ceph分布式存储
一,什么是ceph分布式存储
Ceph 是一套开源、统一、去中心化的软件定义分布式存储系统 ,核心是RADOS ,能同时提供对象、块、文件三种存储服务,具备高可靠、无限扩展、无单点故障、自动自愈等特性,是云计算与云原生场景的主流存储方案。
Ceph采用模块化分布式架构,包含下列元素:
- 对象存储后端,称为RADOS(可靠的自主分布式对象存储)
- 与RADOS交互的多种访问方式
RADOS是一种自我修复、自我管理、基于软件的对象存储。
Ceph访问方式
Ceph提供以下访问Ceph集群的方法:
- Ceph原生API(librados)
- Ceph块设备(RBD、librbd),也称为RADOS块设备(RBD)镜像
- Ceph对象网关(RADOSGW、librgw)
- Ceph文件系统(CephFS、libcephfs)
Ceph存储后端组件
- 监控器(MON):维护集群状态映射。它们可帮助其他守护进程互相协调。
- 对象存储设备(OSD):存储数据并处理数据复制、恢复和重新平衡。
- 管理器(MGR):通过基于浏览器的仪表板和REST API,跟踪运行时指标并公开集群信息。
- 元数据服务器(MDS):存储CephFS使用的元数据(而非对象存储或块存储),以便客户端能够高效运行POSIX命令。
这些守护进程可以扩展,以满足所部署的存储集群的要求。
二,部署
Cephadm简介
Cephadm是一个ceph全生命周期管理工具,通过"引导(bootstrapping)"可创建一个包含一个MON和一个MGR的单节点集群,后续可通过自带的编排接口进行集群的扩容、主机添加、服务部署。
Cephadm使用容器部署Ceph,大大降低了部署Ceph集群的复杂性和包依赖性。
cephadm软件包安装在集群第一个节点中,该节点充当引导节点。Cephadm是部署新集群时启动的第一个守护程序,同时也是管理器守护程序(MGR)中的一个模块。
Cephadm管理接口
Ceph 使用容器化部署,首先创建一个最小的集群,只有一个主机(引导节点)和两个守护进程(监视器和管理器守护进程)。
Ceph 提供两个管理接口:Ceph CLI 和 Dashboard GUI,用于配置 Ceph 守护进程和服务以及扩展或收缩集群。
Ceph Dashboard 接口
Ceph Dashboard GUI 是一个基于 Web 的应用程序,用于监视和管理集群。
Ceph Dashboard GUI 得 到了增强,可通过此界面执行许多集群任务,比 Ceph CLI 更直观的方式提供集群信息。 与 Ceph CLI 一样,Dashboard GUI Web 是 ceph-mgr 守护进程的一个模块。 默认情况下,Ceph 在 创建集群时将 Dashboard GUI 部署在引导节点,并使用 TCP 端口 8443。
Ceph Dashboard GUI 提供以下功能:
用户和角色管理,用户可以创建具有多个权限和角色的不同用户帐户。
单点登录,仪表板 GUI 允许通过外部身份提供者进行身份验证。
审计,用户可以将仪表板配置为记录所有 REST API 请求。
安全,默认情况下,仪表板使用 SSL/TLS 来保护所有 HTTP 连接。
Ceph Dashboard GUI 还实现了集群管理和监控功能:
管理功能 使用 CRUSH 地图查看集群层次结构 启用、编辑和禁用管理器模块 创建、删除和管理 OSD 管理 iSCSI 管理池
监控功能 检查整体集群健康状况 查看集群中的主机及其服务 查看日志 查看集群警报 检查集群容量 下图显示了仪表板 GUI 的状态屏幕,可以快速查看一些重要的集群参数,例如集群状态、集群中的主机 数量或 OSD 数量。
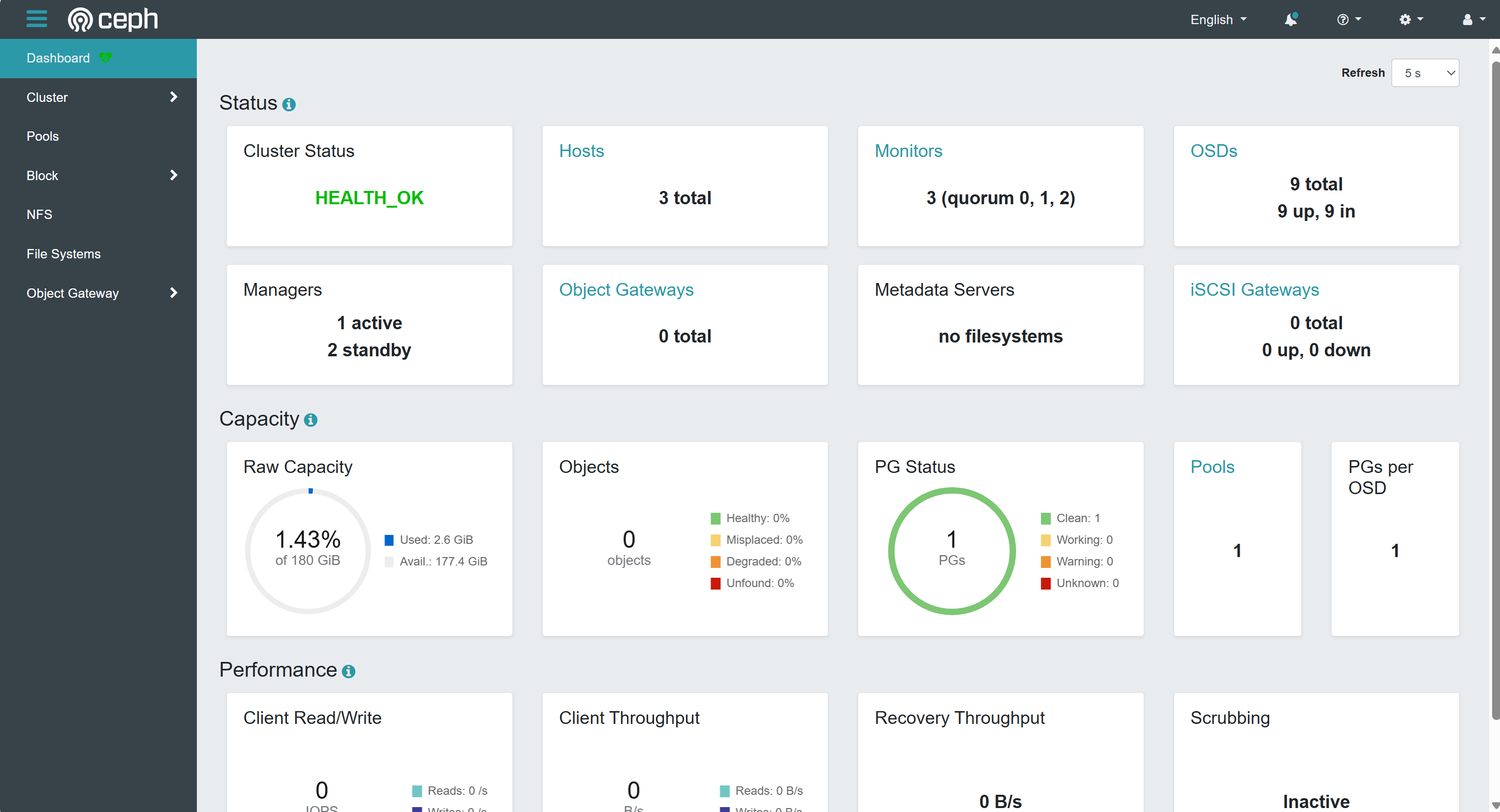
Ceph集群安装过程
Ceph集群环境说明
- 部署方法:cephadm
- 操作系统:Centos Stream 8(最小化安装)
- 硬件配置:2cpu、4G memory、1个系统盘 + 3个20G数据盘
共使用7台虚拟机:
- 客户端:client
- 主集群:ceph1、ceph2、ceph3
- 备集群:ceph4、ceph5、ceph6
| 主机名 | IP 地址 | 角色 |
|---|---|---|
| client.linux.cloud | 192.168.108.10 | 客户端节点 |
| ceph1.linux.cloud | 192.168.108.11 | 主集群-ceph 节点 |
| ceph2.linux.cloud | 192.168.108.12 | 主集群-ceph 节点 |
| ceph3.linux.cloud | 192.168.108.13 | 主集群-ceph 节点 |
| ceph4.linux.cloud | 192.168.108.14 | 备集群-ceph 节点 |
| ceph5.linux.cloud | 192.168.108.15 | 备集群-ceph 节点 |
| ceph6.linux.cloud | 192.168.108.16 | 备集群-ceph 节点 |
准备虚拟机模板
基于CentOS-Stream-8-template模板克隆出ceph-template。根据实验硬件要求,更改ceph-template硬件配置:内存8GB,处理器4,添加3块20G SCSI新硬盘。
-
配置主机名解析
-
关闭 SELinux
bash -
关闭防火墙
bash -
配置yum仓库
bash -
安装基础软件包
-
配置时间同步
bash -
安装cephadm
bash -
提前下载镜像
bash
准备集群节点 使用完全克隆方式,克隆出其他虚拟机,并配置主机名和IP地址。
Ceph集群初始化
bash
bash
[root@ceph1 ~]# cephadm bootstrap --mon-ip 192.168.108.11 --allow-fqdn-hostname --initial-dashboard-user admin --initial-dashboard-password linux@123 --dashboard-password-noupdate选项说明:
--mon-ip 192.168.108.11:指定 monitor ip。--allow-fqdn-hostname:指定允许使用长名称。当主机名是长名称时,初始化时必须使用该参数。--initial-dashboard-user admin:指定 Web UI 登录的管理员账户。--initial-dashboard-password linux@123:指定 Web UI 登录的管理员账户对应密码。--dashboard-password-noupdate:指定不要更新 Web UI 登录密码。
输出信息包含Dashboard登录信息和客户端访问方法。
物理机访问https:ceph1.linux.cloud:8443
用户admin 密码linux@123
添加节点
- 使用命令
ceph cephadm get-pub-key获取到主机接入集群时所需的ssh公钥。 - 使用该公钥实现对节点的免密ssh管理。
- 使用命令
ceph orch host add添加主机。
bash
部署 mon 和 mgr
bash
部署OSD
[root@ceph1 ~]# ceph orch apply osd --all-available-devices验证
ceph orch ls:查看集群中部署的服务ceph -s:查看集群状态ceph osd tree:查看集群osd结构ceph orch ps:查看集群组件
Ceph集群组件管理
ceph orch命令
ceph orch 命令与编排器模块交互,编排器模块是ceph-mgr的插件,与外部编排服务交互。
禁用服务自动扩展
Ceph 集群服务自动扩展功能,会自动部署ceph组件到存储节点。如果想手动管理 ceph 服务,则需要禁 用 ceph 服务自动扩展功能。
删除OSD
- 编排删除(推荐):自动drain数据,停止OSD容器,执行crush remove、auth del、osd rm,可选zap磁盘。
- 手动删除(不推荐,有风险)
删除主机
流程:
- 禁用集群所有服务自动扩展
- 查看待删除主机上当前运行的服务
- 停止待删除主机上的所有服务
- 删除主机上的所有服务
- 删除osd在CRUSH中的映射
- 擦除osd盘中的数据
- 从集群中删除主机
三,集群配置
管理集群配置
Ceph集群配置概述
Ceph配置选项具有唯一名称,该名称由下划线连接的小写字符组成。
当存在多个设置源时,配置生效原则:较新设置将覆盖较早设置源中的设置。配置文件会在启动时配置守护进程。配置文件设置会覆盖存储在中央数据库中的设置。监控器(MON)节点管理集中配置数据库。
修改集群配置文件
Ceph会去以下目录中查找集群相关配置文件:
CEPH_CONF环境变量中包含的路径cpath/path:由命令行参数"-c"指定的路径/cluster.conf/.ceph/Cluster.conf/etc/ceph/Cluster.conf(默认位置)
配置部分
[global]:所有守护进程(包括客户端)共有的一般配置[mon]:监控器(MON)的配置[osd]:OSD守护进程的配置[mgr]:管理器(MGR)的配置[mds]:元数据服务器(MDS)的配置[client]:应用到所有Ceph客户客户端的配置
元变量
$cluster:Ceph存储集群的名称。默认集群名称为ceph。$type:守护进程类型,如mon、osd、mds、mgr、client。$id:守护进程实例ID。$name:守护进程名称和实例ID,是$type.$id的简写。$host:运行守护进程的主机的名称。
集中配置数据库管理命令
ceph config ls:列出集群数据库中所有配置条目。ceph config help <key>:查看特定配置帮助信息。ceph config dump:显示所有被显式设置过的配置项。ceph config show <type.id> [<key>]:显示被显式设置过的配置项。ceph config show-with-defaults <type.id>:显示所有配置项及当前值(包括默认值)。ceph config get <type.id> <key>:获得集群数据库中特定配置设置。ceph config set <type.id> <key> <value>:设置集群数据库中特定配置选项。ceph config rm <type.id> <key>:清除集群数据库中特定配置选项。ceph config log [<num:int>]:显示集群最近配置历史记录。ceph config reset [<num:int>]:回滚集群数据中特定配置为num指定的历史版本。
配置集群监控器 Monitor
配置Ceph监控器
Ceph监控器(MON)存储和维护客户端用于查找MON和OSD节点的集群映射。
各MON分别具有以下其中一个角色:
- Leader:第一个获得集群映射最新版本的MON。
- Provider:拥有最新版本的集群映射,但不是Leader的MON。
- Requester:没有最新版本的集群映射,必须先与Provider同步,然后才能重新加入仲裁的MON。
查看监控器仲裁:
ceph status | grep monceph mon statceph quorum_status -f json-pretty
管理集中配置数据库
MON节点存储和维护集中配置数据库,数据库文件位于MON节点,默认位置是:/var/lib/ceph/$fsid/mon.$host/store.db。
改进措施:
- 运行
ceph tell mon.$id compact命令,整合数据库。 - 将
mon compact on start配置选项为TRUE,以便在每次守护进程启动时压缩数据库。
集群验证
Ceph默认使用Cephx协议进行加密身份验证,同时使用共享密钥进行身份验证。
参数说明:
auth_service_required:客户端与Ceph services之间通信认证。可用值cephx和none。auth_cluster_required:Ceph集群守护进程之间通信认证。可用值cephx和none。auth_client_required:客户端与Ceph集群之间通信认证。可用值cephx和none。
配置公共网络和集群网络
public网络是所有Ceph集群通信的默认网络。配置单独的cluster网络可能会减少public网络的流量负载并与后端OSD运维流量进行客户端分流,从而提高集群的性能。
配置防火墙规则
| 服务名称 | 端口 | 描述 |
|---|---|---|
| 监控器(MON) | 6789/TCP, 3300/TCP | Ceph集群内的通信 |
| OSD | 6800-7300/TCP | 每个OSD使用这个范围中的三个端口 |
| 元数据服务器(MDS) | 6800-7300/TCP | 与Ceph元数据服务器通信 |
| 控制面板/管理器(MGR) | 8443/TCP | 通过SSL与Ceph管理器控制面板通信 |
四,池管理
POOL
池是Ceph存储集群的逻辑分区,用于在通用名称标签下存储对象。
每个池具有以下可调整属性:
- 池ID
- 池名称
- PG数量
- CRUSH规则
- 保护类型(复本或擦除编码)
- 与保护类型相关的参数
- 影响集群行为的各种标志
Place Group
PG全称为Placement group,是构成pool的子集,也是一系列对象的集合。一个PG仅能属于一个Pool。
PG数量会影响ceph的性能。PG数量设置原则:
- 如果OSD少于5个时,PG数量设置为128
- OSD数量大于5小于10时,PG数量设置为512
- OSD数量大于10小于50时,PG数量设置为4096
- 如果osd数量大于50,则需要借助工具进行计算:https://old.ceph.com/pgcalc
映射对象到OSD
- Ceph客户端从MON获取最新的集群映射复本。
- 计算PG ID:
PG ID = hash(Object ID) % PG number - Ceph使用CRUSH算法确定PG负责哪些OSDs(Acting Set)。
- Ceph客户端直接跟主OSD通信以读写对象。
数据保护
Ceph存储支持:复本池和纠删码池。
- replicated pool(复本池):通过将各个对象复本到多个OSD来发挥作用。
- Erasure code pool(纠删代码池):需要较少的存储空间和网络带宽,但因为要进行奇偶校验计算,所以会占用较多的CPU处理时间。
创建池
创建复本池
bash
ceph osd pool create pool-name pg-num pgp-num replicated crush-rule-name创建纠删代码池
bash
ceph osd pool create pool-name pg-num pgp-num erasure erasure-code-profile crush-rule-name管理池
管理池应用类型
使用 ceph osd pool application 命令管理池Ceph应用类型(cephfs、rbd、rgw)。
管理池配额
ceph osd pool get-quota:获取池配额信息ceph osd pool set-quota:设置池配额
管理池中对象
使用 rados 命令管理池的对象:
- 上传对象:
rados -p <pool_name> put <object_name> <file> - 查看对象:
rados -p <pool_name> ls - 检索对象:
rados -p <pool_name> get <object_name> <file> - 删除对象:
rados -p <pool_name> rm <object_name>
管理池快照
- 创建快照:
ceph osd pool mksnap <pool_name> <snap_name> - 删除快照:
ceph osd pool rmsnap <pool_name> <snap_name>
管理池命名空间
命名空间可以对池中对象进行逻辑分组。
重命名池
bash
ceph osd pool rename <old_name> <new_name>删除池
bash
# 需要先设置 mon_allow_pool_delete 为 true
ceph config set mon mon_allow_pool_delete true
ceph osd pool rm <pool_name> <pool_name> --yes-i-really-really-mean-it五,认证和授权管理
Ceph集群身份验证
cephx协议
Ceph存储使用cephx协议管理集群认证。
账户名称
- Ceph守护进程使用的帐户与守护进程名称相匹配,例如 osd.1 或 mgr.ceph1。
- 使用librados的客户端应用所用帐户的名称具有
client.前缀。 - 安装程序会创建超级用户帐户
client.admin。
密钥环文件
Ceph创建用户帐户时,为每个用户帐户生成密钥环文件,通过密钥环文件验证用户身份。默认位置:/etc/ceph/$cluster.$name.keyring。
管理用户账户
- 查看:
ceph auth ls或ceph auth get - 创建:
ceph auth add、ceph auth get-or-create、ceph auth get-or-create-key - 删除:
ceph auth del或ceph auth rm - 导出/导入:
ceph auth export、ceph auth import
配置用户账户功能
cephx中的权限称为功能(caps)。
常用功能:
allow:在守护进程的访问权限之前设置。r:授予读取访问权限。w:授予写入访问权限。x:授予执行扩展对象类的权限。*:授予完整访问权限。
预定义功能配置文件:osd、bootstrap-osd、rbd、rbd-read-only等。
六,块存储管理
管理RADOS块设备
块设备是服务器、笔记本电脑和其他计算系统上最为常见的长期存储设备。它们以固定大小的块存储数 据。块设备包括基于旋转磁盘的硬盘驱动器,以及基于非易失性存储器的固态驱动器。若要使用存储, 用户要使用文件系统格式化块设备,并将它挂载到 Linux 文件系统层次结构中。 Ceph 存储集群的RADOS 块设备 (RBD) 功能 提供虚拟块设备,并以RBD 镜像形式存储在Ceph 存储集群 的池中。
创建RBD镜像
- 创建rbd池:
ceph osd pool create images_pool - 初始化池:
rbd pool init images_pool - 创建RBD镜像:
rbd create images_pool/webapp1 --size 1G
访问RADOS块设备存储
- 使用内核RBD(KRBD)访问Ceph块存储
- 使用librbd库访问Ceph块存储
RBD缓存
RBD缓存对客户端而言是本地的,因为它使用发起I/O请求的计算机上的RAM。
缓存模式:
- 回写缓存(write-back):缓存写入完成即确认写入完成。
- 直写缓存(Write-through):数据写入缓存和所有相关OSD后才确认。
管理RADOS块设备快照
- 创建快照:
rbd snap create <pool_name>/<image_name>@<snap_name> - 查看快照:
rbd snap ls <pool_name>/<image_name> - 回滚快照:
rbd snap rollback <pool_name>/<image_name>@<snap_name> - 删除快照:
rbd snap rm <pool_name>/<image_name>@<snap_name>
RBD克隆
克隆过程:
- 创建快照
- 保护快照:
rbd snap protect <pool_name>/<image_name>@<snap_name> - 创建克隆:
rbd clone <pool_name>/<image_name>@<snap_name> <pool_name>/<clone_name> - 扁平化克隆(可选):
rbd flatten <pool_name>/<clone_name>
RBD Mirror
RBD镜像功能支持在两个存储集群之间进行RBD镜像同步。
镜像模式:
- 基于日志的镜像
- 基于快照的镜像
镜像配置:
- 单向镜像(主动-被动)
- 双向镜像(主动-主动)
七,对象存储管理
对象存储介绍
对象存储将数据存储为离散项,每一项也是一个对象。每个对象都具有唯一的对象ID(也称对象密钥)。
RADOS 网关介绍
RADOS GateWay(RGW)为客户端提供标准对象存储 API 来访问 Ceph 集群,支持 Amazon S3 和 OpenStack Swift API。
RADOS网关架构
- 区域(zone):每个区域会关联一个或多个RADOS网关,这些网关关联Ceph存储。
- 区域组(zone group):由一个或多个区域的集合。存储在区域组中某个区域中的数据会被复制到该区域组中的所有其他区域。
- 域(realm):代表所有对象和存储桶的全局命名空间。域中含有一个或多个区域组,各自包含一个或多个区域。
RADOS 网关部署
- 创建对象存储域
- 创建对象网关
RADOS 网关用户管理
- 创建用户:
radosgw-admin user create --uid="operator" --display-name="s3 Operator" - 列出现有用户:
radosgw-admin user list - 查看用户信息:
radosgw-admin user info --uid=<uid> - 修改用户信息:
radosgw-admin user modify - 删除用户:
radosgw-admin user rm --uid=<uid> --purge-data
使用 Amazon S3 API 访问对象存储
安装awscli工具并配置凭证后,可以使用aws命令操作对象存储:
- 创建存储桶:
aws s3 mb s3://<bucket_name> --endpoint=<rgw_url> - 查看存储桶:
aws s3 ls --endpoint=<rgw_url> - 上传对象:
aws s3 cp <local_file> s3://<bucket_name>/ --endpoint=<rgw_url> - 下载对象:
aws s3 cp s3://<bucket_name>/<object_name> <local_file> --endpoint=<rgw_url> - 删除对象:
aws s3 rm s3://<bucket_name>/<object_name> --endpoint=<rgw_url> - 删除存储桶:
aws s3 rb s3://<bucket_name> --endpoint=<rgw_url>
八,文件系统存储管理
介绍 CephFS
Ceph文件系统 (CephFS) 是构建在Ceph存储之上的一种兼容POSIX的文件系统。
元数据服务器
元数据服务器 (MDS) 负责管理目录层次结构和文件元数据。
MDS运行模式:
- 活动 MDS:负责管理CephFS文件系统上的元数据。
- 备用 MDS:充当备份,并会在活动MDS无响应时切换到活动模式。
部署CephFS
手动部署
- 创建所需池(数据池和元数据池)
- 创建CephFS文件系统:
ceph fs new <fs_name> <metadata_pool> <data_pool> - 部署MDS守护进程:
ceph orch apply mds <fs_name> --placement="<placement>"
卷部署
bash
ceph fs volume create <fs_name> --placement="<placement>"挂载 CephFS 文件系统
使用Kernel挂载
bash
mount.ceph <mon_ip>:/ <mount_point> -o name=<client_name>,fs=<fs_name>使用FUSE挂载
bash
ceph-fuse -n client.<client_name> -r <sub_directory> <mount_point>管理CephFS
管理快照
- 创建快照:
mkdir /mnt/cephfs1/.snap/snap - 恢复文件:从快照目录复制文件
- 删除快照:
rmdir /mnt/cephfs1/.snap/snap/
CephFS Mirror
CephFS Mirror用于在两个或多个Ceph集群之间实现文件系统的异步复制(镜像),主要用于灾难恢复和数据备份。
主要特点:
- 异步复制
- 基于快照
- 多集群支持
h apply mds <fs_name> --placement=""`
卷部署
bash
ceph fs volume create <fs_name> --placement="<placement>"挂载 CephFS 文件系统
使用Kernel挂载
bash
mount.ceph <mon_ip>:/ <mount_point> -o name=<client_name>,fs=<fs_name>使用FUSE挂载
bash
ceph-fuse -n client.<client_name> -r <sub_directory> <mount_point>管理CephFS
管理快照
- 创建快照:
mkdir /mnt/cephfs1/.snap/snap - 恢复文件:从快照目录复制文件
- 删除快照:
rmdir /mnt/cephfs1/.snap/snap/
CephFS Mirror
CephFS Mirror用于在两个或多个Ceph集群之间实现文件系统的异步复制(镜像),主要用于灾难恢复和数据备份。
主要特点:
- 异步复制
- 基于快照
- 多集群支持
- 增量复制