写这篇文章的初衷,是希望大家能打破对大模型的"神秘感"与"滤镜"。如果你曾完整走过传统图像识别的全流程------从数据采集、模型搭建、训练调优,再到最终用 C++ 落地部署,你就会豁然开朗:所谓的大模型,本质上只是模型文件的体量变大了,推理框架换了而已。技术演进有其内在的延续性,希望这篇文章能帮大家褪去大模型的光环,理性看待它的底层逻辑。
第1章 图像模型推理流程
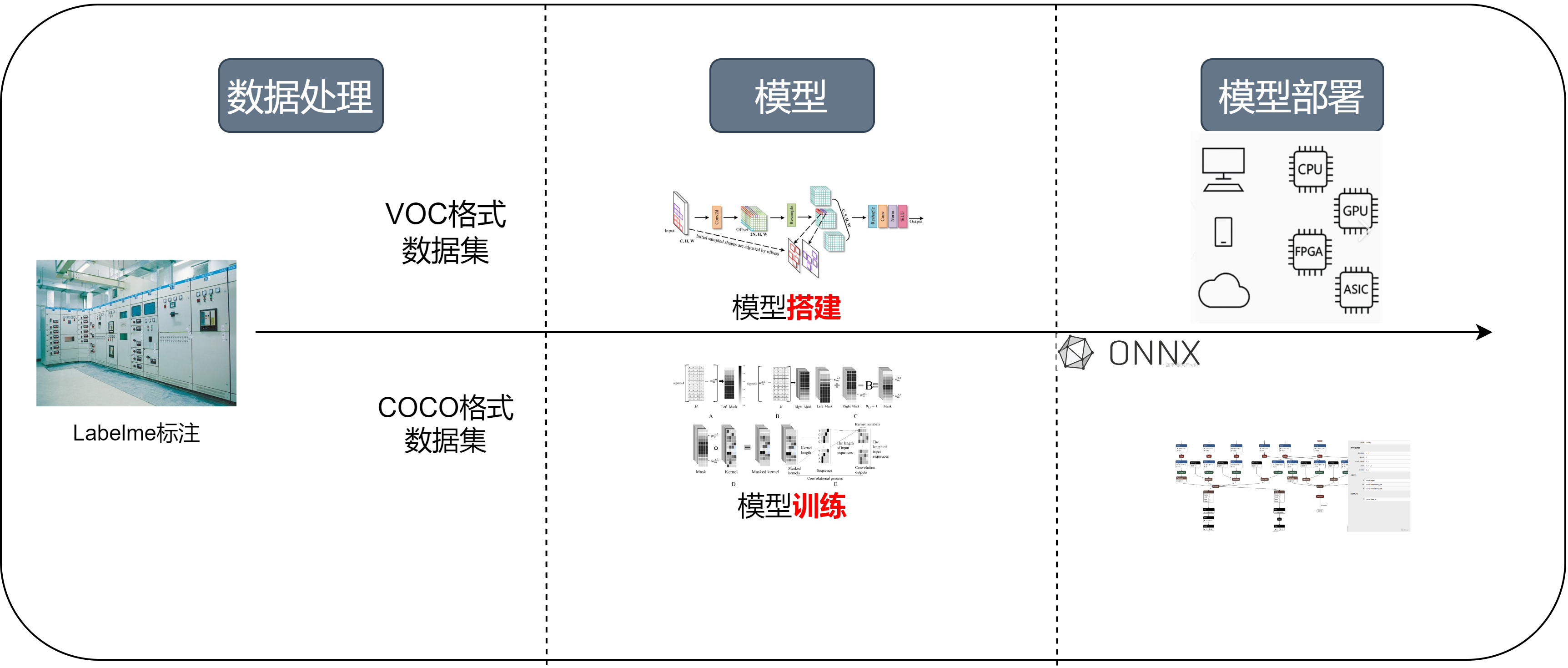
1.1 服务器端的推理流程
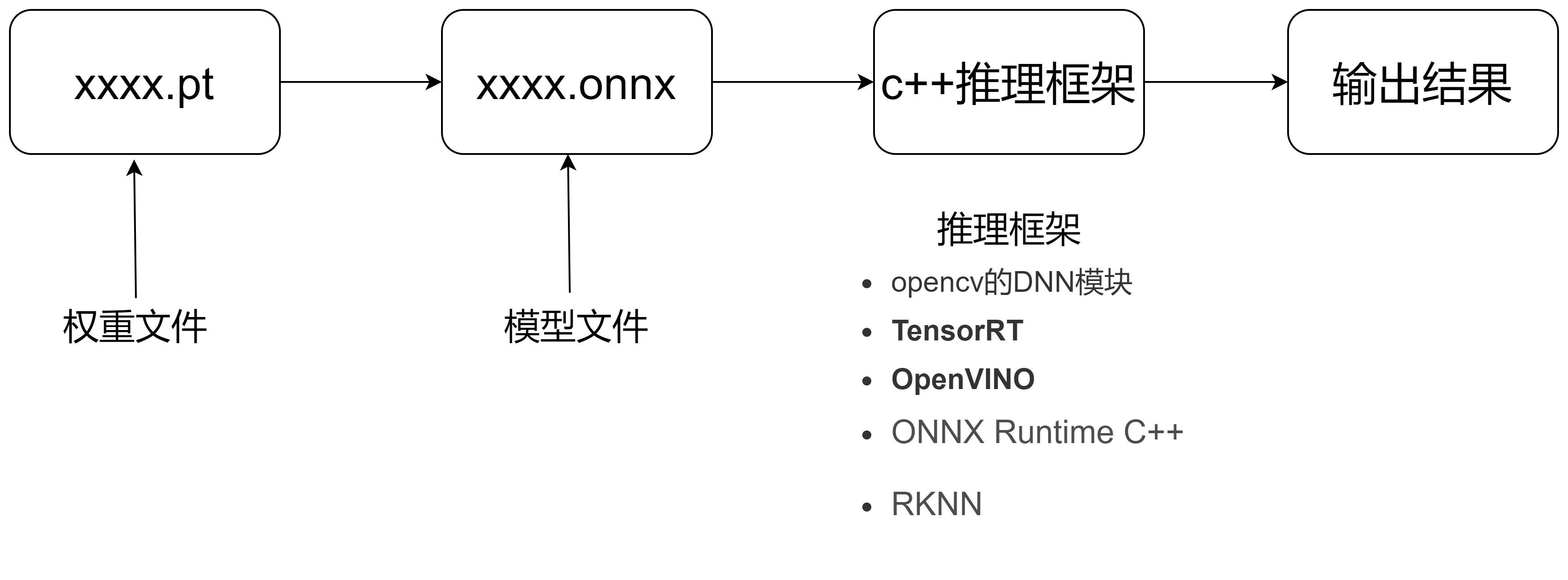
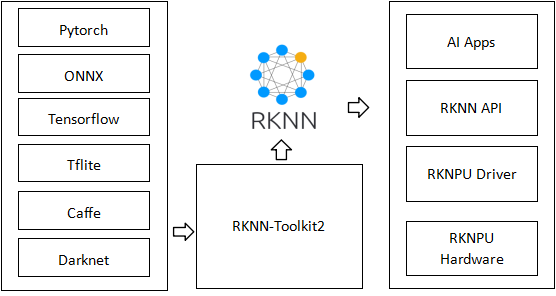
1.2 边缘设备的推理流程
第2章 Hugging Face
**Hugging Face就是一个存放大模型的仓库,类似于github。**你想要什么模型就可以从上面去下载。
huggingface的地址 https://huggingface.co/
https://huggingface.co/
第3章 语言模型推理流程
3.1 llama、llama.cpp、ollama的区别
是不是经常听到llama、llama.cpp、ollama这三个名字,看起来都包括llama,但实际上它们是不同的概念:
3.1.1 LLaMA
LLaMA就是一个大公司训练出来的一个权重文件(模型文件)。简单粗暴理解,该模型文件用了聊天问答。
LLaMA(Large Language Model Meta AI)是由Meta(Facebook)开发的大型语言模型系列
它是一组开源的基础语言模型,包括不同参数规模的版本(如LLaMA、LLaMA 2、LLaMA 3等)
LLaMA是模型本身,即训练好的神经网络权重和架构文件,有不同大小的模型,如3B、7B、13B、65B、70B、130B等。
3.1.2 llama.cpp
llama.cpp是一个纯C++编写的,用来推理模型文件的推理框架。
llama.cpp是一个C++库,用于在CPU上高效运行LLaMA模型。它是由Georgi Gerganov开发的,专注于优化LLaMA模型在消费级硬件上的推理性能
主要特点是内存效率高、支持量化(如4-bit、5-bit、8-bit量化)以减少内存需求。
llama.cpp推理框架源码![]() https://github.com/ggml-org/llama.cpp
https://github.com/ggml-org/llama.cpp
3.1.3 Ollama
Ollama是一个应用程序,让用户能够轻松下载、运行和使用各种大型语言模型。它在底层使用llama.cpp作为推理引擎。
Ollama提供了友好的命令行界面和API,简化了模型的管理和使用
它相当于是llama.cpp的上层封装,增加了模型管理、会话管理等功能
第4章 whisper.cpp
4.1 whisper
whisper 就是一个大公司训练出来的一个权重文件(模型文件)。该模型文件用于语音识别。
4.2 whisper.cpp
whisper.cpp 是一个推理框架。用于对 OpenAI 的 Whisper 语音识别模型进行推理。由开发者 Georgi Gerganov 用纯C++创建。
whisper.cpp推理框架地址![]() https://github.com/ggml-org/whisper.cpp
https://github.com/ggml-org/whisper.cpp
第5章 实战
5.1 项目思路
采集系统音频 → Whisper 语音识别 → 翻译成中文 → 控制台输出。
bash
系统音频 (PCM 波形数据)
│
│ 原始声音,机器看不懂
▼
┌──────────────┐
│ whisper.cpp │ ← 语音识别模型 (Whisper large-v3)
│ │
│ 声音 → 文字 │ "Hello, how are you?"
└──────────────┘
│
│ 识别出的外语文本
▼
┌──────────────┐ ┌─────────────────┐
│ llama.cpp │ 或 │ DeepSeek API │
│ │ │ │
│ 混元 1.8B │ │ 云端大模型 │
│ 文字 → 翻译 │ │ 文字 → 翻译 │
└──────────────┘ └─────────────────┘
│ │
└──────────┬───────────────┘
▼
"你好,最近怎么样?"
控制台输出