你好,我是南一,我做了一个前端知识库,下方是其中一篇文章。
性能优化不是技巧清单
性能优化很容易被写成一串 checklist:开 gzip、上 CDN、压缩图片、代码分割、懒加载、防抖节流。它们都对,但如果没有方法论,真实项目里会遇到两个问题:
- 不知道先做哪个:优化点很多,但人力有限,不能平均用力。
- 不知道有没有效果:改了一堆配置,指标没有变化,甚至引入回归。
更靠谱的性能优化流程是:先度量,再定位,再优化,最后验证。
text
设定目标
-> 采集指标
-> 定位瓶颈
-> 制定方案
-> 小步上线
-> 验证收益
-> 建立防回归机制第一步:先定义性能目标
没有目标的优化很容易变成"哪里都想改"。目标应该和用户体验、业务场景、技术指标绑定。
常见目标有三类:
| 目标类型 | 示例 | 对应指标 |
|---|---|---|
| 加载体验 | 首屏主内容 2.5s 内出现 | LCP、FCP、TTFB |
| 交互体验 | 点击、输入、筛选不卡顿 | INP、TBT、Long Task |
| 稳定体验 | 页面加载不乱跳 | CLS |
例如"首页要快"太模糊,可以改成:
首页在移动端 4G 网络下,P75 LCP 小于 2.5s,CLS 小于 0.1。
这个目标有四个关键信息:页面、环境、分位数、指标阈值。后续优化和验收都有依据。
第二步:用数据定位瓶颈
性能问题不能只靠猜。常用数据来源有两种:实验室数据和线上真实数据。
实验室数据:适合复现和调试
实验室数据来自受控环境,常见工具包括:
- Lighthouse:快速发现 LCP、TBT、CLS、资源体积等问题。
- Chrome DevTools Performance:定位长任务、重排、重绘、脚本执行耗时。
- Network 面板:查看资源瀑布流、缓存、优先级、阻塞时间。
- WebPageTest:模拟不同地域、网络和设备环境。
实验室数据的优势是可重复,适合开发阶段调试。缺点是它不一定代表真实用户。
线上数据:决定优化优先级
线上真实用户监控通常叫 RUM。它能回答:到底有多少用户被影响?影响集中在哪些设备、网络、地域、页面?
可以通过 web-vitals 上报核心指标:
js
import { onCLS, onINP, onLCP, onTTFB } from 'web-vitals'
function report(metric) {
navigator.sendBeacon('/api/perf', JSON.stringify({
name: metric.name,
value: metric.value,
rating: metric.rating,
path: location.pathname,
}))
}
onLCP(report)
onINP(report)
onCLS(report)
onTTFB(report)线上数据建议看 P75 或 P95,而不是只看平均值。性能问题经常出现在低端机、弱网和长尾用户里,平均值会掩盖问题。
第三步:按关键路径拆解问题
前端页面从请求到可交互,大致经过这条链路:
text
网络连接
-> HTML 返回
-> CSS/JS/图片等资源加载
-> HTML/CSS 解析
-> JS 执行
-> 渲染与绘制
-> 用户交互响应性能优化可以围绕这条链路逐段分析。
网络链路优化:让资源更快到达
网络层的核心目标是:更少的请求、更小的体积、更近的访问路径、更合理的优先级。
减少连接和传输成本
常见手段:
- 使用 CDN,让静态资源就近访问。
- 启用 HTTP/2 或 HTTP/3,减少连接阻塞。
- 开启 Gzip 或 Brotli 压缩文本资源。
- 减少重定向,避免多余往返。
- 静态资源使用独立域名时,谨慎控制域名数量。
示例:对文本资源开启 Brotli 或 Gzip 后,HTML、CSS、JS 传输体积通常会明显下降。
nginx
brotli on;
brotli_types text/plain text/css application/javascript application/json image/svg+xml;
gzip on;
gzip_types text/plain text/css application/javascript application/json image/svg+xml;压缩不是越强越好。压缩等级越高,服务端 CPU 成本越大。静态资源可以在构建阶段预压缩,动态接口则要权衡 CPU 和带宽。
使用缓存减少重复请求
缓存优化的原则是:内容不变时尽量不请求,内容变更时必须能更新。
静态资源常用策略:
http
Cache-Control: public, max-age=31536000, immutable前提是文件名带内容 hash:
text
app.8f3a1c.js
style.6d9b2e.cssHTML 通常不能设置太长强缓存,因为它负责引用最新资源。更常见的是短缓存或协商缓存。
| 资源 | 推荐策略 |
|---|---|
| HTML | 短缓存或协商缓存 |
| 带 hash 的 JS/CSS | 长强缓存 |
| 图片、字体 | 长缓存,变更时换 URL |
| 接口数据 | 根据业务时效性设置缓存 |
合理使用预加载
浏览器资源调度有优先级。关键资源如果发现得太晚,会拖慢 LCP。
html
<link rel="preconnect" href="https://cdn.example.com" />
<link rel="preload" href="/hero.webp" as="image" />
<img src="/hero.webp" fetchpriority="high" width="1200" height="630" alt="主视觉" />常见规则:
preconnect:提前建立跨域连接,适合关键 CDN、字体域名。preload:提前加载当前页面必需的关键资源。prefetch:空闲时加载未来可能访问的资源。
不要滥用 preload。预加载太多会抢占带宽,反而影响真正关键的资源。
资源体积优化:让浏览器少下载、少解析
资源体积不只影响下载时间,也影响解析和执行时间。JS 体积大时,低端机上的解析执行成本会非常明显。
代码分割和按需加载
SPA 项目最常见的问题是首屏包过大。解决思路是:首屏只加载当前页面必需代码,其他页面和组件延后加载。
js
const SettingsPage = lazy(() => import('./pages/SettingsPage'))常见拆分维度:
- 按路由拆分。
- 按大型组件拆分,例如图表、编辑器、地图。
- 按第三方库拆分。
- 管理端和用户端分包。
拆包不是越碎越好。拆得太碎会增加请求数量和调度成本,也可能造成用户交互时才开始加载关键组件。需要结合访问路径和缓存命中率判断。
Tree Shaking 和依赖治理
Tree Shaking 可以移除未使用代码,但它依赖模块写法和构建配置。
常见注意点:
- 优先使用 ESM 版本依赖。
- 避免整包引入大型工具库。
- 检查依赖是否有副作用声明。
- 使用 bundle analyzer 分析产物。
js
// 不推荐:可能引入整个库
import _ from 'lodash'
// 推荐:只引入需要的方法
import debounce from 'lodash/debounce'依赖治理很重要。一个页面引入图表库、富文本编辑器、日期库、多语言包后,包体积会快速膨胀。优化前要先用分析工具确认最大的依赖是谁。
图片和字体优化
图片经常是 LCP 的最大来源。
优化方向:
- 使用 WebP、AVIF 等现代格式。
- 按展示尺寸裁剪图片,不传超大原图。
- 首屏图片提高优先级,非首屏图片懒加载。
- 给图片设置
width、height或aspect-ratio,减少 CLS。
html
<img
src="/cover-800.webp"
srcset="/cover-400.webp 400w, /cover-800.webp 800w, /cover-1200.webp 1200w"
sizes="(max-width: 768px) 100vw, 800px"
width="800"
height="450"
loading="lazy"
alt="文章封面"
/>字体优化也会影响 LCP 和 CLS:
css
@font-face {
font-family: "Inter";
src: url("/fonts/inter.woff2") format("woff2");
font-display: swap;
}font-display: swap 可以避免长时间不可见文本,但可能带来字体切换。要结合视觉稳定性一起看。
渲染链路优化:减少阻塞和布局抖动
浏览器渲染大致经历:样式计算、布局、绘制、合成。频繁触发布局和绘制,会带来卡顿。
减少重排和重绘
容易触发布局计算的操作包括读取和修改几何属性:
js
// 不推荐:读写交错,容易强制同步布局
for (const item of items) {
const height = item.offsetHeight
item.style.height = `${height + 10}px`
}更好的方式是批量读、批量写:
js
const heights = items.map((item) => item.offsetHeight)
items.forEach((item, index) => {
item.style.height = `${heights[index] + 10}px`
})样式修改优先通过 class 批量完成,而不是逐个写内联样式。
使用合成友好的动画
动画优先使用 transform 和 opacity,避免频繁改变 top、left、width、height。
css
.panel {
transform: translateY(0);
transition: transform 200ms ease;
}
.panel.hidden {
transform: translateY(100%);
}will-change 可以提示浏览器提前优化,但不要长期、大量使用。它可能增加内存占用。
控制 DOM 规模
DOM 过大会增加样式计算和布局成本。后台表格、长列表、树形结构是重灾区。
常见方案:
- 长列表使用虚拟滚动。
- 大树组件按需展开和渲染。
- 分页替代一次性渲染全部数据。
- 避免隐藏状态下仍然渲染大量复杂节点。
主线程优化:让交互及时响应
JavaScript 执行、样式计算、布局和绘制大多发生在主线程。主线程被长任务占用时,用户点击和输入就会延迟。
拆分长任务
如果一个任务执行超过 50ms,就可能成为 Long Task。可以把大任务切成小块,让浏览器有机会处理输入和绘制。
js
async function processLargeList(list) {
const chunkSize = 500
for (let i = 0; i < list.length; i += chunkSize) {
const chunk = list.slice(i, i + chunkSize)
processChunk(chunk)
await new Promise((resolve) => setTimeout(resolve, 0))
}
}对于复杂计算,优先考虑 Web Worker:
js
const worker = new Worker('/worker.js')
worker.postMessage({ type: 'sort', payload: bigList })
worker.onmessage = (event) => {
render(event.data)
}减少无效渲染
在 React、Vue 等框架中,性能问题经常来自无意义的组件更新。
优化思路:
- 状态尽量下沉,减少父组件更新影响范围。
- 列表项使用稳定的 key。
- 对昂贵计算做缓存。
- 大组件拆分,避免单次渲染过重。
- 高频输入不要每次都触发全量计算。
不要盲目加 memo 或缓存。缓存本身也有成本,应该针对已经定位出的热点使用。
第三方脚本治理
统计、客服、广告、AB 实验、监控 SDK 都可能影响主线程和网络资源。
治理方式:
- 非关键脚本延迟加载。
- 使用
async或defer。 - 对第三方脚本设置超时和降级。
- 定期评估 SDK 体积和执行成本。
- 核心路径避免同步初始化过多 SDK。
第三方脚本的风险在于不可控。上线前要在弱网和低端机上验证,不要只在高性能开发机上测试。
建立优化优先级
不是所有问题都值得马上优化。优先级可以按三个维度判断:
| 维度 | 问题 |
|---|---|
| 用户影响 | 影响多少用户,是否集中在核心页面 |
| 收益空间 | 指标距离目标差多少,是否命中关键路径 |
| 实施成本 | 改动范围、风险、回滚难度 |
可以使用一个简单排序:
- 核心页面、P75 指标明显不达标的问题。
- 影响 LCP、INP、CLS 的关键路径问题。
- 成本低、收益确定的配置类优化。
- 架构级优化,例如 SSR、微前端拆包、资源治理。
架构级优化收益可能很大,但成本和风险也高。不要在没有数据证明的情况下直接大改。
验证收益和防止回归
优化完成后,需要回答三个问题:
- 指标是否改善?
- 用户体验是否改善?
- 有没有引入新问题?
建议验证链路:
text
本地 Lighthouse 对比
-> Performance 面板确认瓶颈消失
-> 灰度上线
-> 观察线上 P75/P95
-> 对比错误率和业务指标性能优化可能引入回归。例如:
- 图片懒加载导致首屏图片也被延迟加载,LCP 变差。
- 代码分割过度导致交互时才加载弹窗,点击后卡顿。
- 缓存策略过强导致用户拿不到最新资源。
font-display: swap改善 FCP,却带来明显字体跳动。
因此优化要小步上线,保留回滚方案。
常见误区
误区一:只优化资源体积
资源体积很重要,但不是所有慢都来自体积。TTFB 高可能是服务端慢,INP 高可能是主线程长任务,CLS 高可能是布局占位问题。先定位,再下手。
误区二:为了分数牺牲体验
Lighthouse 分数只是参考。为了分数移除必要功能、延迟关键内容、让页面看起来更早但不可用,都不是好的优化。
误区三:所有图片都懒加载
首屏 LCP 图片不应该懒加载。它应该尽早加载,并设置合适优先级。懒加载适合非首屏图片。
误区四:滥用缓存
缓存能提升速度,也可能带来更新不及时。静态资源可以长缓存,但必须配合 hash。HTML 和接口数据要结合业务时效性设计。
误区五:把防抖节流当万能药
防抖节流只能减少触发频率,不能消除单次任务过重的问题。如果每次任务本身耗时很长,还需要拆任务、缓存计算、虚拟列表或 Web Worker。
面试中如何回答
可以按下面结构表达:
- 性能优化先定目标,例如 LCP、INP、CLS 的 P75 阈值。
- 用线上 RUM 判断影响面,用 Lighthouse 和 Performance 定位瓶颈。
- 按关键路径拆解:网络、缓存、资源体积、渲染、主线程、第三方脚本。
- 优先优化核心页面和关键指标,不盲目堆技巧。
- 上线后用同一指标口径验证收益,并关注错误率和业务指标。
一个比较完整的回答是:
我会先用数据确认问题,比如 LCP 高还是 INP 高。如果 LCP 高,就看 TTFB、首屏资源、图片和关键 CSS;如果 INP 高,就看主线程长任务、事件回调和组件重渲染;如果 CLS 高,就看图片尺寸、广告位和字体。优化后通过 Lighthouse 做本地对比,灰度上线后看线上 P75 是否改善。
总结
性能优化的核心不是背很多技巧,而是建立闭环:
- 先度量:明确页面、环境、指标和目标值。
- 再定位:判断瓶颈在网络、资源、渲染还是主线程。
- 再优化:针对关键路径选择收益最大的方案。
- 最后验证:用同一指标口径比较优化前后,并防止回归。
真正可靠的性能优化,一定是数据驱动、场景优先、可验证、可回滚的。
思维导图
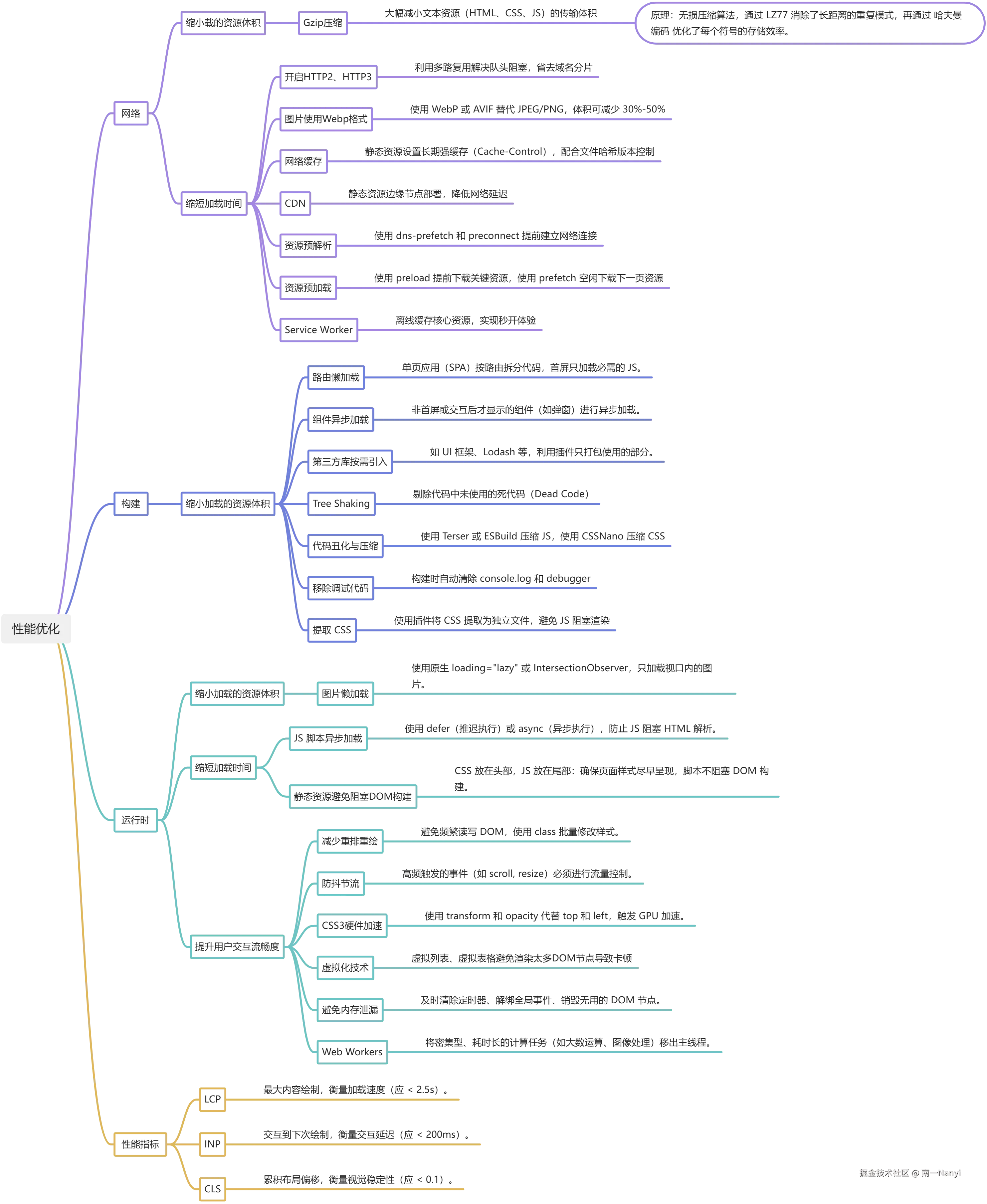
感谢阅读!