搞了块RTX PRO 4000显卡,配置了24G VRAM,做实验发挥的余地又拓展了一些了。Ollama毫无难度的跑了起来,所以还想试试其它更适合生产环境的推理框架。但问了下AI,当前(2026年5月)。一些主流推理框架对英伟达Blackwell架构的GPU(尤其是消费级的)优化仍在进行中,llama.cpp算是比较推荐的一种了(毕竟Ollama也是以它为基础),因此先拿它来折腾。
以下是在WSL2中的记录:
1、Linux基础依赖包:
bash
# 必装
sudo apt install build-essential cmake libcurl4-openssl-dev libssl-dev nvidia-cuda-toolkit
# 可选但强烈建议
sudo apt install unzip nodejs npm ccache2、升级NVCC:
bash
# 1. 下载 CUDA 12.8(支持Blackwell的最低版本。AI说13.2还是有Bug,因此我就用了此版本。)
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda_12.8.0_570.86.10_linux.run
# 2. 安装到独立目录(不装驱动,WSL2 使用 Windows 主机的驱动)
sudo sh cuda_12.8.0_570.86.10_linux.run --silent --toolkit --toolkitpath=/usr/local/cuda-12.8
# 3. 更新环境变量(确保 12.8 在最前,覆盖 12.0)
echo 'export PATH=/usr/local/cuda-12.8/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda-12.8/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
# 4. 验证版本(应显示 12.8)
which nvcc
nvcc --version3、(可选)在python环境中安装modelscope用来下载模型。这只是我的个人偏好:
bash
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple4、下载、编译:
bash
# 直接从github下载
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
rm -rf build
export CUDACXX=/usr/local/cuda-12.8/bin/nvcc
cmake -B build -DGGML_CUDA=ON -DLLAMA_BUILD_SERVER=ON -DLLAMA_BUILD_UI=OFF
cmake --build build --config Release -j$(nproc)
# 测试验证,应该能显示版本号
cd build/bin
./llama-cli --version以上是理想情况。但近期我这边的网络抽风的比较厉害,git clone一直失败,但手动从它家在github的网页下载zip包却有不小的概率会比较顺利,因此采用了从zip包安装的方式,需要多做几个可选步骤,否则编译警告会比较多,而且用--version验证时会没有版本号:
bash
# 手动下载master.zip包到home目录
cd
unzip llama.cpp-master.zip
cd llama.cpp-master
# 随意设置些本地git信息
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
git init && git add . && git commit -m "init"
# 后面都一样
rm -rf build
export CUDACXX=/usr/local/cuda-12.8/bin/nvcc
cmake -B build -DGGML_CUDA=ON -DLLAMA_BUILD_SERVER=ON -DLLAMA_BUILD_UI=OFF
cmake --build build --config Release -j$(nproc)
# 测试验证,应该能显示版本号
cd build/bin
./llama-cli --version新版llama.cpp会试图安装web-ui,尽管预编译时设置了不要UI,但实际编译过程中似乎还是会有相关步骤会去访问huggingface并毫无悬念的超时,但不影响最终使用。
5、下载模型。我选择了qwen3.6-27b_Q4_K_M量化。确认local_dir参数指定的目录存在。顺带说句,来都来了,24G显存都安排上了,多模态不试试吗:
bash
# 必选,基础大语言模型
modelscope download --model unsloth/Qwen3.6-27B-GGUF --include "*Q4_K_M*" --local_dir ~/llama.cpp-master/models/qwen3.6-27b
# 可选,mmproj模型,可用于识图等
modelscope download --model unsloth/Qwen3.6-27B-GGUF --include "mm*BF16*" --local_dir ~/llama.cpp-master/models/qwen3.6-27b6、启动服务(测试):
bash
./build/bin/llama-server \
-m ~/llama.cpp-master/models/qwen3.6-27b/Qwen3.6-27B-Q4_K_M.gguf \
--mmproj ~/llama.cpp-master/models/qwen3.6-27b/mmproj-BF16.gguf \
--host 0.0.0.0 \
--port 8080如果只是想测试对话,--mmproj整行去掉。
7、cherry studio测试:
添加,提供商名字随便写,提供商类型选 OpenAI,API密钥随便写,API地址写 http://你的IP:8080,然后按下"获取模型列表",选择Qwen3.6-27B-Q4_K_M.gguf即可。
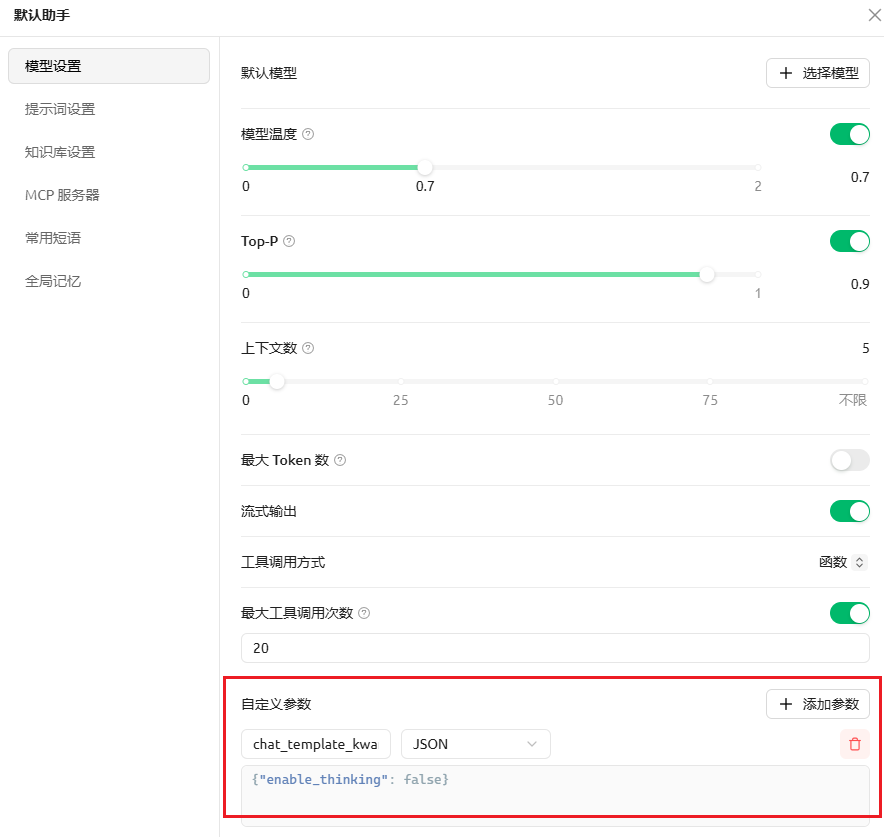
对话可以关闭思考。方法是编辑助手,自定义参数中添加参数 chat_template_kwargs: