提示:本文原创作品,良心制作,干货为主,简洁清晰,一看就会
文章目录
- 前言
- 一、整体概述
-
- [1.1 实验环境](#1.1 实验环境)
- [1.2 K8s基于Prometheus Operator全链路监控指标采集流程](#1.2 K8s基于Prometheus Operator全链路监控指标采集流程)
- 二、监控kube-controller-manager
-
- [2.1 查看集群情况](#2.1 查看集群情况)
- [2.2 修改kube-controller-manager.yaml](#2.2 修改kube-controller-manager.yaml)
- [2.3 创建svc](#2.3 创建svc)
- [2.4 查看dashboard](#2.4 查看dashboard)
- 三、监控kube-scheduler
-
- [3.1 查看集群情况](#3.1 查看集群情况)
- [3.2 修改kube-scheduler.yaml](#3.2 修改kube-scheduler.yaml)
- [3.3 创建svc](#3.3 创建svc)
- [3.4 查看dashboard](#3.4 查看dashboard)
- 四、监控kube-proxy
-
- [4.1 查看集群情况](#4.1 查看集群情况)
- [4.2 修改kube-proxy的configmap](#4.2 修改kube-proxy的configmap)
- [3.3 创建svc](#3.3 创建svc)
- [3.4 创建servicemonitor](#3.4 创建servicemonitor)
- [3.5 查看dashboard](#3.5 查看dashboard)
前言
摘要: 本文详细记录了在kubeadm部署的Kubernetes 1.28高可用集群中,基于Prometheus Operator实现kube-controller-manager、kube-scheduler和kube-proxy等核心组件监控的完整实践。针对Prometheus Operator自动创建ServiceMonitor但缺少对应Service导致监控数据缺失的问题,文章提供了系统性的解决方案:首先修改组件配置文件暴露监控端口,然后手动创建Service资源关联静态Pod,最后通过ServiceMonitor自动发现机制完成指标采集。通过分步操作指南、YAML配置示例和可视化验证,帮助读者构建生产可用的Kubernetes全链路监控体系。
本文档基于kubeadm安装Kubernetes1.28高可用集群,手把手搭建一套能直接上生产的Prometheus监控,不仅做好数据持久化、外网访问,还包含etcd专属监控配置
Prometheus监控K8S:https://blog.csdn.net/m0_63756214/article/details/161484786?spm=1001.2014.3001.5501
在上文中我们已经完成Prometheus部署与持久化,集群大部分指标能自动采集,也分享过etcd的监控实操
不少小伙伴部署完后碰到了常见难题:打开Grafana一看,kube-controller-manager、kube-scheduler、kube-proxy这些面板空空如也没有数据;本篇就逐个落地,帮大家一一解决以上问题
一、整体概述
1.1 实验环境
我的实验环境:
| 主机名 | ip | 作用 |
|---|---|---|
| K8s-master1 | 192.168.13.136 | k8s控制节点 |
| K8s-master2 | 192.168.13.137 | k8s控制节点 |
| K8s-master3 | 192.168.13.138 | k8s控制节点 |
| k8s-node1 | 192.168.13.139 | k8s工作节点 |
| k8s-node2 | 192.168.13.140 | k8s工作节点 |
| NFS | 192.168.13.141 | NFS服务端,提供持久化存储 |
1.2 K8s基于Prometheus Operator全链路监控指标采集流程
用 Prometheus Operator 标准化管理 Prometheus,ServiceMonitor 声明式配置监控规则,依托 K8s 原生 Service/Endpoints 自动发现 Pod,完成指标采集存储并由 Grafana 展示的云原生监控全流程
yaml
【用户编写资源】
↓
1. ServiceMonitor(CRD:采集规则说明书)
配置:标签筛选规则、metrics端口、抓取周期
↓(Operator持续监听CRD变更)
2. Prometheus Operator控制器
✅ 自动解析所有ServiceMonitor
✅ 自动生成prometheus.yml配置文件(内置kubernetes_sd_configs K8s服务发现+relabel规则)
✅ 热更新Prometheus配置,无需手动重启Prometheus Pod
↓(配置下发至Prometheus实例)
3. Prometheus Server
依托配置调用K8s APIServer,触发【K8s Endpoints服务发现】
↓(APIServer查询集群资源关联关系)
4. Service资源(关键中转层)
· Service依靠selector标签绑定后端Pod
· K8s控制器自动生成对应Endpoints(Endpoints=Pod真实IP+端口清单)
· ServiceMonitor靠spec.selector匹配Service标签,命中即纳入采集任务
↓(解析Endpoints列表)
5. Endpoints = 实际监控目标(每个Pod IP:metrics端口)
↓
6. 业务/组件Pod(kube-controller-manager/etcd/node-exporter等)
暴露 /metrics 指标接口
↓
7. Prometheus定时拉取指标存入时序数据库
↓
8. Grafana配置Dashboard读取Prometheus数据源,可视化展示监控数据二、监控kube-controller-manager
采用kube-prometheus-stack(Operator)部署监控时,系统会自动生成kube-controller-manager的ServiceMonitor采集规则,但不会自动生成配套Service。因kube-controller-manager由master节点/etc/kubernetes/manifests托管,属于静态Pod,集群原生无对应Service资源,致使Prometheus无法发现采集目标。因此需手动创建Service,通过标签Selector关联所有kube-controller-manager实例
2.1 查看集群情况
yaml
## 系统自动生产了kube-controller-manager 的 servicemonitor
root@k8s-master1:~# kubectl get servicemonitor -n monitoring | grep kube-controller-manager
kube-controller-manager 4d23h
## 查看kube-controller-manager默认安装的servicemonitor的yaml
root@k8s-master1:~# kubectl get servicemonitor kube-controller-manager -n monitoring -oyaml
yaml
## 搭建K8S集群的时候,可以看到kube-controller-manager没有自动创建svc
root@k8s-master1:~# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.101.28.178 <none> 2379/TCP 40h
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 55d
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 5d19h
## 查看kube-controller-manager的pod
root@k8s-master1:~# kubectl get pod -n kube-system | grep kube-controller-manager
kube-controller-manager-k8s-master1 1/1 Running 55d
kube-controller-manager-k8s-master2 1/1 Running 55d
kube-controller-manager-k8s-master3 1/1 Running 55d
## 由于kube-controller-manager每个pod的标签都一样,所以我们只需要查看其中一个pod的标签
root@k8s-master1:~# kubectl get pod kube-controller-manager-k8s-master1 -n kube-system --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-controller-manager-k8s-master1 1/1 Running 0 55d component=kube-controller-manager,tier=control-plane查看集群现状后,接下来我们需要创建 Service:通过匹配 kube-controller-manager Pod 的标签并生成 ClusterIP,对外开放组件 metrics 访问;同时给 Service 打上app.kubernetes.io/name: kube-controller-manager标签,保证能被对应 ServiceMonitor 规则匹配采集指标
2.2 修改kube-controller-manager.yaml
在此之前,我们需要先修改一下kube-controller-manager.yamll文件中的IP地址,默认配置的ip为127.0.0.1,Prometheus抓取不到监控指标数据,需要修改为本机IP地址或者0.0.0.0,修改完成以后需要重启一下kubelet
kubeadm安装的k8s集群,控制组件属于静态pod,重启kubelet会重新加载组件的yaml文件,重启pod
yaml
root@k8s-master1:~# vim /etc/kubernetes/manifests/kube-controller-manager.yaml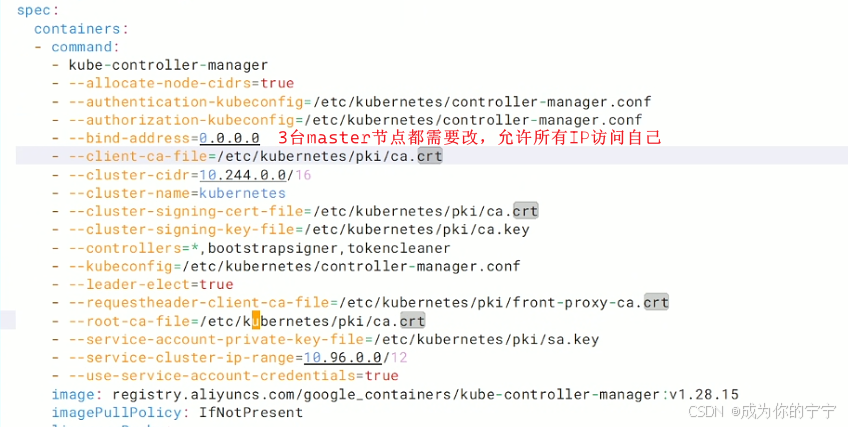
yaml
## 三台master都需要重启
root@k8s-master1:~# systemctl restart kubelet2.3 创建svc
接下来我们创建svc
yaml
## 创建service,Service 是集群级资源,不是节点资源,所以直接找一台master创建一下即可
root@k8s-master1:~# mkdir /k8s/svc
root@k8s-master1:~# cd /k8s/svc/
root@k8s-master1:/k8s/svc# vim kube-controller-manager-service.yaml
---
apiVersion: v1
kind: Service
metadata:
# 这个标签会被servicemonitor匹配到
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
ports:
# servicemonitor中endpoints下会写匹配哪个端口名,里面写的是https-metrics端口名,所以我们这里的端口名不能乱填
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
selector:
# svc会去匹配带有以下两个标签的pod
component: kube-controller-manager
tier: control-plane
type: ClusterIP
root@k8s-master1:/k8s/svc# kubectl apply -f kube-controller-manager-service.yaml
root@k8s-master1:/k8s/svc# kubectl get svc kube-controller-manager -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-controller-manager ClusterIP 10.105.32.118 <none> 10257/TCP 87s浏览器访问Prometheus,可以看到kube-controller-manager实例显示正常
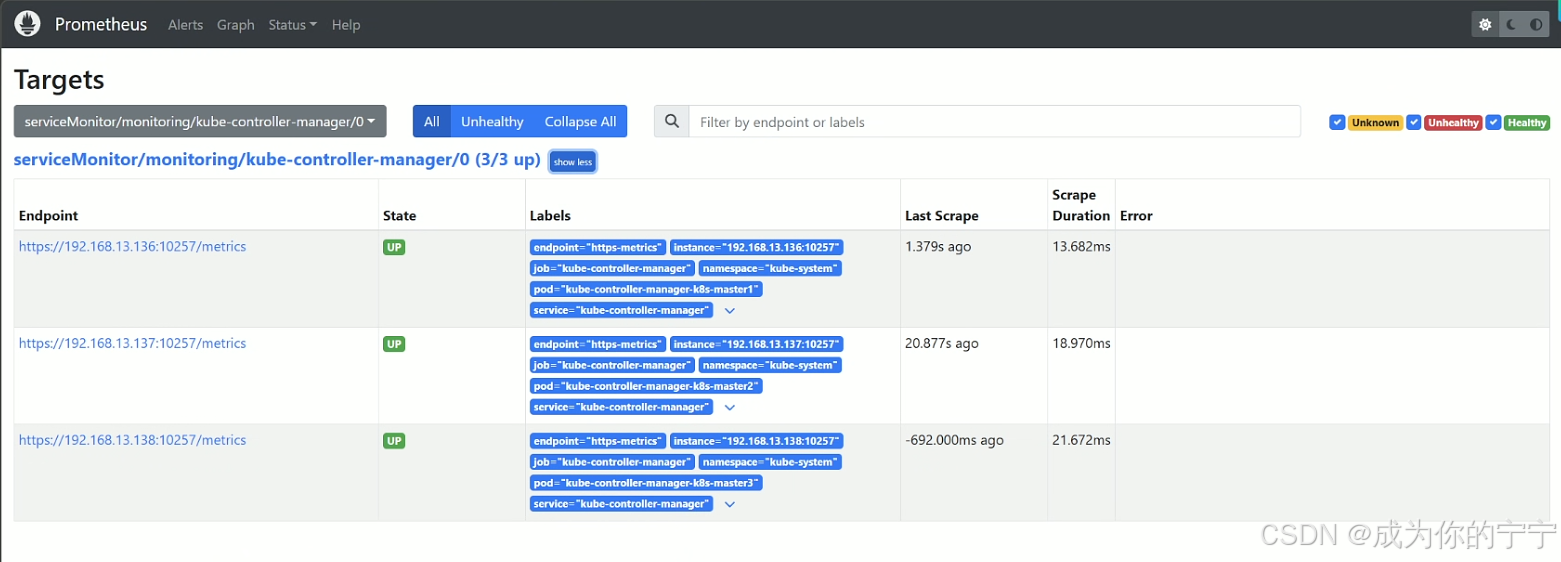
2.4 查看dashboard
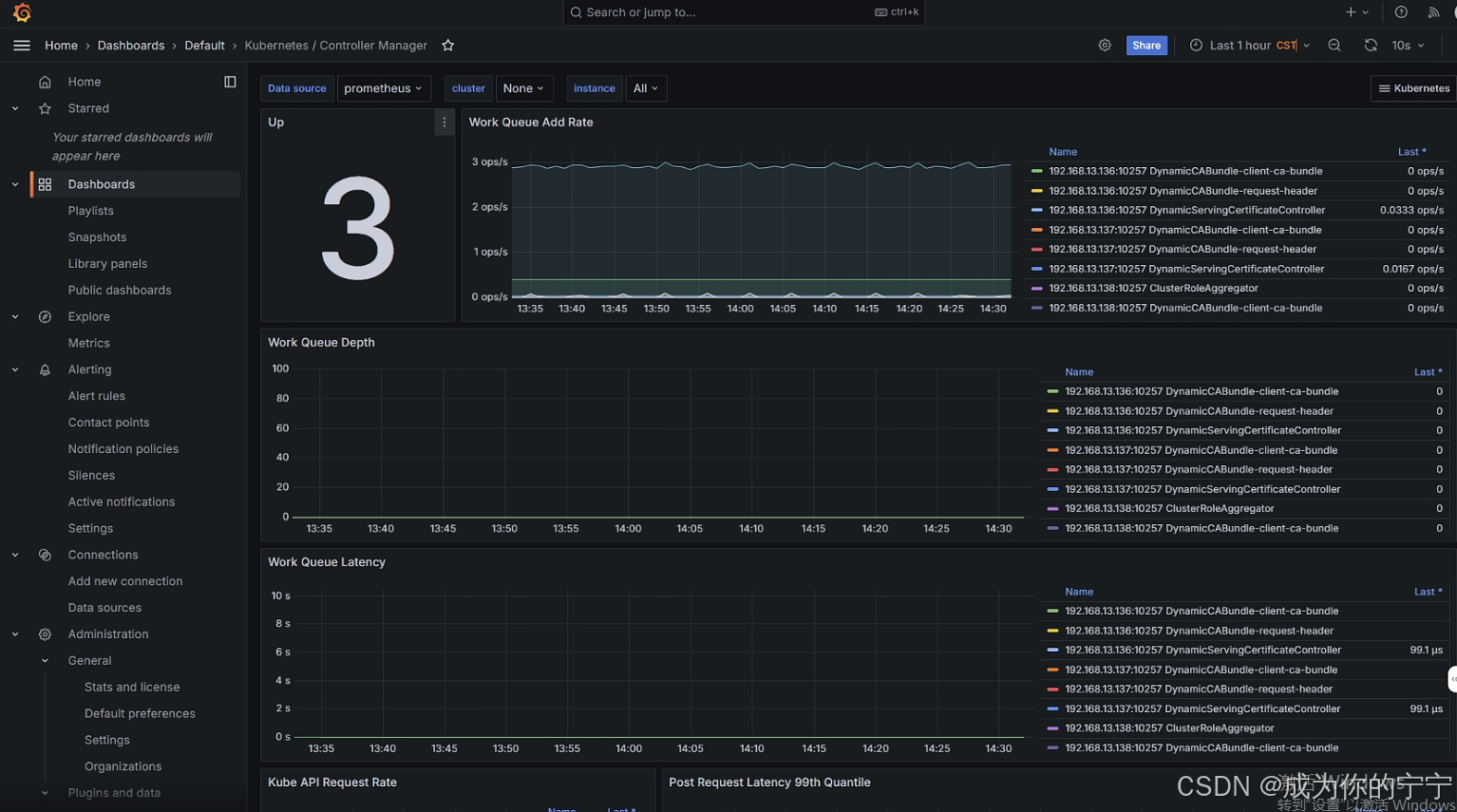
接下来登录grafana,点开名为Controller Manager的控制面板,可以看到有数据产生(在此之前是只有空面板没有数据的)
三、监控kube-scheduler
采用kube-prometheus-stack(Operator)部署监控时,系统会自动生成kube-scheduler的ServiceMonitor采集规则,但不会自动生成配套Service。因kube-scheduler由master节点/etc/kubernetes/manifests托管,属于静态Pod,集群原生无对应Service资源,致使Prometheus无法发现采集目标。因此需手动创建Service,通过标签Selector关联所有kube-scheduler实例
3.1 查看集群情况
yaml
## 查看servicemonitor,发现已经自动创建了kube-sheduler的servicemonitor
root@k8s-master1:~# kubectl get servicemonitor -n monitoring | grep kube-scheduler
kube-scheduler 5d4h
## 查看kube-sheduler的servicemonitor的yaml
root@k8s-master1:~# kubectl get servicemonitor kube-scheduler -n monitoring -o yaml
yaml
# 可以看到系统并没有自动创建kube-scheduler的svc
root@k8s-master1:~# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.101.28.178 <none> 2379/TCP 45h
kube-controller-manager ClusterIP 10.105.32.118 <none> 10257/TCP 22h
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 56d
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 5d23h
## 查看kube-scheduler的pod
root@k8s-master1:~# kubectl get pod -n kube-system | grep kube-scheduler
kube-scheduler-k8s-master1 1/1 Running 9 (5h24m ago) 56d
kube-scheduler-k8s-master2 1/1 Running 10 (5h23m ago) 56d
kube-scheduler-k8s-master3 1/1 Running 1 (5h23m ago) 24h
## 由于kube-scheduler每个pod的标签都一样,所以我们只需要查看其中一个pod的标签
root@k8s-master1:~# kubectl get pod kube-scheduler-k8s-master1 -n kube-system --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-scheduler-k8s-master1 1/1 Running 9 (5h25m ago) 56d component=kube-scheduler,tier=control-plane3.2 修改kube-scheduler.yaml
yaml
root@k8s-master1:~# vim /etc/kubernetes/manifests/kube-scheduler.yaml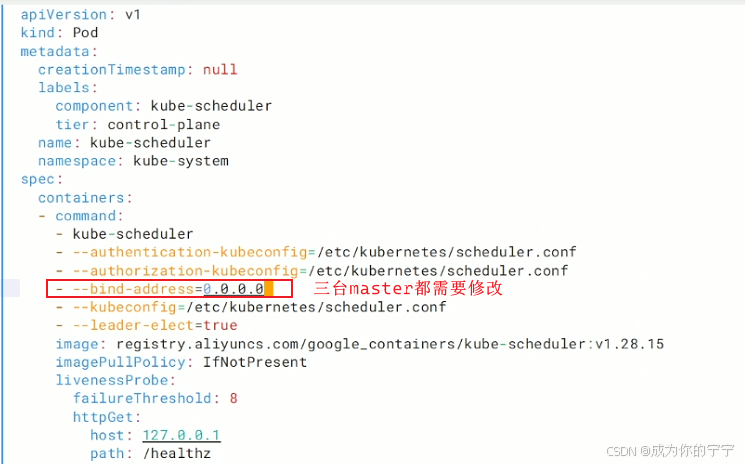
yaml
## 三台master都需要重启
root@k8s-master1:~# systemctl restart kubelet3.3 创建svc
yaml
root@k8s-master1:~# cd /k8s/svc/
root@k8s-master1:/k8s/svc# vim kube-scheduler-service.yaml
---
apiVersion: v1
kind: Service
metadata:
# 这个标签会被servicemonitor匹配到
labels:
app.kubernetes.io/name: kube-scheduler
name: kube-scheduler
namespace: kube-system
spec:
ports:
# servicemonitor中endpoints下会写匹配哪个端口名,里面写的是https-metrics端口名,所以我们这里的端口名不能乱填
- name: https-metrics
port: 10259
protocol: TCP
targetPort: 10259
selector:
# svc会去匹配带有以下两个标签的pod
component: kube-scheduler
tier: control-plane
type: ClusterIP
root@k8s-master1:/k8s/svc# kubectl apply -f kube-scheduler-service.yaml 浏览器访问Prometheus,可以看到kube-scheduler实例显示正常
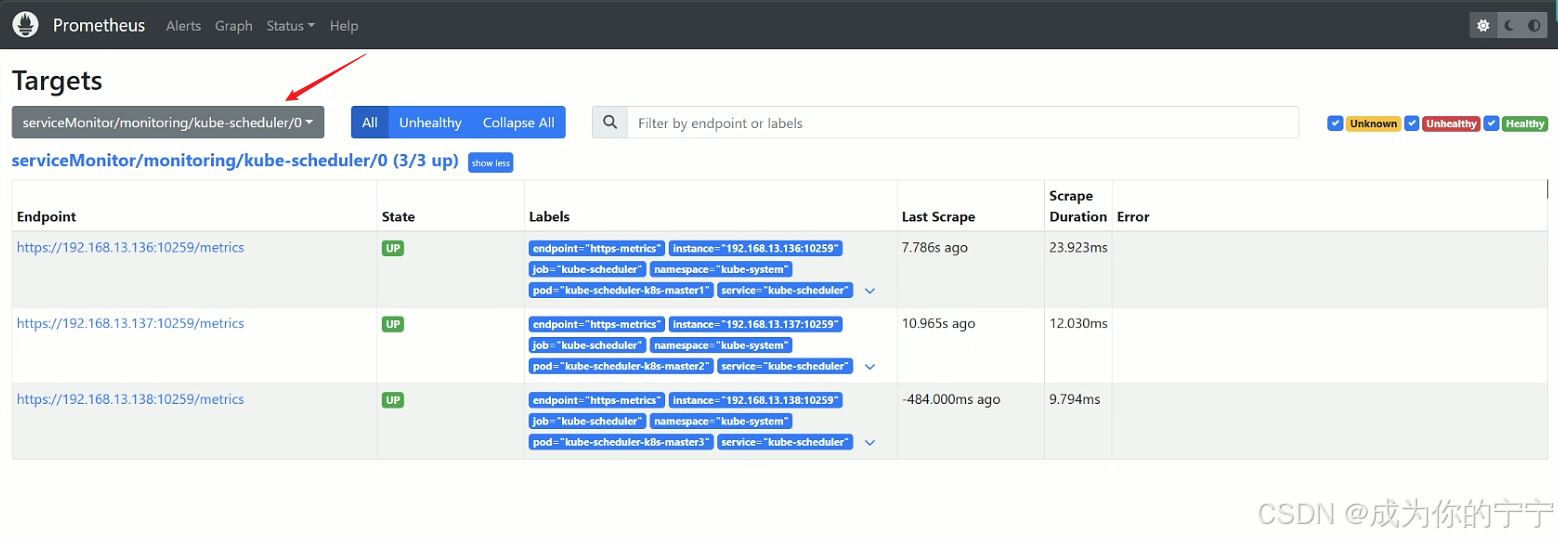
3.4 查看dashboard
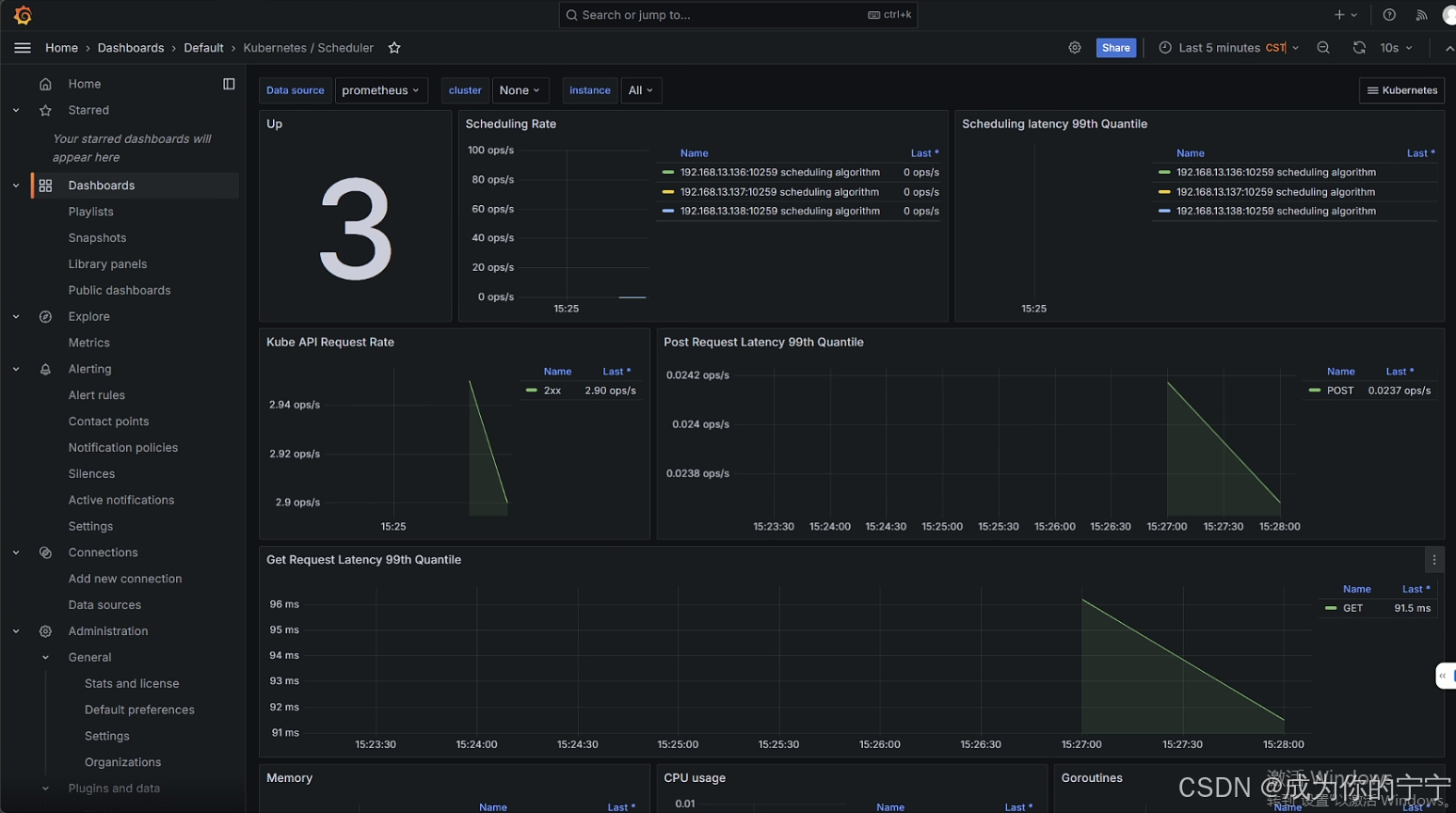
登录grafana,点开对应的dashboard,可以看到有数据产生(在此之前是只有空面板没有数据的)
四、监控kube-proxy
kube-proxy和上面的kube-controller-manager、kube-scheduler不同
kube-proxy 是普通 DaemonSet(由 k8s 控制面管理),它不在 /etc/kubernetes/manifests 里,它是 集群网络组件,不是控制面,依赖 apiserver 才能运行,由 controller-manager 管理
4.1 查看集群情况
yaml
## 查看servicemonitor,发现并没有自动创建kube-proxy的servicemonitor
root@k8s-master1:~# kubectl get servicemonitor -n monitoring | grep kube
kube-apiserver 5d5h
kube-controller-manager 5d5h
kube-scheduler 5d5h
kube-state-metrics 5d5h
kubelet 5d5h
## 查看svc,发现也没有kube-proxy的svc
root@k8s-master1:~# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-prom ClusterIP 10.101.28.178 <none> 2379/TCP 46h
kube-controller-manager ClusterIP 10.105.32.118 <none> 10257/TCP 23h
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 56d
kube-scheduler ClusterIP 10.106.117.24 <none> 10259/TCP 52m
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 6d1h
root@k8s-ma
## 查看kube-proxy的占用端口
root@k8s-master1:~# ss -tunlp | grep kube-proxy
tcp LISTEN 0 4096 127.0.0.1:10249 0.0.0.0:* users:(("kube-proxy",pid=3870,fd=13))
tcp LISTEN 0 4096 *:10256 *:* users:(("kube-proxy",pid=3870,fd=11))
root@k8s-master1:~# curl 192.168.13.136:10249/metrics
curl: (7) Failed to connect to 192.168.13.136 port 10249: Connection refused4.2 修改kube-proxy的configmap
yaml
root@k8s-master1:~# kubectl get configmap -n kube-system
NAME DATA AGE
coredns 1 56d
extension-apiserver-authentication 6 56d
kube-apiserver-legacy-service-account-token-tracking 1 56d
kube-proxy 2 56d
kube-root-ca.crt 1 56d
kubeadm-config 1 56d
kubelet-config 1 56d
root@k8s-master1:~# kubectl edit configmap kube-proxy -n kube-system
# metricsBindAddress字段就是用来指定 kube-proxy 进程自身应该监听哪个地址和端口 来提供指标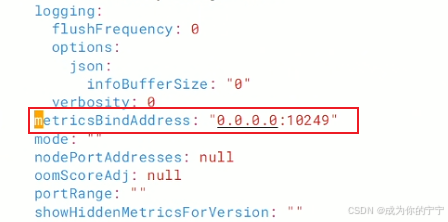
yaml
## 查看kube-proxy的pod
root@k8s-master1:~# kubectl get pod -n kube-system | grep kube-proxy
kube-proxy-9nczw 1/1 Running 1 (6h26m ago) 25h
kube-proxy-k4c82 1/1 Running 7 (6h27m ago) 56d
kube-proxy-qndmg 1/1 Running 7 (6h27m ago) 56d
kube-proxy-t52nw 1/1 Running 8 (6h26m ago) 56d
kube-proxy-wpxwz 1/1 Running 8 (6h27m ago) 56d
## 重启kube-proxy pod
root@k8s-master1:~# kubectl get pod -n kube-system | grep kube-proxy | awk '{print $1}' | xargs kubectl delete pod -n kube-system
root@k8s-master1:~# kubectl get pod -n kube-system -o wide| grep kube-proxy
kube-proxy-48mbj 1/1 Running 0 85s 192.168.13.139 k8s-node1 <none> <none>
kube-proxy-5p5f2 1/1 Running 0 85s 192.168.13.138 k8s-master3 <none> <none>
kube-proxy-8q4jj 1/1 Running 0 85s 192.168.13.137 k8s-master2 <none> <none>
kube-proxy-tpn2c 1/1 Running 0 85s 192.168.13.136 k8s-master1 <none> <none>
kube-proxy-zbwxw 1/1 Running 0 84s 192.168.13.140 k8s-node2 <none> <none>
## 由于每个kube-proxy pod的标签都一致,所以我们查看其中一个即可
root@k8s-master1:~# kubectl get pod kube-proxy-tpn2c -n kube-system --show-labels
NAME READY STATUS RESTARTS AGE LABELS
kube-proxy-tpn2c 1/1 Running 0 3m15s controller-revision-hash=55d6447f46,k8s-app=kube-proxy,pod-template-generation=13.3 创建svc
yaml
root@k8s-master1:~# cd /k8s/svc/
root@k8s-master1:/k8s/svc# vim kube-proxy-service.yaml
---
apiVersion: v1
kind: Service
metadata:
# 这个标签会被servicemonitor匹配到
labels:
k8s-app: kube-proxy
name: kube-proxy
namespace: kube-system
spec:
ports:
# servicemonitor中endpoints下会写匹配哪个端口名,里面写的是https-metrics端口名,所以我们这里的端口名不能乱填
- name: https-metrics
port: 10249
protocol: TCP
targetPort: 10249
selector:
# 由于kube-proxy pod的其它两个标签都是动态变化的,所以这里我们只需要匹配这一个标签即可
k8s-app: kube-proxy
type: ClusterIP
root@k8s-master1:/k8s/svc# kubectl apply -f kube-proxy-service.yaml
root@k8s-master1:/k8s/svc# kubectl get svc -n kube-system | grep kube-proxy
kube-proxy ClusterIP 10.105.44.191 <none> 10249/TCP 4m
## 现在尝试访问会成功
root@k8s-master1:~# curl 192.168.13.136:10249/metrics3.4 创建servicemonitor
yaml
root@k8s-master1:/k8s/svc# cd /root/kube-prometheus/manifests/
root@k8s-master1:~/kube-prometheus/manifests# vim kube-proxy-servicemonitor.yaml
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: kube-proxy
namespace: monitoring
labels:
app: kube-proxy
spec:
jobLabel: kube-proxy
endpoints:
- interval: 30s
port: https-metrics # 这个port对应 Service.spec.ports.name
scheme: http
selector:
matchLabels:
k8s-app: kube-proxy # 跟svc的lables保持一致
namespaceSelector:
matchNames:
- kube-system
root@k8s-master1:~/kube-prometheus/manifests# kubectl apply -f kube-proxy-servicemonitor.yaml浏览器访问Prometheus,可以看到kube-proxy实例添加成功
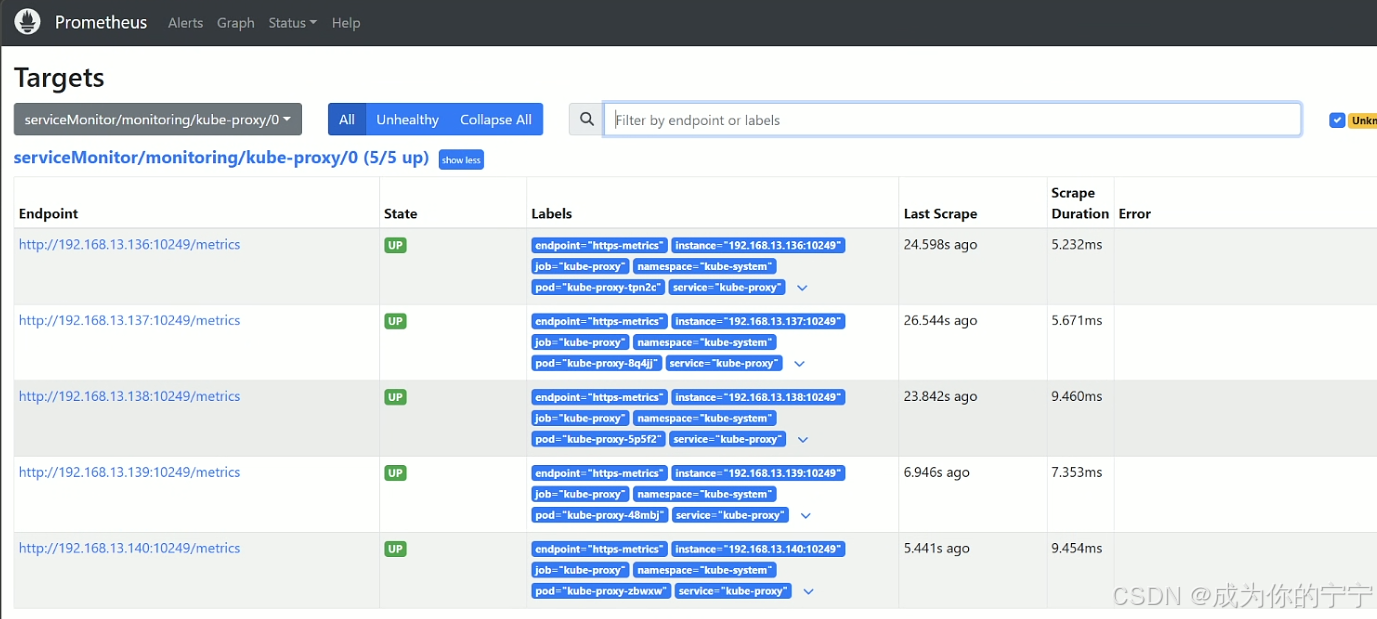
3.5 查看dashboard
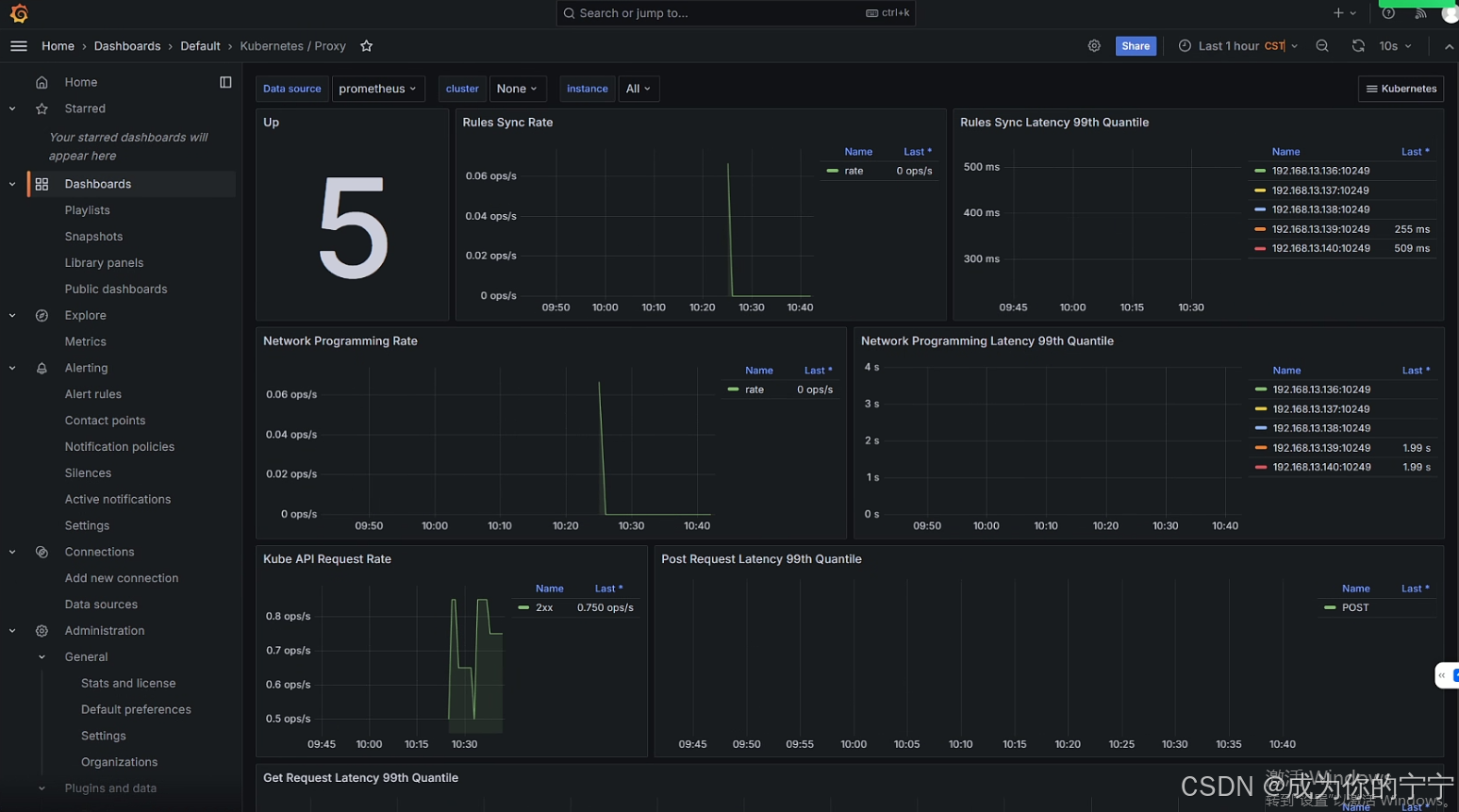
登录grafana,点开对应的dashboard,可以看到有数据产生(在此之前是只有空面板没有数据的)
至此,kube-controller-manager、kube-scheduler、kube-proxy组件就监控完毕了!
注:
文中若有疏漏,欢迎大家指正赐教。
本文为100%原创,转载请务必标注原创作者,尊重劳动成果。
求赞、求关注、求评论!你的支持是我更新的最大动力,评论区等你~