之前在一台内存有限的设备上进行了尝试,下面我们在12G内存RTX4070显卡设备上再次尝试
一、准备工作
主要是部署训练环境、下载模型依赖库、下载模型这些工作
这里安装anaconde的环境就不细说了,为了方便版本管理,在conda中创建虚拟环境并在其中操作
bash
conda create -n qwen3_tts python=3.12 && conda activate qwen3_tts
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
安装其他依赖
**qwen-tts:**pip install -U qwen-tts
**modelscope:**pip install -U modelscope
**ffmpeg:**conda install -c conda-forge ffmpeg -y
**soundfile:**pip install soundfile

然后验证安装结果
bash
python -c "import torch; print(torch.__version__); print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))"
下面是模型下载,现在12G内存的条件下就主要使用1.7B的模型
bash
modelscope download --model Qwen/Qwen3-TTS-12Hz-1.7B-Base --local_dir "E:\work\...\Qwen3-TTS-12Hz-1.7B-Base"这里的路径需要根据情况更改
二、数据准备
这里和之前的要求一样,需要16kHz的wav格式录音文件,和录音文件对应的文本内容,还有一个参考音频(也可以和录音文件一致)
在Qwen3-TTS目录下创建test-data文件夹放入wav的录音文件和对应文本
命令行微调(暂时不使用)
之前的记录没有做好归纳,这里总结为以下几步
步骤一 --- 准备 JSONL 训练数据(含字段说明和数据建议)
步骤二 --- prepare_data.py 提取 audio_codes
步骤三 --- sft_12hz.py 执行 SFT 微调(含参数详解 + 显存参考表)
步骤四 --- 加载 checkpoint 推理测试
这里简要记录流程,本次主要介绍下面的两种使用方式
三、web界面训练
这里可以直接运行启动web界面命令
bash
qwen-tts-demo Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice --ip 0.0.0.0 --port 8000 --no-flash-attn但是遇到了报错:
********
Warning: flash-attn is not installed. Will only run the manual PyTorch version. Please install flash-attn for faster inference.
********
'sox' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
SoX could not be found!
If you do not have SoX, proceed here:
If you do (or think that you should) have SoX, double-check your
path variables.
这里先忽略警告问题(警告理论上也需要解决,但是不是关键问题,只是不使用flash-attn的提示警告)
先安装sox这个库。这里要注意的是,不能直接通过pip来安装(pip安装的只是一个接口)
可以现在 http://sox.sourceforge.net/ 中下载库文件,手动安装在本地,然后配置环境变量
相当于安装一个独立库软件
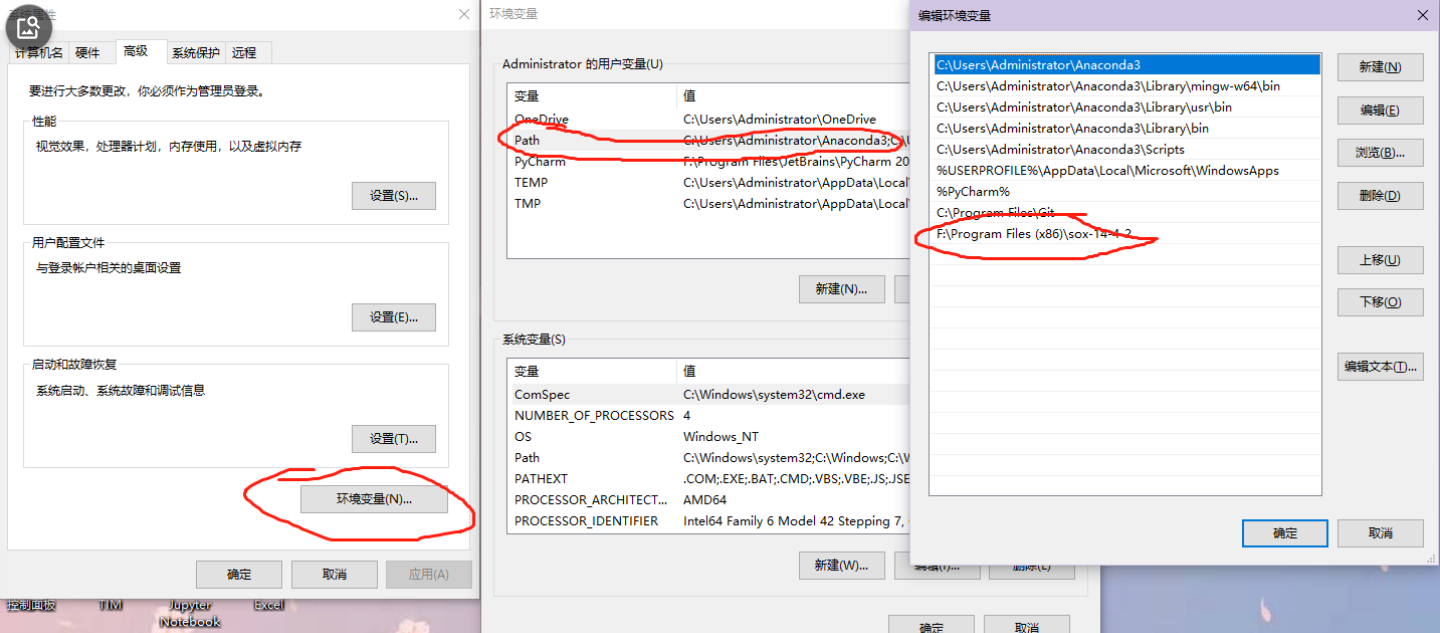
完整步骤可以参考大佬的博客:Windows下sox的安装和使用方法_windows安装sox-CSDN博客
但是还是出现了问题
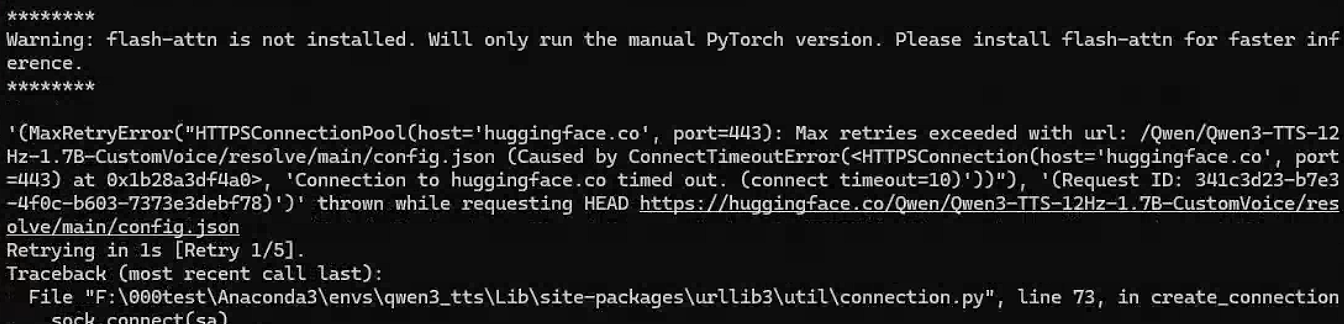
开始还很奇怪,后来明白目前只是下载Base模型,CustomVoice还需要从HF下载,才有这个问题
更改一下命令,切换到本地模型所在目录再执行
bash
qwen-tts-demo Qwen3-TTS-12Hz-1.7B-Base --ip 0.0.0.0 --port 8000 --no-flash-attn现在可以找到模型了

进入本地的8000端口,可以看到训练界面
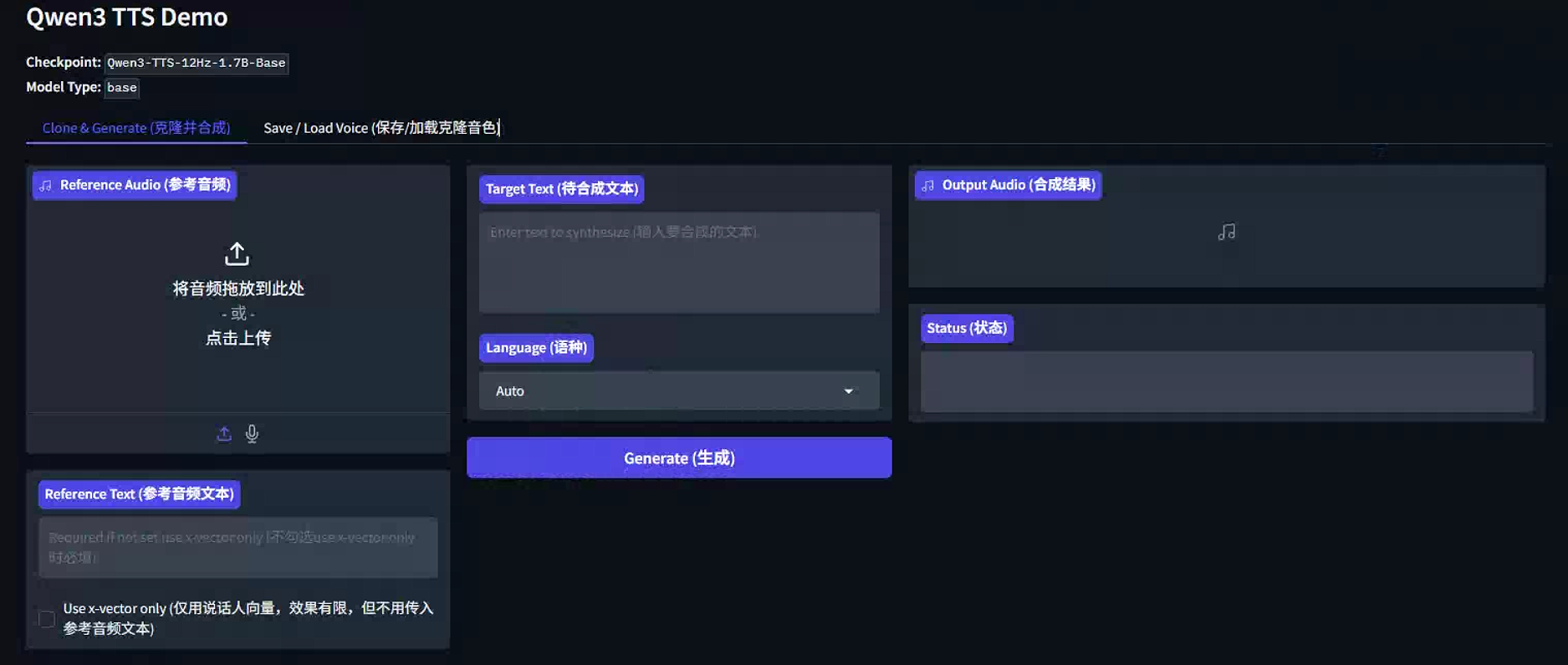
四、api调用
这里的使用方式是登录阿里云百炼 Model Studio,获取 DASHSCOPE_API_KEY,安装dashscope的SDK
python
pip install -U dashscope下面是测试脚本
python
import os
import dashscope
dashscope.base_http_api_url = 'https://dashscope.aliyuncs.com/api/v1'
response = dashscope.MultiModalConversation.call(
model="qwen3-tts-flash",
api_key="sk-XXX", # 直接写这里
text="你好,这是通义千问语音合成测试。",
voice="Cherry",
language_type="Chinese",
stream=False
)
if response.status_code == 200:
audio_url = response.output.audio.url
print("音频生成成功,下载链接:", audio_url)
else:
print("错误:", response.code, response.message)
下载之后是可以听到效果
五、总结
这里更改了上一篇文章的代码微调方式,使用了webui和api两种方式进行使用,但是对于该tts模型的深入程度不够,还在简单调用的阶段。在记录中还有一些不到位的地方,欢迎大佬们指正