PPO(Proximal Policy Optimization)是大语言模型(LLM)对齐中主流的强化学习算法,通过裁剪机制稳定策略更新,结合奖励模型(RM)与参考模型(Reference Model)实现人类偏好对齐,典型用于 RLHF 流程(SFT 后微调);但因需同时维护策略、价值(Critic)、奖励和参考四类模型,显存开销大,近年在千亿级模型中正被 GRPO、DPO 等轻量替代。
HRL 优先用
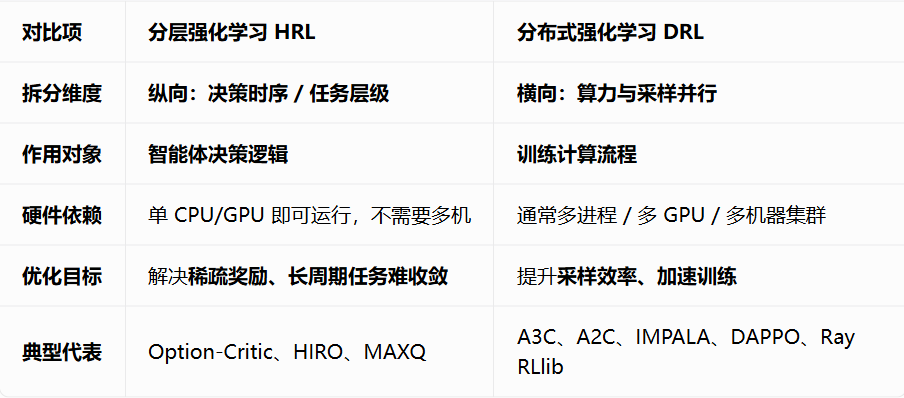
长序列任务:机器人导航、机械臂多步骤组装、游戏闯关(分段完成目标)、奖励稀疏:只有最终成功才有奖励,中间无反馈。解决痛点:长时序稀疏奖励、大动作空间、多阶段复杂任务(导航、机器人操控)。
DRL 优先用
环境交互耗时、需要海量样本:自动驾驶仿真、大规模游戏 AI、大参数量强化学习模型训练。解决痛点:单环境采样慢、训练样本不足、大模型训练耗时过长。
分层强化学习 Hierarchical RL(HRL)从决策逻辑分层,把一个难任务拆成「高层宏观决策 + 低层动作执行」,属于算法层面改进,单卡也能跑。
分布式强化学习 Distributed RL(DRL)从计算资源拆分,多进程 / 多机器并行采集样本、梯度更新,属于工程训练架构,算法本身可以是 DQN/PPO/A3C 任意普通 RL。