📌 写在前面
在日常工作和学习中,我们经常需要将文本内容转换为音频文件------制作有声书、生成课程音频、为视频配音等等。市面上的 TTS 工具要么收费昂贵,要么需要联网调用 API,要么功能单一不能满足批量处理的需求。
今天给大家推荐一款完全免费、本地运行、功能强大 的音频转换工具:Edge TTS 音频转换工具 v2.1。
它基于微软 Edge 浏览器官方 TTS 引擎开发,支持 TXT、DOC、DOCX 格式文件的批量转换,内置多种中文发音人 (大陆普通话、香港粤语、台湾国语),还能按段落或按行拆分文本,每个段落生成独立的音频文件。
开源地址:见文末(代码已附)
🚀 主要功能
| 功能模块 | 说明 |
|---|---|
| 📁 文件管理 | 支持添加单个文件、整个文件夹,支持移除/清空 |
| 🎤 发音人选择 | 大陆/香港/台湾三地发音人,按性别和风格分类展示 |
| 📢 参数调节 | 语速(-50%~+100%)、音量(-100%~+100%)、音调(-20Hz~+20Hz) |
| ✂️ 拆分模式 | 整文件模式 / 按段落拆分 / 按行拆分 |
| 💾 输出设置 | 自定义输出目录,自动避免文件名冲突 |
| 📋 运行日志 | 实时显示转换进度,支持导出日志 |
| 💾 设置保存 | 自动保存上次使用的参数和输出目录 |
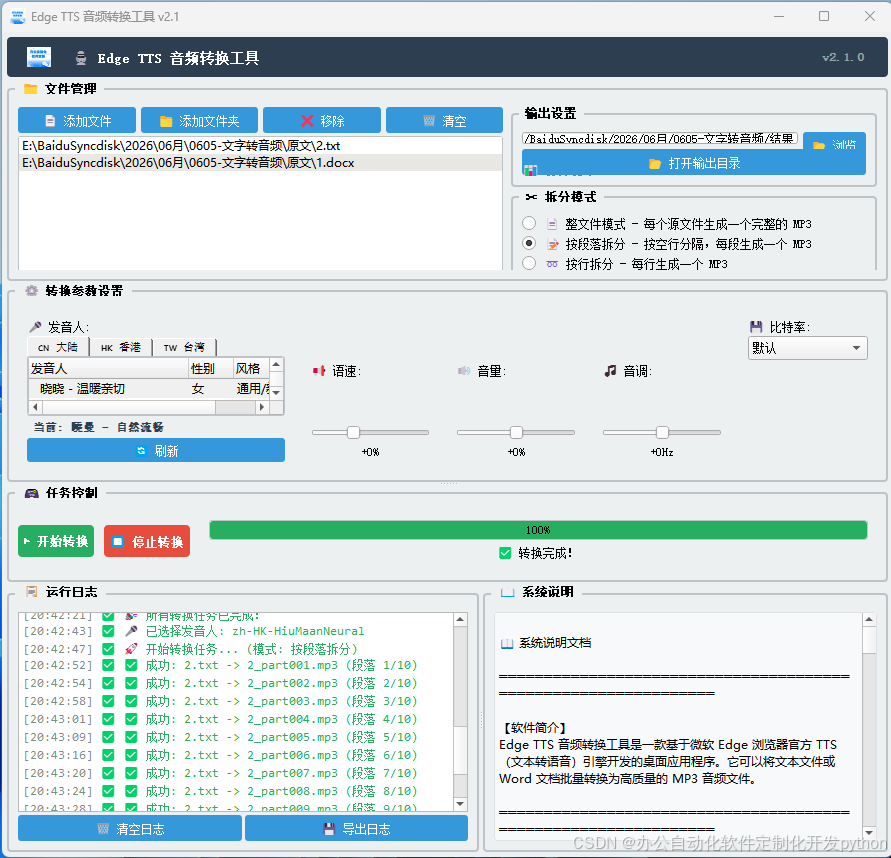
🖼️ 界面预览
🔧 核心代码解析
1. 文本拆分逻辑
def split_text_by_mode(text: str, mode: str) -> List[str]:
"""根据模式拆分文本"""
if mode == 'single':
return [text]
elif mode == 'paragraph':
# 按空行分割段落
paragraphs = [p.strip() for p in text.split('\n\n') if p.strip()]
return paragraphs if paragraphs else [text]
elif mode == 'line':
# 按行分割
lines = [line.strip() for line in text.split('\n') if line.strip()]
return lines if lines else [text]
return [text]2. 异步转换核心
async def convert_single_file(self, file_path: str, ...):
text_content = read_text_file(file_path)
text_segments = split_text_by_mode(text_content, self.split_mode)
for seg_idx, segment in enumerate(text_segments, 1):
communicate = edge_tts.Communicate(
text=segment,
voice=self.params['voice'],
rate=self.params['rate'],
volume=self.params['volume'],
pitch=self.params.get('pitch', '+0Hz')
)
await communicate.save(str(output_path))3. 发音人分类加载
# 按地区分类中文发音人
categorized_voices = {'zh-CN': [], 'zh-HK': [], 'zh-TW': []}
for voice in voices:
locale = voice["Locale"]
if locale.startswith("zh-CN"):
categorized_voices['zh-CN'].append(voice)
# ...📦 环境依赖
bash
pip install edge-tts PyQt5 python-docx注意:无需安装 FFmpeg(edge-tts 不依赖 FFmpeg)
🎯 使用场景
| 场景 | 推荐配置 |
|---|---|
| 有声书制作 | 晓伊/晓柔 + 按段落拆分 + 语速 -10% |
| 课程音频 | 晓晓 + 整文件模式 + 语速 0% |
| 粤语内容 | 曉佳/雲龍 + 香港发音人 |
| 广告配音 | 云希 + 语速 +20% + 音调 +5Hz |
| 批量文档转音频 | 任意发音人 + 添加文件夹 + 批量处理 |
💡 使用技巧
-
拆分模式的选择
-
整文件模式:适合完整的文章、报告
-
按段落拆分:适合有声书、章节分明的文档
-
按行拆分:适合诗歌、台词、逐句跟读材料
-
-
发音人推荐
-
通用场景:晓晓(女)、云健(男)
-
故事有声书:晓伊(女)
-
广告促销:云希(男)
-
-
参数调节
-
语速 -10%~0%:适合学习、跟读
-
语速 +10%~+20%:适合快速浏览
-
音量可根据原始文本适当调整
-
📝 完整代码
代码可以通过以下方式获取:
在评论区留言666.
🏆 版本更新记录
| 版本 | 更新内容 |
|---|---|
| v1.0 | 基础 TTS 转换功能 |
| v2.0 | 图形界面重构,三地发音人分类 |
| v2.1 | 新增段落/行拆分模式,自动保存设置 |
📌 总结
这款工具的核心优势在于:
✅ 完全免费 - 基于 Edge 官方 TTS,无需 API Key
✅ 本地运行 - 数据不上传,保护隐私
✅ 批量处理 - 支持文件夹批量导入
✅ 灵活拆分 - 按段落/按行,满足多种需求
✅ 界面友好 - 中文界面,操作直观
无论是制作有声书、生成课程音频,还是批量处理文档,这款工具都能帮你高效完成任务。
如果觉得有用,欢迎点赞、收藏、转发!
有任何问题或建议,欢迎在评论区留言交流~