
北京大学数据管理实验室胡健鹏关于LLM输出归因与幻觉检测的论文《Detecting Hallucinations in Retrieval-Augmented Generation via Semantic-level Internal Reasoning Graph》被 ACL 2026 Findings接收。
引言
大语言模型(LLM)在自然语言处理领域取得了显著进展,能够生成语法流畅、逻辑连贯的文本。然而,LLM也普遍存在一个关键缺陷:幻觉------即生成语法正确但事实上错误的内容。这种现象在医疗、金融、法律等对准确性要求极高的应用场景中尤为致命。
为了缓解幻觉问题,研究者提出了两种主流方案:一是通过下游任务微调,二是引入检索增强生成(RAG)系统。RAG系统通过从外部知识库中检索相关文档作为上下文,有效减少了事实性幻觉 ------即模型输出与真实世界事实不一致的情况。然而,RAG系统并未完全解决另一类幻觉:忠实性幻觉。
什么是忠实性幻觉?
忠实性幻觉指的是模型生成的内容与用户提供的上下文不一致。例如,当用户提供三篇关于"如何加热冷冻司康饼"的英文技术文档,并询问具体步骤时,模型可能在正确引用第一篇文档中的"预热烤箱"细节后,错误地将第二篇文档中关于"面粉蛋白质含量"的内容嫁接过来,或者编造出一个源自自身参数而非上下文的步骤(如"放入微波炉加热30秒")。这些生成内容在语法上完全正确,但与给定的上下文相矛盾。
现有检测方法的局限
He等人(2022)的研究发现,忠实性幻觉的主要根源在于:LLM的词元级输出与其真实思维过程之间的不一致。换句话说,LLM在推理时仅利用了表层知识(如实体流行度),而没有真正理解并遵循用户提供的上下文。为了检测忠实性幻觉,学术界提出了多种方法,但各自存在明显缺陷:
-
基于LLM的后处理方法。 Manakul等人(2023)和Zhao等人(2025)提出通过多次调用LLM进行自我校验或一致性检测。这类方法虽然直观有效,但多次调用LLM系统会导致显著的资源消耗,同时可能放大模型自身的偏见。
-
基于模型内部嵌入的方法。 Chen等人(2025)、Wu等人(2024)和Burns等人(2022)通过分析模型的隐藏状态、注意力模块输出来判别幻觉。这类方法通常依赖在这些抽象特征上训练的启发式判别器,可解释性较差------我们无法理解模型为何做出某个判断。
-
基于输出归因的方法。 Hu等人(2024)和Chuang等人(2024)从归因角度检测幻觉,通过计算每个词元对最终输出的贡献分数来识别异常。然而,这些方法直接聚合LLM回答中所有词元的归因向量,会引入大量噪声,使得判别器难以学习到有效的判别模式。
为了更好地解释忠实性幻觉的起源,受Phukan等人(2024)启发,我们将LLM自回归推理过程中生成的词元分为两类:
-
连接性词元:用于连接上下文、使句子语法正确的非实质性文本,如"the"、"which"、"a"等虚词。
-
实质性词元:利用用户提供的上下文信息、反映回答语义内容的文本,如名词、动词、命名实体等。
我们认为,幻觉的根源在于LLM错误地将实质性词元当作连接性词元来处理。这导致模型在生成这些词元时,过度依赖自身已生成的内容(如同句内前文),而忽视用户提供的长距离上下文。这种差异从人类视角难以察觉,因为存在"语义漂移"------生成内容在表面上依然连贯,但语义根基已悄然从上下文转移到了模型自身的参数记忆中。
通过归因分数分布的可视化分析(详见论文附录B),我们可以清晰地观察到:连接性词元的归因主要集中在本句内已生成的词元上,而实质性词元则均匀地依赖长距离的上下文信息。当LLM生成幻觉内容时,其归因分布呈现出典型的连接性词元特征。
解决方案概述:语义级内部推理图
由于忠实性幻觉通常发生在语义层面 (而非词元层面),我们将上述概念扩展到语义层级,并提出通过语义级内部推理图来检测忠实性幻觉。具体而言:
-
语义级归因计算:首先采用分层相关传播(LRP)算法计算自回归过程中每个词元的归因向量。该归因方法利用模型内部参数和预定义规则,忠实地反映模型内部的计算过程。
-
语义片段提取与过滤:使用NLP工具将上下文和模型回答切分为语义片段,并通过命名实体识别提取每个片段中的核心语义内容(名词、动词、否定词、命名实体等),过滤掉连接性内容。
-
推理图构建:基于词元级归因向量,建模上下文语义片段与模型回答语义片段之间的归因关系,形成内部推理图。
从下图的示例中可以观察到:产生幻觉的语义片段将更高的归因分数分配给了模型已生成的前序语义片段,而对用户提供的上下文依赖较弱。这表明LLM在推理过程中错误地将实质性片段当作连接性片段处理,导致了幻觉现象。
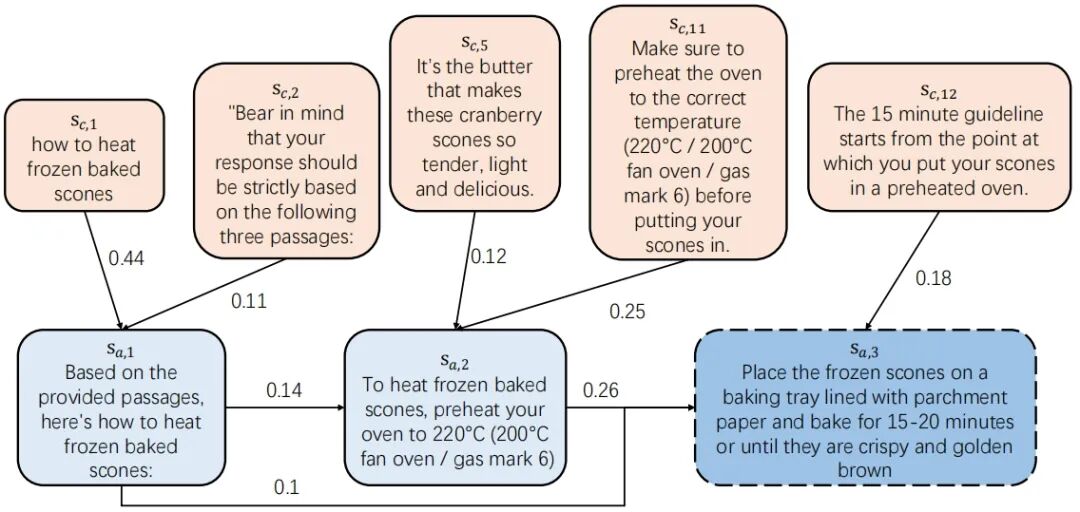
基于上述观察,我们将推理图中每个回答节点及其归因依赖线性化,拼接成提示词,输入到下游预训练语言模型(PLM)中进行二分类任务的微调。在幻觉检测阶段,我们根据LLM生成文本中所有语义片段的二分类标签分布来判断是否存在幻觉。整个检测过程仅依赖一个参数规模极小的模型(124M参数的RoBERTa),无需多次调用LLM。
本文贡献
本文的主要贡献包括:
-
提出语义级内部推理图构建方法。将词元级的LRP算法扩展到语义层级,基于归因向量构建LLM的语义级内部推理图,提供更忠实的语义级依赖关系表示。
-
揭示忠实性幻觉的归因分布差异。从连接性片段与实质性片段的分布差异角度分析忠实性幻觉,并利用内部推理图进行检测。
-
验证框架有效性。在两个通用数据集(RAGTruth和Dolly-15k)上的实验结果表明,我们的框架性能超越了包括基于LLM微调、SelfCheckGPT、LRP4RAG等在内的多个最先进基线方法,同时仅使用轻量级参数模型。
框架详解
本文提出了一种基于语义级内部推理图(Semantic-level Internal Reasoning Graph, SIRG)的忠实性幻觉检测方法。该方法的核心思想是:将词元级的归因分析扩展到语义层级,通过构建能够忠实反映LLM内部推理过程的语义图结构,训练一个轻量级判别器来识别幻觉。整个方法框架如下图所示,包含三个核心阶段:贡献分数计算、内部推理图构建和幻觉判别。
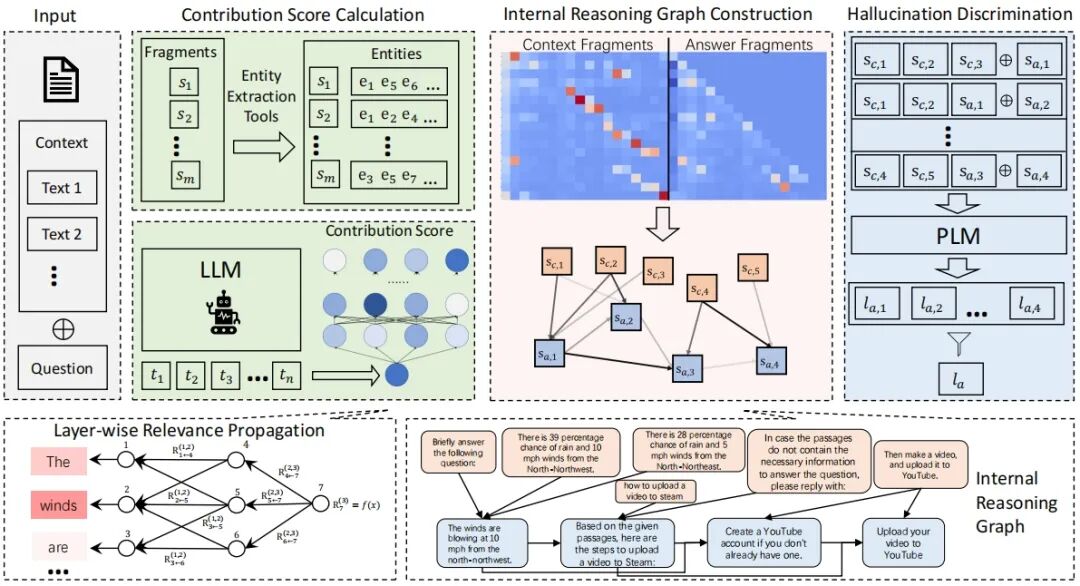
任务形式化
首先,我们对RAG系统中的幻觉检测问题进行形式化定义。
设数据集 包含 个样本,每个样本由用户查询 及其对应的回答 组成。每个回答基于从知识库 中检索到的上下文生成。给定查询 ,检索模型 φ 首先从 中检索最相关的文本块形成提示词,然后生成模型 θ 基于该提示词生成回答 。整个过程可形式化为:
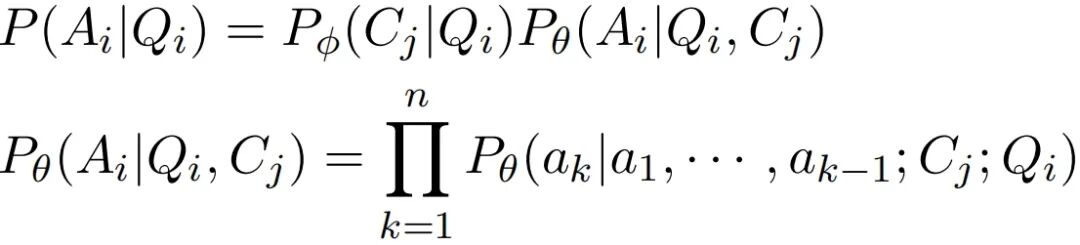
其中 为回答的总词元数。
本文的目标是训练一个判别器 γ 来判断 是否包含幻觉:
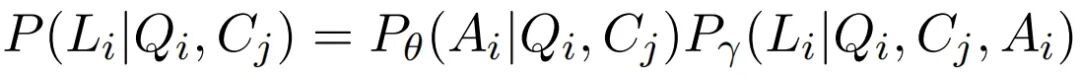
其中标签 指示该样本是否存在幻觉。
贡献分数计算:语义级归因的基础
本文采用分层相关传播(Layer-wise Relevance Propagation, LRP)算法计算每个词元对生成结果的贡献分数。LRP的基本假设是:一个具有 个输入特征 的函数 可以分解为单个输入变量的独立贡献 之和,表示输出 中可归因于输入 的部分。这些贡献求和后与原函数值成正比:
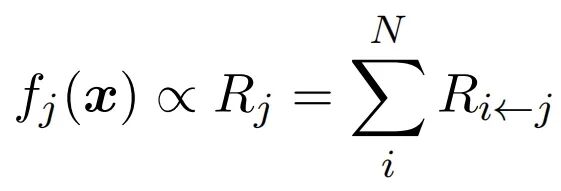
LRP的分解性质带来了重要的守恒性质:每一层所有贡献分数的总和保持不变。这一特性使得归因具有意义和忠实性------每个贡献分数的尺度都可以与原函数输出相关联。
在生成阶段,当生成每个词元 时,生成器同时基于内部梯度和预定义的LRP规则输出一个相关向量 ,用于量化 与每个上下文词元 之间的相关性。通过聚合所有词元的相关分数,我们得到相关矩阵 。
内部推理图构建:从词元到语义的升维
- 语义片段划分
由于忠实性幻觉通常发生在语义层面,我们需要将计算得到的词元级归因提升到语义层级。首先进行语义片段划分:
-
上下文语义片段:使用SpaCy的句子拆分工具和换行符将输入上下文分割为独立的语义片段,得到集合 ,其中每个 表示上下文中的第i个语义片段。
-
回答语义片段:同样对模型输出进行分割,得到集合 。
所有语义片段的并集 构成了模型内部推理图的节点集,即模型推理的原子步骤集合。
- 实质性内容提取
文本中的语义片段既包含用于连接上下文、使语法正确的连接性内容,也包含反映实际语义的实质性内容。在基于LRP计算片段级归因时,连接性片段的归因分数会引入大量噪声。
为解决这一问题,本文使用通用命名实体提取工具(SpaCy和Stanze)从文档中最大程度地提取实体,包括:名词、动词、名词短语、否定词和命名实体。这些内容能够最大化反映文本表达的语义,同时过滤掉连接性内容。去重后的提取结果构成表达语义信息的核心内容集合。
通过将集合 映射到每个语义片段集合 ,我们可以获得每个语义片段中包含的实际意义子集 。
- 语义级归因聚合
在得到语义片段及其核心内容后,我们进行语义级的归因聚合:
第一步:目标片段归因向量计算。对于每个目标语义片段 ,我们仅选择 中包含的词元来计算其相对于前文的归因向量,然后逐元素平均所有选中的相关向量,得到该语义片段相对于前文的词元级归因向量。
第二步:源片段归因分数计算。对于前文中的被归因语义片段 ,我们在 的归因向量中选择 中包含词元的最大值,作为 对 的归因分数。
使用最大函数而非平均函数的原因在于:在归因时, 往往只附属于前文中少数具有实际意义的词元。使用平均函数会因片段长度而稀释 中的高相关信息,而最大函数能够有效保留这些关键信号。
第三步:语义级相关矩阵构建。最终得到语义级相关矩阵 ,其中每个元素 表示第j个语义片段对第 个语义片段的影响程度。由于后续语义片段对前序语义片段不具有归因影响,该矩阵在相应区域为零。
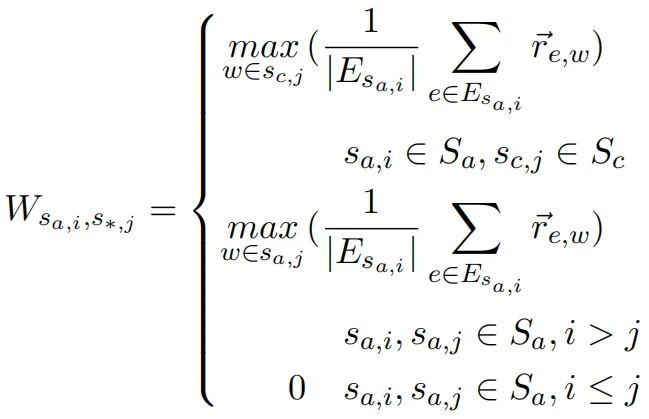
- 图构建策略
基于语义级相关矩阵,本文提出两种内部推理图构建策略:
Top-k策略:将目标语义片段的归因分数从高到低排序,选择前 个片段作为源,在图中插入从源到目标语义片段的边。节点 的入边集合可表示为:
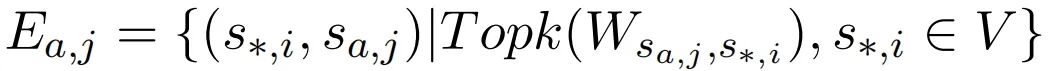
自适应策略:归因分数的分布通常呈现长尾特征。为自适应地选择边,本文将归因分数降序排列并计算序列的离散梯度,以最大离散梯度点区分重要和不重要的源语义片段。假设 是 中元素的非递增排序,每个 通过函数 与 一一对应,则节点 的入边集合为:
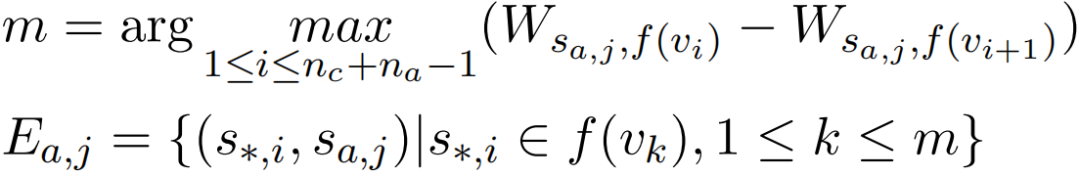
所有节点的入边集合的并集构成整个图的边集。最终得到的内部推理图 是一个有向图,忠实反映了模型内部推理过程中语义片段之间的依赖关系。
幻觉判别:从图结构到二分类
在幻觉语义片段的归因节点中,分配给模型已生成的前序语义片段的比例更高;而非幻觉语义片段的归因节点则倾向于与用户提供的上下文语料相关,表明它们更忠实于人类提供的上下文。因此,幻觉发生的一个重要原因是模型将待生成的下一个语义片段当作连接性内容而非实质性内容。
为使模型能够发现这些上下文依赖中的归因分布差异和语义差异,本文将推理图线性化为多个语义组合。具体地,对于模型回答的每个语义片段 ,将其所有入边拼接成提示词,输入到预训练语言模型(PLM)中获得标签 :
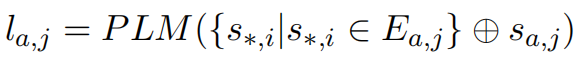
本文采用ALIGNSCORE(Zha et al., 2023)作为PLM,其基于RoBERTa架构,在大规模数据上进行了预训练,专注于衡量任意两个片段之间的信息对齐程度。通过使用下游交叉熵损失函数进行简单微调,即可展现出强大的幻觉检测能力。
最终,本文采用灵活阈值 α 来判断整个模型回答是否存在幻觉。如果模型回答中包含幻觉的语义片段比例超过 α,则认为该回答存在幻觉:
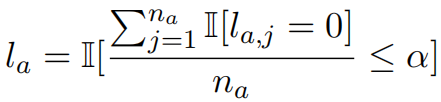
当 α 时,模型回答中任何语义片段被怀疑为幻觉都会导致整个回答被判定为幻觉,这是最严格的检测策略。在实际应用中,α 的取值可根据具体场景所需的模型可靠性要求进行动态调整。
实验设置
数据集
RAGTruth(Niu et al., 2024):这是一个由多种LLM生成的人工标注RAG样本集。本文使用了其中的两个子集:
-
LLaMA-7B部分:包含510个幻觉样本和479个正常样本
-
LLaMA-13B部分:包含399个幻觉样本和590个正常样本
Dolly-15k(Conover et al., 2023:这是一个覆盖多个场景的大模型问答数据集。本文仅使用面向RAG框架的闭卷问答场景,并过滤掉上下文为空的样本。
对比基线
本文将SIRG与以下基线方法进行对比:
-
Prompt(Niu et al., 2024):通过提示工程,人工设计LLM(LLaMA-7b和GPT-3.5-turbo)提示词来识别幻觉。
-
SelfCheckGPT(Manakul et al., 2023):评估采样响应之间的一致性,计算幻觉概率。
-
Fine-tune(Niu et al., 2024):在相应数据集上微调LLaMA-7b和Qwen-7b来检测幻觉。
-
EigenScore(Chen et al., 2024):利用响应协方差矩阵的特征值来衡量嵌入空间中的语义一致性。
-
SEP(Kossen et al., 2024):利用在LLM隐藏状态上训练的线性探针来检测幻觉。
-
LRP4RAG(Hu et al., 2024):基于LRP的方法,将贡献分数直接输入SVM分类器或LLM进行幻觉检测。
评估指标
本文采用三个评估指标来比较各方法:精确率(Precision)、召回率(Recall) 和 F1分数(F1-score)。
实验结果
主要实验结果
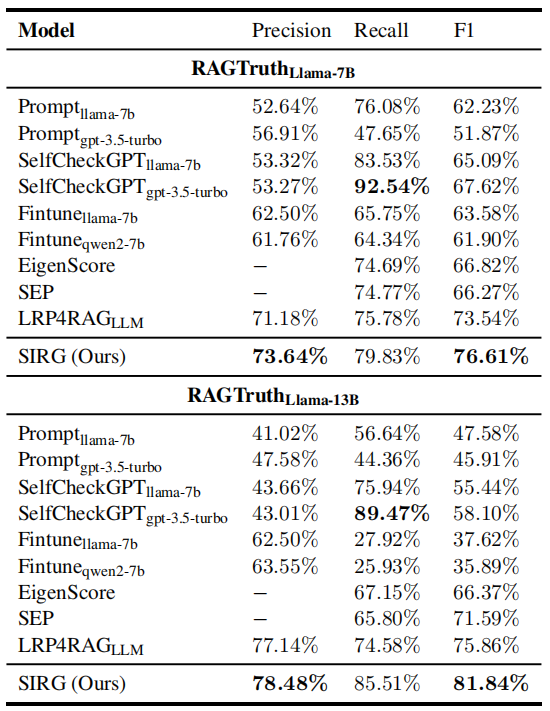
下表展示了在RAGTruth数据集上的对比结果。SIRG在所有指标上都表现出强劲的性能,甚至超越了高资源消耗的方法(如LLM微调)。
-
SIRG的领先优势:在RAGTruth-Llama-7B和RAGTruth-Llama-13B上,SIRG均以最高的F1分数排名第一,分别超越当前最先进方法3.07% 和5.78%。
-
基于Prompt和自验证方法的局限性:SelfCheckGPT等方法依赖于设计提示词使LLM进行单轮或多轮自校正,稳定性较差。切换LLM或提示词会显著影响下游任务性能。例如,使用相同的gpt-3.5-turbo但不同提示词导致召回率相差44.89%。虽然gpt-3.5-turbo在SelfCheckGPT框架下达到92.54%的召回率,但其精确率降至53.27%,表明LLM盲目地将大多数样本分类为正确。这证明仅依赖预训练知识不足以进行准确的幻觉检测。
-
微调方法的不足:Fine-tune方法使用特定的RAGTruth数据样本训练LLM,但平均性能仅为62.74%和36.75%。本文将其归因于训练数据规模不足,微调可能无意中破坏了通过预训练获得的通用知识,导致结果甚至不如直接基于Prompt的方法。
-
向量空间方法的局限:EigenScore和SEP都是基于向量空间判别器的方法,缺乏直接的上下文语义信息,难以充分识别幻觉。
-
与LRP4RAG的对比:LRP4RAG在词元级聚合LRP算法生成的归因向量,以获取模型响应的上下文相关性,是一种粗粒度方法。这种方法引入了过多的连接性文本噪声,导致在分类器训练或使用LLM进行判别任务时性能次优。本文方法同样采用LRP算法,但通过过滤语义噪声并形式化为推理图来增强响应文本中实质性信息的处理,使得下游判别器更容易训练,同时帮助人类理解LLM的决策过程。
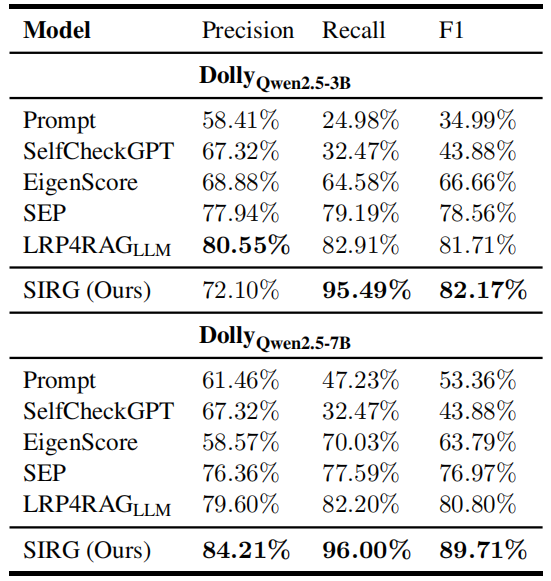
下表展示了在Dolly-15k数据集上的对比结果。对于基于阈值的方法,本文提供了其最优阈值参数。
基于LRP的内部推理图忠实性验证
为了验证SIRG构建的内部推理图的忠实性,本文采用了扰动测试方法。
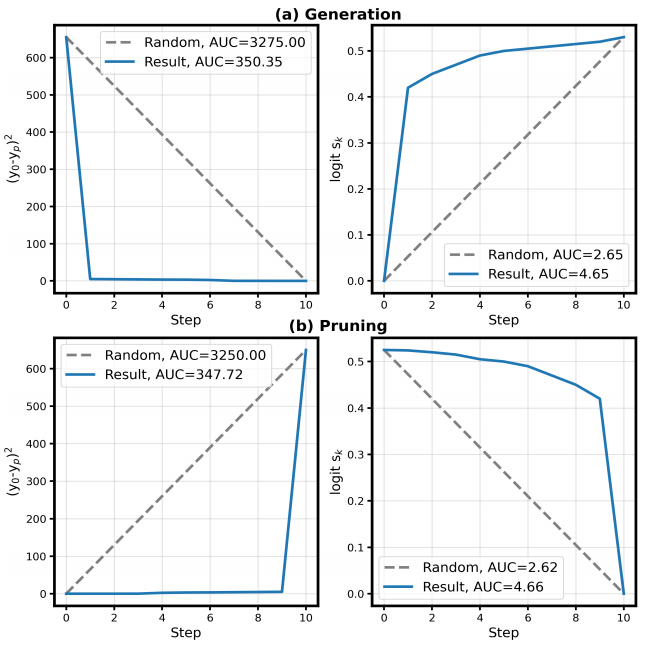
上图为RAGTruth数据集上LLaMA-7B的扰动测试。₀ₚ² 表示扰动前后最终嵌入的变化, 表示目标语义片段的平均概率。虚线表示随机添加或剪枝后的曲线状态。扰动测试在100个样本上进行并取均值。
本文实施了两种扰动测试:
-
生成测试:按相关性从高到低逐步添加语义片段。当添加被LRP判定为最相关的语义片段时,观察到 ₀ₚ² 下降最显著, 上升最明显,表明该语义片段在LLM的计算过程中起关键作用。
-
剪枝测试:按相关性从低到高逐步剪枝语义片段。与目标相关性较低的语义片段被剪枝后对 ₀ₚ² 和 几乎没有影响,而高相关性的片段被剪枝后产生显著影响。
与随机添加或剪枝的标准曲线相比,本文方法在AUC(曲线下面积)指标上表现出显著优势。这证明本文算法能够有效识别对目标语义片段有重大影响的源语义片段。
超参数影响分析
本文重点研究了公式中阈值 α 对分类器性能的影响。
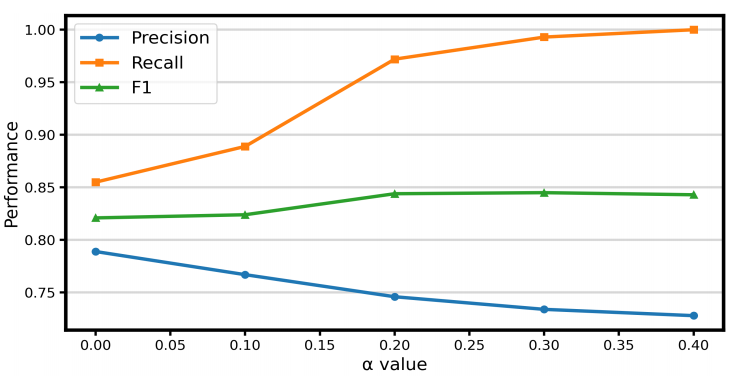
上图为RAGTruth上LLaMA-13B在不同 α 值下的总体精确率、召回率和F1分数
-
α(最严格):只要存在一个幻觉语义片段,该响应就被判定为幻觉样本。此时SIRG对正确样本的召回率相对较低,但识别幻觉的精确率很高。
-
α 增大(更宽松):随着α值增大,检测策略变得越来越宽松,正确样本的通过率上升。当 α 时,正确样本的召回率达到100%,但精确率降至72.86%。
虽然调整 α 对召回率和精确率影响很大,但对F1分数的影响相对较弱,体现了方法的鲁棒性。在实际场景中,可以根据所需的正确样本通过率动态调整α。
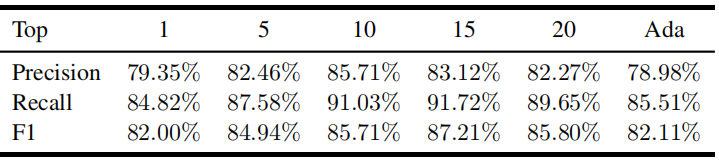
对于内部推理图的构建,本文通过设置不同的Top-k值来调节源语义片段的数量。下表反映了RAGTruth上LLaMA-13B在不同Top-k下的总体精确率、召回率和F1分数(Ada表示公式6中基于梯度的自适应构建策略)。
-
k=15时最优:随着源语义片段数量的增加,判别器可以获得更多语义信息,F1分数在训练初期逐步提升,在k=15时达到峰值(87.21%)。
-
k过大引入噪声:进一步增加k会为目标语义片段引入边贡献噪声,即许多低贡献的语义片段被错误地输入判别器进行训练。判别器可能误将不重要的语义片段与目标片段之间的冲突解释为幻觉,导致k=20时的性能不如k=15。
-
自适应策略的局限:基于梯度的自适应离散梯度策略往往只选择1或2个源语义片段,缺乏足够的信息,判别器性能受限。
总结
本文首先将标记级LRP算法扩展至自回归推理范式中的语义层面。随后,我们利用关系论证(RAG)上下文中的语义片段与大语言模型(LLM)的响应构建内部推理图,从而真实还原内部推理过程的依赖关系。基于此,我们提出了一种名为 SIRG 的框架,用于识别RAG中的忠实性幻觉现象。 SIRG 仅采用轻量级参数化判别器即可达到基于LLM检测框架的性能水平,充分验证了本方法的有效性。