很多人学习 Redis 时,最先记住的是五种基础数据类型:
String、Hash、List、Set、ZSet
但如果面试继续往下问:
String 底层为什么不是普通 C 字符串? Hash 小数据和大数据底层一样吗? List 为什么不用普通链表? ZSet 为什么适合做排行榜? Redis 的跳表是什么? Bitmap、HyperLogLog、Geo 又适合什么场景?
这时候就不能只停留在"会用命令"的层面了。
这篇文章就从 Redis 对外数据类型讲到底层结构,帮助你把 Redis 回答得更有"底层味"。
一、Redis 的数据类型和底层结构是一回事吗?
不是。
Redis 对外提供的数据类型是:
String Hash List Set ZSet
但这些类型在 Redis 内部可能会使用不同的底层编码结构。
比如 Hash:
数据少、字段短:可能使用紧凑结构
数据变多:转换为 hashtable
可以这样理解:
| 层级 | 作用 |
|---|---|
| 对外数据类型 | 给程序员使用,比如 String、Hash、List |
| 底层编码结构 | Redis 内部为了性能和内存选择的实现 |
Redis 的设计思路很明显:
小数据优先省内存 大数据优先查得快
二、Redis String 底层是什么?
Redis String 底层不是 C 语言原生字符串,而是 SDS。
SDS 全称:
Simple Dynamic String
SDS 会记录:
字符串长度 剩余空间 真实内容
大致可以理解为:
len: 已使用长度 alloc: 分配空间长度 buf: 字符串内容
所以 Redis 获取字符串长度时,不需要从头遍历到尾,可以直接拿到长度。
三、SDS 相比 C 字符串有什么优势?
SDS 的主要优势有这些:
| 优势 | 说明 |
|---|---|
| 获取长度 O(1) | C 字符串要遍历到 \0 |
| 防止缓冲区溢出 | SDS 记录空间大小,扩容更安全 |
| 二进制安全 | 内容中可以包含 \0 |
| 减少内存分配 | 通过预分配和惰性释放优化性能 |
C 字符串用 \0 判断结尾,不适合存二进制数据。
而 SDS 自己记录长度,所以即使内容中有 \0,也可以正常存储。
这也是为什么 Redis String 不只是能存文本,还能存图片、序列化对象等二进制数据。
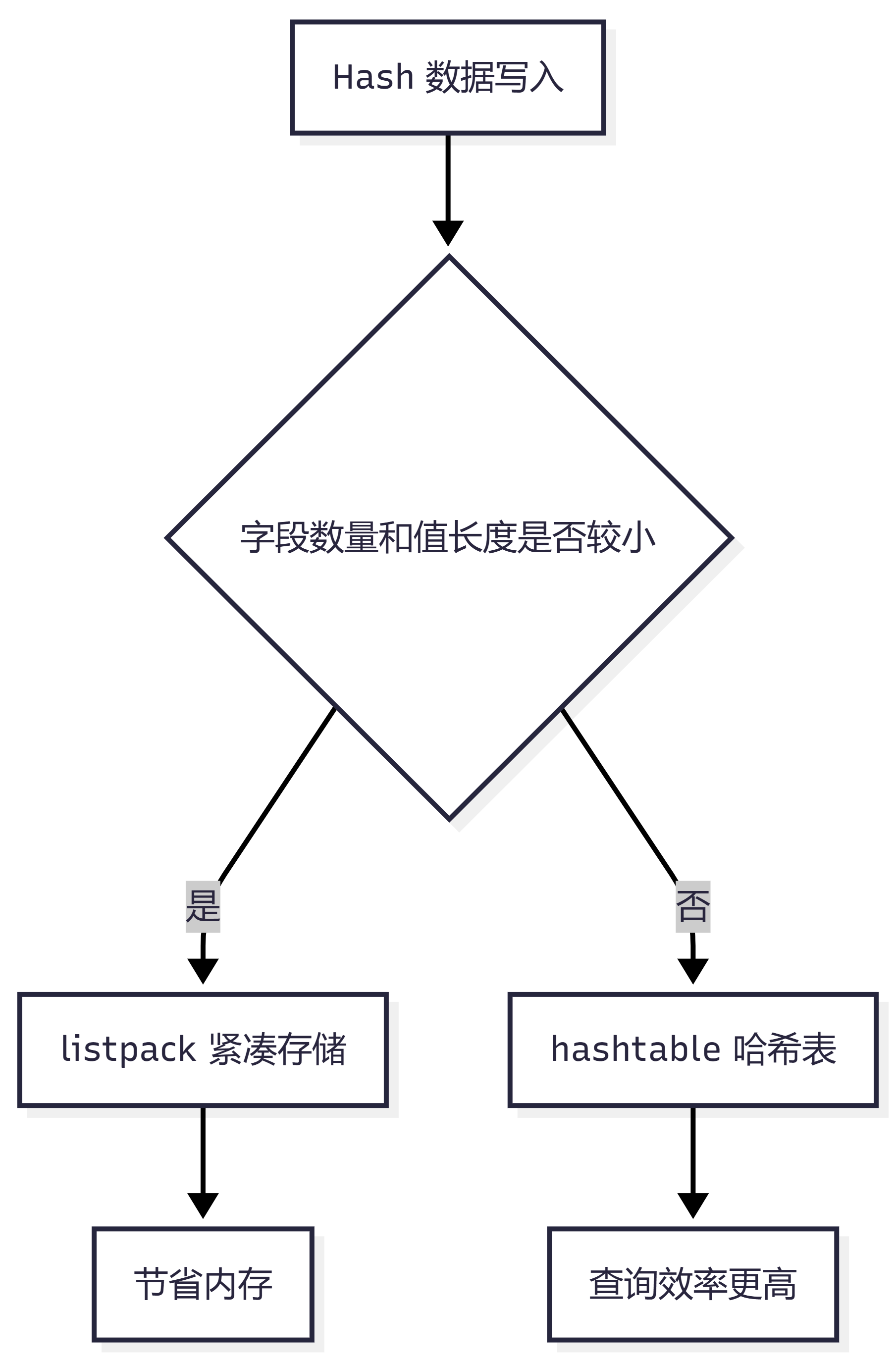
四、Hash 类型底层怎么实现?
Redis Hash 底层常见两种编码:
listpack hashtable
数据量小、字段和值都比较短时,Redis 会使用 listpack,节省内存。
数据变大后,会转成 hashtable,提高查询效率。
可以简单记:
小 Hash:更省内存 大 Hash:更重性能
流程图:
五、为什么小 Hash 不直接用 hashtable?
因为 hashtable 虽然查询快,但有额外开销。
比如:
哈希桶 指针 对象结构 扩容成本
如果一个 Hash 里只有几个字段:
name age city
直接用 hashtable 反而浪费内存。
所以 Redis 对小对象会用更紧凑的结构存储,这也是 Redis 很重要的设计思想:
小数据优先省内存,大数据优先查得快。
六、List 类型底层是什么?
Redis List 以前使用 ziplist 和 linkedlist,后来主要使用 quicklist。
quicklist 可以理解为:
双向链表 + listpack
图示如下:
[listpack] <-> [listpack] <-> [listpack]
每个节点里不是只存一个元素,而是存一小段连续元素。
这样既保留了链表两端插入、删除快的特点,又减少了普通链表的指针开销。
七、为什么 Redis List 不直接用普通链表?
普通链表有几个问题:
每个节点都要额外存前后指针 内存碎片多 缓存局部性差
quicklist 把多个元素压缩在一个 listpack 中,可以减少内存浪费。
所以 List 适合:
消息队列 最新列表 两端插入弹出
但它不适合频繁按下标随机访问中间元素。
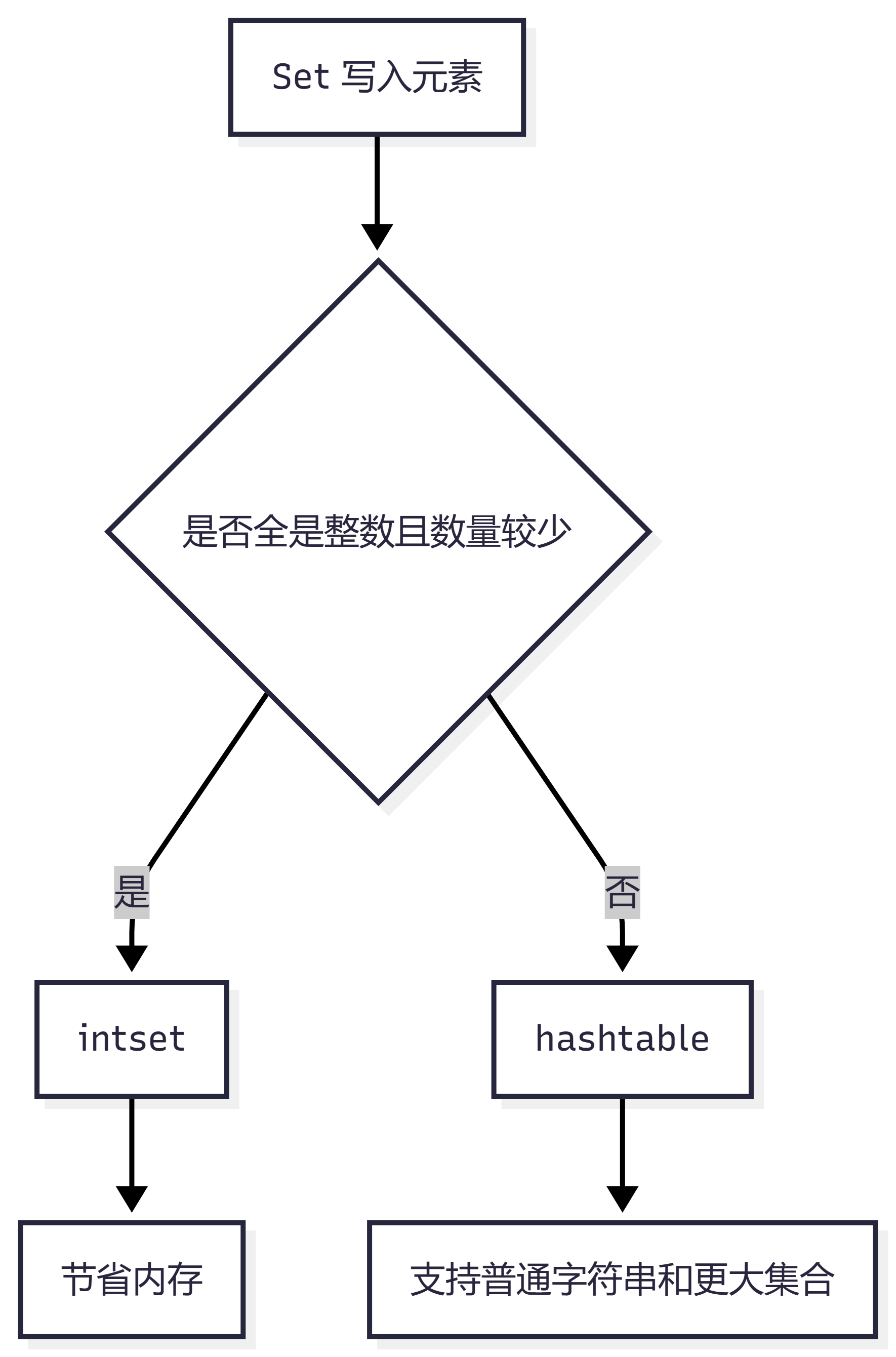
八、Set 类型底层怎么实现?
Redis Set 底层可能是:
intset hashtable
如果 Set 里全是整数,并且数量不多,Redis 会用 intset。
比如:
{1, 2, 3, 4}
如果元素变多,或者出现非整数元素,就会转成 hashtable。
可以这样记:
小整数集合:intset 普通集合:hashtable
流程图:
九、ZSet 底层怎么实现?
ZSet 也叫有序集合,底层核心是:
跳表 skiplist + 哈希表 dict
其中:
| 结构 | 作用 |
|---|---|
| dict | 根据 member 快速找到 score |
| skiplist | 按 score 排序,支持范围查询和排名 |
所以 ZSet 既能快速查分数:
ZSCORE rank user1
又能快速查排行榜:
ZREVRANGE rank 0 9
这也是为什么排行榜场景基本都会想到 ZSet。
十、什么是跳表?
跳表是一种有序数据结构。
它像给普通链表加了多级索引:
第3层:1 ----------------> 9 第2层:1 ------> 5 ------> 9 第1层:1 -> 3 -> 5 -> 7 -> 9
查找时,从高层往低层走,可以跳过很多节点。
平均查询复杂度是:
O(logN)
可以用这个图理解:
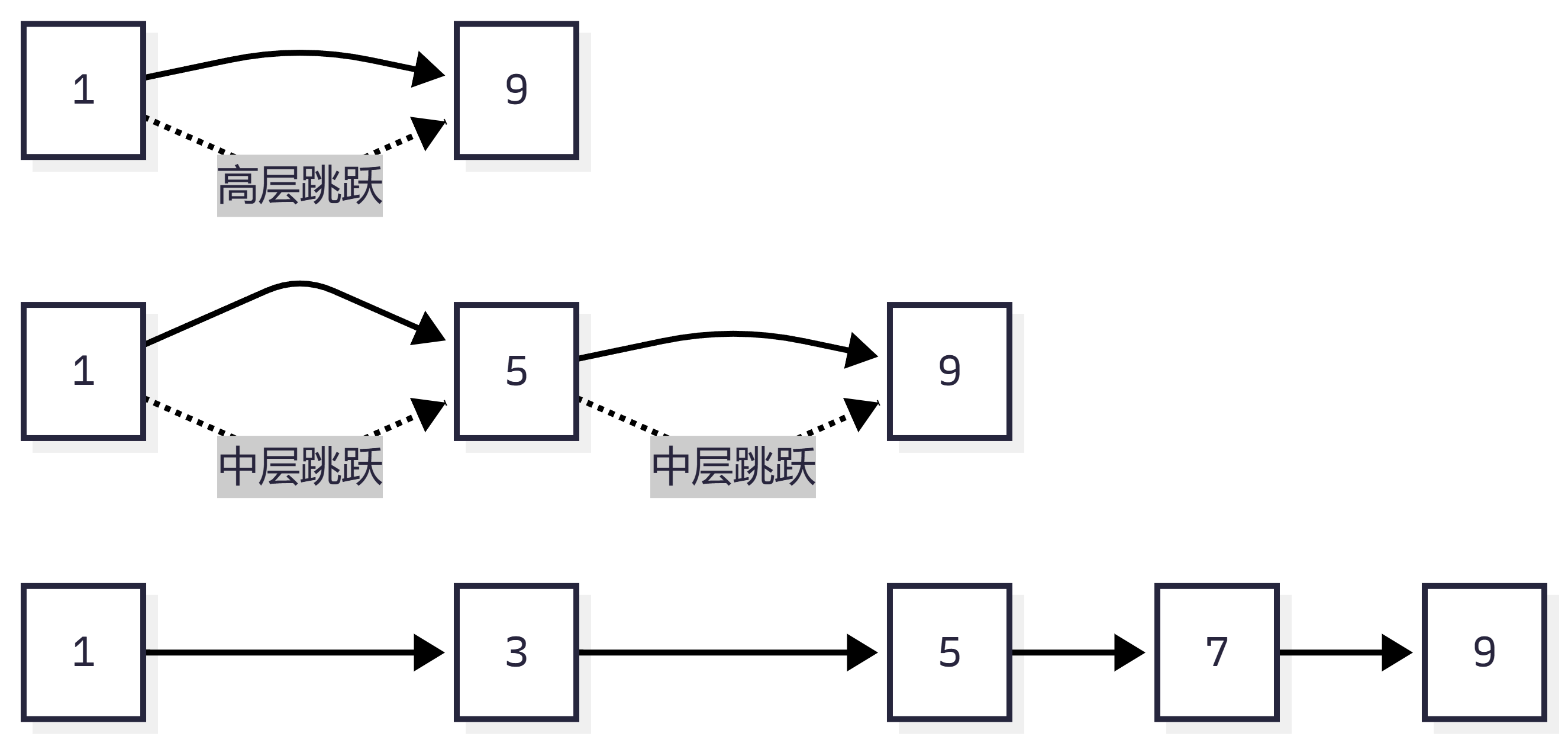
跳表实现起来比很多平衡树更简单,也很适合范围遍历。
十一、为什么 Redis ZSet 用跳表,不用红黑树?
常见原因有几个:
跳表实现相对简单 范围查询很方便 插入、删除、查询平均 O(logN) 调试和维护成本较低
ZSet 经常需要做:
查前 N 名 查某个分数范围 查某个元素排名
跳表天然适合范围遍历,所以 Redis 使用跳表来实现 ZSet 的有序能力。
十二、Redis 的字典 dict 是什么?
dict 是 Redis 内部广泛使用的哈希表结构。
很多地方都用它,比如:
Redis 全局 key 空间
Hash 大对象
Set 大对象
ZSet 的 member 到 score 映射
你可以把它理解为 Redis 内部的 HashMap。
Redis 根据 key 找 value,本质上也是在全局 dict 里查找。
十三、Redis 哈希表扩容会不会阻塞?
Redis 使用 渐进式 rehash。
如果一次性把旧哈希表所有数据迁移到新哈希表,可能会造成明显阻塞。
所以 Redis 会慢慢迁移:
每次处理命令时,顺便迁移一部分
这样把一次大开销拆成很多小开销。
流程图:
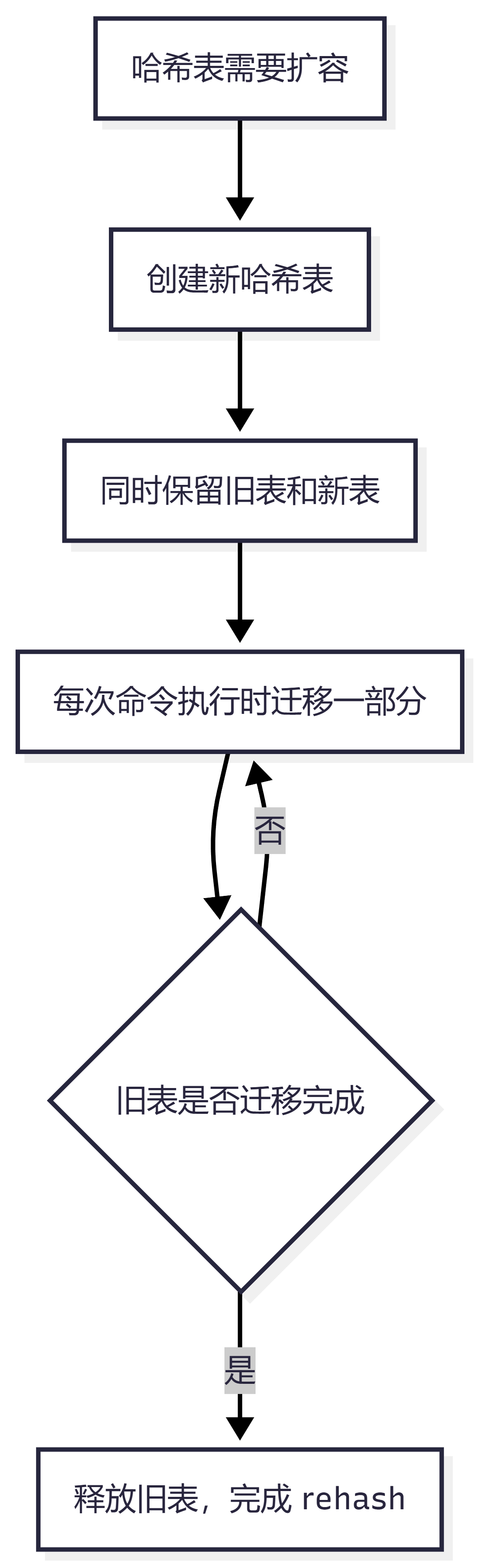
这就是渐进式 rehash。
十四、什么是 Bitmap?
Bitmap 本质上是 String,但按 bit 位操作。
它适合记录大量布尔状态,比如:
是否签到 是否在线 是否活跃 是否打卡
例如用户 1001 今天签到了:
SETBIT sign:2026-06-04 1001 1
统计当天签到人数:
BITCOUNT sign:2026-06-04
Bitmap 最大的优势是省内存。
比如 100 万用户每天是否签到:
100 万 bit ≈ 125 KB
如果用普通 key 存,每个用户一个 key,内存占用会大很多。
十五、Bitmap 适合什么项目场景?
典型场景:
| 场景 | 说明 |
|---|---|
| 用户签到 | 每个用户一个 bit |
| 用户是否活跃 | 记录某天是否活跃 |
| 布尔状态统计 | 在线状态、打卡状态 |
| 连续打卡 | 按日期维护多个 Bitmap |
例如:
sign:2026-06-04 active:2026-06-04
只要业务是大量 yes/no 状态,Bitmap 就很合适。
十六、什么是 HyperLogLog?
HyperLogLog 用来做基数统计。
基数就是去重后的数量。
比如统计网站 UV:
一天内有多少不同用户访问
命令示例:
PFADD uv:2026-06-04 user1 PFADD uv:2026-06-04 user2 PFCOUNT uv:2026-06-04
它的特点是:
占用内存极小 结果有少量误差
所以 HyperLogLog 适合"大规模去重计数,但允许少量误差"的场景。
十七、HyperLogLog 适合什么场景?
适合这些场景:
网站 UV 页面独立访客数
搜索关键词去重数量
活动访问人数估算
但要注意:
如果必须精确知道每个用户是谁,不能用 HyperLogLog; 如果只关心大概有多少不同用户,HyperLogLog 很合适。
比如统计 UV,误差很小但省大量内存,这时候就很划算。
十八、什么是 Geo?
Geo 是 Redis 提供的地理位置功能。
它可以存经纬度,并计算距离、附近的人、附近门店。
示例:
GEOADD shop:geo 116.397 39.908 shop1
GEODIST shop:geo shop1 shop2 km
GEOSEARCH shop:geo FROMLONLAT 116.4 39.9 BYRADIUS 5 km
适合场景:
附近商家 附近司机 附近门店 同城推荐
比如外卖、打车、本地生活类项目里,经常会用到类似能力。
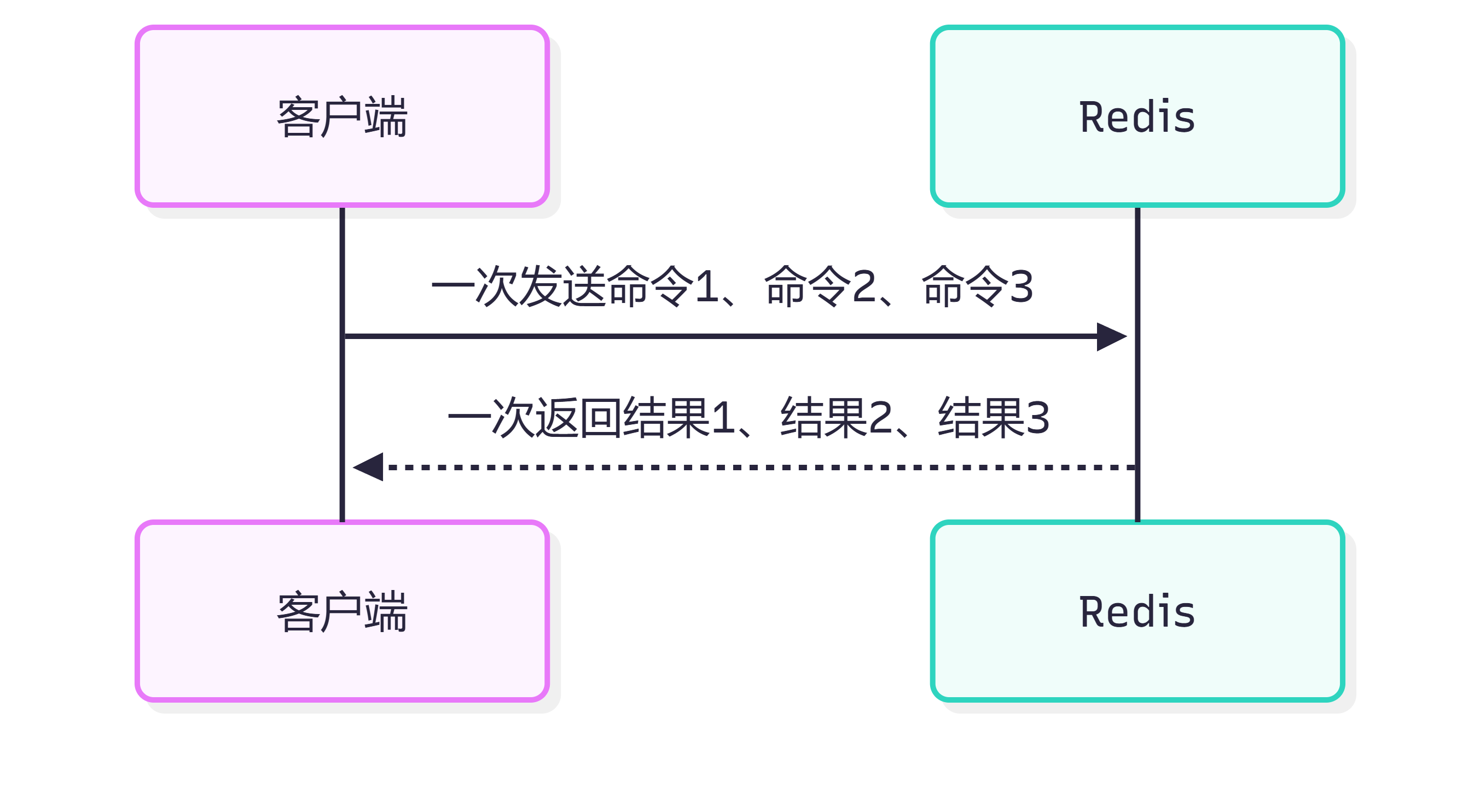
十九、Redis Pipeline 是什么?
Pipeline 是客户端一次性发送多条命令,减少网络往返次数。
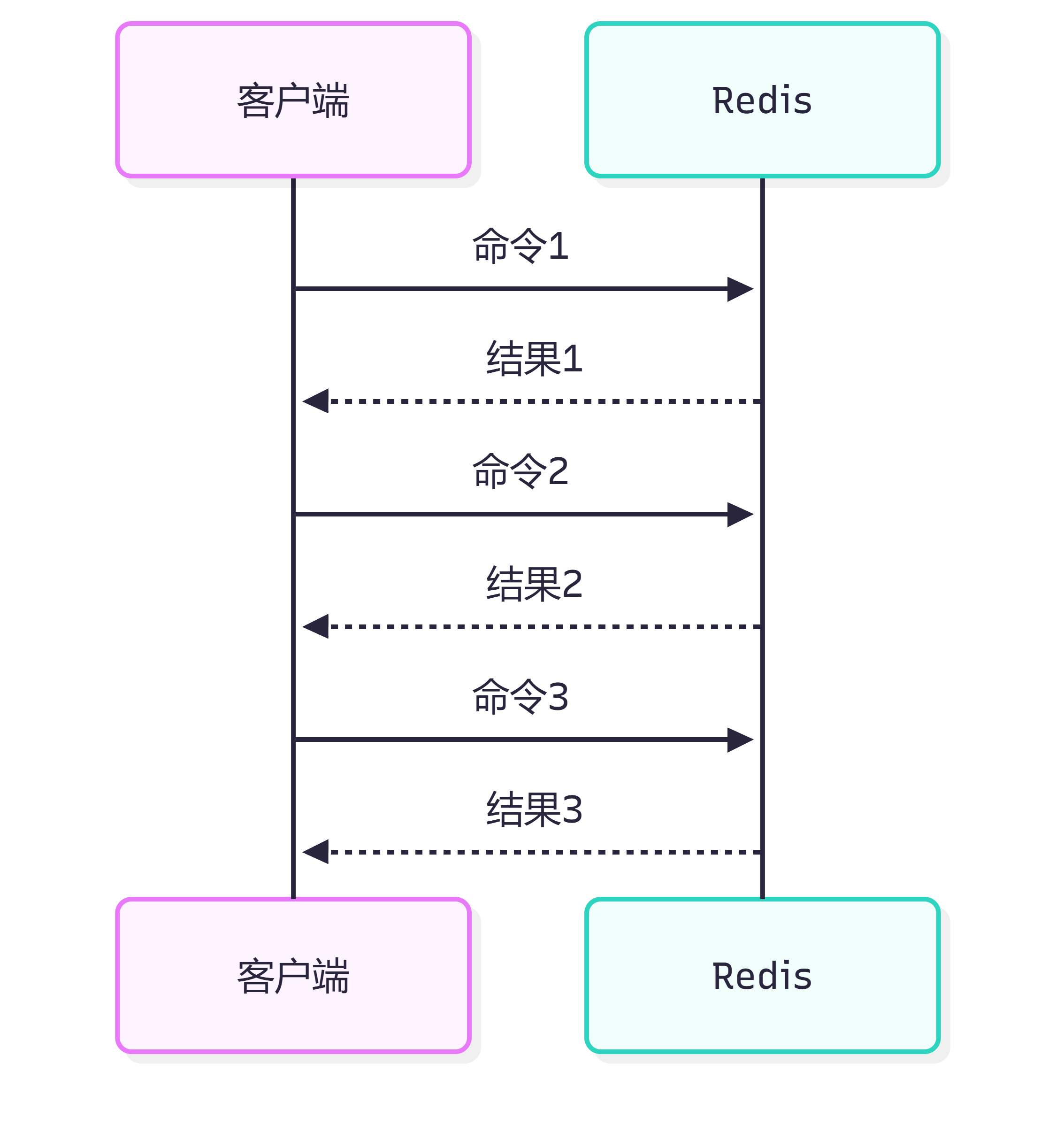
普通方式:
发送命令1 -> 等结果1
发送命令2 -> 等结果2
发送命令3 -> 等结果3
Pipeline:
一次发送命令1、2、3 再一次性接收结果
流程图:
Pipeline 模式:
注意:
Pipeline 不能保证事务原子性,它只是减少网络往返,提高批量操作性能。
二十、Redis 底层结构怎么在面试里串起来讲?
可以这样答:
Redis 对外提供 String、Hash、List、Set、ZSet 等类型,但底层会根据数据规模选择不同编码。 String 底层是 SDS,支持 O(1) 获取长度和二进制安全; Hash 小数据用紧凑结构,大数据用 hashtable; List 底层是 quicklist,兼顾链表操作和内存效率; Set 小整数集合用 intset,大集合用 hashtable; ZSet 通过 dict + skiplist 同时支持快速查分数和排序范围查询。 此外 Bitmap 适合布尔统计,HyperLogLog 适合 UV 估算,Geo 适合地理位置查询,Pipeline 可以减少网络往返。
总体流程图

总结
这一组可以按下面这条线来记:
String:SDS,二进制安全,长度获取 O(1)
Hash:小对象用 listpack 省内存,大对象用 hashtable 提高查询效率
List:quicklist,双向链表 + 紧凑存储
Set:intset 或 hashtable,天然去重
ZSet:dict + skiplist,适合排行榜和范围查询
Bitmap:适合签到、活跃状态这类布尔统计
HyperLogLog:适合 UV 这类去重数量估算
Geo:适合附近的人、附近门店
Pipeline:适合批量命令,减少网络开销
背完这一组,你的 Redis 回答就不只是"会用数据结构"了。
你还能继续往下讲:Redis 为什么 String 是二进制安全的,为什么小 Hash 更省内存,为什么 ZSet 能做排行榜,以及 Redis 是怎么在内存和性能之间做取舍的。
📌 码字不易,技术干货深度复盘!
如果这篇文章帮你看清了 MyBatis-Plus 查询的底层底细,别忘了 点赞、关注、收藏 三连走一波!支持作者不迷路,更多底层源码干货持续输出中!🚀
让我们一起学习面试知识,拿到自己想要的offer!