NeuSO:面向子图查询的学习型优化器

北京大学数据管理实验室杨凌林博士关于学习型子图查询优化器的论文《NeuSO: Neural Optimizer for Subgraph Queries》被 SIGMOD 2026 接收。
引言
图数据模型由于能够自然表达实体之间的复杂关系,近年来在社交网络、生物信息、知识图谱等领域得到了广泛应用。围绕图数据的查询与分析,也逐渐成为数据库研究的重要方向。在众多图查询任务中,子图查询是一类非常基础而又极具挑战性的问题。其目标是:给定一个查询图和一个数据图,在数据图中找出所有满足标签约束与拓扑约束的匹配子图。本论文聚焦的正是这一问题,本论文提出了一种面向子图查询的新型学习型优化器 NeuSO,试图以神经网络方法替代传统依赖启发式规则的匹配顺序生成机制,从而在保证优化质量的同时兼顾执行效率。
研究背景:子图查询中的优化问题
子图查询是图数据库中的关键任务之一。对于一个查询图,系统通常需要在大规模数据图中寻找与之同构的所有子图匹配结果。本论文采用具有代表性的子图同构语义:查询图中的每个顶点需要映射到数据图中的一个顶点,满足顶点标签一致、查询边在数据图中也存在,并且这一映射是单射。
从执行过程看,子图查询通常包含三个阶段:过滤 、规划 和枚举 ,如下图所示1。首先,过滤阶段通过各种剪枝技术为每个查询顶点生成候选集合,从而缩小搜索空间;其次,规划阶段决定查询顶点的匹配顺序,也就是执行计划;最后,枚举阶段按照既定顺序逐步扩展部分匹配,得到最终结果。规划阶段也常被成为查询优化阶段,其产生的匹配顺序对整体执行效率具有重要的影响 ,不同的匹配顺序可能导致中间结果规模出现巨大差异,从而使枚举时间相差几个数量级。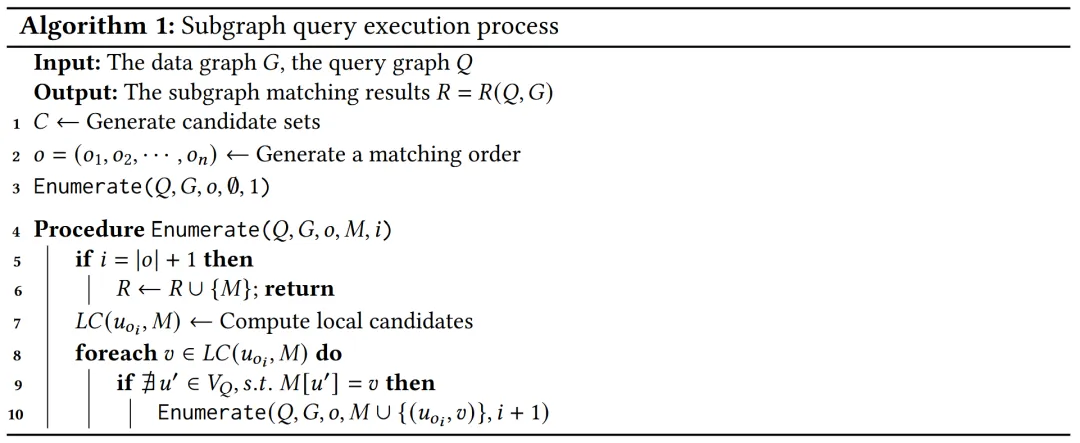
现有子图匹配方法虽然在过滤技术和枚举加速方面已有大量研究,但在匹配顺序优化方面,主流方法仍然存在明显局限,现有方法可以概括为三类。
第一类是基于结构的启发式方法23。这类方法仅依据查询图本身的结构来决定匹配顺序,因此对于同一个查询图,无论数据图如何变化,生成的顺序都基本相同。这种方式忽略了数据图的分布特征,在数据存在偏斜时可能带来显著性能下降。
第二类是基于规则的启发式方法456。这类方法会参考顶点度数、候选集合大小等简单统计量来进行排序。虽然比纯结构方法更具适应性,但其规则设计通常较为粗糙,难以捕捉更复杂的影响因素,因此很容易得到次优顺序,这种偏差在某些查询上甚至可能使性能比最优方案差出数个数量级。
第三类是基于动态规划的方法78。这类方法从更系统的角度枚举子计划,并尝试找到全局更优的匹配顺序。然而,图查询通常包含更多顶点与边,导致计划空间非常庞大。对于较大的查询图,动态规划的代价会迅速上升,在实际系统中往往难以承受。
正是在这一背景下,本文提出了一个核心问题:是否能够借助机器学习,为子图查询构建一种兼具精度与效率的优化器。
研究动机
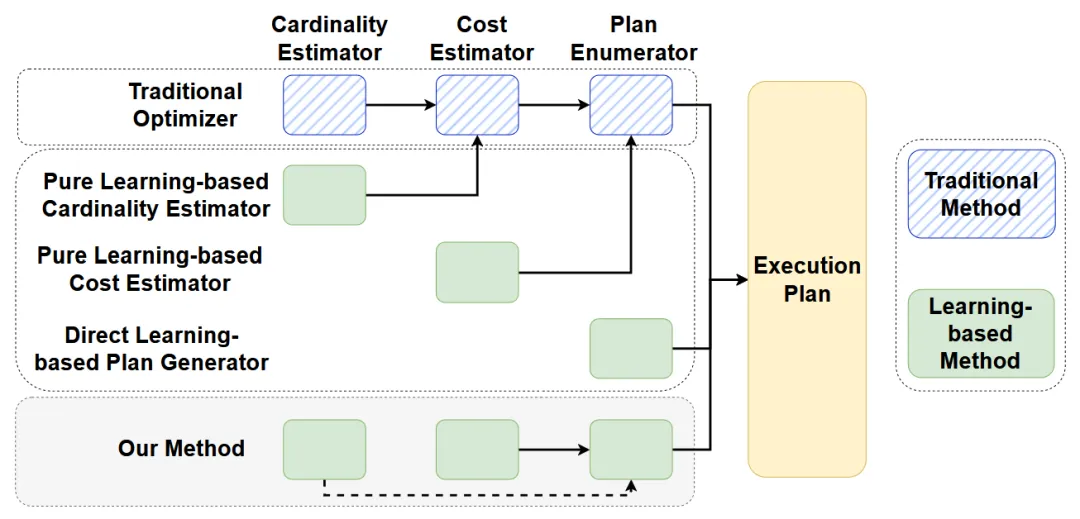
近年来,关系数据库中的学习型优化器成为一个活跃方向。在传统关系数据库中,优化器通常由三个核心部分组成:基数估计器 、代价估计器 以及计划枚举器。其中,计划枚举器负责生成候选执行计划,代价估计器基于基数估计结果来预测每个计划的执行代价,并最终选出代价最低的方案。
围绕这一经典框架,关系数据库领域已经出现了多种学习型方法。论文将其概括为三种类型:一类使用机器学习替代传统基数估计器;一类直接学习执行代价;还有一类通过强化学习等方式直接生成执行计划,而不显式区分基数估计与代价估计。该分类如下图所示。
然而,这些方法通常并不能直接迁移到子图查询场景,原因主要有以下两个方面。
首先,关系数据库中的表模式通常较固定,而图数据则具有更强的异构性和模式灵活性。图查询中的连接关系并不像关系数据库中那样明确受限于表结构,因此学习模型所面对的输入形式更加复杂。
其次,子图查询本质上涉及大量连接操作,计划空间远大于一般的关系查询,这使得许多关系数据库中的学习型方法在图查询中无法保持合理的在线效率。
尽管目前已有一些面向图任务的学习方法虽然能够做子图计数或子图查询的基数估计9101112,但大多数只关注整个查询图,而不是优化器真正需要的大量子查询。而在子图查询优化中,必须频繁估计不同子查询的基数与代价,这使得直接沿用现有方法变得非常困难。并且这些方法所使用的图神经网络方法依赖消息传递神经网络,也就是 MPNN 框架。这类模型在表达能力上受限于 1-WL 测试,难以区分一些在子图查询优化中十分关键的结构差异。
因此,本论文并非简单地将已有学习型优化器"移植"到图数据库中,而是从子图查询的特点出发,重新设计了一套完整的优化框架 NeuSO。
NeuSO 的总体思想
从整体结构上看,NeuSO 由三部分组成:查询图编码器 、基数与代价预测器 、以及计划枚举器。下图的整体框架图中给出了清晰说明:当一个查询图输入系统后,首先经过过滤阶段提取与查询相关的统计信息;随后,这些统计信息连同查询图结构一起被送入查询图编码器,通过图神经网络编码得到查询图以及各个子查询的表示;接着,预测器基于这些表示估计子查询基数、连接代价和最小代价;最后,计划枚举器利用这些估计结果生成最终的匹配顺序。
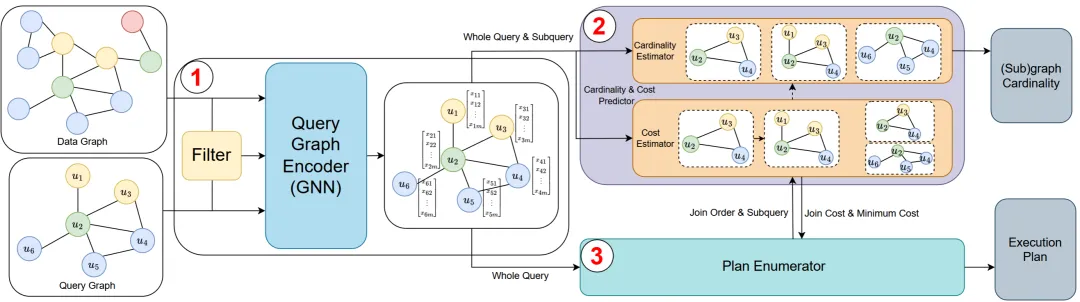
与已有学习型优化方法相比,NeuSO 的一个突出特点是:它不是只学习某一个中间量,而是采用多任务学习框架 ,同时学习子查询基数 与执行代价。这两类信息本质上都属于子查询的内在属性,将它们放在统一框架中联合建模,可以帮助模型学到更鲁棒、更准确的子查询表示。
除此之外,NeuSO 还引入了一个新的概念,即最小代价。它表示从空查询状态到某个子查询状态的最佳执行代价。通过对这一量进行学习,NeuSO 可以在不完整遍历整个计划空间的前提下,以一种自顶向下的方式高效生成高质量计划。
查询图编码器
NeuSO 的第一步,是通过一个图神经网络对查询图进行编码。这一步的关键不只在于使用某种 GNN,更在于如何设计输入特征,以及如何使模型真正感知到查询执行中有意义的结构信息。
初始特征的构造
在图任务中,最基本的顶点特征通常是标签信息。现有工作常常对顶点标签采用 one-hot 编码,但这种做法存在两个问题。其一,表示过于稀疏,不利于学习;其二,只反映了标签本身,无法体现数据图中的结构分布。
为了解决这一问题,本论文首先在一个标签增强图上预训练标签嵌入。这个增强图为每种标签引入一个标签顶点,并将原图中的每个顶点与其对应标签顶点相连。随后,可使用现有图嵌入方法对这一增强图进行训练,从而得到每个标签的向量表示。在实验中,作者采用的是 ProNE。
不过,仅依赖标签嵌入仍然不够,因为同标签顶点在不同查询中的作用可能差异很大。为此,NeuSO 进一步引入了过滤阶段获得的统计信息。具体而言,对于每个查询顶点,模型会使用其候选集合大小;对于每条查询边,模型会使用对应候选边数量。这些统计量不是从原始数据图直接获得,而是从过滤后与查询相关的图上提取,因此更加贴近实际执行过程:最终的顶点初始特征由标签嵌入与候选集大小拼接而成,边特征由两端顶点特征与候选边数量拼接得到:
xu(0)=xL(u)⊕∣C(u)∣,xe(u1,u2)(0)=xu1(0)⊕xu2(0)⊕∣C(u1,u2)∣. x_u^{(0)} = x_{L(u)} \oplus |C(u)|,\\ x_{e(u_1, u_2)}^{(0)} = x_{u_1}^{(0)}\oplus x_{u_2}^{(0)}\oplus |C(u_1, u_2)|. xu(0)=xL(u)⊕∣C(u)∣,xe(u1,u2)(0)=xu1(0)⊕xu2(0)⊕∣C(u1,u2)∣.
TriAT:三角注意力网络
在完成初始特征构造后,NeuSO 提出一种新型 GNN,即 TriAT,来编码查询图。TriAT 的提出基于一个重要观察:标准消息传递 GNN 无法区分某些拓扑结构不同、但局部邻域统计相似的图。论文给出了一个直观示例,两张图中某些顶点虽然处于不同的全局结构位置,但因为其邻居标签分布相同,普通 MPNN 会为它们产生相同表示。
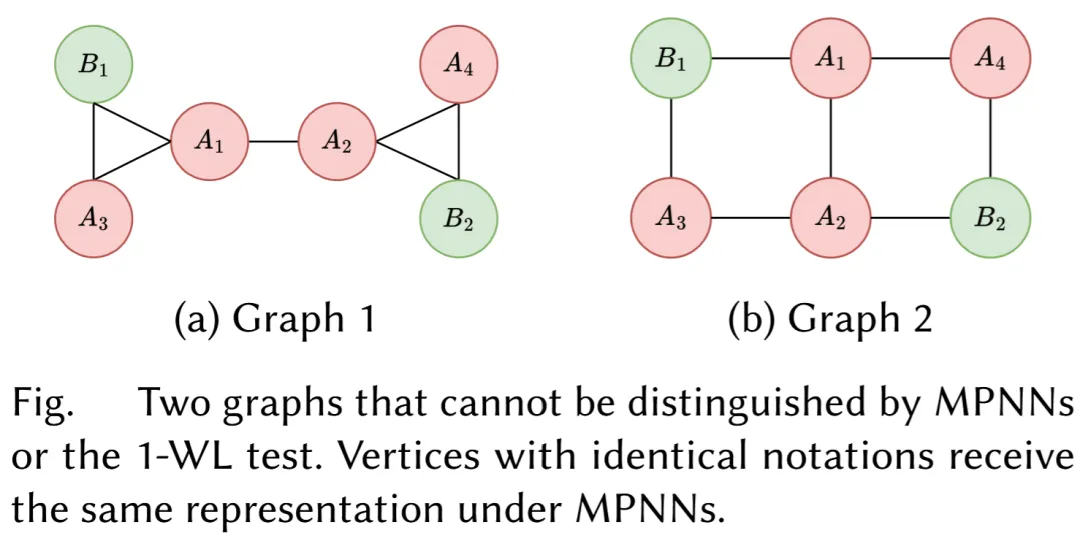
对于子图查询优化而言,这种表达能力不足会直接影响计划质量。不同拓扑模式可能对应不同的最佳匹配顺序,若编码器无法捕获这些差异,后续代价估计就很难准确。
为此,TriAT 在更新某个顶点表示时,不仅考虑其一跳邻居,还显式考虑这些邻居之间的边。换言之,它不仅聚合"与该顶点直接相连的结构信息",也聚合"该顶点邻居之间是否形成三角结构"的信息。三角形作为最简单的环结构,在真实图查询中非常普遍,也是更复杂稠密模式的重要基本单元。
TriAT 的核心机制可以概括为两部分:一部分使用注意力机制聚合邻居顶点及其边信息,另一部分使用注意力机制聚合邻居之间边的信息。之后,顶点表示通过非线性函数进行更新,边表示也在每一层根据两端点表示同步更新。下图展示了对于一个图顶点,TriAT 如何更新其节点表示。论文还采用了多头注意力以进一步增强表达能力。
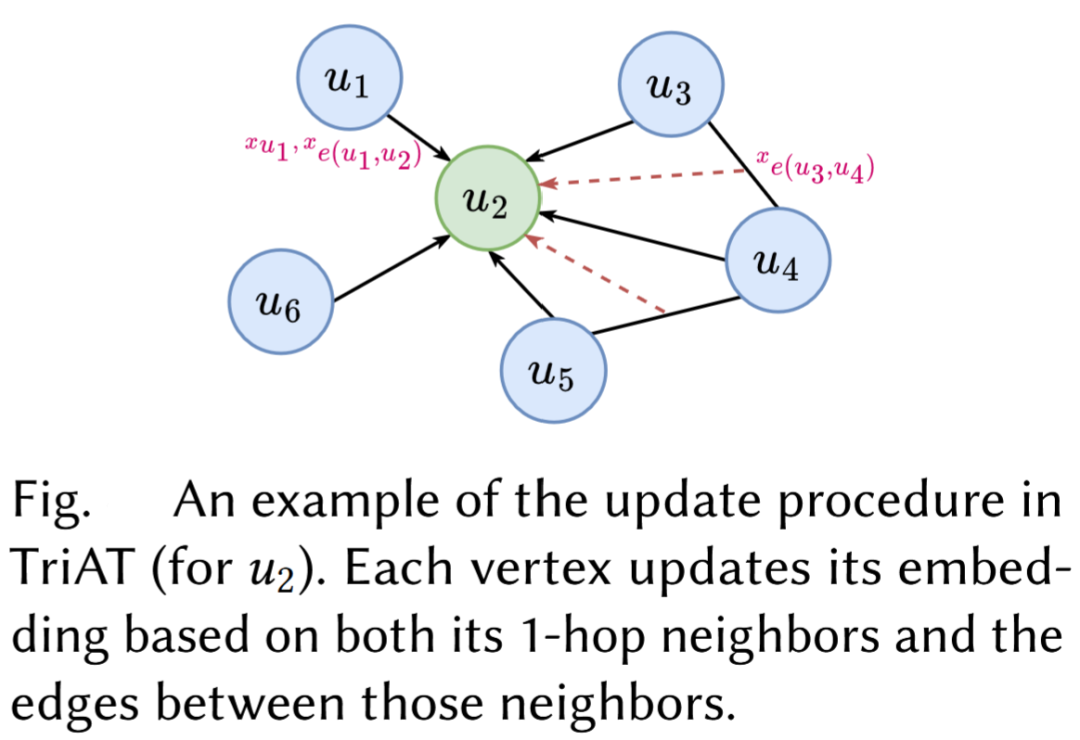
从理论上,论文证明了 TriAT 的表达能力严格强于标准 MPNN 和 1-WL 测试;从复杂度上看,其单层时间复杂度为 O(∣E∣+∣Δ∣)O(|E|+|\Delta|)O(∣E∣+∣Δ∣),其中 ∣Δ∣|\Delta|∣Δ∣ 是图中三角形数量,空间复杂度为 O(∣E∣)O(|E|)O(∣E∣)。
(子)查询图的表示
经过 GNN 编码后,查询图中每个顶点都得到一个高维表示。为了支持优化过程,NeuSO 还需要为任意子查询构造整体表示。为此,论文采用了一种基于自注意力的加权池化方式,对子查询 qqq 中的顶点表示进行聚合,如下面的公式所示。其核心思想是,并非每个顶点对最终执行代价的影响都相同,例如高阶顶点通常带来更强的拓扑约束,因此应在表示中占据更大权重。
xq=∑u∈Vqαuxu, x_q = \sum_{u\in V_q}\alpha_u x_u, xq=u∈Vq∑αuxu,
这一设计使得 NeuSO 不仅能够表示完整查询图,也能够按需构造任意中间子查询的表示,从而支持后续的基数估计与代价预测。
子图查询优化与状态空间上的最短路径问题
本论文中指出子图查询中的匹配顺序,本质上可以看作一个从空查询逐步扩展到完整查询的状态转移过程。每个状态对应一个连通子查询,每次状态转移表示向当前子查询中加入一个与之相邻的新顶点。
基于这一观察,论文定义了一种新的结构,称为 Cardinality-Cost Graph ,简称 CCG。在这张图中:
- 每个顶点表示一个连通子查询状态,包括空查询和完整查询;
- 每条边表示一次由较小子查询扩展到较大子查询的转移;
- 每个状态对应其真实基数;
- 每次状态转移对应其执行代价。
于是,一个完整的匹配顺序就对应于 CCG 上从空状态到完整查询状态的一条路径,而其总代价则是这条路径上各步执行代价之和。例如下面的图中右边的红色路径代表了一个匹配顺序为:(A,B,D,C)(A, B, D, C)(A,B,D,C)。这样,优化目标就自然转化成:在 CCG 上寻找一条最短路径。
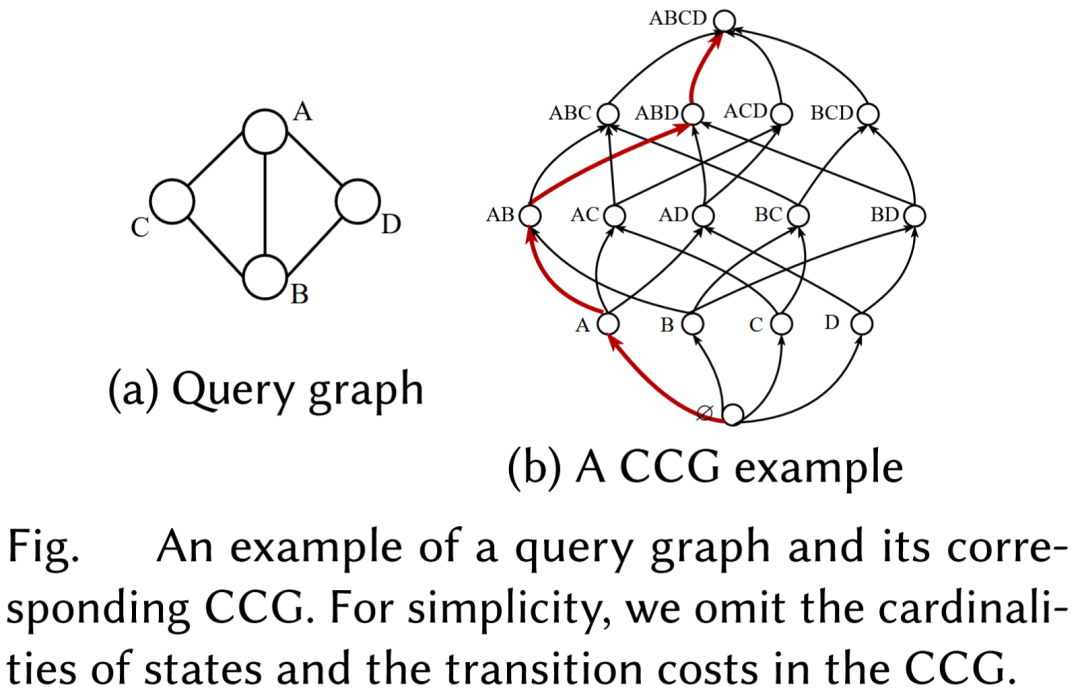
不过由于查询图的连通子查询数量极大,完整构造和遍历 CCG 在大查询上几乎不可行。因此,NeuSO 的下一个关键问题是:在不完整遍历 CCG 的前提下,如何利用神经模型预测结果高效生成高质量执行计划。
基数估计、单步代价估计与最小代价估计
在 CCG 框架下,NeuSO 需要估计两类核心信息:状态的基数,以及状态转移的代价。本论文采用多层感知机来分别完成这些任务。
对于任意子查询状态,NeuSO 利用其表示向量输入到一个基数估计 MLP 中,直接预测该子查询的基数。
对于两个相邻状态之间的转移,NeuSO 同样直接使用一个 MLP,将起始状态和目标状态的表示拼接后输入模型,端到端学习该步连接代价。这种方式避免了手工代价模型容易忽略存储开销等因素、并且会受到基数误差的累积影响等问题,更加稳健。
在此基础上,本论文进一步提出了一个新概念:状态的最小代价。它定义为从空查询到该状态的所有可能路径中总代价最小者。也就是说,它刻画了"达到这个子查询状态时,理论上最优的历史代价"。NeuSO 通过另一个 MLP 直接对这一量进行预测。
通过引入最小代价估计,模型不再只关注某一步"当前扩展代价",而是能够显式地对整个历史最优路径进行建模。这也为后续计划枚举算法奠定了基础。
自顶向下的计划枚举器
在传统动态规划优化器中,最小代价通常是通过自底向上遍历所有子状态计算出来的。然而,对大规模图查询而言,这种方式代价过高。NeuSO 因此设计了一种自顶向下的贪心式计划枚举算法。
这一算法的起点是完整查询状态。对于当前状态,算法会考察其所有可能的前驱状态。对每个前驱状态 q′q'q′,计算"从 q′q'q′ 转移到当前状态的单步代价估计"与"到达 q′q'q′ 的最小代价估计"之和。选择和最小的那个前驱状态,就意味着确定了当前状态最后加入的那个顶点。然后,算法继续对选中的前驱状态递归执行同样过程,直到回溯到空查询状态。最终,将这些被逆序恢复出来的顶点连接起来,就得到完整的匹配顺序。该流程如下面的算法所示。

这一方案避免了完整构造整张 CCG,只探索那些更有希望位于最优路径上的状态,因此在复杂度上显著优于传统动态规划。在模型推理代价视为常数时,该算法复杂度可近似视为 O(∣VQ∣2)O(|V_Q|^2)O(∣VQ∣2),相比需要遍历指数级状态空间的 DP 方法有明显优势。
训练细节
为了训练 NeuSO,需要构造包含基数、单步代价和最小代价的监督数据。首先需要准备一组具有代表性的查询图,这些查询可以来自用户日志,也可以通过模板模拟生成。对每个查询图,系统构造其对应的 CCG,并记录每个状态的基数、每条状态转移的执行代价以及状态的最小代价。
然而,对于大规模查询图,完整遍历整个 CCG 的成本非常高。为此,本论文提出了一种部分收集策略。具体来说,对于较大或较复杂的查询,作者先使用已有优化器生成一个较优匹配顺序,再围绕这一顺序上的状态及其相邻状态收集监督样本。这样,可以在控制收集成本的同时,尽可能保留对优化最有帮助的信息。
在训练目标上,NeuSO 采用多任务损失函数。对于基数、代价和最小代价三个任务,论文都使用了基于对数变换的 L2 损失,以便更合理地衡量不同数量级上的预测误差。除此之外,作者还加入了一个约束损失,用于保证最小代价预测与单步代价预测之间的一致性。例如,如果某个状态的最小代价预测小于其所有可能单步代价中的最小值,那么这种不合理情形就会受到惩罚。
实验分析
实验设置
在实验部分,论文选择了六个常用真实数据集,包括 Yeast、HPRD、DBLP、EU2005、YouTube 和 Patents,涵盖生物网络、社交网络、网页图和引文网络等不同应用场景。数据集在规模、平均度数和标签数量上存在明显差异,有助于全面评估方法的泛化能力。
查询图则依据相关子图查询工作1的设置生成,通过从数据图中随机抽取连通子图构造,保证每个查询至少在数据图中存在一个匹配结果。查询规模从 4 个顶点变化到 32 个顶点,并进一步区分为稠密查询和稀疏查询。
在对比方法上,本论文选择了多种传统子图查询顺序优化方法,包括 QSI12、GQL13、RI2、RM3 和 DPiso6;同时也纳入了现有工作中的学习型方法 RLQVO14。为了保证比较公平,所有方法在过滤和枚举阶段保持一致,差别仅在于匹配顺序生成方式。
实验结果分析
匹配顺序质量
论文首先以枚举时间作为指标比较不同方法生成的匹配顺序质量。由于过滤和枚举过程保持一致,枚举时间的差异可以较为直接地反映顺序优劣。结果表明,NeuSO 在多个数据集上显著优于现有方法,枚举效率相对提升达到 1.63 倍至 47.93 倍。
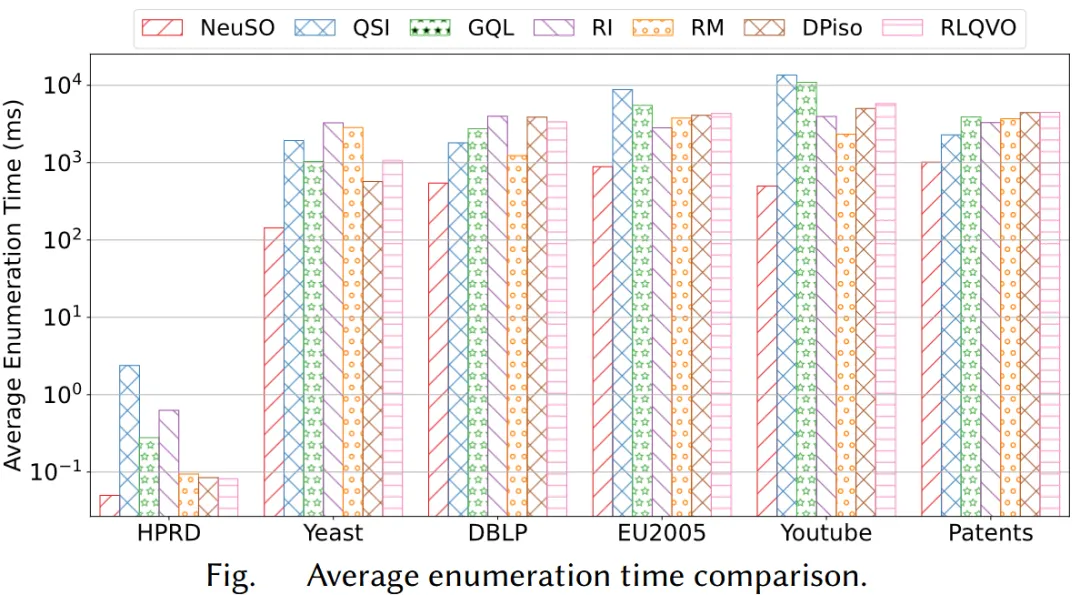
不同匹配顺序对执行效率影响极大。即便在某些相对简单的数据集上,学习型方法 RLQVO 已能优于传统方法,但在更复杂的数据集上它并不稳定,有时甚至逊于一些经典启发式方法。相比之下,NeuSO 在不同查询规模和不同数据图上都表现出更强的一致性。这主要得益于更强的查询图编码器、更丰富的输入统计信息,以及基于子查询状态而非单个顶点的优化建模方式。
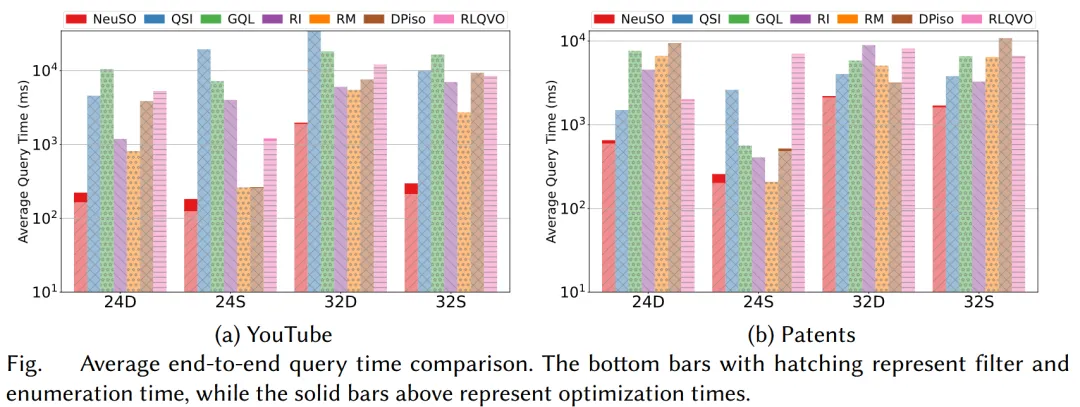
端到端运行时间
除了单纯比较枚举时间,论文还进一步评估了端到端查询运行时间,也就是将优化时间本身纳入考虑。结果显示,虽然 NeuSO 在优化阶段需要额外的神经模型推理开销,但由于其生成的计划质量更高,整体查询时间仍然优于其他方法。
消融实验
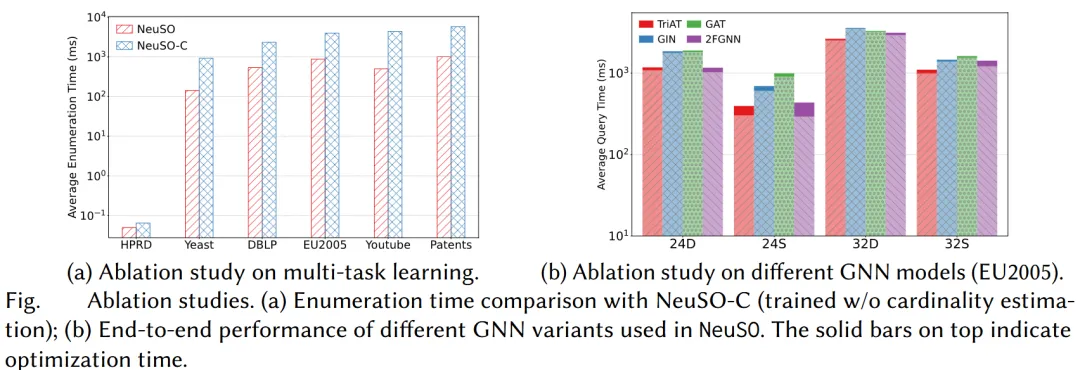
在多任务学习的消融实验中,本论文去掉基数估计任务,仅保留代价学习,得到一个变体模型。实验表明,完整的 NeuSO 相比这一变体仍能取得 1.31 倍到 8.78 倍的加速,说明联合学习基数与代价确实有助于提高表示质量与优化性能。
在 GNN 模块的消融实验中,本论文用 GIN、GAT 和基于 2-FWL 的 2FGNN 替换 TriAT。结果表明,TriAT consistently 优于 GIN 和 GAT,并在效果上接近更复杂的 2FGNN,而在线效率更好。这说明 TriAT 的设计确实适合这一任务。
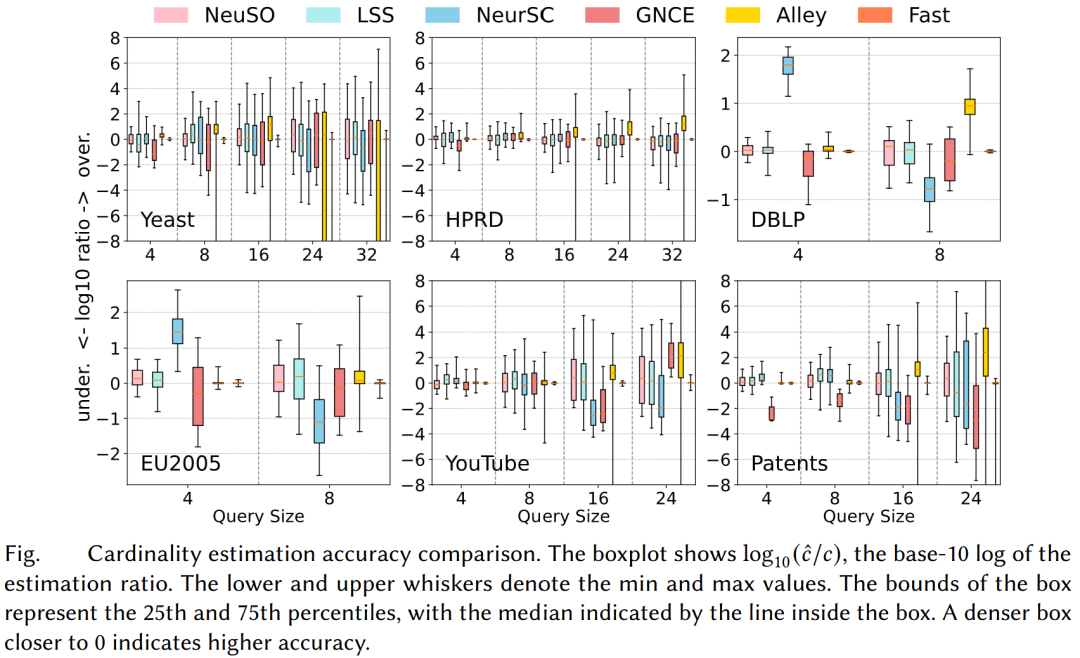
基数估计能力
虽然 NeuSO 的主要目标是优化匹配顺序,但其多任务框架中也包含基数估计模块。论文将其与 LSS9、NeurSC10、GNCE11、Alley15 和 Fast16 等方法进行对比。结果显示,NeuSO 的基数估计准确率总体优于其他多数学习型方法,在推理时间上也远快于一些高成本采样方法。
总结
总体而言,这篇论文围绕子图查询中的"匹配顺序优化"问题,提出了一套较为完整且具有针对性的学习型优化框架。与已有工作相比,NeuSO 的贡献主要可以概括为以下几个方面。
首先,论文提出了一个多任务学习框架,同时建模子查询基数、状态转移代价和最小代价,增强了子查询表示的质量与鲁棒性。
其次,论文设计了新的查询图编码器 TriAT,通过显式引入三角结构信息,突破了传统消息传递 GNN 在表达能力上的局限。
再次,论文提出了基于CCG 与最小代价估计的自顶向下计划枚举策略,避免了对子查询状态空间的完整遍历,从而兼顾了优化质量与在线效率。
最后,从实验结果看,NeuSO 在多个真实数据集和不同查询规模下都取得了显著优势,既优于传统启发式方法,也优于已有学习型方法,表明该工作具有较强的实际意义。
从更大的研究背景来看,NeuSO 的价值并不仅限于提出了一个新的图查询优化器。更重要的是,它展示了一个值得关注的方向:在图数据库中,学习型方法并不是简单替代传统优化器,而是可以与传统过滤、代价建模和计划枚举机制深度结合,形成更符合系统需求的混合式优化框架。这种思路对于未来图数据库优化器的设计,具有一定启发意义。
参考文献
1: Shixuan Sun and Qiong Luo. 2020. In-memory subgraph matching: An in-depth study. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 1083--1098.
2: Vincenzo Bonnici, Rosalba Giugno, Alfredo Pulvirenti, Dennis Shasha, and Alfredo Ferro. 2013. A subgraph isomorphism algorithm and its application to biochemical data. BMC bioinformatics 14 (2013), 1--13.
3: Shixuan Sun, Xibo Sun, Yulin Che, Qiong Luo, and Bingsheng He. 2020. Rapidmatch: A holistic approach to subgraph query processing. Proceedings of the VLDB Endowment 14, 2 (2020), 176--188.
4: Bibek Bhattarai, Hang Liu, and H Howie Huang. 2019. Ceci: Compact embedding cluster index for scalable subgraph matching. In Proceedings of the 2019 International Conference on Management of Data. 1447--1462.
5: Fei Bi, Lijun Chang, Xuemin Lin, Lu Qin, and Wenjie Zhang. 2016. Efficient subgraph matching by postponing cartesian products. In Proceedings of the 2016 International Conference on Management of Data. 1199--1214.
6: Myoungji Han, Hyunjoon Kim, Geonmo Gu, Kunsoo Park, and Wook-Shin Han. 2019. Efficient subgraph matching: Harmonizing dynamic programming, adaptive matching order, and failing set together. In Proceedings of the 2019 International Conference on Management of Data. 1429--1446.
7: Xiyang Feng, Guodong Jin, Ziyi Chen, Chang Liu, and Semih Salihoğlu. 2023. Kùzu graph database management system. In The Conference on Innovative Data Systems Research, Vol. 7. 25--35.
8: Amine Mhedhbi and Semih Salihoglu. 2019. Optimizing subgraph queries by combining binary and worst-case optimal joins. Proceedings of the VLDB Endowment 12, 11 (2019), 1692--1704.
9: Kangfei Zhao, Jeffrey Xu Yu, Hao Zhang, Qiyan Li, and Yu Rong. 2021. A learned sketch for subgraph counting. In Proceedings of the 2021 International Conference on Management of Data. 2142--2155.
10: Hanchen Wang, Rong Hu, Ying Zhang, Lu Qin, Wei Wang, and Wenjie Zhang. 2022. Neural subgraph counting with Wasserstein estimator. In Proceedings of the 2022 International Conference on Management of Data. 160--175.
11: Tim Schwabe and Maribel Acosta. 2024. Cardinality estimation over knowledge graphs with embeddings and graph neural networks. Proceedings of the ACM on Management of Data 2, 1 (2024), 1--26.
12: Haichuan Shang, Ying Zhang, Xuemin Lin, and Jeffrey Xu Yu. 2008. Taming verification hardness: an efficient algorithm for testing subgraph isomorphism. Proceedings of the VLDB Endowment 1, 1 (2008), 364--375.
13: Huahai He and Ambuj K Singh. 2008. Graphs-at-a-time: query language and access methods for graph databases. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 405--418.
14: Hanchen Wang, Ying Zhang, Lu Qin, Wei Wang, Wenjie Zhang, and Xuemin Lin. 2022. Reinforcement learning based query vertex ordering model for subgraph matching. In 2022 IEEE 38th International Conference on Data Engineering (ICDE). IEEE, 245--258.
15: Kyoungmin Kim, Hyeonji Kim, George Fletcher, and Wook-Shin Han. 2021. Combining sampling and synopses with worst-case optimal runtime and quality guarantees for graph pattern cardinality estimation. In Proceedings of the 2021 International Conference on Management of Data. 964--976.
16: Wonseok Shin, Siwoo Song, Kunsoo Park, and Wook-Shin Han. 2024. Cardinality Estimation of Subgraph Matching: A Filtering-Sampling Approach. Proceedings of the VLDB Endowment 17, 7 (2024), 1697--1709.