好久分享文章了,今天分享一个自己手搓的企业级的RAG系统,硬件支持的的情况下可以在本地直接跑,个人学习成果分享,欢迎大家探讨~
系统概览图
登录页
首页
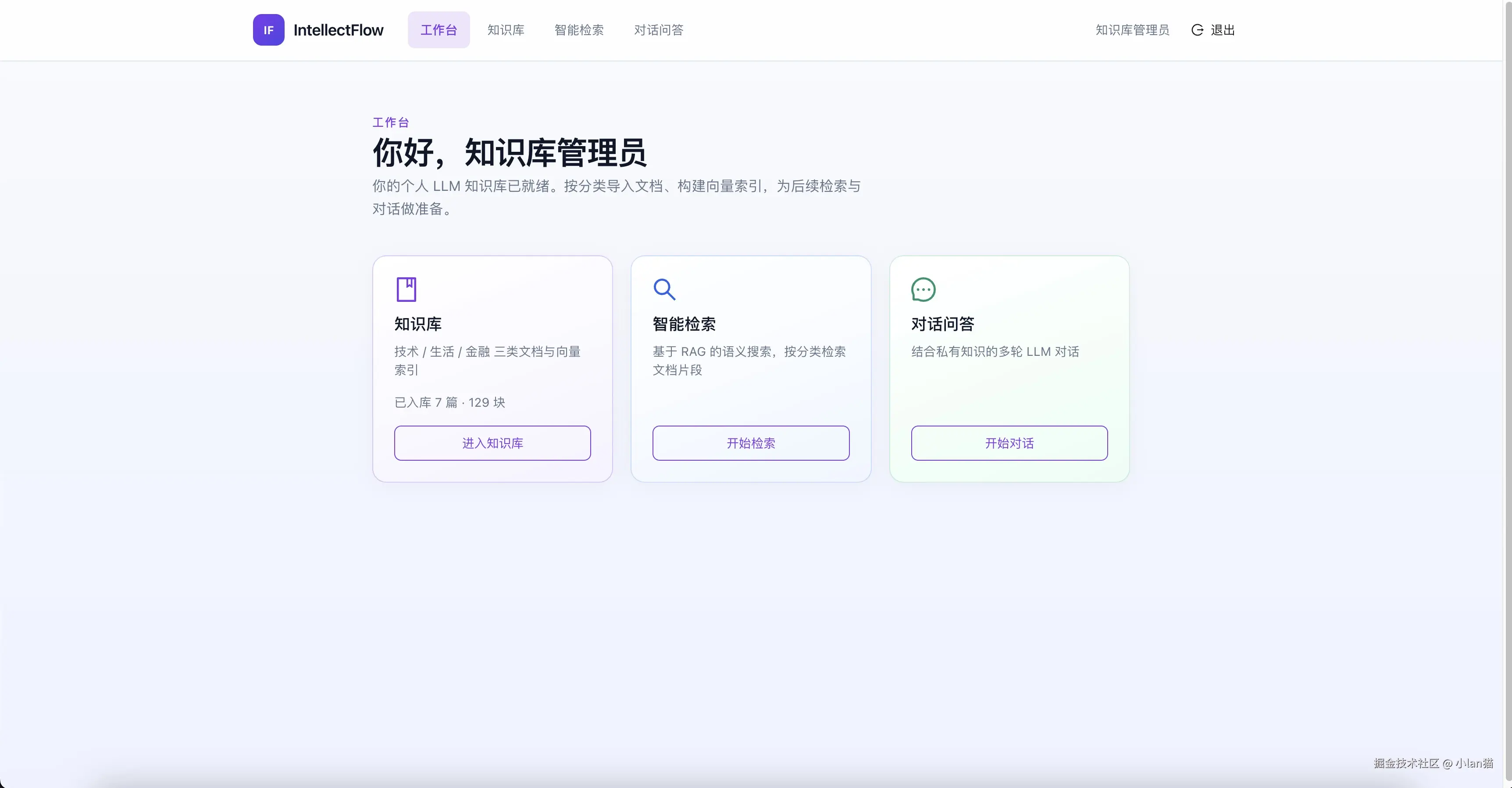
知识库上传页
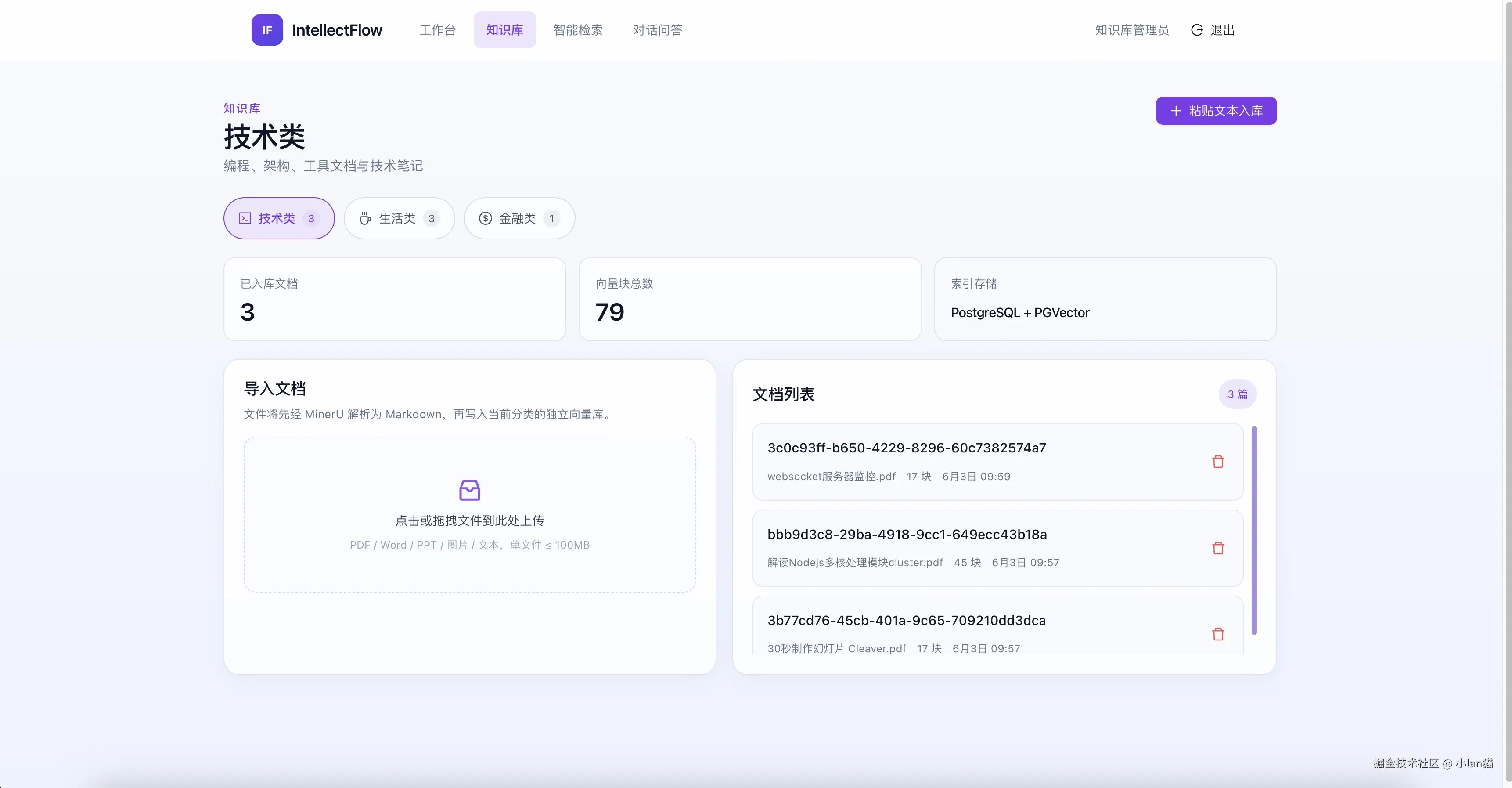
语义搜索页
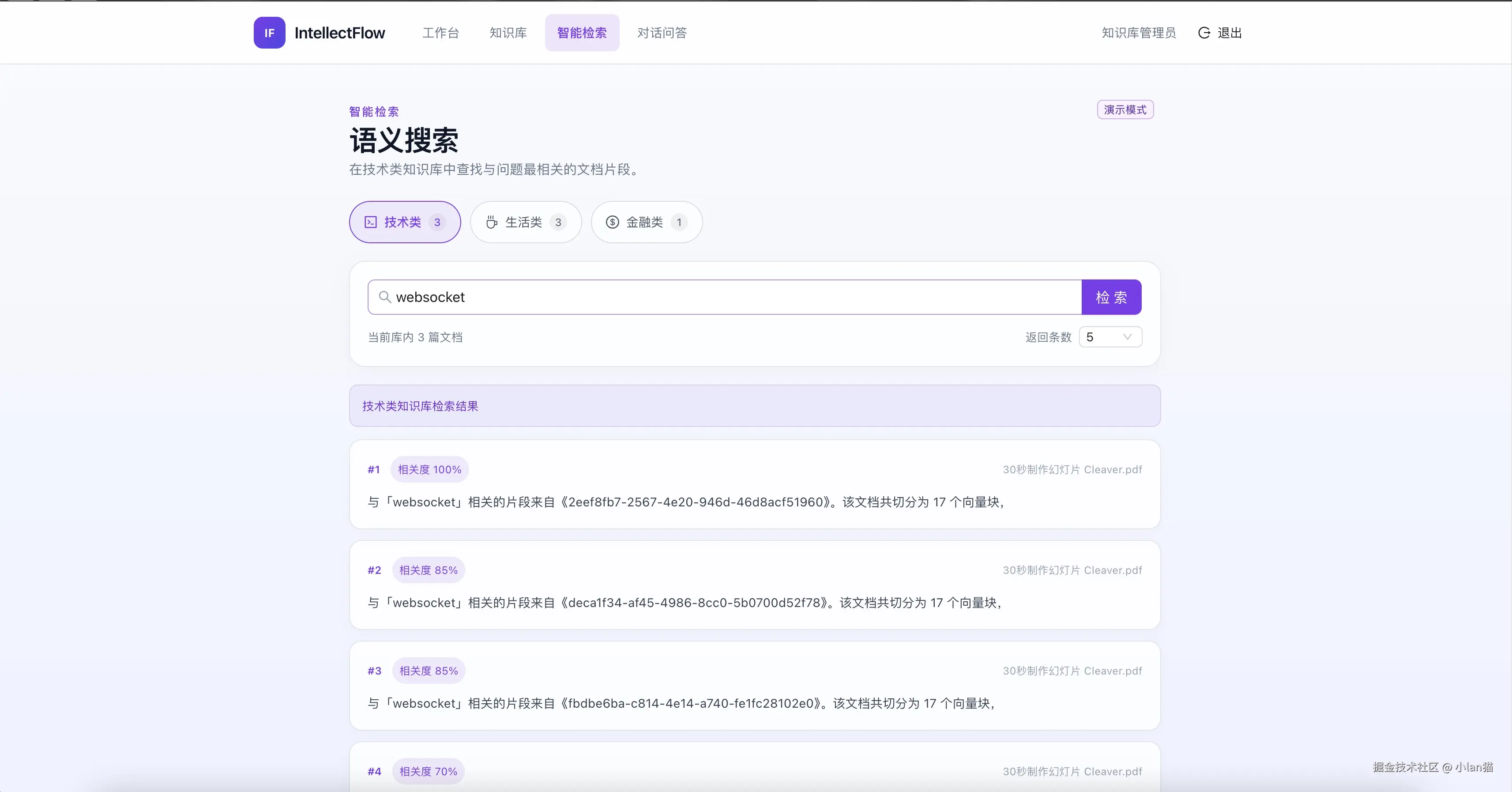
智能聊天页
一、解决什么问题?
大模型擅长泛化推理,却不天然「记得」你的私有资料。检索增强生成(Retrieval-Augmented Generation,RAG)的标准路径是:
- 入库(Indexing) :把文档切块、向量化,写入向量库;
- 检索(Retrieval) :用用户问题取向量库要相关片段;
- 生成(Generation) :把片段塞进 Prompt,约束模型「只依据资料回答」。
IntellectFlow 在此基础上做了两件产品化的事:
- 按领域拆库:技术 / 生活 / 金融三套独立向量表与 API,避免语义空间互相污染;
- 端到端体验:上传 PDF、解析 Markdown、入库、关键词检索、SSE 流式问答,全部可在 Vue 管理界面完成。
二、系统全景
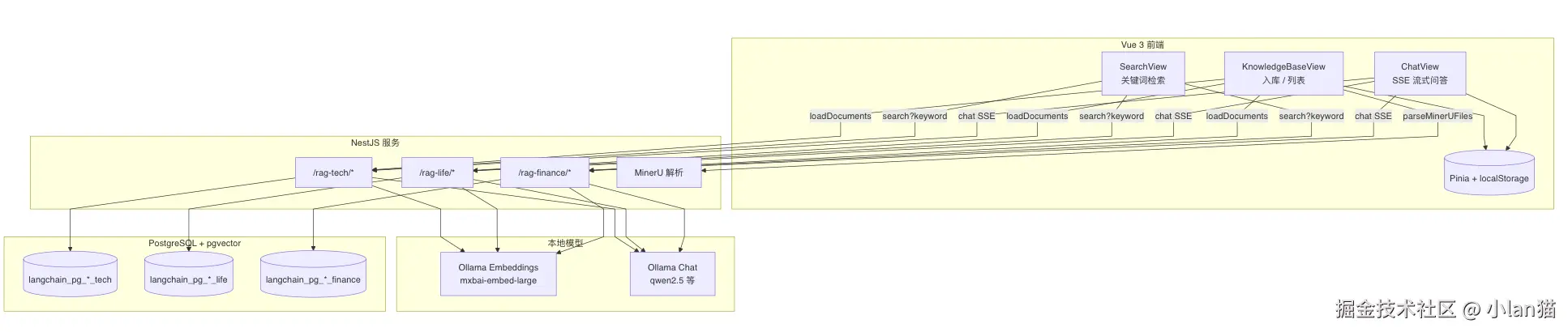
数据流可以概括为两条主线:
| 主线 | 前端入口 | 后端能力 | 检索方式 |
|---|---|---|---|
| 知识管理 | 上传文件 / 粘贴文本 | loadDocuments → 分块 → PGVectorStore.fromDocuments |
--- |
| 问答 | Chat 输入框 | chat → 向量 Top-K → Prompt → 流式 LLM |
语义向量(cosine) |
| 浏览检索 | Search 页 | search → SQL ILIKE + 命中打分 |
关键词(非向量) |
注意:当前 搜索页与对话页使用了不同的检索策略,这是理解系统行为的关键(后文会展开)。
三、技术选型与依赖关系
| 层级 | 选型 | 在项目中的角色 |
|---|---|---|
| 前端 | Vue 3 + Pinia + Ant Design Vue + Vue Router | 三分类路由、本地文档元数据缓存、SSE 消费 |
| 后端 | NestJS + LangChain.js | 模块化 RagTech / RagLife / RagFinance |
| 向量库 | @langchain/community 的 PGVectorStore |
复用 LangChain 表结构,按域拆表 |
| 嵌入 / 对话 | @langchain/ollama |
OllamaEmbeddings + ChatOllama,默认本机 Ollama |
| 文档解析 | MinerU(可选) | PDF 等 → Markdown 再入库 |
| 分块 | RecursiveCharacterTextSplitter |
中文友好分隔符 + 500/50 切块策略 |
Ollama 相关配置集中在 service/config.ts:
- 对话模型 :
OLLAMA_CHAT_MODEL(默认qwen2.5:14b) - 向量模型 :
OLLAMA_EMBED_MODEL(如mxbai-embed-large) - 温度 :RAG 场景在 Service 里写死
temperature: 0.1,偏向稳定、可复现的回答
四、多域知识库:为什么要三套 Service?
前端用 KbCategory(tech | life | finance)统一描述业务,每个分类在 KB_CATEGORIES 里绑定独立 API 前缀:
bash
// client/src/types/knowledge-base.ts(节选)
{
key: "tech",
apiPath: "/rag-tech/loadDocuments",
searchApiPath: "/rag-tech/search",
chatApiPath: "/rag-tech/chat",
apiGetListPath: "/rag-tech/getDocuments",
}
// life、finance 同理,分别指向 /rag-life/*、/rag-finance/*后端镜像这一设计:三个 Nest Module,各自维护 独立的 collectionTableName 与 tableName,例如金融域:
vbnet
// service/src/rag-finance/rag-finance.service.ts(节选)
collectionName: 'rag-finance-knowledge-base',
collectionTableName: 'langchain_pg_collection_finance',
tableName: 'langchain_pg_embedding_finance',
collectionMetadata: {
category: 'finance',
label: '财经类知识库',
info: { charCount, chunkCount, fileName, id, indexedAt, source, title },
},设计收益:
- 隔离:不同领域的文档、元数据、向量不会混在同一 collection;
- 演进:某一域可单独调 chunk 大小、Prompt 人设或表名,而不影响其它域;
- 与路由一致 :前端
router.params.category切换时,API 与 UI 主题色(accent)一并切换,产品感知清晰。
代价是 代码重复 (三个 Service 结构高度相似)。若继续迭代,可抽 BaseRagService 注入 pgVectorStoreConfig 与 system prompt 模板------但当前实现选择了「复制三份、各自可改」的务实路线。
五、入库链路:从上传到向量块
5.1 前端:两种入库方式
KnowledgeBaseView.vue 支持:
- 文件上传 :先调
parseMinerUFiles把 PDF 等转成 Markdown,再indexContent; - 文本粘贴:标题 + 正文直接入库。
核心索引逻辑:
php
const docId = crypto.randomUUID()
const result = await loadDocuments(activeCategory.value, {
id: docId,
content: trimmed,
source: options.source ?? options.title,
})
// 成功后写入 Pinia,并持久化到 localStorage
kbStore.addDocument(activeCategory.value, {
id: docId,
chunkCount: result.totalChunks,
charCount: trimmed.length,
indexedAt: new Date().toISOString(),
...
})本地 Store 的角色 :缓存文档 元数据 (篇数、块数、文件名),提升列表展示速度;向量与正文在 PostgreSQL。启动时若本地列表为空,会 getDocuments 从 collection 表的 cmetadata.info 回填。
5.2 后端:分块 + 写入 PGVector
三个域的 loadDocuments 逻辑一致(以 RagFinanceService 为例):
csharp
const splitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
separators: ['\n\n', '\n', '。', '!', '?', ' ', ''],
})
const chunks = await splitter.createDocuments(
[doc.content],
[{ metadata: { source: doc.source || doc.id, docId: doc.id } }],
)
// 更新 collection 级元数据(info 字段供列表展示)
this.pgVectorStoreConfig.collectionMetadata = { ...info: { charCount, chunkCount, ... } }
await PGVectorStore.fromDocuments(allDocs, this.embedder, this.pgVectorStoreConfig)要点说明:
- 中文分隔符 放在
separators前列,尽量按段落、句号切分,减少半句话块; - chunkSize 500 / overlap 50 在召回粒度与上下文长度之间折中;
- 每个 chunk 的
metadata带docId、source,对话检索时可追溯来源; collectionMetadata.info存 文档级 统计,供getDocuments与关键词搜索 JOIN 使用。
连接池在 Service 内单例创建,onModuleDestroy 时 pool.end(),避免 Nest 热重载泄漏连接。
六、检索:对话用语义,搜索页用关键词
6.1 对话 chat:向量相似度检索
javascript
const vectorStore = await PGVectorStore.initialize(this.embedder, {
distanceStrategy: 'cosine',
scoreNormalization: 'similarity',
})
const pairs = await vectorStore.similaritySearchWithScore(message, 5)
const context = fullResults.map((doc) => doc.content).join('\n\n')流程:
- 用 用户整句问题 做 query embedding;
- 取 Top 5 个 chunk 拼成
context; - 若
context为空,直接 SSE 返回固定文案,不调用 LLM; - 否则构造 强约束 system prompt,再
chain.stream写 SSE。
金融域 Prompt 示例(生活域仅人设不同):
markdown
你是一个专业的金融顾问...
规则:
1. 如果没有检索到相关内容,直接回复「知识库中暂无相关内容...」
2. 只根据参考资料内容回答,不能使用资料外的知识
3. 回答简洁准确,使用中文
参考资料:{context}6.2 搜索 search:SQL 模糊匹配 + 规则打分
searchDocuments 没有走向量检索,而是:
vbnet
SELECT embedding.*, collection.cmetadata AS collection_metadata
FROM langchain_pg_embedding_* AS embedding
LEFT JOIN langchain_pg_collection_* AS collection ON ...
WHERE embedding.document ILIKE $1
OR collection.cmetadata -> 'info' ->> 'title' ILIKE $1
OR ...
LIMIT $2再在应用层用正则统计命中次数,映射到 0.55 + hits * 0.15 的 score,排序后返回。
产品含义:
- Search 页更像「在知识库里找文档 / 片段线索」,响应对中文关键词、标题友好;
- Chat 页才是完整 RAG:语义召回 + 生成。
若希望 Search 也做向量检索,可复用 vectorStore.similaritySearchWithScore,或做 混合检索(Hybrid) :向量 Top-K ∪ 关键词 Top-K,再 RRF 融合------这是常见的下一步优化。
6.3 前端 Search API
client/src/api/search.ts 已切到真实接口(get + keyword、topK),与后端 Query 参数对齐。历史上留有 mockSearch 便于无后端演示,与 VITE_MOCK_* 环境变量配合。
七、生成与流式体验:SSE 协议约定
7.1 后端:Nest + Express Response
javascript
res.setHeader('Content-Type', 'text/event-stream')
res.setHeader('Cache-Control', 'no-cache')
res.setHeader('Connection', 'keep-alive')
for await (const chunk of stream) {
res.write(`data: ${JSON.stringify({ text, sessionId })}\n\n`)
}
res.write('data: [DONE]\n\n')
res.end()- 无
sessionId时服务端生成 UUID; - 每个 token 增量放在
text字段; - 结束哨兵为单独一行
data: [DONE]。
7.2 前端:Fetch ReadableStream 解析
streamChatMessage 使用原生 fetch(而非 axios),以便读 response.body:
arduino
buffer += decoder.decode(value, { stream: true })
const events = buffer.split('\n\n')
// 解析 data: {"text","sessionId"} 与 data: [DONE]
options.onChunk(payload.text, fullReply)ChatView.vue 在发送时:
- 先插入 user / 空 assistant 两条消息;
onChunk里chatStore.updateMessage实现打字机效果;buildHistory()取最近 8 条传给后端(当前后端 chain 尚未把 history 接入 Prompt,属于可演进点)。
对话按分类存入 useChatStore + localStorage,与知识库元数据类似,刷新页面不丢会话。
八、API 契约一览
以金融域为例(技术、生活路径仅前缀不同):
| 方法 | 路径 | 作用 |
|---|---|---|
POST |
/rag-finance/loadDocuments |
Body: { documents: { id, content, source? } } |
GET |
/rag-finance/getDocuments |
返回 collection 行,含 cmetadata.info |
GET |
/rag-finance/search?keyword=&topK=5 |
关键词检索 |
POST |
/rag-finance/chat |
Body: { message, sessionId?, history? },响应 SSE |
前端统一通过 VITE_API_BASE 代理到 Nest;请求可带 Authorization: Bearer(与 useAuthStore 集成)。
九、与「教科书 RAG」的对照
| 教科书步骤 | IntellectFlow 实现 | 备注 |
|---|---|---|
| Load | MinerU / 手动文本 → loadDocuments |
支持 PDF 管线 |
| Split | RecursiveCharacterTextSplitter |
中文标点优先 |
| Embed | OllamaEmbeddings |
本地、可换模型 |
| Store | PGVectorStore.fromDocuments |
按域分表 |
| Retrieve | Chat: 向量 Top-5;Search: SQL | 双轨检索 |
| Generate | ChatPromptTemplate + ChatOllama.stream |
强约束 grounded |
| Deliver | SSE + Vue 打字机 | 体验完整 |
十、运行与排错提示
- PostgreSQL 需启用
pgvector扩展,并配置DATABASE_URL; - Ollama 需预先
pull对话模型与 embedding 模型; - 入库后若 Chat 总提示「暂无相关内容」,检查:embedding 模型是否一致、表中是否有数据、问题是否与文档语言/领域匹配;
- Search 无结果但 Chat 有答案:符合「关键词 vs 向量」双轨设计,可尝试换问法或统一检索实现;
- 前端列表为空但库里有数据:看
getDocuments是否返回cmetadata.info,以及 localStorage 是否 stale。
十一、可演进方向(基于现状的诚实清单)
- 抽取 BaseRagService:减少三份重复,保留 per-domain 配置注入;
- Hybrid Search:搜索页走向量或向量+关键词融合;
- 对话多轮 :将
history写入ChatPromptTemplate的MessagesPlaceholder; - 检索结果展示 :Chat 响应可附带
sources(后端已具备fullResults结构基础); - 删除与更新:目前移除文档多作用于本地 Store,向量侧删除需补 API;
- Prompt 人设:确保技术域 system prompt 与「金融顾问」等模板一致(避免复制粘贴遗漏)。
十二、小结
IntellectFlow 的 RAG 不是单一脚本,而是一条 可演示的产品链路:
- 前端用 分类元数据驱动 API,Pinia 缓存文档与会话;
- 后端用 LangChain + PGVector + Ollama 完成切块、嵌入、存储与流式生成;
- 三域分表 保证知识隔离;
- Chat 走向量、Search 走关键词 构成当前最有特色的工程取舍。
如果你正在搭建自己的知识库,建议先跑通「入库 → Chat 向量问答」闭环,再按需把 Search 升级为混合检索,并把多轮历史接到 Prompt------这三步都能在现有代码结构上自然延伸,而无需推翻重来。