前沿
JiuwenSwarm 基于 openJiuwen 框架实现了完整的 Agent Skills 体系:Skill 是可安装、可管理、可复用的能力包,Swarm Skills 则是将团队协作中跑通的最佳实践标准化封装成可复用的"团队级技能"。本文深入解析这套技能演进体系的设计思路与核心实现,重点介绍自演进机制、演进命令以及 Swarm Skills 的自演进设计。
一、为什么需要技能演进
在没有演进体系的情况下,技能(Skill)一旦写好就基本不会再变。工具调用出错,工程师记录一条日志;用户反馈说理解有误,下次还是同样的逻辑。能力的上限,从部署那天就已经固定了。
从 Harness Engineering 到 Coordination Engineering,AI Agent 领域的工程范式在持续更迭。当行业刚刚把视线从"更强的单 Agent"转向"更强的 Agent 团队",就需要回答一个问题:如何让多个 Agent,像一支精锐团队一样协同作战?
JiuwenSwarm 给出的答案,是基于 openJiuwen 演进栈的自演进机制,让技能能够从真实使用中学习并持续改进。
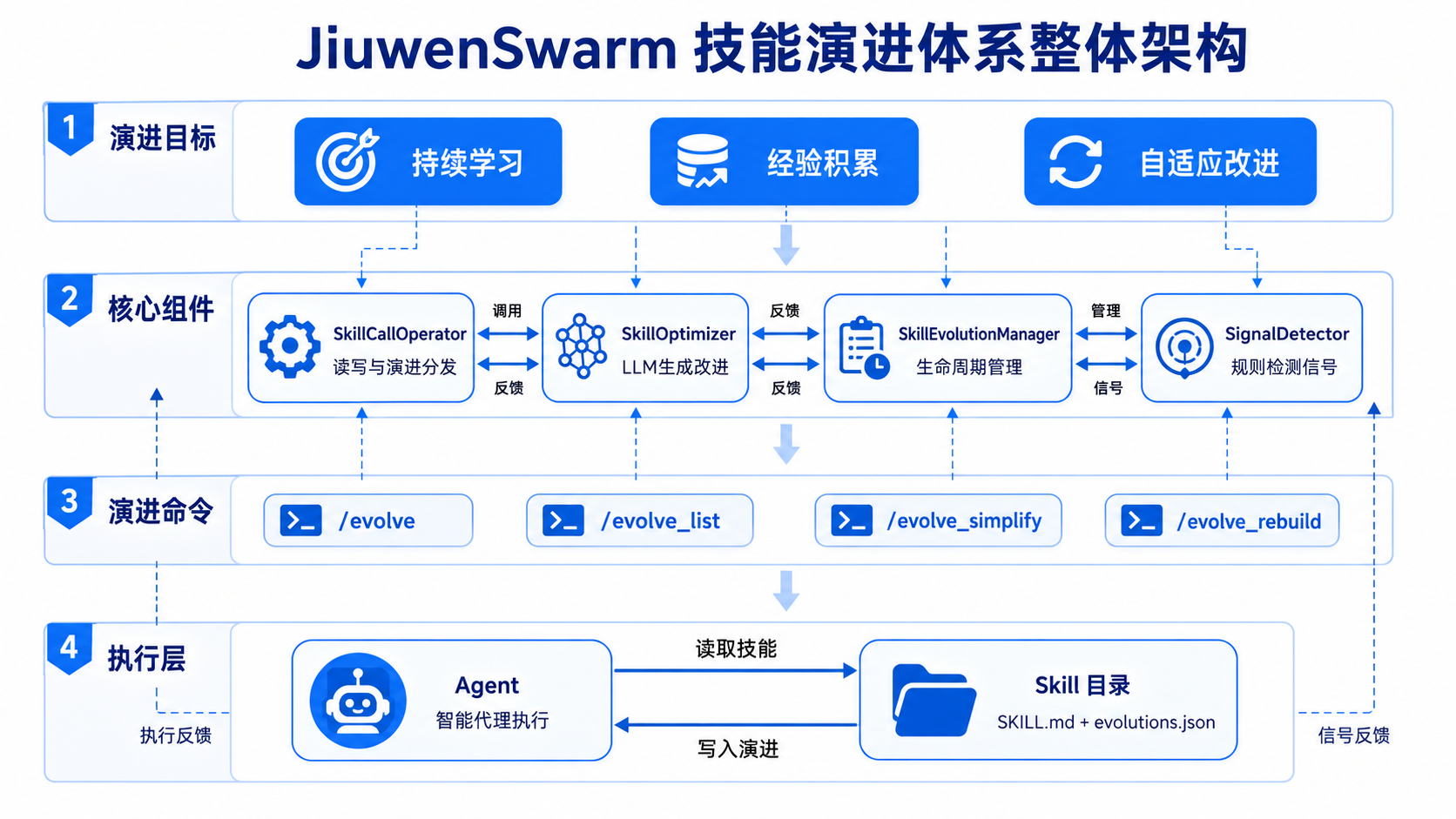
二、自演进的核心组件
JiuwenSwarm 的自演进基于 openJiuwen 的演进栈,以 SkillCallOperator 算子统一管理所有 Skills 的读写与演进分发。在此基础上,系统内置了一套演进信号检测机制,持续监听执行过程和对话内容,将真实使用中遇到的问题转化为 Skills 的改进输入。
2.1 SkillCallOperator
SkillCallOperator 是 JiuwenSwarm 与 Skills 交互的核心入口。当系统检测到需要改进的地方,这些改进会先存入 evolutions.json,SkillCallOperator 会把它们合并后一起返回给 Agent。这意味着每次调用 Skill 时,都能获取到最新的演进经验。
它的核心职责:
- 读取 Skill 定义(SKILL.md)
- 执行 Skill 指令
- 自动加载 Skill 积累的演进经验
2.2 SkillOptimizer
SkillOptimizer 是 JiuwenSwarm 基于 openJiuwen 框架实现的 Optimizer 优化器,负责驱动整个 Skill 演进流程。
它的核心工作包括:
- 接收信号:从 SignalDetector 接收异常信号,理解当前 Skill 遇到了什么问题
- 分析判断:结合对话上下文,判断这个问题是否值得记录
- 生成改进:调用 LLM 生成具体的改进建议
- 执行记录:将生成的改进方案写入演进记录
当你使用 /evolve 命令时,背后就是 SkillOptimizer 在工作。
2.3 SkillEvolutionManager
SkillEvolutionManager 是演进生命周期的核心管理者,负责协调各个阶段的演进工作:
- 信号扫描:调用 SignalDetector 提取需要演进的事件
- 记录生成:调用 LLM 将信号转化为可执行的改进方案
- 存储管理 :维护
evolutions.json文件的读写 - 内容固化:将待定演进记录合并到原始 SKILL.md
它衔接了 SignalDetector、SkillOptimizer 和 SkillCallOperator,形成完整的演进闭环。
2.4 SignalDetector
SignalDetector 是演进信号的检测器,持续监听对话和执行结果中的异常。
它基于规则工作,不需要调用 LLM,因此响应速度快:
- 监听每一次工具执行的结果,捕捉错误关键词
- 捕捉用户的纠正反馈(如"不对"、"应该"等)
- 判断信号应该归到哪个 Skill 并关联上下文
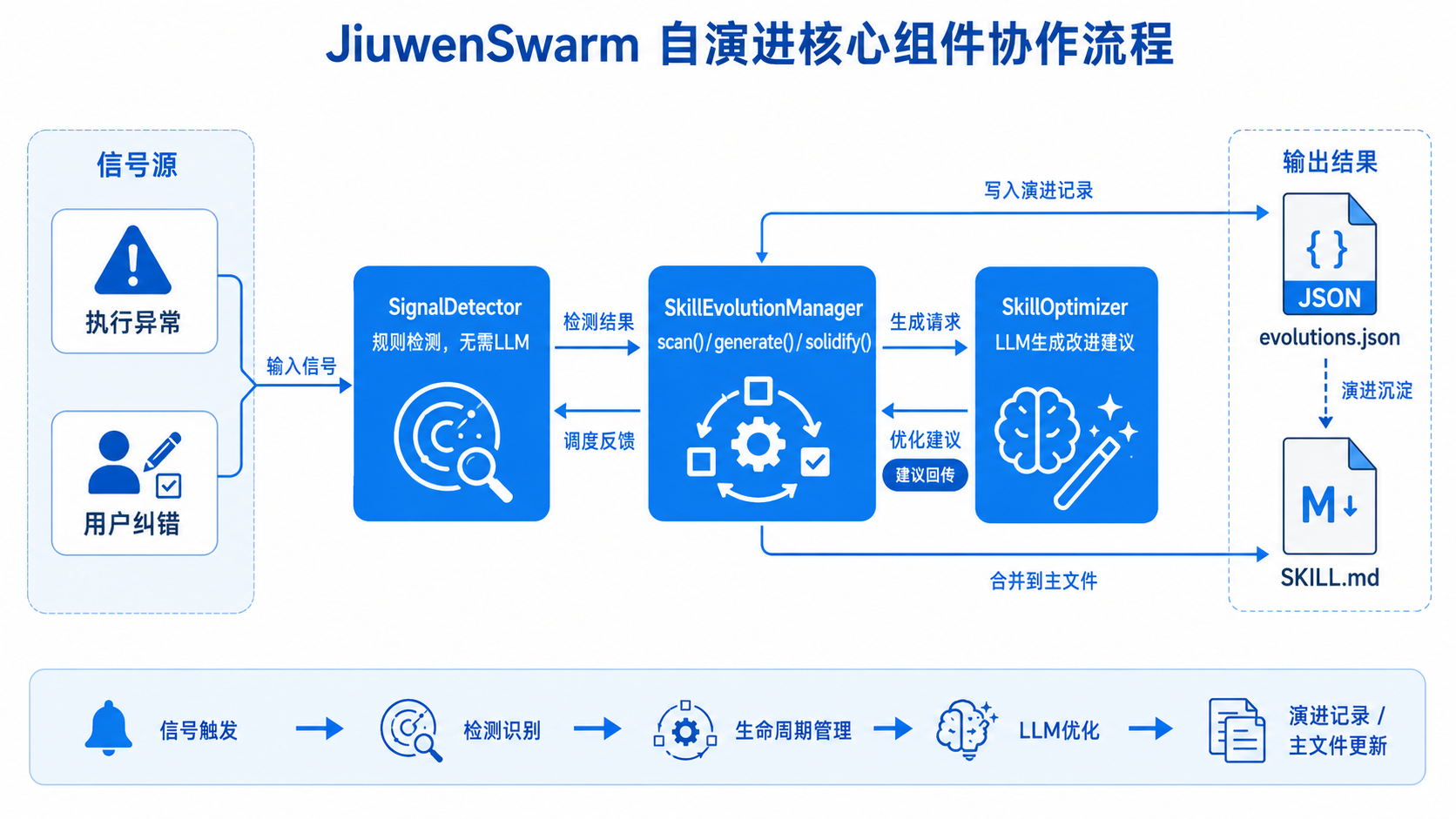
三、识别哪些信号
3.1 执行异常
包括工具调用超时、接口返回报错、代码执行中的异常中断等。只要任务执行中出现明确的失败字样,系统会自动识别并将其归因到当前正在执行的 Skill 上。
检测关键词包括但不限于:
- 通用错误:
error、exception、failed、failure、timeout - 网络相关:
connection error、econnrefused、enoent - 其他:
permission denied、command not found
3.2 用户纠错
当你说"不对"、"应该换个方式"、"你理解错了"这类话语时,系统不会将其当作普通对话略过,而是会识别为一次有效的负反馈。这类信号往往比报错日志更有价值------它直接点出了 Skill 在理解或处理逻辑上的偏差。
检测模式包括:
- 中文:
不对、不是这、错 了、应该 是、你搞错了、纠正一下 - 英文:
that's wrong、you're wrong、should be、actually
四、信号捕获之后做什么
系统会全程追踪当前活跃的 Skill 模块,确保每个信号都能准确对应到具体的 Skill 文档。具体的改写逻辑如下:
4.1 异常案例 → 排障建议
执行失败的现场记录会被整理成具体的操作建议,补充进 Skills 的 Troubleshooting(已知问题与处理方式)部分。下次遇到相同场景,Skill 可以主动提示已知的风险点和应对方式。
latex
原始信号:
Tool 'weather-check' returned: Error: API timeout after 30s
演进为:
## Troubleshooting
- 遇到天气 API 超时错误时,优先检查网络连接,可考虑添加重试机制或降级策略。4.2 纠错交互 → 示例补充
用户纠错的对话片段会作为新的 Example(正确用法示例)写入 Skills 文档,让后续的调用更容易理解用户的真实意图。
latex
原始信号:
User: 不对,我说的是查询上海不是北京
演进为:
## Examples
- 用户说"查询上海天气"时应调用上海的经纬度参数,而非默认北京五、演进流程与文件
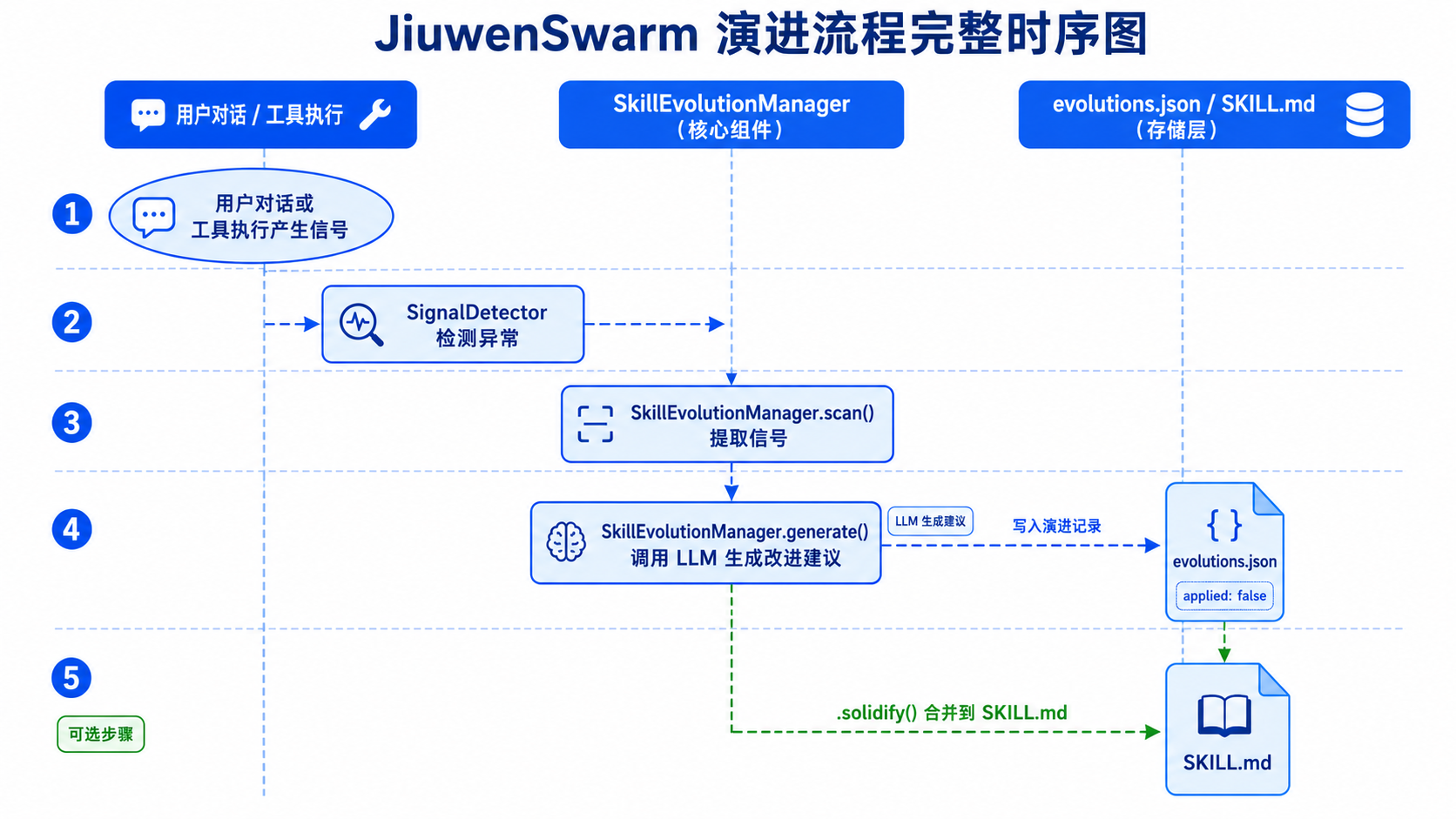
5.1 演进流程图
plain
用户对话 / 工具执行
│
▼
┌───────────────────┐
│ SignalDetector │ 监听并识别信号
│ 检测执行异常 │
│ 检测用户纠错 │
└────────┬──────────┘
│
▼
┌─────────────────────────────┐
│ SkillEvolutionManager │
│ .scan() │ 提取演进信号
└────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ SkillEvolutionManager │
│ .generate() │ LLM 生成演进记录
└────────────┬───────────────┘
│
▼
┌─────────────────────────────┐
│ evolutions.json │ 写入待固化记录
│ (Skill 目录下) │
└────────────┬───────────────┘
│
▼ (可选)
┌─────────────────────────────┐
│ .solidify() │ 合并到 SKILL.md
└─────────────────────────────┘
5.2 演进文件
演进记录存储在每个 Skill 目录下的 evolutions.json 文件中:
json
{
"skill_id": "deep-search",
"version": "1.0.0",
"updated_at": "2024-01-15T10:30:00Z",
"entries": [
{
"id": "ev_1234abcd",
"source": "execution_failure",
"timestamp": "2024-01-15T10:30:00Z",
"context": "API timeout after 30s",
"change": {
"section": "Troubleshooting",
"action": "append",
"content": "## 常见问题\n- 遇到 API 超时错误时..."
},
"applied": false
}
]
}其中 applied: false 表示待固化状态,applied: true 表示已固化到 SKILL.md。
5.3 演进文件位置
plain
~/.jiuwenswarm/workspace/agent/skills/<skill_name>/
├── SKILL.md # Skill 源文档
├── evolutions.json # 演进经验记录 ← 在这里管理
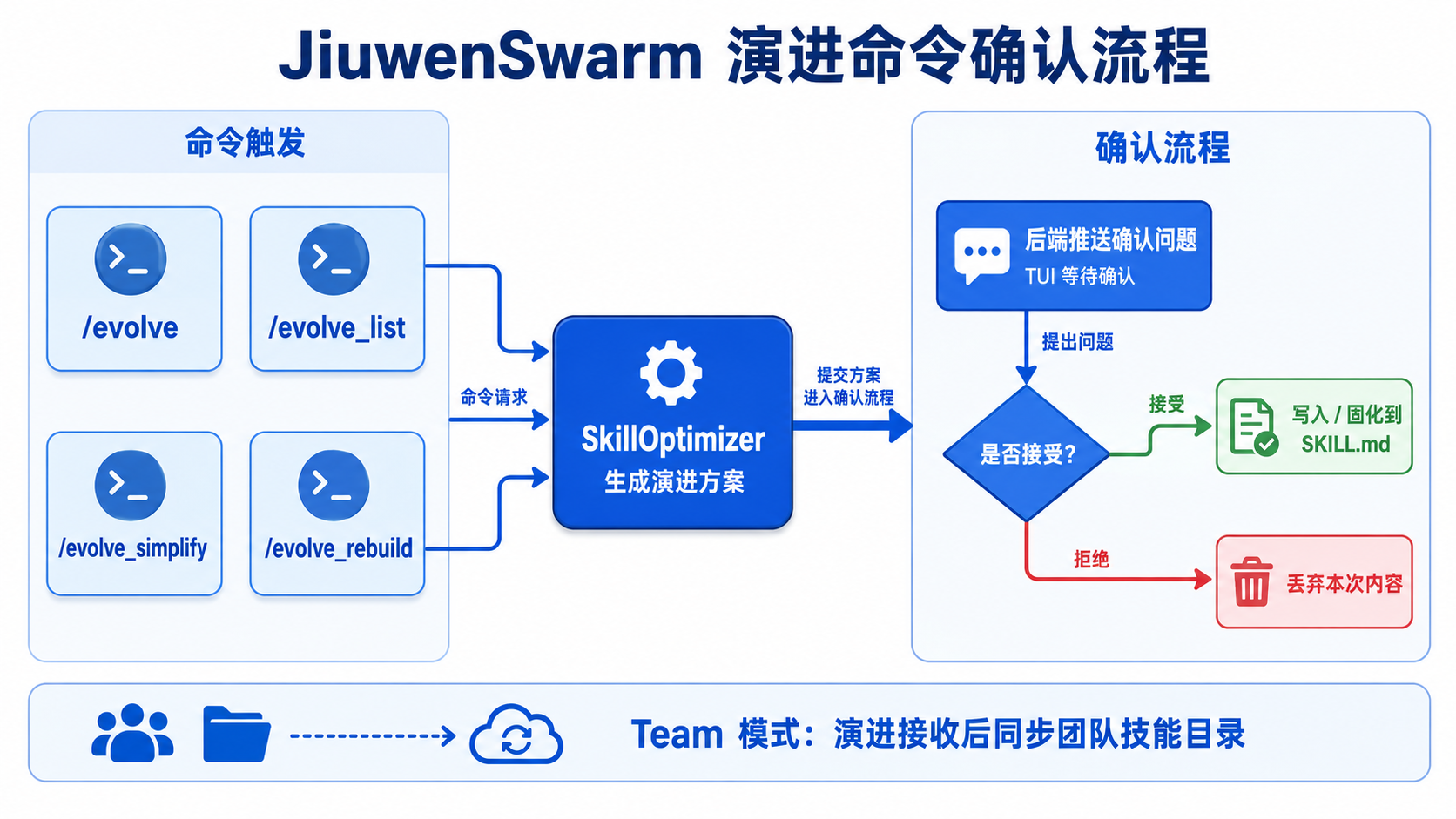
└── ...六、演进命令详解
JiuwenSwarm 提供了一组 /evolve* 命令用于技能自演进。这组命令由 TUI 本地注册并解析,随后通过普通聊天通道把 slash 文本转发给后端。实际演进逻辑在 Agent / Team 侧完成。
6.1 演进命令的模式差异
- Agent 模式 :由
SkillEvolutionRail处理,仅agent.plan可用。 - Team 模式 :由
TeamSkillEvolutionRail处理,用于团队技能演进。 - Code 模式 与
agent.fast不支持这组命令。
6.2 演进命令列表
| 命令 | 说明 |
|---|---|
/evolve <skill_name> [user_query] |
为指定 Skill 触发演进。agent.plan 会扫描当前会话中的工具失败、用户纠错等信号;Team 模式必须提供 user_query。 |
/evolve_list <skill_name> [--sort score] |
按分数查看某个 Skill 的演进经验,展示记录数、平均分、使用/反馈统计、section 与内容预览。 |
/evolve_simplify <skill_name> [user_intent] |
生成经验库整理方案,用于合并重复经验、拆分过长经验或清理低价值经验;尾随文本会作为整理意图传入后端。 |
/evolve_rebuild <skill_name> [user_intent] |
生成重建 SKILL.md 的 follow-up prompt,并继续作为一次普通 Agent / Team 任务执行。 |
6.3 演进命令示例
bash
/evolve pptx 修复导出失败时的错误处理
/evolve_list pptx --sort score
/evolve_simplify pptx 合并重复的导出失败经验
/evolve_rebuild pptx 强化 Troubleshooting 和 Examples6.4 确认流程
/evolve 和 /evolve_simplify 不会直接落盘覆盖内容。后端会推送确认问题,TUI 进入等待确认状态:
- 接收后,后端接受本次演进记录并写入/固化
- 拒绝后丢弃本次生成内容
Team 技能演进接收后会同步团队技能目录。演进或审批未完成时,用户补充的新输入会先排队,等待演进完成后再继续发送。
七、Swarm Skills 的自演进
7.1 Swarm Skill 的结构
Swarm Skill(团队级技能)将团队协作中跑通的最佳实践、SOP、角色搭配、调度策略,标准化封装成可复用的"团队级技能"。它与普通 Skill 的最大区别在于:Swarm Skill 封装的是多个 Agent 角色的协作模式。
Swarm Skill 的标准结构:
plain
swarm-skill-example/
├── SWARM_SKILL.md # 团队技能定义
├── roles/ # 角色定义目录
│ ├── leader/
│ │ └── SKILL.md
│ ├── researcher/
│ │ └── SKILL.md
│ └── writer/
│ └── SKILL.md
├── scripts/ # 协作脚本
├── constraints/ # 约束规则
└── dependencies.yaml # 依赖配置SWARM_SKILL.md 包含团队的整体配置,声明所有参与的角色及其技能依赖。
7.2 Swarm Skills 自演进:越用越强的飞轮
最具想象空间的,是 Swarm Skills 的自演进机制。团队在实际执行任务的过程中,JiuwenSwarm 的演进引擎持续观察任务拆解、角色调度、消息往来等完整轨迹,自动从轨迹里反推出可复用的 Swarm Skill,提交用户审批即可入库。
自演进同时在两个层面进行:
团队层:根据任务执行轨迹自动增减角色、补充约束规则、优化协作流程,让 Leader 的规划与管控能力持续提升。
成员层:把每位 Teammate 在实战中遇到的工具报错、接口超时、调用技巧等经验沉淀下来,再遇同类问题直接解决,不重复踩坑。团队在进步,每位成员也在成长。
7.3 Swarm Skill 的演进管理
Swarm Skill 的演进记录同样存储在 evolutions.json 文件中,与普通 Skill 使用相同的数据格式。演进管理通过 TeamSkillEvolutionRail 处理。
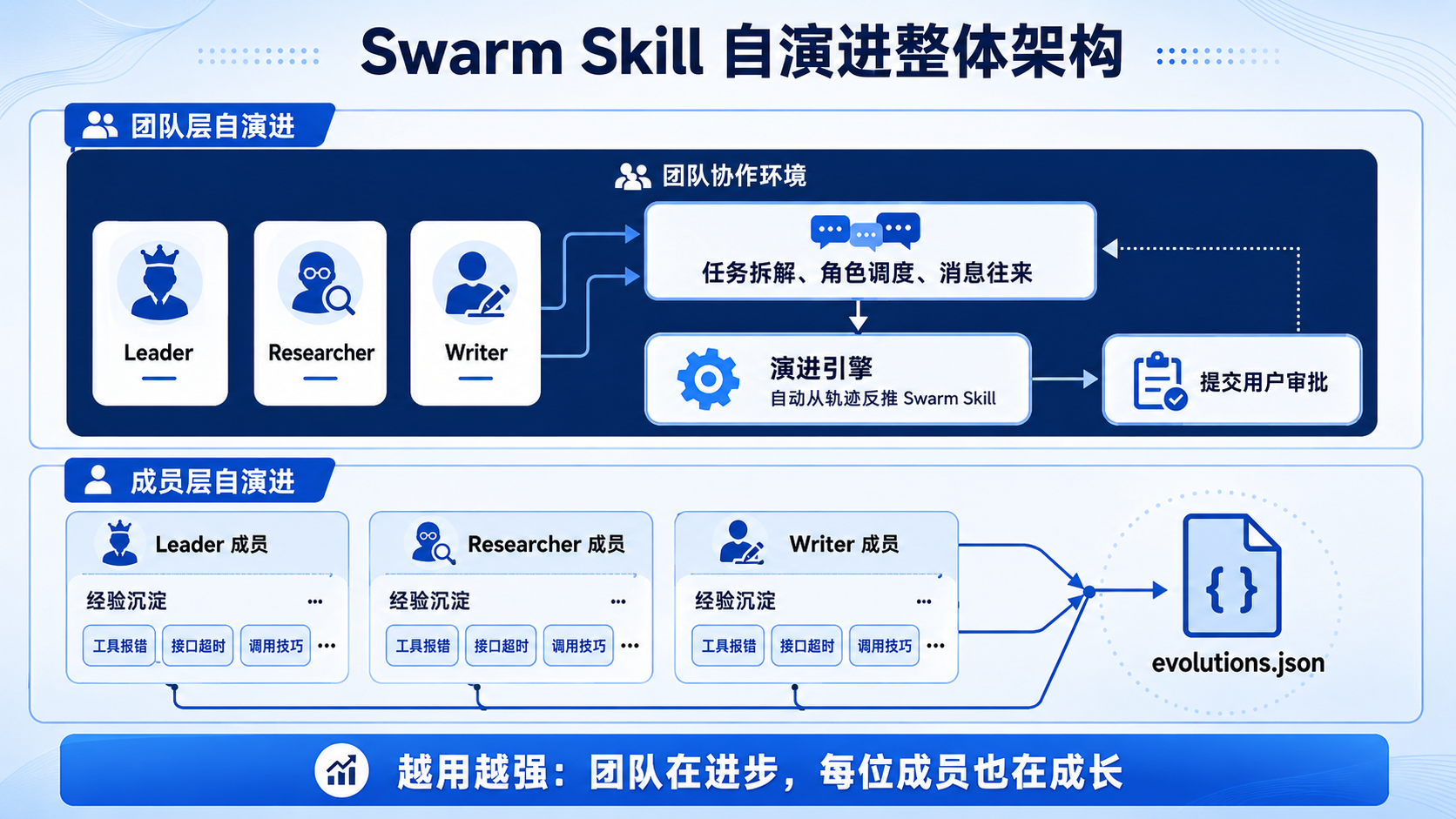
八、TeamSkills Hub 与技能发布
8.1 TeamSkills 命令
JiuwenSwarm 提供了 /teamskills 命令用于 TeamSkills 管理:
| 命令 | 说明 |
|---|---|
/teamskills init <name> |
初始化一个新的 TeamSkill |
/teamskills validate <path> |
验证 TeamSkill 结构 |
/teamskills pack <path> |
打包 TeamSkill |
/teamskills info <asset_id> |
查看 TeamSkill 信息 |
/teamskills search <query> |
在 TeamSkills Hub 搜索 |
/teamskills list |
列出本地已安装的技能 |
/teamskills install <asset_id> |
安装 TeamSkill |
/teamskills uninstall <name> |
卸载 TeamSkill |
/teamskills publish <path> |
发布 TeamSkill 到 Hub |
/teamskills delete <skill_id> |
从 Hub 删除 TeamSkill |
8.2 发布与删除
publish走 TeamSkills Hub 原生发布接口POST /api/v1/pluginsdelete走 TeamSkills Hub 原生删除接口DELETE /api/v1/plugins/{skill_id}/versions/{version}
九、实操演示:Web 界面下 Swarm Skills 自演进流程
以下场景演示在 Windows 10 + 源码启动 + Web 浏览器 环境下的 Swarm Skills 自演进操作。
环境说明:
- 操作系统:Windows 10
- 启动方式:源码启动(不通过 pip 安装)
- 操作入口:Web 浏览器访问前端(通常 http://localhost:5173 或类似地址)
- 团队模式:通过 Web 界面底部的模式切换按钮切换到团队模式
9.1 场景一:团队技能自演进
目标
在 Web 界面中切换到团队模式,执行协作任务,触发 Swarm Skill 的自演进,观察团队层和成员层的演进效果。
前置条件
九、实操演示:Web 界面下 Swarm Skills 自演进流程
以下场景演示在 Windows 10 + 源码启动 + Web 浏览器 环境下的 Swarm Skills 自演进操作。
环境说明:
- 操作系统:Windows 10
- 启动方式:源码启动(不通过 pip 安装)
- 操作入口:Web 浏览器访问前端(通常 http://localhost:5173 或类似地址)
- 团队模式:通过 Web 界面底部的模式切换按钮切换到团队模式
9.1 场景一:团队技能自演进
目标
在 Web 界面中切换到团队模式,执行协作任务,触发团队 Skill 的自演进,观察演进信号的捕获与经验记录生成。
前置条件
- JiuwenSwarm 源码已启动(后端服务)
- Web 前端已启动(
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">npm run dev</font>) - 已安装至少一个 Skill(如
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">openJiuwen-DeepSearch</font>,skills 目录位于<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">~/.jiuwenswarm/agent/workspace/skills/</font>) - 配置文件
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">config.yaml</font>中<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">react.evolution.enabled: true</font>和<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">react.evolution.auto_scan: true</font>
步骤一:启动 JiuwenSwarm 后端服务
在项目根目录下执行:
plain
# Windows
cd D:\Download\jiuwenswarm
python -c "import sys; sys.path.insert(0, 'D:/Download/jiuwenswarm'); from jiuwenswarm.app import main; main()"确认服务启动成功,日志显示 Gateway(ws://127.0.0.1:19000)和 AgentServer(ws://127.0.0.1:18092)已就绪。
步骤二:启动 Web 前端
另开一个终端:
plain
cd jiuwenswarm\channels\web\frontend
npm run dev -- --host 0.0.0.0 --port 5173步骤三:切换到集群模式(团队模式)
- 查看 Web 界面底部的模式切换按钮组
- 点击最右侧的集群模式按钮
- 确认模式已切换,界面左上角或聊天区域显示"Team 模式"标识
步骤四:发送第一条消息建立团队会话
重要:团队在发送第一条消息时自动创建,无需手动"创建团队"。
在聊天输入框输入一条简单的消息,例如:
你好
等待团队初始化完成(看到团队 leader 的响应消息)。此步骤确保 TeamSkillEvolutionRail 被正确注册到 TeamManager。
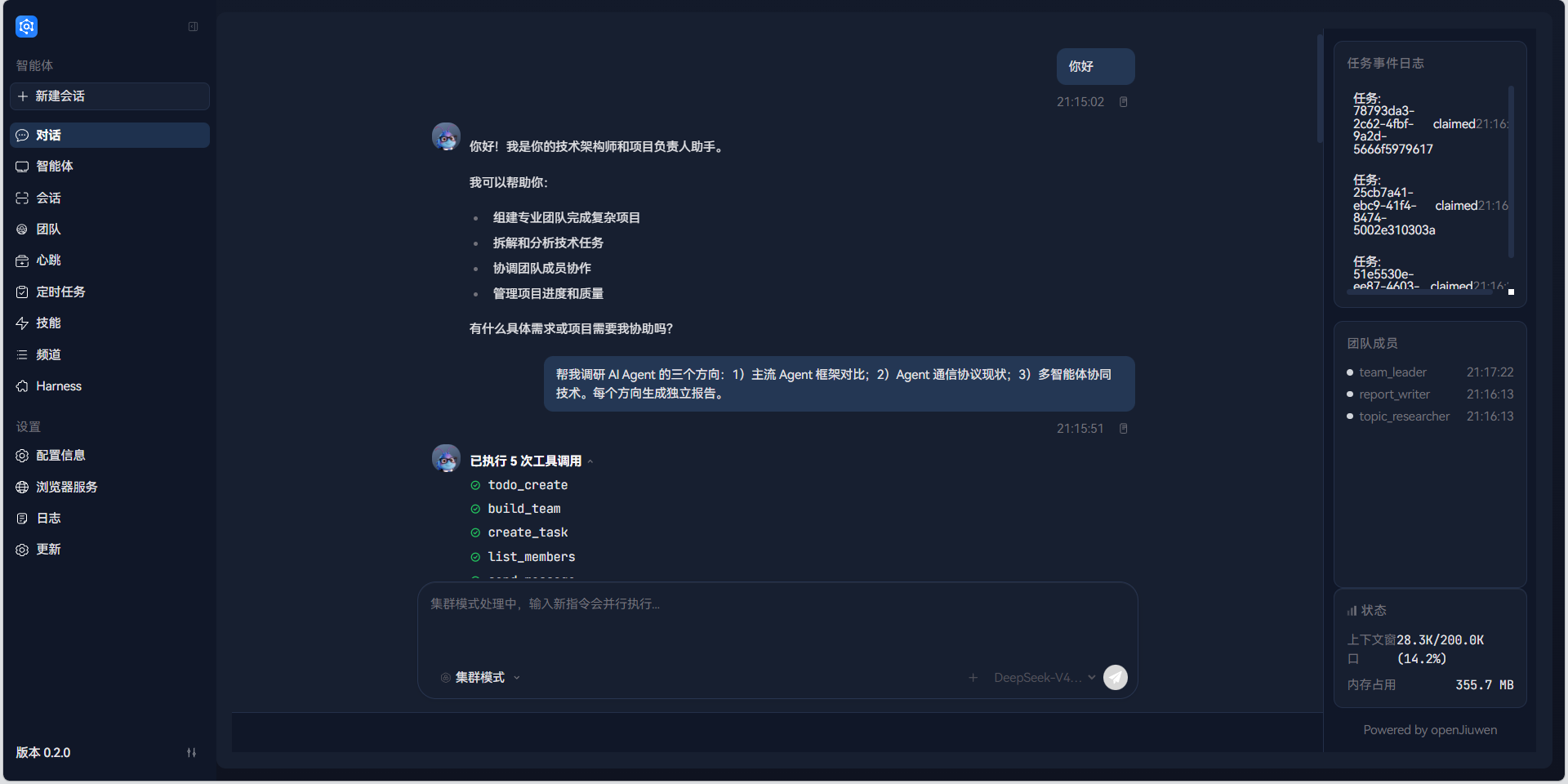
步骤五:执行协作任务
执行一个真实的协作任务:
plain
帮我调研 AI Agent 的三个方向:1)主流 Agent 框架对比;2)Agent 通信协议现状;3)多智能体协同技术。每个方向生成独立报告。团队成员会分工执行搜索、整理和报告撰写工作。如果团队成员遇到工具调用异常(如搜索超时),SignalDetector 会自动捕获这类执行失败作为演进信号。
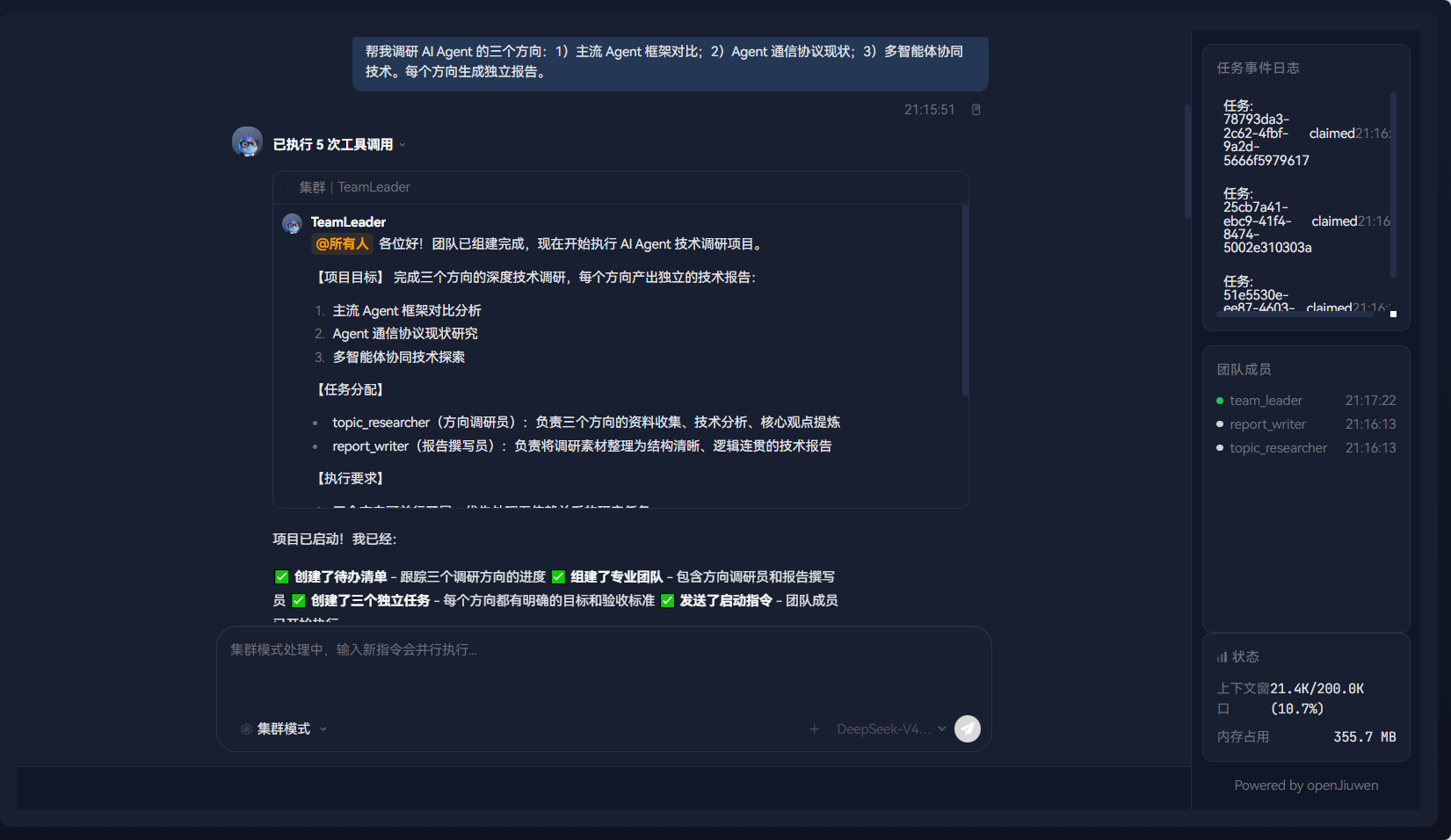
注意:演进信号的生成依赖于真实的执行情况。如果任务顺利完成没有异常,可能不会产生新的演进记录。这是正常现象。
步骤六:触发演进命令
等待团队任务完成后,在聊天输入框输入:
/evolve openJiuwen-DeepSearch 优化搜索策略
步骤七:观察演进结果
后端返回以下之一:
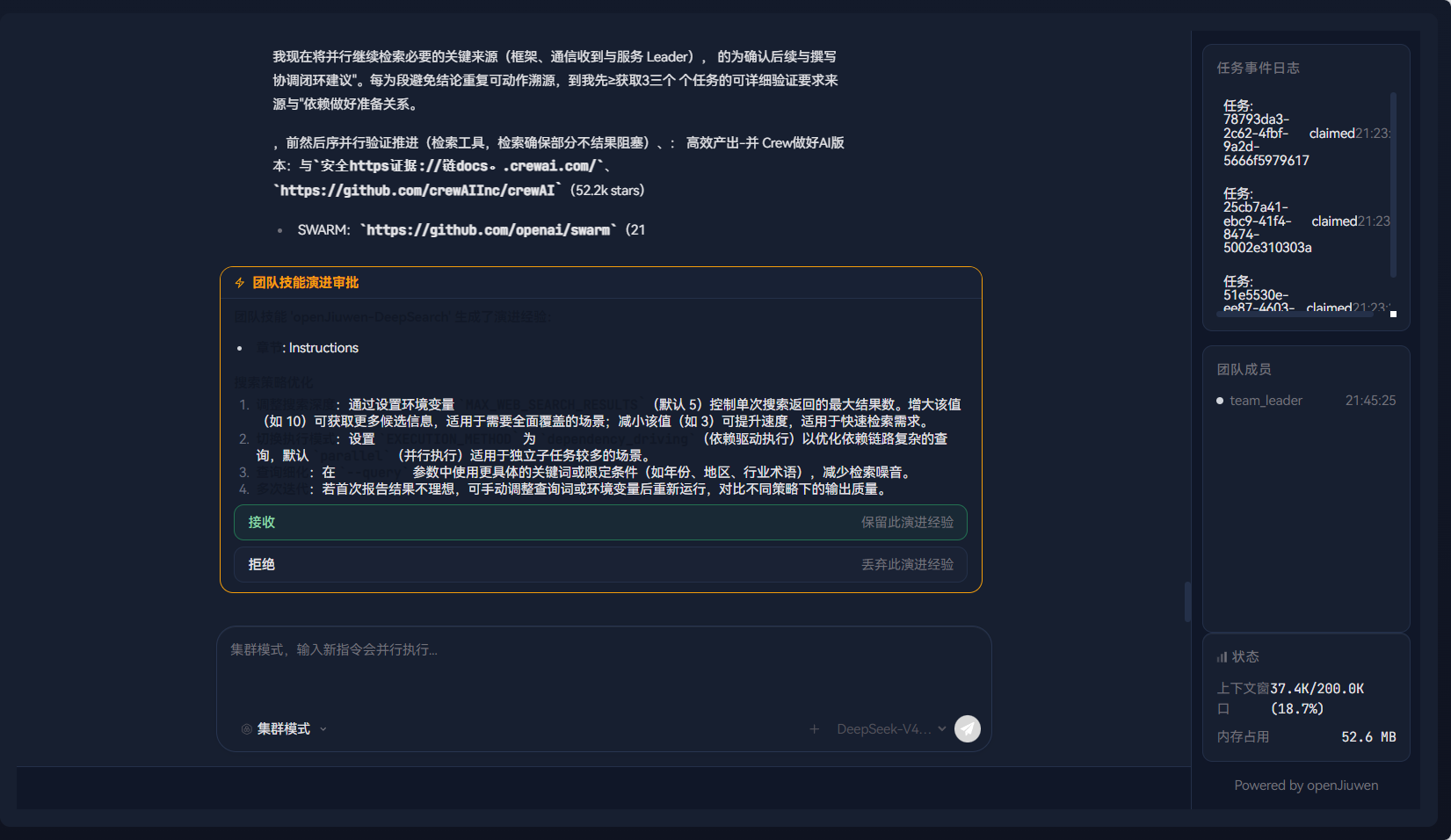
- 有演进信号:生成演进方案并推送确认消息
- 无演进信号 :
<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">Skill 'openJiuwen-DeepSearch' 未生成新的团队技能演进经验。</font>------ 表示在当前任务中未捕获到需要演进的信号,这是正常行为
9.2 场景二:成员层经验积累
目标
观察团队成员在执行任务过程中遇到的问题如何被 SignalDetector 捕获并记录为演进经验。
前置条件
- JiuwenSwarm 已启动(后端+前端)
- 已创建使用 Swarm Skill 的团队
- 团队正在执行任务
步骤一:触发工具执行异常
在团队执行任务时,当某个 Teammate 调用工具(如 <font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">deep-search</font>)出现异常:
plain
[Researcher] 调用 deep-search 查询资料
[SignalDetector] 检测到执行异常: deep-search 返回 Error: API timeout
[SignalDetector] 生成演进信号: ev_xxx (来源: execution_failure)异常会被自动记录,如果启用了自动演进功能(<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">evolution_auto_scan: true</font>),会生成演进记录。
步骤二:查看成员层演进记录
在聊天输入框中输入:
plain
/evolve_list openJiuwen-DeepSearchAgent 会返回该 Skill 的演进经验列表,例如:

步骤三:手动触发成员层演进优化
如果希望进一步优化成员层的经验,可以输入:
plain
/evolve openJiuwen-DeepSearch 优化超时重试逻辑

系统会基于已有的演进记录,生成进一步的优化建议。
十、效果对比与总结
| 维度 | 无自演进 | 有自演进 |
|---|---|---|
| 技能改进 | 人工修改代码后重新部署 | 自动从执行轨迹学习改进 |
| 经验积累 | 每次出错独立记录 | 演进记录持久化,可跨版本合并 |
| 问题追溯 | 日志分散,难以定位 | 完整的演进历史记录 |
| Swarm Skill | 需要手动创建 | 从轨迹自动反推,提交审批入库 |
| 团队协作 | 各自为战,改进无法共享 | 团队层演进可同步到所有成员 |
| 成员成长 | 同类问题反复出现 | 成员层经验积累,避免重复踩坑 |
回顾 JiuwenSwarm 的技能演进设计,几个关键决策值得关注。
演进信号检测机制,让技能能够自动从真实使用中学习。SignalDetector 基于规则工作,不需要调用 LLM,响应速度快,能够及时捕捉执行异常和用户纠错。
evolutions.json 的设计,让演进记录与原始 SKILL.md 分离。演进记录可以先积累、评估,再决定是否固化。这种设计给了管理员充分的控制权,同时保证了技能定义的稳定性。
演进命令的设计 ,区分了不同的使用场景:<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">/evolve</font> 触发演进、<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">/evolve_list</font> 查看经验、<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">/evolve_simplify</font> 整理经验、<font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">/evolve_rebuild</font> 重建文档。对于 Team 场景,还有 <font style="color:rgb(51, 51, 51);background-color:rgb(243, 244, 244);">TeamSkillEvolutionRail</font> 处理团队级演进。
Swarm Skills 自演进的两个层面,让演进既有团队视角的整体优化,也有成员视角的经验沉淀。团队层自动从轨迹反推可复用的 Swarm Skill,成员层积累工具报错、接口超时等实战经验。
总的来说,JiuwenSwarm 的技能演进体系让技能不再是静态定义,而是能够持续进化的"活文档"。演进有记录、经验可积累、团队技能可自动生成------每一层职责清晰,组合起来就是一个可工作的自演进系统。
参考资料: