加粗样式
图像计数(Image Counting):多目标密集场景下的精确统计
1 什么是图像计数
图像计数是视觉-语言跨模态与计算机视觉的核心任务之一,旨在基于图像内容,对指定类别的目标物体进行数量统计,可支持语言提示引导计数,也可完成无提示的密集目标计数,是视觉定位、视觉推理的重要延伸任务。
图像计数的核心应用场景聚焦于密集、遮挡、多目标共存的复杂环境,比如人群统计、商品清点、细胞计数、野生动物监测等,是工业、安防、医疗、科研领域的刚需视觉能力。
2 图像计数的核心依赖:视觉定位
图像计数的底层逻辑是先定位、后计数 ,高度依赖视觉定位(Visual Grounding)的效果。
只有先通过定位模型精准识别出每一个目标实例的位置与边界,才能通过统计有效目标框数量得到最终计数结果,因此视觉定位的精度直接决定计数的准确性。
在遮挡严重、目标重叠的场景中,定位模型的鲁棒性越强,计数误差越小。
3 图像计数的方法演进
图像计数的技术路线随视觉模型发展逐步迭代,形成四大主流方法,适配不同场景需求。
3.1 基于检测的计数
这是最直观、最易解释的计数方式,核心是数有效定位框。
- 实现逻辑:使用检测/定位模型识别图像中所有目标实例,生成独立边界框,统计框的数量即为总数量。
- 代表模型:Faster R-CNN、DETR、Grounding DINO。
- 优点:逻辑清晰、可解释性强,适合目标稀疏、无严重重叠的场景。
- 缺点:计算成本高,密集遮挡场景易出现漏检、重复检测,导致计数偏差。
3.2 基于回归的计数
针对密集场景优化,将计数转化为数值回归问题。
- 实现逻辑:模型将图像映射为密度图,每个像素的数值代表该位置存在目标中心的概率密度,对整张密度图积分得到总数量。
- 代表模型:YOLO-Count、CountGD。
- 优点:擅长人群、细胞等超密集场景,抗遮挡能力强。
- 缺点:可解释性差,泛化能力受训练数据分布影响较大。
3.3 通用/少样本计数
依托大模型与奠基模型的泛化能力,实现零样本/少样本计数。
- 实现逻辑:借助CLIP等多模态模型的开放词汇能力,无需大量标注数据,即可对未见过的类别完成计数。
- 代表模型:CLIP-Count。
- 优点:零样本能力突出,泛化性强,适合小样本、多类别、非标场景。
- 缺点:依赖大模型算力,极端密集场景精度略低于专用模型。
3.4 视频计数
面向动态时序场景,利用多帧信息提升计数稳定性。
- 实现逻辑:结合目标追踪与时序特征,跨帧关联同一目标,解决单帧遮挡、目标消失/重现问题,完成稳定计数。
- 代表模型:CountViD、YOLO+DeepSORT。
- 优点:鲁棒性强,可统计帧内总数与区域流量,适合监控、车流统计。
- 缺点:计算复杂度高,对硬件与推理速度要求更高。
4 主流计数模型深度解析
4.1 YOLO-Count
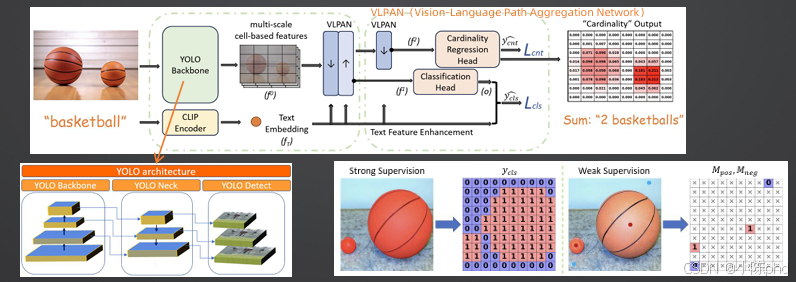
基于YOLO World的开放词汇检测框架,是实时计数的主流方案。
- 核心设计:采用VLPAN多尺度特征聚合网络,构建基数图(Cardinality Map)实现可微分计数。
- 训练方式:混合强弱监督数据,兼顾精度与效率。
- 适用场景:需要实时性、固定类别、中等密集度的计数场景。
4.2 CountGD
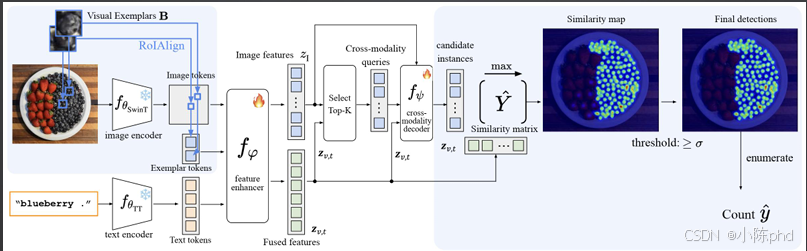
基于Grounding DINO的专用计数模型,是当前通用计数的SOTA方案之一。
- 核心创新:将Grounding DINO的强开放词汇定位能力与计数流程深度融合。
- 实现逻辑:通过视觉样本匹配、相似度矩阵计算、跨模态查询筛选,精准提取有效目标。
- 性能:在FSC-147数据集上实现高精度计数,适配多类别、复杂场景。
4.3 CLIP-Count
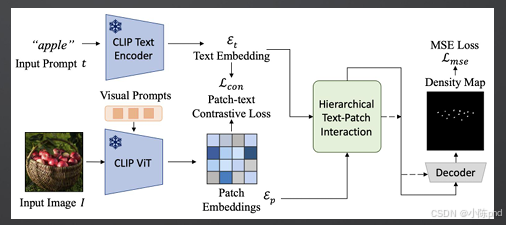
首个端到端开放词汇密集计数模型,依托CLIP的多模态能力实现零样本计数。
- 核心机制:通过文本编码器提取提示特征,视觉编码器提取图像特征,完成层级文本-图像块交互,输出密度图。
- 优势:开放词汇支持强,无需针对新类别重新训练,适合小样本、多品类场景。
4.4 CountViD
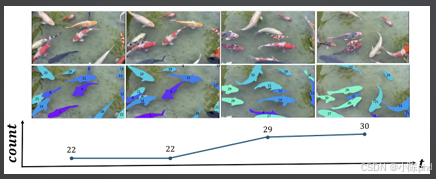
面向视频场景的动态计数模型,实现开放世界目标的跨帧稳定计数。
- 核心能力:融合视频分割、目标追踪与图像计数,解决动态场景下的遮挡、目标出入帧问题。
- 计数类型:支持帧内总数统计与区域流量计数,适配安防、交通监控场景。
5 图像计数常用数据集
5.1 ShanghaiTech dataset
上海科技大学人群计数数据集,分为PartA与PartB。
- PartA:密集人群、视角复杂,适合测试极端密集场景计数能力。
- PartB:人群分布均匀、视角稳定,用于常规场景验证。
5.2 UCF-QNRF
规模最大、密度最高的人群计数数据集,包含超拥挤场景,最高单图计数可达20000人以上,用于检验模型极限性能。
5.3 FSC-147
通用小样本目标计数数据集,覆盖147种不同类别目标,包括家具、车辆、动物、植物等,用于测试开放词汇、少样本计数能力。
6 图像计数核心评估指标
6.1 平均绝对误差(MAE)
所有测试图像的预测计数与真实计数的绝对误差平均值,是衡量计数准确性的核心指标。
MAE数值越小,代表计数整体偏差越小。
6.2 均方根误差(RMSE)
预测计数与真实计数的平方误差平均值的平方根,用于衡量模型的鲁棒性。
RMSE对大误差更敏感,可反映模型在极端场景下的稳定性。
7 总结
图像计数是视觉定位的延伸、视觉推理的基础,从简单的数框统计,到密集场景的密度图回归,再到基于大模型的零样本计数与动态视频时序计数,技术路线持续向高精度、泛化、实时、开放世界方向升级。
基于检测的方法保证可解释性,基于回归的方法适配密集场景,少样本与视频计数则拓展了应用边界。在Grounding DINO、CLIP、CountViD等模型的支撑下,图像计数已能满足安防、工业、医疗、交通等多场景的实用需求,成为跨模态视觉感知的核心能力之一。