这是视觉定位与建图领域首个全面覆盖深度学习方法的权威综述 ,系统梳理了数据驱动方案如何替代传统几何 / 物理建模,回答两大核心问题:深度学习是否适用于定位建图 、如何应用深度学习,并构建统一分类框架。
一、核心定位与背景
- 研究价值 传统 SLAM / 视觉定位依赖人工设计特征(SIFT、ORB)与几何约束,对光照、动态、低纹理场景鲁棒性差;深度学习以数据驱动方式自动提取特征,适配复杂环境,成为下一代空间感知核心方向。
- 覆盖范围 视觉里程计(VO)、全局重定位、建图、回环检测与 SLAM 后端,跨机器人、CV、机器学习三大学科。
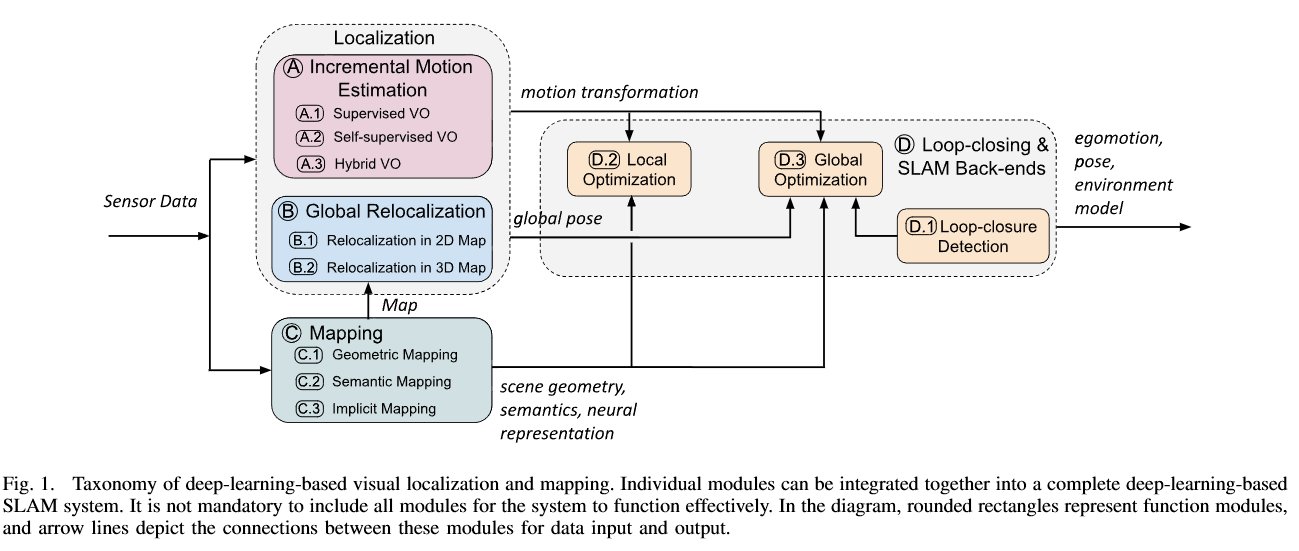
二、整体分类框架(四大模块)
1. 增量运动估计(视觉里程计 VO)
- 核心目标:连续估计相机位姿变换,重建全局轨迹。
- 三类方法
- 有监督 VO:DeepVO(CNN+RNN)、DAVO(注意力机制),需真值位姿,精度高但标注成本大。
- 自监督 VO:SfmLearner、UnDeepVO、GeoNet,以视图合成 / 光度损失为监督,无需标注,泛化性强;解决单目尺度模糊、动态物体干扰问题。
- 混合 VO:D3VO、CNN-SVO,融合深度学习深度 / 不确定性预测与传统几何 VO,精度超越纯学习 / 纯几何方法。
2. 全局重定位
- 核心目标:在已知地图中获取相机绝对位姿,用于追踪丢失恢复、漂移修正。
- 两类地图
- 2D 地图重定位
- 显式:图像检索 + 相对位姿回归(RelocNet、CamNet)。
- 隐式:端到端 6DoF 回归(PoseNet 系列、AtLoc、MS-Transformer)。
- 3D 地图重定位
- 局部描述子匹配:SuperPoint、D2-Net、HF-Net,建立 2D-3D 对应。
- 场景坐标回归:DSAC/*、DSAC++、KFNet,可微 RANSAC 优化,端到端求解位姿。
- 2D 地图重定位
3. 建图
- 几何建图:深度估计、点云、网格、体素、隐式曲面(DeepSDF、NeRF)。
- 语义建图:SemanticFusion、PanopticFusion,融合语义分割与 3D 地图,支持高层理解。
- 隐式建图:CodeSLAM、iMAP、NICE-SLAM,用神经网络编码场景,紧凑且可优化。
4. 回环检测与 SLAM 后端
- 回环检测:BoW→CNN 特征→NetVLAD,基于深度特征提升视角 / 光照鲁棒性。
- 局部优化:BA-Net、LS-Net,可微光束平差,在特征空间优化。
- 全局优化:图优化 + 深度学习预测,修正累积漂移,保证系统一致性。
三、关键结论
- 深度学习的三大优势
- 自动提取鲁棒特征,适配弱纹理、光照变化、动态环境。
- 实现语义 - 几何融合,支撑高层机器人任务。
- 自监督 / 在线学习,可自适应新场景,降低部署成本。
- 应用范式
- 作为通用拟合器:端到端位姿回归。
- 解决数据关联:重定位、回环、语义标注。
- 特征学习与几何先验结合:混合架构最优。
- 自监督训练:从无标注视频学习几何。
- 现存局限
- 大模型算力需求高,移动端部署受限。
- 泛化性与可解释性不足,安全性待验证。
- 动态场景、极端光照仍有挑战。