摘要
TAPIR(Tracking Any Point with per-frame Initialization and temporal Refinement)由Google DeepMind提出,是一个能够在视频中跟踪任意物理表面点的模型。其核心设计是两阶段管线:第一阶段通过全局匹配逐帧独立初始化候选轨迹,第二阶段通过局部相关性的时序深度卷积网络迭代精炼。在TAP-Vid benchmark上,TAPIR在DAVIS数据集上实现~20% AJ绝对提升(61.3 vs PIPs 42.0),同时比PIPs快120倍。论文发表于ICCV 2023。
论文 :TAPIR: Tracking Any Point with per-frame Initialization and temporal Refinement
一、问题背景
点跟踪(Point Tracking)的目标是:给定视频中某一帧的一个查询点 ( x , y , t ) (x, y, t) (x,y,t),预测该物理表面点在所有其他帧中的位置以及可见性。
现有方法的局限:
- TAP-Net(2022):全局匹配一次性输出,无时序精炼,精度受限于低分辨率特征
- PIPs(Persistent Independent Particles):通过"Chaining"在时间块间传递跟踪,但速度极慢(50帧需34.5秒),且MLP-Mixer架构需要固定时间块长度
TAPIR的核心洞察:将TAP-Net的全局初始化能力与PIPs的局部精炼能力结合,同时用全卷积替代MLP-Mixer消除块处理的瓶颈。
二、核心方法
2.1 整体架构
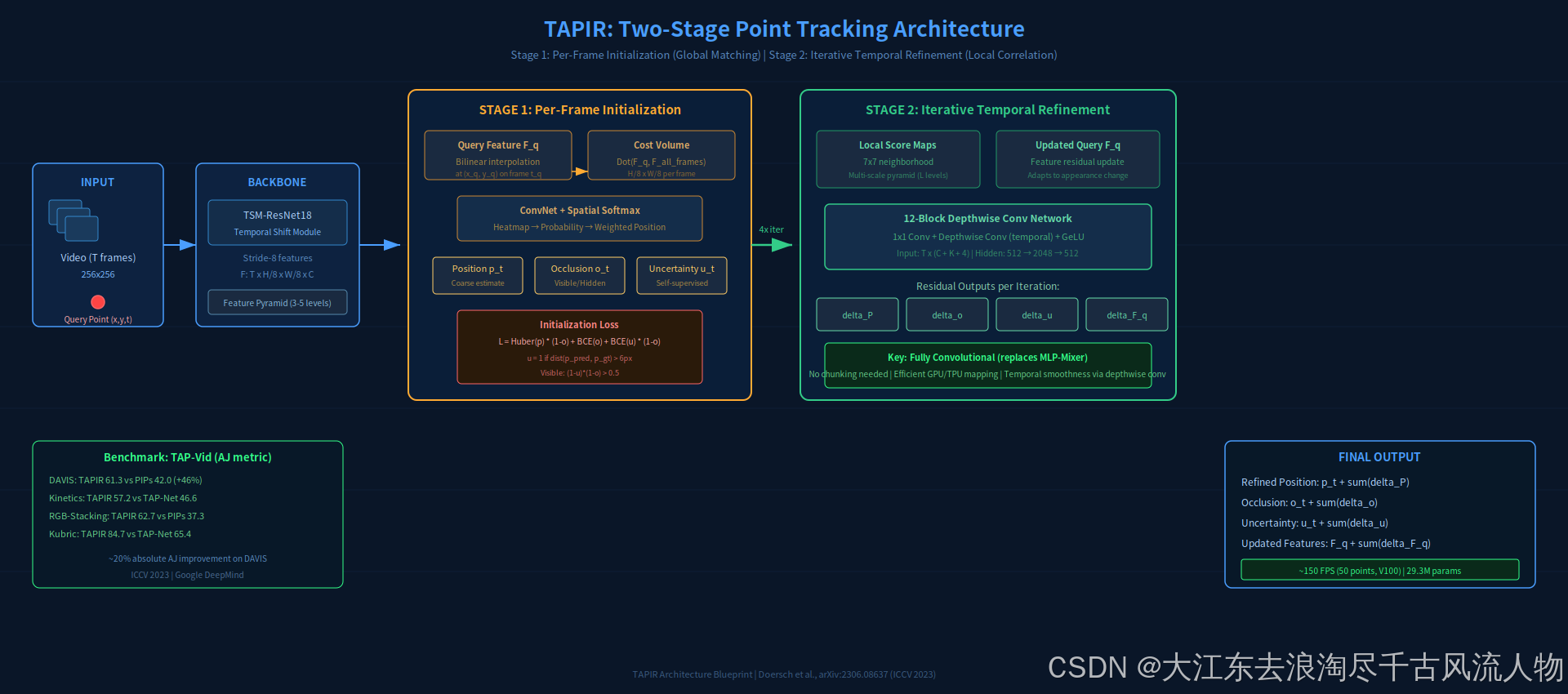
图 1:TAPIR两阶段架构。重点看Stage 2的迭代精炼------12层深度卷积网络输出位置/遮挡/不确定性/特征四路残差,迭代4次收敛。来源:重绘自 design skill
#mermaid-svg-Udw3dg1jvXzekoW1{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-Udw3dg1jvXzekoW1 .error-icon{fill:#552222;}#mermaid-svg-Udw3dg1jvXzekoW1 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-Udw3dg1jvXzekoW1 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-Udw3dg1jvXzekoW1 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-Udw3dg1jvXzekoW1 .marker.cross{stroke:#333333;}#mermaid-svg-Udw3dg1jvXzekoW1 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-Udw3dg1jvXzekoW1 p{margin:0;}#mermaid-svg-Udw3dg1jvXzekoW1 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster-label text{fill:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster-label span{color:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster-label span p{background-color:transparent;}#mermaid-svg-Udw3dg1jvXzekoW1 .label text,#mermaid-svg-Udw3dg1jvXzekoW1 span{fill:#333;color:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 .node rect,#mermaid-svg-Udw3dg1jvXzekoW1 .node circle,#mermaid-svg-Udw3dg1jvXzekoW1 .node ellipse,#mermaid-svg-Udw3dg1jvXzekoW1 .node polygon,#mermaid-svg-Udw3dg1jvXzekoW1 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-Udw3dg1jvXzekoW1 .rough-node .label text,#mermaid-svg-Udw3dg1jvXzekoW1 .node .label text,#mermaid-svg-Udw3dg1jvXzekoW1 .image-shape .label,#mermaid-svg-Udw3dg1jvXzekoW1 .icon-shape .label{text-anchor:middle;}#mermaid-svg-Udw3dg1jvXzekoW1 .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-Udw3dg1jvXzekoW1 .rough-node .label,#mermaid-svg-Udw3dg1jvXzekoW1 .node .label,#mermaid-svg-Udw3dg1jvXzekoW1 .image-shape .label,#mermaid-svg-Udw3dg1jvXzekoW1 .icon-shape .label{text-align:center;}#mermaid-svg-Udw3dg1jvXzekoW1 .node.clickable{cursor:pointer;}#mermaid-svg-Udw3dg1jvXzekoW1 .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-Udw3dg1jvXzekoW1 .arrowheadPath{fill:#333333;}#mermaid-svg-Udw3dg1jvXzekoW1 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-Udw3dg1jvXzekoW1 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-Udw3dg1jvXzekoW1 .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-Udw3dg1jvXzekoW1 .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-Udw3dg1jvXzekoW1 .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-Udw3dg1jvXzekoW1 .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster text{fill:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 .cluster span{color:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-Udw3dg1jvXzekoW1 .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-Udw3dg1jvXzekoW1 rect.text{fill:none;stroke-width:0;}#mermaid-svg-Udw3dg1jvXzekoW1 .icon-shape,#mermaid-svg-Udw3dg1jvXzekoW1 .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-Udw3dg1jvXzekoW1 .icon-shape p,#mermaid-svg-Udw3dg1jvXzekoW1 .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-Udw3dg1jvXzekoW1 .icon-shape .label rect,#mermaid-svg-Udw3dg1jvXzekoW1 .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-Udw3dg1jvXzekoW1 .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-Udw3dg1jvXzekoW1 .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-Udw3dg1jvXzekoW1 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} Yes
No
Video + Query Point
TSM-ResNet18 Backbone
Stage 1: Global Cost Volume
Spatial Softmax → Coarse Position
Stage 2: Local 7x7 Correlation
12-Block Depthwise Conv
Iteration < 4?
Final Track + Visibility
2.2 Stage 1: 逐帧初始化(Per-Frame Initialization)
骨干网络 :TSM-ResNet18,输出stride-8特征图 F ∈ R T × H 8 × W 8 × C F \in \mathbb{R}^{T \times \frac{H}{8} \times \frac{W}{8} \times C} F∈RT×8H×8W×C。
全局匹配流程:
- 在查询帧 t q t_q tq 的位置 ( x q , y q ) (x_q, y_q) (xq,yq) 通过双线性插值提取查询特征 F q F_q Fq
- 对每一帧计算Cost Volume: F q F_q Fq 与该帧所有位置的点积
- ConvNet处理Cost Volume → \rightarrow → 空间热力图
- Spatial Softmax → \rightarrow → 概率分布 → \rightarrow → 加权平均得到位置估计 p ^ t \hat{p}_t p^t
初始化Loss:
L ( p ^ t , o t , u t ) = Huber ( p ^ t , p t ) ⋅ ( 1 − o ^ t ) + BCE ( o ^ t , o t ) + BCE ( u ^ t , u t ) ⋅ ( 1 − o ^ t ) \mathcal{L}(\hat{p}_t, o_t, u_t) = \text{Huber}(\hat{p}_t, p_t) \cdot (1 - \hat{o}_t) + \text{BCE}(\hat{o}_t, o_t) + \text{BCE}(\hat{u}_t, u_t) \cdot (1 - \hat{o}_t) L(p^t,ot,ut)=Huber(p^t,pt)⋅(1−o^t)+BCE(o^t,ot)+BCE(u^t,ut)⋅(1−o^t)
其中不确定性标签 u t u_t ut 为自监督生成:
u ^ t = { 1 if ∥ p pred − p gt ∥ > δ 0 otherwise , δ = 6 pixels \hat{u}t = \begin{cases} 1 & \text{if } \|p{\text{pred}} - p_{\text{gt}}\| > \delta \\ 0 & \text{otherwise} \end{cases}, \quad \delta = 6 \text{ pixels} u^t={10if ∥ppred−pgt∥>δotherwise,δ=6 pixels
推理时可见性判定: ( 1 − u t ) ⋅ ( 1 − o t ) > 0.5 (1 - u_t) \cdot (1 - o_t) > 0.5 (1−ut)⋅(1−ot)>0.5。
2.3 Stage 2: 迭代时序精炼(Temporal Refinement)
这是TAPIR精度提升的核心。消融实验表明去掉精炼后DAVIS AJ从61.3暴跌至41.6(-32%)。
Local Score Maps :在当前位置估计 p t ( i ) p_t^{(i)} pt(i) 周围提取 7 × 7 7 \times 7 7×7 邻域的多尺度相关性分数,使用特征金字塔(3-5层,stride 8/16/32/64/128)。
精炼网络:12层深度卷积网络(Depthwise Convolutional Network)
- 输入维度: T × ( C + K + 4 ) T \times (C + K + 4) T×(C+K+4),其中 K K K 为展平的score map值
- 每层结构: 1 × 1 1 \times 1 1×1 Conv + Depthwise Conv(时间维度)+ GeLU
- 隐藏维度: 512 → 2048 512 \rightarrow 2048 512→2048(通过4路并行depthwise conv扩展) → 512 \rightarrow 512 →512
- 残差连接贯穿
输出(每次迭代):四路残差
( Δ P t ( i ) , Δ o t ( i ) , Δ u t ( i ) , Δ F q , t ( i ) ) (\Delta P_t^{(i)},\; \Delta o_t^{(i)},\; \Delta u_t^{(i)},\; \Delta F_{q,t}^{(i)}) (ΔPt(i),Δot(i),Δut(i),ΔFq,t(i))
位置累积更新 p t ( i + 1 ) = p t ( i ) + Δ P t ( i ) p_t^{(i+1)} = p_t^{(i)} + \Delta P_t^{(i)} pt(i+1)=pt(i)+ΔPt(i),特征更新使查询特征适应目标外观变化。
为什么用Depthwise Conv替代MLP-Mixer?
- MLP-Mixer需要固定时间块长度,不同块间要Chaining传递
- Depthwise Conv在时间维度做局部卷积,天然支持任意长度
- 无需分块 → \rightarrow → 无需Chaining → \rightarrow → 速度从34.5s降到0.25s
2.4 自监督不确定性估计
TAPIR的不确定性是自监督 的:训练时用预测位置与GT的距离是否超过阈值 δ \delta δ 来生成伪标签。推理时低置信度预测被抑制,显著提升benchmark分数(去掉后Kinetics AJ从57.2降到54.4)。
三、实验分析
3.1 TAP-Vid Benchmark

图 2:迭代精炼收敛过程与消融分析。重点看左侧:4次迭代后AJ趋于平台;右侧消融中去掉Refinement影响最大。来源:重绘自 design skill
| 方法 | Kinetics AJ | DAVIS AJ | RGB-Stacking AJ | Kubric AJ |
|---|---|---|---|---|
| TAP-Net | 46.6 | 38.4 | 59.9 | 65.4 |
| PIPs | 35.3 | 42.0 | 37.3 | 59.1 |
| TAPIR | 57.2 | 61.3 | 62.7 | 84.7 |
3.2 高分辨率扩展
TAPIR支持图像金字塔推理(对数间隔分辨率,最低256x256逐步x2到原始分辨率):
| 分辨率 | DAVIS AJ | Kinetics AJ |
|---|---|---|
| 256x256 | 61.3 | 57.2 |
| 1080p | 65.7 | - |
| 720p | - | 60.0 |
3.3 速度对比(V100 GPU,50点)
| 方法 | 25帧 | 50帧 | 参数量 |
|---|---|---|---|
| TAP-Net | 0.05s | 0.09s | 2.8M |
| PIPs | 17.9s | 34.5s | 28.7M |
| TAPIR | 0.15s | 0.25s | 29.3M |
TAPIR与PIPs参数量相当(29.3M vs 28.7M),但快120倍。实时推理可达256点@256x256@40fps。
3.4 消融分析
| 去掉组件 | Kinetics AJ | DAVIS AJ | 影响 |
|---|---|---|---|
| Full Model | 57.2 | 61.3 | - |
| - Iterative Refinement | 48.1 | 41.6 | 最关键 (-32%) |
| - Higher Res Feature | 54.0 | 54.0 | -12% |
| - Depthwise Conv | 54.9 | 53.8 | -12% |
| - Uncertainty | 54.4 | 58.6 | -4.4% |
| - TAP-Net Init | 54.7 | 59.3 | -3.3% |
精炼迭代次数:1次+7.6 AJ,2次+1.0,3次+0.1,4次+0.4后plateau。
四、关键设计决策
4.1 Coarse-to-Fine策略
Stage 1用stride-8低分辨率全局匹配避免局部最优,Stage 2在高分辨率局部邻域精细对齐。类似光流中先计算粗光流再warp精炼的经典范式,但TAPIR将其统一到单个可训练框架中。
4.2 训练数据的关键性
TAPIR仅用合成数据(Kubric MOVi-E,100K视频)训练。关键改进是Panning MOVi-E变体:相机沿线性轨迹运动,模拟真实视频中的相机平移。这一改动使Kinetics AJ从54.1提升到57.2(+3.1)。
4.3 查询特征更新机制
精炼中不仅更新位置,还更新查询特征 F q F_q Fq。这使得跟踪器能适应目标外观变化(如光照、形变),而非始终依赖初始帧的静态特征。
小结
TAPIR的核心贡献是证明了全局初始化 + 局部迭代精炼的两阶段范式在点跟踪中的有效性,且全卷积架构使其兼具高精度与高效率。
创新点:
- 两阶段设计融合TAP-Net全局匹配与PIPs局部精炼的各自优势
- 全卷积Depthwise Conv替代MLP-Mixer,消除Chaining瓶颈,速度提升120倍
- 自监督不确定性估计,无需额外标注即可抑制低置信度预测
局限性:
- 仅用合成数据训练,对真实世界极端场景泛化有限
- 查询点需要手动指定,不支持自动发现可跟踪点
- 遮挡恢复依赖于Stage 1的全局匹配质量
- 长期跟踪(>50帧)精度可能因特征漂移下降
个人判断:TAPIR确立了"初始化+精炼"作为点跟踪标准范式(后续CoTracker、BootsTAP均沿用)。其设计哲学直接影响了VGGT等后续工作:先用全局attention建立粗对应,再用局部信息精炼。对VIO系统的启示------TAPIR的自监督不确定性估计可直接用于前端特征跟踪的质量评估,其"失败时回退到全局重匹配"的策略与VIO中跟踪丢失后的重定位逻辑一脉相承。