目录
[4-1 应用层](#4-1 应用层)
[序列化 和 反序列化](#序列化 和 反序列化)
[4-2 重新理解 read、write、recv、send 和 tcp 为什 么支持全双工](#4-2 重新理解 read、write、recv、send 和 tcp 为什 么支持全双工)
[1. 应用层:结构化数据](#1. 应用层:结构化数据)
[2. 序列化:将结构化数据"拍扁"成字符串](#2. 序列化:将结构化数据“拍扁”成字符串)
[3. 系统调用:从用户态进入内核态](#3. 系统调用:从用户态进入内核态)
[4. TCP层与内核发送缓冲区](#4. TCP层与内核发送缓冲区)
[5. 网络传输](#5. 网络传输)
[6. 接收端内核:接收缓冲区](#6. 接收端内核:接收缓冲区)
[7. 系统调用:从内核拷贝到用户态](#7. 系统调用:从内核拷贝到用户态)
[8. 反序列化:将字符串还原为结构化数据](#8. 反序列化:将字符串还原为结构化数据)
[9. 应用层使用](#9. 应用层使用)
[Encode (编码)代码详解](#Encode (编码)代码详解)
[Decode(解码) 代码详解(重点!面试考点!)](#Decode(解码) 代码详解(重点!面试考点!))
[Request 的序列化/反序列化](#Request 的序列化/反序列化)
[Response 的序列化/反序列化](#Response 的序列化/反序列化)
[jsoncpp 的固定套路](#jsoncpp 的固定套路)
[1. 使用 Json::Value 的 toStyledString 方法:](#1. 使用 Json::Value 的 toStyledString 方法:)
[2. 使用 Json::StreamWriter:](#2. 使用 Json::StreamWriter:)
[3. 使用 Json::FastWriter:](#3. 使用 Json::FastWriter:)
[4. 使用Json::StyledWriter](#4. 使用Json::StyledWriter)
[1. 使用 Json::Reader:](#1. 使用 Json::Reader:)
[2. 使用 Json::CharReader 的派生类(不推荐了,上面的足够了):](#2. 使用 Json::CharReader 的派生类(不推荐了,上面的足够了):)
[1. 构造函数](#1. 构造函数)
[2. 访问元素](#2. 访问元素)
[3. 类型检查](#3. 类型检查)
[4. 赋值和类型转换](#4. 赋值和类型转换)
[5. 数组和对象操作](#5. 数组和对象操作)
[考点3:read/recv 返回值处理](#考点3:read/recv 返回值处理)
[考点5:对比 HTTP](#考点5:对比 HTTP)
4-1 应用层
我们程序员写的一个个解决我们实际问题, 满足我们日常需求的网络程序, 都是在应用 层.
再谈 "协议"
**协议是一种 "约定".**socket api 的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接 收的. 如果我们要传输一些 "结构化的数据"。怎么办呢?
其实,协议就是双方约定好的结构化的数据
网络版计算器
例如, 我们需要实现一个服务器版的加法器. 我们需要客户端把要计算的两个加数发过 去, 然后由服务器进行计算, 最后再把结果返回给客户端.
约定方案一:
• 客户端发送一个形如"1+1"的字符串;
• 这个字符串中有两个操作数, 都是整形;
• 两个数字之间会有一个字符是运算符, 运算符只能是 + ;
• 数字和运算符之间没有空格;
• ...
约定方案二
• 定义结构体来表示我们需要交互的信息;
• 发送数据时将这个结构体按照一个规则转换成字符串, 接收到数据的时候再按 照相同的规则把字符串转化回结构体;
• 这个过程叫做 "序列化" 和 "反序列
序列化 和 反序列化
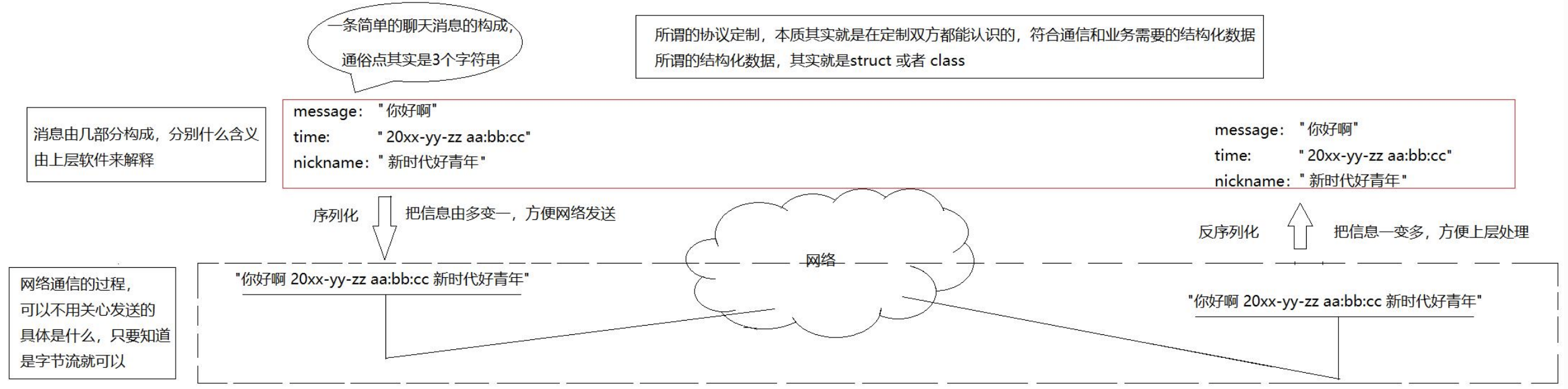
核心问题:数据怎么变成字节流,又怎么变回来?
网络通信的底层只认识0和1构成的字节流,它不关心你发送的是一条"你好啊"的消息,还是一个复杂的图片。所以,通信的过程本质上是:
发送方 :结构化数据 →(序列化)→ 字节流 → 发送
接收方:接收字节流 →(反序列化)→ 结构化数据
"网络通信的过程,可以不用关心发送的具体是什么,只要知道是字节流就可以",这正是因为序列化 和反序列化这两个关键步骤将上层业务逻辑与底层网络传输解耦了。
下面逐一解释:
1. 消息的构成:要发送什么?
原文:一条简单的聊天消息的构成:通信点其实是3个字符串。例如:message: "你好啊",time: "20xx-yy-zz...", nickname: "新时代好青年"
解释 :
在发送之前,数据是结构化的。对于一条聊天消息,它不是一个单纯的字符串,而是包含了多个字段的结构体(struct)或类(class)。
-
message:消息正文
-
time:发送时间
-
nickname:发送者昵称
-
......
为什么不能只发送"你好啊"这个字符串?
因为接收方需要知道是谁、在什么时候发来的。如果没有时间和昵称,程序就无法完整地显示这条消息。这就是协议定制的意义------通信双方约定好,每条消息都必须包含这三个字段。
2. 序列化:把"多变一"
原文:把信息由多变一,方便网络发送
解释 :
网络不能直接发送一个C++的struct对象或Java的class对象,因为不同语言、不同平台的内存布局不一样。序列化就是把这个结构化的、包含多个不同类型字段(字符串、数字、时间等)的数据,按照某种规则"拍扁"成一个连续的、由字节组成的序列。
比喻:
-
序列化前:你有一堆散乱的积木(昵称、时间、消息)。
-
序列化后:你把积木拆开,并按顺序放进一个长条形的盒子里(字节流)。这个盒子可以轻松地通过管道(网络)送到对方手里。
常见的序列化格式有:JSON、XML、Protobuf、MessagePack等。例如,上述消息用JSON序列化后可能是:
{"nickname":"新时代好青年","time":"2026-06-04 17:17:31","message":"你好啊"}
这整个就是一个字符串,可以方便地转换成字节流。
3. 网络通信:只管发字节流
原文:网络通信的过程,可以不用关心发送的具体是什么,只要知道是字节流就可以
解释 :
这是网络分层思想(如OSI七层模型、TCP/IP四层模型)的体现。
-
发送方 :上层的聊天软件把消息序列化成字节流后,交给下层的TCP/IP协议栈。TCP/IP协议栈只管把这个字节流可靠地发送到目标机器的指定端口 。它不需要知道这个字节流里是"你好啊"还是"再见",更不知道什么叫"昵称"。
-
接收方:TCP/IP协议栈收到字节流后,把它交给上层的聊天软件。聊天软件拿到字节流,但此时还无法直接使用。
好处 :这种分层设计使得网络底层可以通用、高效,而上层应用可以千变万化。
4. 反序列化:把"一变多"
原文:把信息一变多,方便上层处理
解释 :
这是序列化的逆过程。接收方的聊天软件从网络层拿到了一个连续的字节流,它需要按照双方事先约定好的协议 ,把这个字节流重新解析成内存中的结构化数据(比如重新变成一个拥有nickname、time、message属性的对象)。
比喻:
-
反序列化前:你收到了对方寄来的那个长条形盒子(字节流)。
-
反序列化后:你打开盒子,按照说明书,把里面的东西重新拼装成原来那堆积木的样子(昵称、时间、消息对象)。然后你的程序才能愉快地使用这些数据,比如显示在聊天窗口上。
总结:完整的流程
-
发送方 :你输入"你好啊"。程序创建了一个包含
message、time、nickname的结构体。 -
序列化:程序将这个结构体按协议(比如JSON)序列化成一个字节流。
-
发送:程序通过Socket将这个字节流发送到网络。
-
传输:网络(TCP/IP)将这个字节流原封不动地传送到接收方的机器。
-
接收:接收方程序从Socket中读取到这个字节流。
-
反序列化 :程序按照相同的协议(JSON)将这个字节流反序列化,重新得到
message、time、nickname字段。 -
处理 :接收方的界面代码取出
nickname和message,显示在屏幕上。
所以,"协议定制"的本质,就是通信双方共同决定:当我们交换字节流时,这个字节流应该遵循怎样的结构(比如先发昵称的长度,再发昵称的UTF-8编码,再发时间......)。而这个结构,在代码里通常就是用 struct 或 class 来描述的。
无论我们采用哪种方案, 只要保证, 一端发送时构造的数据, 在另一端能够正确的进行解析, 就是 ok 的.
这种约定, 就是 应用层协议
为了深刻理解协议,建议自定义实现一下协议的过程。
• 采用方案 2,要体现协议定制的细节
• 要引入序列化和反序列化,只不过我们直接采用现成的方案 -- jsoncpp 库
• 我们要对 socket 进行字节流的读取处理
4-2 重新理解 read、write、recv、send 和 tcp 为什 么支持全双工
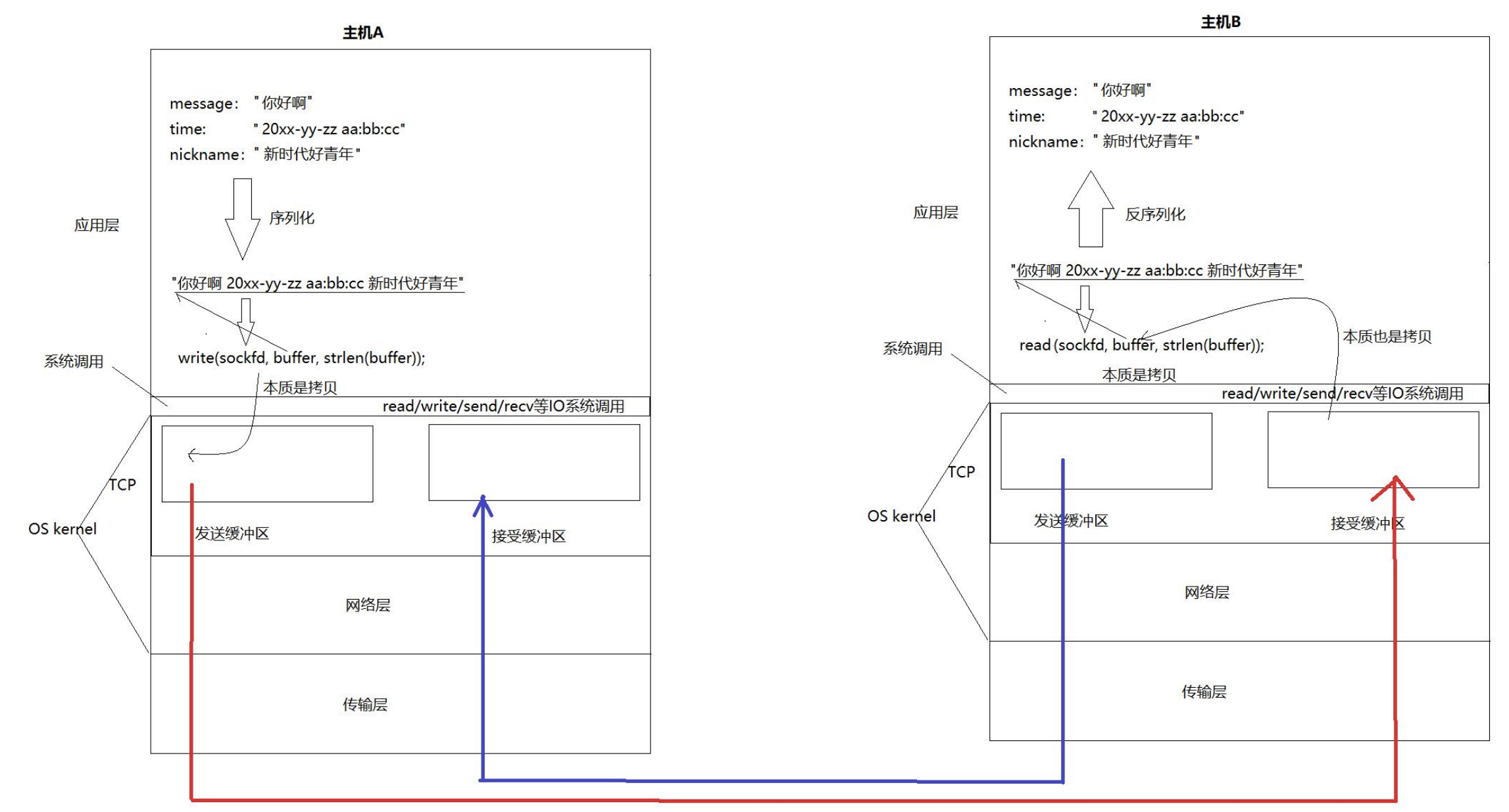
按照图中从左上到右下的顺序,分步骤进行详细解释。
一、发送端(主机A)的处理流程
1. 应用层:结构化数据
-
在主机A的聊天软件中,一条消息在内存里是一个结构化数据 (比如一个
struct或类的对象),包含三个字段:-
message:"你好啊" -
time:"20xx-yy-zz aa:bb:cc" -
nickname:"新时代好青年"
-
-
这些字段类型不同(都是字符串),内存布局复杂,不能直接发送到网络。
2. 序列化:将结构化数据"拍扁"成字符串
-
上层软件调用序列化函数 ,将三个独立的字符串拼接成一个连续的字符串(或其他字节序列)。
-
图中所示的简化序列化结果为:
"你好啊20xx-yy-zz aa:bb:cc新时代好青年"
注:实际序列化通常会加入分隔符、长度字段或使用更紧凑的二进制格式(如Protobuf),以避免解析歧义。但原理一致:由多变一。
-
现在,这一整个字符串就可以被当作普通的字节数组处理了。
3. 系统调用:从用户态进入内核态
-
程序调用
write(sockfd, buffer, strlen(buffer))。-
sockfd:已建立连接的套接字描述符。 -
buffer:指向序列化后的字符串(位于用户进程的内存空间)。 -
strlen(buffer):要发送的数据长度。
-
-
本质是拷贝 :
write系统调用会触发CPU从用户态 切换到内核态 ,并将用户缓冲区中的数据拷贝 到内核中的发送缓冲区。这一步是数据从应用层进入TCP协议栈的入口。
4. TCP层与内核发送缓冲区
-
内核为每个TCP套接字维护一个发送缓冲区。
-
拷贝完成后,
write系统调用返回(通常表示数据已成功放入发送缓冲区,并不代表对方已收到)。 -
TCP协议栈会根据滑动窗口、拥塞控制等机制,将发送缓冲区中的数据逐步打包成TCP报文段,交给网络层(IP)发送。
这里再贴一遍图片,方便照着看
二、网络传输与接收端(主机B)的内核处理
5. 网络传输
-
TCP报文段经过网络层、链路层,最终到达主机B的网卡。
-
主机B的内核TCP/IP协议栈收到数据后,会进行校验、重组,然后将有效负载放入该套接字对应的接收缓冲区中。
6. 接收端内核:接收缓冲区
-
每个TCP套接字在内核中也有一个接收缓冲区。
-
从网络上到达的字节流会暂存在这里,等待应用程序来读取。
三、接收端(主机B)的读取与反序列化
7. 系统调用:从内核拷贝到用户态
-
主机B上的应用程序调用
read(sockfd, buffer, sizeof(buffer))。 -
本质也是拷贝 :该调用将内核接收缓冲区中的数据拷贝 到用户程序提供的
buffer中(位于用户进程的内存空间)。 -
返回实际读取的字节数。应用程序拿到的是一个连续的字节数组,内容正是:
"你好啊20xx-yy-zz aa:bb:cc新时代好青年"
8. 反序列化:将字符串还原为结构化数据
-
应用程序调用反序列化函数,按照事先约定的格式解析这个字符串。
-
从其中重新提取出三个字段:
-
message="你好啊" -
time="20xx-yy-zz aa:bb:cc" -
nickname="新时代好青年"
-
-
由一变多,恢复成应用层方便处理的结构体/对象。
9. 应用层使用
- 主机B的聊天软件就可以拿着这些字段,在界面上显示:"新时代好青年 在 20xx-yy-zz aa:bb:cc 说:你好啊"。
四、关键点深入解释
关于"本质是拷贝"
-
"本质是拷贝",这是理解I/O性能的基础。
-
两次拷贝:
-
发送时:用户缓冲区 → 内核发送缓冲区。
-
接收时:内核接收缓冲区 → 用户缓冲区。
-
-
传统
read/write方式下,数据无法绕过这几次拷贝。零拷贝技术(如sendfile、splice)可以在特定场景下减少拷贝次数。
关于"序列化与协议定制"
-
我们看到的简单拼接方式在实际工程中并不安全,因为无法区分字段的边界(比如消息里本就不能包含时间格式字符串吗?)。
-
真正的协议定制会规定:
-
使用TLV(Type-Length-Value)格式,或固定分隔符(如
\0或特殊字符)。 -
更常见的是使用JSON 、Protobuf 、MessagePack等标准序列化方案。
-
-
但图示的简化模型足以说明序列化将结构化数据转成无结构的字节流 ,而反序列化将其还原。
关于系统调用与内核缓冲区的作用
-
write/read不是立即发送/接收数据到网络,而是与内核缓冲区交互。 -
优点:
-
异步解耦:应用程序可以快速返回,TCP负责可靠传输。
-
流量控制:内核缓冲区配合TCP滑动窗口,避免发送过快。
-
-
缺点:多一次拷贝,带来CPU开销。
五、全链条回顾
| 步骤 | 位置 | 动作 | 数据形态 |
|---|---|---|---|
| 1 | 主机A 应用层 | 构造结构化消息 | {nick, time, msg} 对象 |
| 2 | 主机A 应用层 | 序列化 | 连续字节串(如拼接字符串) |
| 3 | 主机A 用户态→内核态 | write 系统调用(拷贝) |
字节串进入内核发送缓冲区 |
| 4 | 主机A 内核 & 网络 | TCP发送、网络传输 | TCP报文段 |
| 5 | 主机B 内核 | 网卡接收,放入接收缓冲区 | 字节串暂存 |
| 6 | 主机B 内核→用户态 | read 系统调用(拷贝) |
字节串进入用户缓冲区 |
| 7 | 主机B 应用层 | 反序列化 | 还原为 {nick, time, msg} 对象 |
| 8 | 主机B 应用层 | 显示消息 | 界面展示 |
网络通信中下层只关心字节流,上层通过序列化/反序列化赋予字节流业务含义 。而write/read正是连接用户态与内核态、应用逻辑与网络传输的桥梁。
所以: 在任何一台主机上,TCP 连接既有发送缓冲区,又有接受缓冲区,所以,在内核 中,可以在发消息的同时,也可以收消息,即全双工。
-
每个 TCP 连接在内核中都独立维护一个发送缓冲区和一个接收缓冲区,两者互不阻塞。
-
因此,同一时刻可以同时进行读写操作 :向发送缓冲区写数据的同时,也能从接收缓冲区读数据------这就是 TCP 全双工的本质。
-
正因为全双工,一个
sockfd既可以用于read/recv,也可以用于write/send,两个方向独立工作。 -
数据何时真正发出、每次发多少、丢包后如何重传 等细节,全部由 TCP 协议栈内部决定,应用程序只需调用
write/send将数据交给内核发送缓冲区,调用read/recv从接收缓冲区取出数据。 -
这也是 TCP 被称为"传输控制协议" 的原因:它负责控制数据的可靠传输、流量控制、拥塞避免等,而上层只需要通过系统调用与缓冲区交互。
先看全局,再抠细节。整个系统就干一件事:
客户端 服务器
┌──────────────┐ ┌──────────────┐
│ 构造请求 │ │ 接收字节流 │
│ Request │ │ recv→buffer │
│ ↓ │ │ ↓ │
│ 序列化 │ │ 解码(拆包) │
│ Serialize │ ──── TCP字节流(带长度头) ────→ │ Decode │
│ ↓ │ │ ↓ │
│ 编码(加长度头) │ │ 反序列化 │
│ Encode │ │ Deserialize │
│ ↓ │ │ ↓ │
│ send发送 │ │ 业务计算 │
│ │ ←──── TCP字节流(带长度头) ──── │ Calculate │
│ recv接收 │ │ ↓ │
│ ↓ │ │ 序列化 │
│ 解码(拆包) │ │ Serialize │
│ Decode │ │ ↓ │
│ ↓ │ │ 编码(加长度头)│
│ 反序列化 │ │ Encode │
│ Deserialize │ │ ↓ │
│ ↓ │ │ send发送 │
│ 显示结果 │ │ │
└──────────────┘ └──────────────┘记忆口诀:收 → 存 → 拆包 → 反序列化 → 算 → 序列化 → 打包 → 发
模块1:协议编解码(解决TCP粘包问题)
为什么需要这一步?
TCP 是字节流 协议,没有"消息边界"的概念。你 send 了两次数据:
send("hello") → 可能对端一次recv就收到了"hello"
send("world") → 也可能对端一次recv收到"helloworld"这就是粘包 。反过来,你发了一个大包,对方可能 recv 了好几次才收完,这就是拆包。
我们的解决方案:长度前缀法
报文格式约定:
例如要发 {"x":1,"y":2,"op":"+"} 这个 JSON 字符串(21字节),实际发送的是:
21\r\n{"x":1,"y":2,"op":"+"}\r\n```
发送端 接收端
结构体 结构体
│ ↑
│ 序列化(Serialize) 反序列化(Deserialize)
↓ │
JSON字符串 JSON字符串
│ ↑
│ 编码(Encode) 解码(Decode)
↓ │
带长度头的报文 ──── TCP字节流传输 ────→ 带长度头的报文
(可能粘包/拆包)
```
Encode (编码)代码详解
cpp
// 输入: payload = "{\"x\":1,\"y\":2,\"op\":\"+\"}"
// 输出: "21\r\n{\"x\":1,\"y\":2,\"op\":\"+\"}\r\n"
std::string Encode(const std::string &payload)
{
// 第1步: 算出payload的长度,转成字符串
std::string len = std::to_string(payload.size());
// 第2步: 拼接: 长度 + \r\n + payload + \r\n
return len + SEP + payload + SEP;
}就这么简单,编码 = 在外面套一层"壳"。
Decode(解码) 代码详解(重点!面试考点!)
这是整个项目最难理解的部分。因为 buffer 里的数据可能是:
cpp
情况1: "21\r\n{\"x\":1}" → 只来了半个包,要等
情况2: "21\r\n{\"x\":1,\"y\":2}" → 还是半个包,继续等
情况3: "21\r\n{\"x\":1,\"y\":2,\"op\":\"+\"}\r\n" → 一个完整包,可以解了
情况4: "21\r\n{\"x\":1,...}\r\n21\r\n{\"x\":5,...}\r\n" → 两个包粘在一起!
bool Decode(std::string &buffer, std::string *payload)
{
// ========== 第1步: 找 \r\n,分离长度字段 ==========
// buffer = "21\r\n{\"x\":1,...}\r\n"
// ↑ 我们要找到这个位置
auto pos = buffer.find(SEP); // SEP = "\r\n"
if (pos == std::string::npos)
return false; // 连 \r\n 都没找到,数据根本没到齐
// ========== 第2步: 解析长度 ==========
// buffer.substr(0, pos) = "21"
int payload_len = std::stoi(buffer.substr(0, pos));
// ========== 第3步: 计算一个完整报文的总长度 ==========
// 完整报文 = "21" + "\r\n" + payload(21字节) + "\r\n"
// = 2 + 2 + 21 + 2 = 27字节
int total = pos + SEP.size() + payload_len + SEP.size();
if ((int)buffer.size() < total)
return false; // 数据没收够,return false,等下次recv再试
// ========== 第4步: 提取payload ==========
// 从 \r\n 后面开始,取 payload_len 个字节
*payload = buffer.substr(pos + SEP.size(), payload_len);
// ========== 第5步: 从buffer中删掉已处理的部分 ==========
// 这一步是处理"粘包"的关键!
// 如果buffer里有两个包,删掉第一个,第二个留给下次Decode
buffer.erase(0, total);
return true;
}为什么 Decode 要放在 while 循环里?
因为一次 recv 可能收到多个完整报文(粘包),要循环解直到解不出来为止:
cpp
std::string payload;
while (Decode(buffer, &payload)) // 每次解一个完整报文
{
// 处理这个报文...
// 处理完后继续循环,看buffer里还有没有下一个完整报文
}模块2:序列化与反序列化(JSON)
什么是序列化?
序列化: 结构体 → 字符串 (方便网络传输)
反序列化: 字符串 → 结构体 (方便程序使用)Request 的序列化/反序列化
cpp
class Request
{
public:
Request() : _x(0), _y(0), _op('+') {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
// ============ 序列化: 结构体 → JSON字符串 ============
// 输入: _x=10, _y=20, _op='+'
// 输出: "{\"x\":10,\"y\":20,\"op\":\"+\"}\n"
bool Serialize(std::string *out)
{
Json::Value root; // 创建一个JSON对象
root["x"] = _x; // 往里塞字段
root["y"] = _y;
root["op"] = std::string(1, _op); // char没有JSON类型,转string
Json::FastWriter writer; // 用FastWriter(不带格式化,紧凑)
*out = writer.write(root); // 输出为字符串
return true;
}
// ============ 反序列化: JSON字符串 → 结构体 ============
// 输入: "{\"x\":10,\"y\":20,\"op\":\"+\"}"
// 输出: _x=10, _y=20, _op='+'
bool Deserialize(const std::string &in)
{
Json::Value root;
Json::Reader reader;
if (!reader.parse(in, root)) // 解析失败返回false
return false;
_x = root["x"].asInt(); // 按字段名取值,转int
_y = root["y"].asInt();
_op = root["op"].asString()[0]; // string取第一个字符
return true;
}
private:
int _x; // 第一个操作数
int _y; // 第二个操作数
char _op; // 运算符: + - * / %
};Response 的序列化/反序列化
cpp
class Response
{
public:
Response() : _result(0), _code(0) {}
bool Serialize(std::string *out)
{
Json::Value root;
root["result"] = _result; // 计算结果
root["code"] = _code; // 状态码: 0成功, 1除零, 2非法运算符
Json::FastWriter writer;
*out = writer.write(root);
return true;
}
bool Deserialize(const std::string &in)
{
Json::Value root;
Json::Reader reader;
if (!reader.parse(in, root))
return false;
_result = root["result"].asInt();
_code = root["code"].asInt();
return true;
}
void SetResult(int r) { _result = r; }
void SetCode(int c) { _code = c; }
int Result() const { return _result; }
int Code() const { return _code; }
private:
int _result;
int _code;
};jsoncpp 的固定套路
cpp
// ===== 序列化(3步) =====
Json::Value root; // 1. 创建JSON对象
root["key"] = value; // 2. 填数据
*out = Json::FastWriter().write(root); // 3. 转字符串
// ===== 反序列化(3步) =====
Json::Value root;
Json::Reader reader;
reader.parse(in, root); // 1. 解析字符串
value = root["key"].asInt(); // 2. 按key取值模块3:业务逻辑(Calculate)
最简单的部分,就是 switch-case:
cpp
int Calculate(const Protocol::Request &req, Protocol::Response *resp)
{
int result = 0;
int code = 0; // 0=成功
switch (req.Op())
{
case '+': result = req.X() + req.Y(); break;
case '-': result = req.X() - req.Y(); break;
case '*': result = req.X() * req.Y(); break;
case '/':
if (req.Y() == 0) code = 1; // 除零错误
else result = req.X() / req.Y();
break;
case '%':
if (req.Y() == 0) code = 1;
else result = req.X() % req.Y();
break;
default:
code = 2; // 非法运算符
break;
}
resp->SetResult(result);
resp->SetCode(code);
return code;
}完整代码
protocol.hpp(协议层)
cpp
#pragma once
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
namespace Protocol
{
const std::string SEP = "\r\n";
// 编码: payload → "len\r\npayload\r\n"
std::string Encode(const std::string &payload)
{
std::string len = std::to_string(payload.size());
return len + SEP + payload + SEP;
}
// 解码: 从buffer中提取一个完整payload,成功返回true
bool Decode(std::string &buffer, std::string *payload)
{
auto pos = buffer.find(SEP);
if (pos == std::string::npos)
return false;
int payload_len = std::stoi(buffer.substr(0, pos));
int total = pos + SEP.size() + payload_len + SEP.size();
if ((int)buffer.size() < total)
return false;
*payload = buffer.substr(pos + SEP.size(), payload_len);
buffer.erase(0, total);
return true;
}
// 请求: x op y
class Request
{
public:
Request() : _x(0), _y(0), _op('+') {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
bool Serialize(std::string *out)
{
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["op"] = std::string(1, _op);
Json::FastWriter writer;
*out = writer.write(root);
return true;
}
bool Deserialize(const std::string &in)
{
Json::Value root;
Json::Reader reader;
if (!reader.parse(in, root))
return false;
_x = root["x"].asInt();
_y = root["y"].asInt();
_op = root["op"].asString()[0];
return true;
}
int X() const { return _x; }
int Y() const { return _y; }
char Op() const { return _op; }
private:
int _x;
int _y;
char _op;
};
// 响应: result + code
class Response
{
public:
Response() : _result(0), _code(0) {}
bool Serialize(std::string *out)
{
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::FastWriter writer;
*out = writer.write(root);
return true;
}
bool Deserialize(const std::string &in)
{
Json::Value root;
Json::Reader reader;
if (!reader.parse(in, root))
return false;
_result = root["result"].asInt();
_code = root["code"].asInt();
return true;
}
void SetResult(int r) { _result = r; }
void SetCode(int c) { _code = c; }
int Result() const { return _result; }
int Code() const { return _code; }
private:
int _result;
int _code;
};
}calculate.hpp(业务层)
cpp
#pragma once
#include "protocol.hpp"
// 返回: 0=成功, 1=除零, 2=非法运算符
int Calculate(const Protocol::Request &req, Protocol::Response *resp)
{
int result = 0;
int code = 0;
switch (req.Op())
{
case '+': result = req.X() + req.Y(); break;
case '-': result = req.X() - req.Y(); break;
case '*': result = req.X() * req.Y(); break;
case '/':
if (req.Y() == 0) code = 1;
else result = req.X() / req.Y();
break;
case '%':
if (req.Y() == 0) code = 1;
else result = req.X() % req.Y();
break;
default:
code = 2;
break;
}
resp->SetResult(result);
resp->SetCode(code);
return code;
}TcpServer.cc(服务器)
cpp
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <pthread.h>
#include "protocol.hpp"
#include "calculate.hpp"
static int CreateTcpSocket()
{
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) { perror("socket"); exit(1); }
int opt = 1;
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
return sockfd;
}
static void BindAndListen(int sockfd, uint16_t port)
{
struct sockaddr_in addr = {};
addr.sin_family = AF_INET;
addr.sin_addr.s_addr = INADDR_ANY;
addr.sin_port = htons(port);
if (bind(sockfd, (struct sockaddr *)&addr, sizeof(addr)) < 0)
{ perror("bind"); exit(1); }
if (listen(sockfd, 5) < 0)
{ perror("listen"); exit(1); }
}
// 核心函数: 处理单个客户端的完整生命周期
void *HandlerClient(void *arg)
{
int sockfd = *(int *)arg;
delete (int *)arg;
std::string buffer; // 接收缓冲区 --- 处理粘包的关键
while (true)
{
// 第1步: recv读TCP字节流,追加到buffer
char tmp[1024];
ssize_t n = recv(sockfd, tmp, sizeof(tmp) - 1, 0);
if (n <= 0) break;
tmp[n] = '\0';
buffer += tmp;
// 第2步: 循环解包 --- 一次recv可能收到多个完整报文
std::string payload;
while (Protocol::Decode(buffer, &payload))
{
// 第3步: 反序列化
Protocol::Request req;
if (!req.Deserialize(payload)) { continue; }
// 第4步: 业务处理
Protocol::Response resp;
Calculate(req, &resp);
// 第5步: 序列化 + 编码 + 发送
std::string resp_payload;
resp.Serialize(&resp_payload);
std::string packet = Protocol::Encode(resp_payload);
send(sockfd, packet.c_str(), packet.size(), 0);
std::cout << req.X() << " " << req.Op() << " " << req.Y()
<< " = " << resp.Result() << std::endl;
}
}
close(sockfd);
return nullptr;
}
int main(int argc, char *argv[])
{
if (argc != 2)
{ std::cerr << "Usage: " << argv[0] << " <port>" << std::endl; return 1; }
int listenfd = CreateTcpSocket();
BindAndListen(listenfd, atoi(argv[1]));
std::cout << "服务器启动, 端口 " << argv[1] << std::endl;
while (true)
{
struct sockaddr_in peer = {};
socklen_t len = sizeof(peer);
int *newfd = new int;
*newfd = accept(listenfd, (struct sockaddr *)&peer, &len);
if (*newfd < 0) { delete newfd; continue; }
pthread_t tid;
pthread_create(&tid, nullptr, HandlerClient, newfd);
pthread_detach(tid);
}
close(listenfd);
}TcpClient.cc(客户端)
cpp
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "protocol.hpp"
int main(int argc, char *argv[])
{
if (argc != 3)
{ std::cerr << "Usage: " << argv[0] << " <ip> <port>" << std::endl; return 1; }
// 建立TCP连接
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in server = {};
server.sin_family = AF_INET;
server.sin_addr.s_addr = inet_addr(argv[1]);
server.sin_port = htons(atoi(argv[2]));
if (connect(sockfd, (struct sockaddr *)&server, sizeof(server)) < 0)
{ perror("connect"); return 1; }
// 模拟5个计算请求
struct { int x, y; char op; } tests[] = {
{10, 20, '+'}, {100, 30, '-'}, {6, 7, '*'},
{100, 0, '/'}, {10, 3, '%'},
};
std::string buffer;
for (auto &t : tests)
{
// 发送: 构造 → 序列化 → 编码 → send
Protocol::Request req(t.x, t.y, t.op);
std::string payload;
req.Serialize(&payload);
std::string packet = Protocol::Encode(payload);
send(sockfd, packet.c_str(), packet.size(), 0);
// 接收: recv → 解码 → 反序列化 → 显示
while (true)
{
char tmp[1024];
ssize_t n = recv(sockfd, tmp, sizeof(tmp) - 1, 0);
if (n <= 0) { close(sockfd); return 0; }
tmp[n] = '\0';
buffer += tmp;
std::string resp_payload;
if (Protocol::Decode(buffer, &resp_payload))
{
Protocol::Response resp;
resp.Deserialize(resp_payload);
std::cout << t.x << " " << t.op << " " << t.y
<< " = " << resp.Result()
<< " (code=" << resp.Code() << ")" << std::endl;
break;
}
}
}
close(sockfd);
}Makefile
cpp
CC = g++
CFLAGS = -Wall -std=c++11
all: server client
server: TcpServer.cc protocol.hpp calculate.hpp
$(CC) $(CFLAGS) -o $@ TcpServer.cc -ljsoncpp -lpthread
client: TcpClient.cc protocol.hpp
$(CC) $(CFLAGS) -o $@ TcpClient.cc -ljsoncpp
clean:
rm -f server client编译与运行
bash
# 安装依赖
sudo apt-get install libjsoncpp-dev
# 编译
make
# 终端1: 启动服务器
./server 8080
# 终端2: 启动客户端
./client 127.0.0.1 8080Jsoncpp
Jsoncpp 是一个用于处理 JSON 数据的 C++ 库 。它提供了将 JSON 数据序列化为字 符串以及从字符串反序列化为 C++ 数据结构的功能。Jsoncpp 是开源的,广泛用于各 种需要处理 JSON 数据的 C++ 项目中。
特性
-
简单易用:Jsoncpp 提供了直观的 API,使得处理 JSON 数据变得简单。
-
高性能:Jsoncpp 的性能经过优化,能够高效地处理大量 JSON 数据。
-
全面支持:支持 JSON 标准中的所有数据类型,包括对象、数组、字符串、数 字、布尔值和 null。
-
错误处理:在解析 JSON 数据时,Jsoncpp 提供了详细的错误信息和位置,方便 开发者调试。
当使用 Jsoncpp 库进行 JSON 的序列化和反序列化时,确实存在不同的做法和工具类 可供选择。以下是对 Jsoncpp 中序列化和反序列化操作的详细介绍
安装
cpp
ubuntu:sudo apt-get install libjsoncpp-dev
Centos: sudo yum install jsoncpp-devel序列化
序列化指的是将数据结构或对象转换为一种格式,以便在网络上传输或存储到文件 中。Jsoncpp 提供了多种方式进行序列化:
1. 使用 Json::Value 的 toStyledString 方法:
○ 优点:将 Json::Value 对象直接转换为格式化的 JSON 字符串。
○ 示例:
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
std::string s = root.toStyledString();
std::cout << s << std::endl;
return 0;
}$ ./test.exe
{
"name" : "joe",
"sex" : "男"
}
2. 使用 Json::StreamWriter:
○ 优点:提供了更多的定制选项,如缩进、换行符等。
○ 示例
cpp
#include <iostream>
#include <string>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
Json::StreamWriterBuilder wbuilder; // StreamWriter的工厂
std::unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter());
std::stringstream ss;
writer->write(root, &ss);
std::cout << ss.str() << std::endl;
return 0;
}$ ./test.exe
{
"name" : "joe",
"sex" : "男"
}
3. 使用 Json::FastWriter:
○ 优点:比 StyledWriter 更快,因为它不添加额外的空格和换行符。
○ 示例:
cpp
#include <iostream>
#include <string>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
Json::FastWriter writer;
std::string s = writer.write(root);
std::cout << s << std::endl;
return 0;
}$ ./test.exe
{"name":"joe","sex":"男"}
4. 使用Json::StyledWriter
cpp
#include <iostream>
#include <string>
#include <sstream>
#include <memory>
#include <jsoncpp/json/json.h>
int main()
{
Json::Value root;
root["name"] = "joe";
root["sex"] = "男";
// Json::FastWriter writer;
Json::StyledWriter writer;
std::string s = writer.write(root);
std::cout << s << std::endl;
return 0;
}$ ./test.exe
{
"name" : "joe",
"sex" : "男"
}
反序列化
反序列化指的是将序列化后的数据重新转换为原来的数据结构或对象。Jsoncpp 提供 了以下方法进行反序列化:
1. 使用 Json::Reader:
○ 优点:提供详细的错误信息和位置,方便调试。
○ 示例
cpp
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main() {
// JSON 字符串
std::string json_string = "{\"name\":\"张三\", \"age\":30, \"city\":\"北京\"}";
// 解析 JSON 字符串
Json::Reader reader;
Json::Value root;
// 从字符串中读取 JSON 数据
bool parsingSuccessful = reader.parse(json_string, root);
if (!parsingSuccessful) {
// 解析失败,输出错误信息
std::cout << "Failed to parse JSON: " << reader.getFormattedErrorMessages() << std::endl;
return 1;
}
// 访问 JSON 数据
std::string name = root["name"].asString();
int age = root["age"].asInt();
std::string city = root["city"].asString();
// 输出结果
std::cout << "Name: " << name << std::endl;
std::cout << "Age: " << age << std::endl;
std::cout << "City: " << city << std::endl;
return 0;
}$ ./test.exe
Name: 张三
Age: 30
City: 北京
2. 使用 Json::CharReader 的派生类(不推荐了,上面的足够了):
○ 在某些情况下,你可能需要更精细地控制解析过程,可以直接使用 Json::CharReader 的派生类。
○ 但通常情况下,使用 Json::parseFromStream 或 Json::Reader 的 parse 方法就足够了。
总结
• toStyledString、StreamWriter 和 FastWriter 提供了不同的序列化选项, 你可以根据具体需求选择使用。
• Json::Reader 和 parseFromStream 函数是 Jsoncpp 中主要的反序列化工具, 它们提供了强大的错误处理机制。
• 在进行序列化和反序列化时,请确保处理所有可能的错误情况,并验证输入和输 出的有效性。
Json::Value
Json::Value 是 Jsoncpp 库中的一个重要类,用于表示和操作 JSON 数据结构。以 下是一些常用的 Json::Value 操作列表:
1. 构造函数
• Json::Value():默认构造函数,创建一个空的 Json::Value 对象。
• Json::Value(ValueType type, bool allocated = false):根据给定的 ValueType(如 nullValue, intValue, stringValue 等)创建一个 Json::Value 对 象。
2. 访问元素
• Json::Value& operator\[\](const char* key):通过键(字符串)访问对象 中的元素。如果键不存在,则创建一个新的元素。
• Json::Value& operator\[\](const std::string& key):同上,但使用 std::string 类型的键。
• Json::Value& operator\[\](ArrayIndex index):通过索引访问数组中的元 素。如果索引超出范围,则创建一个新的元素。
• Json::Value& at(const char* key):通过键访问对象中的元素,如果键不 存在则抛出异常。
• Json::Value& at(const std::string& key):同上,但使用 std::string 类型的键。
3. 类型检查
• bool isNull():检查值是否为 null。
• bool isBool():检查值是否为布尔类型。
• bool isInt():检查值是否为整数类型。
• bool isInt64():检查值是否为 64 位整数类型。
• bool isUInt():检查值是否为无符号整数类型。
• bool isUInt64():检查值是否为 64 位无符号整数类型。
• bool isIntegral():检查值是否为整数或可转换为整数的浮点数。
• bool isDouble():检查值是否为双精度浮点数。
• bool isNumeric():检查值是否为数字(整数或浮点数)。
• bool isString():检查值是否为字符串。
• bool isArray():检查值是否为数组。
• bool isObject():检查值是否为对象(即键值对的集合)。
4. 赋值和类型转换
• Json::Value& operator=(bool value):将布尔值赋给 Json::Value 对象。
• Json::Value& operator=(int value):将整数赋给 Json::Value 对象。
• Json::Value& operator=(unsigned int value):将无符号整数赋给 Json::Value 对象。
• Json::Value& operator=(Int64 value):将 64 位整数赋给 Json::Value 对象。
• Json::Value& operator=(UInt64 value):将 64 位无符号整数赋给 Json::Value 对象。
• Json::Value& operator=(double value):将双精度浮点数赋给 Json::Value 对象。
• Json::Value& operator=(const char* value):将 C 字符串赋给 Json::Value 对象。
• Json::Value& operator=(const std::string& value):将 std::string 赋给 Json::Value 对象。
• bool asBool():将值转换为布尔类型(如果可能)。
• int asInt():将值转换为整数类型(如果可能)。
• Int64 asInt64():将值转换为 64 位整数类型(如果可能)。
• unsigned int asUInt():将值转换为无符号整数类型(如果可能)。
• UInt64 asUInt64():将值转换为 64 位无符号整数类型(如果可能)。
• double asDouble():将值转换为双精度浮点数类型(如果可能)。
• std::string asString():将值转换为字符串类型(如果可能)。
5. 数组和对象操作
• size_t size():返回数组或对象中的元素数量。
• bool empty():检查数组或对象是否为空。
• void resize(ArrayIndex newSize):调整数组的大小。
• void clear():删除数组或对象中的所有元素。
• void append(const Json::Value& value):在数组末尾添加一个新元素。
• Json::Value& operator\[\](const char* key, const Json::Value& defaultValue = Json::nullValue):在对象中插入或访问一个元素,如果键不存 在则使用默认值。
• Json::Value& operator\[\](const std::string& key, const Json::Value& defaultValue = Json::nullValue):同上,但使用 std::string 类型的
考点
考点1:TCP粘包问题
Q:什么是TCP粘包?怎么解决?
A: TCP是面向字节流的协议,没有消息边界。发送端多次
send的数据,在接收端可能被合并成一次recv收到(粘包),也可能一次send的数据被拆成多次recv(拆包/半包)。常见解决方案有三种:
长度前缀法(本文采用):在每个报文前面加上长度字段,接收端先读长度,再按长度读取payload
分隔符法 :用特殊字符(如
\r\n)标记报文边界,如 HTTP 协议固定长度法:每个报文固定长度,不足补零(浪费带宽,不实用)
Q:我们的协议是怎么用长度前缀解决粘包的?
A: 报文格式是
"len\r\npayload\r\n"。接收端先把数据追加到 buffer,然后 Decode 函数:
在 buffer 中找第一个
\r\n,提取出长度字段计算完整报文总长度 = 长度字段字节数 +
\r\n+ payload长度 +\r\n如果 buffer 大小不够,说明数据没收完,返回 false
够了就提取 payload,并从 buffer 中 erase 掉已处理部分
erase 后 buffer 里可能还有下一个完整报文,所以外面套一层 while 循环
考点2:序列化与反序列化
Q:什么是序列化和反序列化?为什么要用?
A:
序列化:把内存中的结构体/对象 → 转成字节流/字符串,方便网络传输或持久化存储
反序列化:把字节流/字符串 → 转回结构体/对象,方便程序处理
因为网络传输只能发字节流,不能直接发结构体。结构体里有指针、内存对齐等问题,直接
memcpy发过去在不同机器上可能解析错误。
Q:除了 JSON,你还知道哪些序列化方案?
A:
方案 特点 JSON 可读性强,体积大,解析慢,跨语言 XML 更啰嗦,现在很少用 Protobuf Google出品,二进制格式,体积小,速度快,需要.proto文件 自定义文本 如 "x + y"字符串,简单但不灵活自定义二进制 最紧凑,但不跨平台(字节序问题)
考点3:read/recv 返回值处理
Q:recv 返回值有几种情况?分别怎么处理?
A:
返回值 含义 处理 > 0成功读到 n 个字节 追加到 buffer,尝试 Decode = 0对端关闭连接(FIN) 本端也关闭,退出循环 < 0出错(被信号中断等) 检查 errno,决定重试还是退出
Q:为什么 recv 之后不能直接处理数据,而是要追加到 buffer?
A: 因为一次
recv收到的数据可能不是一个完整报文。可能只收到了半个包(比如只有len\r\n,payload 还没到),也可能收到了一个半包(一个完整包 + 第二个包的前半部分)。所以必须用 buffer 累积,然后用 Decode 循环提取完整报文。
考点4:协议设计
Q:如果让你重新设计这个协议,你会怎么改进?
A:(考察开放思维,以下任选几点)
加版本号 :
"v1 len\r\npayload\r\n",方便后续协议升级兼容加校验和:CRC32 或 MD5,防止数据在传输中被篡改或损坏
加消息类型:区分请求、响应、心跳包等
加超时机制 :长时间没收完一个报文就断开连接,防止恶意客户端发一个
len=999999999就不发了限制最大长度:防止客户端说 len=2GB 把服务器内存撑爆
Q:\r\n 作为分隔符有什么潜在问题?
A: 如果 payload 本身包含
\r\n(比如用户输入了换行),Decode 会提前截断。解决方案:
对 payload 做转义(把
\r\n替换成\\r\\n)或者用长度前缀来读 payload(我们的 Decode 已经是按长度读的,所以这个问题其实不存在------我们找的是第一个
\r\n,它一定在长度字段后面)
考点5:对比 HTTP
Q:HTTP 协议是怎么解决粘包的?和我们的方案有什么区别?
A: HTTP 也是用长度前缀 + 分隔符的方式:
请求头 用
\r\n分隔每个字段,用\r\n\r\n标记头部结束请求体 用
Content-Length: xxx字段标明长度,按长度读取本质上和我们的方案一样:
"长度信息\r\npayload"。HTTP 只是把长度信息换成了更可读的键值对格式。
考点6:手写代码题
Q:手写一个 Encode 函数,把字符串编码为 "len\r\nstr\r\n" 格式。
cpp
std::string Encode(const std::string &payload)
{
return std::to_string(payload.size()) + "\r\n" + payload + "\r\n";
}Q:手写一个 Decode 函数,从缓冲区中解出一个完整报文。
cpp
bool Decode(std::string &buffer, std::string *payload)
{
auto pos = buffer.find("\r\n");
if (pos == std::string::npos) return false;
int len = std::stoi(buffer.substr(0, pos));
int total = pos + 2 + len + 2; // len字段 + \r\n + payload + \r\n
if ((int)buffer.size() < total) return false;
*payload = buffer.substr(pos + 2, len);
buffer.erase(0, total);
return true;
}Q:手写一个函数,把 Request{x, y, op} 序列化为 JSON 字符串。
cpp
std::string Serialize(int x, int y, char op)
{
Json::Value root;
root["x"] = x;
root["y"] = y;
root["op"] = std::string(1, op);
return Json::FastWriter().write(root);
}