大家好,我是若风。
很多人学 AI 应用开发,上来就是调 API、接模型、写聊天框。
这当然没错,动手很重要。
但说实话,如果底层概念没想清楚,后面会遇到一堆很诡异、也很让人焦虑的问题:为什么 prompt 明明写了,模型还是像没看见?为什么 RAG 检索出来的文档总是不对?为什么同一个问题,今天答得很好,明天又开始胡说?为什么上下文塞得越多,效果反而越差?
这些问题表面看是"模型不稳定"。真正关键往往是:你还没有建立 AI 工程的心智模型。
这篇文章不讲复杂数学,也不假装一篇文章能让你造出大模型。我们只做一件事:把写 AI 应用前最该懂的 10 个概念讲清楚。
Token 是 AI 世界里的最小账本单位
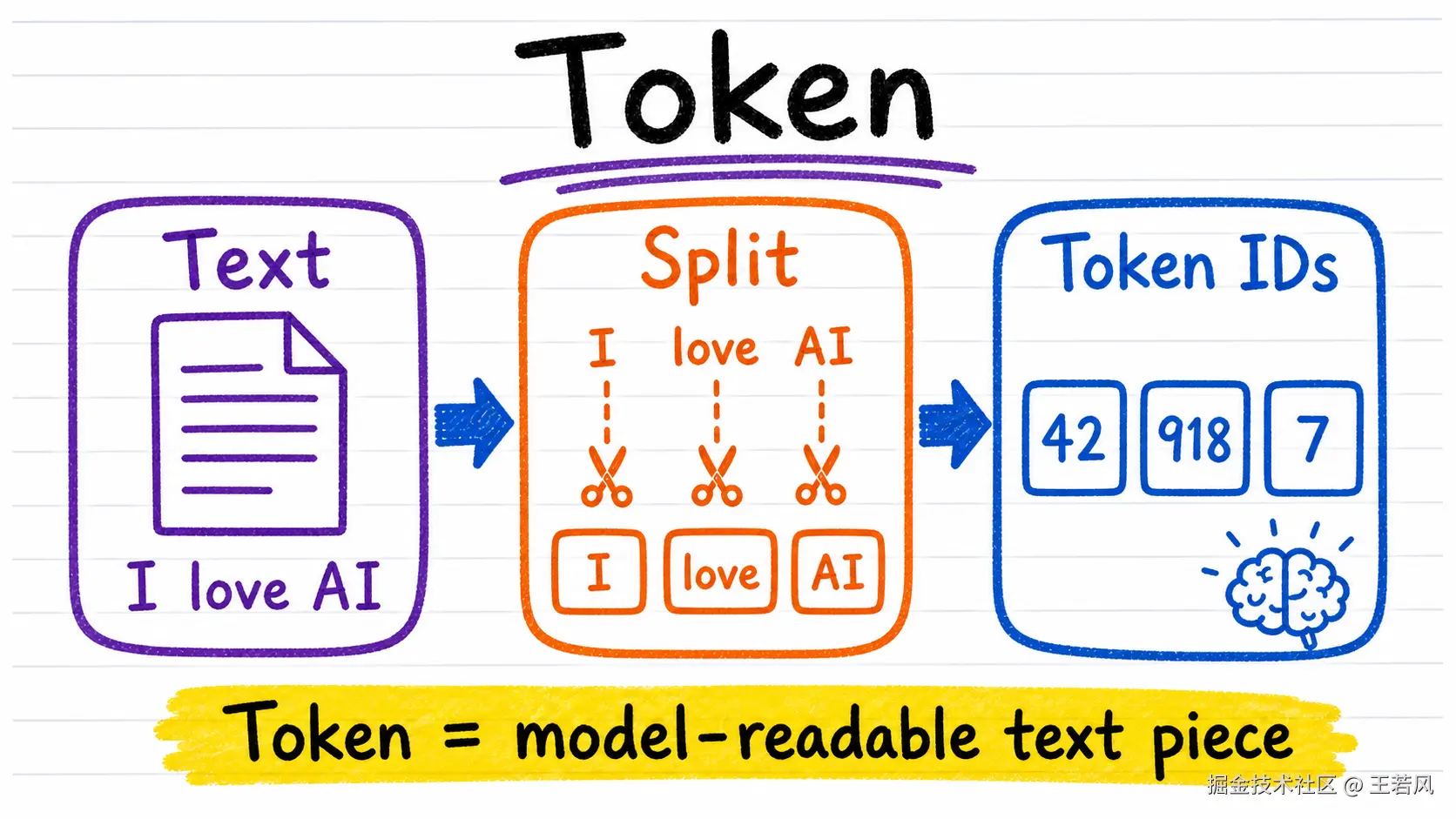
你输入一句话,模型看到的不是"句子",而是一段一段的 Token。Token 可以是一个词,也可以是半个词,还可以是一个标点。比如英文里的 building,可能会被切成 build 和 ing;中文也会被模型按自己的分词规则切成不同片段。
这件事听起来很基础,但它直接影响三件事:API 费用按 Token 算,上下文窗口按 Token 算,模型生成速度也跟 Token 数有关。
所以,当你发现一次调用比预期贵、长文档被截断、模型"忘了前面的话"------很多时候不是模型在耍脾气,而是 Token 预算已经被吃完了。
写 AI 应用时,要先学会估算 Token。
尤其是做文档问答、长对话、代码分析这类功能,Token 就像内存,不够用时系统一定会出问题。
Embedding 让文本变成可以计算的语义
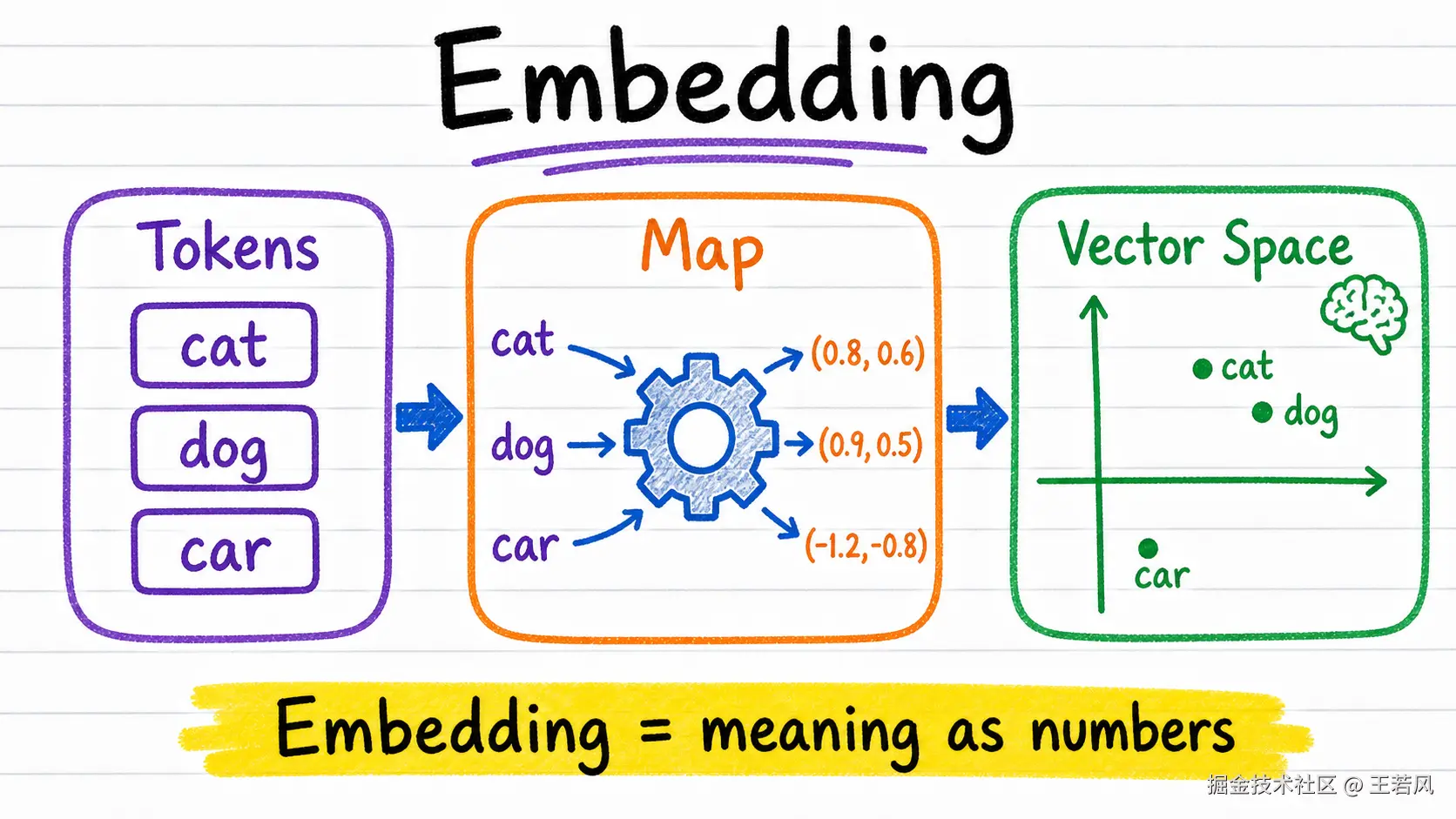
模型不能直接拿"含义"做计算。它需要先把文本变成一串数字,这串数字就是 Embedding,也就是嵌入向量。
你可以把它理解成:每句话、每段文档、每个问题,都会被放进一个高维语义空间里。意思相近的内容,距离就近;意思相差很远的内容,距离就远。
比如"医生"和"护士"通常会靠得比较近,"医生"和"显卡驱动"就会远很多。这就是语义搜索、推荐系统、文档问答能工作的基础。
开发者最容易踩的坑是:以为 RAG 检索不准一定是大模型回答能力差。
很多时候,问题出在 Embedding 阶段。文档切块太粗,向量模型不适合中文,查询语句没有改写------都会导致"搜出来的上下文一开始就是错的"。
后面的 LLM 再强,也只能拿着错误材料努力圆。
Attention 决定模型该看哪里
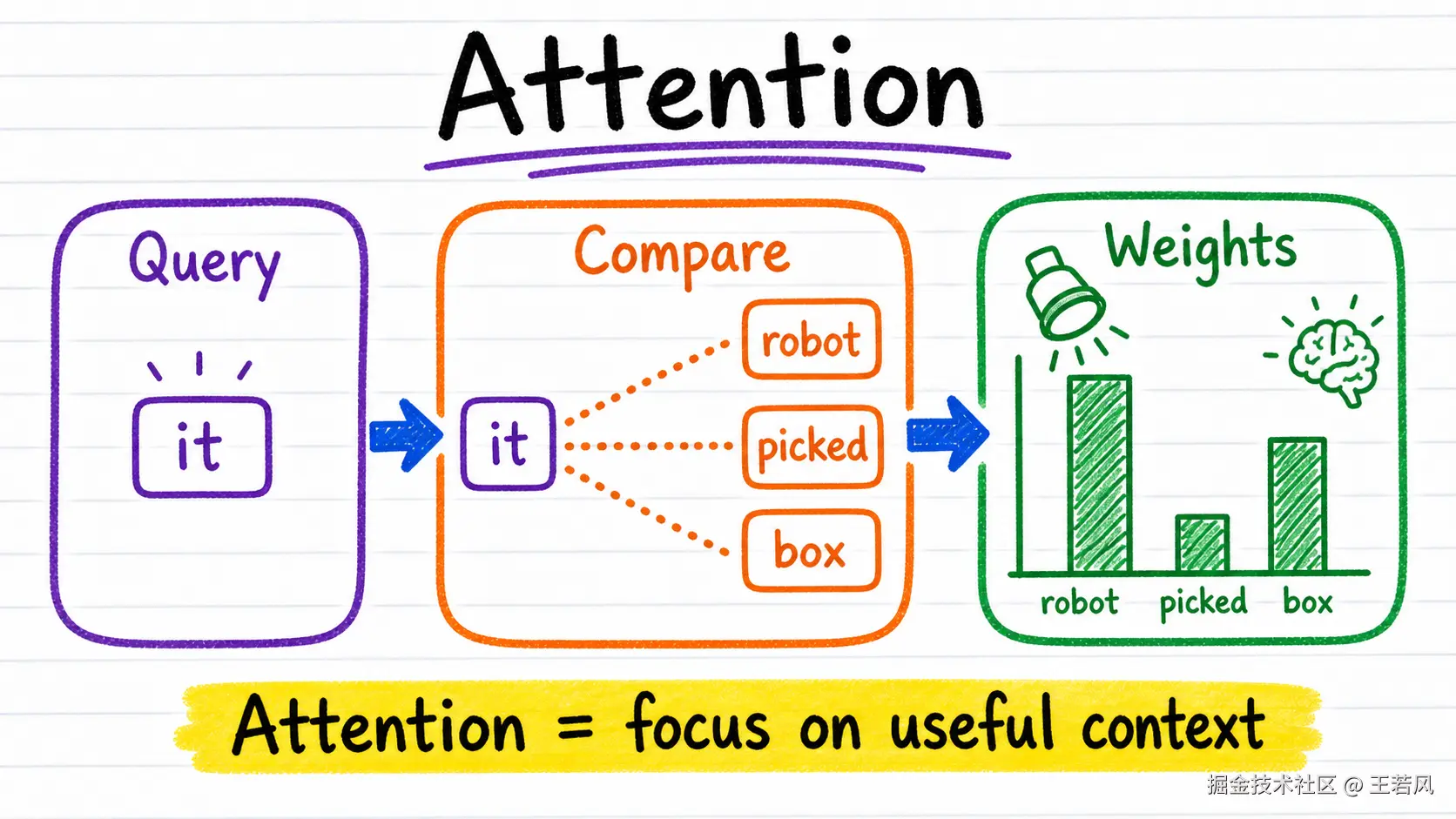
同一个词,在不同上下文里意思完全不同。"苹果很好吃"和"苹果发布了新系统",这里的"苹果"显然不是一回事。模型靠什么判断?靠 Attention。
Attention 的核心思想是:每个 Token 都可以观察上下文里的其他 Token,并给它们分配不同权重。
如果句子里出现"股票""公司""发布会",模型就更可能把"苹果"理解成 Apple;如果出现"削皮""水果""甜",它就更可能理解成水果。
这也是为什么 prompt 写得越清楚,模型越稳。
你给它模糊的一句话,它只能在概率里猜。你给它清晰的背景、目标、约束、示例,它就有更多可用上下文来分配注意力。
所以,提示词工程不是玄学。它本质上是在帮模型把注意力放到正确的地方。
Transformer 是现代大模型的发动机
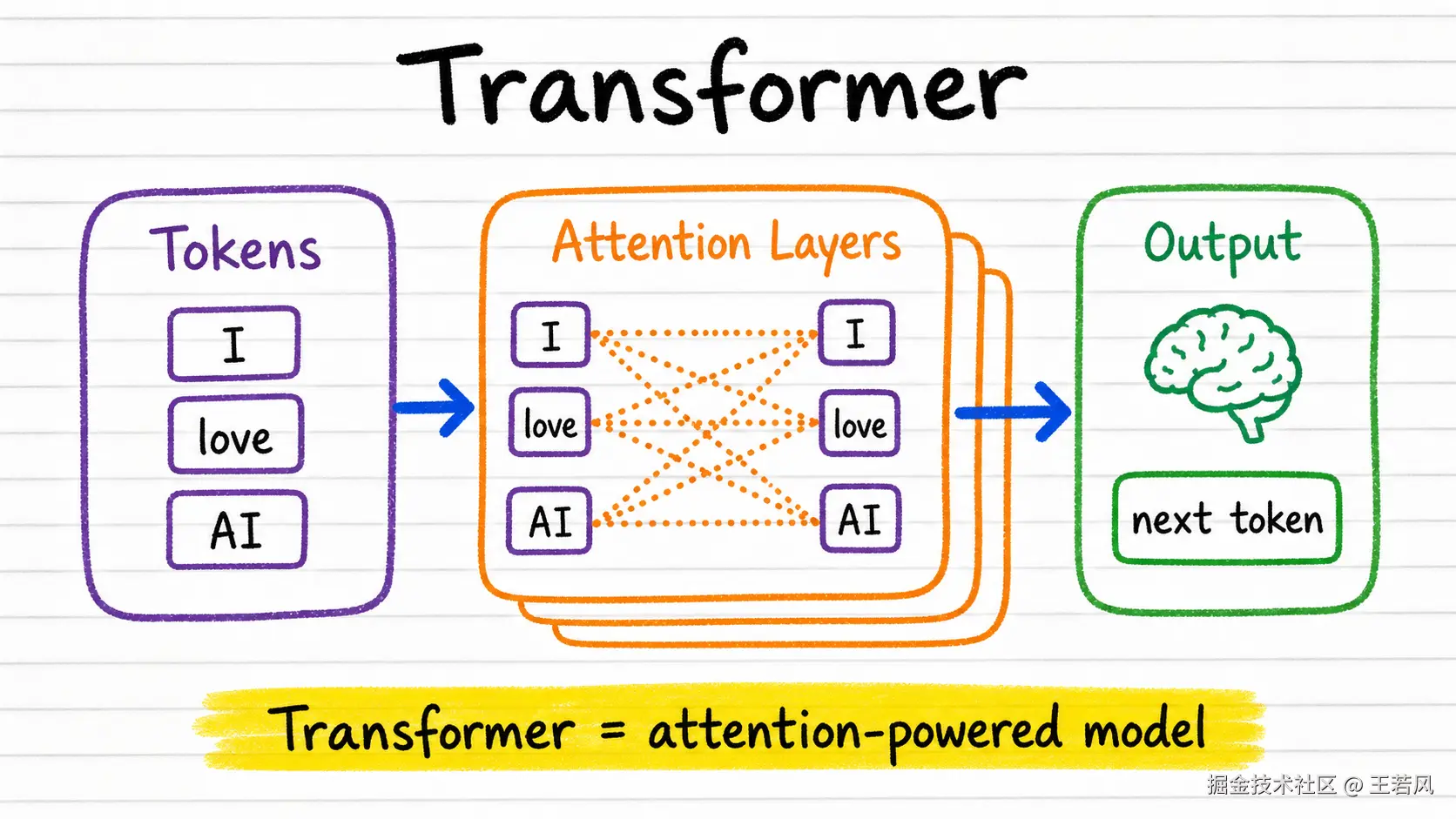
GPT、Claude、Gemini、Llama,背后都离不开 Transformer 这个架构。
你不一定要会手写 Transformer,但你至少要知道它的工作方式:文本先被切成 Token,Token 变成 Embedding,然后经过一层又一层 Attention,最后预测下一个 Token。
注意,是下一个 Token。模型不是一次性写完整篇文章。它是一边生成,一边把刚生成的内容放回上下文里,再继续预测下一个 Token。
这个机制解释了很多现象。
长回答会更慢,因为要预测更多次。前文会影响后文,因为前面生成的 Token 会进入后续上下文。输出偶尔不稳定,因为每一步都在概率分布里做选择。
理解 Transformer,不是为了把模型神秘化,而是为了把模型工程化。
LLM 本质上是一个超大规模文本预测器
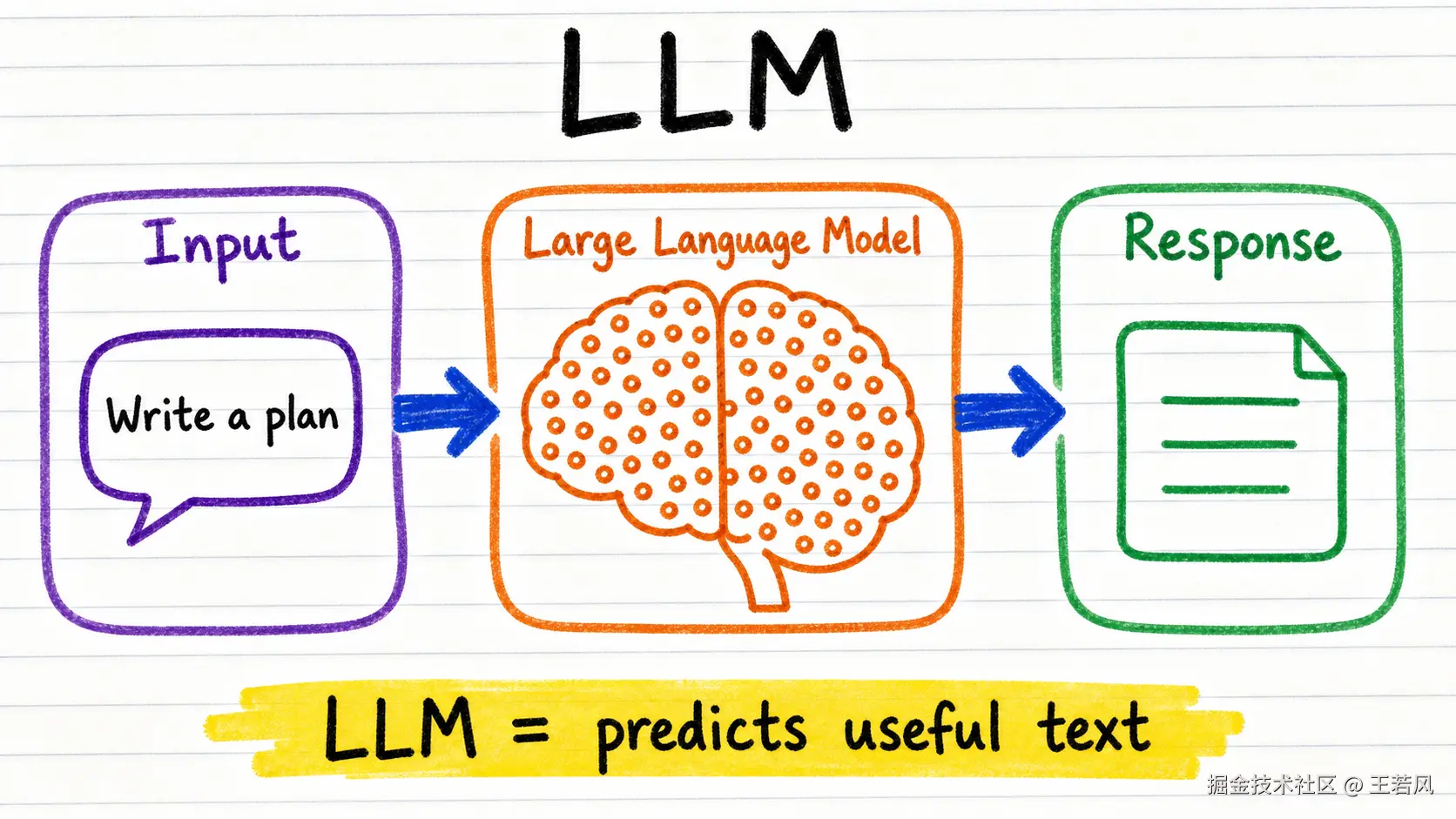
LLM 是 Large Language Model,大语言模型。它的训练任务听起来非常简单:给定前面的文本,预测下一个 Token。
就这么一件事。
大量书籍、网页、代码、论文、论坛内容被喂给模型。模型不断预测,不断修正参数,最后学到语言、代码、事实、推理模式之间的复杂关系。
这就是它为什么能写代码、做总结、翻译、解释概念。
但这里有一个非常重要的边界:LLM 不是数据库。
它并不是每次回答都去某个地方查资料。默认情况下,它是在根据训练中学到的模式生成最可能的文本。
这个差别非常关键。
如果你把 LLM 当数据库用,就会自然期待它"查得准"。但如果你把它理解成预测器,你就会知道:涉及事实、实时信息、内部数据时,必须给它外部来源,不能只靠模型记忆。
Hallucination 是能力边界,不是偶发小 bug
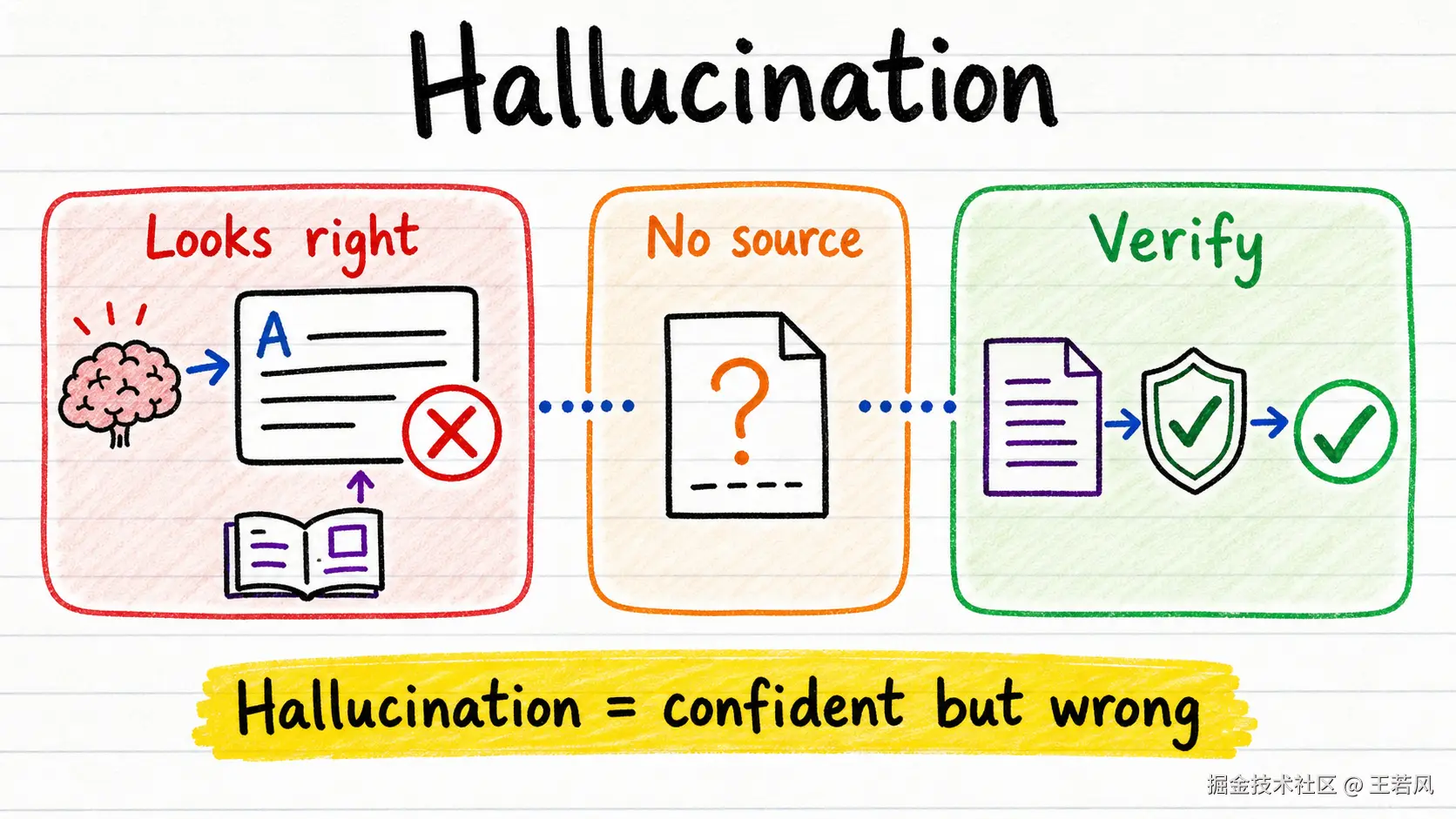
幻觉是 AI 应用里最危险的问题之一。它不是"模型说得不够好",而是模型会自信地生成错误内容。
比如引用不存在的论文,编造 API 参数,给出看起来很合理但完全错误的业务数据,或者把两个相似概念混在一起。
为什么会这样?因为模型的目标不是"保证真相",而是"生成最可能的下一个 Token"。如果一个错误答案在语言模式上很顺,它就可能被生成出来。
这也是为什么幻觉特别危险:它通常不像错误。
它很流畅,很自信,很像真的。
开发者要做的不是祈祷模型别幻觉,而是设计系统时默认它会幻觉。
事实类问题用 RAG。关键输出加验证层。涉及外部状态时使用工具调用。生产环境里,不要把原始 LLM 输出直接当事实展示给用户。
可靠 AI 产品的第一课,就是承认模型会错。
Temperature 是控制随机性的旋钮
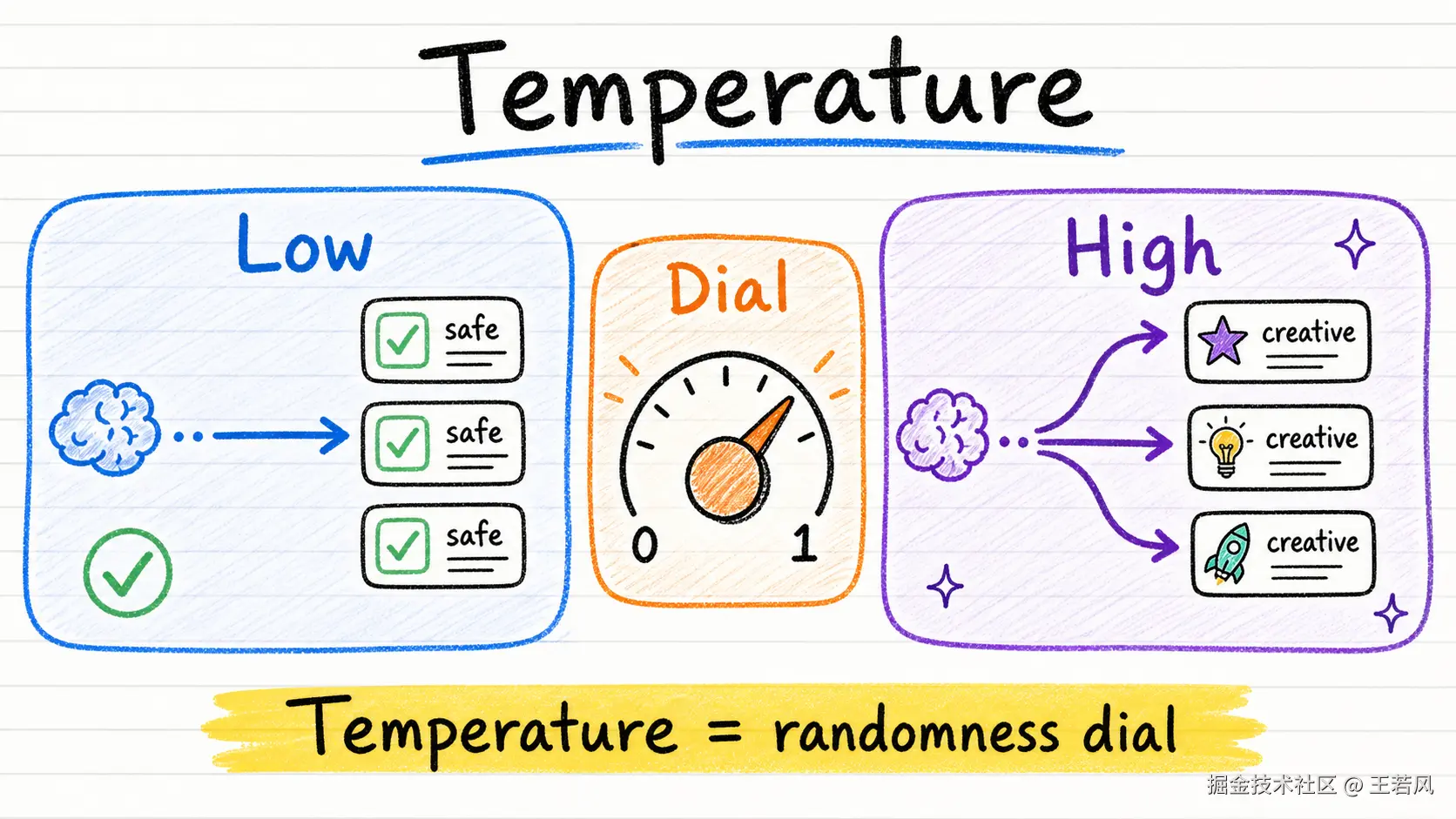
模型生成下一个 Token 时,通常不是只有一个候选。它会给很多可能的 Token 计算概率。
Temperature 控制的是:模型到底有多愿意选择那些概率不是最高、但也有可能的答案。
低 Temperature,更稳定,更保守,更适合代码、事实问答、结构化抽取。
高 Temperature,更发散,更有创意,更适合头脑风暴、文案、故事、创意探索。
一个很实用的经验:写代码,可以从 0.1-0.2 开始;事实问答,可以从 0.2-0.3 开始;总结归纳,可以用 0.3-0.5;聊天和创意写作,可以提高到 0.7 以上。
很多新手的问题在于:所有场景都用默认值。结果让模型写代码时,它过于有创意;让模型写文案时,它又太死板。
Temperature 只是一行参数,但它会明显改变产品体验。
Context Window 是模型的工作记忆
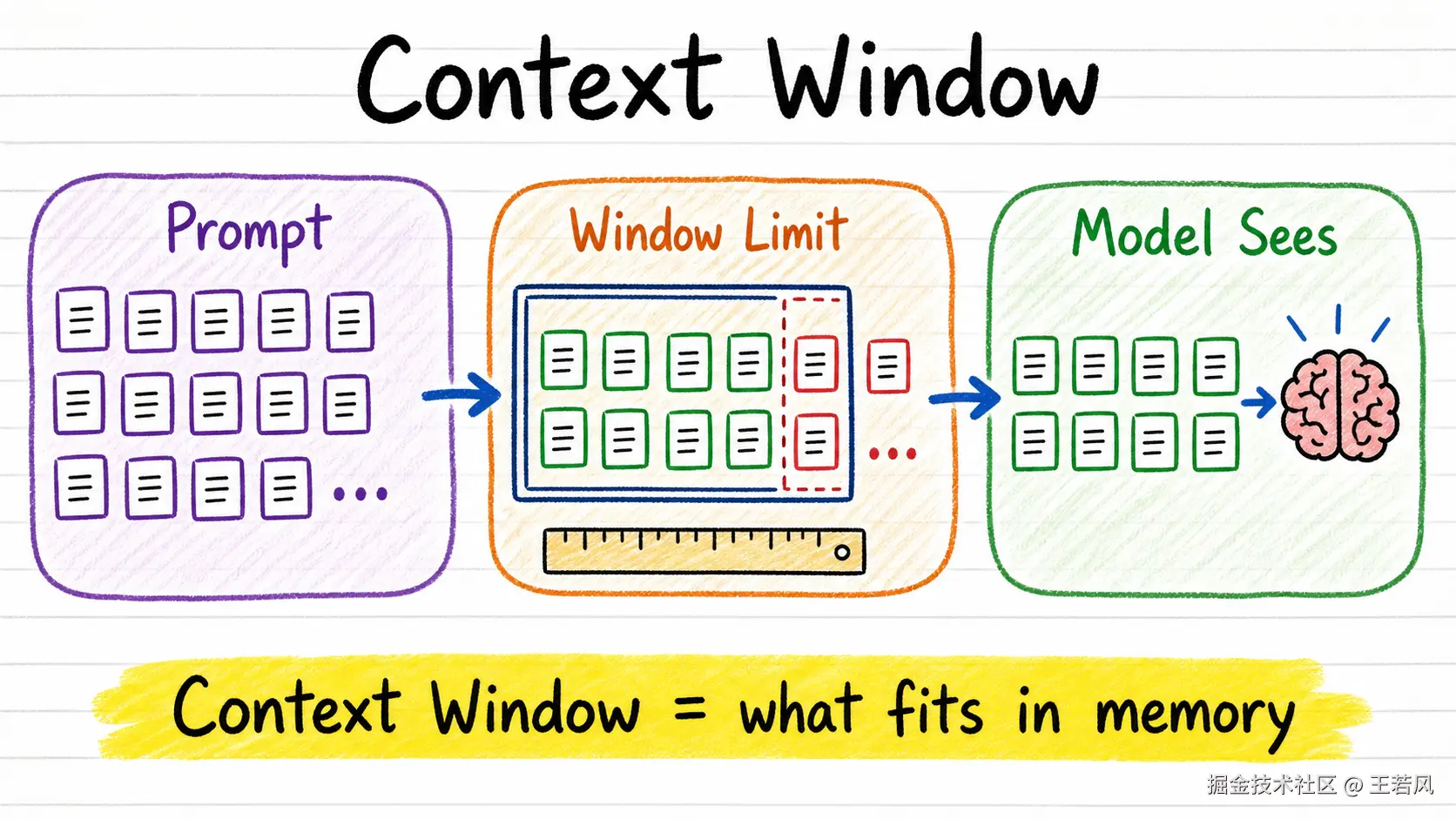
上下文窗口,就是模型一次调用里能看到的全部内容。系统提示词、用户问题、历史对话、检索出来的文档、工具返回结果、模型已经生成的内容------都要塞进这个窗口。
窗口再大,也不是无限大。
更麻烦的是,模型并不会均匀阅读所有上下文。很多模型对开头和结尾更敏感,中间部分更容易被忽略,这就是常说的 "Lost in the Middle"。
所以,管理上下文是 AI 工程里非常核心的能力。
重要指令要放在前面。关键事实要靠近问题。长文档不要一股脑塞进去,要先切块、检索、摘要,再组织给模型。
当你发现"我明明把资料给它了,它怎么还答错",先别急着怪模型。你要检查的是:资料是否真的在窗口里,是否在模型容易注意到的位置,是否和问题强相关。
RAG 让模型回答你的私有数据
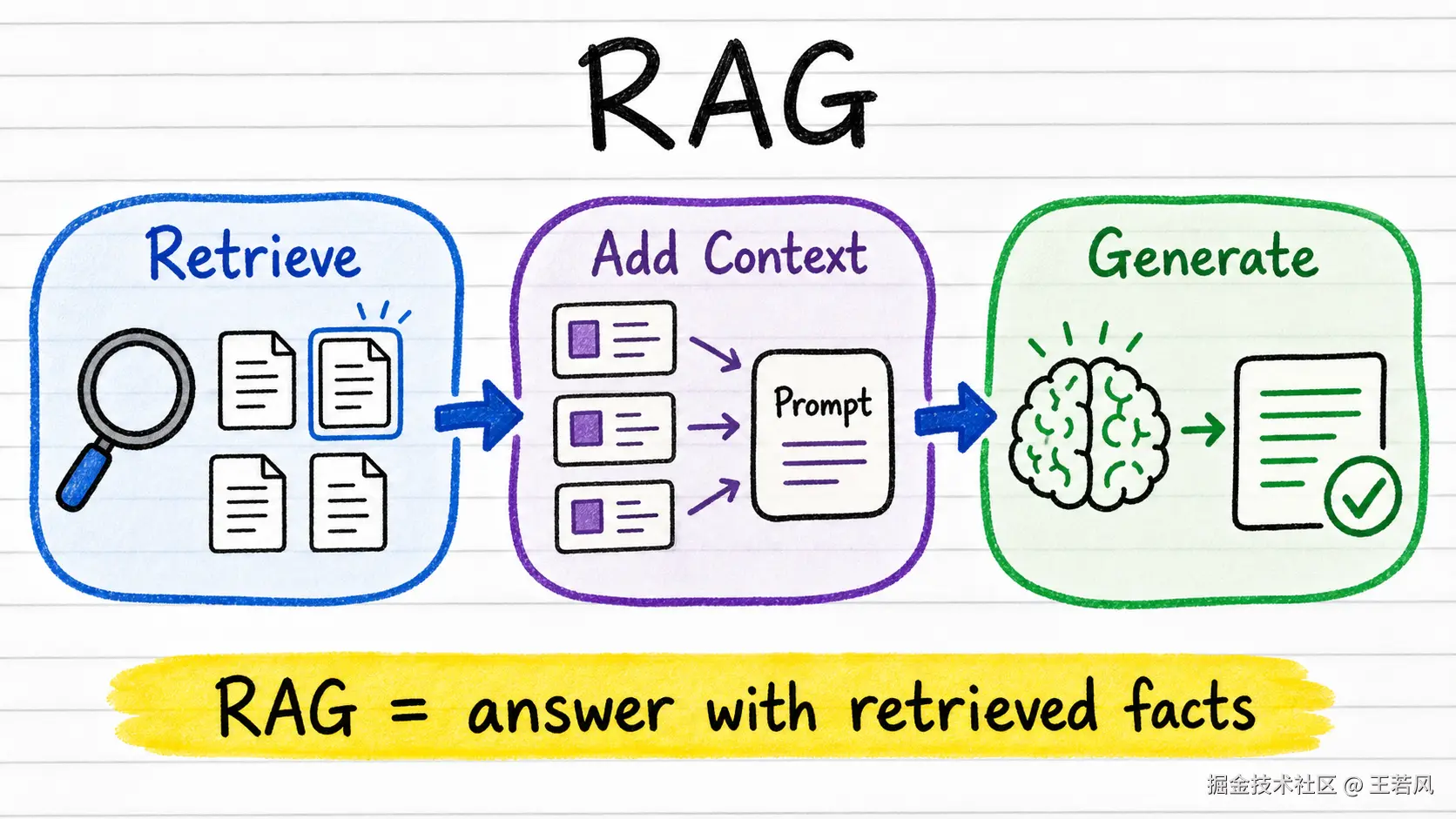
RAG 是 Retrieval-Augmented Generation,检索增强生成。它解决的是一个非常现实的问题:模型训练数据有截止日期,也不知道你的内部文档、产品手册、用户数据和最新业务规则。
RAG 的流程可以拆成 5 步:
用户提问,把问题转成 Embedding,去向量数据库里找相关文档,把文档和问题一起发给模型,模型基于这些材料生成答案。
这就是很多知识库问答、客服机器人、文档助手背后的核心架构。
RAG 的好处很直接。
数据更新时,只要更新文档,不用重新训练模型;需要引用来源时,检索结果本身就是依据;要降低幻觉时,可以让模型围绕真实材料回答。
但 RAG 也不是"接上向量库就完事"。
真正影响效果的是文档切块、Embedding 模型、召回策略、重排序、上下文拼接和答案约束。任何一环粗糙,最后都可能表现为"模型答得不好"。
RAG 看起来是一个功能,实际是一条工程链路。
AI Agent 的关键不是聊天,而是循环
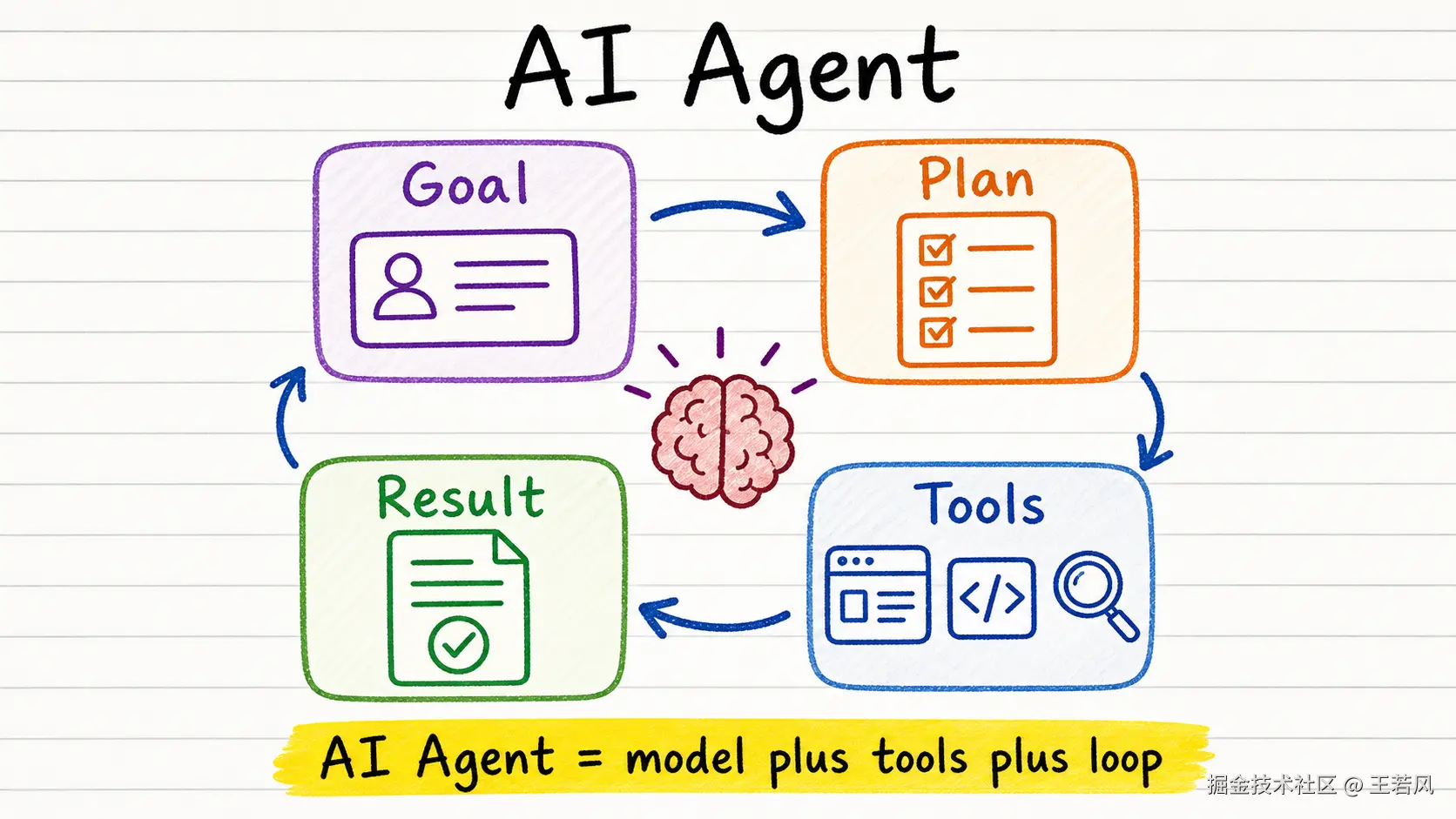
普通 LLM 应用的模式是:你问,它答。AI Agent 的模式是:你给目标,它规划,调用工具,观察结果,再决定下一步。
区别就在这个循环。
一个调试 Agent 可能会这样工作:读取报错,搜索代码库,定位文件,修改代码,运行测试,发现还有失败,再读测试输出,再修复,直到通过。
坦白讲,这也是 Agent 最让人兴奋、也最让人崩的地方:它看起来像自动化,真正难的是每一步都可能偏一点。
这里面模型只是"大脑"。真正让 Agent 能做事的,是工具:文件读写、代码执行、浏览器、搜索、数据库、API、邮件、日历。
但 Agent 最难的地方也在这里。
每一步都有失败概率。一个 3 步任务,每步 90% 准确,最后成功率是 72.9%。如果是 10 步,成功率会掉得非常明显。
所以 Agent 工程的重点不是"让模型能调用工具"这么简单,而是让每一步可观察、可验证、可回滚。
能跑起来的 Agent 很多,能稳定完成任务的 Agent 很少。
写在最后:这 10 个概念要连起来看
如果你刚开始学 AI 应用开发,可以按这个顺序理解。
先懂 Token,因为它是成本、长度和速度的单位。再懂 Embedding,因为它让文本可以被搜索和匹配。然后懂 Attention,因为它解释了上下文为什么重要。
接着看 Transformer 和 LLM,你会明白模型内部大致如何生成文本。再看 Hallucination、Temperature、Context Window,你会开始理解模型为什么会失控,以及怎么控制它。
最后学 RAG 和 Agent,你才真正进入 AI 工程。
这 10 个概念不是 10 个孤立名词。它们其实是一条线:文本如何进入模型,模型如何理解上下文,模型如何生成答案,系统如何补足模型的事实边界,最后如何让模型带着工具完成任务。
理解到这里,AI 就不再是一个神秘黑盒。
它变成了可以设计、可以调试、可以优化的工程系统。我倒是觉得,这才是开始写 AI 应用之前,最值得补上的一课。