OpenCode 踩坑注意事项:上下文压缩、MCP 机制与 Skill
摘要:在使用 OpenCode 进行 AI 辅助开发时,理解其底层运行机制至关重要。本文深入剖析了 OpenCode 的四大核心模块:上下文压缩策略、MCP 工具加载机制、系统提示词组装逻辑以及 Skill 文件索引原理。掌握这些细节,将帮助你避开"技能丢失"、"Token 爆炸"等常见坑点,写出更稳定的 Agent 配置。
1. 上下文压缩机制:避免关键信息丢失
当对话上下文过大时,OpenCode 会自动触发压缩机制。理解这一机制是防止 SKILL.md 等关键配置"意外消失"的关键。
1.1 压缩的工作原理
压缩并非简单的截断,而是通过一次额外的 LLM 调用完成的智能处理:
- 早期对话:被压缩为结构化摘要。
- 最近交互:保留完整内容(默认最后 2 轮用户交互)。
- 后续对话:基于"摘要 + 最近轮次"继续进行。
1.2 SKILL.md 的丢失风险
如果 SKILL.md 在对话早期被读入,它可能会经历以下两种命运:
| 状态 | 条件 | 结果 | 模型行为 |
|---|---|---|---|
| 安全 | 位于尾部保留轮次内 | 内容完好无损 | 正常引用 |
| 危险 | 位于头部被摘要化 | 详细内容丢失 | 仅知道 Skill 存在,需主动 再次调用 skill 工具重新加载 |
💡 最佳实践
不要将工具调用的参数细节、复杂指令写在
SKILL.md中。因为这些内容一旦被摘要化,模型未必能意识到需要重新加载。建议将具体的工具调用逻辑放在 MCP 中实现 ,让SKILL.md仅作为高层级的意图描述。
1.3 配置与 Prune(修剪)机制
可以通过配置文件控制压缩行为。其中 prune 字段的作用是修剪旧的工具输出(包含内置、插件、MCP 等工具),而不是删掉工具本身。
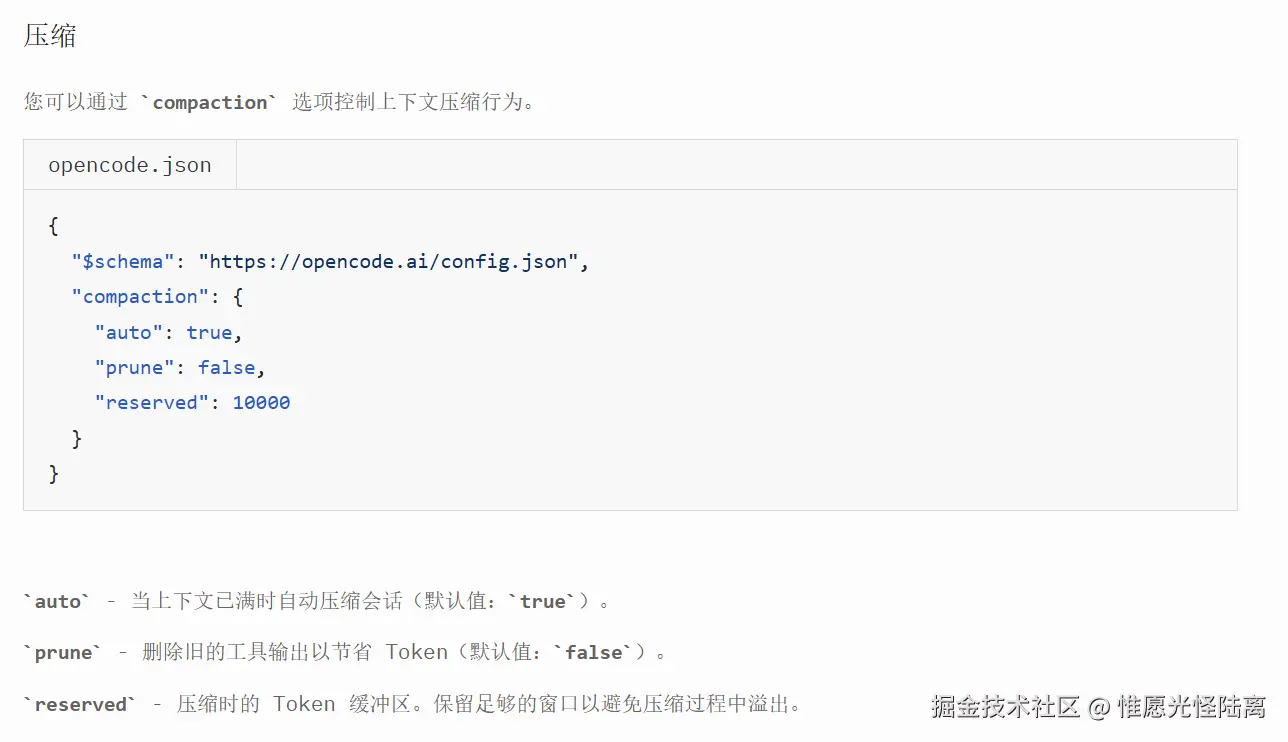
Prune 对 Skill 的特殊保护
虽然 Prune 会清理大部分工具输出,但读取的 SKILL.md 不会被 Prune 删除。源码逻辑如下:
scss
// tool/skill.ts 简化逻辑示意
function prune(messages) {
for (const msg of messages) {
// 第322行:遇到 skill 工具时跳过
if (msg.tool === 'skill') continue;
// 第298行:标记其他工具输出为清除
markForRemoval(msg.toolOutput);
}
}🚨 警告:不被 Prune ≠ 绝对安全!
请务必区分 修剪(Prune) 和 摘要(Summarize) 这两个独立阶段:
- Prune 阶段:Skill 输出确实受到保护,不会被直接清空。
- Summarize 阶段 :当对话继续增长触发摘要时,未被 Prune 的 Skill 内容仍会被 LLM 概括化。
这意味着什么?
即使
SKILL.md逃过了 Prune,其中的精确参数、代码片段、格式模板等细节仍会在摘要中丢失。模型后续只知道"有这个 Skill",但无法再准确执行需要精确信息的操作。正确做法 :永远不要假设
SKILL.md的内容会全程保持原样。将关键执行逻辑下沉到 MCP 工具中 ,让SKILL.md只承担"意图路由"的职责,才是应对压缩机制的根本解法。
2. MCP 工具加载机制:警惕 Token 消耗
2.1 工具是如何传递给模型的?
一个常见的误区是认为 MCP 工具定义在系统提示词中。事实并非如此。MCP 工具和内置工具一样,是在每轮对话请求前动态解析并传递的:
scss
每次 LLM 请求前 (prompt.ts:1387-1401):
→ SessionTools.resolve() 被调用
→ registry.tools() → 内置工具 + 插件工具
→ mcp.tools() → 所有已连接 MCP 服务器的工具 (从缓存读取)
→ 合并后的 tools 传入 handle.process() → llm.stream() → streamText()
→ AI SDK 将全部工具描述 + JSON Schema 随本次请求发给模型 API2.2 性能警告
由于工具描述会占用每次请求的上下文窗口,MCP 工具不宜过多。过多的工具定义不仅消耗 Token,还可能干扰模型的工具选择准确率。官方文档中也做了如此提示:

3. 系统提示词(System Prompt)里都有什么
系统提示词决定了 Agent 的"人设"与"认知边界"。它在 llm/request.ts:56-64 中由以下 5 层拼接而成:
csharp
System Prompt = [
① 模型角色的核心提示模板, // default.txt / anthropic.txt 等
② 环境信息, // Working directory, workspace, git, platform, 日期
③ 指令文件, // AGENTS.md / CLAUDE.md / CONTEXT.md
④ 可用技能列表, // Skill.fmt(list, verbose)
⑤ 用户级自定义 system prompt // 可选
].join("\n")各层详解
| 层级 | 代码位置 | 说明 |
|---|---|---|
| ① 模型提示模板 | system.ts:19-33 + prompt/*.txt |
按模型 ID 匹配,Agent 可自定义覆盖 agent.prompt |
| ② 环境信息 | system.ts:48-63 |
sys.environment() --- 模型名/ID、工作目录、Git 状态、平台、日期 |
| ③ 指令文件 | instruction.ts:109- |
向上搜索项目目录中的指令文件,含全局 ~/.config/opencode/AGENTS.md |
| ④ 技能列表 | system.ts:65-77 |
sys.skills(agent) --- 列出所有可用技能的名称和描述 |
| ⑤ 用户 System | prompt.ts 传递 |
每条用户消息可附带自己的 system 字段 |
🔍 注意
System Prompt 不包含 MCP 工具列表和内置工具列表。这两者是通过 API 的
tools参数独立传递的。简单说:System Prompt = 你是谁 + 你在哪 + 项目规则 + 你能加载哪些技能。
4. Skill 文件索引:隐式发现与显式引导
4.1 未提及的文件也能被发现吗?
是的,完全可以。
即使 SKILL.md 中没有提到 references/ 或 assets/ 文件夹,OpenCode 依然能发现它们。
底层使用 ripgrep 递归扫描整个技能目录(tool/skill.ts:39-44),唯一的过滤条件是排除 SKILL.md 本身:
bash
skills/my-skill/
├── SKILL.md
├── references/architecture.md ← 即使 SKILL.md 没提,也会出现在列表
├── references/api-spec.md
├── assets/diagram.png
├── scripts/setup.sh
└── examples/demo.ts扫描结果会以 <file> 标签形式返回绝对路径列表,模型可随时使用 read 工具按需读取。
4.2 为什么仍需在 SKILL.md 中显式引用?
虽然技术上支持隐式发现,但存在两个限制:
- 数量限制 :文件列表最多返回 10 个,超出部分会被截断。
- 语义缺失:仅靠文件名,模型不一定能在正确的时机判断出应该读取哪个文件。
✅ 推荐做法
始终在
SKILL.md中明确说明何时、为何引用特定文件。例如:"当用户询问架构设计时,请读取references/architecture.md"。这比依赖模型的猜测要可靠得多。