目录
[1.1 DINOV2 的整体框架:Teacher-Student 架构的升级版](#1.1 DINOV2 的整体框架:Teacher-Student 架构的升级版)
[1.2 DINOV2 中的 Transformer 架构](#1.2 DINOV2 中的 Transformer 架构)
[1.3 对比学习机制:让 Student 模型向 Teacher 模型看齐](#1.3 对比学习机制:让 Student 模型向 Teacher 模型看齐)
[1.4 DINOV2 中的 Loss](#1.4 DINOV2 中的 Loss)
[1.5 Teacher 和 Student 模型之间的---知识蒸馏策略](#1.5 Teacher 和 Student 模型之间的---知识蒸馏策略)
[2.1 DINOV3中的改进](#2.1 DINOV3中的改进)
[1)Gram Anchoring](#1)Gram Anchoring)
[2)Axial RoPE (Rotary Positional Embeddings)](#2)Axial RoPE (Rotary Positional Embeddings))
[2.2 DINOV1/V2/V3 的改进之处对比](#2.2 DINOV1/V2/V3 的改进之处对比)
DINO 算法在自监督学习领域具有里程碑性质的意义,本文主要介绍 DINOV2 的算法原理及创新点分析。
一、DINOV2算法原理细节详解
1.1 DINOV2 的整体框架:Teacher-Student 架构的升级版
DINO V2 的整体框架,其实可以看作是 DINO (Distillation with No labels) 算法的"升级版"。DINO 算法本身就采用了 Teacher-Student 的知识蒸馏框架,而 DINO V2 在此基础上进行了多方面的改进和优化,使其性能更上一层楼。
**Teacher-Student 架构中,Teacher 模型和 Student 模型都是 Transformer 架构,**老师模型 (Teacher Model) 比较强大,负责生成"知识"(通常是模型的输出,例如特征向量或概率分布),学生模型 (Student Model) 比较弱小,负责向老师学习"知识",并努力模仿老师的行为。
具体如下图所示:
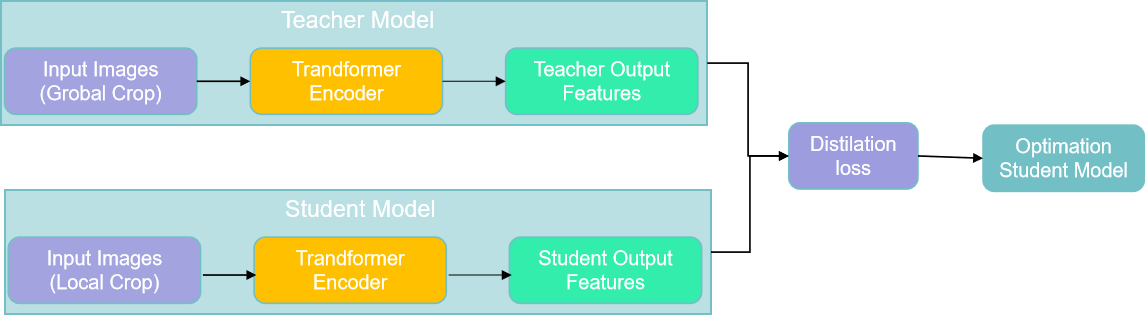
从图中我们可以看到:
- 输入图像 (Input Image): DINO V2 的输入是一张图像。为进行自监督学习,DINO V2 采用了 Multi-Crop Augmentation (多裁剪增强) 的策略,对同一张图像裁剪出多个不同的 views (视角)。这些 views 分为两类:
-
Global Crop (全局裁剪): 通常是较大尺寸的裁剪,例如 224x224 或 256x256,用于提供图像的全局信息。Global Crop 会被输入到 Teacher 模型中。
-
Local Crops (局部裁剪): 通常是较小尺寸的裁剪,例如 96x96 或 112x112,用于提供图像的局部细节信息。Local Crops 会被输入到 Student 模型中。
-
Transformer Encoder (Transformer 编码器): Teacher 模型和 Student 模型都使用 Transformer Encoder 作为 backbone (骨干网络)。Transformer Encoder 的作用是将输入的图像 patches (图像块) 转换为特征向量。
-
Teacher Output & Student Output (Teacher 和 Student 模型的输出): Teacher 模型和 Student 模型分别将输入的 Global Crop 和 Local Crops 编码成特征向量,作为各自的输出。
-
Distillation Loss (蒸馏损失): DINO V2 的核心是知识蒸馏。它通过计算 Teacher 模型和 Student 模型输出特征之间的 Distillation Loss,来指导 Student 模型的学习。Distillation Loss 目的是让 Student 模型的输出尽可能地接近 Teacher 模型的输出,从而让 Student 模型学习到 Teacher 模型的"知识"。
-
Optimize Student Model (优化 Student 模型): 通过最小化 Distillation Loss,DINO V2 使用梯度下降等优化算法来更新 Student 模型的参数,使其不断地逼近 Teacher 模型。
Teacher 模型的参数更新方式与 Student 模型不同: DINO V2 并没有直接使用梯度下降来更新 Teacher 模型的参数,而是采用了 Exponential Moving Average (EMA,指数移动平均) 的策略。具体来说,Teacher 模型的参数是 Student 模型参数的 EMA 版本,即 Teacher 模型的参数会缓慢地向 Student 模型的参数靠拢,但又不会完全相同。这种 EMA 更新策略能够有效地稳定 Teacher 模型的训练,并提高模型的泛化能力。
总结一下,DINO V2 的整体框架可以概括为: 使用 Teacher-Student 架构,Teacher 模型处理 Global Crop,Student 模型处理 Local Crops,通过 Distillation Loss 来指导 Student 模型的学习,Teacher 模型的参数通过 EMA 方式更新。这种框架的设计,使得 DINO V2 能够有效地从无标注数据中学习到高质量的视觉特征。
1.2 DINOV2 中的 Transformer 架构
Transformer 模型的核心组件是 Self-Attention 自注意力机制)。自注意力机制能够让模型在处理序列数据 (如文本) 时,动态地关注序列中不同位置的信息,从而更好理解序列的上下文关系。Transformer 的基本结构可以概括为: Encoder (编码器) 和 Decoder (解码器) 两部分:Encoder 负责将输入序列编码成一个固定长度的向量表示,Decoder 负责将这个向量表示解码成目标序列。在 DINO V2 中,我们主要使用的是 Transformer Encoder 部分。
Transformer Encoder 的基本组成单元是 Transformer Block (Transformer 块)。 一个 Transformer Block 通常包含两个子层:
-
Multi-Head Self-Attention (多头自注意力): 这是 Transformer 的核心组件。多头自注意力机制能够让模型并行地学习多个不同的注意力分布,从而更全面地捕捉输入序列的信息。
-
Feed-Forward Network (前馈神经网络): 这是一个简单的两层全连接神经网络,用于对自注意力层的输出进行非线性变换。
Transformer Block 的结构可以用下图表示:

在 DINO V2 中,Transformer Encoder 被应用于图像处理。 为了将 Transformer 应用于图像,DINO V2 首先将输入图像划分为一个个小的 patches (图像块)。例如,对于一张 224x224 的图像,可以将其划分为 16x16 个 14x14 的 patches。然后将每个 patch 展平成一个向量,作为 Transformer Encoder 的输入序列。
DINO V2 使用的 Transformer Encoder 结构与 Vision Transformer (ViT) 类似。 ViT 是 Google 提出的将 Transformer 应用于图像分类的经典模型。ViT 的结构非常简洁,主要由以下几个部分组成:
-
Patch Embedding (图像块嵌入): 将输入图像划分为 patches,并将每个 patch 展平成向量,然后通过一个线性层进行 embedding (嵌入),得到 patch embedding。
-
Positional Encoding (位置编码): 由于 Transformer 的自注意力机制是位置无关的,为了让模型感知到 patches 的位置信息,需要添加 positional encoding。ViT 使用的是可学习的 positional encoding。
-
Transformer Encoder Layers (Transformer 编码器层): 由多个 Transformer Block 堆叠而成。
-
Classification Head (分类头): 对于图像分类任务,ViT 通常会在 Transformer Encoder 的输出上添加一个简单的分类头,例如一个线性层或 MLP (多层感知机)。
DINO V2 使用的 Transformer Encoder 结构与 ViT 类似,但也有一些不同之处。 例如,DINO V2 并没有使用 ViT 的 classification head,而是直接使用 Transformer Encoder 的输出特征进行自监督学习。此外,DINO V2 在 Transformer Encoder 的结构细节上可能也进行了一些调整和优化,以更好地适应自监督学习任务。1
1.3 对比学习机制:让 Student 模型向 Teacher 模型看齐
DINO V2 的核心思想是知识蒸馏,在 DINO V2 中,它采用了 Contrastive Learning (对比学习) 的机制来实现知识蒸馏。
对比学习是一种自监督学习方法,它的核心思想是 "物以类聚,人以群分"。简单来说,就是将相似的样本拉近,将不相似的样本推远。在图像领域,我们可以认为同一张图像的不同 views 是相似的,而不同图像的 views 是不相似的。
DINO V2 将对比学习应用于知识蒸馏的做法是:
-
Teacher 模型和 Student 模型分别处理同一张图像的不同 views。 Teacher 模型处理 Global Crop,Student 模型处理 Local Crops。
-
**Teacher 模型和 Student 模型分别输出特征向量。**Teacher 输出特征向量 zt,Student 输出特征向量 zs。
-
**DINO V2 定义了一个 Contrastive Loss (对比损失)**来衡量 zt 和 zs 之间的距离。 Distillation Loss 其实就是一种 Contrastive Loss。。
1.4 DINOV2 中的 Loss
在 Loss 设计上,它引入了 iBOT (Image BERT Pre-training with Online Tokenizer) 的思想。
DINOv2 的总 Loss 由三部分组成:
1)损失
DINO V2 使用的 Contrastive Loss 是 Cross-Entropy Loss (交叉熵损失) 的变体。
在分类任务中,Cross-Entropy Loss 通常用于衡量模型预测的概率分布与真实标签之间的差异。 假设模型预测的概率分布为p = p_1, p_2, ..., p_C,真实标签的 one-hot 向量为 q = q_1, q_2, ..., q_C,其中 C 是类别数。则 Cross-Entropy Loss 定义为:
而在 DINO V2 中将 Cross-Entropy Loss 应用于特征向量之间的对比学习。 具体来说,对于 Teacher 模型输出的特征向量 z_t和 Student 模型输出的特征向量z_s,DINO V2 首先对它们进行 softmax 归一化,得到概率分布 P_t和P_s。然后,DINO V2 将 P_t 作为"伪标签",使用 Cross-Entropy Loss 来衡量P_s和 P_t 之间的差异。
其中:
-
是 Student 模型输出的
-
-
-
该 Loss 函数的含义是 :对于 Student 模型输出的每个 Local Crop 特征向量 ,我们希望它能够"预测"出 Teacher 模型输出的 Global Crop 特征向量
,我们希望两者之间的相似度尽可能高,而
和其他特征向量
(包括其他 Teacher 和 Student模型的输出)之间的相似度尽可能低。
为进一步提高模型性能,DINO V2 在 Contrastive Loss 中还引入了两个重要技巧:
(1)Centering(中心化):在计算 softmax 之前,DINO V2 对 Teacher 模型的输出特征向量 进行了中心化处理。具体来说,对于 Teacher 模型的输出特征向量
,DINO V2 计算其均值
,然后将
减去
,得到中心化后的特征向量
。中心化的目的是防止模型 collapse(坍塌),即所有样本的特征向量都聚集到同一个点。
(2)Sharpening(锐化):DINO V2 对 Teacher 模型的输出概率分布 进行了锐化处理。具体来说,对于 Teacher 模型的输出概率分布
,DINO V2 使用一个更小的 temperature 参数
来计算 Student 模型的概率分布
。锐化的目的是让 Teacher 模型的概率分布更加 sharp(尖锐),从而提供更明确的学习目标给 Student 模型。
结合 Centering 和 Sharpening,DINO V2 的 Contrastive Loss 可以表示为:
其中 是对应特征向量
的均值(如果 来自 Teacher 模型,则
,如果
来自 Student 模型,则
)。
2)iBOT Loss
这是提升密集预测(Dense Prediction)能力的关键。
-
操作:对 Student 的输入进行 随机 Masking(类似 MAE,遮挡部分 Patch)。
-
目标:Teacher 看到完整的图,Student 必须根据上下文,补全被 Mask 掉的 Patch 的特征。
-
区别于 MAE:MAE 预测的是像素值(Pixel reconstruction),而 iBOT 预测的是 Teacher 提取的 特征分布(Feature Softmax)。这让模型学到的是语义而非纹理。
3)KoLeo Regularizer
为了进一步提升特征的利用率,引入了 Kozachenko-Leonenko (KoLeo) 差分熵正则项。
- 作用:它鼓励 Batch 内的样本特征在特征空间中均匀分布(Uniform Span),避免特征簇过度拥挤。
总结一下,DINO V2 的对比学习机制可以概括为: 使用 Cross-Entropy Loss 的变体,将 Teacher 模型的 Global Crop 特征向量作为"伪标签",指导 Student 模型的 Local Crops 特征向量的学习。同时,引入 Centering 和 Sharpening 技巧,进一步提高模型的性能和稳定性。这种对比学习机制,使得 Student 模型能够有效地"看齐" Teacher 模型,学习到高质量的视觉特征。
1.5 Teacher 和 Student 模型之间的---知识蒸馏策略
DINO V2 的核心是知识蒸馏,而对比学习机制只是实现知识蒸馏的一种手段。**知识蒸馏的最终目的是让 Student 模型学习到 Teacher 模型的"知识"。**在 DINO V2 中,"知识"主要指的是 Teacher 模型学习到的 **特征表示 (Feature Representation)**。
**Teacher 模型能够学习到更好的特征表示,**主要归功于以下几个方面:
-
Global View (全局视角): Teacher 模型处理的是 Global Crop,能够获取图像的全局信息,从而更好地理解图像的整体结构和语义内容。
-
EMA Update (指数移动平均更新): Teacher 模型的参数通过 EMA 方式更新,能够有效地稳定训练过程,并提高模型的泛化能力。
-
更大的模型容量 (可能): 在某些情况下,Teacher 模型可能比 Student 模型具有更大的模型容量 (例如,更深的网络结构或更多的参数)。更大的模型容量通常意味着更强的学习能力。
DINO V2 的知识蒸馏策略,有以下几个关键特点:
-
Self-Distillation (自蒸馏): DINO V2 的 Teacher 模型和 Student 模型都是基于同一个网络架构 (Transformer),只是参数更新方式不同。这种 Teacher 模型和 Student 模型来自同一个网络的知识蒸馏方式,被称为 Self-Distillation。Self-Distillation 的优势在于,Teacher 模型和 Student 模型具有相似的特征空间,更容易进行知识迁移。
-
No Labels (无标签): DINO V2 的训练过程完全不需要人工标注的标签,只需要大量的无标注图像数据。这使得 DINO V2 能够充分利用海量的无标注数据,学习到通用的视觉特征。
-
Online Distillation (在线蒸馏): DINO V2 的知识蒸馏过程是 online 的,即 Teacher 模型和 Student 模型是同时训练的。相对于离线蒸馏,Online Distillation 的优势在于 Teacher 模型和 Student 模型可以相互促进,共同进步。
二、DINO系列演变进程中的改进创新
2.1 DINOV3中的改进
1)Gram Anchoring
DINOv3 引入了一个核心创新:Gram Anchoring Loss,其目的就是锁住几何结构。
Gram 矩阵:

锚定机制 (Anchoring):
DINOv3 的策略是:
-
在训练的中途,当 Dense 性能达到峰值时,保存一个 "Gram Teacher"(或者使用 Teacher 的历史版本)。
-
在后续训练中,增加一个约束:Student 的 Patch 特征的 Gram 矩阵,必须与 Gram Teacher 保持一致。
直观理解:类似于给模型加了一个限制条件,可以继续学习更高级的语义(让 Global Loss 变小),但是不能破坏 Patch 之间的相对位置关系和几何结构。
2)Axial RoPE (Rotary Positional Embeddings)
DINOv3 在 Backbone 上也做了针对性修改,传统的绝对位置编码在推理分辨率改变时(如 224 -> 800)性能会剧降。DINOv3 引入RoPE旋转位置编码,改善ViT在长序列中的几何一致性问题,并引入了 Jitter(抖动) 机制。使得模型天然支持任意分辨率输入,无需插值。
3)单教师多学生蒸馏
7B教师模型向多个学生(ViT-S/B/L)蒸馏,提供多种选择,兼顾性能与部署效率。
2.2 DINOV1/V2/V3 的改进之处对比
此处用表格总结DINO系列的改进之处:
|------|--------------------------------|------------------------------------|-------------------------------------------|
| 维度 | DINOV1 | DINOV2 | DINOV3 |
| 核心思路 | Student--Teacher 自蒸馏,global 对齐 | DINOv1 + iBOT:global + patch 预测 | 引入Gram Anchoring解决长训练下结构退化问题 |
| 位置编码 | 绝对、相对位置编码 | 绝对位置编码 | Axial RoPE + Jitter |
| 数据规模 | 以 ImageNet 为主(百万级) | LVD-142M(1.42亿) | Curated Web Data (17亿+) |
| 训练目标 | Global CE | Global CE + iBOT + KoLeo正则 | Global CE + iBOT + KoLeo正则+Gram Anchoring |
| 强项 | ViT 上的自监督分割能力、简洁框架 | 泛化强、任务覆盖面广、真正意义上的视觉基础特征 | 极致(sota), Gram锁结构 |
| 工程优化 | 多 crop + EMA + centering | 再加 FlashAttention / FSDP / 高分辨率收尾等 | FSDP2、fp8训练、高效推理 |
| 适用场景 | 中小规模数据上自监督预训练 | 希望直接用现成 backbone 做各种任务 | |