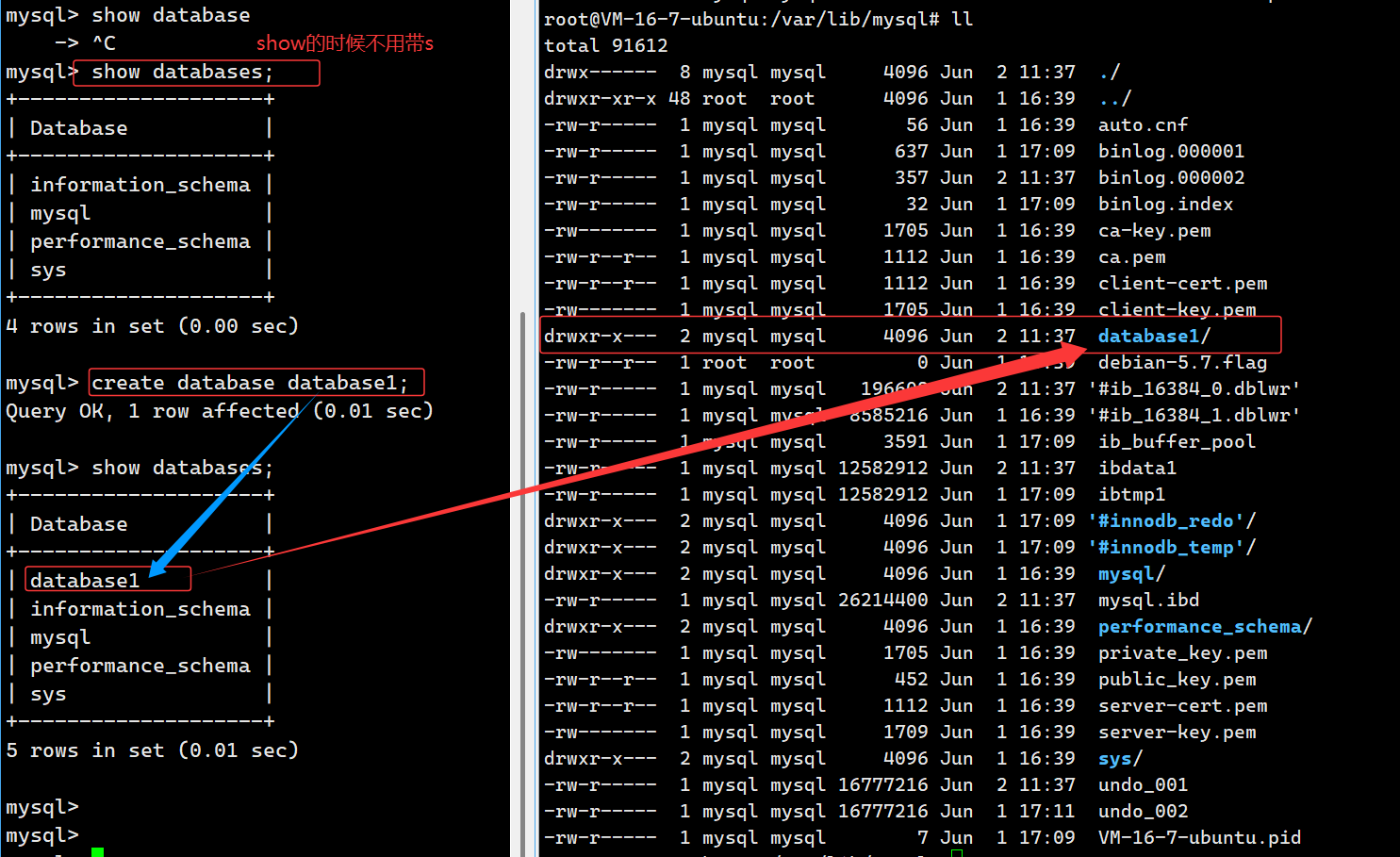
如果我们在 /var/lib/mysql 里新建一个文件夹,show databases; 查询时 MySQL 也会把这个文件夹识别成数据库;但我们一般不会这么做,所有库只用 create/drop database 语句管理,避免 MySQL 数据和磁盘文件不一致。
总结:
一个是MySQL层面的,一个是Linux文件系统层面的
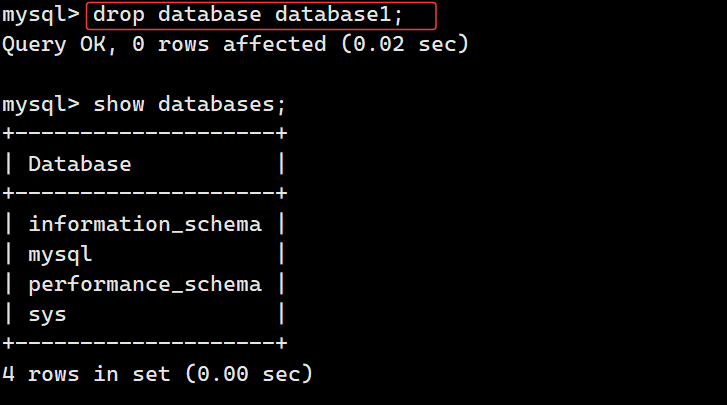
MySQL 层面就是数据库的系统元数据登记,执行 create database db_name; 时,除了 Linux 在 /var/lib/mysql 生成对应文件夹 (文件系统层面),MySQL 还会在自身内置的系统数据表中记录这条库信息,包含库名、默认字符集、创建时间等配置,这就是 MySQL 逻辑层面。我们执行 show databases; 能查到这个库,本质就是 MySQL 读取自己保存的这份登记信息;执行 use db_name; 切换数据库,也是 MySQL 依靠这条记录定位到对应的逻辑空间。反过来执行 drop database db_name;,除了删掉磁盘文件夹,MySQL 同步删除系统表里这条库的登记记录,之后 show databases; 就不再显示该库。
这里我们说的 MySQL 整体就是服务端程序 (mysqld 后台进程),运行在 Linux 后台、监听端口、存磁盘数据、解析 SQL、管理 /var/lib/mysql 目录的 mysqld 程序 。而我们敲 mysql> 命令进入的黑框,是 MySQL 客户端,只负责输入 SQL 指令、把语句发给服务端,自身不存任何数据。当我们在客户端输入 create database xxx;,客户端把这条语句通过网络发给服务端进程,服务端一边在 Linux 的 /var/lib/mysql 建磁盘文件夹 (文件系统),一边在自己内部系统表登记库信息 (MySQL 逻辑层),两件事全是服务端完成。
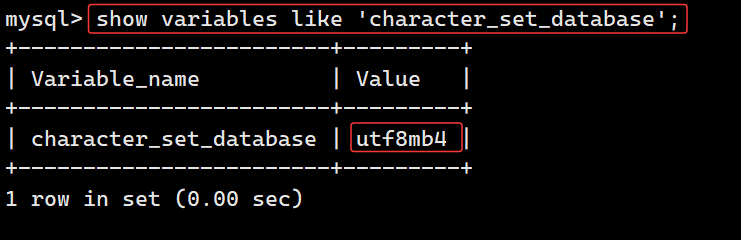
查看当前库字符集使用 show variables like 'character_set_database';,如上,查询结果为 utf8mb4,这就是当前数据库用来存储字符数据的编码格式;
校验集
查看当前库校对集使用 show variables like 'collation_database';,对应配套校对集是 utf8mb4_unicode_ci,这个校对集依附 utf8mb4 字符集,用来负责字段对比、数据排序时的字符规则。
另外执行 show variables like 'collation_%'; 能够一次性查出全系统三处校对配置,分别是连接、当前库、服务全局的校对规则,当前环境里三项统一都是 utf8mb4_unicode_ci,全链路编码保持一致可以避免乱码问题。
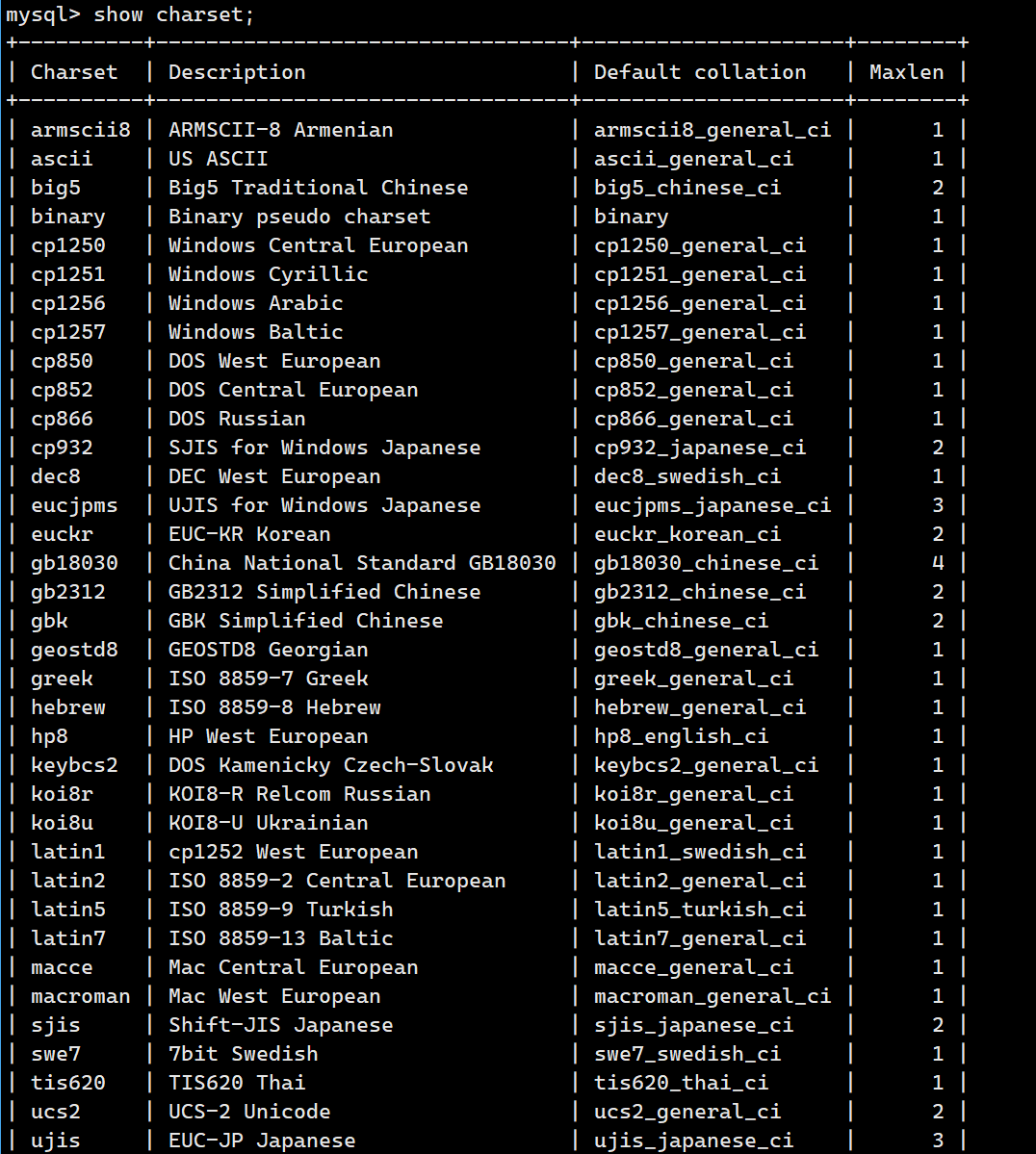
此外我们还可以用 show charset; 语句查看所有的字符集:
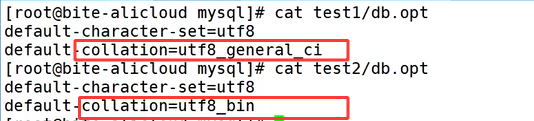
在老版本 MySQL 里,两个库对应的磁盘目录中都会生成 db.opt 配置文件,打开文件就能查看,文件内会完整记录该库默认绑定的字符集与校验集。这两个库的字符集一致,存储数据的编码格式没有区别,但检验规则不同直接影响数据对比和排序逻辑,utf8mb4_unicode_ci 在字段匹配、排序时不区分英文字母大小写,而 utf8mb4_bin 会严格区分大小写。
下面我们建表:
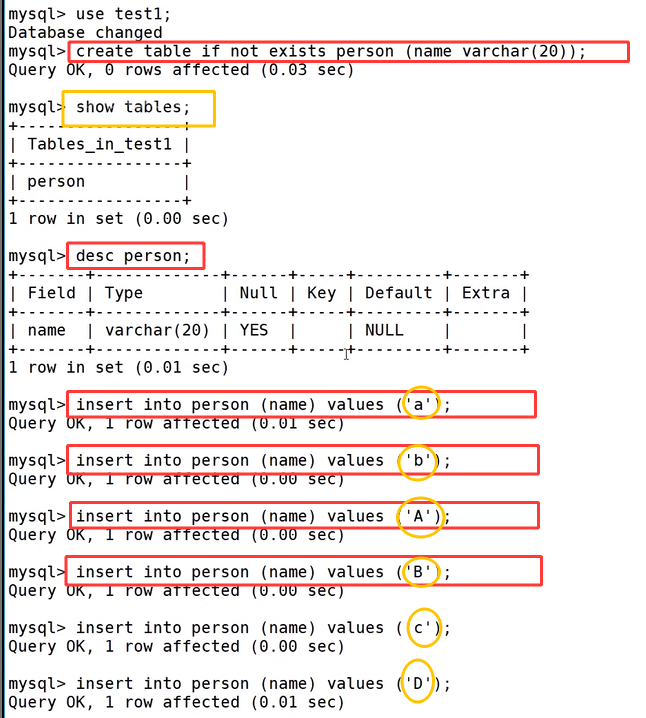
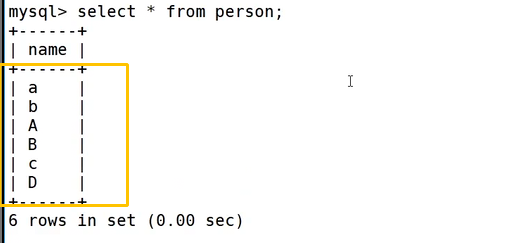
我们先进入 test1 数据库,执行 create table if not exists person(name varchar(20)); 建立 person 表,用 show tables; 可以查到建好的表,desc person; 能够查看表字段结构,随后逐条执行 insert 语句,往表里插入 a、b、A、B、c、D 六条大小写不同的数据,数据落地存储使用数据库配置的字符集编码。
执行 select * from person; 可以把全部六条数据完整查询出来。
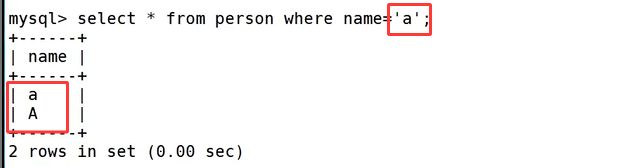
接着执行 select * from person where name='a'; 进行条件检索,这条语句同时查出 a 和 A 两条数据,也就证明 test1 的 utf8_general_ci 校对规则在匹配字段时不区分英文字母大小写。
下面我们再在 test2 数据库中再做上面的操作:
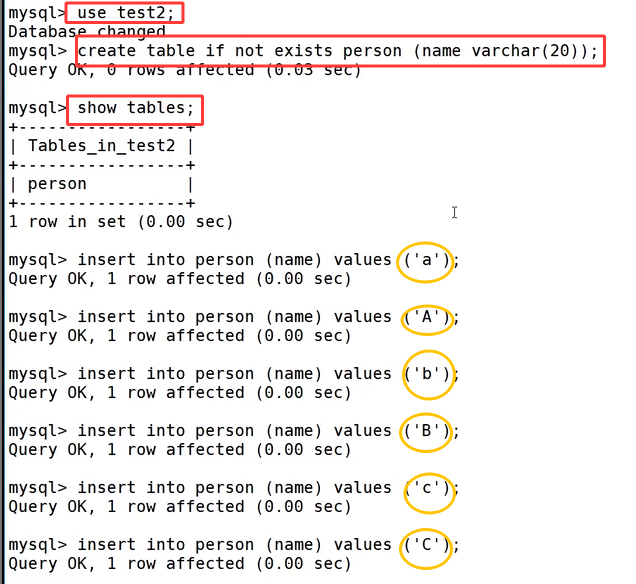
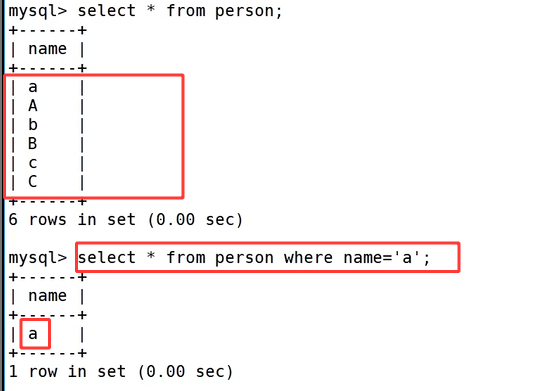
同样创建 person 数据表,再逐条插入 a、A、b、B、c、C 六条数据,全量查询时六条数据也都正常存在磁盘中。
在 test2 里执行 select * from person where name='a';,最终结果只出现小写 a 一条数据,由此验证 test2 的 utf8_bin 校验规则严格区分大小写。
除此之外我们还可以对比排序:
我们继续通过 order by 排序语句验证两种校对规则带来的排序差异,先在 test2 库执行 select * from person order by name;,结果里大写 A、B、C 排在前面,小写 a、b、c 排在末尾,这是 utf8_bin 检验集的特点,大写字母二进制数值更小,优先靠前排列;随后切换到 test1 库再次执行相同的排序查询,数据变成 a 和 A 挨在一起、b 和 B 挨在一起的排布,因为 utf8_general_ci 不区分大小写,排序时把同一个字母的大小写视作同等字符。
/var/lib/mysql 是 Linux 系统里 MySQL 服务默认的数据根目录,mysqld 服务运行时所有落地磁盘的数据、日志、数据库目录、密钥文件都保存在这个文件夹内,目录归属 mysql 用户和用户组,由 MySQL 进程独占读写权限。在这个目录中,我们用 create database 库名创建数据库时,就会自动生成一个同名子文件夹,子目录内部存放对应数据表的 .ibd 数据文件;除此之外目录里还有ibdata1、ibtmp1这类 InnoDB 引擎共用的系统表空间文件,负责存储共享数据与回滚信息,binlog开头的是二进制日志文件,用来记录所有修改数据的 SQL 操作,各类 .pem 后缀文件是 MySQL 的 SSL 安全证书密钥,整份目录里所有文件都由 mysqld 服务统一管理,我们不能手动直接修改里面的文件,只能通过客户端发送 SQL 语句间接改动磁盘数据。



查看当前库校对集使用 show variables like 'collation_database';,对应配套校对集是 utf8mb4_unicode_ci,这个校对集依附 utf8mb4 字符集,用来负责字段对比、数据排序时的字符规则。
另外执行 show variables like 'collation_%'; 能够一次性查出全系统三处校对配置,分别是连接、当前库、服务全局的校对规则,当前环境里三项统一都是 utf8mb4_unicode_ci,全链路编码保持一致可以避免乱码问题。

 我们继续通过 order by 排序语句验证两种校对规则带来的排序差异,先在 test2 库执行 select * from person order by name;,结果里大写 A、B、C 排在前面,小写 a、b、c 排在末尾,这是 utf8_bin 检验集的特点,大写字母二进制数值更小,优先靠前排列;随后切换到 test1 库再次执行相同的排序查询,数据变成 a 和 A 挨在一起、b 和 B 挨在一起的排布,因为 utf8_general_ci 不区分大小写,排序时把同一个字母的大小写视作同等字符。
我们继续通过 order by 排序语句验证两种校对规则带来的排序差异,先在 test2 库执行 select * from person order by name;,结果里大写 A、B、C 排在前面,小写 a、b、c 排在末尾,这是 utf8_bin 检验集的特点,大写字母二进制数值更小,优先靠前排列;随后切换到 test1 库再次执行相同的排序查询,数据变成 a 和 A 挨在一起、b 和 B 挨在一起的排布,因为 utf8_general_ci 不区分大小写,排序时把同一个字母的大小写视作同等字符。
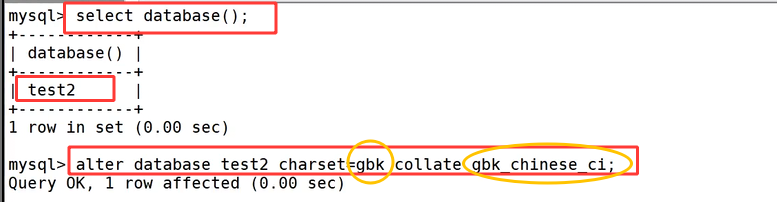 操作前可以先用 select database(); 确认当前所处的数据库,如上图查询结果为 test2,随后执行 alter database test2 charset=gbk collate gbk_chinese_ci; 来更改编码配置。
操作前可以先用 select database(); 确认当前所处的数据库,如上图查询结果为 test2,随后执行 alter database test2 charset=gbk collate gbk_chinese_ci; 来更改编码配置。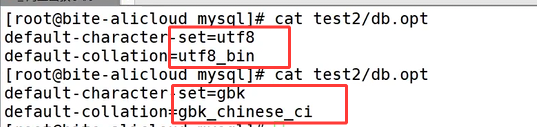

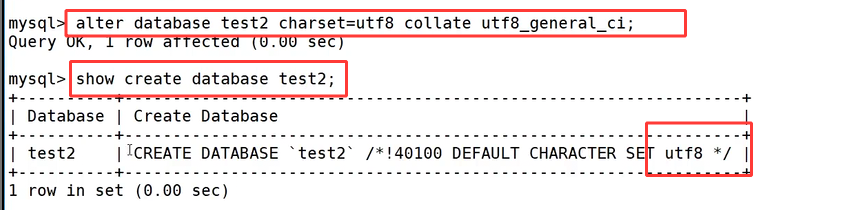 我们再执行 alter database test2 charset=utf8 collate utf8_general_ci;,将字符集改回 utf8,再次执行查看语句,建库信息里的字符集同步变为 utf8,也就代表数据库默认编码修改生效。
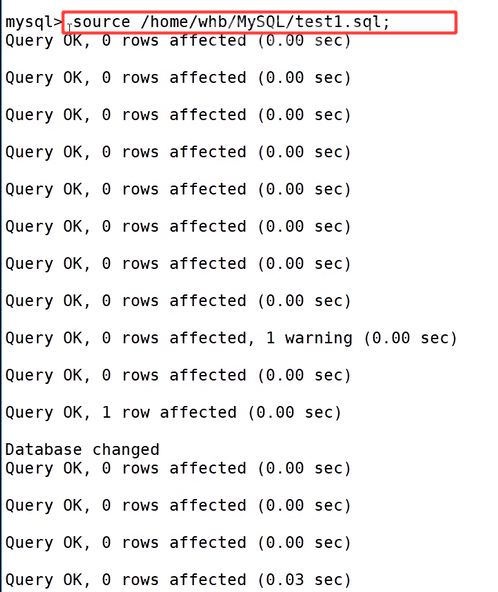
我们再执行 alter database test2 charset=utf8 collate utf8_general_ci;,将字符集改回 utf8,再次执行查看语句,建库信息里的字符集同步变为 utf8,也就代表数据库默认编码修改生效。 我们在 Linux 系统的终端里执行 mysqldump 备份命令 mysqldump -P3306 -uroot -p -B test1 > test1.sql,回车之后按照提示输入数据库 root 用户的密码,命令执行完毕后,使用 ll 指令查看当前目录,能够看到生成了 test1.sql 备份文件。
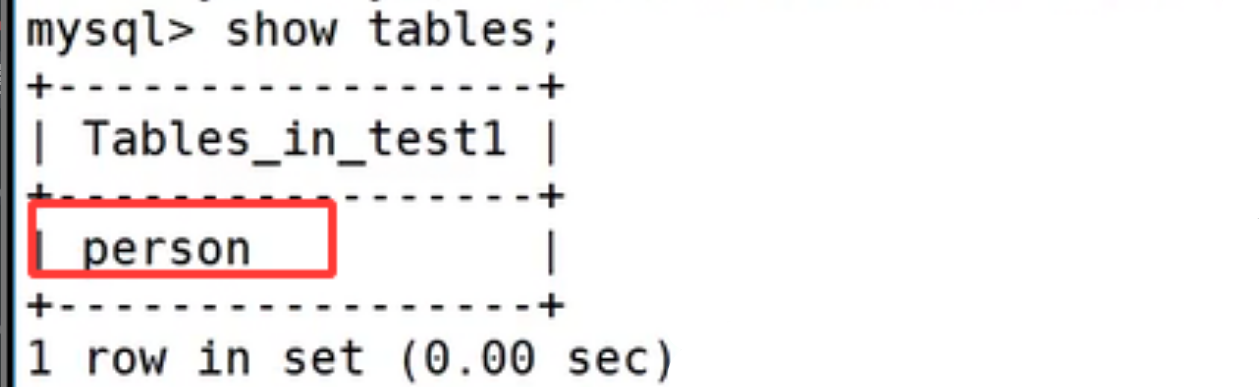
我们在 Linux 系统的终端里执行 mysqldump 备份命令 mysqldump -P3306 -uroot -p -B test1 > test1.sql,回车之后按照提示输入数据库 root 用户的密码,命令执行完毕后,使用 ll 指令查看当前目录,能够看到生成了 test1.sql 备份文件。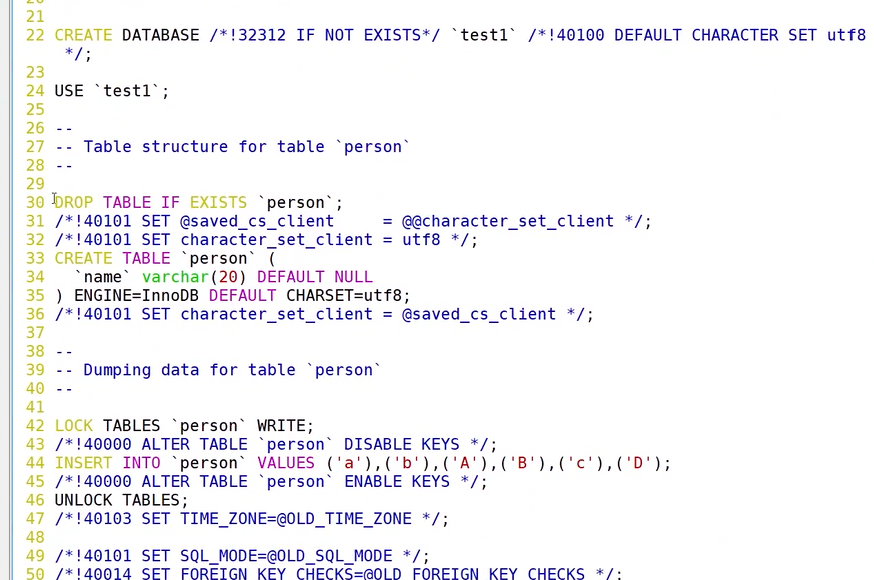 打开这份 sql 文件可以发现,文件内部完整保存了整套 SQL 语句,从创建 test1 数据库、切换使用数据库,到删除原有 person 表、重建 person 表结构,再到插入全部已存数据的语句都被完整记录,这也就说明 mysqldump 属于逻辑备份,备份文件不单存储数据表中的业务数据,同时把建库、建表、录入数据的全量操作语句一并保存,后续依靠该文件就可以完整还原出一模一样的数据库环境。
打开这份 sql 文件可以发现,文件内部完整保存了整套 SQL 语句,从创建 test1 数据库、切换使用数据库,到删除原有 person 表、重建 person 表结构,再到插入全部已存数据的语句都被完整记录,这也就说明 mysqldump 属于逻辑备份,备份文件不单存储数据表中的业务数据,同时把建库、建表、录入数据的全量操作语句一并保存,后续依靠该文件就可以完整还原出一模一样的数据库环境。