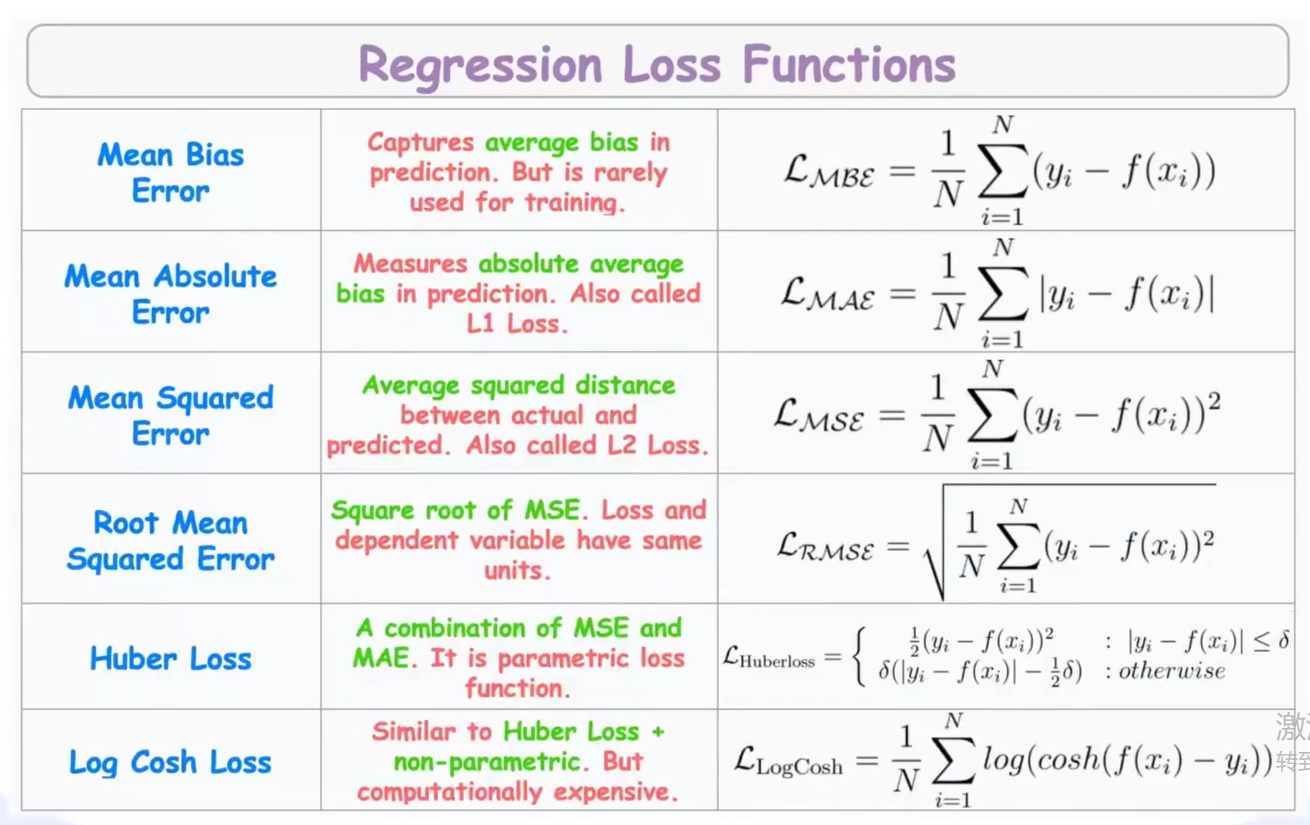
1. Mean Bias Error (MBE, 平均偏差误差)
- 公式 :1n∑(y−y^)\frac{1}{n}\sum(y - \hat{y})n1∑(y−y^)
- 特点:直接计算误差的平均值,不取绝对值也不平方。
- 缺点:正负误差会相互抵消,导致即使误差很大,MBE也可能接近0。
- 用途 :极少作为损失函数用于训练,主要用于评估模型是高估了还是低估了数据(判断偏差方向)。
2. Mean Absolute Error (MAE, 平均绝对误差)
- 公式 :1n∑∣y−y^∣\frac{1}{n}\sum|y - \hat{y}|n1∑∣y−y^∣
- 特点:计算预测值与真实值之差的绝对值平均。
- 优点 :对异常值不敏感,鲁棒性强;物理意义直观(平均误差多少)。
- 缺点:在0点处不可导,优化时需要特殊处理(如次梯度)。
3. Mean Squared Error (MSE, 均方误差)
- 公式 :1n∑(y−y^)2\frac{1}{n}\sum(y - \hat{y})^2n1∑(y−y^)2
- 特点:计算误差平方的平均值。
- 优点:处处可导,优化方便(梯度计算简单);统计学性质优良(高斯噪声假设下的最大似然估计)。
- 缺点 :对异常值非常敏感(平方放大了异常值的影响),可能导致模型偏向异常值。
4. Root Mean Squared Error (RMSE, 均方根误差)
- 公式 :MSE\sqrt{MSE}MSE
- 特点:MSE 的平方根。
- 优点 :单位与目标变量 yyy 一致,解释性强("误差大概是多少米/元")。
- 缺点 :同 MSE 一样,对异常值敏感。常作为评价指标而非训练时的损失函数。
5. Huber Loss
- 公式:分段函数。误差小时用 MSE,误差大时用 MAE。
- 特点:结合了 MSE 和 MAE 的优点。
- 核心优势 :
- 误差较小时(如 ∣y−y^∣<δ|y-\hat{y}| < \delta∣y−y^∣<δ),表现为MSE,保证了解的稳定性和可导性。
- 误差较大时,表现为MAE,降低了对异常值的敏感度。
- 用途:数据中包含噪声或异常值,但不想完全忽略它们时的首选。
6. Log Cosh Loss
- 公式 :∑log(cosh(y−y^))\sum\log(\cosh(y - \hat{y}))∑log(cosh(y−y^))
- 特点:Huber Loss 的平滑近似版。
- 优点 :
- 处处二阶可导(这使得它比 Huber 更适合需要使用牛顿法等二阶优化算法的场景,如 XGBoost)。
- 同样具备对小误差近似平方、对大误差近似线性的特性,对异常值鲁棒。
- 缺点:计算复杂度略高于前两者。
总结对比表
| 损失函数 | 对异常值敏感度 | 导数性质 | 适用场景 |
|---|---|---|---|
| MBE | 低(正负抵消) | 可导 | 不用于训练,仅用于偏差分析 |
| MAE | 低(鲁棒) | 0点不可导 | 数据含较多异常值 |
| MSE | 高(敏感) | 处处可导 | 数据干净、高斯分布 |
| RMSE | 高 | 处处可导 | 评价指标(量纲一致) |
| Huber | 中等 | 处处可导 | 需兼顾鲁棒性与平滑性 |
| Log Cosh | 中等 | 处处二阶可导 | 鲁棒回归 + 需要二阶导数优化 |