摘要:本文面向 Java 开发者及准备后端面试的同学,系统梳理 Elasticsearch 的核心概念、常用 API 与 DSL 查询,并结合黑马点评项目的实际场景整理出 12 道高频面试题及回答思路。全文约 15 分钟读完,建议搭配项目代码一起复习。
一、Elasticsearch 核心总结
1. 为什么用 Elasticsearch
-
MySQL 模糊查询痛点 :
LIKE不走索引,数据量大时性能急剧下降;无法处理错别字、拼音、同义词等复杂搜索。 -
ES 优势:基于倒排索引,海量数据搜索性能稳定;支持分词、拼音、同义词等复杂检索;还支持聚合分析。
2. 倒排索引原理
-
正向索引:以文档为主体,通过文档 ID 找到其中包含的词条(或字段值)。典型如 MySQL 的 B+Tree 索引,适合精确查询,但模糊匹配需要全表扫描。
-
倒排索引(es):以词条为主体,先对文档内容分词,建立"词条 → 文档ID列表"的映射,同时记录词频和位置信息。搜索时直接根据词条快速定位文档,性能极高。Elasticsearch 正是基于倒排索引实现全文检索。

-
核心概念:
-
文档(Document):一条 JSON 数据。
-
词条(Term):分词后的最小语义单元。
-
3. 核心概念对比(MySQL vs ES)
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(文档集合) |
| Row | Document | 文档(JSON 格式) |
| Column | Field | 字段 |
| Schema | Mapping | 映射(字段类型、分词等约束) |
| SQL | DSL | JSON 风格的查询语言 |
4. 分词与 IK 分词器
-
分词器作用:创建倒排索引和搜索时,将文本切分为词条。
-
IK 分词器模式:
-
ik_smart:粗粒度,按语义切分。 -
ik_max_word:细粒度,穷尽所有可能组合。
-
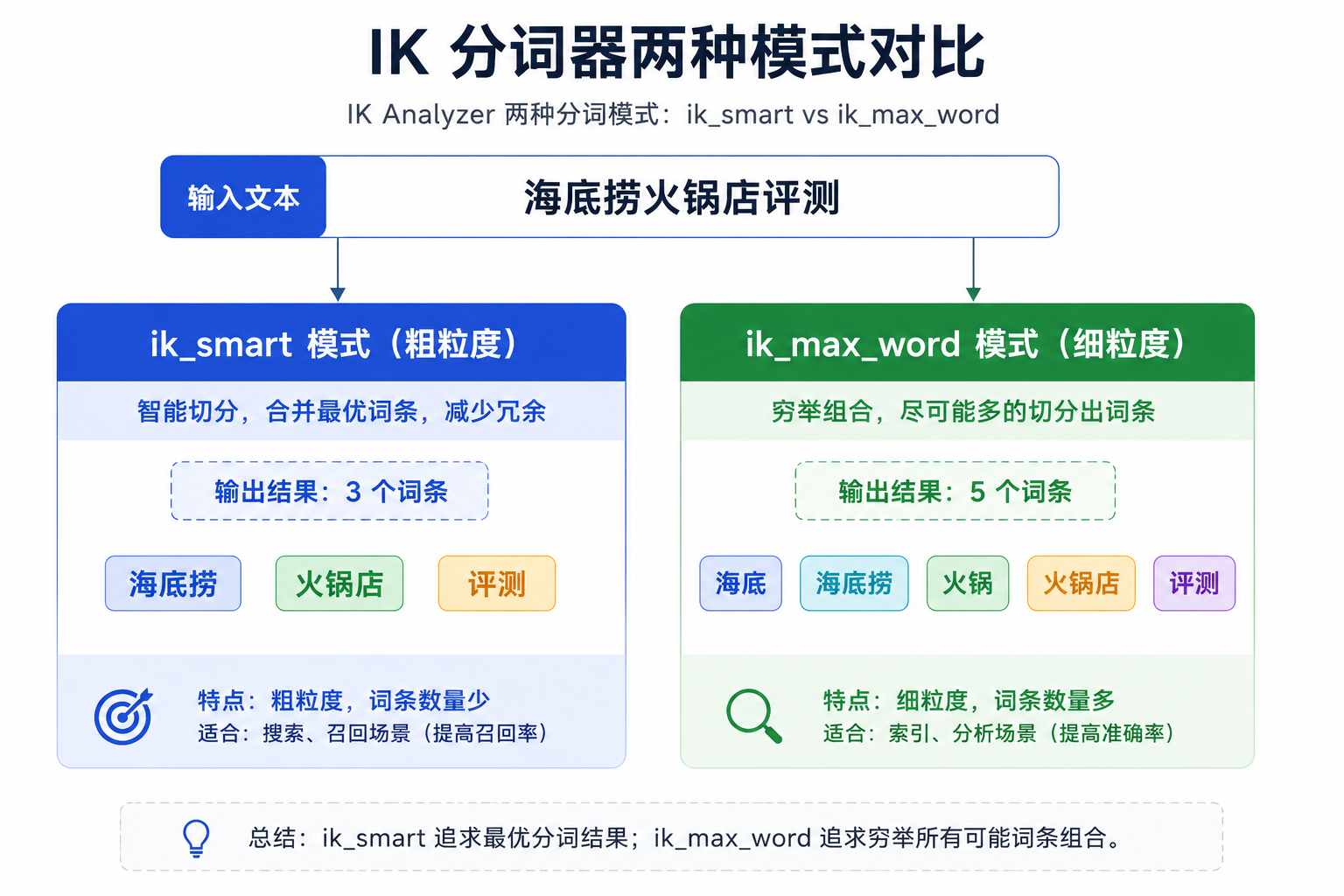
- 扩展词典 :修改
IKAnalyzer.cfg.xml添加ext.dic,放入新词后重启 ES 即可生效。
5. Mapping 映射属性
- 关键字段类型:
text(可分词的字符串)、keyword(精确值,不分词)、integer/long/float/double/boolean/date/object
-
重要属性:
-
index:是否建立索引(默认 true,设为 false 则不可搜索)。 -
analyzer:指定分词器(如ik_max_word)。
-
6. 索引库 RESTful API
| 操作 | 请求方式 | 路径 | 说明 |
|---|---|---|---|
| 创建索引库 | PUT |
/索引库名 |
携带 mappings |
| 查询索引库 | GET |
/索引库名 |
|
| 删除索引库 | DELETE |
/索引库名 |
|
| 修改索引库 | PUT |
/索引库名/_mapping |
只能添加新字段 |
7. 文档 CRUD
| 操作 | 请求方式 | 路径 | 请求体 |
|---|---|---|---|
| 新增文档 | POST |
/索引库名/_doc/文档ID |
JSON 文档 |
| 查询文档 | GET |
/索引库名/_doc/文档ID |
|
| 全量修改 | PUT |
/索引库名/_doc/文档ID |
完整 JSON(会覆盖) |
| 局部修改 | POST |
/索引库名/_update/文档ID |
{"doc": {"字段":"新值"}} |
| 删除文档 | DELETE |
/索引库名/_doc/文档ID |
|
| 批量操作 | POST |
/_bulk |
组合 index/delete/update |
8. Java RestClient 操作
- 初始化:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(HttpHost.create("http://127.0.0.1:9200"))
);-
索引库操作 :
client.indices().create(request, RequestOptions.DEFAULT)------ 创建索引;类似的还有get()(查询)、exists()(判断存在)、delete()(删除)。 -
文档操作:
-
新增:
client.index(request, RequestOptions.DEFAULT) -
查询:
client.get(request, RequestOptions.DEFAULT) -
更新:
client.update(request, RequestOptions.DEFAULT) -
删除:
client.delete(request, RequestOptions.DEFAULT) -
批量:
client.bulk(request, RequestOptions.DEFAULT)
-
-
批量导入 :分页从 DB 查询数据,每页转成
IndexRequest加入BulkRequest。
9. DSL 查询结构
基础查询模板如下,各字段含义详解:
GET /索引库名/_search
{
"query": { ... }, // 查询条件(核心)
"from": 0, // 分页起始位置
"size": 10, // 每页条数
"sort": [ ... ], // 排序规则
"highlight": { ... }, // 高亮配置
"aggs": { ... } // 聚合分析
}-
query:定义筛选条件,支持全文匹配、精确匹配、范围、组合等多种查询。 -
from+size:控制分页,类似 MySQL 的LIMIT offset, size。 -
sort:指定排序字段与方向。 -
highlight:对关键字高亮标记,返回带标签的片段。 -
aggs:聚合统计,与query同级,互不影响。
10. 查询分类
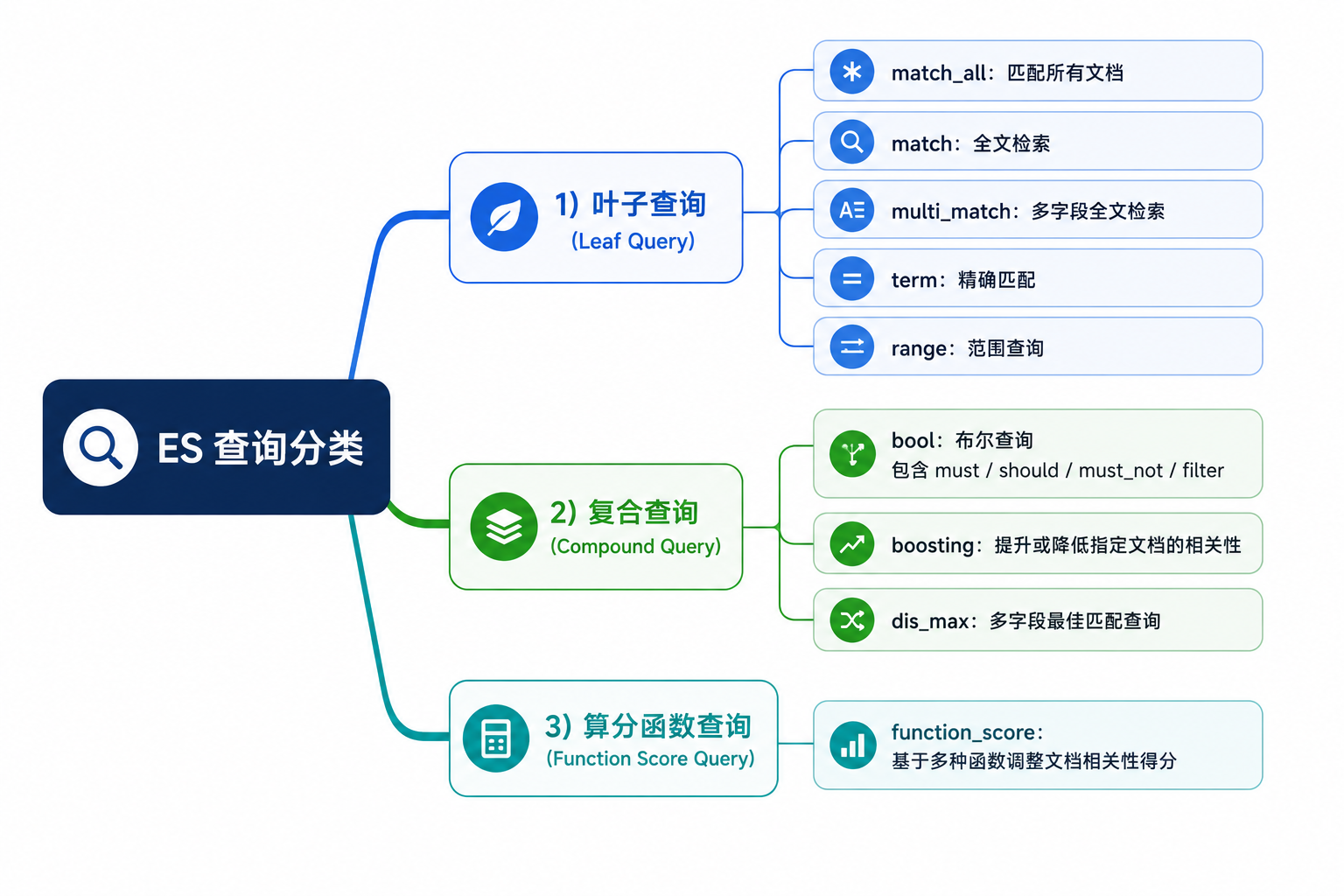
- 叶子查询:
match_all / match(全文检索,分词) / multi_match / term(精确匹配,不分词) / range(范围)
-
复合查询 :
bool(must/should/must_not/filter),filter不参与算分,性能更好。 -
算分函数查询 :
function_score,可人工干预排名(如竞价广告)。
11. 排序、分页、高亮
-
排序 :只能对 keyword/数值/日期类型排序,
"sort": [ {"price": "desc"} ] -
分页 :
from+size,深度分页限制 10000,深分页用search_after。 -
高亮 :
highlight指定字段和标签,结果需从hit.getHighlightFields()单独解析。
12. 数据聚合
-
桶聚合 :
terms(按字段值分组)、date_histogram -
度量聚合 :
stats/avg/max/min -
聚合与 query 同级,
size: 0可不返回文档只返回聚合结果。 -
Java API:
AggregationBuilders.terms("名称").field("字段"),结果从response.getAggregations()获取。
13. Java RestClient 速查
-
QueryBuilders :
matchQuery(),termQuery(),rangeQuery(),boolQuery() -
AggregationBuilders :
terms(),stats() -
高亮构建 :
SearchSourceBuilder.highlight() -
解析结果 :
response.getHits()→ 遍历SearchHit[],hit.getSourceAsString()反序列化。
掌握了上面的核心概念之后,我们来看看面试中常见的 Elasticsearch 问题。以下 12 道题全部结合黑马点评项目的实际场景进行拆解------不仅告诉你"怎么答",还会讲清楚"为什么这样设计",帮助你把理论知识真正落地到项目经验中。
二、Elasticsearch 面试题(结合黑马点评项目)
Q1. 黑马点评项目中哪些场景用到了 Elasticsearch?为什么不用 MySQL 模糊查询?
回答:
-
应用场景:
-
商户搜索:用户可根据名称、分类、地址等关键字搜索商户。
-
探店笔记搜索:对笔记标题、内容进行全文检索,支持高亮显示。
-
-
不使用 MySQL 的原因:
-
商户表和笔记表数据量大,模糊查询
LIKE不走索引,性能极差。 -
ES 基于倒排索引,查询速度快且稳定;支持分词、拼音、同义词等复杂搜索。
-
需要聚合统计(如按分类、区域统计商户数量),MySQL 实现复杂且慢。
-
Q2. 倒排索引是什么?与传统数据库索引有什么区别?
回答:
-
倒排索引:先将文档内容分词得到词条,再建立"词条→文档ID列表"的映射。搜索时直接根据词条快速找到文档ID。
-
与正排索引对比:
-
正排索引(如 MySQL B+Tree):通过 ID 找数据,适合精确查询,模糊查询需全表扫描。
-
倒排索引:通过词条找文档,天然适合全文搜索和模糊匹配,效率极高。
-
-
在黑马点评中,用户输入"海底捞火锅",倒排索引可以快速定位包含"海底捞"、"火锅"等词条的所有商户,无需全表扫描。
Q3. 黑马点评项目中商户索引的 Mapping 是怎么设计的?为什么这样设计?
回答:
-
Mapping 设计(部分字段):
-
id:keyword(精确查询) -
name:text + ik_max_word(全文搜索) -
category:keyword(分类过滤、聚合) -
area:keyword(区域过滤、聚合) -
price:integer(价格过滤、排序) -
score:integer(评分排序) -
location:geo_point(地理坐标搜索)
-
-
设计理由:
-
需要分词的用
text,需要精确匹配/过滤/排序/聚合的用keyword。 -
使用
ik_max_word能最大程度匹配用户可能输入的关键字。 -
地理坐标类型支持附近商户搜索。
-
index: false可设置给不需要搜索的字段(如图片URL),节省索引空间。
-
Q4. IK 分词器有什么作用?如果分不出新词怎么办?
回答:
-
作用:将中文字符串切分成有意义的词条,是倒排索引的核心基础。
-
模式:
-
ik_smart:粗粒度,尽量按语义切分。 -
ik_max_word:细粒度,穷举所有可能词汇。
-
-
新词处理 :修改
IKAnalyzer.cfg.xml,添加自定义词典文件(如ext.dic),将"黑马点评"、"网红店"等新词加入词典,重启 ES 即可生效。
Q5. 黑马点评中商户搜索接口怎么写?用到哪些查询?
回答:
-
接口逻辑:
-
接收关键词、分类、区域、排序、分页等参数。
-
构建
bool查询:-
must:用match对name进行关键词搜索。 -
filter:用term筛选分类/区域,用range筛选价格/评分,不参与算分,提高性能。
-
-
设置排序(如按评分
score降序或距离升序)。 -
设置高亮,将匹配的关键字用
<em>标签包裹。 -
调用
client.search()返回结果并解析。
-
-
优化 :使用
filter而不是must处理与相关性无关的条件,利用缓存提升查询速度。
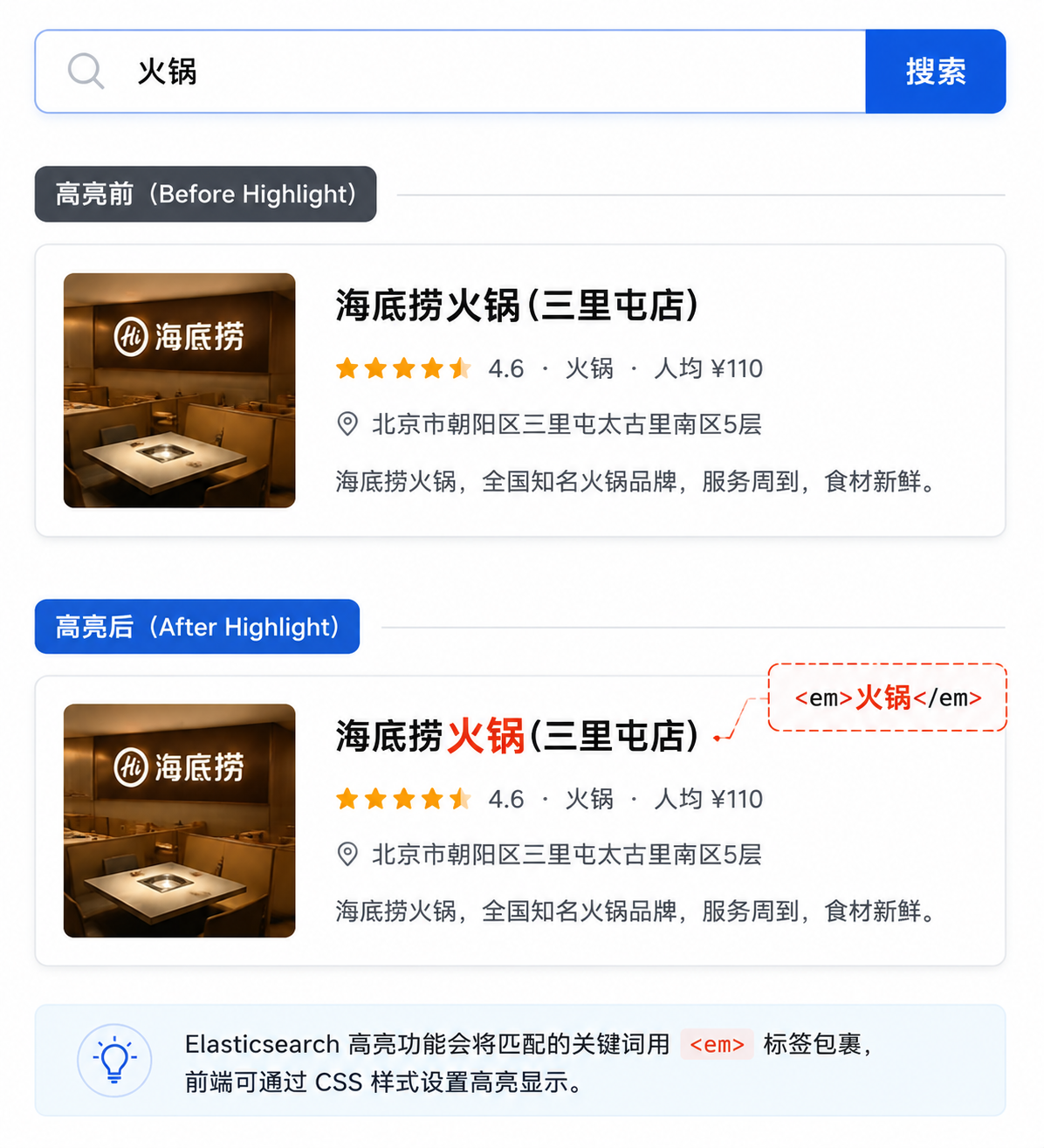
Q6. 搜索结果高亮是怎么实现的?
回答:
-
DSL 配置:
"highlight": { "fields": { "name": { "pre_tags": "<em>", "post_tags": "</em>" } } } -
Java 解析:
-
从
SearchHit中获取HighlightField映射。 -
根据字段名取出高亮片段:
hf.getFragments()[0].string()。 -
用高亮字符串替换原始文档中的字段值。
-
-
黑马点评中商户名称、笔记标题都采用高亮,前端通过 CSS 设置
<em>颜色即可。
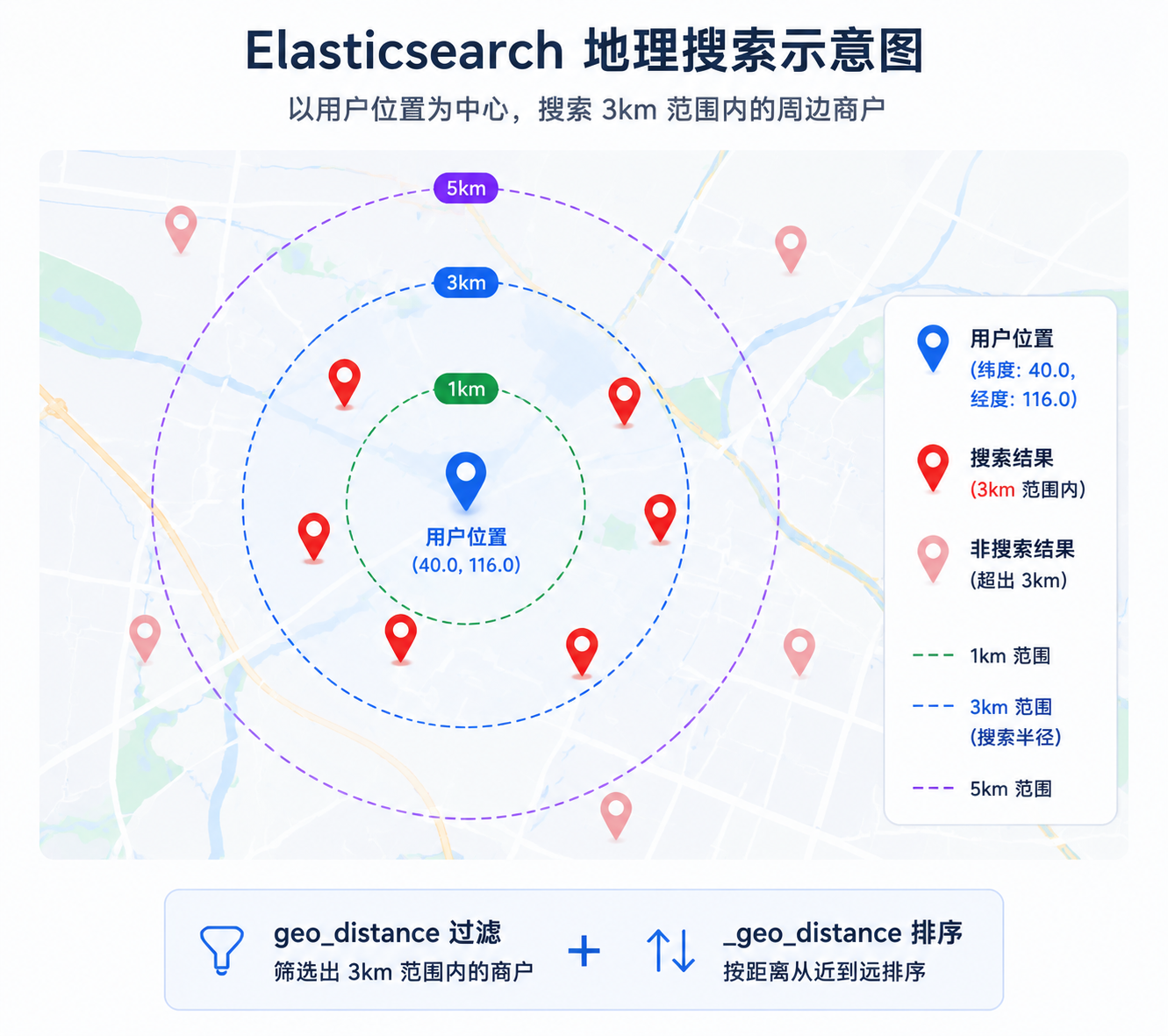
Q7. 如何实现"附近商户"按距离排序?
回答:
-
索引中商户位置字段设为
geo_point。 -
搜索时使用
geo_distance过滤范围,配合sort按距离排序:"sort": [ { "_geo_distance": { "location": { "lat": 40.0, "lon": 116.0 }, "order": "asc", "unit": "km" } } ] -
还可以用
geo_distance聚合统计不同距离范围内的商户数量。
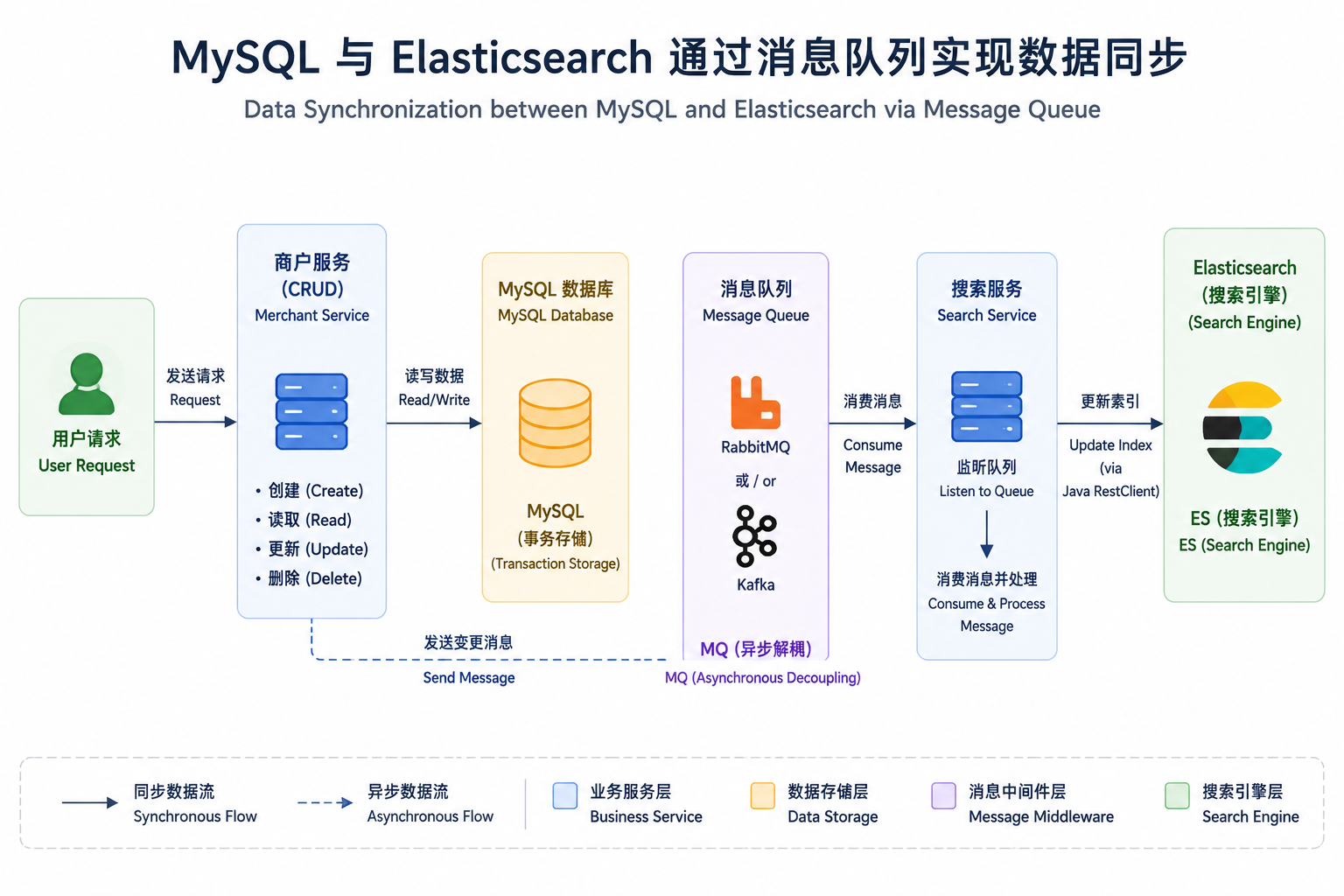
Q8. 项目中是如何保证 MySQL 与 ES 数据一致性的?
回答:
-
方案:采用 MQ(如 RabbitMQ 或 Kafka)实现异步同步。
-
商户服务(CRUD)完成后,发送消息到 MQ(如
shop.sync)。 -
搜索服务监听消息,解析后通过 Java RestClient 更新 ES 文档。
-
对于新增/修改,调用
IndexRequest或UpdateRequest;删除则调用DeleteRequest。
-
-
保障:利用消息队列的可靠性传输和重试机制,确保最终一致性。
-
防重:基于消息 ID 或业务 ID 实现幂等,避免重复更新。
Q9. 聚合分析在项目中有什么应用?举例说明。
回答:
-
应用 :搜索页面的筛选条件动态展示。
-
用户搜索"火锅"后,过滤栏应只展示搜索结果中实际存在的分类和区域。
-
使用带相同搜索条件的
terms聚合,对category和area字段聚合,获取桶中的 Key 和文档数。 -
将聚合结果返回前端渲染筛选条件。
-
-
补充 :还可统计各分类的平均消费、评分分布等(使用
stats子聚合),用于运营报表。
Q10. ES 分页有哪几种方式?黑马点评用哪种?
回答:
-
三种方式:
-
from + size:适用于浅分页,但深度受限(默认限制 10000)。 -
scroll:生成快照,适合数据导出,不推荐实时搜索。 -
search_after:基于排序值实时分页,推荐用于深度分页。
-
-
黑马点评中商户列表采用
from + size,因用户一般只浏览前几页;同时限制最大分页深度,防止性能问题。
Q11. ES 如何优化查询性能?
回答:
-
硬件和架构:合理分片、多副本,根据数据量设计集群。
-
索引设计 :减少不必要的字段索引(
index: false),用keyword代替text进行过滤。 -
查询优化:
-
用
filter代替must,利用缓存。 -
减少返回字段
_source过滤。 -
避免 wildcard、前缀通配等高性能损耗查询。
-
-
Java 客户端 :批量操作使用
BulkRequest,一次发送多条请求,减少网络开销。
Q12. ES 和 MySQL 是如何配合使用的?为什么不是只用一个?
回答:
-
MySQL 负责事务性数据的存储和强一致性操作(如订单、账户),擅长数据安全和 ACID。
-
ES 负责海量数据的搜索、分析和聚合,擅长高性能非结构化查询。
-
黑马点评中:
-
商户基本信息、用户订单由 MySQL 管理。
-
商户搜索、笔记搜索由 ES 负责。
-
通过 MQ 同步,既能保证事务安全又能保证搜索性能,达到优势互补。
-
三、总结
回顾全文,我们从 Elasticsearch 的核心原理 (倒排索引、IK 分词、Mapping)出发,到 Java RestClient 的实际操作 ,再到 黑马点评项目中的面试真题,形成了一条完整的知识链路。
面试小贴士:回答 ES 相关问题时,不要只背概念。面试官更希望听到你结合项目的真实思考------"我们项目里有 XX 场景,遇到了 XX 问题,我选择了 ES 的 XX 特性来解决,最终的 Mapping 是这样设计的......" 这样的回答才有说服力。
如果你想进一步深入,推荐阅读官方文档的 Elasticsearch Definitive Guide,并结合黑马点评的源码把搜索接口自己实现一遍------动手写一遍,胜过看十遍。