MTP(Multi-Token Prediction,多Token预测)是一项新兴的大模型推理优化技术。本文基于完整测试数据,对比vLLM和llama.cpp在MTP模式下的性能表现,并提供可操作的部署指南。
什么是MTP(多Token预测)?
MTP是Google在Gemma 4中引入的一种推测解码技术。与传统逐Token生成不同,MTP允许模型在一次前向传播中预测多个Token,然后用验证器快速验证这些预测是否正确。如果预测准确,就能跳过多个推理步骤,从而实现加速。
简单理解:传统方式像一个字一个字说话,MTP则像一口气说出一句话,只要说得对,速度就快很多。
测试环境配置
|------|-------------------------------|
| 处理器 | AMD Ryzen 9 9950X |
| 显卡 | NVIDIA RTX PRO 6000 Blackwell |
| 显存 | 96GB |
| 内存 | 92GB |
| 操作系统 | Ubuntu 24.04 Desktop |
完整测试结果:13组配置排名
以下是13组不同配置的完整测试数据,覆盖了vLLM和llama.cpp两款推理引擎。
| 排名 | 引擎 | 模型 | 量化 | MTP | n | 速度 |
|---|---|---|---|---|---|---|
| 1 | vLLM | Gemma 4 31B | FP8 | 是 | 5 | 132.52 |
| 2 | vLLM | Gemma 4 31B | FP8 | 是 | 4 | 129.82 |
| 3 | vLLM | Qwen 3.6 27B | FP8 | 是 | 5 | 127.31 |
| 4 | vLLM | Gemma 4 31B | FP8 | 是 | 3 | 124.26 |
| 5 | vLLM | Qwen 3.6 27B | FP8 | 是 | 4 | 121.96 |
| 6 | llama.cpp | Qwen 3.6 27B | Q8 | 是 | 3 | 117.70 |
| 7 | llama.cpp | Qwen 3.6 27B | Q8 | 是 | 5 | 116.74 |
| 8 | llama.cpp | Qwen 3.6 27B | Q8 | 是 | 4 | 114.21 |
| 9 | llama.cpp | Qwen 3.6 27B | Q8 | 是 | 2 | 95.75 |
| 10 | vLLM | Gemma 4 31B | FP8 | 是 | 2 | 94.00 |
| 11 | vLLM | Qwen 3.6 27B | FP8 | 否 | - | 49.23 |
| 12 | llama.cpp | Qwen 3.6 27B | Q8 | 否 | - | 43.40 |
| 13 | vLLM | Gemma 4 31B | FP8 | 否 | - | 39.69 |
注:11-13为无MTP的基准测试结果。
关键发现
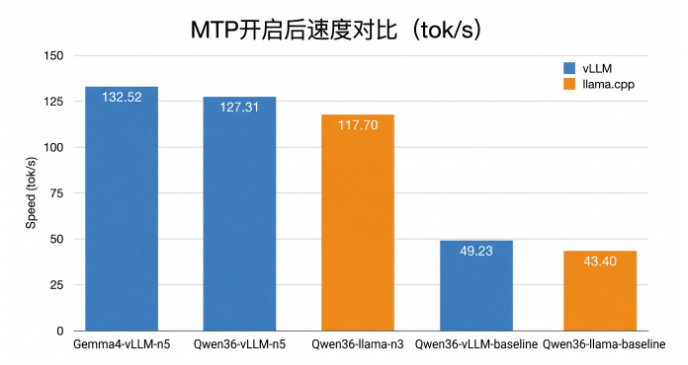
**MTP效果显著:**开启MTP后,Qwen3.6 vLLM从49.23 tok/s提升到127.31 tok/s,加速达2.59倍。
**n参数影响性能:**随着n值增大,速度通常提升,但提升幅度逐渐减小。n=3-5是较为理想的选择。
**vLLM略占优势:**在相同配置下,vLLM普遍比llama.cpp快约9%,但llama.cpp在量化模型兼容性上更好。
**最佳性能:**Gemma 4 31B FP8 + vLLM + MTP n=5 达到 132.52 tok/s。
部署指南:手把手启动MTP服务
下面提供三种主流部署方案,均已在Ubuntu 24.04上验证通过。
方案一:llama.cpp 部署 Qwen3.6-27B-MTP(GGUF格式)
第一步:编译llama.cpp(需支持MTP)
# 克隆llama.cpp(MTP已合并到主分支)
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
# NVIDIA CUDA编译
cmake -B build -DGGML_CUDA=ON -DCMAKE_BUILD_TYPE=Release
cmake --build build --target llama-server -j$(nproc)
# 验证MTP支持
./build/bin/llama-server --help | grep spec-type第二步:下载MTP专用模型
# 安装huggingface_hub
pip install huggingface_hub
# 下载Qwen3.6-27B-MTP GGUF模型
huggingface-cli download unsloth/Qwen3.6-27B-MTP-GGUF \
Qwen3.6-27B-Q4_K_M.gguf \
--local-dir ~/models/qwen36-27b-mtp第三步:启动服务(启用MTP)
./build/bin/llama-server \
-m ~/models/qwen36-27b-mtp/Qwen3.6-27B-Q4_K_M.gguf \
--host 0.0.0.0 \
--port 8000 \
-c 32768 \
-ngl 99 \
-fa on \
--spec-type draft-mtp \
--spec-draft-n-max 3关键参数说明:
--spec-type draft-mtp:启用MTP推测解码模式(必填)--spec-draft-n-max 3:每次最多预测3个Token(推荐2-4)-fa on:启用FlashAttention加速-ngl 99:将所有层加载到GPU
方案二:vLLM 部署 Qwen3.6-27B(FP8格式)
第一步:安装vLLM nightly
# 安装vLLM nightly版本(支持MTP)
pip install vllm>=0.8.0第二步:启动服务(启用MTP)
vllm serve Qwen/Qwen3.6-27B-FP8 \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 1 \
--speculative-config '{"method":"mtp","num_speculative_tokens":4}'启动命令(无MTP对比):
vllm serve Qwen/Qwen3.6-27B-FP8 \
--host 0.0.0.0 \
--port 8001 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 1方案三:vLLM 部署 Gemma 4 31B(FP8格式)
前置条件:
- 安装vLLM nightly版本
- 至少80GB显存
- 接受Gemma许可协议
启动命令(启用MTP):
vllm serve RedHatAI/gemma-4-31B-it-FP8-block \
--host 0.0.0.0 \
--port 8000 \
--max-model-len 8192 \
--gpu-memory-utilization 0.9 \
--max-num-seqs 1 \
--speculative-config '{"method":"mtp","num_speculative_tokens":5}'验证服务是否正常运行
健康检查:
# 检查服务状态
curl -sS http://127.0.0.1:8000/health
# 查看可用模型
curl -sS http://127.0.0.1:8000/v1/models测试推理:
curl http://127.0.0.1:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3.6-27B-FP8",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 100
}'Docker部署(推荐)
使用Docker可以简化环境配置,推荐使用官方提供的docker-compose配置。
快速启动:
# 1. 克隆项目
git clone https://github.com/lukaLLM/llamacpp-vllm-mtp-setup-and-speed-benchmark-qwen3.6-gemma4.git
cd llamacpp-vllm-mtp-setup-and-speed-benchmark-qwen3.6-gemma4
# 2. 配置环境变量
cp .env.example .env
# 编辑.env文件,设置HF_TOKEN
# 3. 启动服务(以Qwen3.6 MTP为例)
docker compose --env-file .env \
-f docker/docker-compose_mtp_qwen3.6_27B.yaml up -d服务端口对照:
| 服务 | 端口 | 说明 |
|---|---|---|
| Qwen3.6 MTP | 8000 | llama.cpp + MTP |
| Qwen3.6 无MTP | 8001 | llama.cpp 对比组 |
| Gemma4 MTP | 8000 | vLLM + MTP |
常见问题
Q: llama.cpp提示不支持MTP?
A: 确保使用最新版本的llama.cpp(2025年5月后),并且模型是专门支持MTP的版本(如Qwen3.6-MTP-GGUF)。普通GGUF模型无法启用MTP。
Q: vLLM启动失败,提示CUDA版本不兼容?
A: vLLM nightly版本需要最新的CUDA驱动。建议使用Docker镜像 vllm/vllm-openai:nightly 来避免兼容性问题。
Q: MTP的n值设置多大合适?
A: 根据测试数据,n=3-5是较为理想的选择。n值过大会增加验证失败的风险,反而降低效率。
Q: 显存不足怎么办?
A: 可以降低 --gpu-memory-utilization 参数,或者使用更激进的量化(如Q4_K_M)。llama.cpp对显存需求更低。
MTP技术确实能带来显著的推理加速。从测试数据来看:
- 最高速度:Gemma 4 31B FP8 + vLLM + MTP n=5 达到 132.52 tok/s
- 加速效果:Qwen3.6 vLLM 启用MTP后提升 2.59倍
- n参数建议设置为3-5
- vLLM适合追求极致性能,llama.cpp适合追求兼容性