本文以两条主线并行展开:一条是用户触发的 HTTPS 请求 ,一条是页面建立的 WSS 长连接。我们用一个具体场景串起全程------用户打开一个实时数据页面,HTTPS 拉取初始数据,同时 WSS 保持连接接收服务端推送。
我们会跟随这两个请求,经历前端、公网、CDN、网关、业务服务、消息队列、数据库,再回到用户手中。每一层,我们都会顺带讨论:这里可能出什么问题,怎么让它更稳定。
出生 ------ 前端发起请求
1.1 为什么前端是单线程 + Event Loop
在讲 Event Loop 之前,先说一个更根本的问题:前端为什么要设计成这样,而不是和后端一样用多线程?
前端的核心约束是 DOM
浏览器的核心任务是渲染 UI 和响应用户交互,这两件事天然要求串行------如果两个线程同时修改同一个 DOM 节点,结果不可预测。与其用锁来解决并发问题,不如直接设计成单线程,把复杂度消灭在源头。JavaScript 最初只是给网页加点小交互的脚本语言,单线程 + Event Loop 完全够用,而且没有死锁、没有竞态条件。
后端也走过类似的路
后端最早也是"每个请求一个线程"的模型,逻辑直观:一个线程等数据库的时候,CPU 去跑另一个线程。但这个模型有上限------线程不是免费的,并发量上来之后线程池很快被打满。所以后端也在往事件驱动靠拢:Node.js 把浏览器的 Event Loop 搬到服务端,Go 用极轻量的 goroutine,Java 有 Virtual Thread 和 Spring WebFlux。不同语言的具体解法在第 4 章展开。
两边殊途同归
有意思的是,前端因为 DOM 的约束走向了单线程,后端为了追求高并发也越来越向事件驱动靠拢------Go 用 goroutine 让少量线程撑起几十万并发,Java 引入 Virtual Thread 让线程在 IO 等待时自动挂起而不是干等,Node.js 直接把浏览器的 Event Loop 搬到服务端。出发点不同,最终的方向却越来越像。
理解了这个背景,再看 Event Loop 就不是在背一个机制,而是在理解一个在约束下做出的合理设计选择。
1.2 Event Loop:单线程怎么做到"并发"
浏览器的 JavaScript 是单线程的。但我们每天都在用它发请求、处理定时器、响应点击事件,看起来好像什么都能同时做。这背后依靠的是 Event Loop 机制。
JavaScript 引擎本身只有一个调用栈(Call Stack),同一时刻只能执行一件事。真正的"并发"能力,来自浏览器提供的 Web APIs(比如 fetch、setTimeout、DOM 事件监听)。这些 API 由浏览器在后台处理,完成后把回调放入任务队列,Event Loop 负责在调用栈空闲时把任务取出来执行。
任务队列分两种,优先级不同:
- 宏任务(Macro Task) :
setTimeout、setInterval、I/O 事件、UI 渲染。每次 Event Loop 取一个执行。 - 微任务(Micro Task) :
Promise.then、queueMicrotask、MutationObserver。每个宏任务执行完后,会把所有微任务队列清空,再执行下一个宏任务。
所以一个 fetch 请求的完整生命周期在前端是这样的:
scss
调用 fetch()
→ 浏览器在后台发起网络请求(Web API 处理,不阻塞 JS 线程)
→ 网络响应到达
→ 把 .then() 的回调放入微任务队列
→ 当前宏任务执行完毕
→ Event Loop 清空微任务队列,执行 .then() 回调这意味着:你写的 await fetch(...) 之后的代码,并不是"立刻"执行,而是在当前调用栈清空、微任务轮到它时才执行。这对理解竞态条件(race condition)和请求取消(AbortController)很重要。
主线程卡住
单线程最常见的问题。Event Loop 里某个任务执行时间过长,其他所有事情都得等------用户点击没反应、动画卡帧、网络响应回调进不来。常见触发场景:大量同步计算(解析大 JSON、复杂排序)、频繁的 DOM 读写触发 reflow、过深的 Promise 链把微任务队列憋住。
值得注意的是,fetch 本身不会卡主线程,卡的是 .then() 回调里的代码------很多人以为"用了异步就没问题了",其实异步只是把等待的时间让出去了,回调执行的代价还在。
解决方案:
- Web Worker :CPU 密集的计算丢给独立线程,不能访问 DOM,通过
postMessage和主线程通信。 - 任务切片 :大任务拆成小块,每块之间用
setTimeout(fn, 0)让出主线程,给浏览器机会渲染和响应用户。React Fiber 本质上就是在做这件事。 - requestAnimationFrame:DOM 操作放在这里,和浏览器渲染节奏对齐,避免无效的重复计算。
容灾视角:前端的稳定性往往被忽视,但它是第一道防线。
- 重复请求 :用户快速点击,可能发出多个相同请求。需要防抖(debounce)或在新请求发出时取消旧请求(
AbortController)。 - 请求超时 :
fetch默认没有超时。需要手动用AbortController+setTimeout实现。 - 失败重试:网络抖动导致的瞬时失败,可以做指数退避(exponential backoff)重试,但要注意幂等性。
1.3 HTTPS 请求的"出门前准备"
一个 HTTPS 请求在离开浏览器前,需要做几件事:
-
构造 URL :确定协议(
https://)、域名、路径、query 参数。 -
序列化请求体 :JSON、FormData、二进制(ArrayBuffer)等,对应不同的
Content-Type。 -
附加 Header:
Authorization:携带 JWT token 或其他凭证Content-Type:告诉服务端如何解析请求体Accept:告诉服务端客户端能接受什么格式- 自定义 header:比如
X-Request-ID,用于链路追踪(非常重要,后面会反复提到)
-
CORS 预检 :如果是跨域请求且带了自定义 header,浏览器会先发一个
OPTIONS请求(preflight),等服务端确认允许后,才发真正的请求。这是一个常见的性能陷阱和调试难点。服务端可以通过返回Access-Control-Max-Age来缓存预检结果,避免每次请求都多一次 RTT。
容灾视角:
- Token 过期处理 :请求发出前检查 token 是否即将过期,或者收到
401响应后自动刷新 token 再重试,而不是直接把错误抛给用户。这一层处理好,能避免大量不必要的用户登出。 - 幂等 Key(Idempotency Key) :对于写操作(下单、支付、提交表单),可以在 header 里带一个客户端生成的唯一请求 ID(
X-Idempotency-Key)。服务端用它做幂等判断------同一个 Key 的请求只处理一次,返回相同的结果。这样前端在网络抖动时重试,不会产生重复的副作用(比如重复扣款)。
1.4 WebSocket 连接的建立
new WebSocket('wss://example.com/ws') 这一行代码,背后做了什么?
WebSocket 并不是从零开始的新协议,它的握手是基于 HTTP 的。流程如下:
- 客户端发一个普通的 HTTP GET 请求,但带了特殊的 header:
ini
GET /ws HTTP/1.1Host: example.comUpgrade: websocketConnection: UpgradeSec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==Sec-WebSocket-Version: 13- 服务端如果支持,返回
101 Switching Protocols,连接协议从 HTTP 升级为 WebSocket。 - 升级完成后,这条 TCP 连接不再遵循 HTTP 的请求-响应模式,变成全双工的持久连接,双方都可以随时发消息。
WSS(WebSocket Secure)= WebSocket over TLS,和 HTTPS 的关系类似,握手前先建立 TLS 层。
容灾视角:
- 心跳保活(ping/pong) :网络中间节点(负载均衡、NAT)通常会把长时间没有数据的连接断掉。需要客户端定期发 ping,服务端回 pong,保持连接活跃。
- 断线重连:网络抖动时连接可能中断,客户端需要实现自动重连,通常用指数退避避免服务端被重连风暴打垮。
- 断线期间的消息补偿:重连成功后,断线期间服务端推送的消息怎么办?需要客户端在重连时携带最后收到的消息序号,服务端补发缺失的消息。
上路 ------ 穿越公网
请求离开浏览器后,要穿越整个公网才能到达服务器。这段旅程看不见摸不着,但却是延迟和故障的重灾区。
2.1 DNS 解析
浏览器拿到的是域名,比如 api.example.com,但网络传输需要的是 IP 地址。DNS 就是这本"电话簿"。
解析流程大致是:
浏览器缓存 → 操作系统缓存 → 本地 DNS 服务器 → 根域名服务器 → 顶级域服务器 → 权威域名服务器每一级都有缓存,缓存的有效期由 TTL(Time To Live) 控制。TTL 设置是个权衡:
- TTL 太长:改了 IP 后,老缓存还在,切换生效慢,故障切换也慢。
- TTL 太短:每次都要重新解析,增加延迟,DNS 服务器压力也大。
实际生产中,在做故障切换前,通常会提前把 TTL 调低(比如从 300s 降到 60s),等缓存失效后再改 IP,切换完成后再调回去。
容灾视角:DNS 本身也可能故障,或者被劫持。企业级方案通常用多个 DNS 服务商,配合健康检查做自动切换(DNS Failover)。
2.2 TCP 三次握手 + TLS 握手
DNS 解析拿到 IP 后,需要建立连接。HTTPS 和 WSS 都基于 TCP,而且都需要 TLS 加密层。
TCP 三次握手:
客户端 → SYN → 服务端
客户端 ← SYN + ACK ← 服务端
客户端 → ACK → 服务端
(连接建立,可以开始传数据)三次握手是建立可靠连接的代价,每次都要耗费 1.5 个 RTT(Round Trip Time,网络往返时延):客户端发 SYN、收到 SYN+ACK 是 1 个 RTT,再发 ACK 等服务端收到才算握手完成,额外多 0.5 个 RTT。标准 TCP 里,应用数据要等握手完全完成后才能发送,第三次 ACK 本身不携带数据。(有一个扩展特性 TCP Fast Open 允许在 SYN 里就携带数据,但需要双端都支持,并不是默认行为。)
为什么是三次握手,而不是两次?
两次握手(客户端发 SYN,服务端回 SYN+ACK)在理论上服务端就认为连接建立了,但这有两个问题:第一,服务端无法确认自己的 SYN+ACK 有没有送达;第二,历史上延迟的 SYN 包可能让服务端凭空建立一个无效连接。三次握手的第三个 ACK,本质上是让双方都确认"我发的你收到了,你发的我也收到了",是建立可靠连接的最小代价。
SYN Flood 攻击
正因为两次握手就能让服务端分配资源,攻击者可以利用这一点发动 SYN Flood 攻击 :伪造大量虚假源 IP,向服务端发送海量 SYN 包。服务端每收到一个 SYN,就回一个 SYN+ACK 并分配资源等待第三次握手,这些半完成的连接(half-open connection)会堆满服务端的 SYN 队列。由于源 IP 是假的,ACK 永远不会到来,队列满了之后,正常用户的连接请求就被丢弃了------服务端实际上已经瘫痪。
解决方案:SYN Cookie
Linux 内核的 SYN Cookie 机制是应对 SYN Flood 的主要手段。思路是:服务端收到 SYN 后,不立即分配资源,而是把连接的关键信息(源 IP、端口、时间戳等)哈希成一个 Cookie,编码进 SYN+ACK 的序列号里发回去。只有当客户端回了正确的 ACK(Cookie 验证通过),服务端才正式建立连接、分配资源。伪造 IP 的攻击者收不到 SYN+ACK,也就无法构造合法的 ACK,服务端的资源因此不会被耗尽。
TLS 握手(以 TLS 1.3 为例):
TLS 1.3 相比 1.2 做了大幅简化,握手只需要 1 个 RTT(1.2 需要 2 个)。流程大致是:
客户端 → ClientHello(支持的加密套件、随机数)→ 服务端
客户端 ← ServerHello + 证书 + 加密参数 ← 服务端(Nginx 把证书发给浏览器)
客户端 → 验证证书,发送 Finished → 服务端
(握手完成,开始加密传输)证书是什么,为什么需要它
光有加密还不够------中间人也可以和你建立 TLS 连接,用自己的密钥加密,你的数据对他是明文的。证书解决的是身份验证 问题:浏览器怎么确认它连的服务器真的是 api.example.com,而不是有人伪装的?
证书里包含:域名、服务端公钥、颁发机构(CA)、有效期、CA 的数字签名。浏览器用内置的 CA 根证书验证签名,签名对了说明这个证书是可信 CA 颁发的,域名和公钥是真实的。
这是一条信任链:操作系统 / 浏览器内置根 CA → 中间 CA → 你的域名证书。Let's Encrypt、DigiCert 这类公认的 CA 都在根证书列表里,它们签发的证书浏览器直接信任。
证书由服务端持有,TLS 在 Nginx 终止
证书不在业务代码里,而是由 Nginx 持有。每次新连接握手时,Nginx 把证书发给浏览器验证。验证通过后,TLS 连接建立,Nginx 负责加解密,解密后的明文 HTTP 请求才转发给业务服务。浏览器把 TLS 验证和加解密封装好,用户只看到地址栏的小锁;Nginx 把 TLS 终止,业务服务收到的是明文 HTTP。两端都感知不到证书的存在:
用户(只看到小锁)
↕ TLS(浏览器负责验证证书、加解密)
Nginx(持有证书,TLS 在这里终止)
↕ 明文 HTTP
业务服务(感知不到 TLS)证书过期会怎样
证书有有效期,过期后浏览器在握手阶段验证证书时会失败,直接中断连接,用户看到"您的连接不是私密连接 / NET::ERR_CERT_DATE_INVALID"。不只是页面,fetch 发出的 HTTPS 请求同样失败,业务完全不可用。这是硬故障,不是降级。
自动续期
Let's Encrypt 证书有效期只有 90 天,设计上就是逼你做自动续期。k8s 里通常用 cert-manager 实现:
vbnet
cert-manager 监控证书过期时间
→ 还有 30 天过期时,自动向 Let's Encrypt 申请新证书
→ Let's Encrypt 做域名所有权验证(HTTP-01 或 DNS-01)
→ 验证通过,签发新证书
→ cert-manager 把新证书写入 k8s Secret
→ Nginx reload,新连接用新证书
→ 旧连接握手已完成,继续跑直到自然结束nginx -s reload 是平滑重载,不中断现有连接------旧连接的 TLS 握手在换证书之前已经完成,不需要重新验证;新连接才会用新证书握手。整个续期过程对用户和业务完全透明。
唯一需要关注的是监控:自动续期失败了(DNS 验证超时、Let's Encrypt 限流)要有告警,提前发现,不能等证书真的过期才知道。
与 TCP 不同,TLS 1.3 明确设计了客户端可以在发送 Finished 的同时附带应用数据(Early Data),不需要等服务端确认握手完成,这是 TLS 1.3 相比 1.2 的重要优化之一。但服务端要收到 Finished 才算握手完成,所以 TLS 这一层计算下来仍然是 1.5 个 RTT。如果用户距离服务器 100ms,客户端在第 2.5 个 RTT(250ms)时就可以随 Finished 一起发出第一个业务数据包,服务端在第 3 个 RTT(300ms)时才收到。也就是说光建连,服务端收到第一个请求就已经过去了 300ms。这是 CDN 存在的重要原因之一。
2.3 HTTP 协议演进:HTTP/2 与 HTTP/3
HTTP/1.1 的问题:队头阻塞
HTTP/1.1 同一个 TCP 连接上,请求必须串行------上一个响应没回来,下一个请求发不出去。浏览器的解法是同时开多个 TCP 连接(通常 6 个),但每个连接都要经历握手,开销大,且并发上限有限。
HTTP/2:多路复用
HTTP/2 在同一个 TCP 连接上引入了**流(Stream)**的概念,多个请求可以并发,不需要等前一个响应回来。头部压缩(HPACK)也减少了重复 header 的传输开销。对于同一个域名下的大量请求,HTTP/2 比 HTTP/1.1 效率高得多。
但 HTTP/2 有一个残留问题:多路复用是在 TCP 层之上的,TCP 本身不知道有多个流。一旦 TCP 层丢包,所有流都要等重传,队头阻塞问题从应用层下沉到了传输层。
HTTP/3:换掉 TCP
HTTP/3 直接把底层从 TCP 换成 QUIC(基于 UDP)。QUIC 在用户态实现了可靠传输,每个流独立处理丢包重传,一个流丢包不影响其他流,彻底解决了队头阻塞。同时 QUIC 内置 TLS 1.3,建连只需要 1 个 RTT(首次),甚至支持 0-RTT(再次连接时)。
但 HTTP/3 目前普及有限,适合特定场景:
- 弱网 / 移动端:QUIC 有 Connection ID,网络切换(WiFi 换 4G)后连接可以继续,不需要重新握手
- 高丢包网络:QUIC 的流独立重传比 TCP 更高效
- CDN 大流量分发:Cloudflare、Google 已在自己的基础设施上大规模部署
对于普通企业内网服务,HTTP/2 已经够用,HTTP/3 部署成本高(防火墙对 UDP 的限制、运维工具链不成熟),收益不明显,不必急于跟进。
2.4 HTTP 分支:CDN
CDN(Content Delivery Network,内容分发网络)在全球各地部署了大量节点。用户的请求会被解析到离他最近的节点,而不是直接打到源站。
缓存命中(Cache Hit) :如果请求的资源在 CDN 节点上有缓存,直接返回,不需要访问源站。静态资源(JS、CSS、图片)通常走这条路。
回源(Cache Miss) :如果没有缓存,CDN 节点向源站发请求,拿到数据后返回给用户,同时缓存起来供后续使用。
CDN 对 HTTPS API 请求也有意义,即使不缓存响应,仅仅是"就近建连"这一点,就能把 TCP + TLS 的握手时延从跨洋的 150ms 降到同城的 10ms。
容灾视角:CDN 本身是多节点的,单个节点故障会自动切换。但 CDN 也可能整体出问题,或者缓存了错误数据(缓存污染)。要设计好缓存策略(Cache-Control header)和缓存刷新机制。
2.5 WSS 分支:长连接穿越公网的麻烦
WebSocket 在公网上遇到的问题比 HTTP 多,因为它是长连接。
代理和 CDN 的支持问题 :很多 HTTP 代理和早期 CDN 对 WebSocket 支持不好,遇到 Upgrade header 可能直接拒绝或截断。现在主流 CDN(Cloudflare、AWS CloudFront 等)都已经支持 WebSocket,但配置上需要显式开启。
Upgrade 握手经过 CDN:WSS 的 HTTP 升级握手会经过 CDN,升级成功后,CDN 节点和客户端之间维持一条 WebSocket 连接,CDN 节点和源站之间也维持一条,CDN 在中间做转发。这意味着 CDN 也需要维持大量长连接,对 CDN 的资源消耗更大。
NAT 超时:公网上的 NAT 设备(家用路由器、运营商 NAT)会对长时间没有数据的连接做超时清理,通常在 30s 到几分钟不等。这就是为什么 WebSocket 必须做心跳的原因。
容灾视角:
- 心跳间隔建议设在 20-25s,低于大多数 NAT 的超时时间。
- 网络路径上的故障可能导致连接"静默断开"(TCP 连接看起来还在,但数据发不出去),心跳超时是检测这种情况的主要手段。
入城 ------ TLB 与业务网关
请求离开公网后,进入公司内部网络,要经过两层才能到达业务服务:TLB 和业务网关。这两层职责不同,不能混为一谈。
3.1 TLB:入口负载均衡
TLB(内部负载均衡,实现上通常是 Nginx 集群)是流量进入内网的第一站。它的职责相对单一:把外部流量分发到业务网关集群的各个实例上。
TLB 不理解业务,不做鉴权,不看请求内容,只管把流量均匀打散。这一层的存在,是为了让业务网关可以水平扩展------网关加实例,TLB 自动感知并分流。
TLB 和服务发现的关系:TLB 知道业务网关有哪些实例,是通过查询服务发现得到的。每个业务网关实例启动时,把自己的 ip:port 注册到服务发现,TLB 从服务发现拿到实例列表,做负载均衡。
css
客户端
→ TLB(查服务发现,拿到业务网关实例列表,分发流量)
→ 业务网关实例 A / B / C容灾视角:
- TLB 本身要多实例部署,是整个链路的入口,挂了影响全部流量。
- TLB 依赖服务发现,服务发现要高可用,否则 TLB 拿不到最新的实例列表。
- TLB 要做健康检查,及时把不健康的业务网关实例从列表里摘掉。
3.2 业务网关:流量的"大脑"
流量经过 TLB 分发后,到达业务网关。业务网关才是真正理解请求内容、做业务决策的地方,核心职责包括:
- 鉴权:验证请求携带的 token 是否合法,不合法直接拒绝,不让脏请求进入业务服务。
- 限流:对同一用户、同一 IP 或全局的请求频率做限制,防止过载。
- 路由 :根据请求的路径、header、域名,决定转发到哪个下游业务服务。
/api/user/**转到用户服务,/api/order/**转到订单服务。 - 熔断(Circuit Breaker) :如果某个下游服务持续出错,网关会"熔断"对它的请求,直接返回错误,避免雪崩效应。
- 协议转换:比如对外是 REST,内部是 RPC,网关做转换。
限流算法
常见的两种算法:
- 漏桶(Leaky Bucket) :请求以固定速率流出,超出的排队或丢弃。流量输出是平滑的,但突发流量会被削平,正常的业务峰值也可能被误限。
- 令牌桶(Token Bucket) :桶里以固定速率补充令牌,有令牌才能处理请求。桶满之后多余的令牌丢弃。允许一定程度的突发------只要桶里有积累的令牌,短时间的流量峰值可以通过。API 限流通常用令牌桶,因为正常业务有突发流量,不应该被平滑掉。
限流策略:单实例 vs 中心化
限流算法之外,还有一个更关键的设计决策:限流计数器放在哪里。
- 单实例限流:每个实例各自维护计数器,不需要共享状态,实现简单,性能高。但阈值是针对单个实例的,负载均衡不均匀时,某个实例已经触发限流,其他实例还有余量,整体流量其实没到上限,用户却已经被拒绝了。
- 中心化限流:所有实例共享一个中心计数器(通常是 Redis),阈值针对整个服务,限流更精确。代价是每次请求都要访问 Redis,增加网络开销,Redis 本身也可能成为瓶颈或单点。
- 折中方案 :本地缓存一段时间的配额,批量同步到 Redis,减少每次请求都访问 Redis 的开销。但这不是真正解决了精确度问题------本地消耗的配额在同步前对其他实例不可见,极端情况下 N 个实例同时消耗本地配额,实际放过的请求可能远超阈值。本质上是用精确度换性能,批量同步间隔越短越精确,但 Redis 压力越大,越接近中心化限流。三种方案是一个连续的谱,没有完美解法,选哪个取决于业务对限流精确度的要求和对性能开销的容忍度。
用户鉴权
网关是鉴权的第一道关,在请求进入业务服务之前先验证调用方身份。常见方案,适用场景不同:
Session / Cookie
传统方案。用户登录后,服务端生成 session 存在 Redis 里,把 session ID 写入 cookie 返回给浏览器。之后每次请求浏览器自动带上 cookie,网关查 Redis 验证 session 是否有效。
优点:撤销简单,直接删 Redis 里的 session 就能让用户立即下线。缺点:有状态,水平扩展需要 session 共享,每次请求都要查 Redis。
JWT(JSON Web Token)
现代 Web / 移动端最常用。用户登录后,服务端用私钥签发一个 JWT,客户端存在本地。之后每次请求带上 JWT,网关用公钥验证签名,从 payload 读取用户身份,不需要查数据库。
JWT 结构是三段:header.payload.signature,payload 是 Base64 编码不是加密,任何人都能解码,不能放敏感信息。
安全实践:
- 短过期 + refresh token:access token 短过期(几分钟到几小时),泄露了损失窗口小;refresh token 长过期,用于换新的 access token
- httpOnly cookie:token 存在 httpOnly cookie 里,JS 读不到,防 XSS 攻击窃取 token
- token 撤销问题:JWT 无状态,签发出去很难撤销。用户封号或登出,token 在过期前还是有效的。解法是维护 Redis 黑名单存被撤销的 token,但这又引入了状态,和无状态初衷矛盾。没有完美解法,通常靠短过期时间缩小风险窗口
OAuth 2.0
解决"第三方应用代表用户访问资源"的问题。OAuth 2.0 是授权框架,定义获取 token 的流程;JWT 通常作为其 access token 的格式,两者是不同层面的东西。
四种授权模式,常用的两种:
- 授权码模式:最常用、最安全。"用微信登录"走的就是这个------用户在微信页面授权,微信把一次性授权码回调给你的服务端,服务端再用授权码 + client_secret 换 access_token。access_token 在服务端换,不经过浏览器,client_secret 不暴露给前端。
css
用户点击"用微信登录"
→ 跳转微信授权页(带 client_id、redirect_uri、scope)
→ 用户确认授权
→ 微信回调 redirect_uri,带上一次性 code
→ 服务端用 code + client_secret 换 access_token
→ 拿到 access_token,代表用户访问微信资源- 客户端凭证模式:没有用户参与,纯服务间调用。服务 A 用自己的 client_id + client_secret 向授权服务器换 access_token,再调用服务 B。适合后台服务间调用,不代表任何用户。
另外两种模式(隐式模式、密码模式)因安全问题已基本废弃,OAuth 2.1 已移除。
HMAC 签名 + 防重放
高安全要求的开放平台常用,比如支付宝、微信支付的接口。调用方和服务端共享一个密钥(secret),每次请求用 secret 对请求参数 + 时间戳 + 随机数(nonce)做 HMAC 签名,服务端验证签名。
防重放靠两个机制配合:
- 时间戳:服务端拒绝时间戳超过窗口期(比如 5 分钟)的请求,过期的截获请求无法重放
- nonce:每次请求带一个唯一随机数,服务端在窗口期内用 Redis 缓存用过的 nonce,相同 nonce 第二次来直接拒绝
时间戳限制重放窗口,nonce 保证窗口内也不能重放。
3.3 WSS 穿透这两层的问题
TLB 层:WSS 的 Upgrade 握手经过 TLB,升级成功后 TLB 需要在客户端和业务网关之间维持长连接做转发。TLB 要配置好对 WebSocket 的支持,否则可能截断 Upgrade 请求。
业务网关层 :WebSocket 连接建立后,后续所有消息都要走同一条连接,必须打到同一个业务网关实例,这叫 Session 亲和(Sticky Session) 。TLB 在分发 WSS 流量时,需要根据某个标识(比如 cookie 或 IP)做一致性哈希,保证同一个客户端的连接始终落到同一个网关实例。
连接数压力 :每个 WebSocket 连接在 TLB 和网关上各占一个文件描述符(fd),大量长连接场景下需要调整系统参数(ulimit -n)。
容灾视角:
- 业务网关多实例部署,TLB 感知实例健康状态,自动摘除故障实例。
- 网关实例故障时 WSS 连接断开,客户端重连要用指数退避,避免重连风暴把新实例打垮。
- 熔断阈值配置要谨慎,太敏感会导致误熔断,放大故障。
落地 ------ 业务服务
请求穿过业务网关后,到达真正的业务服务。在正式讨论服务发现和请求处理之前,先看一个更基础的问题:服务端是怎么同时处理多个请求的?
4.1 服务端并发模型:各语言的解法
后端最早是"每个请求一个线程"的模型,逻辑直观,但线程不是免费的------每个线程要占内存,并发量上来之后线程池很快被打满,线程切换的开销也越来越大。不同语言走向了不同的解法:
Python:多进程模型
Python 因为 GIL(全局解释器锁)的存在,多线程无法真正并行执行 CPU 密集任务。生产环境通常用 Gunicorn 拉起多个 worker 进程,每个进程独立处理一个请求,并发数 = worker 数量。
但多进程有一个容易踩的坑:模块级别的初始化代码会被每个 worker 各自执行一遍。比如连接池,每个 worker 各自建一套,实际连接数 = worker 数 × 池大小,很容易把数据库连接打满;又比如定时任务(AsyncIOScheduler),如果不加保护,N 个 worker 会各自启动一个,定时任务执行 N 次。
Gunicorn 提供了 hook 来区分初始化时机:
vbnet
on_starting → 运行在主进程,只执行一次,但主进程没有 event loop,无法运行异步代码
post_fork → 运行在每个 worker,worker 级别的初始化主进程没有 asyncio event loop,AsyncIOScheduler 放进去直接跑不起来。实际的解法是在 post_fork 里用文件锁竞争------多个 worker 同时启动,第一个拿到文件锁的 worker 初始化 Scheduler,其他 worker 检测到锁已被占用,跳过初始化。文件锁天然跨进程,不需要引入 Redis 等外部依赖。
Java + Spring Boot:线程池模型
Spring Boot 默认用 Tomcat 作为内嵌服务器,维护一个线程池(默认最大 200 个线程)。每个请求进来,从线程池借一个线程处理,处理完归还,这叫 Thread-per-Request 模型。
问题是 IO 等待期间线程被占着不释放------查数据库、调下游服务时,线程就在那干等,CPU 利用率低,线程池很快被打满。
Java 的演进方向:
- Spring WebFlux + Netty:响应式编程,少量线程处理大量请求,IO 等待时不阻塞线程。并发能力强,但编程模型复杂,调试困难。
- Virtual Thread(Java 21) :折中方案。写法和普通线程一样(同步代码),但底层由 JVM 调度而不是操作系统,可以开几十万个,IO 等待时自动挂起让出资源。兼顾了开发体验和并发能力。
Go:goroutine + GMP 模型
Go 的并发模型是目前最优雅的方案之一。每个请求起一个 goroutine,goroutine 是 Go runtime 管理的轻量级协程,初始栈只有 2KB(操作系统线程通常 1MB+),可以轻松开几十万个。
Go runtime 内部用少量操作系统线程(M)调度大量 goroutine(G),通过处理器(P)做中间层,这就是 GMP 模型。goroutine 遇到 IO 等待时自动挂起,runtime 把线程调度给其他 goroutine,CPU 利用率高,开发者写同步代码,runtime 在背后做异步调度。
┌─────────────┬──────────────┬────────────────┬──────────────┐
│ │ Python │ Java │ Go │
├─────────────┼──────────────┼────────────────┼──────────────┤
│ 并发单位 │ 进程 │ OS 线程 │ goroutine │
│ 内存开销 │ 高 │ 中 │ 极低(2KB) │
│ IO 等待 │ 进程阻塞 │ 线程阻塞 │ 自动挂起 │
│ 编程模型 │ 简单 │ 简单 │ 简单 │
└─────────────┴──────────────┴────────────────┴──────────────┘(Java Virtual Thread 出现后,Java 在内存开销和 IO 等待上已经接近 Go 的水平,但生态成熟度还在追赶中。)
4.2 PSM 与服务发现
公司内部每个服务有一个唯一标识 PSM(Product Service Module) ,类似 order.service.prod。服务实例启动时,把自己的 PSM + ip:port 注册到服务发现;下线时注销。
服务间调用时,调用方用 PSM 查服务发现,拿到目标服务的实例列表,再做负载均衡选一个实例发请求:
- HTTPS 调用 :走 TLB,由 TLB 查服务发现并转发。调用方只需要知道目标服务的域名,不需要关心对方有几个实例、IP 是什么。这里有一层映射关系:公司内部 DNS 把域名(比如
order.service.internal)解析到 TLB 的 IP,TLB 收到请求后根据 Host header 找到对应的 PSM,再查服务发现拿到实例列表,转发过去。域名到 PSM 的映射配置在 TLB 上,服务注册时配置一次,之后调用方只填域名,服务发现这层对调用方完全透明。 - RPC 调用(Thrift / gRPC):调用方本地的 SDK 直接查服务发现,拿到 ip:port 列表,在本地做负载均衡,直连目标实例,不经过 TLB。
css
服务 A 调用服务 B(HTTPS):
服务 A → TLB(查服务发现:B 的实例列表)→ 服务 B 的某个实例
服务 A 调用服务 C(RPC):
服务 A 的 SDK 查服务发现 → 拿到 C 的实例列表 → 直连服务 C 的某个实例容灾视角:服务发现本身是整个体系的基础设施,它挂了,TLB 和 RPC 调用都会出问题。服务发现要高可用部署,客户端 SDK 通常会在本地缓存一份实例列表,服务发现短暂不可用时用缓存兜底。
4.3 服务间鉴权
服务 A 调用服务 B,B 怎么确认请求真的来自 A,而不是内网里的其他进程?内网不是绝对安全的,一旦某台机器被入侵,攻击者可以在内网横向移动,伪造请求调用其他服务。
API Key
最简单的方案。服务 B 给服务 A 签发一个固定的 key,A 每次请求把 key 放在 header 里(X-API-Key),B 验证 key 是否合法。
优点是实现简单,不需要额外基础设施。缺点是 key 是静态的,泄露了就完全暴露,需要手动轮换;而且只验证"持有 key 的人",不验证"发请求的机器"。
mTLS(双向 TLS)
普通 TLS 是单向的------客户端验证服务端的证书。mTLS 是双向的------服务端也要验证客户端的证书。每个服务有自己的证书,由内部 CA 签发。
css
服务 A 调用服务 B
→ A 出示自己的证书(内部 CA 签发)
→ B 验证 A 的证书,确认是合法的内部服务
→ B 出示自己的证书
→ A 验证 B 的证书
→ 双向验证通过,建立连接优点:身份和机器绑定,私钥不需要在服务间传递,证书可以自动轮换(cert-manager),即使内网被渗透,没有合法证书的进程无法调用服务。缺点:需要维护内部 CA,基础设施复杂度高,调试比 API Key 难。
vbnet
┌──────────────┬───────────────────┬──────────────────────────┐
│ │ API Key │ mTLS │
├──────────────┼───────────────────┼──────────────────────────┤
│ 实现复杂度 │ 低 │ 高 │
│ 安全性 │ 中(key 泄露风险)│ 高(证书 + 私钥绑定机器)│
│ 运维成本 │ 低 │ 高(需要内部 CA) │
│ 适合场景 │ 快速落地 │ 安全要求高、零信任网络 │
└──────────────┴───────────────────┴──────────────────────────┘4.4 Pod 健康检查与服务生命周期
请求到了 Pod,Pod 还需要告诉 k8s"我准备好了",以及"我还活着"。这是保证流量不打到异常实例的关键机制。
标准 k8s Probe 方案
k8s 提供了三种 probe:
- startup probe:服务启动慢时使用,启动期间 liveness probe 暂停,避免服务还没起来就被误杀
- readiness probe:服务还没准备好接流量时(比如还在预热缓存),probe 失败,k8s 不把流量打过来
- liveness probe:服务陷入死锁或僵死状态时,probe 失败,k8s 自动重启容器
三者组合,覆盖了服务从启动到运行的完整生命周期。但有一个缺点:容器重启后,上一次的日志就丢了,kubectl logs --previous 只能看上一次,再往前的历史就没有了。
内部封装方案:宿主进程 + 端口探测
针对日志保留的问题,一种做法是在 k8s 之上做一层封装:Pod 内运行一个宿主进程,由宿主进程负责拉起真正的业务服务进程,同时监听业务端口是否可用:
k8s 拉起 Pod
→ 宿主进程启动
→ 宿主进程拉起业务服务进程
→ 宿主进程探测业务端口是否可用
→ 端口通了 → Pod 标记为 Ready,开始接流量
→ 端口一直不通 → 宿主进程重复拉起业务服务这样服务进程和 Pod 生命周期解耦------服务崩了,宿主进程还在,所有历史启动日志都保留在 Pod 里,每次启动的完整日志都可以查到。
两种方案的取舍:
| 标准 k8s Probe | 宿主进程方案 | |
|---|---|---|
| 日志保留 | 容器重启后丢失 | 完整保留在 Pod 里 |
| 服务重启 | 重启整个容器 | 只重启业务进程,Pod 不变 |
| 感知异常 | k8s 原生感知 | 需要额外监控宿主进程本身 |
| 实现复杂度 | 低,配置即可 | 高,需要维护宿主进程 |
需要注意的是,宿主进程方案下,如果业务服务一直拉起失败,Pod 看起来是活的,但服务实际上没在工作,k8s 感知不到这种状态,需要额外的监控和告警来覆盖。
4.5 HTTPS 请求的处理分叉
HTTPS 请求到达业务服务后,根据操作的性质,会走两条不同的路:
- 同步处理:操作简单、响应快,比如查询用户信息,直接查数据库返回结果。
- 异步处理:操作耗时、或者需要跨服务协作,比如下单,业务服务把任务投递到 MQ,立刻返回"已受理",实际处理在后台异步完成。
选择哪条路,取决于:用户能不能等?操作能不能重试?下游服务是否稳定?
4.6 WSS 连接管理:分布式状态问题
这是 WebSocket 在分布式系统中最核心的难题。
WebSocket 连接是有状态的------它本质上是一条 TCP 连接,TCP 连接是操作系统层面的资源,天然属于某一台机器。谁接受了这条连接,连接就在谁那里,跑不掉。在 k8s 里,连接绑定在某个 Pod 的进程上,Pod 重启,连接消失。
当我们需要给某个用户推送消息时,必须找到持有他连接的那个 Pod,才能把消息发出去。
单机方案(不可扩展) :连接 Map 存在进程内存里。只有一个实例时没问题,但无法水平扩展。
分布式方案 :用 Redis 存储 userId → podIP 的映射。
less
连接建立时:
客户端连上 Pod A
Pod A 向 Redis 写入:user:123 → pod-a-ip:port
推送消息时:
Consumer 收到消息,需要推给 user:123
查 Redis:user:123 在 pod-a-ip
Consumer 通过内部 RPC/HTTPS 调用 Pod A
Pod A 找到连接,推送消息
连接断开时:
Pod A 删除 Redis 中的记录
(或者设 TTL,避免异常断开时 key 残留)Pod 重启的问题:Pod 重启时,上面所有的 WebSocket 连接都会断开。客户端重连后,可能落到不同的 Pod,需要重新在 Redis 注册。这个过程要足够快,否则重连期间消息会丢失(需要结合消息补偿机制)。
容灾视角:
- Pod 要实现优雅退出(Graceful Shutdown) :收到 SIGTERM 后,先停止接收新连接,然后通知所有已连接的客户端主动重连(发一个特殊的 close frame),等客户端重连到其他 Pod 后再退出,把连接中断的影响降到最低。
- Redis 本身也需要高可用(Redis Sentinel 或 Redis Cluster)。
转手 ------ 消息队列
不是所有操作都适合同步处理。消息队列(MQ)在这条链路里承担了异步解耦的角色。
5.1 为什么需要 MQ
考虑下单场景:下单成功后,需要通知库存服务扣库存、通知积分服务加积分、发短信给用户、给用户推 WebSocket 消息。如果都是同步调用,任何一个下游服务慢或挂,都会拖累下单接口。用 MQ 的话,下单服务只需要把"下单成功"这个事件发到 MQ,其他服务各自消费,互不影响。
核心价值:削峰 (流量高峰时 MQ 做缓冲)、解耦 (生产者不需要知道谁在消费)、异步(不等下游处理完就返回)。
5.2 Kafka 基本模型
Kafka 是最常见的选择之一,几个核心概念:
- Topic :消息的分类,类比"频道"。比如
order.created是一个 Topic。 - Partition:每个 Topic 分成多个 Partition,Partition 是并行消费的单位。同一个 Partition 内消息有序,不同 Partition 间无序。
- Offset:每条消息在 Partition 内的位置编号。Consumer 通过提交 Offset 来记录"消费到哪了"。
- Consumer Group:同一个 Group 内的 Consumer 共同消费一个 Topic,每个 Partition 只会被 Group 内的一个 Consumer 消费,实现负载均衡。不同 Group 之间互相独立,同一条消息可以被多个 Group 各消费一次。
5.3 Kafka 的数据存储
Kafka 的数据存在磁盘 上,但它很快,原因是写入方式是顺序写------磁盘顺序写的速度接近内存随机写。
每个 Partition 是一个有序、只追加的日志文件(Log) ,消息只写到末尾,不修改、不删除。存储结构大致如下:
sql
Topic: order.created
└── Partition 0
├── 00000000000000000000.log ← 实际消息数据
├── 00000000000000000000.index ← offset 索引
└── 00000000000000000000.timeindex ← 时间索引
└── Partition 1
└── ...一个 Partition 会被切分成多个 segment 文件,文件名是该 segment 的起始 offset。Consumer 读消息时,先查 .index 文件找到大致位置,再在 .log 文件里定位读取。
消息不会永久保留,Kafka 按两种策略清理旧数据:
- 按时间:超过保留时长的 segment 直接删除(默认 7 天)
- 按大小:超过磁盘限制时,删除最老的 segment
5.4 宕机处理
Kafka 每个 Partition 有多个副本,分布在不同 Broker 上,其中一个是 Leader ,其余是 Follower。所有读写都走 Leader,Follower 只做同步备份。
Kafka 维护了一个 ISR(In-Sync Replicas) 列表,记录哪些 Follower 与 Leader 的数据是同步的。
- Follower 宕机:无影响,Leader 继续工作,Follower 恢复后重新同步追上来即可。
- Leader 宕机 :Controller 从 ISR 里选一个 Follower 升为新 Leader,通常在秒级完成。数据会不会丢,取决于
acks配置------acks=all加上min.insync.replicas=2能保证 Leader 宕机后 ISR 里的 Follower 有完整数据,不丢消息;acks=1则存在 Follower 还没同步完、Leader 就挂掉导致消息丢失的风险。 - Controller 宕机:Controller 本身也是一个 Broker,挂了之后集群会重新选一个 Broker 担任,短暂不可用后自动恢复。
5.5 消息可靠性
MQ 的可靠性涉及三个环节:
生产端 :Kafka 的 acks 配置决定了"发送成功"的定义:
acks=0:发出去就算成功,不管 Broker 有没有收到,可能丢消息。acks=1:Leader Partition 写入成功就算成功,Leader 挂了可能丢。acks=all:所有副本都写入才算成功,最安全,但延迟最高。
Broker 端:Kafka 每个 Partition 有多个副本(Replica),分布在不同的 Broker 上,主副本(Leader)负责读写,其他副本(Follower)同步数据,Leader 挂了自动选新 Leader。
消费端 :Consumer 消费完消息后才提交 Offset(而不是收到就提交),保证消息不丢。但这带来了重复消费的可能------如果消费成功但提交 Offset 前崩溃,重启后会重新消费这条消息。所以消费逻辑必须是幂等的(同一条消息处理多次,结果一样)。
容灾视角:Kafka 集群本身通过多副本保证高可用。业务层面,要设计好死信队列(Dead Letter Queue)------消费失败重试若干次后,消息进入死信队列,人工介入处理,而不是无限重试阻塞后续消息。
5.6 顺序消息:MQ 选型的一个关键差异
需要保证顺序消费的场景(比如同一个订单的状态变更消息必须按顺序处理),要注意不同 MQ 在 broker 故障时的行为差异。
Kafka 的 partition 数量是 Topic 级别的固定配置,broker 故障只是这个 partition 的 Leader 换了,numPartitions 不变,hash(key) % numPartitions 的路由结果不变,顺序性有保证。
RocketMQ 的路由逻辑是 hash(key) % queueNum,queueNum 是当前可用的 queue 数量,和存活的 broker 数量绑定。broker 挂了或运维操作导致 broker 数量变化时,queueNum 随之变化,同一个 key 的前后两条消息可能落到不同 queue,顺序无法保证。
在对顺序消费有强依赖的场景下,这是选择 MQ 时需要提前考虑的差异。
落库 ------ 数据库
业务逻辑处理完,最终需要把数据持久化。这一层是整条链路里状态最重的地方,也是最需要精心设计容灾的地方。本章以 Elasticsearch 为主展开,MySQL 作为对比参照。
6.1 在 k8s 上跑数据库:有状态服务的特殊性
k8s 原本是为无状态服务设计的------Pod 随时可以重建、迁移、扩缩容。但数据库是有状态的,它的数据必须持久化,Pod 重建后数据不能丢。
k8s 为此提供了专门的工作负载类型:StatefulSet。与 Deployment 的区别:
- Pod 有稳定的名字(
es-0、es-1),而不是随机后缀。 - 每个 Pod 绑定自己的 PVC(Persistent Volume Claim) ,Pod 重建后会重新挂载同一个 PVC,数据不丢。
- Pod 的启动和删除是有序的,对节点角色分配很重要。
PVC 和存储:PVC 是对底层存储的抽象,实际存储可以是云厂商的块存储(AWS EBS、GCP PD),也可以是本地磁盘或 Ceph 等分布式存储。
在 k8s 上跑 DB 的取舍:容器化数据库运维复杂度高,需要对 k8s 存储、网络有深入理解。很多公司选择用托管服务(AWS OpenSearch、Elastic Cloud),把运维责任转移出去,业务团队只关心使用层面。
StatefulSet 的局限与 Operator
STS 提供的是通用的有状态服务能力,但数据库这类有状态服务往往有自己特殊的运维逻辑,STS 处理不了,实际场景中经常需要自己写 Operator 来处理 CRD 的变更。
几个典型的 STS 不够用的场景:
- 主从切换:STS 只管 Pod 的启停顺序,不理解"Pod 0 是主、Pod 1 是从"这个业务语义。主库挂了,STS 只会重启 Pod,不会自动把从库提升为主库、更新其他从库的同步源、通知业务层切换连接。
- 扩缩容:ES 加节点不是简单地起一个新 Pod,还需要触发 Shard rebalance,把数据均匀分布到新节点。缩容时要先把节点上的 Shard 迁移走再下线 Pod,否则数据会丢。STS 的扩缩容不理解这些。
- 滚动升级:数据库升级需要按特定顺序(比如先从库后主库)、验证每一步健康状态后再继续。STS 的 RollingUpdate 策略太粗糙,控制不了这个粒度。
- 配置变更:某些配置改了需要重启,某些不需要,某些需要按顺序逐个生效,这些判断逻辑只有 Operator 能做。
Operator 的本质是:把运维工程师的操作经验编码进控制器,监听 CRD 的变更,自动执行对应的运维动作。比如 ECK(Elastic Cloud on Kubernetes)就是 Elastic 官方提供的 ES Operator,把 ES 的运维逻辑全部封装进去了。
6.2 Elasticsearch 的核心概念
ES 是天然分布式的,从设计上就考虑了水平扩展,理解它需要先搞清楚几个层次:
- Index :类比 MySQL 的"表",是一组文档的集合。比如
orders是一个 Index。 - Document:类比 MySQL 的"行",是一条 JSON 格式的数据。
- Shard(分片) :ES 把一个 Index 切分成多个 Shard,每个 Shard 是一个独立的 Lucene 实例,分布在不同节点上。这是 ES 水平扩展的基础------MySQL 要分库分表才能做到的事,ES 天然支持。
- Primary Shard:承担写入和读取,数量在 Index 创建时确定,之后不能修改。
- Replica Shard:Primary 的副本,承担读请求,提高读吞吐,同时做容灾备份。Replica 数量可以随时调整。
sql
Index: orders(3 个 Primary Shard,每个 1 个 Replica)
Node 1: Primary-0, Replica-1
Node 2: Primary-1, Replica-2
Node 3: Primary-2, Replica-0ES 保证 Primary 和它的 Replica 不会在同一个节点上,任意一个节点宕机,数据不会丢。
ES 的定位与局限 :ES 的设计目标是搜索和分析,不是事务型数据库。单个文档的操作是原子的,但不支持跨文档、跨 Index 的事务。如果业务需要"要么两条数据都写成功,要么都不写",ES 做不到,需要在业务层设计补偿机制,或者把需要事务的数据放到 MySQL。理解这个边界,是选型时最重要的一步。
6.3 写入:近实时(Near Real-Time)
这是 ES 和 MySQL 差异最大、最容易踩坑的地方。
MySQL 写入后,下一个查询立刻能读到。ES 不是这样的------写入后,数据要经过一个 refresh 过程才能被搜索到,默认间隔是 1 秒。但这里要注意:1 秒是 refresh 的触发间隔,不是完成时间的保证。当单个节点的数据量或分片数较多时,refresh 任务会排队,即便设置了 1s 的间隔,实际可见延迟也可能远超 1s。
原因是 ES 底层用的是 Lucene,Lucene 的索引结构(倒排索引)写入后需要先放在内存缓冲区,refresh 时才会生成新的 Segment 文件,搜索才能看到。
arduino
写入请求
→ 数据写入内存缓冲区(translog 同步记录,防崩溃丢数据)
→ 每隔 1s refresh:内存缓冲区 → 新的 Segment(此时可搜索)
→ 每隔 30min flush:Segment 落盘,清理 translogtranslog 的作用类似 MySQL 的 redo log:节点崩溃后,未落盘的数据可以从 translog 恢复,保证写入不丢。translog 的无序问题和 CDC 的挑战,在 6.7 节展开讨论。
实际影响 :如果你的业务是"写入后立刻查询",在 ES 里可能查不到刚写的数据。可以在写入后手动调用 refresh API,但频繁 refresh 会影响写入性能,需要权衡。
6.4 Mapping:schema 的坑
Mapping 是 ES 的字段类型定义,类比 MySQL 的建表语句。ES 有动态 Mapping------第一次写入文档时,ES 会自动推断字段类型。
这是一把双刃剑:
- 方便:不需要提前定义 schema,快速写入
- 危险:类型推断一旦确定就不能修改。比如第一条数据里
age字段是"25"(字符串),ES 推断为text类型,之后想按数值范围查询就不行了,只能重建 Index - 浪费:字符串字段默认会被推断为
text+keyword两种类型同时存在------text用于全文检索,keyword用于精确匹配和聚合。但大多数业务场景只需要其中一种,两个都建意味着索引体积翻倍,写入开销增加,大部分是没有必要的
生产环境的最佳实践是提前定义好 Mapping,不依赖动态推断,避免字段类型错误导致后期被迫 reindex。
6.5 连接池
ES 的客户端(如官方的 Java High Level REST Client)内部维护了连接池,管理和各个节点的 HTTP 连接。原理和 MySQL 连接池类似:
- 预先建立连接,避免每次请求都重新握手
- 连接复用,减少开销
- 连接数有上限,超出排队等待
ES 是 HTTP 协议,连接池管理的是 HTTP 长连接(Keep-Alive),而不是 MySQL 那种专有协议的 TCP 连接,但本质问题一样------池耗尽同样会导致服务雪崩,需要监控连接池使用率。
ES vs MySQL:节点异常的用户感知
ES 客户端和 MySQL 客户端一个关键的区别是:ES 客户端直连集群的每个节点,负载均衡在客户端内部做。当某个节点异常时,客户端不是立刻知道的------它可能还会把请求打到这个节点上,失败后再重试到其他节点。这个"打过去 → 失败 → 重试"的过程,对调用方来说就是一次偶发的错误或延迟抖动。对失败很敏感的场景,这种偶发失败很容易被业务层感知到。
MySQL 通常前面有 VIP(虚拟 IP,由 Keepalived 或云厂商负载均衡实现),客户端只连 VIP,不需要感知后面有几个节点。主库挂了之后,VIP 漂移到新主库,窗口期内请求同样会失败,但失败是集中的------一段连续的错误,窗口期过后恢复正常。
ES 的失败是分散的------集群任何一个节点抖动,都可能透传一次偶发失败,不集中在某个时间窗口,监控上更难发现,用户侧更容易有感知,排查起来也更难。
官方客户端有节点嗅探(node sniffing)和失败节点标记机制,但默认配置灵敏度不够,对失败敏感的场景需要手动调整:缩短失败节点的重试等待时间、调低节点被标记为不可用的失败阈值,同时结合业务层重试,但写操作重试要注意幂等性。
6.6 权限控制
鉴权(Authentication)解决"你是谁",权限控制(Authorization)解决"你能做什么"。数据库是权限控制最集中的地方,分控制面和数据面两个维度。
控制面:最小权限原则
每个业务服务用独立的数据库账号,账号只有自己需要的权限。订单服务的账号只能读写 orders 库,不能访问用户库;只有 SELECT + INSERT + UPDATE,没有 DROP TABLE 的权限。
好处是:某个服务被入侵,攻击者拿到的账号只能访问这个服务的数据,无法横向扩散到其他库。控制面的操作(建表、改 schema、备份)只有 DBA 和运维有权限,业务开发账号不应该有。
数据面:两层控制
第一层,数据库账号级别:数据库能控制某个账号能不能访问某张表、能不能写入,这层由数据库自己保证,不需要业务代码参与。
第二层,行级别 :某个用户只能看自己的数据,数据库做不到这个粒度,必须在业务层处理------查询时带上 WHERE user_id = ?,用当前登录用户的 ID 过滤。这也是越权漏洞(IDOR,Insecure Direct Object Reference)最常发生的地方:接口参数里带了订单 ID,但没有校验这个订单是不是当前用户的,攻击者改一下 ID 就能看别人的数据。
RBAC(Role-Based Access Control)
如果业务有复杂的权限体系(比如 SaaS 产品有管理员、普通用户、只读用户),通常在业务层实现 RBAC:用户 → 角色 → 权限,权限存在数据库里,每次请求查权限表判断是否有权限。
6.7 热点数据
某一条或某一批数据被大量请求同时访问,导致存储这条数据的节点压力远超其他节点,形成木桶效应。ES 因为查询天然分散到各个 Shard,热点问题不明显。热点问题更多出现在 Redis 和 MySQL 上。
热点分两种:读热点 和写热点,解法不同。
读热点:加缓存
加 Redis 缓存是最直接的方案,把热点数据挡在数据库前面。但缓存引入了一系列新问题:
缓存一致性
最常用的模式是 Cache Aside:更新数据库后删除缓存(而不是更新缓存),下次读时重建。删而不是更新,是为了避免并发写时缓存被覆盖成旧值。
删缓存失败怎么办?延迟双删(先删、写库、再延迟删一次)看起来是解法,但第二次删除同样可能失败,只是把问题概率降低了,没有真正解决。更可靠的做法是:
- 消息队列异步删除:删除操作发到 MQ,失败可以重试,有 ack 保证最终执行
- 订阅 binlog(Canal / Debezium):监听数据库变更事件,变更发生时自动删缓存,天然支持重试
缓存击穿(Cache Breakdown)
热点 Key 突然过期,大量请求同时 cache miss,全部打到数据库,数据库瞬间被压垮。解法:
- 互斥锁:缓存 miss 时只让一个请求去重建缓存,其他请求等待,代价是有等待延迟
- 永不过期:热点 Key 不设 TTL,由业务逻辑主动更新,代价是一致性更难保证
- 提前续期:后台线程检测到 Key 快过期时,提前异步刷新,不等到真正过期
缓存穿透(Cache Penetration)
请求的数据在缓存和数据库里都不存在,每次都穿透缓存直接打到数据库。恶意攻击者可以用大量不存在的 Key 把数据库打垮。解法:
- 缓存空值:查不到也缓存一个空结果,设短 TTL,代价是浪费缓存空间
- 布隆过滤器:请求进来先查布隆过滤器,Key 不存在直接拒绝,代价是有一定误判率
缓存雪崩(Cache Avalanche)
大量 Key 同时过期,或者 Redis 整体宕机,所有请求同时打到数据库。解法:
- TTL 加随机抖动:不同 Key 的过期时间加一个随机值,避免同时过期
- Redis 高可用:Sentinel 或 Cluster,避免单点故障
- 熔断降级:数据库压力过大时直接返回降级数据,不让请求继续堆积
Redis 本身的 Hot Key
即使加了缓存,如果缓存 Key 本身是热点,单个 Redis 节点还是会被打垮。这时需要在应用层再加一层本地缓存(JVM 内存 / 进程内 dict),热点数据不每次都走 Redis。但本地缓存的一致性更难保证,通常只适合允许短暂不一致的场景。
写热点:分段
写热点比读热点难处理,因为写操作通常需要保证原子性。常见场景:秒杀库存、点赞计数、余额扣减。
**分段(Sharding)**是主要解法:把一个热点 Key 拆成 N 份(stock_1、stock_2 ... stock_N),写请求随机打到其中一份,读的时候把 N 份加起来。
这里有两个没有通用答案的问题:
- 拆成多少份:拆少了还是热点,拆多了读聚合开销大,而且每份数量太小,容易出现某份提前耗尽但其他份还有余量的不均衡问题。通常需要根据预估 QPS 压测后决定。
- 支不支持动态扩缩:大促时需要更多分片,平时不需要那么多。动态扩缩的难点是扩缩时要重新分配各份数量,期间有并发写入,需要加锁或用版本号协调,实现复杂。很多系统选择提前预估好、固定分片数,接受一定资源浪费,换取实现简单。
如果业务确实需要支持动态扩缩,可以参考 Redis Cluster 的做法------它是目前工程上比较成熟的动态扩缩方案。
Redis Cluster 把所有 key 的空间分成 16384 个 slot ,每个 key 通过 CRC16(key) % 16384 计算出落在哪个 slot,每个节点负责一部分 slot:
css
Node A:slot 0 - 5460
Node B:slot 5461 - 10922
Node C:slot 10923 - 16383扩缩容本质上就是把 slot 从一个节点迁移到另一个节点,迁移是逐个 key 进行的原子操作:
- 扩容 :新节点加入后,从现有节点迁移部分 slot 过来。迁移期间 slot 处于 MIGRATING 状态,请求先打到老节点,如果 key 已迁走,老节点返回
ASK重定向,客户端临时打到新节点;迁移完成后返回MOVED,客户端永久更新路由表。ASK和MOVED的区分保证了迁移期间路由的正确性,又不会过早更新客户端缓存。 - 缩容:先把要下线节点的所有 slot 迁移到其他节点,再从集群摘除。
客户端路由表的更新有两种触发方式:收到 MOVED 时被动更新,以及后台定时任务主动向集群拉取 CLUSTER SLOTS 刷新------保证即使长时间没有请求,路由表也不会永远停在旧状态。
整个过程对业务几乎无感知。业务层手动分段如果需要支持动态扩缩,可以借鉴这套"slot + 迁移 + 重定向"的思路,但自己实现的成本很高,大多数情况下直接用 Redis Cluster 是更务实的选择。
6.8 CDC:从 ES 实时导出数据
CDC(Change Data Capture,变更数据捕获)是把数据库的变更实时同步到下游的常见需求。MySQL 有 binlog,天然支持可靠的 CDC。ES 没有等价的机制,这条路走起来要难得多。
基于磁盘 translog 文件的方案:走不通
直觉上,translog 记录了所有写入操作,订阅它就能拿到变更流。但问题是 translog 在主从之间是无序落地的------主从切换时,新主的 translog 起点和老主的终点对不上,中间可能有空洞,也可能有重复。实际尝试了多种方案后,结论是:无法在主从切换时保证数据不丢,这条路在当前 ES 的架构下走不通。
基于 checkpoint + 软删除的方案:可行,但有代价
要理解为什么这个方案能解决 translog 的问题,先要搞清楚 translog 走不通的根本原因:translog 是物理文件,每个分片各自写,没有全局顺序,主从同步也没有顺序保证。CDC 消费方拿不到一个可靠的全局位点,不知道"我消费到哪了",主从切换后更是无法对齐。
ES 7.10 在 translog 之上引入了三个机制,分别解决这三个问题:
_seq_no(sequence number) :每次写操作都分配一个全局递增的序列号,主从同步时 Follower 按_seq_no顺序应用操作。解决了 translog 无序的问题,CDC 消费方终于有了一个可靠的、有序的位点。- checkpoint :记录"所有副本都已同步到的最大
_seq_no"。低于 checkpoint 的操作是安全的,主从切换后新主的 checkpoint 是连续的,不会有空洞。CDC 消费方用 checkpoint 做断点续传,不会丢也不会重复。 - 软删除(soft deletes) :删除操作不是真正从 Lucene 里移除数据,而是写入一个删除标记,保留在 segment 里一段时间。没有软删除的话,数据被删了就真的消失了,CDC 消费方感知不到删除事件。软删除让删除变更也能被 CDC 捕获到。
三者加在一起:_seq_no 解决顺序问题,checkpoint 解决位点可靠性问题,软删除解决删除可见性问题,才构成一个完整的实时 CDC 方案。
但代价是软删除对频繁删除场景的性能影响非常大:被删除的数据不会立刻从 segment 里清除,要等 merge 时才真正回收。对于频繁删除的场景(比如日志滚动、TTL 数据清理),segment 里会堆积大量删除标记,merge 压力增大,磁盘占用显著增加,写入性能受影响。开启软删除前,需要评估业务的删除频率。
基于 Snapshot 的方案:可靠但不实时
Snapshot 是另一条路。ES 的 Snapshot 之所以快,是因为它直接拷贝 Lucene 的 segment 文件,而不是重新计算或导出数据。Lucene 的 segment 文件是不可变的(immutable)------segment 一旦生成就不会被修改,只会被新的 segment 合并替换。这个特性让增量快照变得极其简单:
第一次快照:拷贝所有 segment 文件到块存储
第二次快照:对比文件列表,只上传新增的 segment,已有的直接复用不需要做 diff、不需要记录变更日志,就是文件级别的增量拷贝,所以即使数据量很大,每次增量快照的实际传输量也可能很小。
但代价是实时性差------最快也要等一个 refresh 周期生成新 segment,再触发快照上传,通常是分钟级甚至小时级的延迟,做不到秒级 CDC。
基于轮询的方案:折中
社区里还有基于 scroll + search_after 轮询的方案,定期扫描新增或更新的文档。实现简单,但实时性受轮询间隔限制,数据量大时扫描开销也不小,不是真正的 CDC。
结论:ES 的 CDC 方案经历了从"没有可靠方案"到"有条件可用"的演进。7.10 之前,translog 无序、Snapshot 不实时、轮询不可靠,三条路都是折中。7.10 之后,checkpoint + 软删除提供了一条可靠的实时 CDC 路径,但软删除对频繁删除场景的性能影响是真实的代价,需要结合业务场景评估。如果业务对 CDC 的实时性和可靠性都有要求,且删除频率不高,checkpoint 方案是目前最可行的选择;否则,更稳妥的方式是在写入 ES 的同时把变更事件发到 Kafka,由 Kafka 承担可靠的变更流职责。
6.9 备份策略
ES 的备份通过 Snapshot 机制实现:
- Snapshot:把当前 Index 的数据快照存到远端存储(S3、HDFS、NFS),支持增量快照,只备份上次之后变化的数据。
- 恢复:从 Snapshot 恢复到指定时间点,但不像 MySQL 有 binlog 可以做细粒度的 Point-in-Time Recovery,ES 的恢复粒度是快照级别的。
- 备份验证:和 MySQL 一样,备份要定期做恢复演练,确认快照真的可用。
6.10 主副切换与容灾
节点宕机:ES 集群有一个 Master 节点负责管理集群状态(Shard 分配、节点加入/离开)。某个节点宕机后:
- Master 检测到节点失联(默认超时 30s)
- 把宕机节点上的 Primary Shard 对应的 Replica 提升为新 Primary
- 重新分配 Replica,保证副本数满足要求
整个过程自动完成,对比 MySQL 需要借助外部工具(MHA、Orchestrator)做主从切换,ES 的自愈能力是内置的。
Master 宕机 :ES 集群有多个 Master 候选节点,通过选举(类 Raft 协议)选出新 Master,通常在秒级完成。为避免脑裂(split-brain),候选节点数量建议设为奇数,且 minimum_master_nodes 要设为 (候选节点数 / 2) + 1。
多机房容灾:单集群的容灾只能应对节点级别的故障,机房级别的故障需要多机房策略。常见方案是在多个机房各自部署一套独立的 ES 集群,数据写入统一发到 Kafka,各机房的 Consumer 独立消费同一个 Topic,各自写入本机房的 ES 集群。这样每个机房的数据最终一致,任何一个机房不可用,其他机房可以独立提供服务。
对于云上多 Region 的场景,还可以把 Master 候选节点分布到不同 Region------比如三个 Master 候选节点分别在三个 Region。单个 Region 不可达时,另外两个 Region 的节点仍然能凑够多数派,重新选出 Master,集群继续工作,不会因为单 Region 故障导致整个集群不可用。
回家 ------ 响应与推送
处理完成后,结果要回到用户手中。HTTP 和 WSS 的回程方式完全不同。
7.1 HTTPS 回程
HTTPS 响应沿原路返回:业务服务 → 网关 → CDN/公网 → 浏览器。
响应到达浏览器后,进入 Event Loop 的微任务队列,await fetch() 之后的代码得以继续执行,.then() 回调被调用。
错误处理要区分两类:
- 网络错误 :请求没有到达服务端,或者响应没有回来,
fetch抛出异常(TypeError: Failed to fetch)。 - 业务错误 :请求到达了,服务端返回了 4xx / 5xx,
fetch本身不抛异常,需要检查response.ok或response.status。
这两类错误的处理策略不同:网络错误可以重试,业务错误(比如 400 参数错误)重试没有意义。
TraceID 的作用 :如果响应里带了 X-Trace-ID header,前端可以在错误日志里记录它,用户反馈问题时,提供这个 ID,后端可以用它在链路追踪系统里找到这次请求的完整调用链,快速定位问题。
7.2 WSS 推送:服务端主动找到你
WSS 的回程不是"响应",而是"推送"。消息是服务端主动发出的,时机由业务事件决定,不是由用户请求触发的。
推送触发链路:
以前面的下单场景为例,整条推送链路是:
css
订单服务写库成功
→ 发消息到 Kafka(topic: order.created, payload: {userId, orderId, ...})
→ 推送服务的 Consumer 消费到这条消息
→ 查 Redis:userId 对应的 WebSocket 连接在哪个 Pod
→ 内部调用目标 Pod
→ 目标 Pod 找到连接,通过 WebSocket 推送消息给客户端消息可靠性问题:推送出去的消息,客户端不一定收到了。可能的情况:
- 连接在推送瞬间断开了。
- 客户端收到了,但处理时崩溃了。
- 网络丢包(WebSocket 底层 TCP 会重传,但连接断开就没有重传了)。
解决方案通常是:
- 客户端 ACK:客户端收到消息后,发一个 ACK 给服务端。服务端如果超时没收到 ACK,重新推送。
- 消息序号 + 断线补偿:每条推送消息带一个递增的序号。客户端重连时,携带最后收到的序号,服务端把缺失的消息重新推送。
- 客户端主动拉取兜底:WebSocket 推送是尽力而为,关键数据(比如订单状态)要支持客户端主动 HTTPS 轮询或重连后拉取,不能只依赖 push。
保护自己
前面每一层都在讨论"怎么让请求顺利完成",但有时候更重要的是"怎么在系统压力过大时保护自己不崩"。
8.1 重试风暴
每一层加重试看起来是在提高可靠性,但所有层叠加在一起,重试会指数级放大流量:
前端重试 3 次
→ 网关重试 3 次
→ 业务服务重试 3 次
最坏情况:1 个用户请求 → 27 个实际请求打到下游某层处理变慢时,触发的死亡螺旋:
某层处理变慢
→ 上游超时,触发重试
→ 重试让下游压力更大
→ 下游更慢,更多超时
→ 更多重试 → 雪崩解法:
- 重试要有退避:指数退避 + 随机抖动,不要立刻重试,避免所有重试同时打过来
- 重试要有上限:最多重试 N 次,超过直接失败,不无限堆积
- 重试要幂等:写操作重试必须保证幂等,否则重试本身会造成数据问题
- 全链路协商重试:约定好哪层重试、重试几次,不是每层都无脑加重试
8.2 反压
重试风暴的根本原因是:消费者处理不过来,但上游不知道,还在不断发请求。反压的思路是:消费者处理不过来时,主动告诉上游放慢速度。
这条链路里反压出现的地方:
- 前端 → 服务端:服务端返回 429,前端收到后退避,不继续发请求
- 网关 → 业务服务:业务服务线程池满,网关触发熔断,停止往这个服务发请求
- 业务服务 → Kafka :Broker 写入跟不上,对 Producer 产生背压,
send()开始阻塞 - Kafka → Consumer:Consumer 消费太慢,lag 增大。Kafka 不会主动通知 Consumer 慢下来,需要业务层监控 lag,主动控制消费速率
- 业务服务 → ES:ES 有内置的多层熔断器------JVM 堆内存超阈值、单个请求预估内存超阈值、in-flight 请求内存超阈值,触发后直接返回 429 拒绝新请求。业务层收到 429 要识别是限流还是 ES 熔断,处理策略不一样
- 业务服务 → 数据库:连接池耗尽,新请求排队等待,这是数据库对上游的隐性反压
反压没有处理好,通常表现为雪崩------某层处理不过来,请求堆积,内存撑满,进程崩溃,上游继续打流量,整条链路依次崩掉。
有一个极简的反压实现值得一提:服务端收到请求后,先 sleep 一段时间再返回。对于串行客户端(发出请求等响应,再发下一个),这直接把客户端的请求速率压下来------吞吐量 = 1 / 响应时间,sleep 100ms,客户端每秒最多发 10 个请求。不需要改客户端,一行代码搞定。代价是线程被 sleep 占着,只对串行客户端有效,是个 hack,不是正经方案,但在特定场景下是最快的解法。
容灾视角:反压机制本身也可能失效,需要多层兜底。
- 429 没被正确处理:前端或调用方收到 429 后没有退避,反而立刻重试,流量不减反增。需要在客户端严格实现退避逻辑,并监控 429 的返回率------429 率持续上升是系统即将过载的信号。
- 熔断误触发:熔断阈值设得太敏感,正常的流量抖动就触发熔断,把健康的服务也断掉,放大了故障。需要结合错误率 + 持续时间双重条件才触发,而不是单次超时就断。
- 降级兜底 :当反压和熔断都没能保住系统时,最后一道防线是降级------返回缓存数据、返回默认值、或者直接告诉用户"服务繁忙请稍后再试",总好过整个系统崩掉什么都返回不了。降级策略要提前设计,不能等到真出问题了再临时想。
稳定的秘密 ------ 可观测性
容灾设计让系统在出问题时能自愈,但你还需要知道系统在哪里出了问题 ,以及出问题之前有什么征兆。这是可观测性(Observability)要解决的问题。
可观测性通常由三根支柱构成:
9.1 链路追踪(Tracing)
一个请求经过了前端、CDN、网关、多个业务服务、MQ、数据库,每一跳都可能引入延迟或错误。链路追踪把这一路串起来。
实现方式:在请求最开始生成一个唯一的 TraceID (通常在网关层),之后每一层在转发请求时都携带这个 ID(通过 HTTP header 传递,比如 X-Trace-ID 或标准的 traceparent)。每个服务记录自己处理这个请求花了多少时间、有没有错误,上报到追踪系统(Jaeger、Zipkin、SkyWalking)。
出问题时,用 TraceID 在追踪系统里搜索,可以看到这个请求在每一层的耗时和错误,精确定位瓶颈。
9.2 指标(Metrics)与告警
指标是系统健康状态的"生命体征"。关键指标包括:
- RED 指标:Rate(请求速率)、Error(错误率)、Duration(响应时间),适用于每个服务。
- USE 指标:Utilization(资源使用率)、Saturation(饱和度)、Errors,适用于基础设施(CPU、内存、磁盘、连接池)。
Prometheus + Grafana 是最常见的组合。告警配置在 Prometheus Alertmanager 上,比如"错误率超过 1% 持续 5 分钟,发告警"。
9.3 日志(Logging)
日志是最详细的调试信息,但也是量最大、最难管理的。
关键实践:
- 结构化日志:用 JSON 格式而不是纯文本,方便后续查询和分析。
- 日志里带 TraceID:这样可以从指标告警跳转到追踪,再从追踪跳转到具体的日志行。
- 日志分级:ERROR / WARN / INFO / DEBUG,生产环境通常只开 INFO 及以上,避免日志量过大。
- 集中管理:k8s 里 Pod 随时可能销毁,日志不能只存在 Pod 本地。用 Fluentd/Filebeat 采集,发到 Elasticsearch,用 Kibana 查询(ELK Stack)。
还有更多
10.1 异构容灾
本文涉及的容灾大多是同构容灾 ------同一种技术的多副本、多节点、多机房。还有一个方向没有展开:异构容灾------用不同技术栈互相备份,比如主存储是 ES,降级用 MySQL;主缓存是 Redis,降级用本地缓存。
异构容灾能应对同一技术栈的系统性故障(比如某个版本 bug 导致所有节点同时崩),但维护成本极高,数据同步、一致性、切换逻辑都要维护两套,通常只有对可用性要求极高的核心链路才值得做。这是一个值得单独展开的话题,留待后续。
10.2 goroutine 的轻量秘密
在第 4 章介绍 Go 并发模型时,我们说 goroutine 是轻量级协程,初始栈只有 2KB,可以轻松开几十万个。但这背后有很多值得深挖的问题:
- goroutine 是真正的线程吗?如果不是,它是怎么被调度的?
- goroutine 的栈从 2KB 开始,需要更多内存时怎么扩容?有上限吗?
- G、M、P 三者具体是什么关系?P 的数量是怎么决定的?
- goroutine 遇到 IO 等待时,是怎么和操作系统线程解绑的?
- 什么是 work stealing?P 的队列空了会怎样?
- goroutine 泄漏是什么?怎么发现和排查?
10.3 程序员能力地图
git 项目:github.com/TeamStuQ/sk...

结语
跟随这个请求走了一圈,从浏览器的 Event Loop 到 k8s 上的数据库 StatefulSet,我们经历了十几层不同的系统。每一层都有自己的故障模式,每一层也都有对应的加固手段。
"稳定"不是某一层做到极致就能实现的,而是整条链路上每一个环节都在认真对待可能的失败。从前端的重试退避,到 Kafka 的 acks=all,到数据库的主从切换,到推送的消息补偿------这些设计加在一起,才构成了一个请求"稳定的一生"。
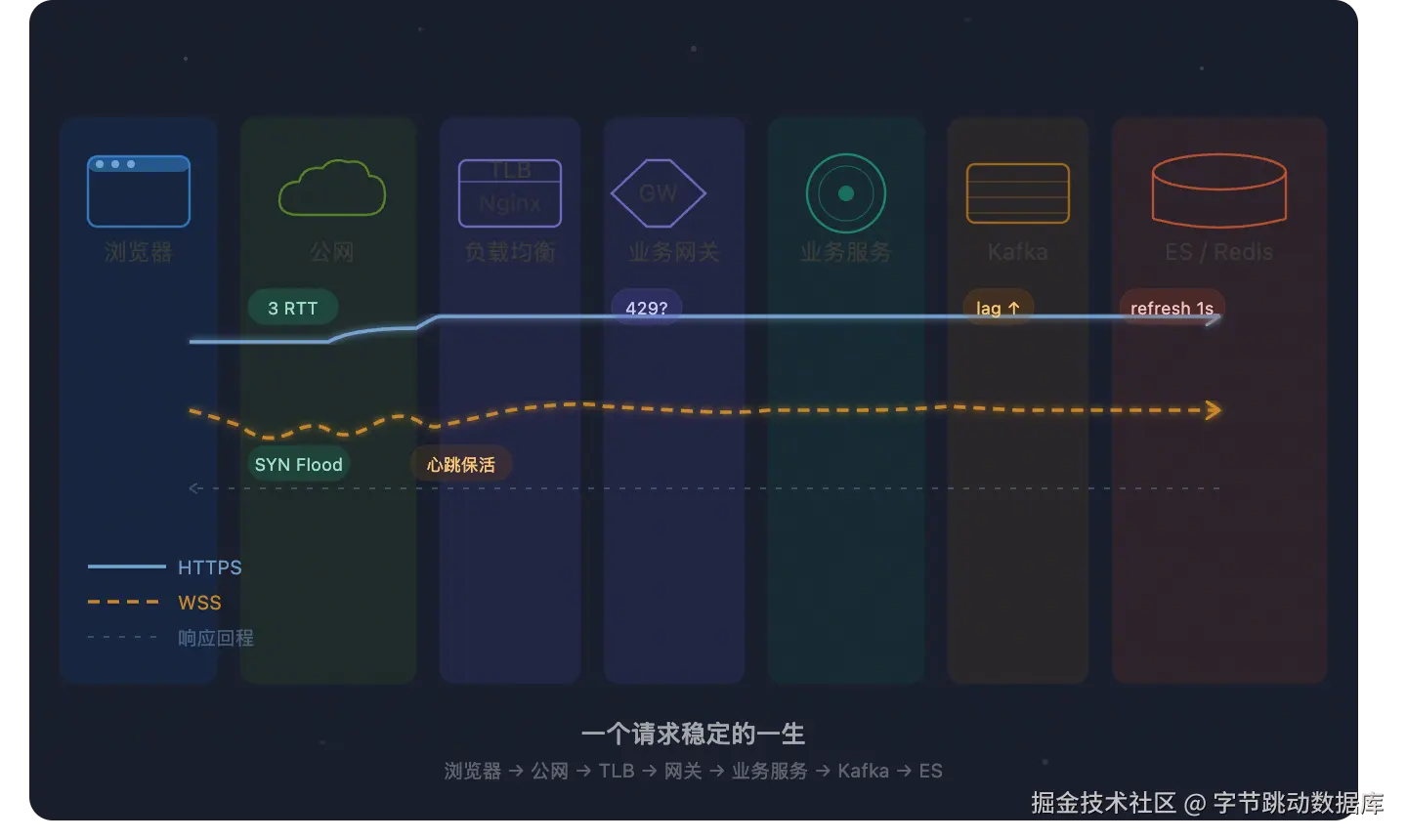
第一眼看到这张 AI 配图的时候,感觉也太黑了吧。可实际不黑吗 ? 其实一个请求很脆弱,无论哪层有点问题,它可能就"死"了。是千万个程序员给它铺了一条不算那么亮,但可以走通的路。