏、租房押金、课程退款等)
-
每一轮对话走真实的
extract_and_store_knowledge -
每条note写入SQLite,过程文件保存至
backend/data/mmem_showcase_runs/
前端看到的月度记忆图是系统实际抽取、入库、构图后的结果。
3.5 新增API接口
-
GET /nav-graph- 返回完整HNSW图(nodes, edges, layers, params) -
GET /nav-path/{note_id}- 对指定note执行真实trace,返回路径高亮数据 -
POST /search- 支持strategy="layered_nav",融合HNSW路由与向量检索
四、前端风格统一与深色模式修复
4.1 设计令牌体系
创建 variables.css,定义180余项CSS自定义属性,覆盖:
-
色彩体系:主题色、成功色、警告色、危险色、文字色、背景色
-
字体层级:超小号至5倍大号全套字号
-
间距规范:0至24级统一间距
-
圆角、阴影、层级索引、贝塞尔曲线缓动
4.2 全域样式替换
在20余个组件及页面中,将硬编码十六进制色值批量替换为CSS变量。已优化的组件包括:图谱画布、聚类面板、实体视角面板、AI悬浮工具栏、聊天弹窗、结果展示卡片、法律术语悬浮提示、批量总结弹窗、字段提取展示、对话历史面板、关键词统计云图等。已优化的页面包括:知识图谱页面、文档阅读页面、AI智能助手页面。
4.3 深色模式修复
根因 :theme.ts 使用 classList.add('dark'),而 variables.css 使用 [data-theme="dark"] 属性选择器,两者不匹配导致深色模式CSS变量从未生效。
修复:
-
修改
setTheme()使用setAttribute('data-theme', 'dark') -
在
index.html添加内联脚本,页面加载时立即应用本地存储的主题 -
移除
App.vue中多余的darkclass绑定
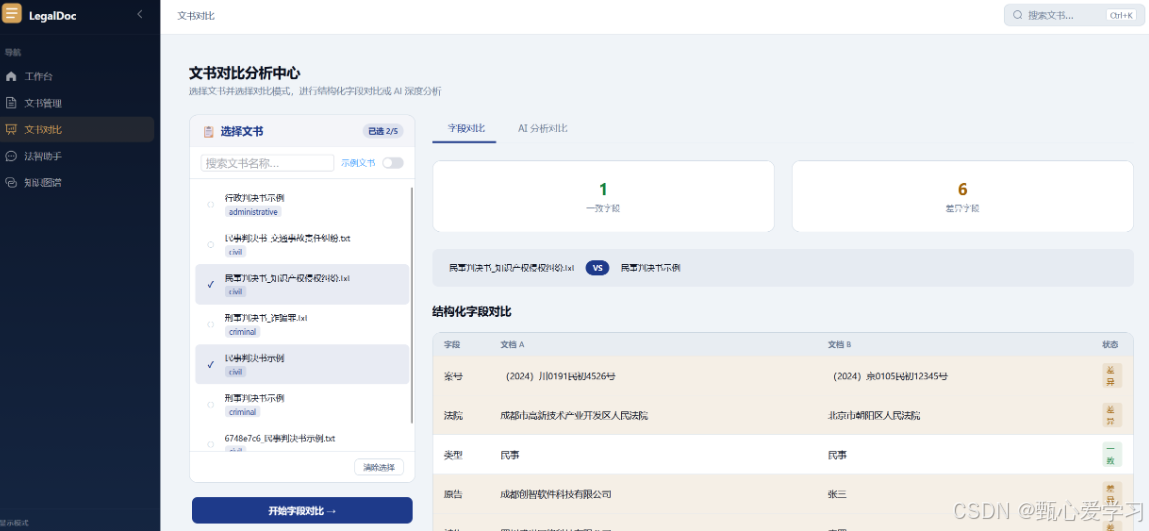
五、文书对比逻辑整合
5.1 原有问题
系统存在两套独立的文书对比功能:
| 对比维度 | 基础文书对比 | AI智能文书对比 |
|---|---|---|
| 对比形式 | 结构化字段层级比对 | AI语义深度解析 |
| 支持文档数 | 仅2份 | 2-5份 |
| AI介入 | 无 | 大语言模型 |
| 操作入口 | /compare 页面 |
法智助手页面标签页 |
两套系统整合性差:字段对比需单独跳转,AI对比需切换标签页,无互通入口,文档选择样式不统一,视觉风格杂乱。
5.2 优化方案
-
精简路由 :下线独立的
/compare路由,将所有文书对比功能统一归集至"法智助手"核心页面 -
组件复用:两套对比模式共用同一套文档选择组件
-
数据联动:字段比对结果可同步展示在AI智能分析报告旁
-
视觉统一:全线采用新版深蓝色系设计规范
六、登录状态与用户体系优化
6.1 登录状态存储改进
将token存储从 localStorage(永久保存)改为 sessionStorage(关闭浏览器自动清除),提升安全性。
javascript
// 登录成功
sessionStorage.setItem('token', res.data.token)
// 路由守卫
const token = sessionStorage.getItem('token')6.2 退出登录与注册优化
-
退出登录:
sessionStorage.clear()并跳转至登录页 -
注册功能:注册成功后自动调用登录接口,保存token并跳转首页,同时增加错误提示
6.3 全局个人悬浮球
在 App.vue 中增加右下角悬浮球组件,点击展开个人面板,包含退出登录功能。样式采用固定定位、圆角头像、阴影效果。
七、当前局限与后续计划
7.1 已知局限
-
知识图谱当前基于关系型数据库构建,规模较大时需迁移至原生图数据库(如Neo4j)
-
HNSW图为可视化和解释层,不是工业级ANN索引替代
-
记忆抽取仍依赖LLM,可能存在漏抽或误抽
-
分层规则还需更多真实法律任务验证
-
图谱当前适合几十到几百条note,更大规模需分页、聚类或按需加载
7.2 后续计划
-
引入时间轴动态图谱,展示案件引用关系的时序演化
-
进一步细粒度同步文书对比的数据联动
-
探索更大规模记忆图的增量更新与按需加载策略
-
完善法律领域特定实体的识别与链接
八、总结
本期开发完成了知识图谱从0到1的落地,实现了跨案件关联分析与可视化探索;长程记忆系统从"能存能搜"走向"有层级、有路径、可解释";前端建立了统一的设计令牌体系,支持深浅主题无缝切换;文书对比功能整合后减少了用户学习成本;登录状态优化提升了安全性。系统整体更加稳定、易用、可解释,为后续法学实证研究和规模化应用奠定了坚实基础。