LLama
模型权重 DeepSeek-R1-Distill-Llama-70B
模型参数 DeepSeek-R1-Distill-Llama-70B/config.json
json
{
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 128000,
"eos_token_id": [
128001,
128008,
128009
],
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 28672,
"max_position_embeddings": 131072,
"mlp_bias": false,
"model_type": "llama",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": {
"factor": 8.0,
"high_freq_factor": 4.0,
"low_freq_factor": 1.0,
"original_max_position_embeddings": 8192,
"rope_type": "llama3"
},
"rope_theta": 500000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.47.0.dev0",
"use_cache": true,
"vocab_size": 128256
}q 部分: 64头×128=8192,k/v 各: 8头×128=1024。
Attention类型为Grouped query attention。
docode layer: 80层。
llama 模型结构
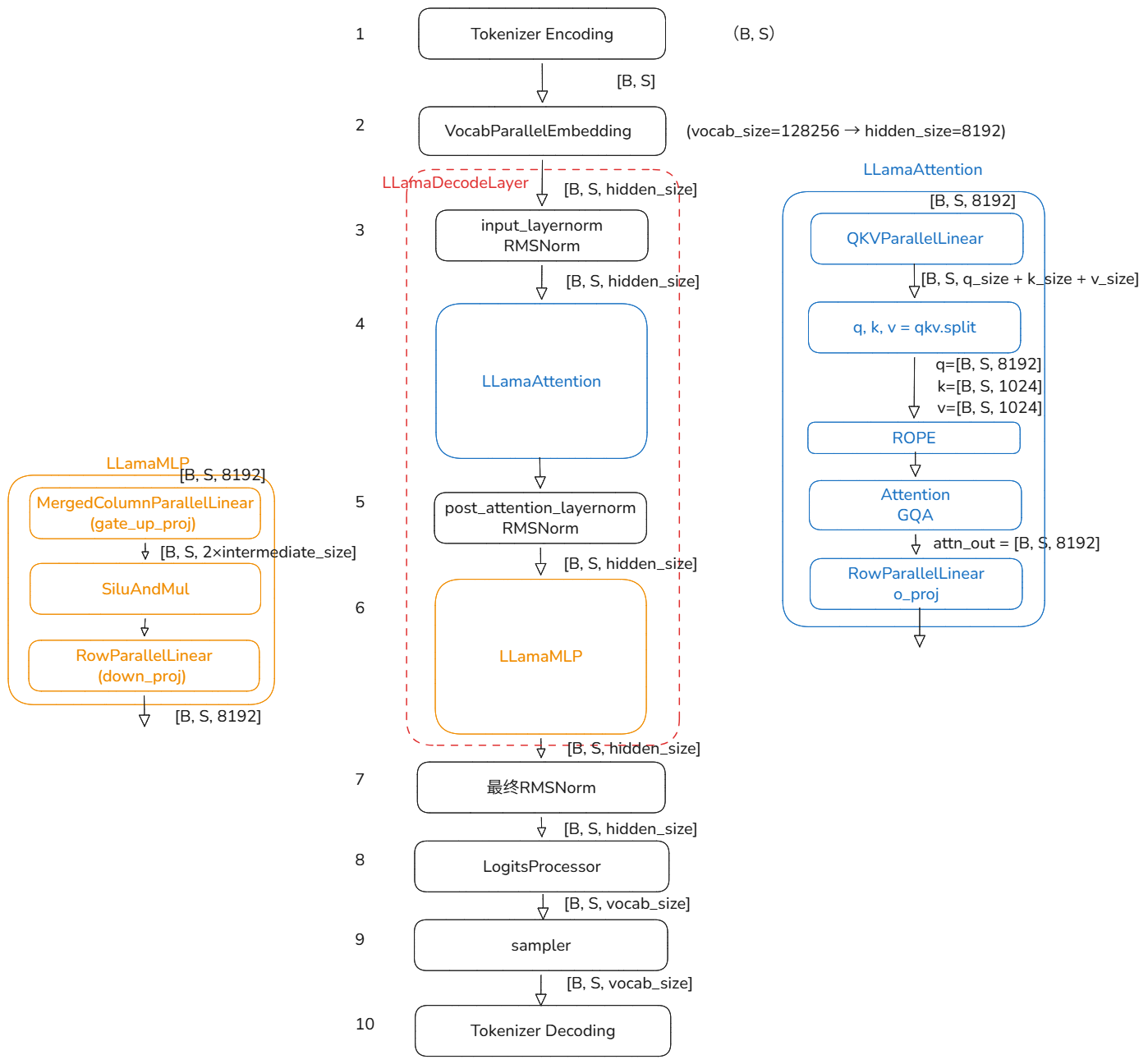
vllm 中的模型构建文件:llama.py
2 嵌入层 (VocabParallelEmbedding)
| 方向 | 张量形状 | 说明 |
|---|---|---|
| 输入 | B, S | token IDs,dtype=torch.long |
| 输出 | B, S, 8192 | token embeddings,hidden_size=8192 |
在tp>1场景,当需要查找词嵌入时,每个设备独立计算自己负责的词,然后通过一个集合通信操作(All-Reduce)将所有设备的结果聚合起来,得到最终的完整嵌入。
refer: 从零实现 vLLM (1.1):并行词嵌入 VocabParallelEmbedding
LlamaDecoderLayer
3 input_layernorm (RMSNorm)
vllm 中的 class RMSNorm中融合了残差Add 和rmsnorm计算。
text
input_layernorm (RMSNorm)
- 若 residual 为 None:
residual = hidden_states
hidden_states = norm(hidden_states)
- 否则:
hidden_states, residual = norm(hidden+residual)| 方向 | 张量形状 | 说明 |
|---|---|---|
| 输入 | hidden_states=B, S, 8192, residual=B, S, 8192 或 None | 第一次调用时 residual 为 None |
| 输出 | normed=B, S, 8192, residual=B, S, 8192 | 若 residual 为 None,则 residual = 原始 hidden_states |
博客Deepseek R1/V3模型结构总览,分别画出了Add 和 RMSNorm。
在vllm,Add + RMSNorm 被封装到class RMSNorm。
4 LlamaAttention
python
class LlamaAttention(nn.Module):
def __init__(
self,
config: LlamaConfig,
hidden_size: int,
num_heads: int,
num_kv_heads: int,
max_position_embeddings: int = 8192,
quant_config: QuantizationConfig | None = None,
bias: bool = False,
bias_o_proj: bool = False,
cache_config: CacheConfig | None = None,
prefix: str = "",
attn_type: str = AttentionType.DECODER,
) -> None:
self.qkv_proj = QKVParallelLinear(
hidden_size=hidden_size,
head_size=self.head_dim,
total_num_heads=self.total_num_heads,
total_num_kv_heads=self.total_num_kv_heads,
bias=bias,
quant_config=quant_config,
prefix=f"{prefix}.qkv_proj",
)
self.o_proj = RowParallelLinear(
input_size=self.total_num_heads * self.head_dim,
output_size=hidden_size,
bias=bias_o_proj,
quant_config=quant_config,
prefix=f"{prefix}.o_proj",
)
self._init_rotary_emb(config, quant_config=quant_config)
self.attn = attn_cls(
self.num_heads,
self.head_dim,
self.scaling,
num_kv_heads=self.num_kv_heads,
cache_config=cache_config,
quant_config=quant_config,
per_layer_sliding_window=sliding_window,
attn_type=attn_type,
prefix=f"{prefix}.attn",
)
def forward(
self,
positions: torch.Tensor,
hidden_states: torch.Tensor,
) -> torch.Tensor:
qkv, _ = self.qkv_proj(hidden_states)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q, k = self.rotary_emb(positions, q, k)
attn_output = self.attn(q, k, v)
output, _ = self.o_proj(attn_output)
return output子模块:
rotary_emb: 旋转位置编码,ROPE。为什么需要位置编码?: 在未加入位置信息的情况下,无论 q和k 所处的位置如何变化,它们之间的注意力权重均不会发生变化,也就是位置无关,这显然与直觉不符。对于两个词向量,如果它们之间的距离较近,我们希望它们之间的的注意力权重更大,当距离较远时,注意力权重更小。为此引入了位置编码机制。
Attention计算,self.attn(q, k, v)。
| 子模块 | 方向 | 张量形状 | 说明 |
|---|---|---|---|
| QKVParallelLinear | 输入 | B, S, 8192 | |
| 输出 | B, S, 64\*128 + 2\*(8\*128) = B, S, 8192 + 2048 = B, S, 10240 | q 部分: 64头×128=8192,k/v 各: 8头×128=1024,合计 8192+1024+1024=10240 | |
| 拆分 q,k,v | 输入 | B, S, 10240 | |
| 输出 | q=B, S, 8192, k=B, S, 1024, v=B, S, 1024 | 形状保持 2D 以便后续 reshape | |
| RoPE | 输入 | q=B, S, 8192, k=B, S, 1024, positions=B, S | |
| 输出 | 同输入形状,旋转变换 | ||
| Reshape for Attention | 输入 | q=B, S, 64, 128, k=B, S, 8, 128, v=B, S, 8, 128 | 视图变换 |
| Attention (Paged/Flash) | 输入 | q, k, v 同上 | |
| 输出 | attn_out=B, S, 64, 128 → B, S, 8192 | 合并头维度 | |
| RowParallelLinear (o_proj) | 输入 | B, S, 8192 | |
| 输出 | B, S, 8192 |
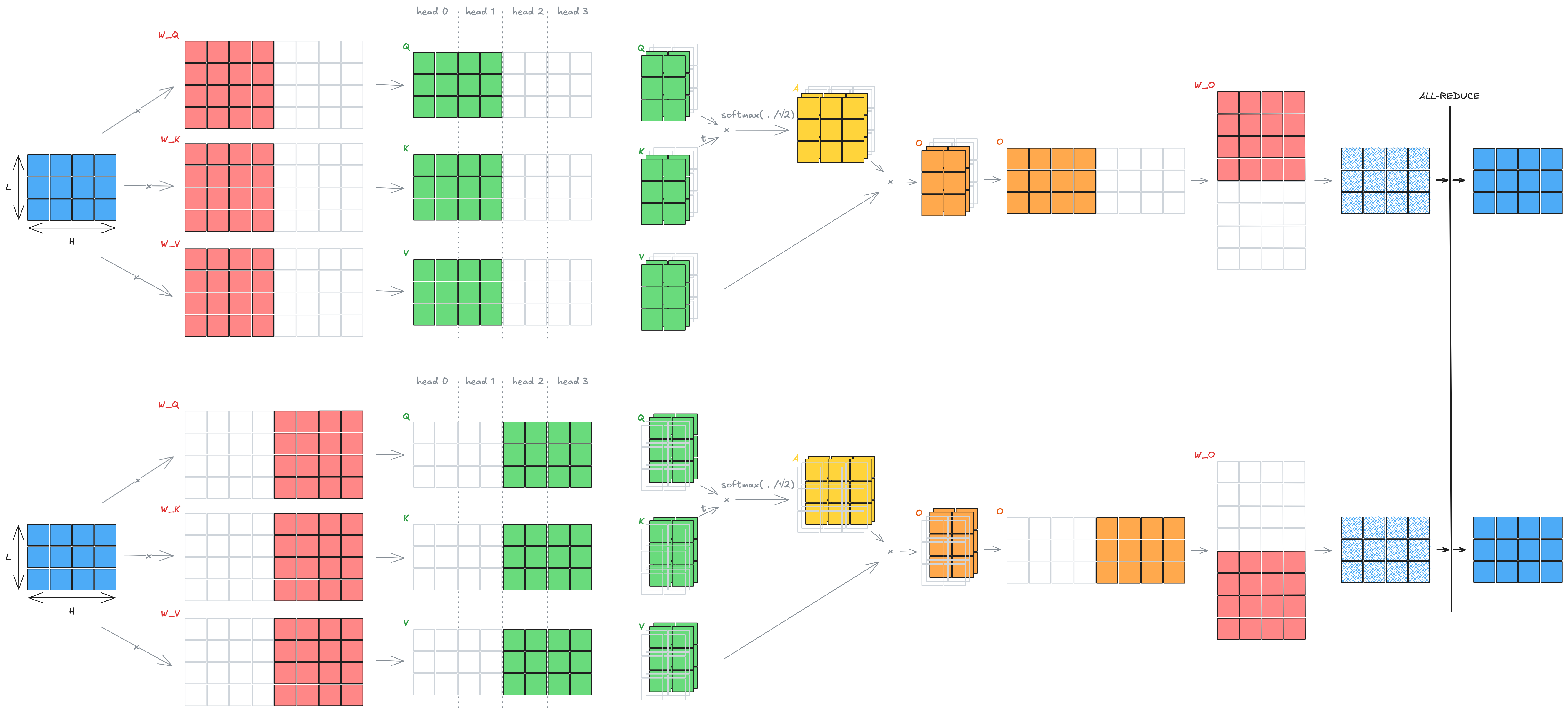
在tp>1场景,RowParallelLinear最后会执行All-Reduce,收集结果。
Tensor Parallelism in Attention,以MHA为例,tp=2场景:
post_attention_layernorm (RMSNorm)
| 方向 | 张量形状 |
|---|---|
| 输入 | hidden_states=B, S, 8192, residual=B, S, 8192 |
| 输出 | normed=B, S, 8192, residual=B, S, 8192 |
LlamaMLP
MLP的计算公式,Act代表激活函数,一般为SiLU:
F F N ( x ) = d o w n _ p r o j × ( u p _ p r o j × x ∗ A c t ( g a t e _ p r o j × x ) ) FFN(x) = down\_proj \times (up\_proj \times x \ * \ Act(gate\_proj \times x)) FFN(x)=down_proj×(up_proj×x ∗ Act(gate_proj×x))
python
class LlamaMLP(nn.Module):
def __init__(
self,
hidden_size: int,
intermediate_size: int,
hidden_act: str,
quant_config: QuantizationConfig | None = None,
bias: bool = False,
prefix: str = "",
reduce_results: bool = True,
disable_tp: bool = False,
) -> None:
super().__init__()
self.gate_up_proj = MergedColumnParallelLinear(
input_size=hidden_size,
output_sizes=[intermediate_size] * 2,
bias=bias,
quant_config=quant_config,
disable_tp=disable_tp,
prefix=f"{prefix}.gate_up_proj",
)
self.down_proj = RowParallelLinear(
input_size=intermediate_size,
output_size=hidden_size,
bias=bias,
quant_config=quant_config,
reduce_results=reduce_results,
disable_tp=disable_tp,
prefix=f"{prefix}.down_proj",
)
if hidden_act != "silu":
raise ValueError(
f"Unsupported activation: {hidden_act}. Only silu is supported for now."
)
self.act_fn = SiluAndMul()
def forward(self, x):
x, _ = self.gate_up_proj(x)
x = self.act_fn(x)
x, _ = self.down_proj(x)
return x在vllm中,gate_proj 和 up_proj对应的权重融合进了 MergedColumnParallelLinear。
SiluAndMul 的计算:
python
class SiluAndMul(CustomOp):
"""An activation function for SwiGLU.
The function computes x -> silu(x[:d]) * x[d:] where d = x.shape[-1] // 2.代码中的 * 运算符执行的是对应元素相乘(即逐元素乘法,Hadamard product)。
| 子模块 | 方向 | 张量形状 | 说明 |
|---|---|---|---|
| MergedColumnParallelLinear (gate_up_proj) | 输入 | B, S, 8192 | |
| 输出 | B, S, 2\*28672 = B, S, 57344 | gate 和 up 两个投影拼接 | |
| SiluAndMul | 输入 | B, S, 57344 | 看成 gate, up 各 28672 |
| 输出 | B, S, 28672 | SiLU(gate) * up | |
| RowParallelLinear (down_proj) | 输入 | B, S, 28672 | |
| 输出 | B, S, 8192 |
在tp>1场景,RowParallelLinear最后会执行All-Reduce,收集结果。
MLP 输出形状:B, S, 8192
最终 RMSNorm
hidden_states, _ = self.norm(hidden_states, residual)
| 方向 | 张量形状 | 说明 |
|---|---|---|
| 输入 | hidden_states=B, S, 8192, residual=B, S, 8192 | 最后一层输出 |
| 输出 | hidden_states = B, S, 8192 | 归一化后的最终表示,丢弃 residual |
LogitsProcessor
Logits processors allow you to modify the model's output distribution before sampling, enabling controlled generation behaviors like token masking, constrained decoding, and custom sampling strategies.
| 方向 | 张量形状 | 说明 |
|---|---|---|
| 输入 | B, S, 128256 | |
| 输出 | B, S, 128256 | 可选乘 logit_scale |
模型文件中的compute_logits已经废弃,Logits processors的处理逻辑在Sampler中触发: self.apply_logits_processors
这个部分,在最新的代码中,封装层次已经很复杂了,参考:Logits处理器体系
Sampler
A layer that samples the next tokens from the model's outputs.
Sampler 的处理过程:
text
forward(logits, sampling_metadata)
│
├─ 确定 logprobs_mode,如需 logprobs 则计算 raw_logprobs
├─ logits = logits.float()
├─ logits = apply_logits_processors(logits, ...)
│ ├─ 合并 output + spec token ids (若 predict_bonus_token)
│ ├─ 应用 allowed token ids mask
│ ├─ 应用 bad words
│ ├─ 应用非 argmax‑invariant logits processors
│ └─ 应用 penalties (repetition, frequency, presence)
│
├─ sampled, processed_logprobs = sample(logits, sampling_metadata)
│ ├─ 若 all_greedy:直接 argmax 并返回
│ ├─ 温度缩放
│ ├─ 应用 argmax‑invariant processors (如 min_p)
│ ├─ 调用 topk_topp_sampler 获得随机采样结果
│ └─ 根据 temperature 阈值合并贪婪结果
│
├─ 若需要 logprobs:
│ ├─ num_logprobs == -1 → 返回原始 raw_logprobs
│ └─ 否则 gather_logprobs(raw_logprobs, num_logprobs, sampled)
│
└─ 返回 SamplerOutput(sampled_token_ids, logprobs_tensors)采样策略,参考: Top-k & Top-p解码策略
Qwen3MoeForCausalLM
模型权重 Qwen3-30B-A3B-Instruct-250
模型参数 Qwen3-30B-A3B-Instruct-2507/config.json
json
{
"architectures": [
"Qwen3MoeForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 151643,
"decoder_sparse_step": 1,
"eos_token_id": 151645,
"head_dim": 128,
"hidden_act": "silu",
"hidden_size": 2048,
"initializer_range": 0.02,
"intermediate_size": 6144,
"max_position_embeddings": 262144,
"max_window_layers": 48,
"mlp_only_layers": [],
"model_type": "qwen3_moe",
"moe_intermediate_size": 768,
"norm_topk_prob": true,
"num_attention_heads": 32,
"num_experts": 128,
"num_experts_per_tok": 8,
"num_hidden_layers": 48,
"num_key_value_heads": 4,
"output_router_logits": false,
"rms_norm_eps": 1e-06,
"rope_scaling": null,
"rope_theta": 10000000,
"router_aux_loss_coef": 0.001,
"sliding_window": null,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.51.0",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 151936
}q 部分: 32头×128=4096,k/v 各: 4头×128=512。
Attention类型为Grouped query attention。
docode layer: 48层。
每层由128专家,每个Token选择 topk=8个专家。
Qwen3Moe 模型结构
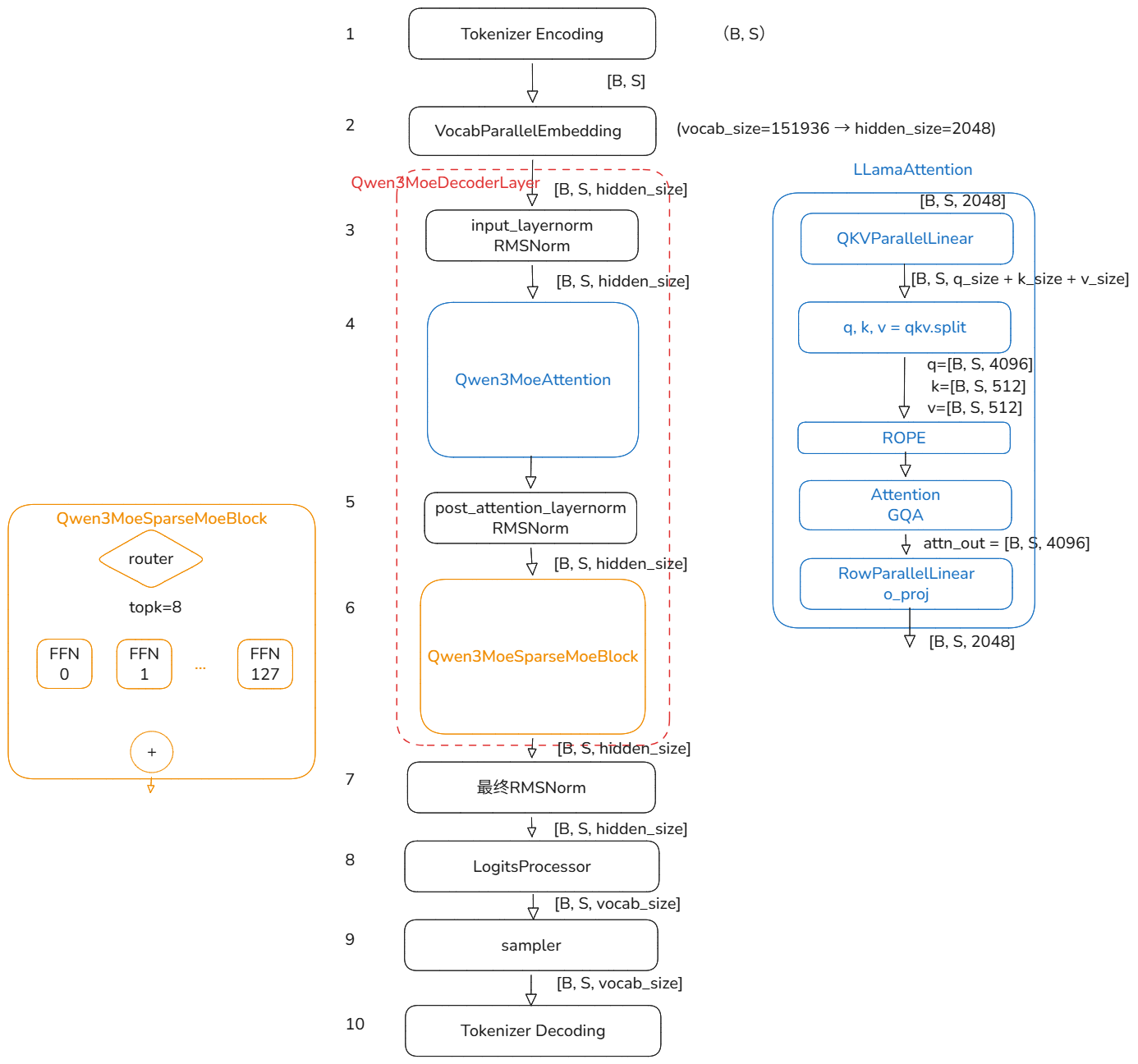
vllm 中的模型构建文件:qwen3_moe.py
Qwen3MoeSparseMoeBlock
text
┌──────────────────────────────────────────────────────┐
│ MoE 层 (Qwen3MoeSparseMoeBlock) |
│ - 门控: ReplicatedLinear → 128个专家的logits │
│ - 每个token选择 top-8 专家 │
│ - 专家混合 (FusedMoE): │
│ 每个专家是双层FFN: 输入2048 → 中间768 → 输出2048 │
│ - 按门控概率加权求和 │
│ - 无共享专家 (shared_expert为空) │
└──────────────────────────────────────────────────────┘ Router为某一个专家计算出来的8个专家分别为0, 7, 9, 34, 77, 89, 110, 127号专家,他们的权重分别为0.1, 0.2, 0.2, 0.1, 0.05, 0.05, 0.1, 0.1。
最后专家输出的矩阵,每个专家的输出分别乘上0.1, 0.2, 0.2, 0.1, 0.05, 0.05, 0.1, 0.1,就这个Token的moe输出。