摘要
卷积神经网络(CNNs)近期在各类计算机视觉任务中取得了显著成功,尤其在识别相关的任务中表现尤为突出。然而,光流估计并未成为卷积神经网络取得成功的应用领域之一。在本文中,我们设计了合适的卷积神经网络,将光流估计问题构建为 supervised learning(监督学习)任务。我们提出并比较了两种网络架构:一种为通用架构,另一种则包含一个在不同图像位置之间对特征向量进行相关计算的层。
由于现有的真实数据集规模不足以用于训练卷积神经网络,我们构建了一个合成的"Flying Chairs"数据集。我们表明,在该不真实数据上训练的网络仍能够很好地泛化到现有数据集(如 Sintel 和 KITTI),在 5 到 10 帧每秒的帧率下达到了具有竞争力的精度。
引言
由于尚不清楚是否可以使用标准的卷积神经网络(CNN)架构来解决此任务,我们 additionally 开发了一种带有相关性层(correlation layer)的架构,以显式地提供匹配能力。该架构采用端到端(end-to-end)方式进行训练。其核心思想是利用卷积网络在多个尺度和抽象层次上学习强大特征的能力,并借助这些特征来寻找实际的对应关系。相关性层之上的层负责学习如何从这些匹配中预测光流。令人惊讶的是,以这种方式辅助网络并非必要,甚至原始网络也能以具有竞争力的准确度学习预测光流。
训练此类网络以预测通用光流需要足够庞大的训练集。尽管数据增强有所帮助,但现有的光流数据集仍然太小,不足以训练出与最先进方法相媲美的网络。获取真实视频材料的光流 ground truth 被公认为极其困难7。为了在数量上换取真实性,我们生成了合成数据集"Flying Chairs",该数据集由来自 Flickr 的随机背景图像构成,并在其上叠加了来自文献1的椅子分割图像。这些数据与现实世界几乎没有共同之处,但我们可以生成任意数量且具有自定义属性的样本。仅使用这些数据训练的 CNN 竟然能够很好地泛化到真实数据集,即使不进行微调也是如此。
利用 CNN 高效的 GPU 实现,我们的方法比大多数竞争方法更快。我们的网络在 Sintel 数据集的全分辨率下,每秒可预测高达 10 对图像的光流,在实时方法中达到了最先进的准确度。
2. 相关工作
光流。自 Horn 和 Schunck 19 的工作以来,变分方法一直主导着光流估计领域。此后引入了许多改进29, 5, 34。最近的研究重点在于大位移,组合匹配已被整合到变分方法中6, 35。文献35提出的 Deep-Matching 和 DeepFlow 与我们的工作相关,因为它们使用稀疏卷积和最大池化,将特征信息从细粒度到粗粒度进行聚合。然而,这些方法不进行任何学习,所有参数均手动设置。随后的 EpicFlow 工作30进一步强调了稀疏匹配的质量,因为文献35中的匹配仅被插值到稠密流场中,同时尊重图像边界。我们仅在可选情况下使用变分方法来细化卷积网络预测的流场,不需要任何手工设计的聚合、匹配和插值方法。
几位作者此前已将机器学习技术应用于光流。Sun 等人32研究光流的统计特性,并使用高斯尺度混合模型学习正则化项;Rosenbaum 等人31用高斯混合模型对光流的局部统计进行建模。Black 等人4计算流场训练集的主成分。为了预测光流,他们随后估计这些"基础流"线性组合的系数。其他方法训练分类器以在不同的惯性估计中选择21,或获得遮挡概率27。
已有研究利用神经网络模型无监督地学习视频帧之间的视差或运动。这些方法通常使用乘法相互作用来建模一对图像之间的关系。然后可以从潜在变量中推断出视差和光流。Taylor 等人33采用因子化门控受限玻尔兹曼机器来解决该任务。Konda 和 Memisevic 23 使用一种称为"同步自编码器"的特殊自编码器。虽然这些方法在受控环境下工作良好,并学习了用于视频活动识别的有用特征,但它们在处理真实视频时并不具备与传统方法相竞争的竞争力。
3. 网络架构
卷积网络。Krizhevsky 等人 24 最近表明,通过反向传播 25 训练的卷积神经网络在大规模图像分类任务中表现优异。这引发了将卷积神经网络(CNN)应用于各种计算机视觉任务的研究热潮。
尽管目前尚无使用卷积神经网络估计光流的工作,但已有基于神经网络进行特征匹配的研究。Fischer 等人 12 从以监督或非监督方式训练的卷积神经网络中提取特征表示,并基于欧氏距离对这些特征进行匹配。Zbontar 和 LeCun 36 采用孪生网络结构训练卷积神经网络,以预测图像块之间的相似性。这些方法与本文方法的显著区别在于,它们是建立在图像块基础上的,并将空间聚合留待后处理完成,而本文中的网络则直接预测完整的光流场。
卷积神经网络的近期应用包括语义分割 11, 15, 17, 28、深度预测 10、关键点预测 17 以及边缘检测 13。这些任务与光流估计类似,都涉及逐像素的预测。由于我们的网络架构在很大程度上借鉴了这些逐像素预测任务的最新进展,我们在此简要回顾不同的方法。
最简单的解决方案是以"滑动窗口"的方式应用传统的卷积神经网络,从而为每个输入图像块计算单个预测结果(例如类别标签)8, 11。这种方法在许多情况下表现良好,但存在缺点:计算成本高(即使采用涉及中间特征图复用的优化实现),以及基于图像块的本质特性,无法考虑全局输出属性,例如锐利边缘。另一种简单的方法 17 是将所有特征图上采样至期望的全分辨率,并将它们堆叠在一起,从而形成一个拼接的逐像素特征向量,可用于预测目标值。
Eigen 等人 10 通过训练一个额外的网络来细化粗粒度深度图,该网络的输入包括粗粒度预测结果和原始输入图像。Long 等人 28 和 Dosovitskiy 等人 9 则利用"上卷积层"迭代细化粗粒度特征图¹。我们的方法融合了这两种工作的思想。与 Long 等人不同,我们不仅对粗粒度预测结果进行上卷积,还对整个粗粒度特征图进行上卷积,从而能够将更多高层信息传递至细粒度预测阶段。与 Dosovitskiy 等人不同,我们进行拼接将"上采样卷积"的结果与网络"收缩"部分的特征进行整合。
卷积神经网络在拥有足够的标注数据的情况下,被证明非常擅长学习输入--输出关系。因此,我们采用端到端的学习方法来预测光流:给定由图像对和真实光流组成的数据集,我们训练网络直接从图像中预测 x--y 方向的光流场。但什么样的架构适合这一目的呢?
一种简单的选择是将两幅输入图像堆叠在一起,并传入一个相对通用的网络,让网络自行决定如何处理图像对以提取运动信息。这如图 2(顶部)所示。我们将这种仅由卷积层组成的架构称为"FlowNetSimple"。
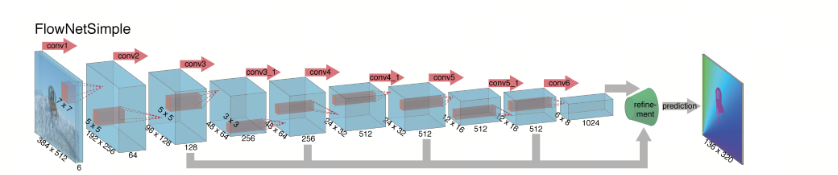
原则上,如果该网络足够大,它本应能够学会预测光流。然而,我们永远无法保证像随机梯度下降这样的局部梯度优化算法能够将网络训练至该状态。因此,设计一种虽然通用性较低、但在给定数据和优化技术下表现可能更好的架构或许更为有益。
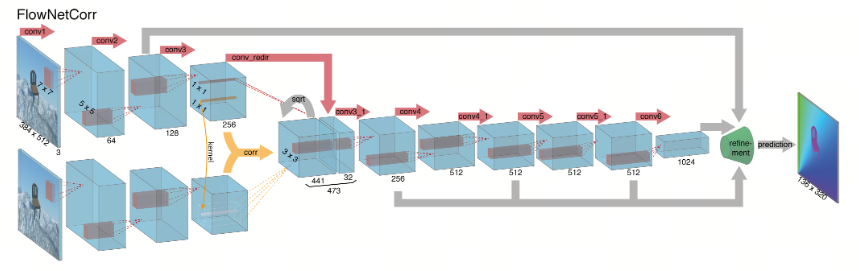
一个直接的步骤是为两幅图像创建两个独立但相同的处理流,并在后续阶段将其合并,如图 2(底部)所示。通过这种架构,网络被约束为首先分别生成两幅图像的意义明确的表示,然后在更高层级上将它们结合。这大致类似于传统的匹配方法:先从两幅图像的块中提取特征,然后比较这些特征向量。然而,给定两幅图像的特征表示后,网络如何找到对应关系呢?
为了协助网络完成这一匹配过程,我们引入了一种"相关性层"(correlation layer),用于在两个特征图之间执行乘法式的块比较。包含该层的网络架构"FlowNetCorr"的示意图如图 2(底部)所示。给定两个多通道特征图 f1, f2 : R² → Rᶜ,其中 w、h 和 c 分别为它们的宽度、高度和通道数,我们的相关性层允许网络将 f1 中的每个块与 f2 中的每个块进行比较。
目前,我们仅考虑两个块之间的单次比较。第一个特征图中以 x1 为中心、第二个特征图中以 x2 为中心的两个块之间的"相关性"定义为:
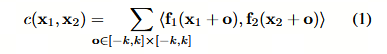
其中块的尺寸 K := 2k + 1 为正方形。请注意,公式 (1) 与神经网络中卷积的一步操作相同,但这里不是用滤波器对数据进行卷积,而是用数据对数据进行卷积。因此,它没有可训练的参数。
计算 c(x1, x2) 涉及 c · K² 次乘法运算。比较所有块组合需要进行 w² · h² 次此类计算,产生的结果规模庞大,使得高效的前向和反向传播变得不可行。因此,为了计算出于计算效率的考虑,我们在比较时限制最大位移,并在特征图中引入步长(stride)。给定最大位移 ddd,对于每个位置 x1x_1x1,我们通过限制 x2x_2x2 的范围,仅在大小为 D:=2d+1D := 2d + 1D:=2d+1 的邻域内计算相关性 c(x1,x2)c(x_1, x_2)c(x1,x2)。我们使用步长 s1s_1s1 和 s2s_2s2 分别对全局的 x1x_1x1 和以 x1x_1x1 为中心的邻域内的 x2x_2x2 进行量化。
理论上,相关性操作产生的结果是四维的:对于每一对 2D 位置组合,我们得到一个相关值,即分别包含裁剪补丁值的两个向量的标量积。在实践中,我们将相对位移组织在通道中。这意味着我们得到的输出大小为 (w×h×D2)(w \times h \times D^2)(w×h×D2)。在反向传播过程中,我们相应地实现了针对每个底部输入张量(bottom blob)的导数。
细化(Refinement)。
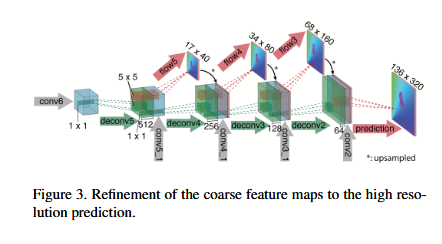
卷积神经网络(CNN)通过交替使用卷积层和池化层(即空间上缩小特征图),擅长提取图像的高层抽象特征。池化对于使网络训练在计算上可行是必要的,更根本地说,是为了允许在输入图像的大面积上聚合信息。然而,池化会导致分辨率降低,因此为了提供密集的逐像素预测,我们需要一种方法来细化粗糙的池化表示。
我们用于细化的方法如图 3 所示。其主要组件是"上卷积"(upconvolutional)层,由反池化(扩展特征图,与池化相反)和卷积组成。此类层此前已被使用过 38, 37, 16, 28, 9。为了执行细化,我们将"上卷积"应用于特征图,并将其与网络"收缩"部分对应的特征图以及上采样后的较粗光流预测(如果可用)进行拼接。通过这种方式,我们既保留了从较粗特征图传递的高层信息,又保留了来自较低层特征图的精细局部信息。每一步都将分辨率提高两倍。我们重复此过程 4 次, resulting in a predicted flow for which the resolution is still 4 times smaller than the input.
我们发现,与此分辨率相比,进一步的细化并不会显著提高结果,其效果不如计算成本更低的双线性上采样至全图像分辨率。双线性上采样的结果即为网络预测的最终光流。
在一种替代方案中,我们不使用双线性上采样,而是使用文献 6 中的变分方法 (不含匹配项):我们从 4 倍下采样的分辨率开始,然后使用粗到细的方案进行 20 次迭代,将光流场提升至全分辨率。最后,我们在全图像分辨率上再运行 5 次迭代。我们还采用文献 26 中的方法计算图像边界,并通过将平滑系数替换为 α=exp(−λb(x,y)κ)\alpha = \exp(-\lambda_b(x, y)\kappa)α=exp(−λb(x,y)κ) 来尊重检测到的边界,其中 b(x,y)b(x, y)b(x,y) 表示在相应尺度及像素之间重采样的薄边界强度。这种上采样方法比简单的双线性上采样计算成本更高,但它增加了变分方法的优势,从而获得平滑且亚像素精度的光流场。在下文中,我们用后缀"+v"表示通过这种变分细化获得的结果。变分细化的一个例子如图 4 所示。

图 4. 变分细化的效果。在运动较小的情况下(第一行),预测的光流发生了显著变化。对于较大的运动(第二行),大误差不被纠正,但光流场被平滑,从而导致更低的 EPE(端点误差)。
数据集
4.1. 现有数据集
Middlebury 数据集 2 仅包含 8 对图像用于训练,其真值光流通过四种不同的技术生成。位移量非常小,通常低于 10 像素。
KITTI 数据集 14 规模更大(194 对训练图像),包含较大的位移量,但仅包含一种非常特殊的运动类型。真值是通过同时使用相机和 3D 激光扫描仪拍摄真实世界场景获得的。这种方法假设场景是刚性的,且运动源于移动的观察视角。此外,它无法捕捉远处物体(如天空)的运动,导致生成的光流真值较为稀疏。
MPI Sintel 7 数据集的真值来自渲染的人工场景,并特别注重逼真的图像属性。该数据集提供两个版本:Final 版本包含运动模糊和大气效果(如雾气),而 Clean 版本则不包含这些效果。Sintel 是目前可用的最大数据集(每个版本包含 1,041 对训练图像),并为小位移和大位移幅度提供了稠密真值。
4.2. Flying Chairs
Sintel 数据集对于训练大型卷积神经网络(CNN)来说仍然太小。为了提供足够的训练数据,我们创建了一个简单的合成数据集,命名为 Flying Chairs。该数据集通过对从 Flickr 收集的图像以及一个公开可用的 3D 椅子模型渲染集 1 应用仿射变换而生成。
我们从 Flickr2 检索了 964 张图像,分辨率为 1,024 × 768,类别包括"城市"(321 张)、"风景"(129 张)和"山脉"(514 张)。我们将这些图像切成四个象限,并使用生成的 512 × 384 图像裁剪部分作为背景。作为前景物体,我们将 1 中的多把椅子图像叠加到背景上。我们从原始数据集中移除了非常相似的椅子,最终得到 809 种椅子类型和每把椅子的 62 个视角。示例如图 5 所示。
为了生成运动,我们随机采样背景和椅子的仿射变换参数。椅子的变换是相对于背景变换而言的,这可以被解释为相机和物体同时在移动。利用这些变换参数,我们渲染第二张图像、光流以及遮挡区域。
每对图像的所有参数(椅子的数量、类型、尺寸和初始位置;变换参数)均随机采样。我们调整这些参数的随机分布,使得生成的位移直方图与 Sintel2 的直方图相似。
2 非商业公共许可证。我们使用 Hays 和 Efros 18 的代码框架(详细信息可在补充材料中找到)。
使用此过程,我们生成了一个包含 22,872 对图像及光流场的数据集(我们多次重用每个背景图像)。请注意,此规模是随意选择的,原则上可以更大。
4.3. 数据增强
提高神经网络泛化能力的广泛使用策略是数据增强 24, 10。尽管 Flying Chairs 数据集相当大,但我们发现使用增强技术对于避免过拟合至关重要。我们在网络训练过程中在线执行数据增强。我们使用的增强操作包括几何变换:平移、旋转和缩放,以及加性高斯噪声以及亮度、对比度、伽马值和颜色的变化。为了保证速度合理,所有这些操作均在 GPU 上处理。数据增强的一些示例见图 5。
由于我们不仅希望增加图像的多样性,还希望增加光流场的多样性,我们对每对图像中的两张图像应用相同的强几何变换,但在两张图像之间额外应用较小的相对变换。我们通过对光流场分别应用针对每张图像的增强操作来相应地调整光流场。
具体而言,我们在图像宽度的 -20%, 20% 范围内随机采样 x 和 y 方向的平移量;旋转角度从 -17°, 17° 中采样;缩放比例从 0.9, 2.0 中采样。高斯噪声的标准差从 0, 0.04 中均匀采样;对比度从 -0.8, 0.4 中采样;每张图像 RGB 通道的乘性颜色变化从 0.5, 2 中采样;伽马值从 0.7, 1.5 中采样;加性亮度变化使用标准差为 0.2 的高斯分布进行生成。
6. 结论
基于最近在卷积网络架构设计方面的进展,我们证明,能够训练网络从两幅输入图像中直接预测光流。有趣的是,训练数据无需具备真实性。仅包含合成刚体仿射运动的"Flying Chairs"人工数据集,就足以在自然场景中以具有竞争力的精度预测光流。这证明了所提出网络的泛化能力。在Flying Chairs测试集上,卷积神经网络甚至优于DeepFlow和EpicFlow等当前最先进的方法。随着更逼真的训练数据逐渐可用,观察未来网络的性能将是一件有趣的事。
站在2026看这个论文
站在 2026年 的视角回望这篇发表于2015年的开山之作《FlowNet: Learning Optical Flow with Convolutional Networks》(作者:Nikolaus Mayer等),我们不仅是在回顾一段历史,更是在审视现代计算机视觉基石的诞生时刻。
以下是从2026年角度对这篇论文及其深远影响的深度回顾:
历史地位:光流估计的"奇点"
在2015年之前,光流估计(Optical Flow Estimation)是传统计算机视觉的堡垒,由变分方法(如Horn-Schunck)、光流一致性(Lucas-Kanade)以及后来的基于优化的方法(如DeepFlow, EpicFlow)主导。这些方法依赖手工设计的特征、平滑假设和复杂的迭代优化,计算成本高且难以并行化。
FlowNet的革命性在于它首次证明了端到端(End-to-End)的深度学习可以直接解决稠密预测任务。
- 从"特征工程"到"特征学习":它打破了必须人工设计特征或正则项的范式,让网络自动学习从像素到运动场的映射。
- 实时性的愿景:虽然2015年的5-10 fps在今天看来很慢,但在当时,它证明了光流预测可以比基于优化的迭代方法快几个数量级,为实时视频理解打开了大门。
核心洞察的验证:合成数据的泛化魔力
论文中最令人惊叹的洞察------"无需真实标签,合成数据即可训练"------在随后的十年中被反复验证并深化。
- Flying Chairs 的意义:当时Sintel和KITTI数据量太小,无法训练深层CNN。作者创造性地使用随机生成的仿射变换椅子构建合成数据。
- 2026年的反思 :这一策略奠定了现代视觉模型的训练范式。现在的基座模型(如Segment Anything, DINOv2, 以及最新的视觉Transformer变体)几乎都依赖大量合成数据或自监督数据预训练。FlowNet是这一思想的先驱,它证明了域适应(Domain Adaptation)和泛化能力可以通过合理的合成数据分布来弥补真实数据的稀缺。
架构遗产:FlowNet 系列与后续演进
FlowNet提出的两种架构(FlowNetSimple 和 FlowNetCorr)成为了后续所有光流网络的基础模板:
- 编码器-解码器结构(Encoder-Decoder):FlowNet 使用的下采样(Pooling)和上采样(Upconvolution/Transposed Conv)结构,直接影响了后来的DeepLab(分割)、U-Net(医学图像)以及RAFT、PWC-Net(光流)等架构。
- 相关层(Correlation Layer) :这是FlowNet最具技术含量的贡献之一。它用可微的互相关操作替代了传统的匹配代价体积(Cost Volume)计算。
- 2026年视角 :虽然现在的SOTA模型(如RAFT)更多使用"迭代细化(Iterative Refinement)"和"注意力机制(Attention)",甚至使用不同的匹配策略(如Dot-product Matching),但互相关层依然是立体匹配(Stereo Matching)和光流估计的标准操作原语(Primitive)。任何现代光流网络如果不包含某种形式的显式匹配模块,几乎是不完整的。
- 变分细化(Variational Refinement):FlowNet提出在最后阶段使用传统变分方法细化CNN输出,这是一种"混合范式"。虽然现在的SOTA(如RAFT)更倾向于完全可微的迭代更新(Differentiable Iterative Update),但这种"粗到细(Coarse-to-Fine)"的推理思想被完整继承了下来。