1. 写在最前面
最近在折腾 AI Agent 的时候,笔者越来越明显地感觉到一个问题:单个 AI 工具再强,也很容易卡在「任务管理」这件事上。
比如让 AI 写一段代码、查一个资料、整理一篇文章,这些都不难。但如果任务稍微变复杂一点,就会出现几个很现实的问题:
-
任务到底分给谁做?
-
做到哪一步了?
-
中间讨论、结论、阻塞原因放在哪里?
-
换一个 Agent 接手时,怎么知道前面发生过什么?
-
如果一个任务要拆成多个子任务,怎么避免大家互相等、互相打架?
以前笔者更多是把这些信息放在聊天记录里,或者自己在本地记个任务清单。短期看还能凑合,时间一长就会变得很乱:上下文散在不同窗口里,AI 说过什么要翻半天,另一个 AI 接手时又要重新解释一遍。
Multica 给笔者的第一感觉,就是它不只是一个「能启动 AI Agent 的工具」,而是把 AI Agent 放进了一个更接近真实研发协作的工作台里:有 workspace,有 issue,有 agent,有 comment,有 metadata,也有本地 runtime。
注:本文基于笔者本机使用的
multica 0.3.10和一次真实 issue 执行过程整理。Multica 还在快速迭代,具体命令建议以multica --help为准。
2. Multica 是什么
2.1 一句话理解
Multica 可以简单理解为:一个面向 AI Agent 协作的工作空间和任务调度平台。
它不是单纯的聊天工具,也不是单纯的代码编辑器。更准确地说,它像是把这些东西组合到一起:
-
用 issue 描述任务;
-
用 agent 执行任务;
-
用 comment 保留过程和结果;
-
用 status 标记任务进度;
-
用 metadata 记录少量关键上下文;
-
用本地 daemon 负责真正启动和管理 Agent runtime。
如果只看界面,它有点像一个轻量的任务系统;如果从 Agent 执行角度看,它更像一个「AI 任务派发中心」。
2.2 它解决的核心问题
笔者觉得 Multica 主要解决三个问题。
第一,任务有了稳定入口。
以前让 AI 干活,经常是一段 prompt 直接丢进对话框。问题是这个 prompt 没有生命周期,做完就散了。Multica 里任务会落到 issue 上,issue 有标题、描述、状态、评论、附件和元数据,后续回看会清楚很多。
第二,Agent 有了可管理的身份。
在 Multica 里,Codex、Claude、Hermes、Kiro 这类 Agent 都可以是 workspace 里的成员。每个 Agent 有自己的运行时、模型、技能和状态。这样分工就更自然:这个任务给 Codex,那篇调研给 Hermes,某个 review 交给另一个 Agent。
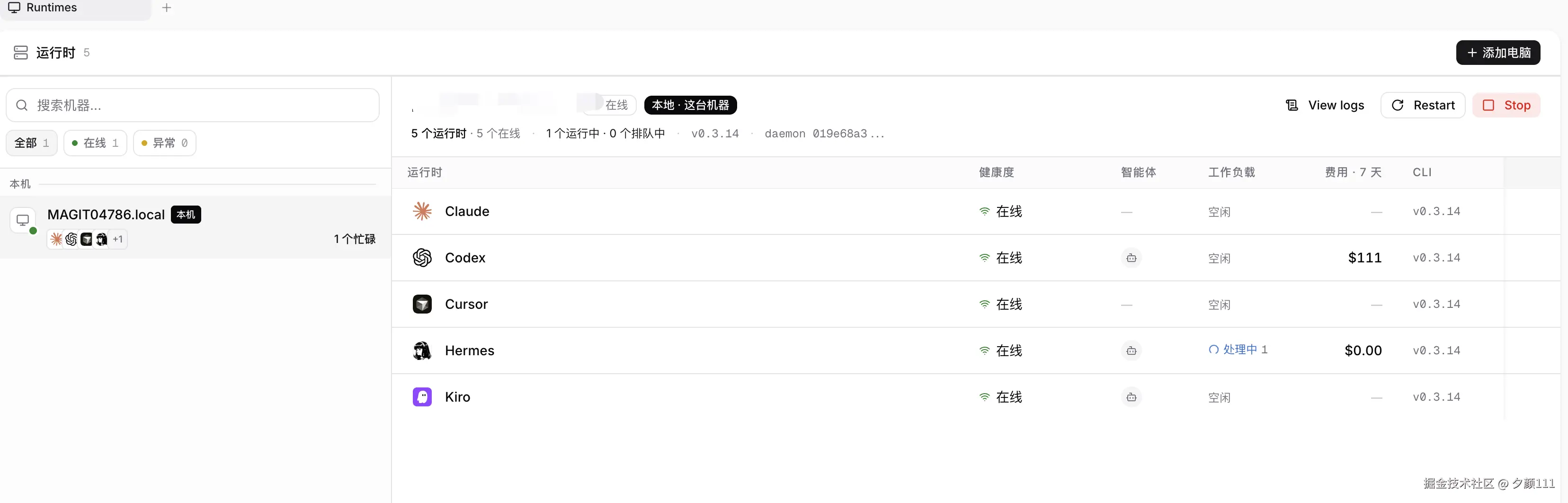 第三,协作过程不再只靠聊天记录。
第三,协作过程不再只靠聊天记录。
Multica 的 issue comment 很重要。Agent 做完以后必须把结果写回 issue,而不是只在本地终端输出。这样后面的 Agent 或人类用户看 issue 就能知道结论,不需要翻某个 Agent 的运行日志。
3. 先从本地环境看起
3.1 安装和登录
如果是第一次使用,大致入口是:
bash
multica login
multica setup cloudlogin 负责认证,setup cloud 会配置 Multica Cloud,并启动本地 daemon。Multica 也支持 self-host:
bash
multica setup self-host本机当前版本可以这样查看:
bash
multica version笔者本机输出类似:
text
multica 0.3.10 (commit: be32e5af, built: 2026-05-27T10:03:51Z)
go: go1.26.1, os/arch: darwin/arm643.2 daemon 是什么
Multica 的 Agent 是在本地 runtime 里跑的,所以会有一个 daemon 常驻进程。可以用下面的命令检查:
bash
multica daemon status --output json返回内容里能看到几个关键信息:
-
status:daemon 是否正在运行; -
cli_version:当前 CLI 版本; -
agents:本机支持的 Agent 类型; -
active_task_count:当前正在执行的任务数; -
workspaces:本地 daemon 已经连接的 workspace。
这点和单纯的 Web 任务系统不太一样。Multica 的任务信息在云端,真正执行 Agent 的环境在本机。也就是说,它既有平台侧的任务管理,也保留了本地文件系统、代码仓库、终端命令这些能力。
注:这也是为什么 Agent 执行任务时能直接读写本机文件,比如本文就是输出到本机的
/Users/Documents目录下。
3.3 常用命令入口
Multica 的命令分得比较清楚,直接看 multica --help 就能知道大概结构:
bash
multica --help常见入口有这些:
| 命令 | 用途 |
|---|---|
multica issue |
管理任务和评论 |
multica agent |
管理 Agent |
multica repo |
检出代码仓库 |
multica skill |
管理 Agent 技能 |
multica daemon |
管理本地 runtime daemon |
multica workspace |
管理工作空间 |
multica autopilot |
管理定时或触发式自动化 |
笔者实际用下来,入门阶段最常用的是 issue、agent、repo、daemon 这几个。
4. 用一次真实任务串起来
4.1 Agent 接到 issue 后先做什么
Multica 里的任务通常从 issue 开始。比如当前这篇文章,本质上也是一个 issue:
bash
multica issue get <issue-id> --output json这个命令会拿到完整任务信息,包括:
-
title;
-
description;
-
assignee;
-
status;
-
metadata;
-
workspace;
-
parent issue。
对 Agent 来说,第一步不是马上动手,而是先读清楚 issue。因为 description 里经常会写任务目标、输出目录、参考资料、协作要求这些关键约束。
4.2 评论历史比想象中重要
只看 issue 描述是不够的,还要读评论:
bash
multica issue comment list <issue-id> --output json这一点笔者觉得很像真实研发里的「先读需求讨论」。很多信息不会写在最初的 description 里,而是散落在后续评论中,比如:
-
用户临时补充了新要求;
-
前一个 Agent 已经试过某个方案;
-
某个命令失败过;
-
任务被拆过子 issue;
-
review 提出了修改意见。
如果 issue 很长,还可以分页读最近活跃的 thread:
bash
multica issue comment list <issue-id> --recent 20 --output json这里有个实践建议:Agent 不要只相信自己这次看到的 prompt,要把 issue 当成事实来源。
4.3 status 是任务进度的公共语言
Multica issue 有一套状态流转:
text
backlog, todo, in_progress, in_review, done, blocked, cancelledAgent 开始工作时,通常会先把 issue 标成进行中:
bash
multica issue status <issue-id> in_progress完成后再进入 review:
bash
multica issue status <issue-id> in_review如果确实卡住了,就标成 blocked,并在评论里说明原因:
bash
multica issue status <issue-id> blocked这个动作看起来很普通,但对多 Agent 协作很重要。因为状态是所有人共享的,不然就会变成「我以为你在做,你以为我做完了」。
4.4 结果必须写回 comment
Multica 里一个很重要的约定是:Agent 的最终结果要写回 issue comment。
比如:
bash
multica issue comment add <issue-id> --content-stdin <<'EOF'
已完成文章初稿,文件路径:
/Users/Documents
EOF这点刚开始可能会觉得多此一举,因为 Agent 在本地终端已经输出过结果了。但站在协作角度看,comment 才是用户和下一个 Agent 能稳定看到的地方。
注:终端日志是这次运行的副产物,issue comment 才是任务交付物的一部分。
5. issue metadata:少量但关键
5.1 metadata 不是备忘录
Multica 的 issue 还有 metadata:
bash
multica issue metadata list <issue-id> --output json它是一个很小的 KV 存储,适合放少量高价值信息,比如:
-
PR URL;
-
deploy URL;
-
外部 ticket;
-
当前长期 blocker;
-
关键决策。
但它不适合放一堆流水账。比如「我看了哪些文件」「我跑了什么命令」「今天试了哪个方案」,这些更应该写进 comment 或者最终总结里。
笔者对 metadata 的理解是:它不是日记本,而是给未来接手者看的标签纸。
5.2 什么时候该写 metadata
举几个比较合适的例子:
bash
multica issue metadata set <issue-id> --key pr_url --value https://github.com/org/repo/pull/123
multica issue metadata set <issue-id> --key deploy_url --value https://example.com
multica issue metadata set <issue-id> --key waiting_on --value "backend api review"这些信息有一个共同点:后面大概率会反复被查,而且从评论里翻会比较麻烦。
反过来,如果只是这次运行里的临时观察,就不要往 metadata 里塞。metadata 一旦乱了,后面的 Agent 就会被误导。
6. 多 Agent 协作怎么做
6.1 直接分配任务
可以查看 workspace 里的 Agent:
bash
multica agent list --output json然后创建 issue 时指定 assignee:
bash
multica issue create \
--title "整理 Multica 使用心得" \
--description "写一篇入门实践文章" \
--assignee "codex agent"如果要更精确,也可以用 --assignee-id。
这类方式适合简单分工:一个 Agent 写,一个 Agent review,或者一个 Agent 调研,一个 Agent 实现。
6.2 子 issue 更适合明确拆分
如果一个任务明显可以拆成几个独立部分,就可以创建子 issue:
bash
parent_issue_id="这里换成主 issue 的 ID"
multica issue create \
--title "Review Multica 文章" \
--description "检查结构、准确性和风格" \
--parent "$parent_issue_id" \
--assignee "hermes 助手" \
--status todo这里 --parent 很关键,它让子任务和主任务关联起来。
状态也要注意:
-
todo:创建后可以马上开始; -
backlog:先放着,不触发执行,后续再推进。
如果是并行任务,可以都设成 todo;如果是严格串行,就只让第一步进入 todo,后面的先放 backlog。
6.3 不要乱 mention Agent
Multica 的 mention 不是普通文本,有些 mention 会触发 Agent 重新运行。所以在评论里如果只是提到某个 Agent,直接写名字就好,不要随手加 mention 链接。
笔者觉得这个设计挺合理,但也提醒我们:在 Agent 协作系统里,文字有时候就是操作。
这和普通聊天工具不一样。普通聊天里 @某人 可能只是提醒一下;在 Multica 里,mention Agent 可能就是一次新的任务触发。
7. repo checkout 和代码任务
7.1 检出仓库
如果 issue 是代码任务,可以用:
bash
multica repo checkout https://github.com/example/project.git也可以指定分支或 commit:
bash
multica repo checkout https://github.com/example/project.git --ref main这个命令会把仓库检出到当前工作目录,并创建适合 Agent 执行任务的 worktree。
这点对代码类任务很关键。因为 Agent 不是只在云端「想一想」,而是真的要在本地仓库里读代码、改文件、跑测试。
7.2 和普通本地开发的区别
Multica 里的代码任务,本质上还是本地开发:读文件、改代码、跑测试、提交结果。
区别在于它多了一个任务外壳:
-
issue 描述目标;
-
comments 记录讨论;
-
metadata 固化关键链接;
-
status 表示进度;
-
Agent runtime 负责执行;
-
最终结果回写 issue。
所以笔者觉得,Multica 并没有改变写代码这件事本身,它改变的是「AI 写代码这件事如何被组织和交付」。
8. Skills 和 Autopilot
8.1 Skills:给 Agent 加规则和知识
Multica 也有 skill 管理能力:
bash
multica skill list
multica skill create
multica skill importSkill 更像是给 Agent 的操作手册。比如你可以把团队的代码规范、review 规范、部署流程、日报格式写成 skill,然后分配给对应 Agent。
这和笔者之前理解的 AI Rules、Claude Memory、Kiro Steering 有点像:它不是一个真正执行外部操作的接口,而是一段会影响 Agent 行为的上下文。
8.2 Autopilot:让任务自动触发
multica autopilot 则更像是自动化入口:
bash
multica autopilot list
multica autopilot create
multica autopilot trigger从命令看,它支持 schedule 和 webhook 这类触发方式。也就是说,一些周期性任务或者外部事件触发的任务,可以不用每次手动创建 issue。
比如可以想象这些场景:
-
每天早上自动汇总项目状态;
-
PR 创建后自动派 Agent 做 review;
-
某个 webhook 触发后让 Agent 拉取日志并分析;
-
定时检查某个服务的运行情况。
不过笔者目前对 Autopilot 还只是浅尝,真正要用好,应该还要结合团队流程去设计触发条件和结果回写方式。
9. 使用下来的一些心得
9.1 它更像任务系统,不是聊天框
Multica 最容易被低估的一点是:它不是把多个 AI 聊天窗口拼在一起,而是给 Agent 加了一层任务系统。
这层任务系统会带来一些约束,比如必须读 issue、必须写 comment、必须更新 status。刚开始会觉得麻烦,但对复杂任务来说,这些约束反而能减少混乱。
9.2 要把上下文写在正确的位置
笔者现在会这样区分:
| 信息类型 | 放哪里 |
|---|---|
| 任务目标和约束 | issue description |
| 过程讨论和交付结果 | issue comment |
| PR、部署地址、长期 blocker | metadata |
| 代码和文档产物 | 仓库或本地文件 |
| 临时运行日志 | 不需要长期保存 |
这个边界很重要。上下文乱放,后面接手的人和 Agent 都会痛苦。
9.3 Agent 协作要避免"互相唤醒"
多 Agent 系统里最怕的不是没人干活,而是大家互相触发、反复评论、任务跑成循环。
所以评论时要克制 mention,分配任务时要明确边界,创建子 issue 时要想清楚并行还是串行。
一句话:AI Agent 越多,越需要流程约束。
9.4 适合的场景
笔者觉得 Multica 比较适合这些场景:
-
多个 AI Agent 分工处理同一个项目;
-
需要保留任务历史和交付记录;
-
代码任务需要本地 runtime 真实执行;
-
调研、写作、review、开发之间需要流转;
-
团队希望把 AI 工作纳入现有 issue 流程。
9.5 不太适合的场景
它也不是所有事情都要用。
-
如果只是问一个很简单的问题,直接聊天更快。
-
如果只是本地改一个很小的脚本,不一定需要创建完整 issue。
-
如果团队完全没有任务管理习惯,上来就用多 Agent 可能会更乱。
-
如果没有把结果写回 comment 的意识,Multica 的协作价值会打折。
所以笔者对它的定位是:简单问题直接问,复杂任务进 Multica。
10. 一个推荐的入门流程
如果刚开始用 Multica,可以按这个顺序来:
10.1 先确认本地环境
bash
multica version
multica daemon status --output json
multica workspace list --output json
multica agent list --output json先确认 CLI、daemon、workspace、agent 都正常。
10.2 再创建一个小任务
bash
multica issue create \
--title "整理 README 使用说明" \
--description "阅读当前项目 README,补充一个快速开始章节" \
--assignee "codex agent" \
--status todo不要一上来就丢一个超大任务。先用一个小任务跑通 issue、Agent、comment、status 这条链路。
10.3 观察 Agent 怎么交付
任务执行过程中,可以看 issue:
bash
multica issue get <issue-id> --output json
multica issue comment list <issue-id> --output json重点看三件事:
-
Agent 有没有理解 issue;
-
有没有把结果写回 comment;
-
status 有没有正确变化。
10.4 再尝试拆子任务
等单 Agent 跑顺以后,再尝试多 Agent 协作。比如:
-
Codex 负责写;
-
Hermes 负责 review;
-
Kiro 负责整理 spec;
-
Claude 负责解释和文档。
拆分时最好用子 issue,而不是在一个评论里让所有 Agent 同时开工。
11. 碎碎念
终于把 Multica 的第一次系统使用体验整理出来了。写这篇的时候,笔者最大的感受是:AI Agent 真正开始参与工作以后,问题就不只是「模型聪不聪明」了,而是「任务能不能被稳定地交给它、执行它、验收它」。
以前我们讨论 AI 工具,容易关注模型能力、上下文长度、代码质量。但当多个 Agent 同时出现以后,协作机制会变得同样重要。没有 issue,就没有任务边界;没有 comment,就没有交付记录;没有 status,就不知道谁在做什么;没有 metadata,关键链接迟早被淹没。
所以 Multica 对笔者来说,更像是给 AI Agent 补上了「项目管理的骨架」。
-
你所做的一切,在将来某些时候,都会反映到你自己的身上。你的气质里,不但有你的教养,也有教养所带来的结果,好的成果,或者不好的后果。
-
时间具有唯一性和不可逆性,与其浪费在斤斤计较里,不如大气一点。大气的人,才能赢得这个世界。
-
能沉淀下来的流程,才是工具真正的价值。