它是专门用来存储和检索高维向量的数据库,核心能力是做近似最近邻搜索(也就是 ANN) 。
简单来说,它能在百万甚至亿级的向量里,毫秒级地找出最相似的几条。像现在 RAG 架构里"检索"这一步,底层就是靠向量数据库撑着的。
【对比传统数据库】
可能有人会觉得,在 MySQL 或者 ES 里加个向量字段也能存向量,为什么还要专门的数据库?其实这有本质区别:
MySQL 擅长的是精确匹配 ,比如 WHERE id = 123,底层靠 B-tree 索引,在一维有序数据上效率极高。但是向量检索是要找"最相近"的,高维空间里的距离是多个维度综合计算的,B-tree 根本无法工作。
ES 也是同理 ,它加的 dense_vector 只是个补丁,数据量一大,性能根本扛不住。所以,传统数据库解决的是"等于"的问题,向量数据库解决的是"相似"的问题,两者不能互相替代。
【索引算法】
向量数据库之所以能做到毫秒级检索,秘密全在索引算法上。目前主流的就是 HNSW 和 IVF 两种:
-
HNSW 是图结构 。你可以想象成在地图上找餐厅,先在全国层找大方向,再一层层缩小到省、市、区。它这种分层导航的方式,能跳过99%的无关节点,优点是召回率极高、速度快,缺点是比较吃内存 。像 Qdrant、Milvus 默认用的就是这个。
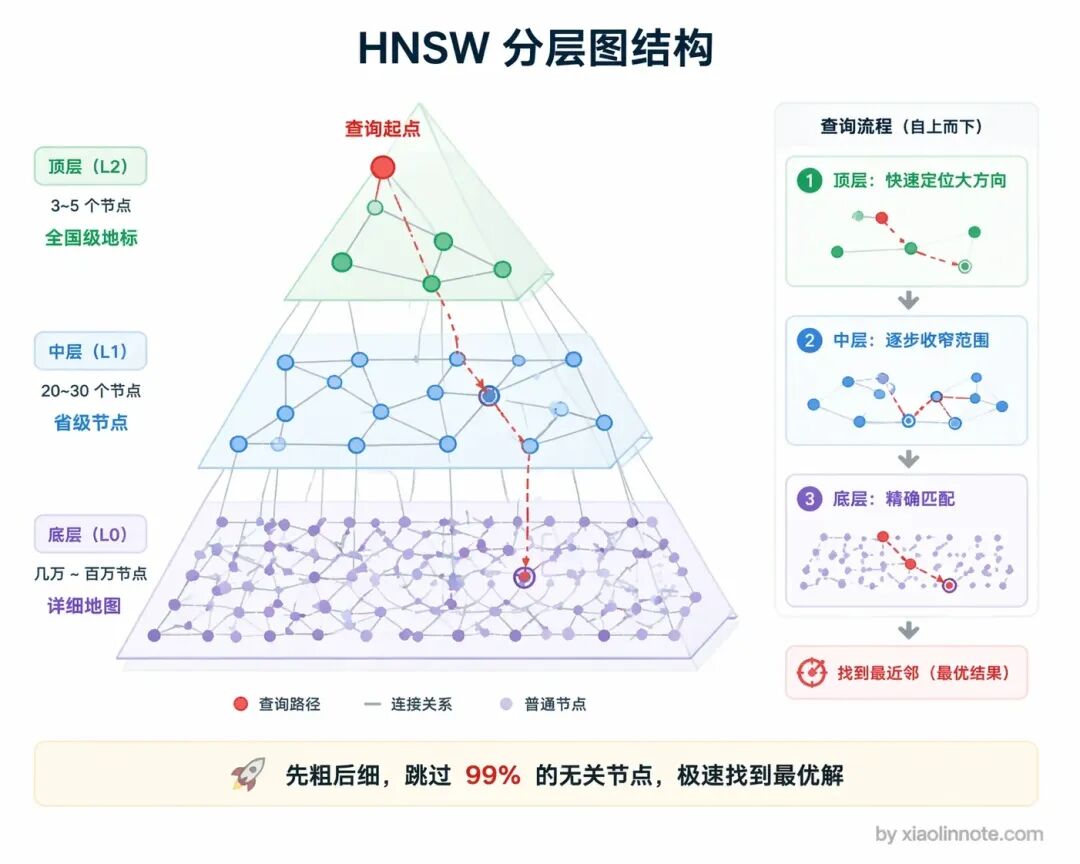
-
IVF 是桶结构 。它先对向量做聚类分桶,检索时只搜最相关的几个桶,就像在图书馆先找"计算机区"再找书。优点是内存占用小、适合超大规模,缺点是精度略低、需要调参 。
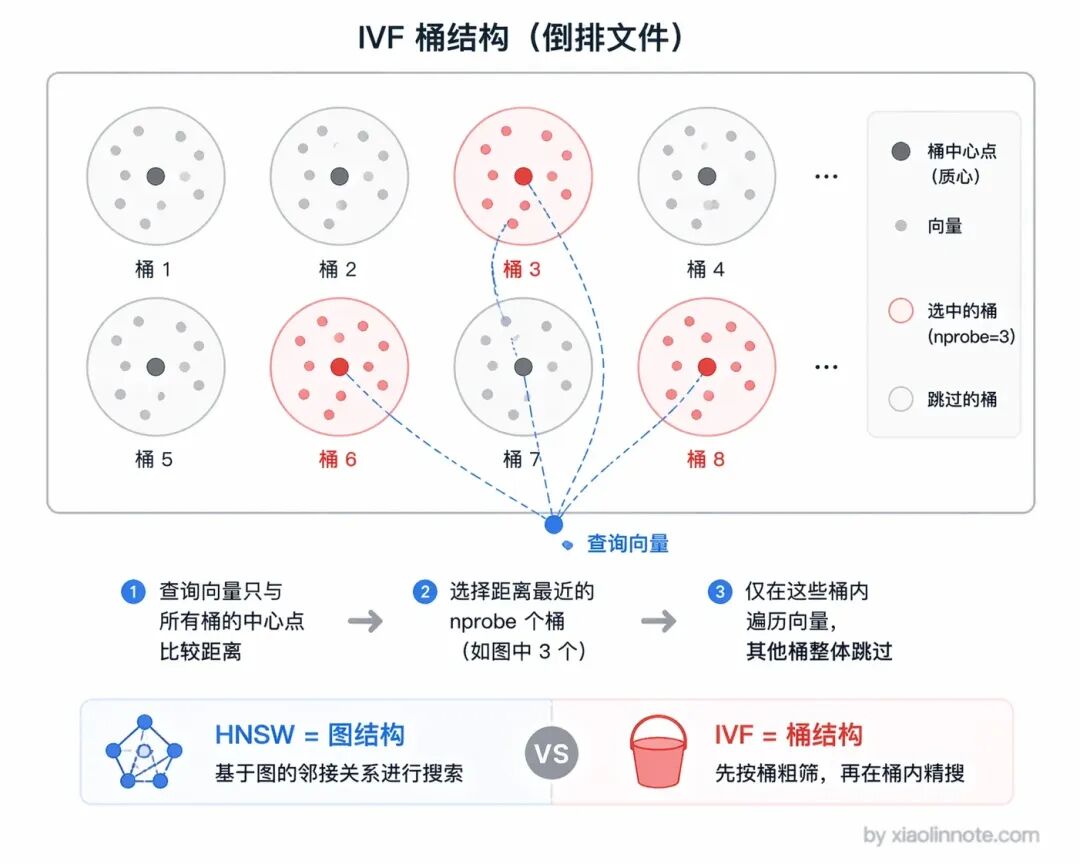
简单说,HNSW 用内存换精度,IVF 用精度换内存,两者适用场景不同。
当然,光有 ANN 搜索还不够,生产级的向量数据库还必须具备三个关键能力:
-
Metadata 过滤(先过滤再搜) :业务上往往只想搜"技术部2024年的文档",如果不先过滤,搜出来的 Top-K 可能全不满足条件,浪费名额。所以必须是先按 metadata 过滤,再在子集里做 ANN 搜索。
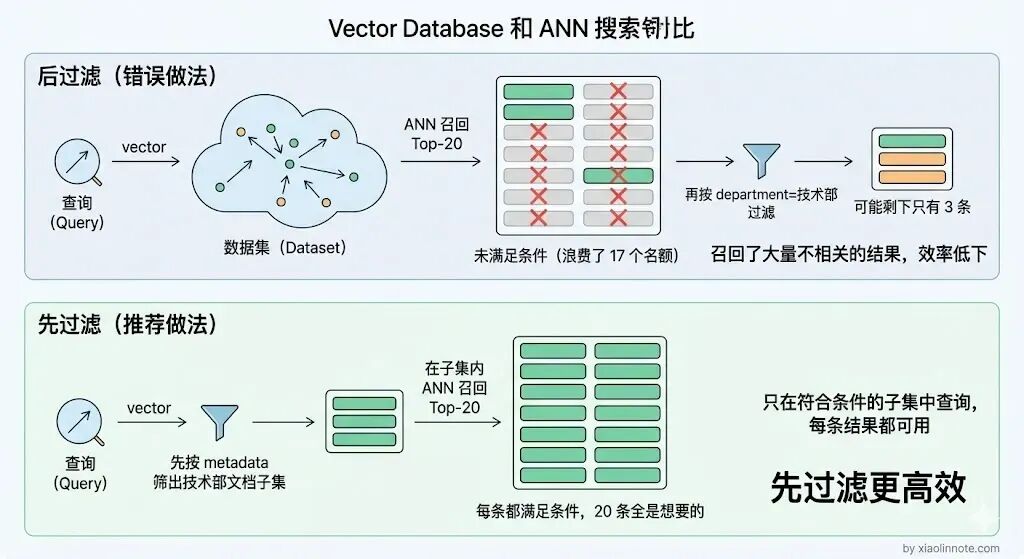
-
实时增量更新:知识库频繁变更,向量数据库必须支持在线写入和增量构建索引,不能一改数据就停服重建。
-
混合检索:纯向量检索对专有名词(比如产品型号 GPT-4o)效果不好,需要结合 BM25 关键词检索做混合召回,效果才最佳。
【落地选型】
主要看数据规模、部署方式和是否需要混合检索这三个维度:
- 如果是本地快速原型验证 ,用 Chroma,零配置上手极快;
- 如果是中小到大规模的生产环境 ,我推荐 Qdrant,Rust 写的性能很稳,API 简洁,现在也支持分布式,亿级数据也能扛,很多团队是从 Chroma 起步然后切到 Qdrant 上生产;
- 如果是千万到亿级的超大规模 ,需要水平扩展,选 Milvus,国内大厂都在用,但运维复杂度高,需要专门的人力维护;
- 如果不想运维 ,用 Pinecone 这种全托管 SaaS,不过要注意数据出境的合规问题;
- 如果项目里已经有 PG ,数据量又不大,直接用 pgvector 插件就够了,运维成本为零。