
一张表,2000 万行,为什么只需要 3 次 IO?
假设你有一张用户表,存了 2000 万条记录。没有索引时,一次 SELECT * FROM users WHERE id = 19999999 要扫描整张表,在机械硬盘上这意味着几秒钟的等待。加了主键索引之后,同样的查询响应时间降到毫秒级。
背后发生了什么?答案在一个叫 B+ 树的数据结构里。
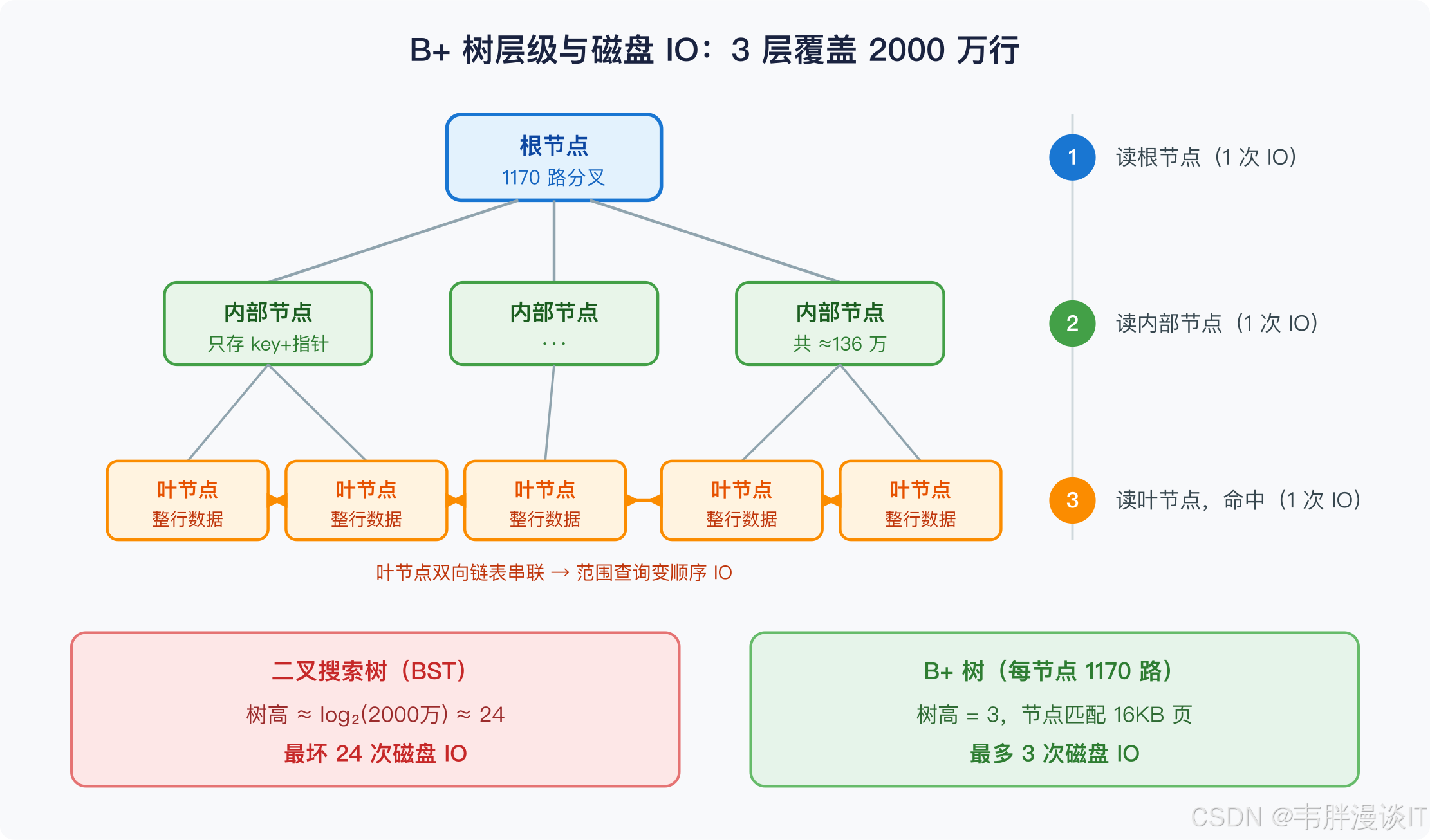
更反直觉的数字是:InnoDB 默认页大小 16KB,一个 3 层的 B+ 树足以覆盖约 2000 万行 数据,每次精确查找最多触发 3 次磁盘 IO。这不是调参调出来的,是结构决定的。
理解这个结论,需要先弄清楚一件事:数据库的真正性能瓶颈不在 CPU,在磁盘。
磁盘才是真正的敌人
内存随机读取延迟约 100 纳秒;SSD 随机读取约 100 微秒;机械硬盘随机读取约 10 毫秒。这不是 10 倍的差距,是 10 万倍。
数据库设计者在选择索引数据结构时,优化目标只有一个:把磁盘随机 IO 次数降到最低。
拿常见的二叉搜索树(BST)对比一下。同样 2000 万行数据,平衡二叉树的高度约为 log₂(20,000,000) ≈ 24,最坏需要 24 次磁盘 IO。每次 IO 读一个节点,只得到一个 key,利用率极低。
B+ 树的策略完全不同:让每个节点变胖 。一个 16KB 的页,假设索引 key 是 8 字节的 bigint,加上 6 字节的子节点指针,每个内部节点能放约 16384 / (8 + 6) ≈ 1170 个 key,也就是 1170 路分叉。
- 第 1 层(根节点):覆盖 1170 个子树
- 第 2 层:覆盖
1170 × 1170 ≈ 136 万个叶节点 - 第 3 层(叶节点):每页存约 16 行完整数据(假设每行 1KB),共约 2176 万行
3 次 IO,2000 万行,精确命中。
B 树 vs B+ 树:一个关键的设计分叉
B+ 树从 B 树演化而来,但做了两个关键改动,每个改动都针对磁盘特性量身定制。
改动一:数据只存叶节点,内部节点只存 key 和指针。
B 树的内部节点同时存 key 和 data,导致每个内部节点能塞的 key 变少,树变高,IO 次数增多。B+ 树把数据全部下沉到叶节点,内部节点变成纯导航结构,扇出(fan-out)最大化,树高被压到极低。
以 InnoDB 的聚簇索引为例:叶节点存整行数据,非叶节点只存主键值和页号(6 字节指针)。这是一个刻意的权衡:牺牲"在中间节点命中直接返回"的可能性,换取稳定的低树高和最大扇出。
改动二:所有叶节点通过双向链表串联。
这解决了范围查询的问题。假设你执行 WHERE create_time BETWEEN '2024-01-01' AND '2024-12-31'------在 B 树里,你必须反复回溯到中间节点再下探,路径杂乱;在 B+ 树里,找到起始叶节点后,顺着链表向右扫就行,变成顺序 IO,比随机 IO 快一到两个数量级。
MySQL 的排序(ORDER BY)、分组(GROUP BY)利用这条链表几乎"免费"完成,LIMIT 分页也是顺着链表数格子,无需重复遍历树。
聚簇索引:InnoDB 的深度工程选择
InnoDB 在 B+ 树之上还做了一层设计:聚簇索引(Clustered Index)。
聚簇索引的叶节点直接存储整行数据,而不是数据行的磁盘地址。这意味着数据的物理存储顺序就是主键顺序------表即索引,索引即表。
效果是:按主键查询或范围扫描时,找到叶节点就找到了数据,不需要再跳一次去读实际数据行(MyISAM 的非聚簇索引需要这个"回表"操作)。InnoDB 少一次随机 IO。
代价呢?写入性能对主键选择非常敏感。
- 自增 INT 主键:新行永远插入末尾,页分裂几乎不发生,写入高效。
- UUID 主键:UUID 随机分布,每次插入都可能落在 B+ 树中间某个满页,触发页分裂,频繁移动磁盘块。在高写入场景下,UUID 主键的 InnoDB 表写性能可比自增主键差 30%-50%。
这不是理论推断。GitHub 在早期曾经因为一批使用随机 UUID 作为主键的表出现严重写入抖动,后来部分表改回自增主键或使用时序 UUID(如 UUIDv7)。原理正是 B+ 树页分裂的代价。
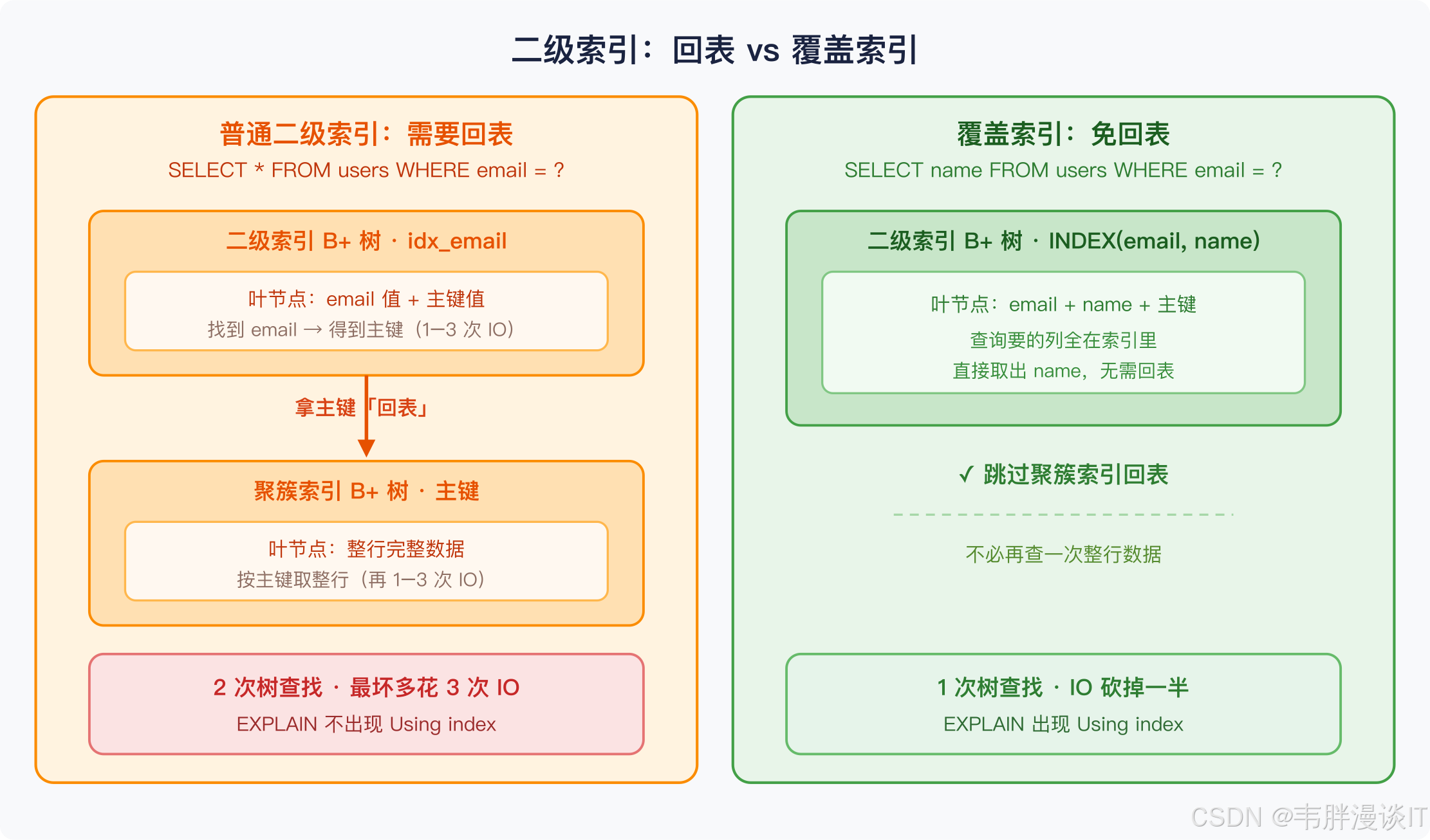
二级索引:回表的代价
除主键外,用户加的普通索引(如 INDEX idx_email (email))都是二级索引 ,同样是 B+ 树结构,但叶节点不存整行数据,只存 索引列值 + 主键值。
查询走二级索引时:
- 在二级索引 B+ 树里找到对应的主键值(1-3 次 IO)
- 拿着主键值回到聚簇索引 B+ 树查完整行数据(1-3 次 IO)
这叫回表,最坏情况多花 3 次 IO。
针对这个代价,有一个经典优化叫覆盖索引(Covering Index):如果查询所需的列全都在索引里,不需要回表。
sql
-- 假设有 INDEX(email, name)
SELECT name FROM users WHERE email = 'alice@example.com';
-- 直接在二级索引叶节点取到 name,无需回表EXPLAIN 里出现 Using index 就是走了覆盖索引,跳过了主键回表,节省一半 IO。
这是 DBA 优化 SQL 时最常用的手段之一,本质是利用 B+ 树叶节点的数据布局,主动减少磁盘访问次数。
局限性:B+ 树不是万能钥匙
理解 B+ 树的设计权衡,才能理解它的边界。
等值查询:哈希表更快。
哈希索引的等值查询是 O(1),B+ 树是 O(log N)。如果只有等值查询没有范围查询,哈希表是更优的选择。MySQL 的 Memory 引擎默认用哈希索引;PostgreSQL 也提供 Hash Index 类型,专门应对高频等值查询场景。
高维向量查询:B+ 树无法胜任。
近年来 AI 应用爆发,向量数据库(如 Milvus、Weaviate、pgvector)需要做近似最近邻搜索(ANN)。B+ 树基于全序比较,无法处理高维欧氏距离。这类场景使用的是 HNSW(分层可导航小世界图)或 IVF(倒排文件索引)等完全不同的结构。
写放大问题。
B+ 树的页分裂和页合并在高并发写入时会产生写放大效应。LSM-Tree(Log-Structured Merge-Tree)在这一点上更优秀,它把随机写转化为顺序写,RocksDB、LevelDB、Cassandra 都采用了 LSM-Tree,而不是 B+ 树。
B+ 树的统治地位来自它在读写均衡、范围查询、磁盘亲和性三角的综合最优解。当某一个维度被极端放大(纯写吞吐、向量搜索、等值查询),专用结构会取而代之。
结尾:工程权衡的本质
B+ 树不是凭空发明出来的。它是 1972 年 Rudolf Bayer 和 Edward McCreight 在设计磁盘文件系统索引时,针对磁盘物理特性做出的一系列权衡结果:
- 磁盘读写以块为单位 → 让节点大小匹配磁盘块
- 随机 IO 昂贵 → 压缩树高,减少 IO 次数
- 范围查询常见 → 叶节点串成链表,变随机为顺序
- 数据需要持久化 → 每个节点是独立的磁盘页,便于写回和缓存
这些选择在 50 年前确定,今天仍然驱动着全球绝大多数 OLTP 数据库。
技术落地的真实底色不是追新,而是在约束条件下找到最能解决真实痛点的那个结构。理解 B+ 树,不只是理解一棵树,而是理解一代工程师如何把"磁盘很慢"这个约束,变成一个优雅的数据结构决策。