一、什么是LangChain
LangChain 是一套工具和库,帮助开发人员将 LLMs 集成到您的软件项目中。 LLMs 是将文本作为输入并生成新文本作为输出的 AI 模型。商业 LLMs 具有专有接口;它们的输入长度有限,必须遵循称为提示的合理结构来迫使模型产生有用的输出。因此,集成此类模型可能会变得相当复杂,特别是如果您想构建可投入生产的集成。这不仅仅是向 API 发送文本并寄希望于最好的结果。
LangChain 通过规范化 LLM 接口、帮助进行提示和文档管理,以及支持多个 LLM 交互的链式操作
LangChain是一个强大的开源框架,用于构建基于大语言模型(LLM)的应用。它将大模型开发中的常用功能、工具和流程封装为模块化组件,使开发者能够像搭积木一样快速构建适用于不同场景的大模型应用。
其官方地址为:https://github.com/langchain-ai
虽然 LangChain 框架可以独立使用,但它也能与任何 LangChain 产品无缝集成,为开发者在构建 LLM 应用时提供一套完整的工具。
- Deep Agents --- 构建能够规划、使用子代理并利用文件系统处理复杂任务的代理
- LangGraph --- 构建能够通过代理编排框架可靠处理复杂任务的代理
- Integrations --- 聊天与嵌入模型、工具与工具包等
- LangSmith --- 用于 LLM 应用的代理评估、可观察性和调试
- LangSmith Deployment --- 使用专为长时间运行、有状态工作流构建的平台部署和扩展代理
二、LLM 应用开发的核心框架
由 LLM 驱动的应用程序的框架,它们的目标是提供构建复杂 LLM 应用(如带有记忆的代理、复杂的RAG 系统、多步骤工作流)所需的全套工具。以下是按语言生态划分的主流框架:
Python 生态

JavaScript/TypeScript 生态

Java 生态

技术架构的天然分工(核心原因)现代 LLM 应用架构普遍采用 "Python/JAVA 负责应用层(做什么),C++ 负责底层推理(怎么做)" 的分工模式。
一个完美的例子是 llama.cpp(官网: https://github.com/ggerganov/llama.cpp):
- 它本身是一个用 C/C++ 编写的热门项目,用于高效推理 LLaMA 系列及众多其他架构的模型。它以其出色的性能和极低的内存需求(通过量化)而闻名。
- 你可以将 llama.cpp 作为库链接到你的 C++ 应用程序中,从而在本地直接运行模型。我们可以自行提供的 server 功能,启动一个 HTTP API 服务。
- 然后,上层的 Python 或 JavaScript 应用通过调用这个 API 来使用它,从而结合了 C++ 的推理性能和 Python 的应用开发效率。
三 、LangChain 框架
LangChain 提供了 JavaScript/TypeScript 和 Python 实现,形成一个旨在简化 LLM 编程的框架。这些模块被分为不同的类别,每个类别专注于特定的集成任务。
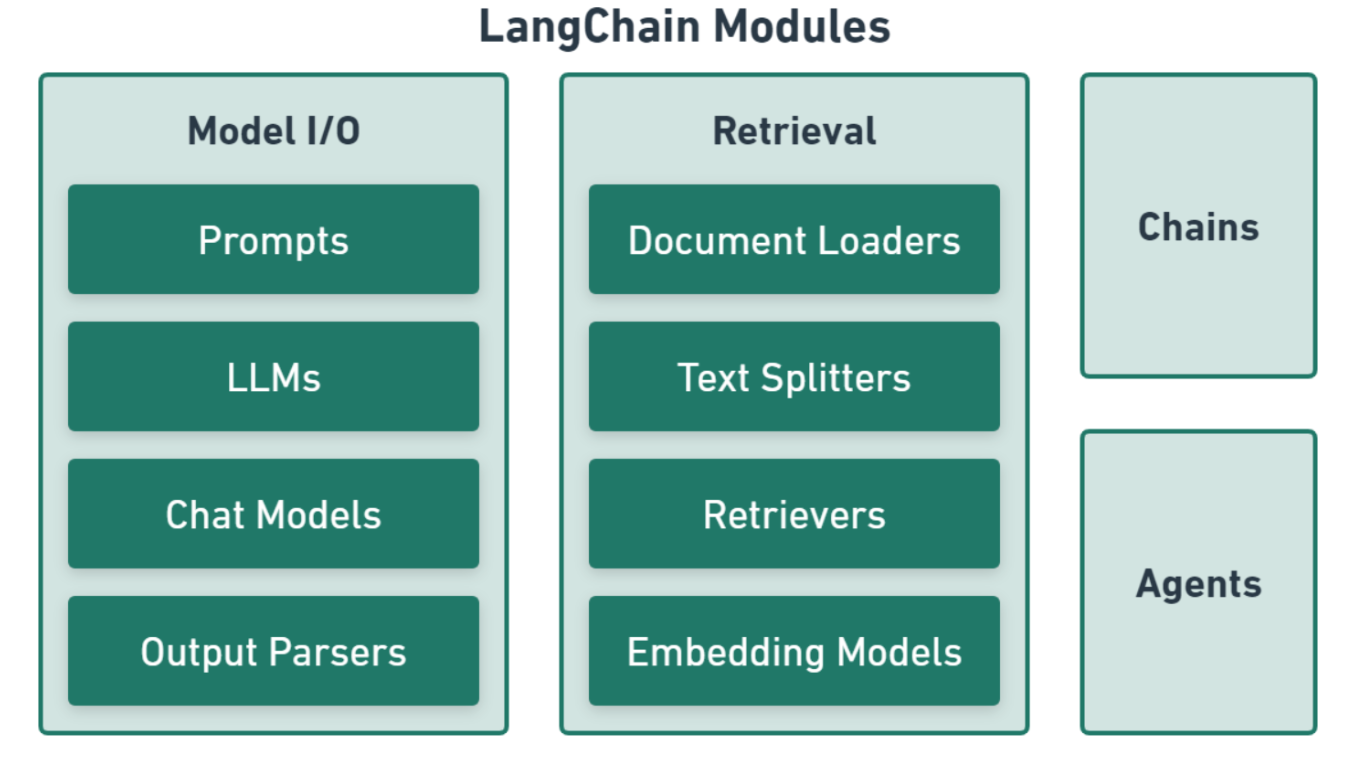
一、Model I/O:大模型输入输出层(和 LLM 交互的基础)
负责构建提示词→调用大模型→解析模型返回结果,是所有功能的底层交互入口,包含 4 个子组件:
- **Prompts(提示词)**负责管理提示模板、动态拼接用户输入、角色设定,统一规范传给大模型的指令,比如 PromptTemplate、FewShotPrompt 少样本提示。
- **LLMs(大语言模型)**对接各类原生大模型接口(文心一言、GPT、通义千问等),封装统一调用 API,完成文本补全类生成。
- **Chat Models(对话模型)**针对 Chat 对话格式优化(区分 System/User/Assistant 角色消息),是现在主流对话大模型(GPT3.5/4、豆包等)的封装层。
- Output Parsers(输出解析器) 把 LLM 自由文本输出,结构化转为 JSON / 列表 / 自定义对象,解决大模型输出格式混乱问题,方便程序后续读取数据。
Model I/O = 造指令->丢给模型→拆返回结果
二、Retrieval:知识库检索层(RAG 检索增强核心)
专门用来做私有文档知识库 + 向量检索,实现【外部资料喂给大模型】,一个4 个子组件组成完整文档处理流水线:
- **Document Loaders(文档加载器)**读取各类数据源:PDF/Word/TXT/ 网页 / 数据库 / CSV,把不同格式文件统一转为 LangChain 标准 Document 文档对象。
- **Text Splitters(文本分割器)**超长文档切分小块 Chunk(解决 LLM 上下文长度限制),支持按字符、递归、语义分割,是向量入库前必备步骤。
- Embedding Models(嵌入模型) 将文本 Chunk 转为数值向量,用来计算语义相似度(如 OpenAI Embedding、bge、m3e 中文嵌入模型)。
- **Retrievers(检索器)**对接向量数据库,用户提问后把问题向量化,从知识库中召回最相关片段,把参考资料塞进 Prompt 给 LLM。
Retrieval = 读文档→切片段→向量化存库→提问查资料,RAG 全链路就是靠这个模块。
三、Chains:链路编排层(功能串联流水线)
把上面 Model I/O、Retrieval 等零散组件按业务逻辑串成流水线,实现复杂任务:
- 基础链:提示词 + LLM
- RAG 常用:检索 + 拼 prompt + 调用 LLM
- 复合链:多步骤任务拆分,然后再通过一步一步串行执行。
Chains 是一根线,将零散工具串联起来变成完整业务流程。
四、Agents:智能代理层(自主决策调用工具)
一种基于大模型(LLM)的应用设计模式,利用 LLM 的自然语言理解和推理能力(LLM 作为大脑),根据用户的需求自动调用外部系统、设备共同去完成任务。和 Chains 固定流程不同,Agents 让 LLM 自己思考:该调用什么工具、什么时候调用:
- LLM 自主判断用户问题:要不要查知识库、调用计算器、联网搜索、调用第三方 API;
- 内置 Tool 工具集(搜索、代码解释器、数据库查询)+ Agent 决策逻辑;
- 典型场景:智能客服自主查订单、科研助手自主搜文献算数据。
Chains 是人定死步骤,Agents 是 AI 自己选步骤。
整体简单架构逻辑:私有数据→Retrieval(文档入库) + 用户提问→Model I/O(构建prompt+调用LLM+解析结果) → Chains/Agents串联组合 → 落地RAG、智能Agent等AI应用
如果使用 LangChain 进行大模型应用开发,需要安装 LangChain 的依赖包,安装命令如下:
#langchain框架安装
pip install langchain
#langchain版本查看
pip show langchain四、 LangChain 核心模块
LLM
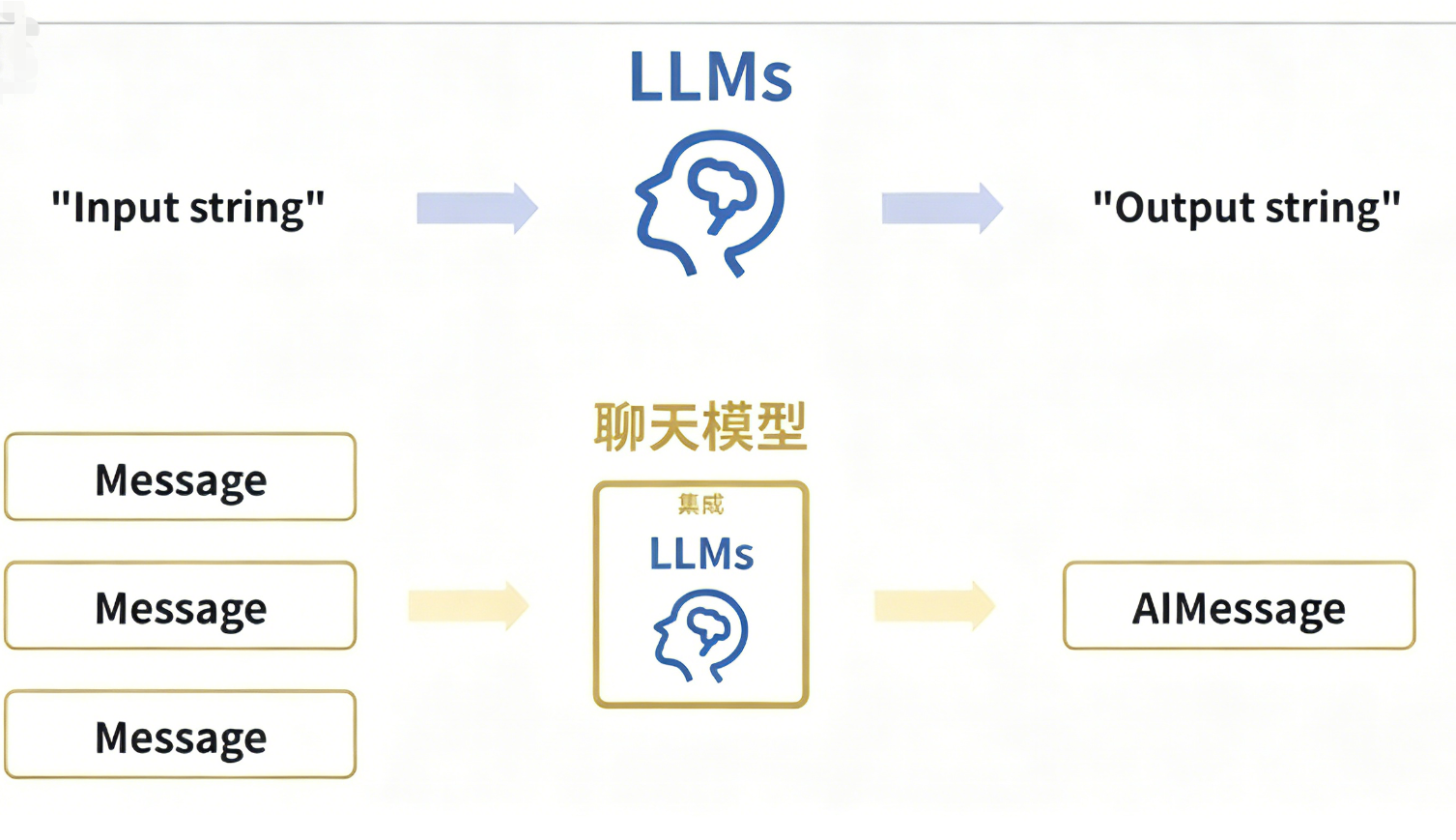
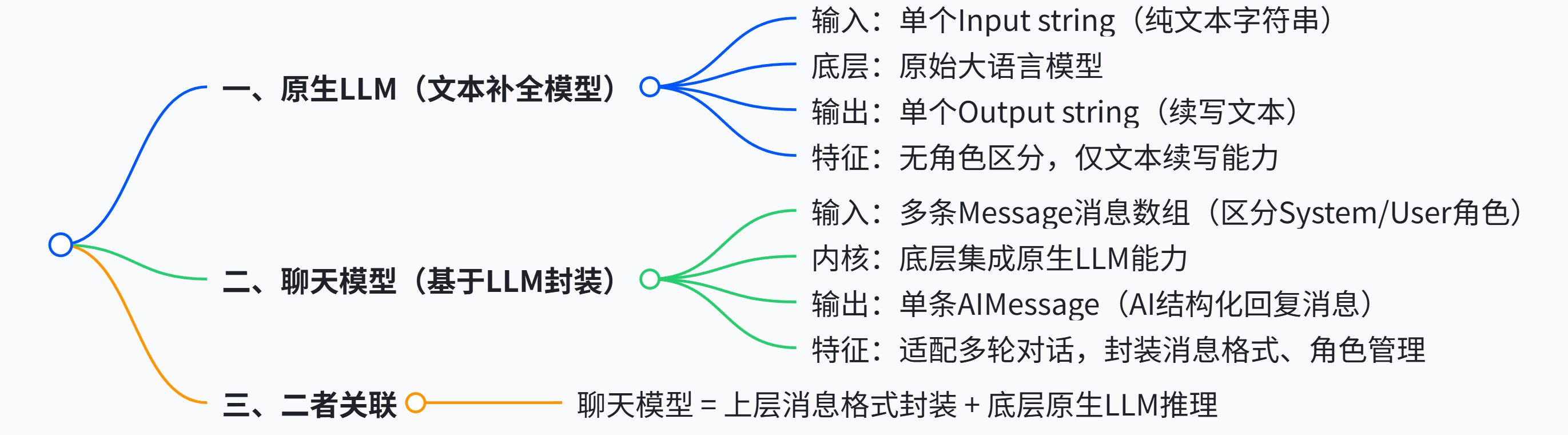
大语言模型(LLM)在各种与语言相关的任务(例如文本生成、翻译、摘要、问答等)中表现出色。现代 LLM 通常通过聊天模型接口访问,该接口将消息列表作为输入,并返回消息作为输出,而不是使用纯文本。这里需要注意 LLM 与 LangChain 中 聊天模型 的关系:
- 在 LangChain 的官方文档中,认为 LLM 大多数是纯文本补全模型。这些纯文本模型封装的 API 接口接受一个字符串提示作为输入,并输出一个字符串补全结果(实际上 LLM 还包括多模态输入)。OpenAI 的 GPT-5 就是作为 LLM 来实现的。
- LangChain 中的 聊天模型 通常由 LLM 提供支持,但经过专门调整以用于对话。关键在于,它们不是接受单个字符串作为输入,而是接受聊天消息列表,并返回一条 AI 消息作为输出
接入 大模型的 两种方式对比
openai方式接入大模型
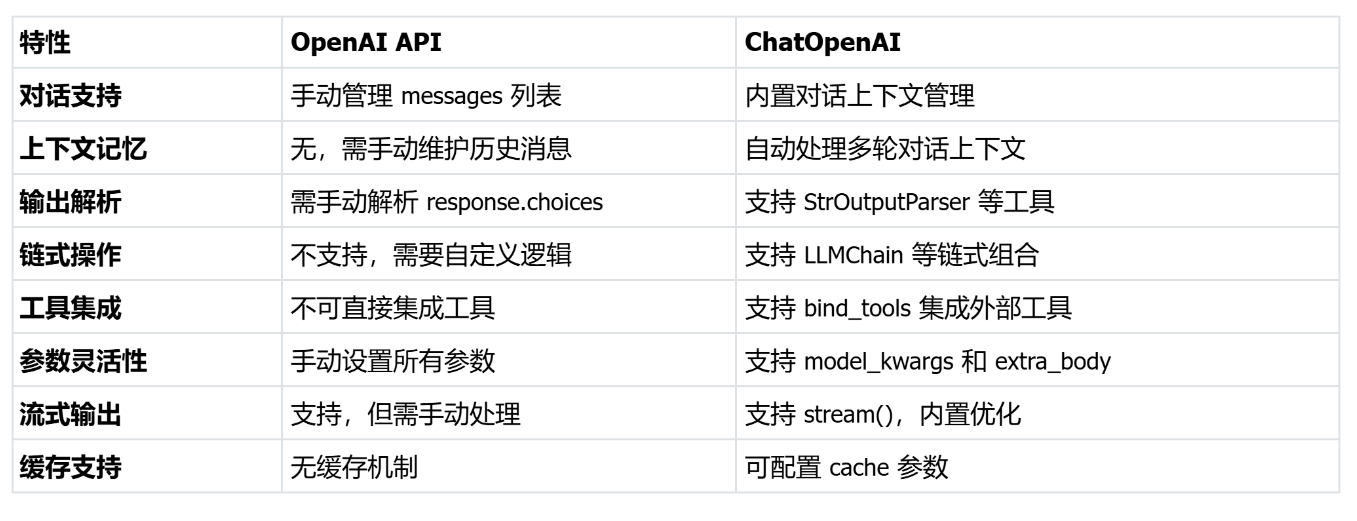
OpenAI 是一个基本的类,主要用来调用 OpenAI 的传统文本生成模型(比如早期的 text-davinci-003),适合处理简单的文本完成任务。
特点:
专注于生成单段文本,比如回答问题或写一段文字。
不太适合对话场景,因为它没有内置的对话上下文管理。
**使用场景:**如果你只是想让模型生成一段独立的文本(比如写一篇短文或解释某个概念),可以用这个。
接下来的 API 我们都是用的 DeepSeek 的 API,大家可以自行去官方 注册 并获取 API key
from config import Config
conf=Config()
# 1、openai方式连接大模型
from openai import OpenAI
# 初始化DeepSeek的API客户端
client = OpenAI(api_key=conf.API_KEY, base_url="https://api.deepseek.com")
# 调用DeepSeek的API,生成回答
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是小助手,请根据用户的问题给出回答"},
{"role": "user", "content": "你好,请你介绍一下你自己。"}
]
)
# 打印模型最终的响应结果
print(response.choices[0].message.content)langchain方式接入大模型
langchain中ChatOpenAI 是一个更高级的类,专门为对话模型设计(比如 deepseek、gpt-3.5-turbo 或 gpt-4),支持多轮对话。
特点:
- 能记住之前的对话内容,适合构建聊天机器人或需要上下文的场景。
- 通过消息列表(messages)来管理对话,比如用户输入和模型回应。
- 支持流式输出和更多参数调整。
使用场景:如果你想做一个能聊天的应用,比如客服机器人或问答系统,ChatOpenAI 是首选。
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
# 初始化 ChatOpenAI,配置 API
llm = ChatOpenAI(
model=conf.MODEL,
api_key=conf.API_KEY,
base_url=conf.API_URL,
temperature=0.7,
max_tokens=150)
messages = [
SystemMessage(content="你是小助手,请根据用户的问题给出回答"),
HumanMessage(content="你好,请你介绍一下你自己。")]
result = llm.invoke(messages)
print(result.content)prompt
提示词模板(Prompt Template)是 LangChain 的核心抽象之一,它被广泛应用于构建大语言模型(LLM)应用的各个环节。简单来说,只要是需要动态、批量、或有结构地向大语言模型【发送请求】的地方,几乎都会用到提示词模板。
Prompt 模板 (Prompt Template) 可以理解为是一个预先定义好的、可复用的输入结构,它像一个"建筑蓝图",清晰地规划了最终发送给 LLM 的指令中,哪些部分是固定的框架,
prompt是一个专业的"剧本"蓝图,允许我们一次性定义好"剧本"的固定结构(如系统指令、模仿范例),之后每次使用时,只需填充动态变化的部分即可。
在 LangChain 中,针对这种情况,可以定义一个模板:
- 固定文本(模板): "请介绍 {city} 的历史。"
- 输入变量: "city"定义好后,可以使用该模板:
- 当我们需要查询北京时,就将 city 变量赋值为 "北京"。模板引擎会生成: "请介绍北京的历史。"
- 当我们需要查询上海时,就将 city 变量赋值为 "上海"。模板引擎会生成: "请介绍上海的历史。"
目的 :将提示的逻辑(固定结构)与提示的数据(动态变量)彻底分离,从而实现代码的简洁、复用、安全和可维护性。

Message
消息是聊天模型中的通信单位,用于表示聊天模型的输入 和输出 ,以及可能与对话关联的任何其他上下文或元数据。
LLM 消息结构
每条消息都包含角色、内容,以及随 LLM 厂商差异变化的附加元数据。
- 消息角色 (Role):区分对话内不同类型消息,引导聊天模型根据消息序列合理生成回复。
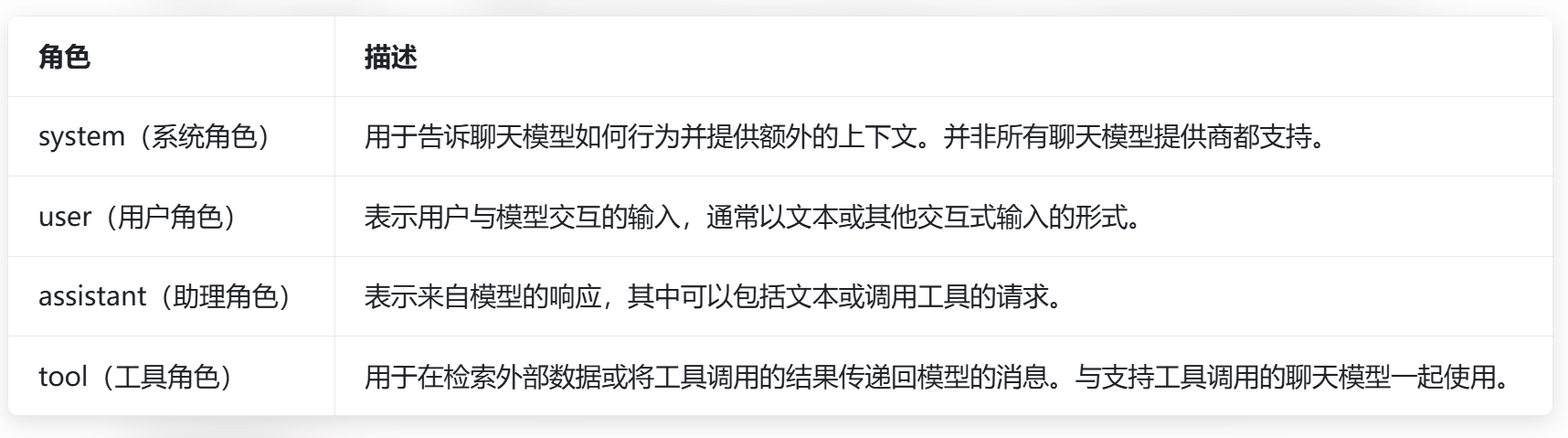
角色分为system/user/assistant/tool四类,是约束模型行为、区分消息来源的核心标识;
1. 消息内容(Content)
代表消息主体数据,可分为 文本、多模态资源(图片 / 音频 / 视频) 两类:
- 纯文本场景:直接填入字符串文本,是当前绝大多数 LLM 的标准格式;
- 多模态场景:采用字典列表格式封装图文、音视频数据,不同厂商模型(通义千问、GPT、Gemini)的结构体定义存在差异;
- 现状:文本输入全模型兼容,图片、音视频等多模态输入仅多模态大模型支持,通用文本 LLM 适配有限。
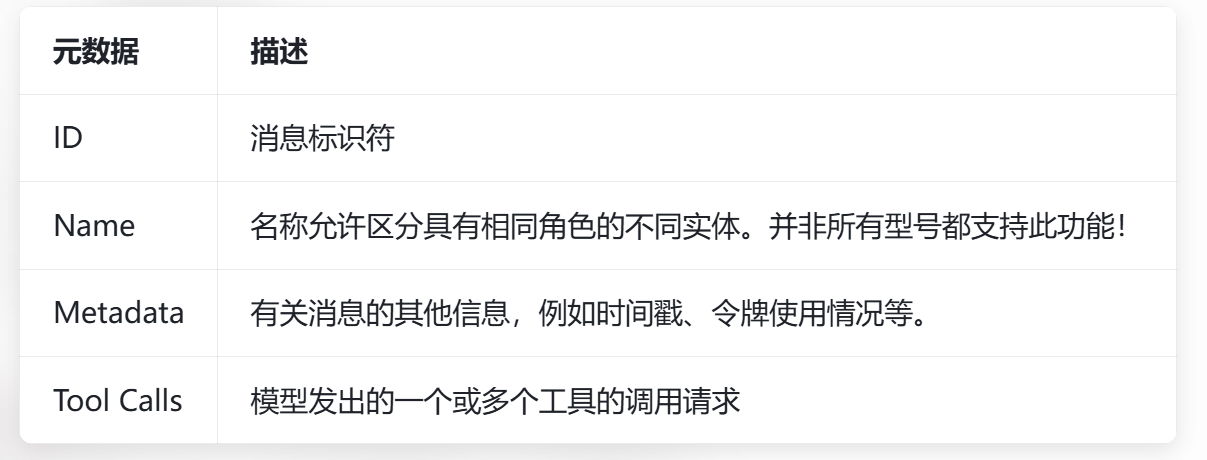
2. 消息其他元数据(Additional metadata)
对应上表格四类扩展字段:ID、Name、Metadata、Tool Calls
3. 其他元数据
如模型参数、工具 ID、token 计数、多模态图片链接等,不同大模型接口定义不一致。
常见的 元数据 如下:
Chain
LangChain核心功能之链式调用, LangChain之所以被称为LangChain,其核心概念就是Chain。 Chain翻译成中文就是"链"。
一个链,指的是可以按照某一种逻辑,按顺序组合成一个流水线的方式。比如以问答流程为例: 用户输入一个问题 --> 发送给大模型 --> 大模型进行推理 --> 将推理结果返回给用户。这个流程就是一个链。
python
# 定义大模型
model = ChatOpenAI(model="gpt-5-mini")
# 定义消息列表
messages = [
SystemMessage(content="Translate the following from English into Chinese"),
HumanMessage(content="hi!"),
]
# 定义输出解析器
parser = StrOutputParser()
# 定义链
chain = model | parser
# 执行链
result = chain.invoke(messages)
print(result)一个最基本的 Chain 结构,是由 Model 和 OutputParser 两个组件构成的,其中 Model 是用来调用大模型的,OutputParser 是用来解析大模型的响应结果的。
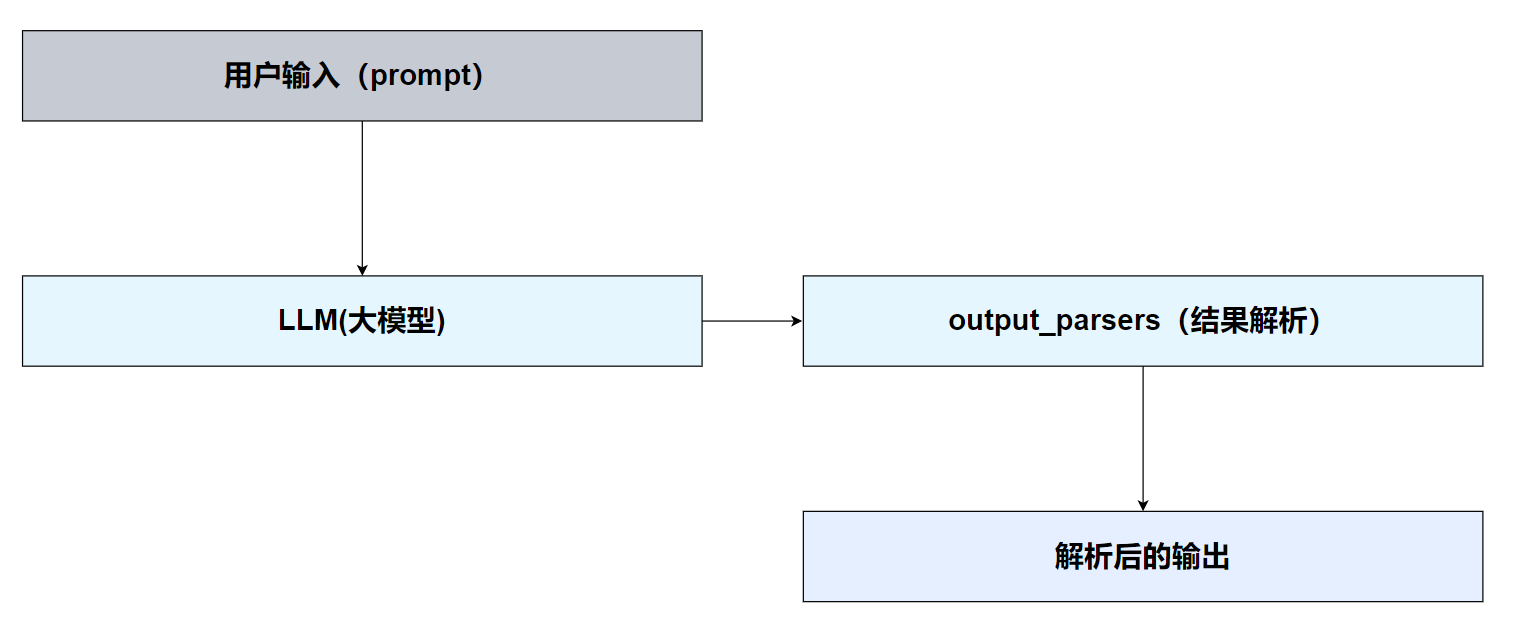
在LangChain框架中,Chain(链) 和 LCEL(LangChain Expression Language) 是两个密切相关但本质不同的概念。
Chain(链): 是LangChain中处理流程的抽象概念,指将多个组件(模型、工具、逻辑)串联成一个可执行的任务序列。
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的"提示+LLM"链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
在本文中 LCEL 产生的对象,被叫做 runnable 或 chain,经常两种叫法混用。本质就是一个自定义调用流程。
Runnable 接口
Runnable 接口是使用 LangChain Components(组件)的基础。
概念说明
Components(组件):用来帮助我们在构建应用程序时,提供了一系列的核心构建块,例如语言模型、输出解析器、检索器、编译的 LangGraph 图等。
Runnable 定义了一个标准接口,允许 Runnable 组件:
- Invoked(调用):单个输入转换为输出。
- Batched(批处理):多个输入被有效地转换为输出。
- Streamed(流式传输):输出在生成时进行流式传输。
- Inspected(检查):可以访问有关 Runnable 的输入、输出和配置的原理图信息。
- Composed(组合):可以组合多个 Runnable,以使用 LCEL 协同工作以创建复杂的管道。
语言模型(model)、输出解析器(StrOutputParser)都是 Runnable 接口的实例!它们都使用了 Invoked(调用)的能力
python
# 语言模型(model)
model = ChatOpenAI(model="gpt-5-mini")
result = model.invoke(messages) # 语言模型是 Runnable 接口实例,允许 invoke 调用
# 输出解析器(StrOutputParser)
parser = StrOutputParser()
parser.invoke(result) # 输出解析器是 Runnable 接口实例,允许 invoke 调用LangChain Expression Language
LangChain Expression Language(LCEL):采用声明性方法,从现有 Runnable 对象构建新的 Runnable 对象。
通过 LCEL 构建出的新的 Runnable 对象,被称为 RunnableSequence,表示可运行序列。
RunnableSequence 就是一种链。chain 的类型就是 RunnableSequence。如下所示:

重要的是,RunnableSequence 也是 Runnable 接口的实例,它实现了完整的 Runnable 接口,因此它可以用与任何其他 Runnable 相同的姿势使用。
python
chain = model | parser
chain.invoke(messages) # 链是 Runnable 接口实例,允许 invoke 调用可以看到,LCEL 其实是一种编排解决方案,它使 LangChain 能够以优化的方式处理链的运行时执行。任何两个 Runnable 实例都可以 "链" 在一起成序列。上一个可运行对象 .invoke() 调用的输出作为输入传递给下一个可运行对象。方法就是使用 |(管道 / 运算符):
python
chain = model | parser它通过两个 Runnable 对象去创建一个 RunnableSequence。实际上 LangChain 重载了 | 运算符,使用 | 运算符就相当于:
python
from langchain_core.runnables import RunnableSequence
chain = RunnableSequence(first=model, last=parser)除此之外,可以使用 .pipe 方法代替。这也相当于 | 运算符:
在 Unix/Linux 系统中,pipe() 系统调用和 | 管道操作符都用于实现进程间通信,这里同样也是迁移过来的用法。
chain = model.pipe(parser)Output Parsers
OutputParser (输出解析器) 是 LangChain "模型 I/O" 模块中的关键组件。它的核心职责是扮演一个"翻译官"的角色。
大语言模型(LLM)像一个健谈的人,它的输出本质上是自由流动的纯文本字符串 。然而,我们的应用程序(无论是网站后端、数据分析脚本还是自动化流程)需要的是精确、结构化的数据(如 JSON、Python 对象、列表等)。
OutputParser 正是连接这两者的桥梁。它接收 LLM 返回的文本,并根据我们预先设定的规则(例如,"请提取姓名和邮箱"),将其解析并转换为程序可以轻松使用的、干净的结构化数据。
Output Parser重要性:
LLM 输出不确定性:LLM 生成的响应往往是自然语言文本,格式不固定、可能包含噪声或多余信息。如果直接使用这些输出,会导致应用逻辑复杂、易出错。
结构化需求:在实际应用中,我们需要将 LLM 输出用于数据库存储、API 调用、决策逻辑等场景,这些都需要标准化的数据格式(如 JSON 用于 API 交互)。
提高效率:通过 OutputParser,可以自动化解析过程,减少手动后处理工作,支持链式操作(例如,在 LangChain 的链中直接将解析结果传递给下一个组件)。
错误处理:许多 OutputParser 内置重试或修复机制,能处理 LLM 输出中的语法错误或不完整内容。
以下是langchain目前提供的多种 OutputParser结构化解析器功能如下:
根据功能可分为基础类型解析、结构化解析、模式匹配解析、数据处理解析、组合解析器和错误处理解析。LangChain 提供了丰富的解析器来满足不同场景的需求 ,以下是核心解析器的列表(基于官方文档和常见工业应用,按 JSON 优先和实用性排序),包括功能描述、类型和工业场景应用:
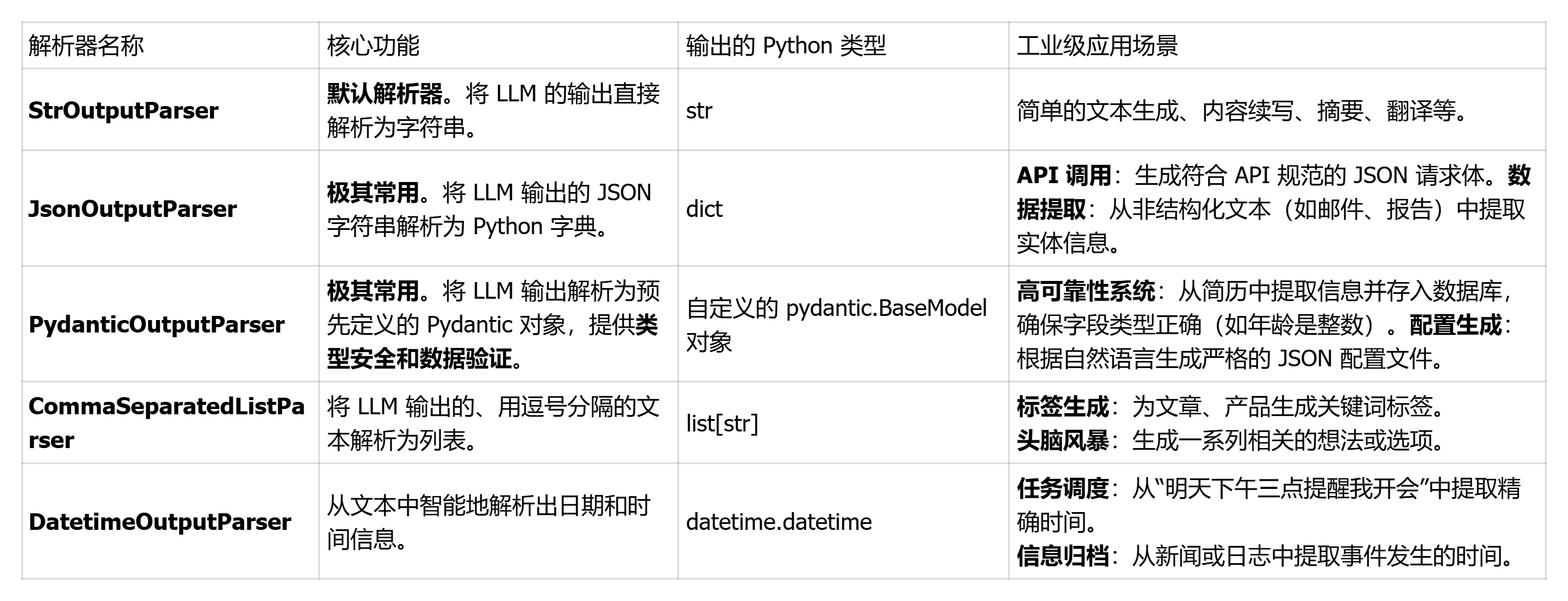
tips:
以上列表覆盖了 LangChain 的核心 OutputParser。LangChain 框架不断更新,可能会有新解析器(如针对多模态输出的扩展)。
在实际使用中,许多解析器可结合 Pydantic 模型定义输出 schema,确保类型安全。
示例:对于 JsonOutputParser,可以定义一个 Pydantic 类来指定 JSON 结构,然后解析 LLM 输出为字典,便于工业数据处理。
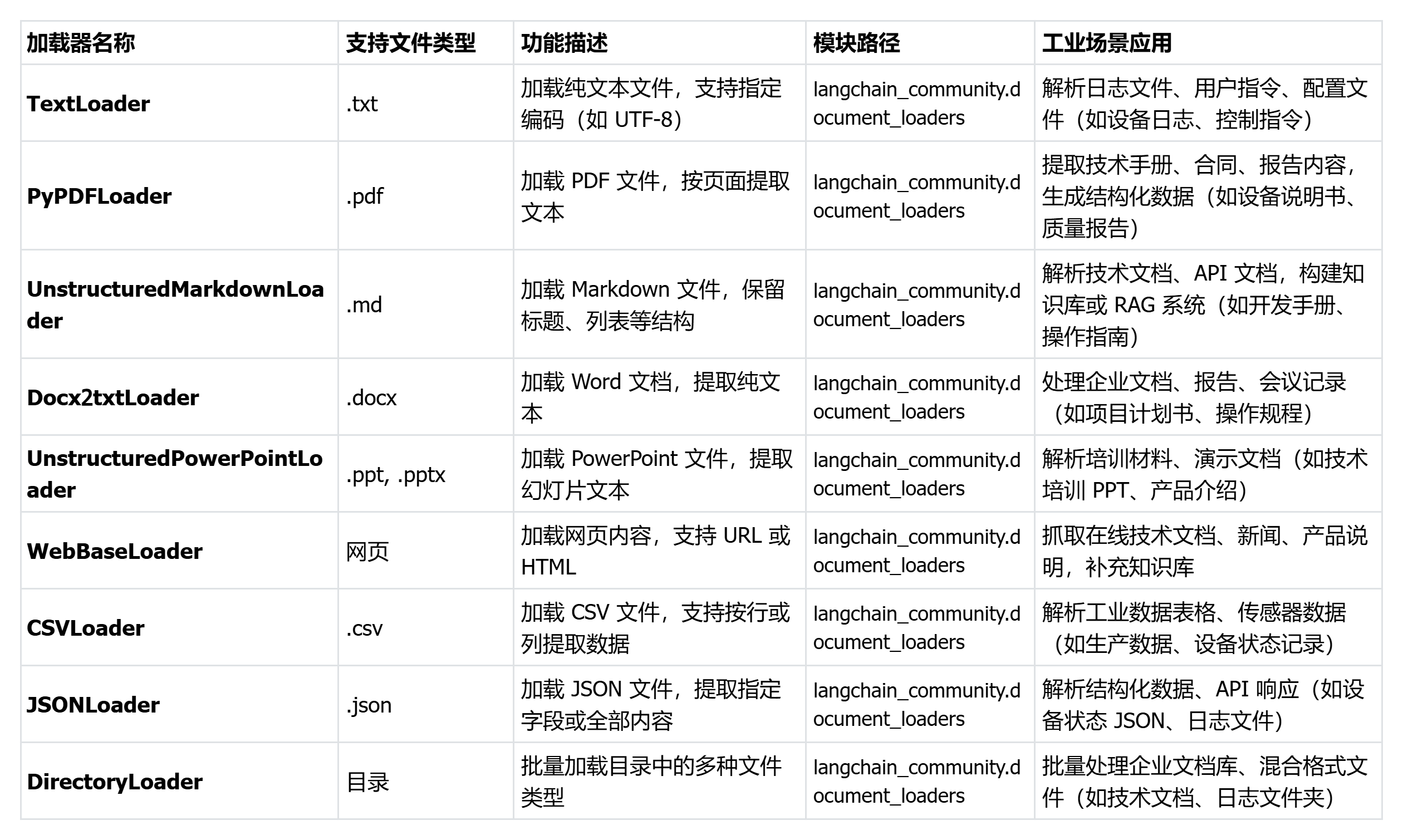
document_loaders
LangChain 的文档加载器(Document Loaders)是 LangChain 框架中用于从各种数据源加载文档的组件,旨在将不同格式的文件(如文本、PDF、Markdown、Word、PowerPoint 等)或数据源(如网页、数据库)转换为统一的 Document 对象。每个 Document 对象包含 page_content(文档内容)和 metadata(元数据,如文件路径、页码等)。加载器是 LangChain 数据处理管道的起点,常用于 RAG(检索增强生成)系统、知识库构建和文档分析。
LangChain 中常用文档加载Langchain_community.document_loaders:
TextSplitters
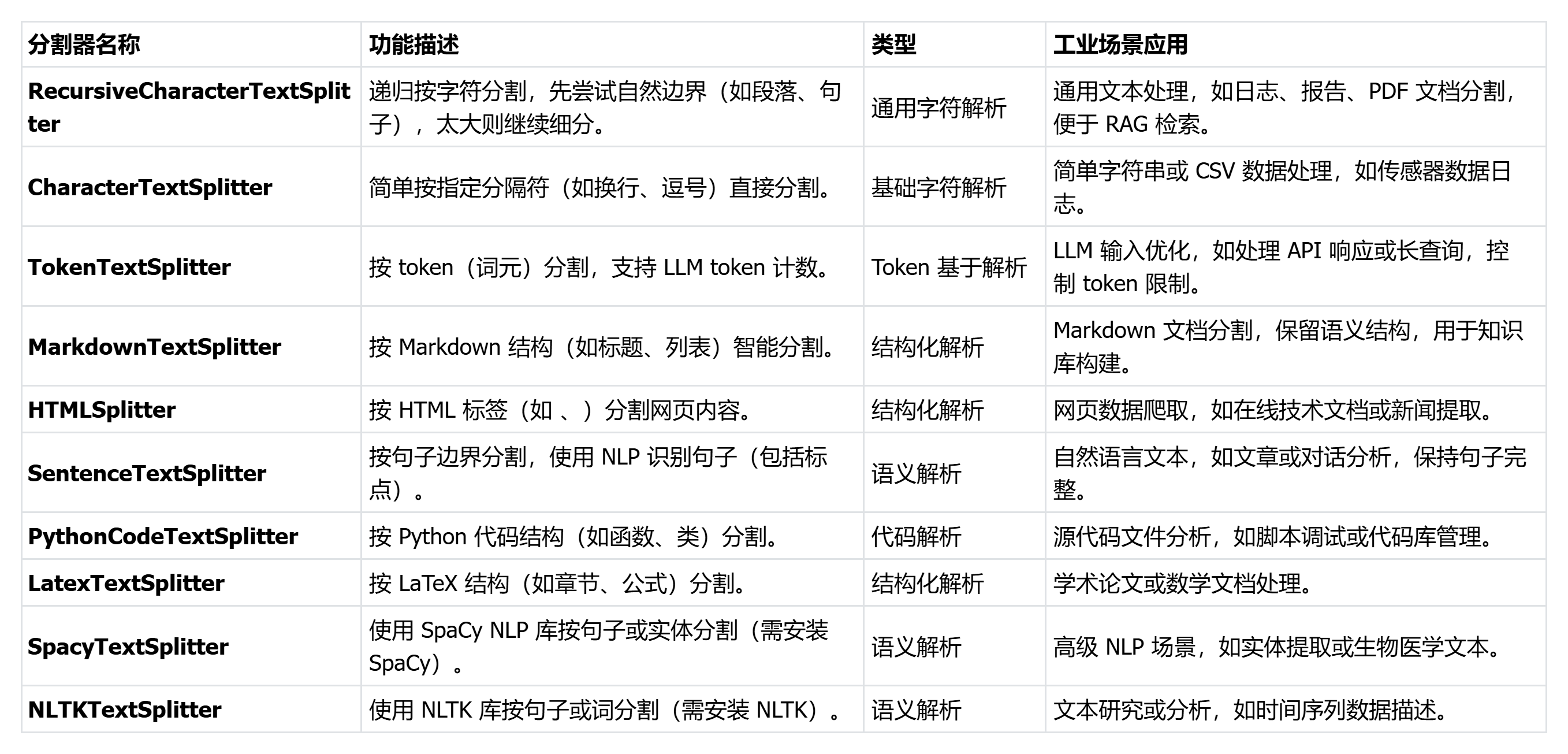
LangChain 的 Text Splitter(文本分割器)是框架中用于处理长文本的核心组件。它将大块文本(如文档、文章或日志)分割成小片段(称为 chunks),以便于后续处理。
为什么需要它?因为 LLM(如 ChatOpenAI 或 DeepSeekLLM)有输入长度限制,长文本无法一次性处理。Text Splitter 像一把"剪刀",根据规则(如字符数、句子边界或文档结构)智能剪切文本,确保每个小块完整、有意义。每个 chunk 通常以 Document 对象形式存在,包含 page_content(文本内容)和 metadata(元数据,如来源、ID)。
Text Splitter主要作用:
处理大文档:将 PDF、TXT、MD 等文件切分成可管理的小块,便于向量嵌入、检索或 LLM 输入。
保留上下文:通过重叠(overlap)机制,避免切断句子或段落,保持语义连贯。
支持多种策略:提供通用分割(如按字符)或语义分割(如按 Markdown 标题、代码结构),适配不同场景。
工业应用:在 RAG(检索增强生成)系统中,Text Splitter 是关键步骤,用于构建知识库、搜索系统或数据分析管道。例如,在工业监控中,将设备日志切分成小块,便于 LLM 快速分析异常或生成报告。
LangChain 提供了多种 Text Splitter,根据功能可分为基础型、语义型和结构化型。以下是核心分割器的表格:
Tools
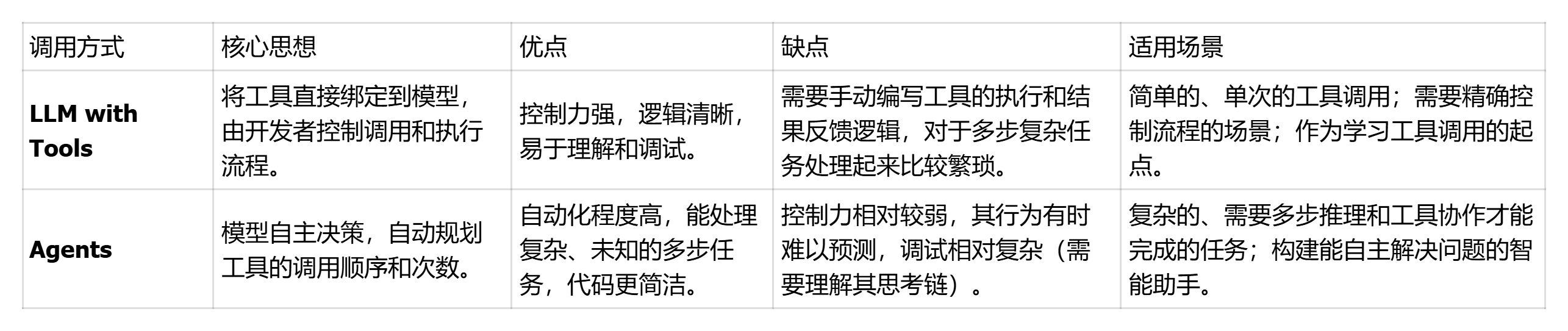
基础调用
在 LangChain 的世界里,"工具(Tool)"并不仅仅指我们日常生活中使用的扳手或锤子。在这里,工具是赋予大型语言模型(LLM)与外部世界交互能力的接口。
语言模型本身是一个非常聪明的大脑,但它被"囚禁"在一个封闭的房间里,只能基于它在训练时学到的知识进行思考和回答。它不知道今天的天气,无法访问最新的新闻,也不能帮你发送邮件或查询数据库。(原生 LLM 上下文长度有限、幻觉严重、知识过期)
工具调用(Tool Calling) 就是为这个大脑打开一扇通往外部世界的窗户。通过工具调用,模型可以:
- 获取实时信息:例如查询当前天气、股票价格、新闻头条。
- 与外部系统交互:例如访问数据库、调用 API、操作文件。
- 执行具体任务:例如进行复杂的数学计算、发送电子邮件、在日历上创建行程。
工具调用目的:
- 突破知识限制:语言模型的知识是静态的,截止于其训练数据的最后日期。工具调用使其能够访问实时数据,回答"今天天气怎么样?"或"最近有什么关于 AI 的新闻?"这类问题。
- 执行实际动作:模型本身无法改变世界,但工具可以。通过调用发送邮件的工具、操作数据库的工具,模型可以将它的"想法"转化为实际的行动。
- 提升任务处理能力:对于一些精确计算或逻辑性极强的任务(如复杂的数学运算),语言模型有时会出错("幻觉")。将这些任务交给专业的工具(如计算器),可以保证结果的准确性。
- 构建更强大的应用:工具调用是构建智能代理(Agent)和复杂应用(如自动化工作流)的核心。它让 LLM 从一个单纯的"聊天机器人"进化为可以解决实际问题的"智能助手"。
Retrievers
LangChain 中的 Retrievers(检索器) 是框架中用于从数据源(如向量数据库、关键字索引或其他存储)检索相关文档的核心组件。它是 RAG(Retrieval-Augmented Generation,检索增强生成)系统的关键部分,负责根据用户查询(如问题或关键词)从存储的文档中找出最匹配的内容(通常是文档片段,称为 chunks),然后传递给 LLM(如 ChatOpenAI 或 DeepSeekLLM)生成答案。
主要作用:
检索相关信息:根据查询向量或关键字,从存储的文档中提取匹配项。
支持多种检索策略:包括向量相似度检索(基于 embedding)、关键字检索(BM25)、混合检索(稠密向量 + 稀疏向量)。
提升 LLM 准确性:通过提供真实文档,减少 LLM 的"幻觉"(hallucination),确保答案基于可靠数据。
工业应用:广泛用于知识库查询、文档搜索、故障诊断。例如,在工业场景中,Retriever 可从设备日志、技术手册或简历中检索相关内容,帮助 LLM 分析问题或筛选候选人。
Retrievers 通常与 VectorStore(向量存储)结合使用,支持异步检索和分数过滤(如相关度阈值)。LangChain 提供了内置 Retriever(如 VectorStoreRetriever),也支持自定义。