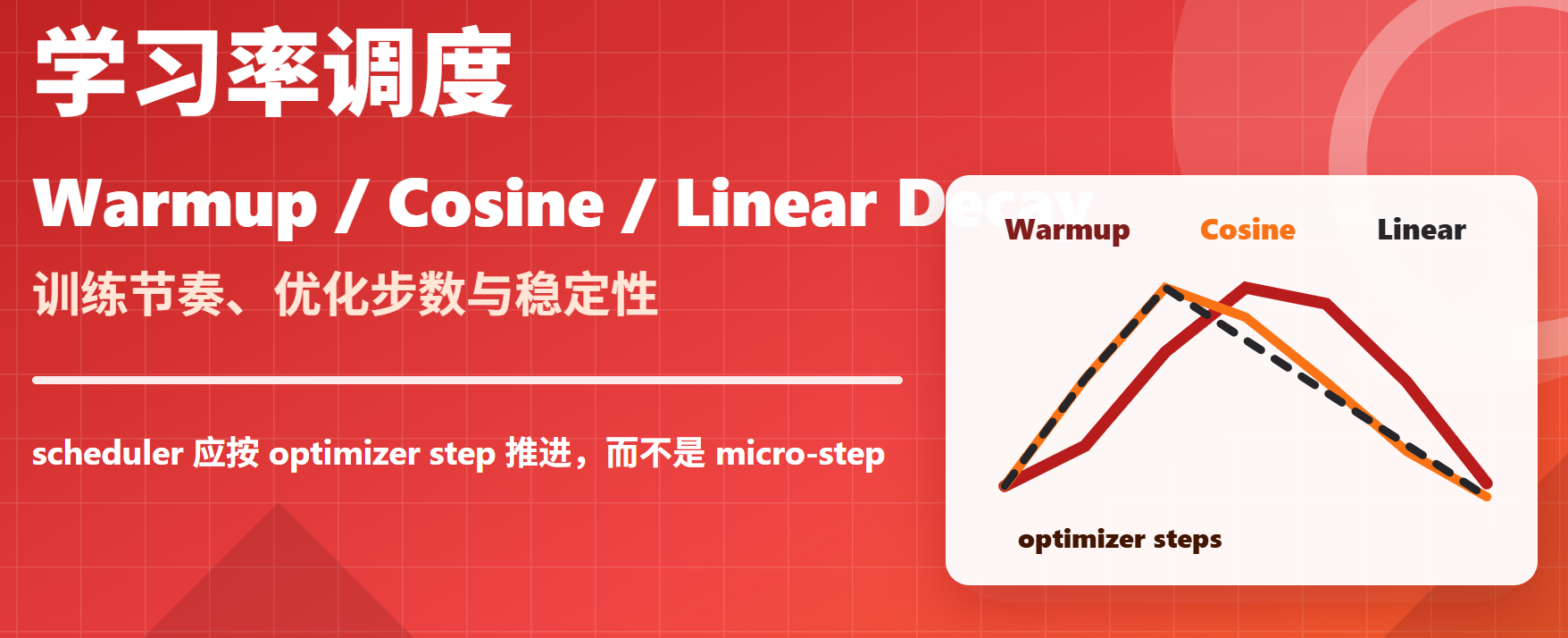
核心结论:学习率调度控制的是"每次参数更新走多远"。Warmup 让优化器和模型在早期稳定进入训练状态,Cosine/Linear/Inverse-Sqrt 决定中后期如何降低更新幅度。调度器应按 optimizer step 推进,而不是按 micro-step、batch iteration 或 token chunk 推进;梯度累积、AMP、DDP/FSDP 都会影响这个计步口径。
第 0 层:30 秒理解
学习率调度要先明确三个 step:
text
micro-step: 一个 micro-batch 的 forward/backward
optimizer step: 真正更新一次权重
scheduler step: 通常应跟随 optimizer step最常见的大模型调度:
text
linear warmup -> cosine decay最常见的 BERT/Transformers 微调调度:
text
short warmup -> linear decay 或 cosine decay核心公式:
text
lr(step) = peak_lr × schedule_factor(optimizer_step / total_optimizer_steps)注意这里的 step 是 optimizer step,不是 dataloader 迭代次数;如果 gradient_accumulation_steps=8,那么 8 个 micro-step 才推进 1 个 optimizer step。
第 1 层:Warmup、Cosine、Linear 的基础
1. Warmup:缓启动而不是玄学

Warmup 的目标是让训练早期从较小学习率逐步升到 peak LR。它常见于:
text
大模型预训练
AdamW / Adafactor 等自适应优化器
大批次训练
混合精度训练
深层残差网络和 TransformerWarmup 不只是为了"初始梯度大"。更完整的原因包括:
| 原因 | 说明 |
|---|---|
| Adam 早期估计不稳 | 一阶/二阶矩估计刚开始还不可靠 |
| 大批次训练 | 使用更大 peak LR 时,需要逐步拉升 |
| 残差流和归一化 | 深层模型早期激活尺度仍在调整 |
| 混合精度 | 早期大更新更容易触发 overflow 或 NaN |
线性 warmup 足够常用:
python
def linear_warmup_factor(step: int, warmup_steps: int) -> float:
if warmup_steps <= 0:
return 1.0
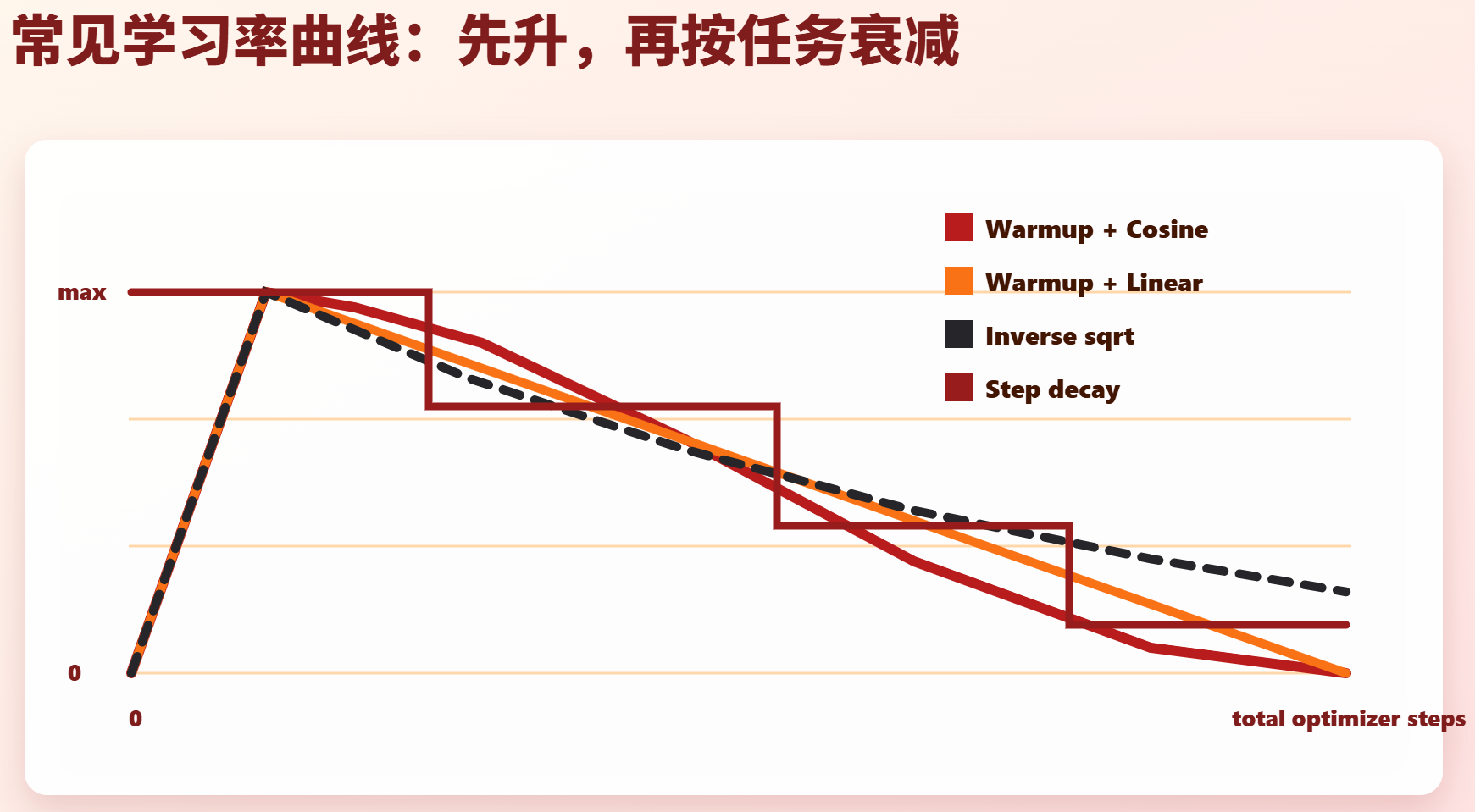
return min(1.0, step / warmup_steps)2. Cosine Decay:两头慢,中间快
Cosine decay 的标准形式:
text
lr = min_lr + 0.5 × (peak_lr - min_lr) × (1 + cos(pi × progress))其中:
text
progress = decay_step / decay_total_steps特点:
text
开始:斜率接近 0,学习率平滑离开 peak LR
中间:下降最快
末尾:斜率接近 0,平滑靠近 min_lr实现:
python
import math
def cosine_decay_factor(step: int, total_steps: int, min_factor: float = 0.0) -> float:
if total_steps <= 0:
return min_factor
progress = min(1.0, max(0.0, step / total_steps))
cosine = 0.5 * (1.0 + math.cos(math.pi * progress))
return min_factor + (1.0 - min_factor) * cosine3. Linear Decay:简单、可控、微调常用
Linear decay 从 peak LR 线性降到 min LR:
python
def linear_decay_factor(step: int, total_steps: int, min_factor: float = 0.0) -> float:
if total_steps <= 0:
return min_factor
progress = min(1.0, max(0.0, step / total_steps))
return max(min_factor, 1.0 - progress)它的优点是简单,常用于 BERT 风格微调;缺点是末端斜率不如 cosine 平滑,训练后期可能更早进入很小 LR 区间。
4. 还应补充 Inverse-Sqrt、OneCycle、Step Decay
原稿只讲 Warmup/Cosine/Linear 不够完整。常见补充:
| 方法 | 常见场景 |
|---|---|
| inverse square root | Transformer 原论文、T5/Adafactor 一类训练风格 |
| step decay | 经典 CNN/ResNet 训练仍常见 |
| OneCycle | 视觉训练、小中型网络、快速收敛实验 |
| cosine with restarts | SGDR、小中型任务;LLM 预训练不常默认重启 |
第 2 层:组合调度与正确代码
1. Warmup + Cosine
python
import math
def warmup_cosine_lr(
step: int,
total_steps: int,
peak_lr: float,
warmup_steps: int,
min_lr: float = 0.0,
) -> float:
if step < warmup_steps:
return peak_lr * step / max(1, warmup_steps)
decay_steps = max(1, total_steps - warmup_steps)
decay_step = min(step - warmup_steps, decay_steps)
progress = decay_step / decay_steps
cosine = 0.5 * (1.0 + math.cos(math.pi * progress))
return min_lr + (peak_lr - min_lr) * cosine2. Warmup + Linear
python
def warmup_linear_lr(
step: int,
total_steps: int,
peak_lr: float,
warmup_steps: int,
min_lr: float = 0.0,
) -> float:
if step < warmup_steps:
return peak_lr * step / max(1, warmup_steps)
decay_steps = max(1, total_steps - warmup_steps)
decay_step = min(step - warmup_steps, decay_steps)
progress = decay_step / decay_steps
factor = 1.0 - progress
return max(min_lr, peak_lr * factor)3. PyTorch LambdaLR 写法
PyTorch 的 LambdaLR 返回的是相对初始 LR 的倍率,因此 optimizer 里的 lr 应设置为 peak LR。
python
from torch.optim.lr_scheduler import LambdaLR
optimizer = torch.optim.AdamW(model.parameters(), lr=peak_lr, weight_decay=0.1)
def lr_lambda(step: int) -> float:
if step < warmup_steps:
return step / max(1, warmup_steps)
decay_steps = max(1, total_steps - warmup_steps)
decay_step = min(step - warmup_steps, decay_steps)
progress = decay_step / decay_steps
min_factor = min_lr / peak_lr
return min_factor + (1.0 - min_factor) * 0.5 * (1.0 + math.cos(math.pi * progress))
scheduler = LambdaLR(optimizer, lr_lambda=lr_lambda)训练循环:
python
for batch in train_loader:
loss = training_step(batch)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad(set_to_none=True)4. Hugging Face Transformers 写法
Transformers 已内置常见 schedule:
python
from transformers import get_cosine_schedule_with_warmup
optimizer = torch.optim.AdamW(model.parameters(), lr=peak_lr)
scheduler = get_cosine_schedule_with_warmup(
optimizer,
num_warmup_steps=warmup_steps,
num_training_steps=total_optimizer_steps,
)如果你用 Trainer,需要确认:
text
max_steps / num_train_epochs
gradient_accumulation_steps
warmup_steps / warmup_ratio
lr_scheduler_typenum_training_steps 应该是 optimizer step 数,不是 micro-batch 数。
第 3 层:梯度累积、AMP 与调度器
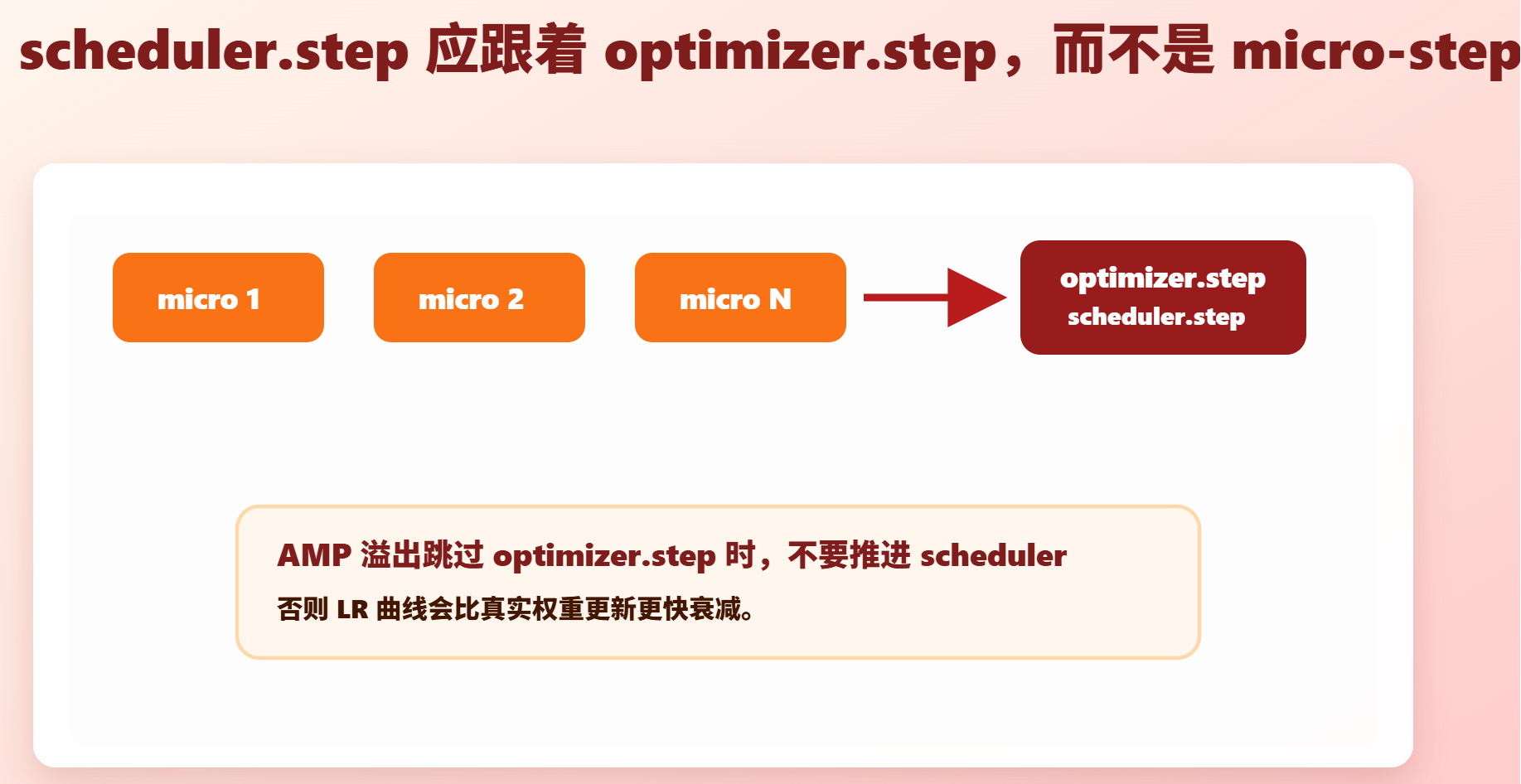
1. 梯度累积下只在 optimizer step 后调度
错误写法:
text
每个 micro-batch 后 scheduler.step()正确写法:
python
optimizer.zero_grad(set_to_none=True)
global_step = 0
for micro_step, batch in enumerate(train_loader):
loss = training_step(batch) / gradient_accumulation_steps
loss.backward()
if (micro_step + 1) % gradient_accumulation_steps == 0:
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
optimizer.zero_grad(set_to_none=True)
global_step += 1学习率 warmup、decay、logging、checkpoint 间隔都应该对齐 global_step。
2. AMP overflow 时不要错误推进 scheduler
如果 FP16 AMP 发生 overflow,scaler.step(optimizer) 可能跳过真正的参数更新。此时继续 scheduler.step() 会让学习率曲线和真实更新次数错位。
一种常见处理方式:
python
from torch.amp import GradScaler, autocast
scaler = GradScaler("cuda")
for batch in train_loader:
optimizer.zero_grad(set_to_none=True)
with autocast(device_type="cuda", dtype=torch.float16):
loss = training_step(batch)
scaler.scale(loss).backward()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
old_scale = scaler.get_scale()
scaler.step(optimizer)
scaler.update()
new_scale = scaler.get_scale()
optimizer_was_skipped = new_scale < old_scale
if not optimizer_was_skipped:
scheduler.step()BF16 通常不需要 GradScaler,但仍应遵守"optimizer step 后再 scheduler step"。
第 4 层:Batch Size 与学习率
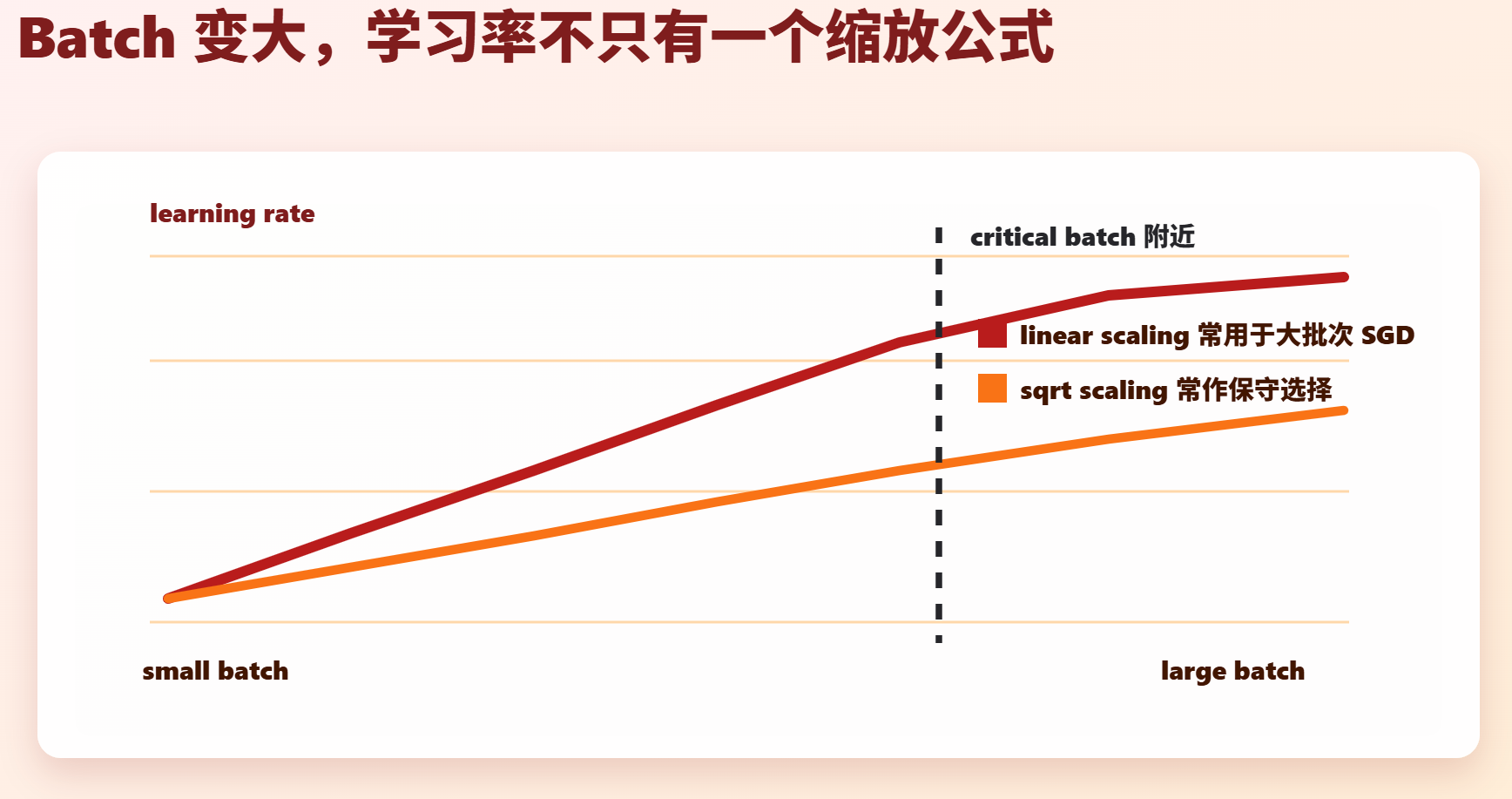
1. Linear Scaling 与 Sqrt Scaling
当 batch size 变大时,常见经验有两类:
text
linear scaling: lr_new = lr_old × (B_new / B_old)
sqrt scaling: lr_new = lr_old × sqrt(B_new / B_old)如何选择:
| 场景 | 常见选择 |
|---|---|
| 大批次 SGD 训练 CNN | linear scaling + warmup |
| AdamW 训练 LLM | 更保守,常不严格线性放大 |
| 微调任务 | 通常重新搜索 peak LR,不机械套公式 |
| batch 接近 critical batch | 继续放大 batch 和 LR 的收益下降 |
所以原稿里"学习率应与批次大小成 sqrt(B) 正比"需要改成:
text
batch size 变化后需要重新校准 LR。
SGD 大批次常用 linear scaling;Adam/LLM 场景常更保守。2. Warmup 与大 batch
大 batch 常配合更长 warmup,因为:
text
peak LR 通常更大
梯度噪声更低,早期探索变少
优化器状态需要时间稳定但 warmup 不是越长越好。过长 warmup 会让大量训练预算停留在低 LR,导致欠训练。
实用范围:
| 训练类型 | warmup 建议 |
|---|---|
| LLM 预训练 | 固定 1k-10k steps 或 0.1%-3% 总 optimizer steps |
| BERT/分类微调 | 0%-10%,常见 3%-10% |
| 小数据微调 | 0-几百 optimizer steps |
| 大批次 ImageNet | 几个 epoch 的 warmup 常见 |
具体比例需要按总训练步数看。总步数很短时,10% warmup 可能已经太长。
第 5 层:策略选择
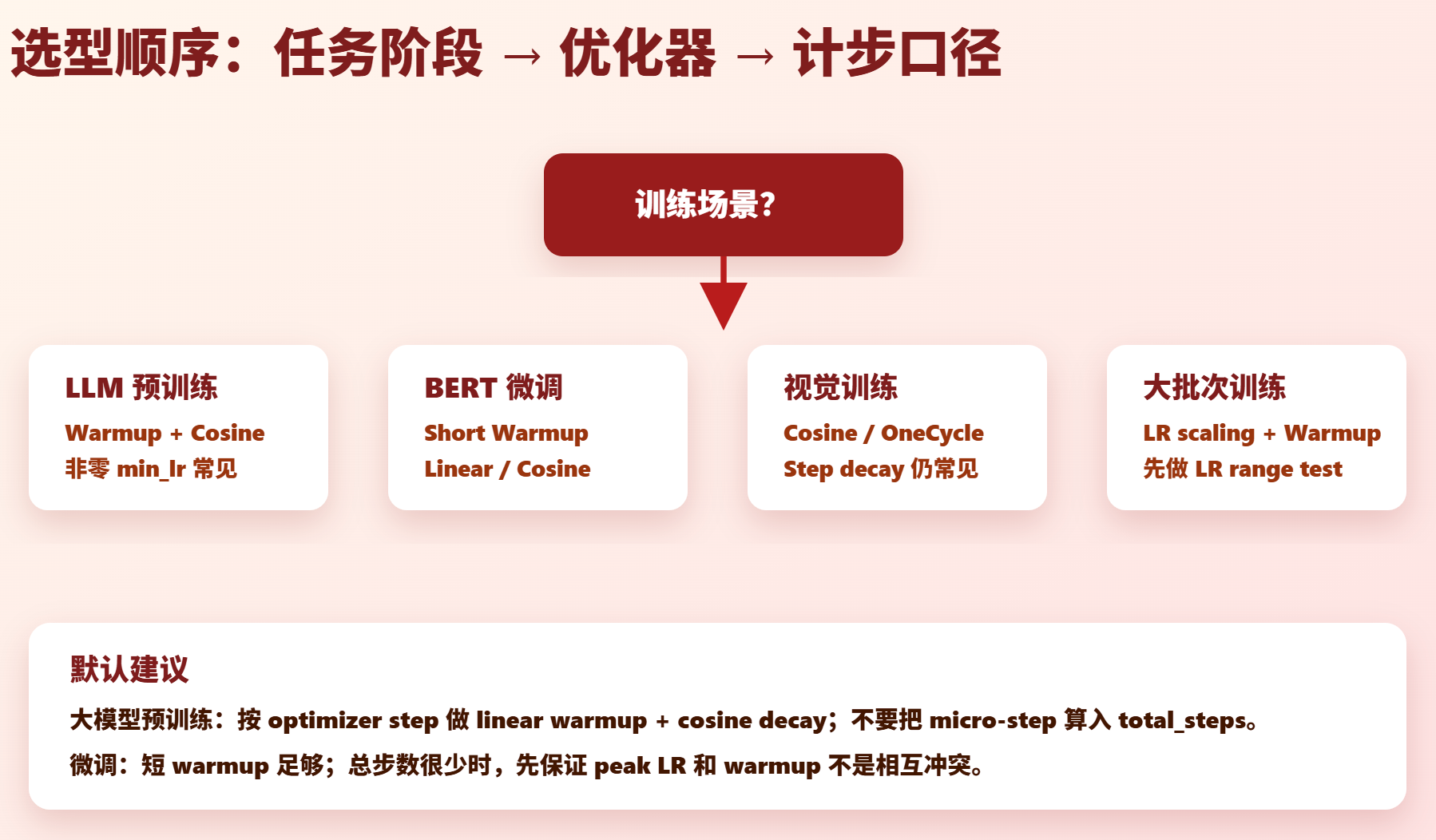
| 场景 | 推荐起点 | 备注 |
|---|---|---|
| LLM 预训练 | linear warmup + cosine decay | 常用非零 min_lr,例如 peak 的 1%-10% |
| LLM SFT / 指令微调 | short warmup + cosine 或 linear | 总步数短,重点搜索 peak LR |
| BERT 风格微调 | warmup + linear | Transformers 生态常见默认 |
| 视觉模型从头训练 | cosine / step decay / OneCycle | step decay 仍有大量成熟 recipe |
| 大批次 SGD | LR scaling + warmup + cosine/step | 不要只改 batch,不改 warmup |
| Adafactor / T5 风格 | warmup + inverse sqrt / relative step | 遵循模型原 recipe |
| 继续预训练 | 可重新 warmup,也可从较低 LR 接续 | 取决于数据分布变化和 checkpoint 状态 |
默认推荐
如果没有强 recipe,先用:
text
AdamW
peak_lr: 通过 LR range test 或小规模网格搜索
warmup_ratio: 1%-3% for pretrain, 0%-10% for finetune
schedule: cosine
min_lr: 0%-10% peak_lr
scheduler step: optimizer step第 6 层:常见问题排查
| 症状 | 常见原因 | 修正 |
|---|---|---|
| 前几百步 loss 爆炸 | peak LR 太大、warmup 太短、AMP overflow | 降低 peak LR,延长 warmup,检查梯度裁剪 |
| 训练很慢 | peak LR 太小、warmup 太长 | 做 LR range test,缩短 warmup |
| 后期 loss 还在快速下降 | decay 太快或训练预算不够 | 提高 min_lr,延长训练,改 cosine |
| 后期震荡 | min_lr 太高或 batch 太小 | 降低 min_lr,增大 batch/accumulation |
| 梯度累积后效果变差 | scheduler 按 micro-step 推进 | 改为 optimizer step 后推进 |
| AMP 训练 LR 曲线错位 | overflow 跳过 optimizer step 但 scheduler 仍 step | 只在 optimizer step 未跳过时 scheduler.step |
| 微调过拟合 | LR 太大、decay 太慢、warmup 占比不合适 | 降 LR,缩短训练,增加 regularization |
| 大 batch 不收敛 | LR scaling 过激、warmup 不够 | 用更保守 scaling,延长 warmup |
参考资料
- PyTorch learning rate scheduler 文档:https://docs.pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate
- PyTorch
LambdaLR文档:https://docs.pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.LambdaLR.html - Hugging Face Transformers optimization schedules:https://huggingface.co/docs/transformers/main_classes/optimizer_schedules
- Loshchilov & Hutter, SGDR: Stochastic Gradient Descent with Warm Restarts:https://arxiv.org/abs/1608.03983
- Goyal et al., Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour:https://arxiv.org/abs/1706.02677
- Liu et al., On the Variance of the Adaptive Learning Rate and Beyond / RAdam:https://arxiv.org/abs/1908.03265
- Xiong et al., On Layer Normalization in the Transformer Architecture:https://arxiv.org/abs/2002.04745
- Raffel et al., Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer / T5:https://arxiv.org/abs/1910.10683