 之前写了:SDD+TDD+Harness+Ralph:AI 编程不翻车指南。 今天决定用这套流程开发一个简单的应用练手,我选择让 AI 给撸一个独立开发经典三件套之一的记账软件。
之前写了:SDD+TDD+Harness+Ralph:AI 编程不翻车指南。 今天决定用这套流程开发一个简单的应用练手,我选择让 AI 给撸一个独立开发经典三件套之一的记账软件。
独立开发圈有个梗:十个独立开发者,九个写过 Todo,八个做过记账,七个撸过番茄钟,最后自己一个都不用。
这三类软件都是需求明确,门槛极低,却又是功能完备的极简应用,特别适合做工作流的快速验证。 首先展示一下最终成果:
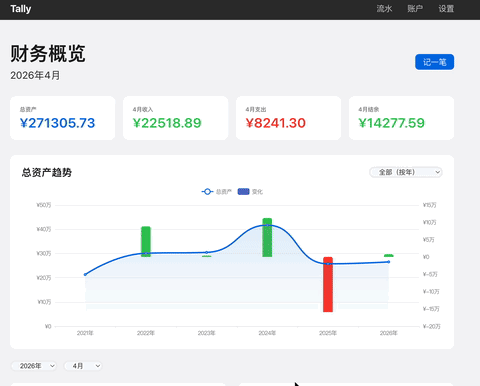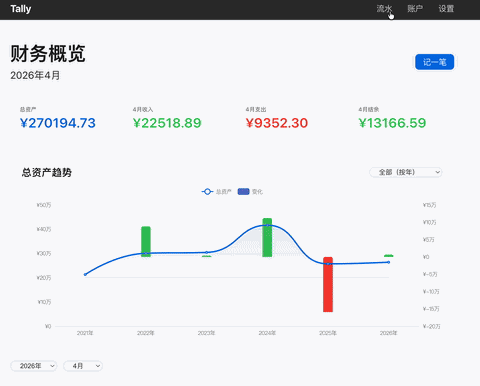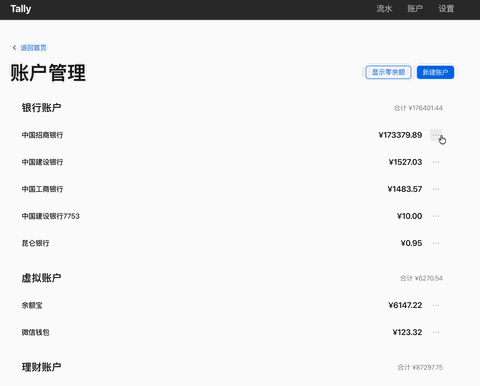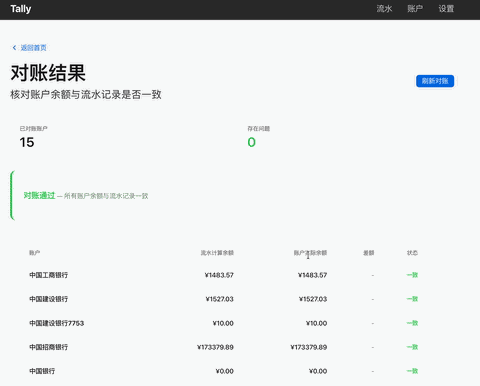
下面就是整个应用 AI 开发的全流程。
01|从几句话到一个规范
首先我写了一个prompt_v1.md 的文件,大致描述了整个应用的大致需求:

文件名带个 v1 标记是因为我最初以为 AI 没那么强,估计要进行多轮的需求确认要迭代多个版本,实际上我小看了 AI 的能力,整个应用开发完只需要这一个版本的需求描述就足够了。
我说:读取prompt_v1.md中我描述的需求,根据 SDD 的编程思想完善一个 spec 出来
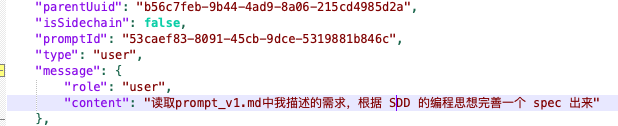
AI 进行了以下工作:
-
读取需求文件,开始编写 SDD 规范
-
brainstorming skill 触发使用头脑风暴技能探索需求
-
按 SDD 思想完善 spec,提出关键问题明确需求
-
AI 针对我没明确的需求提问:是否支持多用户,是否支持预算功能,转账怎么记录,记录一条转账流水还是两条收支流水
-
我明确了单用户版本优先、转账记录一条流水两账户可见、预算功能后续扩展、禁止透支
-
SDD 规范文档已写入 spec.md,涵盖限界上下文(账户/分类/流水/统计)、聚合设计、余额不变量等
令人惊喜的是 AI 没急着动手写代码,而是先问了几个关键问题:
-
是否支持多用户?
-
是否支持预算功能?
-
转账记录成一条流水还是两条?
-
是否允许透支?
我快速回答了这些问题:单用户优先、转账只记一条流水但两账户可见、禁止透支。

很快,AI 生成了一份 1300 多行的 spec.md,里面定义了四层架构、四个聚合(账户/分类/流水/统计)、值对象校验规则、业务不变量(如禁止透支)

这就是 SDD 的核心:先有规范,再写代码。 规范就是 AI 的"施工图纸",没有它,写出来的东西跟你想的可能完全不是一个东西。
02|TDD+Ralph Loop:先写测试,再写代码,循环直至需求完成
规范有了,接下来就是开发。
我说:按照 TDD 的规范实现相关逻辑,可以先列计划然后通过ralph loop 的方式逐步实现整个应用
-
AI: 制定 TDD 实现计划
-
AI: 确认 spec.md 中的 SDD 规范,制定 TDD 实现计划
-
AI: 计划已制定,使用 loop 技能开始 TDD 实现
-
AI: 开始循环1 Account 聚合 TDD 实现
-
AI: 创建项目结构和配置文件
-
AI: 测试已写好,运行测试确认 TDD 红灯阶段
-
AI: 安装依赖
-
AI: 检查并修复测试语法错误
-
AI: 运行测试确认红灯阶段
-
AI: 值对象测试全部通过(37 passed),继续实现 Account 实体;对账/统计500错误修复
-
AI: 循环所有任务直至开发完成
AI 执行循环直至所有规划任务完成
TDD(测试驱动开发)的核心是"红灯-绿灯-重构"循环:
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 🔴 RED │────▶│ 🟢 GREEN │────▶│ 🔵 REFACTOR│
│ 写失败测试 │ │ 最小实现 │ │ 重构代码 │
└─────────────┘ └─────────────┘ └─────────────┘
▲ │
└─────────────────────────────────────────┘
先写一个失败的测试,然后写最少的代码让它通过,最后重构优化。
这个流程看起来"多此一举",但它有一个近乎神奇的效果:代码质量从第一行开始就有保障。
举个例子:
AI 先写了一个 Money 值对象的测试:
def test_money_must_be_positive():
"""金额必须大于0"""
with pytest.raises(ValueError, match="金额必须大于0"):
Money(Decimal("0"))
这时候 Money 类还不存在,测试跑起来当然是红的。
然后 AI 创建了 Money 类,加上校验逻辑:
@dataclass(frozen=True)
class Money:
value: Decimal
def __post_init__(self):
if self.value <= 0:
raise ValueError("金额必须大于0")
测试通过,绿灯。
接着按照Ralph Loop 的方式继续写精度测试、计算测试... 一共 37 个值对象测试 ,全部绿灯。 我说的 Ralph Loop,是一种"自驱动迭代开发模式":
用户指令 ──▶ AI 理解任务 ──▶ 执行一个步骤 ──▶ 自我检查 ──▶ 继续下一步
│ │
└──────────── 循环直到完成 ────────────┘
我给它定好了目标(spec.md),它自己拆解成步骤:
-
循环1:Account 聚合
-
循环2:Category 聚合
-
循环3:Transaction 聚合
-
循环4:统计功能
每个循环里,它自己安排:先建项目结构,再实现值对象,测试通过后继续实体,实体搞定后写仓储...
整个过程我基本没插手。 它每完成一小步,就跑一遍测试,遇到问题自己调整方案------不需要我反复"催促"或"纠正"。
就这样,从值对象到实体、从实体到仓储、从仓储到用例... 一层一层地,158 个测试覆盖了整个核心业务逻辑。
03|成果:一个完整的记账应用
几轮循环下来,应用成型了:
tally/
├── tally/
│ ├── domain/ # 领域层
│ │ ├── model/ # 实体(Account, Category, Transaction)
│ │ ├── value_object/ # 值对象(Money, Balance, AccountType 等)
│ │ ├── service/ # 领域服务
│ │ ├── repository/ # 仓储接口
│ │ └── exception/ # 领域异常
│ ├── application/ # 应用层
│ │ ├── usecase/ # 用例
│ │ └── dto/ # 数据传输对象
│ ├── infrastructure/ # 基础设施层
│ │ ├── persistence/ # SQLite 仓储实现
│ │ └── config/ # 配置
│ └── presentation/ # 表现层
│ ├── cli/ # CLI 命令
│ └── web/ # FastAPI + Jinja2
├── tests/ # 测试
├── .venv/ # 虚拟环境
├── main.py # CLI 入口
├── start_web.sh # WebUI 一键启动脚本
├── import_data.py # 数据导入脚本
├── tally.db # SQLite 数据库
├── spec.md # DDD 规范文档
└── PLAN.md # TDD 实现计划
完成后整个应用能跑通,但是没数据我又让 AI 造了一些数据
数据造完之后就可以开始测试了,测试过程中发现一些 BUG,我之后又进行了几轮沟通
-
前端页面有点丑,按照 WEB_UI_DESIGN.md 风格重新设计页面样式,WEB_UI_DESIGN.md文件是我从 https://getdesign.md/ 下载的苹果网站风格设计说明
-
交易流水查询支持按年、月、账户查询
-
统计功能缺少总资产趋势图,按年或按月显示总资产变化
-
账户列表默认隐藏金额为0的账户加一个按钮可显示隐藏账户
-
账户列表按照账户类别分组显示依次是银行/虚拟/理财/现金账户,每个类别下按余额从大到小排序
-
统计图表总资产趋势图增加显示记账以来总资产趋势图,时间筛选框和其他图表分开单独处理
-
资产分布图表把金额为0的账户过滤掉,金额小于1000的账户合并归类到其他;总资产趋势右侧 Y 轴文字没显示全;顶部导航栏文字太小放大一些
-
首页之外的页面顶部增加返回首页的按钮;账户、流水和分类等页面每个条目的操作按钮隐藏在最后一个小按钮里面点击弹出操作列表;流水页面优化:按日期分组显示、列表主要显示交易类型和金额、交易账户和时间变小字
-
记录支出的时候账户选择列表不显示金额为0的账户
最终的成果就是文章开头看到的一个完成的应用,支持
Web 界面,基础操作和可视化图表:
-
总资产趋势图
-
支出分类饼图
-
月度收支柱状图
-
账户资产分布图
CLI 命令行工具,留给 AI agent 用辅助随手记账:
tally account list # 查看账户
tally transaction expense 1 5 88.5 # 记支出
tally statistics expense # 支出分析
然后我想以后肯定是 AI AGENT 来帮忙操作应用了,所以我又给加了两个需求:
-
写一个脚本可以把本项目的命令行注册到全局命令中,使用 tally 命令就可以执行;注意执行注册时本项目所在目录不是固定的,还需要支持重复执行
-
为当前本项目写一个 agent skill 指导 agent 使用 CLI 帮助记账和基于数据做财务分析等
-
CLI 命令再增加两个:一个是能获取数据库表的 DDL;一个是能执行任意 select SQL(只读)。这俩命令是给 AI agent 用的用来分析数据
随后我把它生成的 tally-cli.md 发给了我的 AI 助手
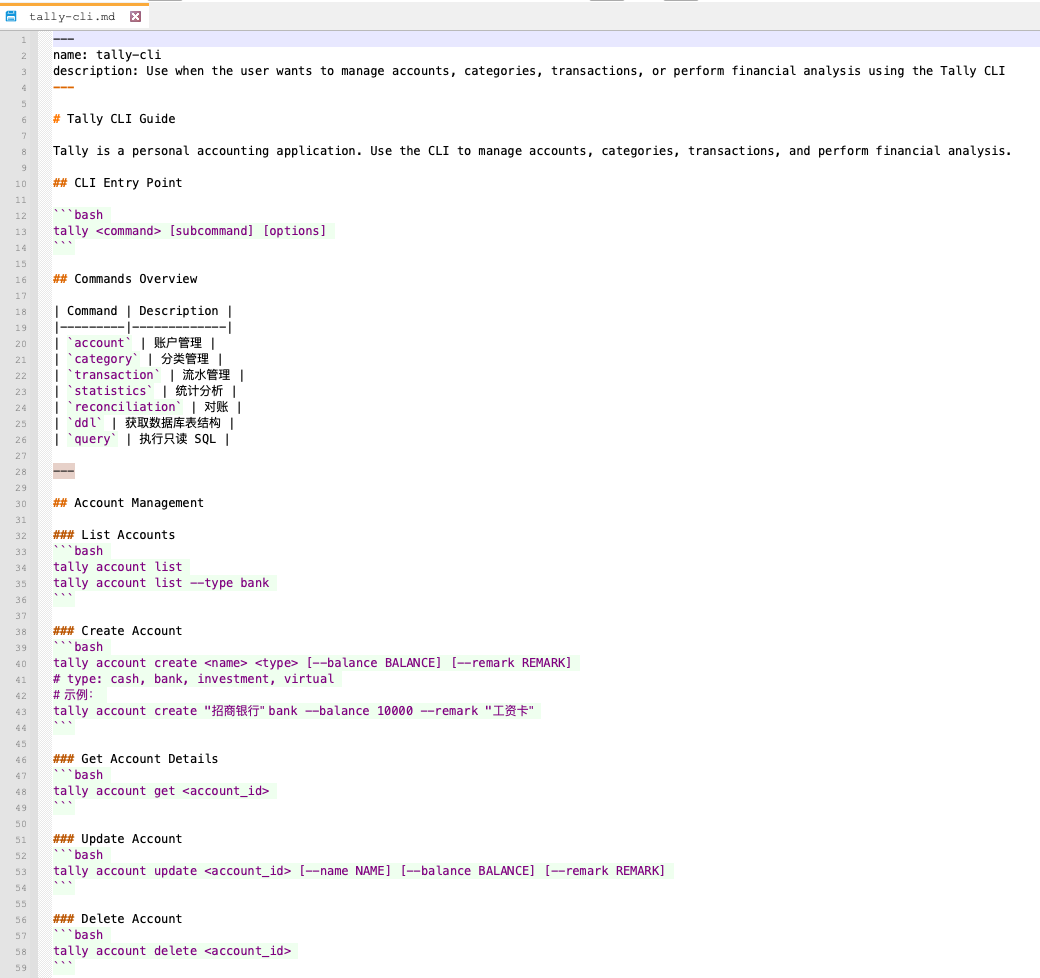
然后我就可以让 AI 助手帮我记账和分析财务数据了
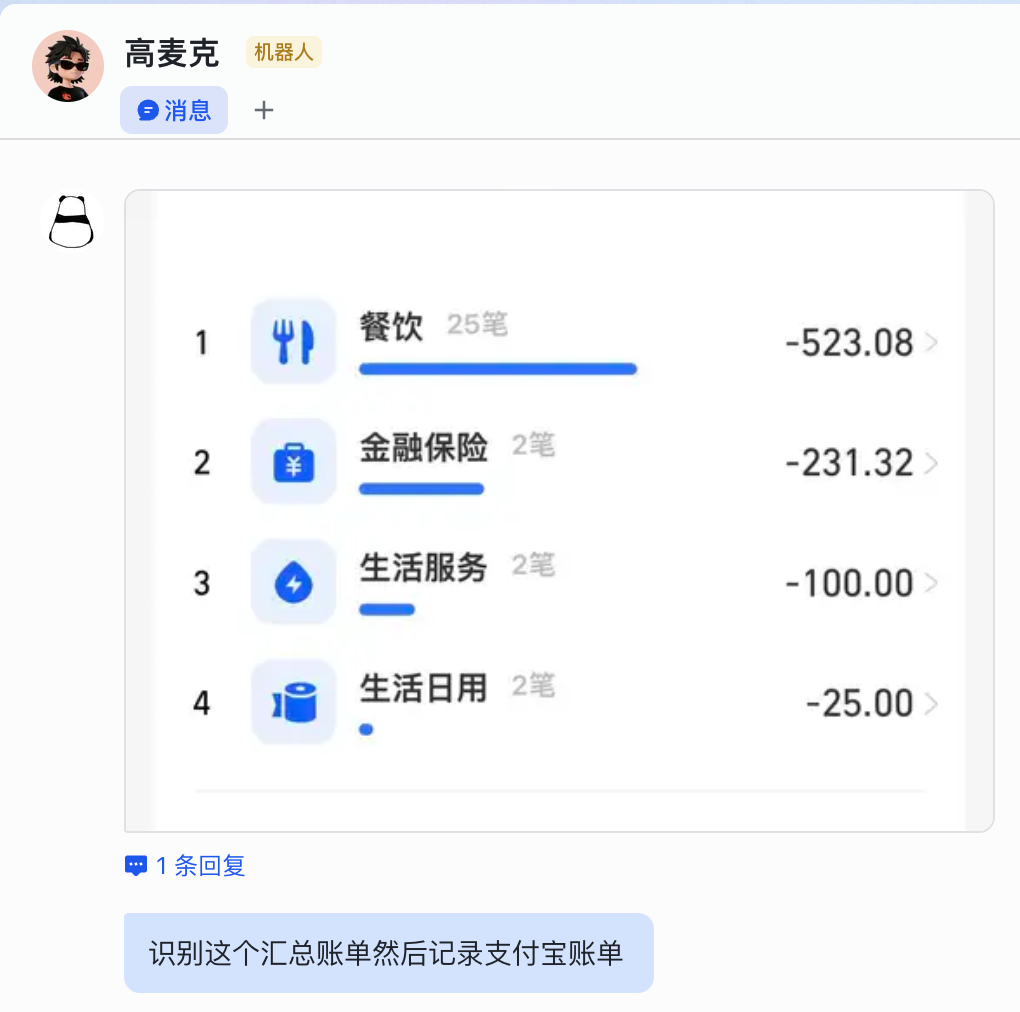
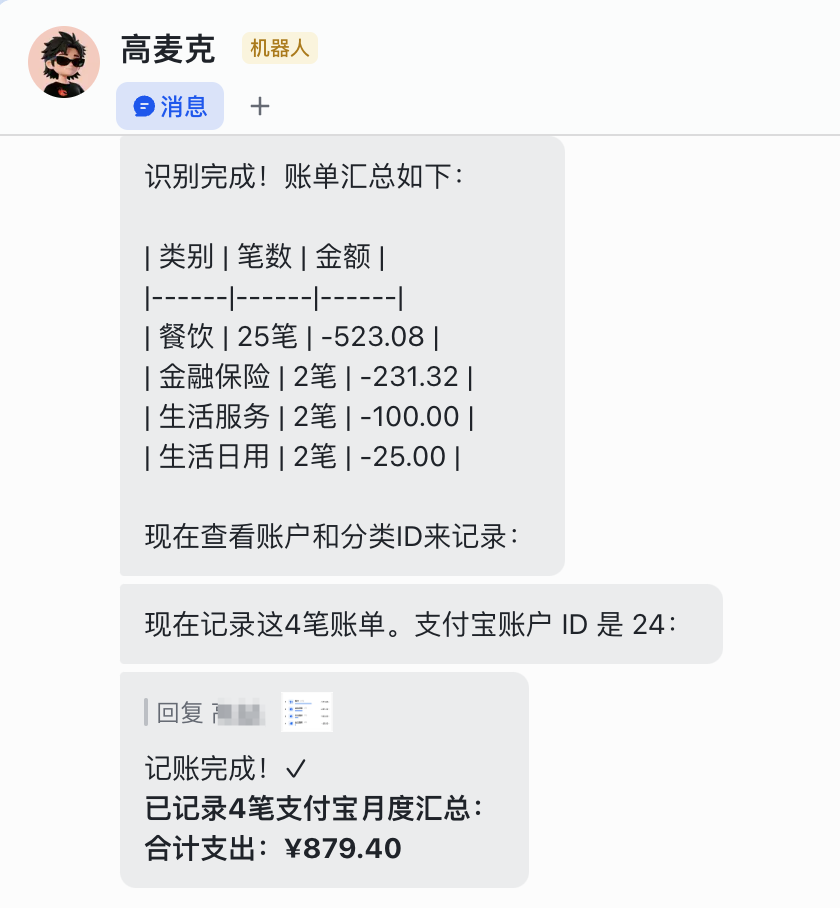
去应用的 WEB 端查看流水,果然记录进去了
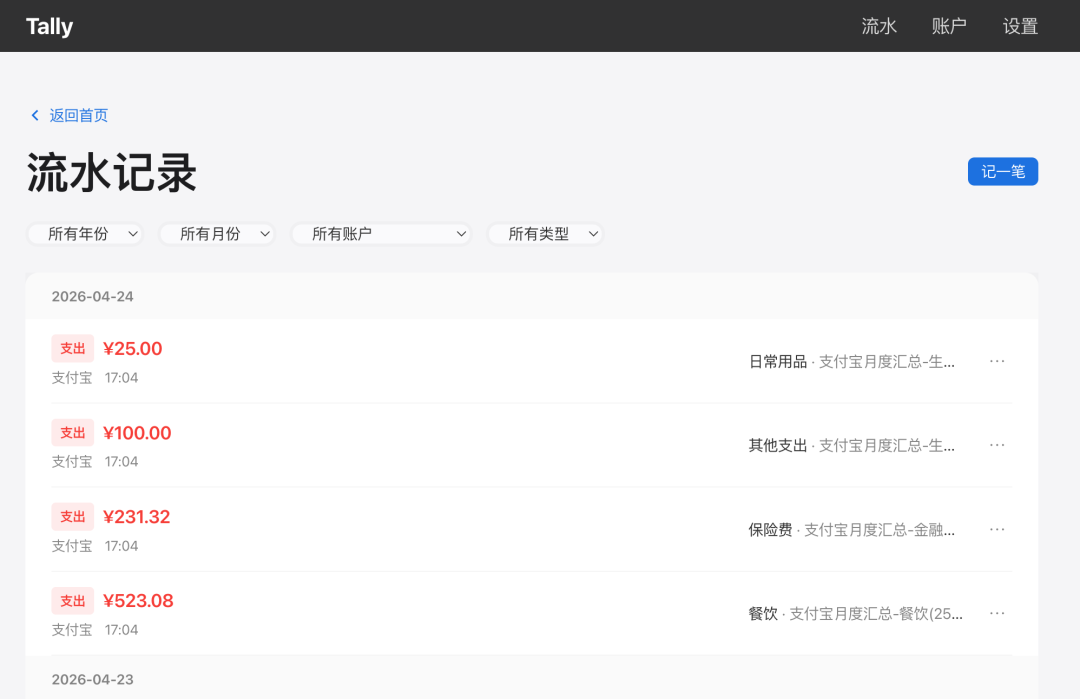
我说给我分析一下今年财务情况
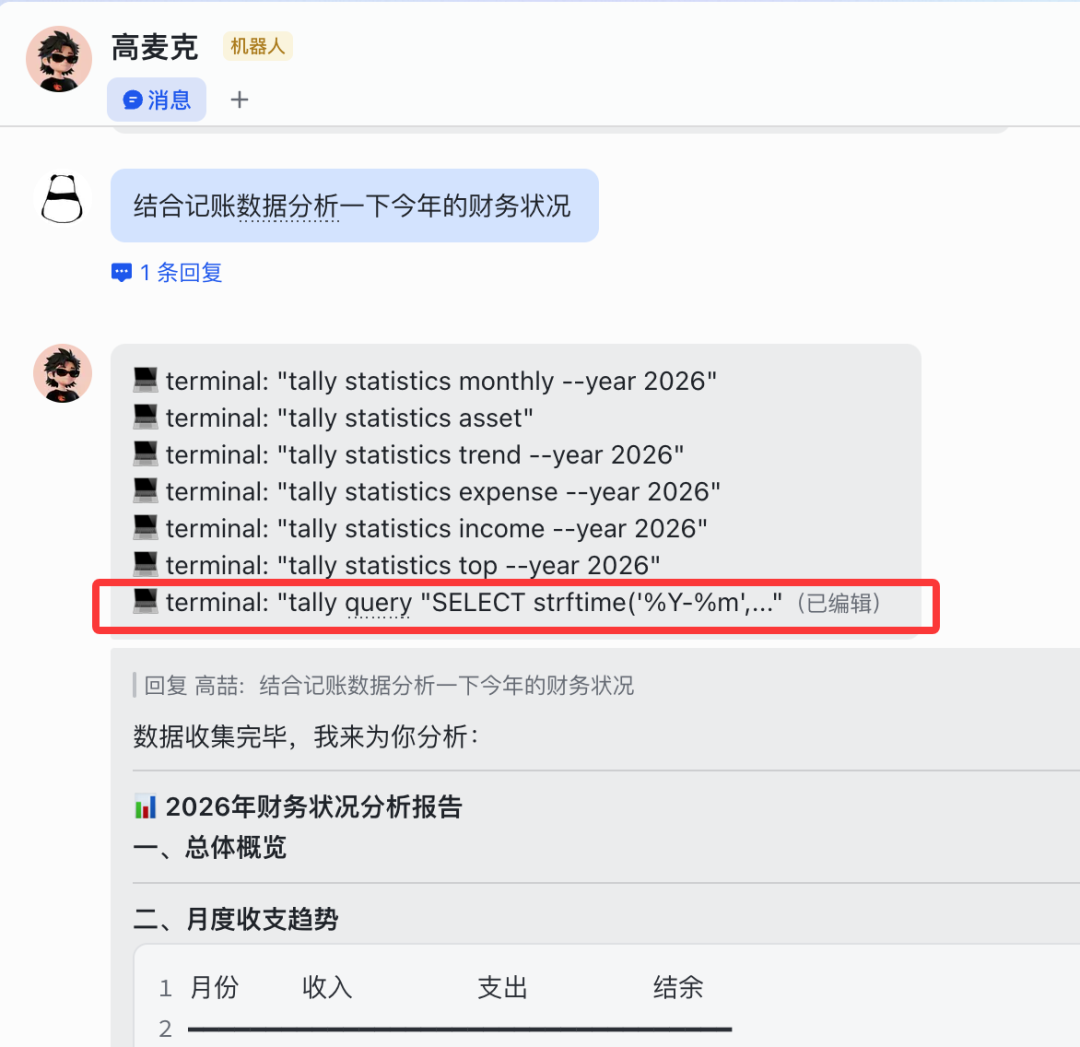
可以看到 AI agent 不光使用 tally 内置统计分析命令获取数据,还自己写了 sql 去分析数据,并给出了完整全面的报告 报告涵盖了:
-
月度收支趋势及趋势解读
-
资产结构分析及风险提示
-
收入稳定性分析
-
财务健康评分
-
改进建议如:建立应急基金,资产配置优化
04|思考:AI 时代,开发方式变了
Ralph Loop 的关键要素
-
明确的目标:SDD 规范(spec.md)定义了最终目标
-
分解计划:按聚合分解为可执行的小步骤
-
自我验证:每步完成后运行测试,确保绿灯
-
状态追踪:维护进度,知道下一步做什么
-
错误恢复:遇到问题时自动调整,不中断循环
实际效果
通过 Ralph Loop + TDD + SDD 的组合:
-
158 个测试覆盖核心业务逻辑
-
4 个聚合清晰划分业务边界
-
10+ 个值对象确保类型安全
-
领域服务封装复杂业务规则
-
从零到完整应用,代码质量由测试保障
TDD 的价值
-
测试即文档,代码即规范
-
快速反馈,立即发现问题
-
重构有信心,测试保驾护航
Ralph Loop 的价值
-
降低认知负担,AI 驱动开发
-
持续验证,确保质量
-
高效迭代,快速交付
二者结合,形成了一个自验证、自文档、高质量的开发流程。
以前写一个应用,我要:
-
设计数据表结构
-
写 CRUD 代码
-
手写前端页面
-
自己测一遍
-
发现 Bug,自己改
现在:
-
描述需求,AI 生成规范
-
下达 TDD + Ralph Loop 指令
-
AI 自己测试、自己迭代
-
我测试,发现问题,AI 修复
省掉了大量"机械重复"的工作。 我不用关心 SQL 语句是否正确、不用一行行写表单校验、不用自己调试泛型报错。
但这不意味着"躺平"。
AI 的能力取决于两件事:
-
规范是否清晰 --- spec.md 写得好,它就不会跑偏
-
测试是否充分 --- TDD 让错误无处藏身
这套流程不是"魔法",而是一种"驾驭":你提供规范和边界,AI 提供执行力和迭代速度。
结尾
从几行描述,到一个完整应用;从 0 测试,到 158 个测试全部通过。
TDD 给了代码"安全感",Ralph Loop 给了开发"效率感"。
这支记账应用不复杂,但它验证了一件事:AI 时代的开发,不再是"一个人扛所有",而是"人定义规范,AI 负责执行"。
下次你想做点什么,试试这套流程。一个 Todo、一个记账、甚至一个小工具... 放手让 AI 跑一跑,你看看它有多能干。