map
package map;
/**
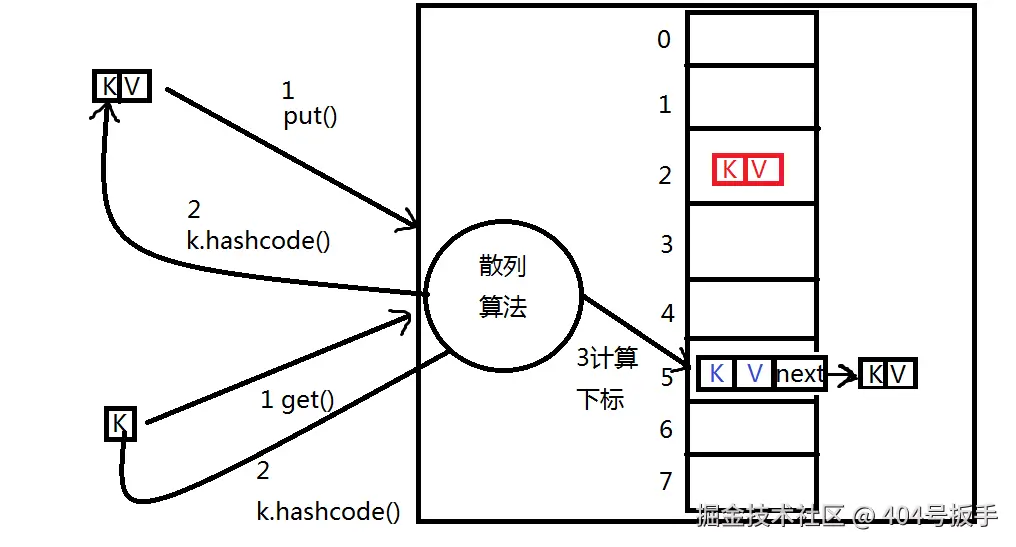
* HashMap是查询速度最快的数据结构,内部使用
* 数组实现,它通过Key的hashcode值计算该元素
* 在数组中的下标位置,从而避免了遍历数组的操
* 作,从而查询不受元素多少影响。
*
* 由于Key的hashcode方法(决定其在HashMap内部
* 数组的位置)和equals方法(决定Key是否为重复)
* 直接影响HashMap是否会出现链表,对此这两个
* 方法在Object类中有明确的重写说明。
*
* 当一个HashMap内部出现链表时,会降低其查询
* 性能,应当尽量避免。而出现链表的情况在于:
* 当两个Key的hashcode值相同,而equals比较不
* 为true时就会形成。
*
* API手册中在Object类里说明了这两个方法的重
* 写规则:
* 1:成对重写
* 当我们需要重写一个类的equals方法时,就
* 应当连同重写hashcode方法
* 2:一致性
* 当两个对象的equals比较为true时,hashcode
* 方法返回的数字必须相等。反之则不是必须的,
* 但是应当尽量保证当两个对象hashcode值相同
* 时equals方法比较为true,否则在HashMap中
* 作为Key使用时会出现链表!
* 3:稳定性
* 当一个对象参与equals比较的属性值没有发生
* 过改变的前提下,多次调用hashcode方法返回
* 的数字应当相同
*
* @author ta
*
*/
public class Key {
private int x;
private int y;
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + x;
result = prime * result + y;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Key other = (Key) obj;
if (x != other.x)
return false;
if (y != other.y)
return false;
return true;
}
}
package map;
import java.util.HashMap;
import java.util.Map;
/**
* java.util.Map
* Map 查找表,结构看起来像是一个多行两列的
* 表格。左列称为key,右列称为value。
* 所以Map总是以key-value对的形式保存元素。
* 并且总是根据key去获取对应的value.
* 对此我们经常将"查询条件"作为key,将要查询
* 的数据作为value进行保存。
*
* Map本身是一个接口,规定了Map操作的相关方法。
* 常用实现类:java.util.HashMap
*
* HashMap又称为散列表,哈希表
* 使用散列算法实现的Map,当今世界上查询速度
* 最快的数据结构,查询速度最快,查询速度最快!
*
* @author ta
*
*/
public class MapDemo1 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
/*
* V put(K k,V v)
* 将给定的一组键值对存入到Map中
*
* Map有一个要求,即:key不允许重复,
* 是否重复是依靠key自身equals比较的
* 结果。
* 如果使用map中已有的key保存value,
* 则这个操作为替换value操作,那么
* 这时put方法会将被替换的value返回。
* 否则返回值为null。
*/
/*
* 如果value是一个包装类,那么接收时
* 应当避免直接用基本类型。因为这会
* 导致自动拆箱,若没有做替换操作,返
* 回的value为null时就引发了空指针异常
*/
Integer d = map.put("语文", 98);
System.out.println(d);
map.put("数学", 97);
map.put("英语", 96);
map.put("物理", 95);
map.put("化学", 98);
System.out.println(map);
d = map.put("语文", 55);
System.out.println(d);
System.out.println(map);
/*
* V get(Object key)
* 根据给定的key获取对应的value,若
* 给定的key不存在,则返回值为null
*/
d = map.get("数学");
System.out.println("数学:"+d);
/*
* int size()
* 获取Map中的元素个数,每组键值对算
* 一个元素
*/
int size = map.size();
System.out.println("size:"+size);
/*
* V remove(K k)
* 将给定的key所对应的键值对删除。
* 返回值为该key对应的value。
*/
d = map.remove("语文");
System.out.println(map);
System.out.println(d);
}
}
package map;
import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
/**
* Map的遍历
* 遍历Map有三种方式
* 1:遍历所有的key
* 2:遍历每一组键值对
* 3:遍历所有的value(相对不常用)
*
* @author ta
*
*/
public class MapDemo2 {
public static void main(String[] args) {
Map<String,Integer> map = new LinkedHashMap<String,Integer>();
map.put("语文", 98);
map.put("数学", 97);
map.put("英语", 96);
map.put("物理", 95);
map.put("化学", 98);
System.out.println(map);
/*
* 遍历所有的key
* Set<K> keySet()
* 将当前Map中所有的key以一个Set集合
* 形式返回。遍历这个集合就等同于遍历
* 了所有的key
*/
Set<String> keySet = map.keySet();
for(String key : keySet) {
System.out.println("key:"+key);
}
/*
* 遍历每一组键值对
* Set<Entry> entrySet()
*
* java.util.Map.Entry
* Entry的每一个实例用于表示当前Map中的
* 一组键值对。其中有两个常用的方法:
* getKey(),getValue()分别用于获取对应的
* key与value
*/
Set<Entry<String,Integer>> entrySet = map.entrySet();
for(Entry<String,Integer> e: entrySet) {
String key = e.getKey();
Integer value = e.getValue();
System.out.println(key+":"+value);
}
/*
* 遍历所有的value
*/
Collection<Integer> values = map.values();
for(Integer value : values) {
System.out.println("value:"+value);
}
}
}
package map;
import java.util.HashMap;
import java.util.Map;
/**
* 判断Map是否包含给定元素。
* 可以分别判断是否包含key和value
* boolean containsKey(Object k)
* boolean containsValue(Object v)
* @author ta
*
*/
public class MapDemo3 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("语文", 98);
map.put("数学", 97);
map.put("英语", 96);
map.put("物理", 95);
map.put("化学", 98);
System.out.println(map);
/*
* 查看是否包含指定的key
*/
boolean ck = map.containsKey("语文");
System.out.println("包含key:"+ck);
boolean cv = map.containsValue(95);
System.out.println("包含value:"+cv);
}
}
xml 的解析与生成
package xml;
/**
* 员工信息
* @author ta
*
*/
public class Emp {
private int id;
private String name;
private int age;
private String gender;
private int salary;
public Emp(int id, String name, int age, String gender, int salary) {
super();
this.id = id;
this.name = name;
this.age = age;
this.gender = gender;
this.salary = salary;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getGender() {
return gender;
}
public void setGender(String gender) {
this.gender = gender;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public String toString() {
return id+","+name+","+age+","+gender+","+salary;
}
}
package xml;
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
/**
* 使用DOM4J解析XML文件
* @author ta
*
*/
public class ParseXmlDemo {
public static void main(String[] args) {
/*
* 将emplist.xml文件中的所有员工信息
* 读取出来
*/
List<Emp> list = new ArrayList<Emp>();
/*
* 使用dom4j解析XML的大致步骤:
* 1:创建SAXReader
* 2:使用SAXReader读取xml文档并生成
* Document对象。
* 这一步也是dom解析耗时耗资源的地方
* 因为要先将文档所有数据读取完毕,
* 并且以一个Document对象形式保存在
* 内存中
* 3:通过Document对象获取根元素
* 4:按照XML文档结构从根元素开始逐级获
* 取子元素已达到遍历XML文档数据的目
* 的
*/
try {
//1
SAXReader reader = new SAXReader();
//2
// reader.read(new File("emplist.xml"));
Document doc = reader.read(
new FileInputStream("emplist.xml")
);
/*
* 3
* Document提供了获取根元素的方法:
* Element getRootElement()
*
* 而Element的每一个实例用于表示当前
* xml文档中的一个元素(一对标签)
* 它提供了获取其表示的元素的相关信息
* 的方法:
*
* String getName()
* 获取当前标签的名字
*
* String getText()
* 获取当前标签中间的文本
*
* Element element(String name)
* 获取当前标签下指定名字的子标签
*
* List elements()
* 获取当前标签下所有子标签
*
* List elements(String name)
* 获取当前标签下指定名字的所有同名
* 子标签
*
* Attribute attribute(String name)
* 获取当前标签下指定名字的属性
* Attribute的每个实例表示一个属性
* 它有两个常用方法:
* String getName()获取属性名
* String getValue()获取属性值
*/
Element root = doc.getRootElement();
/*
* 获取根标签<list>下的所有员工标签<emp>
*/
List<Element> empList = root.elements("emp");
/*
* 遍历获取每个员工信息
*/
for(Element empEle:empList) {
//获取名字
//1获取<name>标签
Element nameEle = empEle.element("name");
//2获取<name>标签中间的文本
String name = nameEle.getText();
//获取年龄
Element ageEle = empEle.element("age");
int age = Integer.parseInt(
ageEle.getText()
);
//获取性别
// String gender = empEle.element("gender").getText();
String gender = empEle.elementText("gender");
//获取工资
int salary = Integer.parseInt(
empEle.elementText("salary")
);
//获取id
//1 获取id属性
// Attribute attr = empEle.attribute("id");
//2获取对应的值
// int id = Integer.parseInt(attr.getValue());
// int id = Integer.parseInt(
// empEle.attribute("id").getValue()
// );
int id = Integer.parseInt(
empEle.attributeValue("id")
);
Emp emp = new Emp(id, name, age, gender, salary);
System.out.println(emp);
list.add(emp);
}
System.out.println("解析完毕");
} catch (Exception e) {
e.printStackTrace();
}
}
}
package xml;
import java.io.FileOutputStream;
import java.util.ArrayList;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
/**
* 使用DOM4J生成一个xml文档
* @author ta
*
*/
public class WriteXmlDemo {
public static void main(String[] args) {
List<Emp> list = new ArrayList<Emp>();
list.add(new Emp(1,"张三",22,"男",5000));
list.add(new Emp(2,"李四",23,"女",6000));
list.add(new Emp(3,"王五",24,"男",7000));
list.add(new Emp(4,"赵六",25,"女",8000));
list.add(new Emp(5,"钱七",26,"男",9000));
/*
* 生成XML的大致步骤:
* 1:创建一个Document对象,表示一个空白
* 文档
* 2:向Document中添加根元素
* 3:按照XML文档结构从根标签开始逐级添加
* 子标签及对应数据
* 4:创建XmlWriter
* 5:使用XmlWriter写出Document以生成文档
*/
try {
//1
Document doc = DocumentHelper.createDocument();
/*
* 2
* Document提供了添加根元素的方法:
* Element addElement(String name)
* 添加后会将根标签以一个Element实例形式返
* 回,以便于我们对其继续操作。注意,这个
* 方法只能被调用一次。
*/
Element root = doc.addElement("list");
/*
* Element也提供了添加相关信息的方法:
* Element addElemnt(String name)
* 向当前标签中添加给定名字的子标签
*
* Element addText(String text)
* 向当前标签中间添加指定文本。返回值还是当前
* 标签(这样做的好处是可以连续操作当前标签)
*/
for(Emp emp : list) {
//向根标签中添加<emp>子标签
Element empEle = root.addElement("emp");
//添加名字
Element nameEle = empEle.addElement("name");
nameEle.addText(emp.getName());
//添加年龄
empEle.addElement("age")
.addText(emp.getAge()+"");
empEle.addElement("gender")
.addText(emp.getGender());
empEle.addElement("salary")
.addText(emp.getSalary()+"");
//添加属性
empEle.addAttribute("id", emp.getId()+"");
}
/*
* XMLWriter符合java高级流用法。它负责将
* Document对象以XML文档格式进行写出,并
* 通过其连接的文件流写入到文件中。
*/
XMLWriter writer = new XMLWriter(
new FileOutputStream("myemp.xml"),
OutputFormat.createPrettyPrint()
);
//将Document写出以生成XML文档
writer.write(doc);
System.out.println("写出完毕!");
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
反射机制
package reflect;
/**
* 测试反射功能的类
* @author ta
*
*/
public class Person {
public void sayHello() {
System.out.println("hello!");
}
public void sayHello(String name) {
System.out.println("hello!"+name);
}
public void sayHello(String name,int age) {
System.out.println("hello!"+name+",您今年"+age+"岁.");
}
public void sayHi() {
System.out.println("hi!");
}
}
package reflect;
import java.lang.reflect.Method;
/**
* java的反射机制
* 反射机制可以允许我们实例化一个类,调用方法
* 操作属性从编码期改为在运行期决定。并且也可
* 以在运行期间动态的得知一个类的情况(它有哪些
* 方法,属性等)
* 反射机制可以大大提高代码的灵活度,但是实际
* 开发中使用要适度。过度使用反射会降低代码的
* 运行效率。
*
* @author ta
*
*/
public class ReflectDemo1 {
public static void main(String[] args) throws ClassNotFoundException {
/*
* 反射的第一步:获取要操作的类的类对象
*
* java中每个被JVM加载的类在JVM内部都
* 有且只有一个类对象(Class的实例)与之
* 对应。
* 通过某个类的类对象可以得知这个类的
* 信息(有哪些方法,哪些属性等等信息)
* 并且可以进行实例化等操作。
*
* 想获取一个类的类对象的方式:
* 1:类名.class
* 每个类都有一个静态属性:class,
* 可以直接获取这个类的类对象。
* 当我们明确需要获取某个类的类对象
* 时可以使用这种方式。
*
* 2:通过Class的静态方法:forName,
* 这种方式我们可以指定想加载的类
* 的名字来获取该类的类对象
*
* 3:通过类加载器ClassLoader
*/
//查看Person类的信息
/*
* 1:先获取Person的类对象
*/
// Class cls = Person.class;
/*
* Class.forName(String className)
* 这里在加载一个类时指定的字符串为加载类的
* 完全限定名:包名.类名
*/
Class cls = Class.forName("reflect.Person");
String name = cls.getName();
System.out.println(name);
Method[] methods = cls.getMethods();
for(Method method:methods) {
System.out.println(method.getName());
}
}
}
package reflect;
import java.util.Scanner;
/**
* 通过类对象快速创建实例
* @author ta
*
*/
public class ReflectDemo2 {
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException {
/*
* 实例化Person
*/
Person p = new Person();
System.out.println(p);
/*
* 利用反射
*/
Scanner scanner = new Scanner(System.in);
Class cls = Class.forName(scanner.nextLine());
/*
* java.util.Date
* java.util.ArrayList
*
* Class有一个快速实例化对象的方法:
* newInstance()
* 但是需要注意,该Class实例表示的类必须要
* 包含无参构造方法,否则不能使用这种方式
* 实例化
*/
Object obj = cls.newInstance();
System.out.println(obj);
}
}
package reflect;
import java.lang.reflect.Method;
/**
* 利用反射调用方法
* @author ta
*
*/
public class ReflectDemo3 {
public static void main(String[] args) throws Exception {
Person p = new Person();
p.sayHello();
/*
* 利用反射
*/
//1 加载类对象
Class cls = Class.forName("reflect.Person");
//2 实例化
Object o = cls.newInstance();
/*
* 3通过类对象获取其定义的方法
* Method的每一个实例用于表示一个类中
* 的一个具体的方法
*/
Method method = cls.getMethod("sayHello",null);
/*
* 4调用该方法
*/
method.invoke(o, null);
}
}
package reflect;
import java.lang.reflect.Method;
/**
* 调用有参方法
* @author ta
*
*/
public class ReflectDemo4 {
public static void main(String[] args) throws Exception {
/*
* Person p = new Person();
*/
Class cls = Class.forName("reflect.Person");
Object o = cls.newInstance();
/*
* p.sayHello("张三");
*
* 1:获取Person的sayHello方法
* void sayHello(String)
*/
Method method = cls.getMethod(
"sayHello", String.class
);
/*
* 2:调用o这个对象的sayHello方法并
* 传入实际参数
*/
method.invoke(o, "张三");
/*
* p.sayHello("李四",22)
*/
Method method2 = cls.getMethod(
"sayHello", String.class,int.class
);
method2.invoke(o,"李四",22);
}
}
package reflect;
import java.util.Arrays;
/**
* JDK5之后推出了一个新的特性:
* 可变参数
* @author ta
*
*/
public class ArgDemo {
public static void main(String[] args) {
dosome("a");
dosome("a","b");
dosome("a","b","c");
dosome(2,"a","b","c");
}
public static void dosome(int a,String... s) {
}
public static void dosome(String... s) {
System.out.println("方法开始");
System.out.println(s.length);
System.out.println(Arrays.toString(s));
System.out.println("方法结束");
}
}