文章目录
- 前言
- [1 先简短看下 dionv1 和 v2](#1 先简短看下 dionv1 和 v2)
-
- [1.1 DINO V1](#1.1 DINO V1)
- [1.2 DINOv2](#1.2 DINOv2)
- [1.3 dinov3 比 dinov2 强在哪里](#1.3 dinov3 比 dinov2 强在哪里)
- [2 dinov3 的 loss](#2 dinov3 的 loss)
-
- [2.1 L D I N O L_{DINO} LDINO](#2.1 L D I N O L_{DINO} LDINO)
- [2.2 L i B O T L_{iBOT} LiBOT](#2.2 L i B O T L_{iBOT} LiBOT)
- [2.3 L D K e l e o L_{DKeleo} LDKeleo](#2.3 L D K e l e o L_{DKeleo} LDKeleo)
- [2.4 极端 1: 输出恒定](#2.4 极端 1: 输出恒定)
- [2.5 极端 2: 均匀输出](#2.5 极端 2: 均匀输出)
- [2.6 crop 如果 大图小图无关怎么办?](#2.6 crop 如果 大图小图无关怎么办?)
- [3. dinov3 贡献详述](#3. dinov3 贡献详述)
-
- [3.1 contribution(i) Data Preparation](#3.1 contribution(i) Data Preparation)
-
- [3.1.1 part1:`做"更均衡的视觉概念覆盖"`](#3.1.1 part1:
做“更均衡的视觉概念覆盖”) - [3.1.2 part2: `做"更贴近下游任务"的数据`](#3.1.2 part2:
做“更贴近下游任务”的数据) - [3.1.3 part3: data sampling](#3.1.3 part3: data sampling)
- [3.1.1 part1:`做"更均衡的视觉概念覆盖"`](#3.1.1 part1:
- [3.2 contribution(ii): Large-Scale Training with Self-Supervision](#3.2 contribution(ii): Large-Scale Training with Self-Supervision)
-
- [3.2.1 Learning Objective :核心学习目标与损失函数的融合](#3.2.1 Learning Objective :核心学习目标与损失函数的融合)
- [3.3 Gram Anchoring](#3.3 Gram Anchoring)
- [3.4 Updated Model Architecture](#3.4 Updated Model Architecture)
-
- [3.4.0 Axial-RoPE](#3.4.0 Axial-RoPE)
- [3.4.1 RoPE-box](#3.4.1 RoPE-box)
- [3.4.2 RoPE-box jittering](#3.4.2 RoPE-box jittering)
- [4 工业落地](#4 工业落地)
- 总结
前言
DINO 系列(尤其 DINOv2)的一大优势是:自监督学出来的特征既能做全局语义(分类/检索),又能做局部密集任务(分割/匹配/深度)。但作者指出:当你把模型、数据、训练时长都继续放大时,会出现一个"已知但没彻底解决"的问题------dense feature map 在长训练/大模型时会退化(变噪、变糊、结构性崩坏),导致密集任务能力受损。DINOv3 的核心贡献之一就是专门把这个坑填了:提出 Gram anchoring 来"钉住"密集特征质量,避免塌陷

关键名词:
SSL: Self-Supervised Learning
scaling law: 尺度律/规模定律, 当你把训练的关键"规模因素"变大(比如 模型参数量 N、训练数据量 D、训练计算量 C),模型的性能(通常用 loss/困惑度/错误率)会呈现出可预测的幂律关系------也就是"越大越好"并不是随意的,而是遵循一条近似的数学曲线。
RoPE: Rotary Position Embedding.
dinov3 的模型不容易下载,
可以从这里: https://www.modelscope.cn/search?page=1\&search=dinov3\&type=model
笔者也将其存入了百度网盘:
1 先简短看下 dionv1 和 v2
1.1 DINO V1
略
1.2 DINOv2
其实原论文比较朴素, 就是在 ViT 训练中,发现经常有artifacts 出现, 下图就是 "高范数伪影的特征", 这些token的范数约为其他token的10倍,占总token数量的约2%。这些token通常出现在图像的背景区域,原本信息量较低, 但携带更多的全局信息。
这种情况出现在例如图中的 DINO v2 非常多平坦区域的artifact, 而 DINO v1 几乎没有.
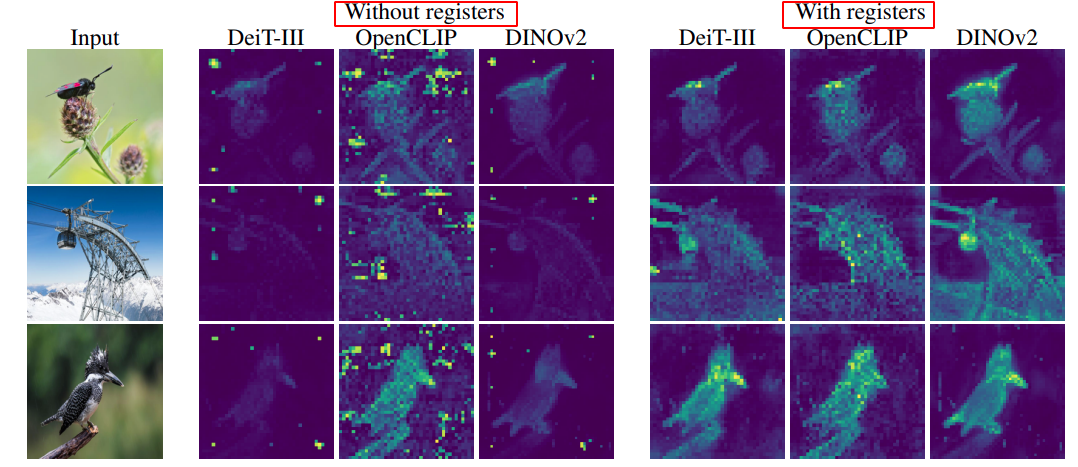
为什么DINO v2 有而v1没有?
原因一:训练目标不同(Contrastive vs. Distillation)
DINO v1 使用的是 对比学习(contrastive learning),目标是学习空间上连贯、语义一致的 embedding。它鼓励所有 token 都有意义(避免冗余 token)。会对异常 token 产生惩罚。所以模型不会"偷偷"把背景 patch 用作临时内存。
原因二:模型容量更大,ViT 有"懒惰策略"
训练目标更复杂,主要关注 cls token 的表现。对 patch token 的约束变弱,模型更容易利用背景区域做"缓存"。
原因三:DINO v1 更强的 per-token 学习机制
DINO v1 每个 patch token 都被要求有一致性输出(比如用不同视角增强后的结果一致)。而 DINO v2 由于有 teacher-student distillation 和更多 cls-guided 目标,patch token 不一定需要一致。
说实话我觉得 cls-guided 才是罪魁祸首.
ViT 分类策略中经常有:CLS + patch_1 + patch_2 + ... + patch_n 这种方式 CLS token 就成了全局
因为论文作者这么说:The root cause of the artifact is that ViTs are usually supervised via the CLS token only, allowing the model to utilize other tokens for internal memory without constraint.
所以作者引入了更多的全局 register 变为:CLS + Register1 ,...,Register R, patch_1 + patch_2 + ... + patch_n
说白了就是从 CLS + N 个 patch token 变为 CLS + R 个 Register token + N 个 patch token
1.3 dinov3 比 dinov2 强在哪里
我们直接看贡献点

4个贡献点:
数据规模化(Data scaling):
利用自动数据筛选/构建方法拿到一个很大的"背景"训练集,然后混入少量专门数据(ImageNet-1k). 说白了就是散集合 + 专家数据, 作者这里提出了他们的工作基于近年来自动化数据整理(automatic data curation)(Vo et al., 2024)的进展,获得了一个大型的"背景(background)"训练数据集
相比DINOV2, DINOv3 不只是"数据更多"而是把数据准备做成了一个完整方案:
(1) 用 clustering-based curation 做更均衡的视觉概念覆盖
(2) 用 retrieval-based curation 提高和下游任务相关的概念覆盖
(3) 再混入一部分高质量公开 CV 数据
(4) 训练时还专门设计了 sampling 策略
也就是说,v3 在 data scaling 上比 v2 更讲究"数据怎么构、怎么混、怎么喂",不是单纯扩大规模。
模型规模化 + 训练配方(Model architecture & training):
(1) 论文表 2 直接对比了 teacher:DINOv2:ViT-giant,1.1B, DINOv3:ViT-7B,6.7B
(2) 位置编码从 learnable positional embedding 换成 RoPE
(3) patch size 从 14 改成 16
(4) embedding dim 从 1536 提到 4096
(5) DINO / iBOT 的 heads 和 prototypes 规模也一起变大
(6)而且训练上,DINOv3 不再沿用 DINOv2 那种多段 cosine schedules,而改成了 constant hyperparameter schedules + warmup。
所以可以说:DINOv3 比 DINOv2 更强的一大来源,是它不仅把模型做大了,还把"大模型怎么稳定训练"这套 recipe 改了。
核心算法改进:Gram anchoring(解决 dense feature 退化):
在规模化训练时,dense features 会退化;为此提出一个 Gram anchoring 的训练阶段,通过"清理 feature map 噪声"来显著提升 dense 任务表现(包含 parametric 和 non-parametric 的 dense task)。
论文明确说:
长训练时,global/classification 指标会继续提升
但 dense tasks 的表现会下降
patch similarity maps 会越来越噪
这个问题在更大模型、更长训练里更明显
(1)DINOv3 为此提出了 Gram Anchoring:
不直接钉死 patch 特征本身
而是约束 patch 特征之间的 Gram matrix / 相似性结构
用一个早期 teacher 的局部结构来"锚住"后期训练
这一步的结果是:
DINOv3 在 dense features 上明显比 DINOv2 更干净、更稳定、更强。
这也是为什么论文里一直强调 DINOv3 的 patch 相似度图、PCA feature maps、dense benchmark 都比 DINOv2 好。
后训练阶段 + 蒸馏成模型家族(Post-training & distillation):
延续以往做法,在训练末期加入 高分辨率后训练(高分辨率是指 crop 的分辨率变大) 阶段,并把 7B teacher 蒸馏到不同尺寸的一系列模型;其中蒸馏部分提出一个 single-teacher multiple-students 的高效流程,把 7B "frontier model"的能力转移到更实用的小模型上。
2 dinov3 的 loss
看dinov 3 的论文前首先要 看下 这个loss
dinov3训练模型时使用一种 discriminative self-supervised strategy这个策略是多个自监督目标的组合,并且同时包含 global 和 local 的 loss terms;
继承DINOv2,dinov3使用 两个 loss:
image-level objective: L D I N O L_{DINO} LDINO
patch-level latent reconstruction objective: L i B O T L_{iBOT} LiBOT
DINOV3 的 total loss: L D I N O + L i B O T + 0.1 L D K o l e o L_{DINO}+L_{iBOT}+0.1L_{DKoleo} LDINO+LiBOT+0.1LDKoleo
L D I N O L_{DINO} LDINO 和 L i B O T L_{iBOT} LiBOT 都是student 和 teatcher 算交叉熵,只是老师和学生网络吃入的数据不一样
2.1 L D I N O L_{DINO} LDINO
为了在完全没有人工标签(Self-Supervised)的情况下,仅靠这套交叉熵就逼着模型学到强大的宏观语义,且保证计算图绝对不发生塌陷(Collapse),DINO loss 在数据流控制和工程抑制手段上玩到了极致: DINO 的核心机制是 "Local-to-Global"(局部对齐全局)。
DINO loss的过程
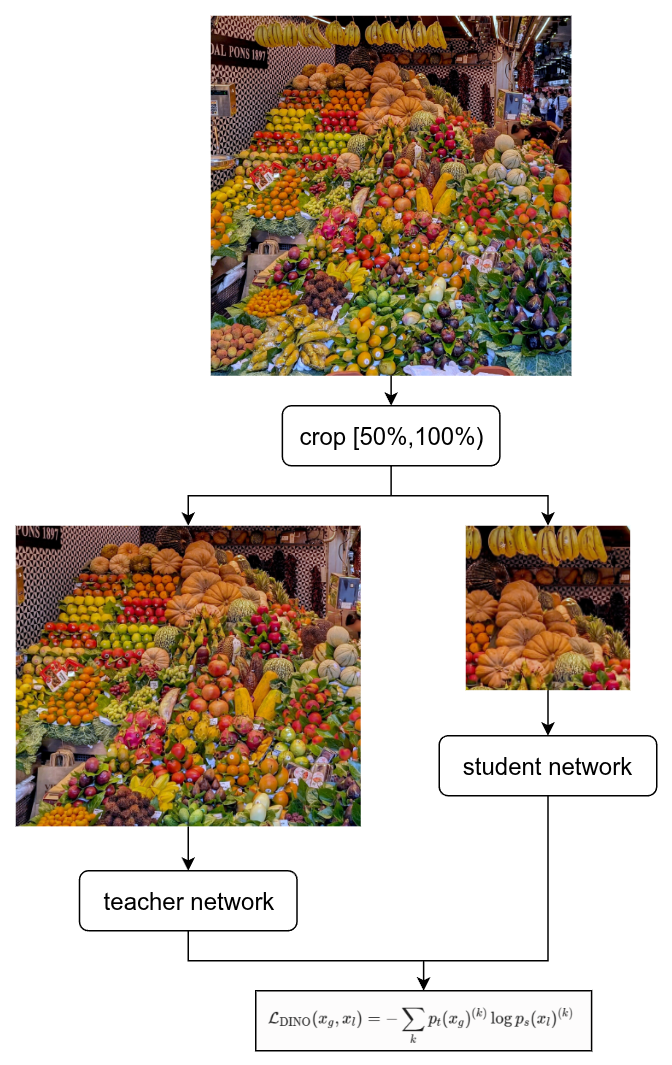
step1:
多尺度裁剪(Multi-crop): 对于同一张输入的完整图片,代码里会随机裁剪出两种视角的图片块:Global Crops(全局视角): 比如 2 张 224 × 224 224 \times 224 224×224 的大图,能看到物体的主体(比如整只猫)。Local Crops(局部视角): 比如 6 张 96 × 96 96 \times 96 96×96 的小图,只能看到局部碎片(比如猫的耳朵、爪子)。
step2:
喂给两个网络:Teacher 网络(只吃大餐):只能输入 Global Crops。Student 网络(大餐小餐都吃):既要输入 Global Crops,又要输入 Local Crops。
step3:
输出对齐(计算 Loss):DINO Loss 强迫 Student 看到局部(Local)时的输出,去预测 Teacher 看到全局(Global)时的输出。
数学公式计算loss:
假设 x g x_g xg 是全局裁剪图, x l x_l xl 是局部裁剪图。它们经过 Backbone(ViT)后,提取出 CLS Token,然后通过一个 Projection Head(通常是一个几万维的多层感知机分类头,代表几万个聚类原型 Prototype)。
(1) Teacher 输出的概率分布为 p t ( x g ) p_t(x_g) pt(xg),
(2) Student 输出的概率分布为 p s ( x l ) p_s(x_l) ps(xl)。
DINO Loss 就是它们之间的交叉熵: L DINO ( x g , x l ) = − ∑ k p t ( x g ) ( k ) log p s ( x l ) ( k ) \mathcal{L}{\text{DINO}}(x_g, x_l) = - \sum{k} p_t(x_g)^{(k)} \log p_s(x_l)^{(k)} LDINO(xg,xl)=−k∑pt(xg)(k)logps(xl)(k)
2.2 L i B O T L_{iBOT} LiBOT
就是视觉领域的 MIM(Masked Image Modeling,掩码图像建模)。简单来说,它的逻辑和 NLP 大模型(如 BERT)里随机抠掉一些词让模型去"猜"的 完形填空 机制一模一样,只不过在 iBOT 里,抠掉的不是"词",而是"图片里的局部方块(Patches)"。
结合 DINO 经典的"教师-学生"双分支架构,我们可以用最纯粹的数据流对一下过程:
iBOT loss的过程
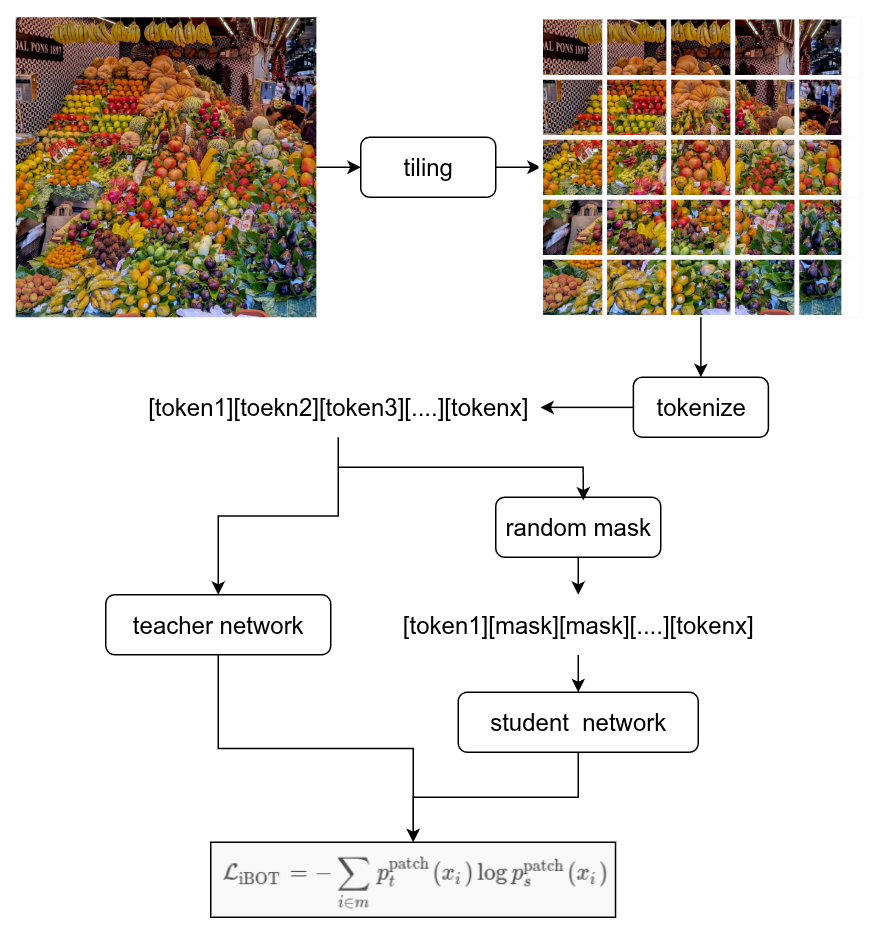
step1:
切片与掩码(Tokenization & Masking): 图像首先被切成互不重叠的 16 × 16 16 \times 16 16×16 像素的小方块(Patches),每一个方块通过 Linear Projection 变成一个视觉 Token。
在送入学生网络(Student)之前,会被随机挑选其中很大一部分 Token(通常高达 50% 以上),把它们用一个共享的 MASK 符号替换掉。
step2:
学生网络的任务------"盲猜": 学生网络吃进这组残缺不全、带掩码的 Token 序列,通过自注意力机制(Self-Attention)强迫被遮挡的位置去观察周围没被遮挡的像素,然后预测出被遮挡区域对应的局部类别概率分布(Local Patch Token Distribution)。
step3:
教师网络的角色------"标准答案": 教师网络(Teacher) 吃进的是完全没有被掩码(Unmasked)的完整图像。它会产生所有 Patch 最完美的、高保真的特征和类别概率。
数学公式与损失函数计算:
iBOT 损失只在被抹掉的那些位置(Masked Patches)上计算。
假设 m m m 代表所有被掩码的 Patch 索引集合。对于任意一个被遮挡的位置 i ∈ m i \in m i∈m 有如下:
(1) 学生网络在该位置输出的概率分布为: p s patch ( x i ) p_s^{\text{patch}}(x_i) pspatch(xi)
(2) 教师网络在对应位置输出的概率分布为: p t patch ( x i ) p_t^{\text{patch}}(x_i) ptpatch(xi)
iBOT 损失本质上就是它们两者之间的交叉熵(Cross-Entropy),并在整个 Batch 和所有被掩码的位置上求平均: L iBOT = − ∑ i ∈ m p t patch ( x i ) log p s patch ( x i ) \mathcal{L}{\text{iBOT}} = - \sum{i \in m} p_t^{\text{patch}}(x_i) \log p_s^{\text{patch}}(x_i) LiBOT=−i∈m∑ptpatch(xi)logpspatch(xi)
DINO 这种"自己左脚踩右脚"的自监督逻辑里,有一个致命的数学死穴:塌陷(Collapse)。
如果没有任何约束,Teacher 和 Student 网络为了让交叉熵变成 0,会走向两个偷懒的极端:
极端 1(输出恒定): 不管输入什么图片,网络全部输出一个固定的one hot 向量(比如全输出第 1 维为 1,其余为 0)。
看到猫: g ( x ) = 15.0 , 1.0 , 0.5 g(x) = 15.0, 1.0, 0.5 g(x)=15.0,1.0,0.5 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
看到狗: g ( x ) = 12.0 , 0.8 , 0.2 g(x) = 12.0, 0.8, 0.2 g(x)=12.0,0.8,0.2 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
看到人: g ( x ) = 14.0 , 1.2 , 0.3 g(x) = 14.0, 1.2, 0.3 g(x)=14.0,1.2,0.3 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
极端 2(输出均匀): 不管输入什么图片,网络在所有维度上的概率全部均分(变成绝对随机的平涂分布)。
看到猫: g ( x ) = 2.0 , 2.0 , 2.0 g(x) = 2.0, 2.0, 2.0 g(x)=2.0,2.0,2.0 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
看到狗: g ( x ) = 1.5 , 1.5 , 1.5 g(x) = 1.5, 1.5, 1.5 g(x)=1.5,1.5,1.5 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
看到人 : g ( x ) = 3.0 , 3.0 , 3.0 g(x) = 3.0, 3.0, 3.0 g(x)=3.0,3.0,3.0 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
为了彻底堵死这两个漏洞,DINO 损失在计算交叉熵之前,对 Teacher 和 Student 的输出概率做了完全不同的数学魔改(Softmax 差异化处理): 见 2.3 和 2.4.
2.3 L D K e l e o L_{DKeleo} LDKeleo
在自监督预训练的后期,虽然有 DINO 和 iBOT 损失在拼命拉近 Teacher 和 Student,但模型往往会产生一种隐性的、叫做 "特征各向异性"(Anisotropy / Feature Elongation) 的病态退化:
特征扎堆现象: 模型为了省事(就是大家经常说的偷懒),把所有图片提取出来的 CLS 向量,在高维空间里全部塞进一个极其狭窄的"圆锥体"或者"特定方向的通道"里。
后果: 比如你的特征有 1024 维,如果所有图片的特征向量方向都差不多(夹角极小),那这个 1024 维的特征空间实际上就退化成了 1 维。特征与特征之间拉不开距离,当下游任务(比如自动驾驶看周围的车辆、机器人看抓取点)需要高精度的判别时,模型就会因为特征太密、分不清楚而抓瞎。
KoLeo Loss 就是为了解决这个"特征扎堆"问题而生的。
KoLeo Loss 的数学公式基于最近邻距离(Nearest Neighbor Distance)。它的物理逻辑非常粗暴:对于 Batch 里的任意一个特征向量,它必须要和离它最近的那个兄弟向量保持足够的距离。
假设在一个 Batch(注意是在batch 维度) 里面,有 B B B 张图片,经过 ViT 提取出了 B B B 个全局特征向量(经过 L2 归一化后): x 1 , x 2 , ... , x B \mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}B x1,x2,...,xB。对于其中某一个特征向量 x i \mathbf{x}i xi,我们在整个 Batch 里找出离它最近(距离最小)的另一个特征向量,记为 x ρ ( i ) \mathbf{x}{\rho(i)} xρ(i)。它们之间的欧氏距离就是: d i = min j ≠ i ∥ x i − x j ∥ d_i = \min{j \neq i} \|\mathbf{x}i - \mathbf{x}j\| di=j=imin∥xi−xj∥KoLeo 损失函数的公式为: L KoLeo = − 1 B ∑ i = 1 B log d i \mathcal{L}{\text{KoLeo}} = - \frac{1}{B} \sum{i=1}^B \log d_i LKoLeo=−B1i=1∑Blogdi
注意: 我们的 模型是自监督的,因为没有标签, 所以只能自己学
假设你在做自动驾驶视觉底座:
同一个 DINOv3 模型部署在两辆不同的车上(或者同一辆车在不同的光照下看同一个红绿灯):
输入 A:白天看到的红绿灯。
输入 B:黄昏看到的同一个红绿灯。
如果不加 KoLeo Loss:模型可能会觉得这两个场景太像了,提取出来的特征向量 x A \mathbf{x}_A xA 和 x B \mathbf{x}_B xB 在空间里几乎重合(距离 d i → 0 d_i \to 0 di→0)。
当算法想要精细微调去判断黄昏下的红绿灯是否有轻微炫光时,由于特征贴得太死,下游网络的分类器根本切不开这层边界。
加上 KoLeo Loss 之后:在预训练时,KoLeo 发现 x A \mathbf{x}_A xA 和 x B \mathbf{x}_B xB 挨得太近了,飙升Loss。模型被迫去寻找两张图片里更细微的差异,把它们的特征向不同的高维方向推开。
2.4 极端 1: 输出恒定
针对输出恒定: 中心化(Centering)或在线聚类(Sinkhorn-Knopp)
如果 Teacher 的分布变锐利了,模型可能又会走向另一个极端:不管输入什么图,大家都只赌某一个相同的维度。为了破这个局,必须引入归一化机制,让网络在整个 Batch(所有图片)上输出的均值是均匀的。
传统 DINO 做法(Centering):在 Teacher 进入 Softmax 前,减去一个动态更新的"历史全局均值" c \mathbf{c} c(Center):
g t ( x ) ← g t ( x ) − c g_t(x) \leftarrow g_t(x) - \mathbf{c} gt(x)←gt(x)−c
这个 Center 是通过指数移动平均(EMA)在训练中实时更新的。
对于刚才的例子:
看到猫: g ( x ) = 15.0 , 1.0 , 0.5 g(x) = 15.0, 1.0, 0.5 g(x)=15.0,1.0,0.5 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
看到狗: g ( x ) = 12.0 , 0.8 , 0.2 g(x) = 12.0, 0.8, 0.2 g(x)=12.0,0.8,0.2 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
看到人: g ( x ) = 14.0 , 1.2 , 0.3 g(x) = 14.0, 1.2, 0.3 g(x)=14.0,1.2,0.3 → \rightarrow → 过 Softmax 之后几乎是 1.0 , 0.0 , 0.0 1.0, 0.0, 0.0 1.0,0.0,0.0
每个维度进行历史求平均后: c = 13.6 , 1.0 , 0.3 \mathbf{c} = 13.6, 1.0, 0.3 c=13.6,1.0,0.3
每个维度送入softmax之前就成了 :
g t ( x ) ← g t ( x ) − c = 12.0 , 0.8 , 0.2 − 13.6 , 1.0 , 0.3 = − 1.6 , − 0.2 , − 0.1 \begin{aligned} g_t(x) \leftarrow g_t(x) - \mathbf{c} &= 12.0, 0.8, 0.2 - 13.6, 1.0, 0.3 \\ &= -1.6, -0.2, -0.1 \end{aligned} gt(x)←gt(x)−c=12.0,0.8,0.2−13.6,1.0,0.3=−1.6,−0.2,−0.1
如果模型老是倾向于输出某一个维度,Center 就会把这个维度狠狠地拉下来,强迫模型去开发别的特征维度。
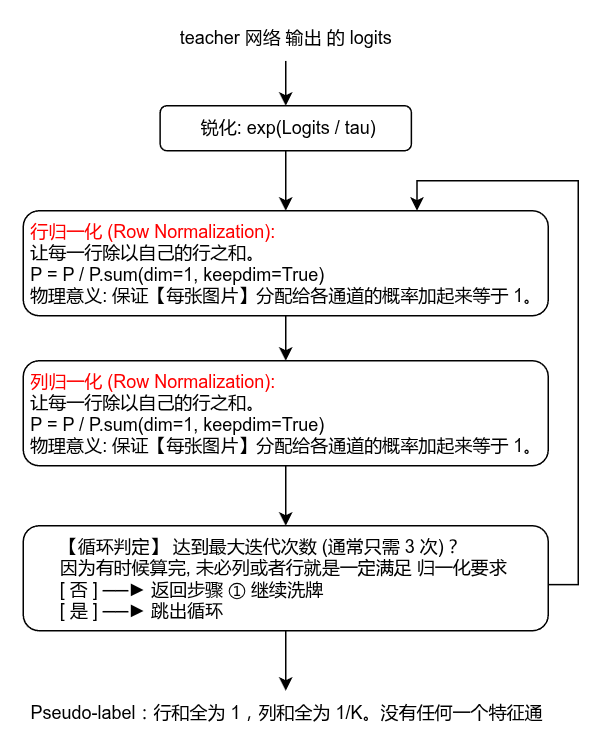
DINOv3 升级做法(Sinkhorn-Knopp 算法):在最新的 DINOv3.pdf 论文中,Meta 提到在 7B 级别的大模型上,传统的 Centering 经验平移极度不稳定,计算图经常崩掉。于是他们全面改用了基于最优传输理论的 Sinkhorn-Knopp 算法(源自 SwAV 算法)。它在数学上用严格的矩阵行列归一化,硬性断绝了所有图片聚到同一个中心处的可能,彻底稳住了大模型的计算图。
Sinkhorn-Knopp
优点1: Sinkhorn-Knopp 是实时纠偏, 而 centering 是基于历史纠偏.
Centering (传统 DINO) :
它在计算时,用 Center ( c \mathbf{c} c) 的特征向量作为基准。这个 c \mathbf{c} c 是一个平均值,它是靠指数移动平均(EMA)在过去成千上万步训练中慢慢累积出来的历史全局均值。漏洞:它存在时间滞后性。如果当前这个 Batch 的数据突然发生了剧烈抖动,历史均值 c \mathbf{c} c 根本来不及反应,模型就会在这一瞬间发生塌陷(NaN 崩溃)。
Sinkhorn-Knopp (DINOv3) :
它完全没有历史积累的平均值(不需要维护历史均值 c \mathbf{c} c)。只盯着当前这一个 Batch 内的 B, K 矩阵。通过在当前 Batch 内部进行硬性的行列交替洗牌,直接在当下求出最优传输的闭环解。优势:它是 100% 实时防塌陷的。不管 Data Loader 怎么随机、不管当前 Batch 的样本有多极端,SK 算法都能在这一步瞬间把特征空间"摆平"。
优点2: Sinkhorn-Knopp 进行了 normalize, 而 centering 只是平移坐标系.
Centering 是"减法(平移)":
g t ( x ) ← g t ( x ) − c g_t(x) \leftarrow g_t(x) - \mathbf{c} gt(x)←gt(x)−c
它的逻辑是:既然历史告诉我第 x个通道的 历史均值最高,那我就减去一个很大的常数 c x c_x cx。
但它无法严格保证减完之后各通道的总比例绝对相等。
SK 算法则是"除法(normalize)":它在迭代中交替进行 P /= P.sum(dim=1) 和 P /= P.sum(dim=0) * K。它的逻辑是:管你原始得分有多高,只要你这个通道发生了垄断(列和严重超标),我在这一步直接拿你当分母把你整体除掉、稀释掉。这在数学上是一种刚性的等式约束,能保证输出矩阵的列和绝对完美等于 1 K \frac{1}{K} K1。
Sinkhorn-Knopp 流程如下图
2.5 极端 2: 均匀输出
针对均匀输出: 锐化(Sharpening)
在自监督学习(没有人工标签)中,Teacher 网络的输出,本质上就是要充当 Student 的"高保真真值标签"。
如果 Teacher 的输出太模糊(比如 [0.4, 0.3, 0.3]),Student 学起来就会变得极其痛苦、无所适从。
我们必须在数学上强迫 Teacher 的输出向 One-hot 靠拢(例如变成 [0.98, 0.01, 0.01]),
这样就像一个斩钉截铁的严厉导师,清清楚楚地告诉学生:"听我的,这题就选第一个选项!"
借用均匀输出中的例子:
看到猫: g ( x ) = 2.0 , 2.0 , 2.0 g(x) = 2.0, 2.0, 2.0 g(x)=2.0,2.0,2.0 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
看到狗: g ( x ) = 1.5 , 1.5 , 1.5 g(x) = 1.5, 1.5, 1.5 g(x)=1.5,1.5,1.5 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
看到人 : g ( x ) = 3.0 , 3.0 , 3.0 g(x) = 3.0, 3.0, 3.0 g(x)=3.0,3.0,3.0 → \rightarrow → 过普通 Softmax → 0.33 , 0.33 , 0.33 \rightarrow 0.33, 0.33, 0.33 →0.33,0.33,0.33
我们希望像one-hot(独热编码) 一样:
在 K K K 个维度里,有且仅有一个维度是 1 1 1(绝对真理),其余所有维度全部死死踩在 0 0 0 上(绝对错误)。例如: 0 , 1 , 0 0, 1, 0 0,1,0这就代表模型 100% 确认当前的物体属于第 2 个类别,没有一丝一毫的犹豫。
对抗"输出均匀", 在计算 Teacher 的概率时,会引入一个极小的温度系数 τ t \tau_t τt(比如 0.04):
P s ( x ) ( k ) = exp ( g s ( x ) ( k ) / τ s ) ∑ j = 1 K exp ( g s ( x ) ( j ) / τ s ) P_s(x)^{(k)} = \frac{\exp(g_s(x)^{(k)} / \tau_s)}{\sum_{j=1}^K \exp(g_s(x)^{(j)} / \tau_s)} Ps(x)(k)=∑j=1Kexp(gs(x)(j)/τs)exp(gs(x)(k)/τs)
因为 τ t \tau_t τt 非常小,它会在数学上强制把 Teacher 输出里最高的那一个分量极度放大(使分布变得非常尖锐,向 One-hot 靠拢)。这迫使模型必须明确做出选择,不能靠"把概率均分"来作弊。
因此刚才的过程假设: g t ( x ) = 2.2 , 1.8 , 1.0 g_t(x) = 2.2, 1.8, 1.0 gt(x)=2.2,1.8,1.0
如果不加 Sharpening(普通的 Softmax)直接送入标准 Softmax,我们要算每个维度的 exp ( g t ( x ) ) \exp(g_t(x)) exp(gt(x)):维度 1: exp ( 2.2 ) ≈ 9.02 \exp(2.2) \approx 9.02 exp(2.2)≈9.02维度 2: exp ( 1.8 ) ≈ 6.05 \exp(1.8) \approx 6.05 exp(1.8)≈6.05维度 3: exp ( 1.0 ) ≈ 2.72 \exp(1.0) \approx 2.72 exp(1.0)≈2.72分母(求和): 9.02 + 6.05 + 2.72 = 17.79 9.02 + 6.05 + 2.72 = 17.79 9.02+6.05+2.72=17.79最终得到的概率分布为: P n o r m a l = 9.02 / 17.79 , 6.05 / 17.79 , 2.72 / 17.79 = 0.51 , 0.34 , 0.15 P_{normal} = 9.02/17.79, 6.05/17.79, 2.72/17.79 = \mathbf{0.51, 0.34, 0.15} Pnormal=9.02/17.79,6.05/17.79,2.72/17.79=0.51,0.34,0.15
加了 Sharpening(除以极小的温度系数 τ t = 0.1 \tau_t = 0.1 τt=0.1),在进 Softmax 前让所有 Logits 强行除以 τ t = 0.1 \tau_t = 0.1 τt=0.1。这相当于把所有的数值放大 10 倍!新的 Logits 变成了: g t ( x ) / τ t = 22.0 , 18.0 , 10.0 g_t(x) / \tau_t = 22.0, 18.0, 10.0 gt(x)/τt=22.0,18.0,10.0重点来了:2.2 和 1.8 刚才只差了 0.4;
那么现在的第一维: 22.0 和 18.0 差了整整 4.0!
这个差距在指数函数( exp \exp exp)里会被呈几何倍数放大!我们再来算一次 exp \exp exp:
维度 1: exp ( 22.0 ) ≈ 3 , 584 , 912 , 846 \exp(22.0) \approx 3,584,912,846 exp(22.0)≈3,584,912,846
维度 2: exp ( 18.0 ) ≈ 65 , 659 , 969 \exp(18.0) \approx 65,659,969 exp(18.0)≈65,659,969
维度 3: exp ( 10.0 ) ≈ 22 , 026 \exp(10.0) \approx 22,026 exp(10.0)≈22,026
分母(求和): 3 , 584 , 912 , 846 + 65 , 659 , 969 + 22 , 026 ≈ 3 , 650 , 594 , 841 3,584,912,846 + 65,659,969 + 22,026 \approx 3,650,594,841 3,584,912,846+65,659,969+22,026≈3,650,594,841
最终得到的锐化概率分布为: P s h a r p = 3584912846 / 3650594841 , ... = 0.982 , 0.018 , 0.000 P_{sharp} = 3584912846 / 3650594841, \\dots = \mathbf{0.982, 0.018, 0.000} Psharp=3584912846/3650594841,...=0.982,0.018,0.000
再补充下:这个温度就是 大模型里大家常用的 tempure 用来防止长尾效应的.
Softmax ( g ( x ) τ ) \text{Softmax}\left(\frac{g(x)}{\tau}\right) Softmax(τg(x))
2.6 crop 如果 大图小图无关怎么办?
DINO Loss 盯着全局 CLS,在大图和小图之间拉近语义。
iBOT Loss 则是盯着同一张图内部的 Patch 块。
这两个 loss 兜底
例如:
所以,大图和小图的不匹配,不是自监督学习的漏洞,恰恰是它的解药。
轻微不匹配(整体与局部):逼着模型去通过"猫尾巴"联想"整只猫",学到了见微知著的宏观语义不变性。
严重不匹配(主体与纯噪点背景):由于老师网络给出的概率极其模糊,导致 Loss 梯度近乎为 0;同时有 iBOT 损失在局部像素级死死焊住,网络根本不会被带偏。
3. dinov3 贡献详述
3.1 contribution(i) Data Preparation

作者指出:数据变大≠一定更好`。单纯把训练数据"naively 增大"并不保证模型质量提升,成功的数据规模化通常依赖精心的数据整理/构建 pipeline。
DINOv3 延续了 SSL(自监督学习)的优势,即能够利用海量的原始、未标注图像进行训练 。为了从无标签的图像集合中收集有用的数据,DINOv3 采用了自动化的数据管理技术 。作者说 dinov3 利用一个来自 Instagram 公共帖子的 web 图像大型数据池来构建大规模预训练数据集。这些图片已经经过平台级内容审核,以帮助防止有害内容,并得到一个初始数据池,规模约为 170 亿张图像。基于这个原始数据池,我们构建三个数据部分(parts)。
并且作者明确给出了两个目标轴:
一类方法偏向 覆盖得更广、更均衡
一类方法偏向 更贴近下游任务、更实用
DINOv3 不是只选其中一边,而是都要。

3.1.1 part1:做"更均衡的视觉概念覆盖"
数据是这样得到的:
(1) 使用 DINOv2 as image embeddings
(2) 做 5 levels of clustering,各层cluster 数量分别是:
200M, 8M, 800k, 100k, 25k(3) 构建好这个 hierarchical cluster structure 之后,应用 Vo et al. (2024) 提出的 balanced sampling
(4) 最终得到一个 curated subset:1.689 billion images, 命名为 LVD-1689M
(5) 这个子集的目标是保证:balanced coverage of all visual concepts present on the web
这里有三个关键点。(1) "We employ DINOv2 as image embeddings"
这里不是说 DINOv2 被重新训练,而是说:
他们先用 DINOv2 给海量图片提取整图表征,再用这些表征做聚类。
(2) hierarchical k-means
这不是单层的"一次聚类",而是分层聚类结构。
也就是说,作者不是只想得到一个平面的聚类划分,而是想得到一个层级化的视觉概念组织方式。
(3) balanced coverage
这是这一部分最关键的目标。原文没有说"长尾"这个词,但它明确说这部分数据要实现:
balanced sampling
balanced coverage of all visual concepts
所以最稳妥的理解是:
第一部分数据的目标,是从巨大而复杂的 web 图像池中抽出一个在视觉概念上更均衡覆盖的子集。
问题1: 什么是图像嵌入(image embedding)入?就是把一张图的内容用一个网络编码成一个向量
𝑒 ∈ 𝑅 𝑑 𝑒∈𝑅^𝑑 e∈Rd(比如 CLS token 或 pooled 特征),然后这些向量特征位于同一个特征空间,可以做:
(1) 距离/相似读计算
(2) 聚类(kmeans)
(3) 采样平衡(balanced sampling)
本文这里将
dinov2作为特征提取器
问题2: 什么是更均衡?原始 web 数据里,某些常见模式会特别多,另一些模式会特别少。DINOV3不想让训练集只是"谁原本多就继续占主导",而是希望借助聚类和均衡采样,让训练集对不同视觉模式的覆盖更平衡一些。
3.1.2 part2: 做"更贴近下游任务"的数据
第二部分数据:采用一个
retrieval-based curation system类似于 Oquab et al. (2024) 的流程从大数据池中检索与某些 selected seed datasets 相似的图像得到一个覆盖 visual concepts relevant for downstream tasks 的数据集。
这部分和第一部分的目标不一样。第一部分偏向 balanced coverage
第二部分偏向 downstream relevance
也就是说,第二部分不是优先追求"全网视觉概念都尽量照顾到",而是:优先让数据更贴近下游任务真正需要的视觉概念。
问题1: 什么是类似于 Oquab et al. (2024) 的retrieval-based curation system先拿一些"种子数据集"作为参考,再去超大原始图像池里找与这些种子图像相似的图片,把这些相似图像收集起来,形成一个更贴近下游任务需要的数据集。
问题2: 和 clustering-based curation 的区别是什么?clustering-based curation重点是:diversity and balance
对全体数据做 embedding
做层次聚类
再做 balanced sampling
retrieval-based curation重点是:usflness,也就是更贴近下游任务相关概念先有 seed datasets
再从大池中检索相似图像
数据整理方法可能侧重 data diversity and balance,也可能侧重 data usefulness---its relevance to common practical applications;DINOv3 选择把这两类互补方法结合起来。
3.1.3 part3: data sampling
我们使用公开可获得的计算机视觉数据集,包括:
ImageNet1k(Deng et al., 2009)
ImageNet22k(Russakovsky et al., 2015)
Mapillary Street-level Sequences(Warburg et al., 2020)。
这一最后部分使我们能够在遵循 Oquab et al. (2024) 的做法下,进一步优化模型性能。
问题1: dinov3 是自监督的 为啥还要 cv 数据?首先我们可以确认 dinov3 是"a discriminative self-supervised strategy", 且 loss 是 L P r e = L D I N O + L i B O T + 0.1 L D K o l e o L_{Pre}=L_{DINO}+L_{iBOT}+0.1L_{DKoleo} LPre=LDINO+LiBOT+0.1LDKoleo
使用
image-level objectiveL D I N O L_{DINO} LDINO和patch-level objectiveL i B O T L_{iBOT} LiBOT但是有标注数据集 ≠ 必须使用标签,在这篇论文的主训练阶段里,
标签没有被拿来当监督信号
笔者在训练机器人模型时也遇到:多模态/多任务训练中的"数据配比"(Dataset Balancing)这是大模型训练中最常说的 Data Sampling。
假设训练一个 VLA 机器人大模型,手头有三种数据:
A 数据集: 互联网上抓取的图文对(如 LAION),有 10 亿条。
B 数据集: 机器人的机械臂抓取仿真数据,有 1000 万条。
C 数据集: 人类专家远程操控机械臂的真实精细数据,只有 5 万条。
如果你不做任何处理(直接顺着数据读),模型会遭遇 数据淹没(Data Overwhelming)。
模型走一万步都在学互联网图文,根本学不到怎么控制机械臂。
这时候的 Data Sampling 策略: 算法工程师会设定采样权重(Sampling Weights)。
比如在每个训练的 Batch(批次)里,强制规定 50 % 50\% 50% 的数据从 A 里面抽, 30 % 30\% 30% 从 B 里面抽, 20 % 20\% 20% 从 C 里面抽。
上采样(Up-sampling): 把数量少但极其珍贵的数据(如 C)重复抽取、反复喂给模型。
下采样(Down-sampling): 把数量巨大、信息冗余的数据(如 A)只抽取一小部分使用,避免模型被喂吐。
这也是笔者在训练时遇到的多莫太训练时 有2万多行的 python 数据配置文件
训练方式
虽然第三部分数据本身带标签,但 DINOv3 主训练阶段仍然采用自监督目标: L D I N O + L i B O T + 0.1 L D K o l e o L_{DINO}+L_{iBOT}+0.1L_{DKoleo} LDINO+LiBOT+0.1LDKoleo,不是做监督分类训练。
3.2 contribution(ii): Large-Scale Training with Self-Supervision
zhezhangjie1DINOv3 在不使用监督标签的前提下,怎样把 SSL 扩展到更大的模型和更大的数据规模,并且让模型同时保住全局与局部特征质量?

curated data: 精选数据,去噪数据或者人工帅选清洗后的数据.这里是精心筛选过滤清洗和结构化处理的数据
weakly-supervision: (弱监督模型): 利用不完全的,不准确, 不精确或含有噪声的标签来训练的机器学习模型 , 弱监督学习通常体现在以下三个维度. 我们用找出图片中的毛
global task: Global Task(全局任务): 模型需要去观察整张图片(全局裁剪,通常包含物体的大部分甚至全部)。VLA(Vision-Language-Action) 或具身智能(Embodied AI)路线中,Global Task 通常指宏观的、长程的(Long-horizon)高级指令目标。
机器人任务是分层级的:
Global Task(全局任务): 人类下达的抽象、宏观指令。例如:"帮我把厨房清理干净" 或者 "去冰箱里拿一瓶可乐放到桌子上"。
Local/Sub-Task(局部/子任务): 为了完成全局任务,规划器(Planner)拆解出的一步步微观操作。
例如:1. 移动到冰箱前;2. 伸手开冰箱门;3. 识别可乐位置;4. 抓取可乐...。
在架构上,通常由一个大语言模型(如 GPT-4, Llama)负责理解 Global Task 并进行任务拆解(Task Planning),再由底层的 VLA 动作策略网络(Policy)去具体执行每一个 Local Action。
本段论文指出: 过去很多SSL模型虽然展示了一些有趣性质,但是并没有真正扩展到更大的模型规模.
原因有两点: 1 训练稳定性 2 训练方案过于简单. 就算是训练上规模,也未必一定变得很好. 一个重要的例外是 1.1B 的 DINOv2, 在经过curated data 训练后,能达到CLIP这类 weakly-supervised 模型的表现; 但是 把DINOV2 扩展到7B 的时,gloabal tasks 上表现不错,但是 dense prediction 上不理想.
3.2.1 Learning Objective :核心学习目标与损失函数的融合
论文在 3.2 的开头重新规范了基础的自监督多任务损失函数。
它指出 DINOv3 采用的预训练总目标( L Pre \mathcal{L}_{\text{Pre}} LPre)完美融合了三大支柱:
DINO Loss:
负责全局 CLS Token 的特征级最优传输与在线聚类分配(通过 Sinkhorn-Knopp 实现)。
iBOT Loss:
负责补丁级别(Patch-level)的掩码图像建模(MIM)重建。
KoLeo Regularization:
作为正则化项,以 0.1 0.1 0.1 的权重系数引入( L Pre = L DINO + L iBOT + 0.1 L KoLeo \mathcal{L}{\text{Pre}} = \mathcal{L}{\text{DINO}} + \mathcal{L}{\text{iBOT}} + 0.1 \mathcal{L}{\text{KoLeo}} LPre=LDINO+LiBOT+0.1LKoLeo),强制令 Batch 内的全局类 Token 在高维超球面上均匀平摊。物理意义与贡献:这种融合保证了模型在 7B 参数量的大规模吞吐下,能够同时兼顾宏观语义判别、微观空间上下文补全以及防止特征扎堆退化。
前面有详细讲解,不赘述
3.3 Gram Anchoring
作者发现:
在之前的 DINOv2 或 7B 级别的巨型 Vision Transformer(ViT)长时间训练中,研究人员发现了一个诡异的黑天鹅现象:随着训练步数(Iterations)无限拉长,模型的全局语义指标(如 ImageNet 分类)越来越强,但是它的局部密集特征图(用于语义分割、深度估计、3D 空间感知的 Patch 特征)却开始大面积摆烂、散架、充斥着高范数的离群尖峰噪声。
提取"空间几何相似度":Gram 矩阵的计算
Gram Anchoring 的核心,是把这个 N, D 的特征矩阵做一次自内积(Self-Inner Product): G = X X T \mathbf{G} = \mathbf{X} \mathbf{X}^T G=XXT维度对账:N, D 乘以 D, N,最终得到的 Gram 矩阵 G \mathbf{G} G 形状是 N, N。物理语义:这个 N, N 的矩阵里,每一个元素 G i , j G_{i,j} Gi,j 代表的是图片内部第 i i i 个小方块和第 j j j 个小方块之间的相对相似度(纹理、几何、协方差结构)。它抛弃了绝对的特征数值,死死锁定了图像内部各个局部之间的相对几何骨架。
时间上的"跨时空锚定"
在 7B 巨量训练的早期(约 100 万步时),模型的密集特征是最清白、局部辨识度最高、最没有噪声的。Gram 老师 (Gram Teacher):Meta 将这个早期最完美的模型权重"冻结存盘",作为绝对不会被带偏的"高维几何判官"。
计算 Loss:在接下来的中后期训练中(Stage 2),对于同一个 Batch 的同一张图:
用早期的 Gram Teacher 算出一个完美的历史骨架: G past \mathbf{G}_{\text{past}} Gpast
用当前正在训练、容易退化的当前模型算出一个实时骨架: G current \mathbf{G}_{\text{current}} Gcurrent
惩罚约束:强制要求当前的骨架去对齐过去的骨架。
L Gram = 1 N 2 ∑ i = 1 N ∑ j = 1 N ( G i , j past − G i , j current ) 2 \mathcal{L}{\text{Gram}} = \frac{1}{N^2} \sum{i=1}^N \sum_{j=1}^N (G^{\text{past}}{i,j} - G^{\text{current}}{i,j})^2 LGram=N21∑i=1N∑j=1N(Gi,jpast−Gi,jcurrent)2
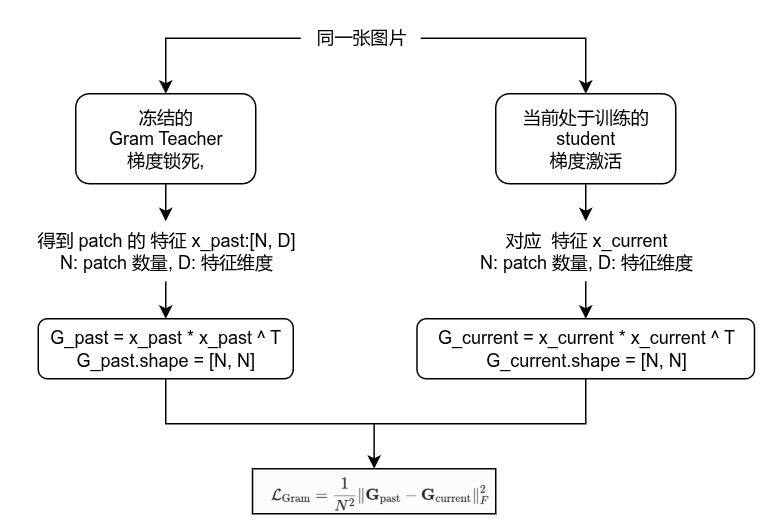
其实说白了: 该机制利用矩阵矩阵的 Frobenius 范数(矩阵欧氏距离)计算双侧 Gram 矩阵的残差
此时 refine 阶段的 total loss 就是:
L R e f = w D L D I N O + L i B O T + w D K L D K o l e o + w G r a m L G r a m L_{Ref}=w_{D} L_{DINO}+L_{iBOT}+w_{DK}L_{DKoleo}+w_{Gram}L_{Gram} LRef=wDLDINO+LiBOT+wDKLDKoleo+wGramLGram
论文后来还很严谨的补上消融实验:
选 100k 或 200k 的 Gram teacher,差别不大, 但如果选一个很晚的 Gram teacher(例如 1M)反而会变差
因为那个时候 teacher 自己的 patch-level consistency 已经不行了。
这再次说明:Gram Anchoring 之所以有效,关键就在于它用的是"早期还健康的局部结构"。
3.4 Updated Model Architecture
为了让 7B 巨量网络平稳落地并具备真正的空间 3D 感知能力,3.2 小节阐述了架构上的关键革新:
引入轴向旋转位置编码 (Axial RoPE):彻底抛弃了传统的二维绝对/相对位置编码,将 LLM 领域大获成功的旋转位置编码(RoPE)沿图像的高、宽双轴(Axial)进行解耦与适配。
RoPE-box Jittering (位置编码框抖动正则化):在训练时配合边界框的随机抖动,强制模型学习对尺度连续缩放、平移不敏感的相对几何空间关系,主要是为了解决多尺度 crop 下的位置编码对齐与泛化问题,
让模型更关注 crop 内 patch 的相对几何关系,提升不同裁剪、尺度、分辨率下的空间表征稳定性。
寄存器 Token (Register Tokens):在 ViT 架构中引入了 4 个专门的 Register Tokens(DINOv3 最终的 Token 构成为 1 个 CLS Token + 4 个 Register Tokens + 196 个 Patch Tokens)。
贡献点:这些寄存器 Token 能够主动吸走深层网络中由于注意力机制产生的异常高范数噪声点,防止噪声毒化正常的 Patch 补丁特征。
3.4.0 Axial-RoPE
先提一嘴 ROPERoPE(比如 LLaMA 里的标准文本 RoPE)的底层特征通道配对机制。
假设一个 Token 的特征向量维度是 D = 64 D = 64 D=64。
为了把它放到复数空间里去旋转,一维 RoPE 会把这 64 个维度两两结对(分成 32 组复数平面):
维度 0 , 1 0, 1 0,1 组成第 1 个复数平面,乘以频率 ω 1 \omega_1 ω1
维度 2 , 3 2, 3 2,3 组成第 2 个复数平面,乘以频率 ω 2 \omega_2 ω2 ... \dots ...
维度 62 , 63 62, 63 62,63 组成第 32 个复数平面,乘以频率 ω 32 \omega_{32} ω32
这个"两两配对算旋转"是 RoPE 这项技术与生俱来的基础底层算子。
不管是处理文本的一维 RoPE,还是处理图像的二维、三维 RoPE,内部都在用这种两两配对的方式做矩阵乘法。
如果只有 RoPE
如果我们要把图像(2D)喂给 ViT,最原始的做法是把图像扁平化(Flatten)成一条线。
比如把 14 × 14 14 \times 14 14×14 的图像网格硬生生拉成一条包含 196 个 Patch 的"一维长线"。 那么遇到换行的token时看起来距离较远,但是 图像上实则相邻的情况信息就丢了。
现在我们假设在某个训练步,图像切成了很多 Patch。其中第 5 个 Patch(假设它在图像里的物理坐标是 x = 0.8 , y = 0.2 x=0.8, y=0.2 x=0.8,y=0.2)。
这个 Patch 的特征向量(Query)从前面的 ViT 主干网络里传过来,维度 D = 4 D=4 D=4: q = 0.15 , − 0.42 , 0.88 , − 0.11 \mathbf{q} = 0.15, -0.42, 0.88, -0.11 q=0.15,−0.42,0.88,−0.11此时,这 4 个数字完全不知道自己身处何方,它们只代表这个 Patch 里的纹理语义。
目前没有任何xy坐标信息, 怎么加入?毕竟 token是不知道自己信息的
Axial RoPE 强行加入 2D 信息
现在,Axial 硬性规定前 2 个维度归 x x x 管,后 2 个维度归 y y y 管。
(1) 处理前一半通道 0.15 , − 0.42 0.15, -0.42 0.15,−0.42(水平方向):
step1:
代码把这个 Patch 的水平坐标 x = 0.8 x=0.8 x=0.8 拿过来。
step2:
乘以一个基频(假设 ω = 1.0 \omega=1.0 ω=1.0),算出旋转角度: θ x = 0.8 × 1.0 = 0.8 弧度 \theta_x = 0.8 \times 1.0 = 0.8 \text{ 弧度} θx=0.8×1.0=0.8 弧度。
step3:
计算正余弦: cos ( 0.8 ) ≈ 0.70 , sin ( 0.8 ) ≈ 0.72 \cos(0.8) \approx 0.70, \sin(0.8) \approx 0.72 cos(0.8)≈0.70,sin(0.8)≈0.72。
step4:
注入 x x x 信息:让前两个维度的数字与 x x x 算出来的正余弦进行矩阵乘法: ( q ~ 0 q ~ 1 ) = ( 0.70 − 0.72 0.72 0.70 ) ( 0.15 − 0.42 ) = ( 0.41 − 0.19 ) \begin{pmatrix} \tilde{q}_0 \\ \tilde{q}_1 \end{pmatrix} = \begin{pmatrix} 0.70 & -0.72 \\ 0.72 & 0.70 \end{pmatrix} \begin{pmatrix} 0.15 \\ -0.42 \end{pmatrix} = \begin{pmatrix} 0.41 \\ -0.19 \end{pmatrix} (q~0q~1)=(0.700.72−0.720.70)(0.15−0.42)=(0.41−0.19)看这里!原本清白的数字 0.15 , − 0.42 0.15, -0.42 0.15,−0.42 变成了 0.41 , − 0.19 0.41, -0.19 0.41,−0.19。这两个新数字的体内,已经混合了 x = 0.8 x=0.8 x=0.8 的空间几何基因。
(2) 处理后一半通道 0.88 , − 0.11 0.88, -0.11 0.88,−0.11(垂直方向):
step5:
代码把这个 Patch 的垂直坐标 y = 0.2 y=0.2 y=0.2 拿过来。
step6:
乘以同样的基频,算出旋转角度: θ y = 0.2 × 1.0 = 0.2 弧度 \theta_y = 0.2 \times 1.0 = 0.2 \text{ 弧度} θy=0.2×1.0=0.2 弧度。
step7:
计算正余弦: cos ( 0.2 ) ≈ 0.98 , sin ( 0.2 ) ≈ 0.20 \cos(0.2) \approx 0.98, \sin(0.2) \approx 0.20 cos(0.2)≈0.98,sin(0.2)≈0.20。
step8:
注入 y y y 信息:让后两个维度的数字去乘以由 y y y 算出来的正余弦: ( q ~ 2 q ~ 3 ) = ( 0.98 − 0.20 0.20 0.98 ) ( 0.88 − 0.11 ) = ( 0.88 0.07 ) \begin{pmatrix} \tilde{q}_2 \\ \tilde{q}_3 \end{pmatrix} = \begin{pmatrix} 0.98 & -0.20 \\ 0.20 & 0.98 \end{pmatrix} \begin{pmatrix} 0.88 \\ -0.11 \end{pmatrix} = \begin{pmatrix} 0.88 \\ 0.07 \end{pmatrix} (q~2q~3)=(0.980.20−0.200.98)(0.88−0.11)=(0.880.07)
看这里!后两个维度的体内,混合了 y = 0.2 y=0.2 y=0.2 的空间几何基因。这里面压根没有发生任何 x x x 的计算!
(3)拼装结果:带有空间烙印的高维 Token最后,代码把这两组经过不同坐标洗礼的数字重新拼接(Concat)起来,得到了最终的: q final = 0.41 , − 0.19 , 0.88 , 0.07 \mathbf{q}_{\text{final}} = 0.41, -0.19, 0.88, 0.07 qfinal=0.41,−0.19,0.88,0.07
这样 Axial RoPE 的 前一半和 x x x 相关,后一半和 y y y 相关".
如果有人偷偷把这个 Patch 的水平坐标从 x = 0.8 x=0.8 x=0.8 改成了 x = 0.1 x=0.1 x=0.1,那么前一半的数字 0.41 , − 0.19 0.41, -0.19 0.41,−0.19 会发生剧烈改变,而后一半的数字 0.88 , 0.07 0.88, 0.07 0.88,0.07 纹丝不动。
3.4.1 RoPE-box
现在讲解 RoPE-box.
RoPE -box 取代 Axial-RoPE 的原因不是因为 Axial-RoPE算力过高 而是 多尺度输入的坐标对齐问题.
在 DINO 的预训练中,每一张原始图片(假设原图是 1000 × 1000 1000 \times 1000 1000×1000 像素),在被喂给 GPU 之前,Data Loader 会对它进行极其非常庞大的随机裁剪.
假设 deta loader 一次性生成 10 个不同的边界框(Crops):
2 个大图(Global Crops,如 224 × 224 224 \times 224 224×224):随机切出原图 80% 的区域。
大图 1 的物理边界框:从原图的 ( x : 0 ∼ 800 , y : 0 ∼ 800 ) (x: 0\sim800, y: 0\sim800) (x:0∼800,y:0∼800) 切下来,然后缩放到 224 × 224 224 \times 224 224×224。
大图 2 的物理边界框:从原图的 ( x : 200 ∼ 1000 , y : 200 ∼ 1000 ) (x: 200\sim1000, y: 200\sim1000) (x:200∼1000,y:200∼1000) 切下来,然后缩放到 224 × 224 224 \times 224 224×224。
8 个小图(Local Crops,如 96 × 96 96 \times 96 96×96):随机切出原图 10% ∼ \sim ∼ 30% 的局部区域。
小图 1 的物理边界框:可能切自原图的 ( x : 100 ∼ 300 , y : 150 ∼ 350 ) (x: 100\sim300, y: 150\sim350) (x:100∼300,y:150∼350),缩放到 96 × 96 96 \times 96 96×96。
小图 2 的物理边界框:可能切自原图的 ( x : 500 ∼ 700 , y : 400 ∼ 600 ) (x: 500\sim700, y: 400\sim600) (x:500∼700,y:400∼600),缩放到 96 × 96 96 \times 96 96×96。
果没有 RoPE-box
没有 RoPE-box ,网络要让大图 1 吐出的特征和小图 1 吐出的特征在 Loss 特征近似(也就是小图表示的区域能在大图中对其)。如果使用传统的绝对位置编码,为了让模型知道它们之间的空间相对关系,程序必须在 GPU 内部执行以下三步频繁的坐标变换与对齐:
以下面流程为例, 我们有多个batch 时, 每个 batch 因为 crop的图片不一样, 那么 需要重新计算 cos 和 sin 来对其绝对世界坐标以保证loss有效对齐
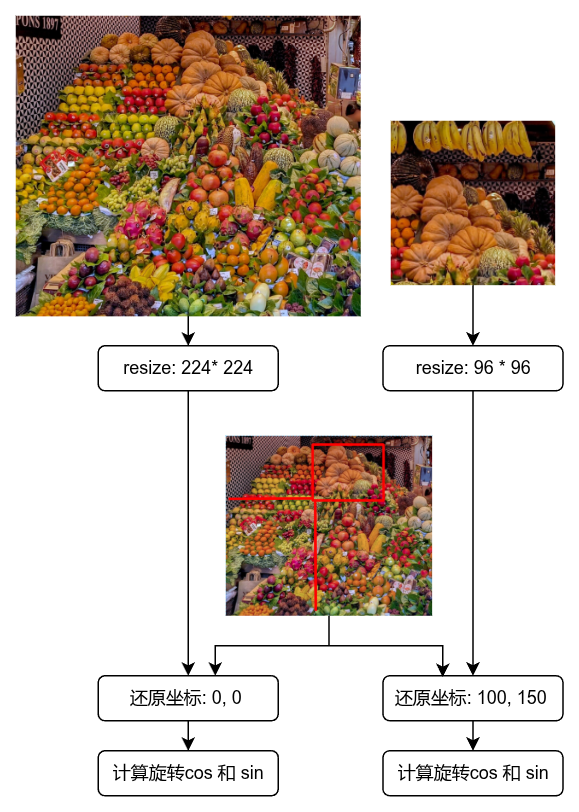
RoPE-box 则不需要
RoPE-box 规定,大图不管怎么切:
(1) 废除动态计算:
大图的 Patch 坐标永远是静态固定的 Grid_14x14(归一化到 − 1 , 1 -1, 1 −1,1);
小图也永远是静态固定的 Grid_6x6。
这两组网格在训练前就初始化好了,整个预训练几百万步里再也不用重算。
(2)用极其廉价的线性代数代替反向投影:
大图和小图之间因为物理裁剪产生的空间错位和尺度差异,不再需要大费周章地去做高维的反向投影对齐。因为坐标被限制在了 − 1 , 1 -1, 1 −1,1 的统一盒子里,大图和小图的相对位置差异,在数学上直接坍缩成了一个极其性感的一维线性缩放平移算子:
r ~ = s ⋅ r + t \tilde{\mathbf{r}} = s \cdot \mathbf{r} + \mathbf{t} r~=s⋅r+t
其中 s s s 和 t \mathbf{t} t 就是这个边界框的缩放比和平移常数。
网络只需要给大图的静态网格乘上大图的 s 1 , t 1 s_1, \mathbf{t}_1 s1,t1,
给小图的静态网格乘上小图的 s 2 , t 2 s_2, \mathbf{t}_2 s2,t2,
一次性的矩阵乘加,直接在最底层的连续频域里完成了空间对齐。
这里的 r ~ = s ⋅ r + t \tilde{\mathbf{r}} = s \cdot \mathbf{r} + \mathbf{t} r~=s⋅r+t就是后面要说的 jittering 这玩意有两个好处
3.4.2 RoPE-box jittering
如果说 Gram Anchoring 是为了解决长周期训练的特征退化,那么 RoPE-box jittering 的使命则是:让 7B 级别的大模型彻底摆脱固定分辨率的束缚,获得极强的零样本分辨率自适应能力(Resolution Invariance)和连续 3D 几何空间感知。上面搞懂了ROPE-box 现在 我们看下jittering 是做什么的.
Jittering(抖动正则化)算子的本质是一种向位置编码信号中主动引入"连续噪声(Continuous Noise)"的低频平滑算子.Jittering 算子干的事情,就是在前向传播(Forward)的瞬间,强行破坏这个固定的、死板的坐标,让它产生随机抖动。所以干这么两个事情:
(1) 尺度空间抖动(Scale Jittering)在训练的每一步,从连续均匀分布中采样一个随机缩放因子 s:
s ∼ U ( s min , s max ) ( 例如 U ( 0.5 , 2.0 ) ) s \sim U(s_{\min}, s_{\max}) \quad (\text{例如 } U(0.5, 2.0)) s∼U(smin,smax)(例如 U(0.5,2.0))
令所有的相对坐标统一乘以这个因子:
r ~ i = s ⋅ r i \tilde{\mathbf{r}}_i = s \cdot \mathbf{r}_i r~i=s⋅ri
(2) 偏移空间抖动(Translation Jittering / Shift)在某些更严谨的实现中,还会加入一个随机平移向量 t = ( Δ x , Δ y ) \mathbf{t} = (\Delta x, \Delta y) t=(Δx,Δy): r ~ i = s ⋅ r i + t \tilde{\mathbf{r}}_i = s \cdot \mathbf{r}_i + \mathbf{t} r~i=s⋅ri+t
如果只是之前固定分辨率, 那么模型背图很厉害 之记住了之前高频关系. 如果给如不同分辨率(下图蓝色点是resize 的新的像素点), 模型是不能处理新的高频关系(如下图蓝色箭头)
当我们加入了jittering 后,就会造出更多新的高频关系,那么这样就可以防止模型被图,
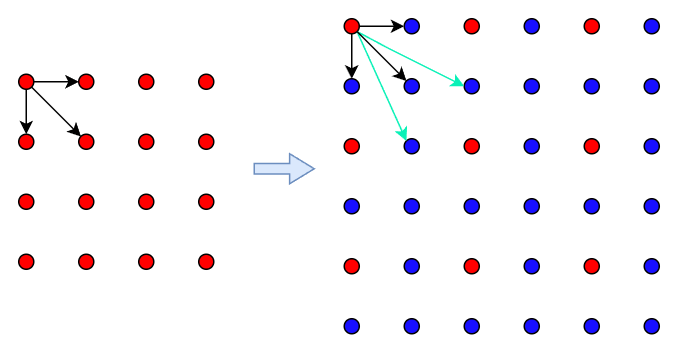
4 工业落地
在自动驾驶、工业检测等需要极其追求高吞吐量、低延迟(Low Latency)、低功耗的边缘场景中,经典的 CNN(纯卷积架构,如 ConvNeXt) 依然占据着不可动摇的霸主地位。
(1) ViT 的硬件劣势:ViT 的自注意力机制(Self-Attention)计算复杂度与 Patch 数量呈二次方增长( O ( N 2 ) \mathcal{O}(N^2) O(N2))。而且 ViT 内部大量不规则的张量切片、重组(如经常做 Permute、Reshape、高维矩阵相乘),在车载或边缘芯片的硬件流水线里执行效率极低。
(2) ConvNeXt 的硬件优势:ConvNeXt 采用纯卷积(Convolution)和池化(Pooling)操作,硬件对它的算子优化到了极致。它在端侧芯片上的跑数速度极快,显存占用极小,天生就是为了工业落地而生的"牛马"架构。
(3) CNN 致命硬伤:由于缺少了全局注意力,传统的 CNN 感受野是局部的。在自监督预训练中,CNN 很难自己学到那种具有 3D 物理大局观、对未知分辨率和长宽比免疫的高级相对几何表征能力。
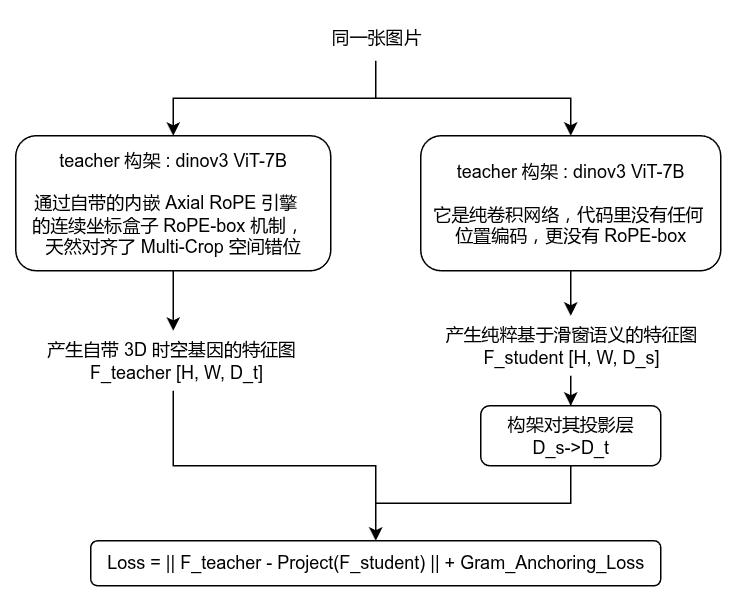
如何蒸馏?
DINOv3 的解法:ViT teacher,ConvNeXt students
跨架构自监督特征蒸馏(Cross-Architecture Feature Distillation)
流程如下图
总结
(1) RoPE-box jittering 强制模型学习相对几何关系,不学习绝对位置,就是不背图.
(2) gram anchoring 在 refine 阶段接近早期较健康 teacher 的 Gram matrix,从而抑制 dense feature map 在长训练中的结构退化和噪声化。
(3) DINO 是训练法,ViT 是模型;DINO 常用 ViT 训练,但不限定必须是 ViT
(4) dino loss, ibot loss DKeleo loss
(5) 3个监督学习的死穴
(6) refine loss
(7) 如何蒸馏