p12 3.3 学习状态值函数
UP主 : 吴恩达-深度学习
时长 : 16:50
笔记时间: 2026-06-05 11:52:16
【2025版】吴恩达强化学习教程 - 3.3 学习状态值函数
LIST 课程概览
本节课主要讲解如何使用深度神经网络来学习状态-动作值函数 Q(s,a)Q(s,a)Q(s,a),重点介绍了在连续状态空间中通过贝尔曼方程构建训练样本,并将强化学习问题转化为监督学习任务。课程以月球着陆器为例,展示了如何将状态和动作编码为输入向量,并利用神经网络逼近 Q(s,a)Q(s,a)Q(s,a)。
TOC 目录大纲
- 引入:连续状态空间与状态值函数学习
- 神经网络结构设计:输入与输出
- 状态与动作的编码方式
- 贝尔曼方程的推导与应用
- 从强化学习到监督学习的转化
- 训练数据的生成机制
NOTE 详细笔记
1. 引入:连续状态空间与状态值函数学习

- 本节主题是"Continuous State Spaces "下的"Learning the state-value function"。
- 在连续状态空间中,无法用查表法存储所有状态的值,因此需要使用函数逼近方法(如神经网络)来估计状态值或动作值函数。
- 核心目标是学习一个函数 Q(s,a)Q(s,a)Q(s,a),表示在状态 sss 下采取动作 aaa 的期望回报。
📌 注:此处未出现字幕,但截图明确显示课程主题为"Learning the state-value function",结合上下文可确认这是本节核心目标。
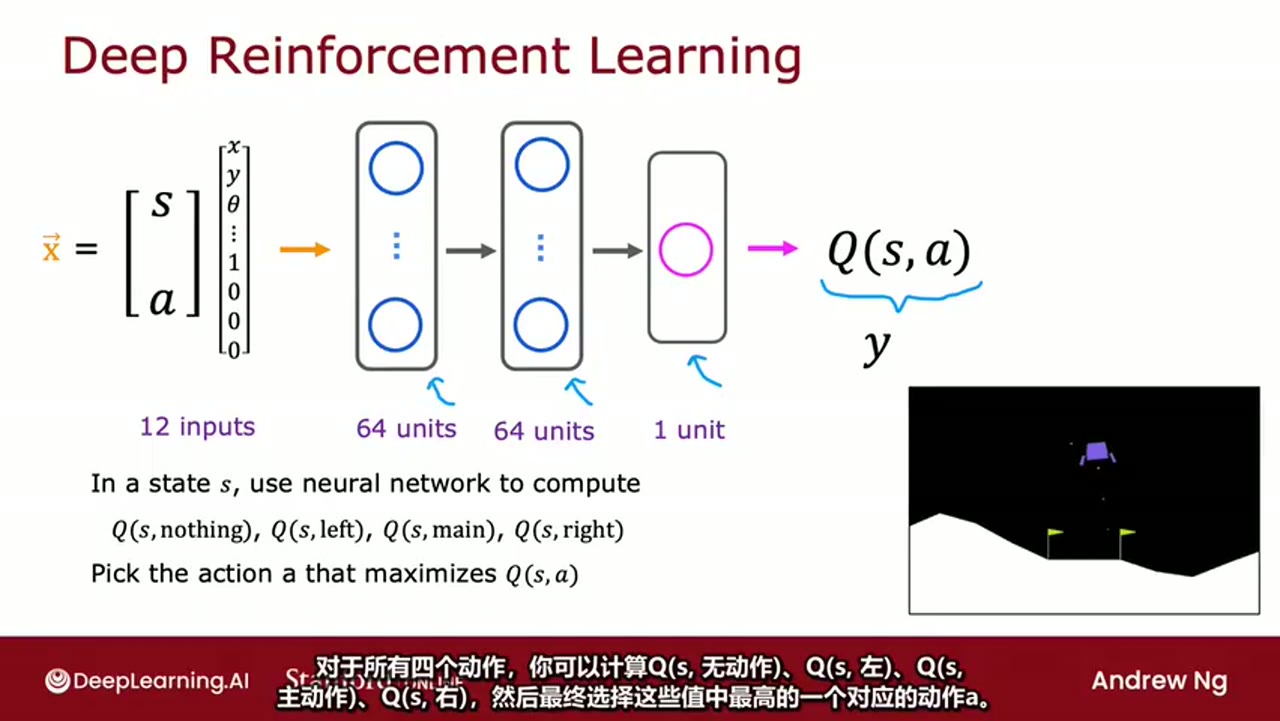
2. 神经网络结构设计:输入与输出

-
使用一个前馈神经网络来近似 Q(s,a)Q(s,a)Q(s,a):
- 输入层:12个输入单元
- 第一隐藏层:64个单元
- 第二隐藏层:64个单元
- 输出层:1个单元,输出 Q(s,a)Q(s,a)Q(s,a)
-
网络结构图示如下:
[输入] → [64 units] → [64 units] → [1 unit]
↑ ↑ ↑
12 inputs hidden layer output -
每次输入一个状态 sss 和一个动作 aaa,网络输出对应的 Q(s,a)Q(s,a)Q(s,a) 值。
-
动作选择策略:对所有可能动作计算 Q(s,a)Q(s,a)Q(s,a),选择最大值对应的动作。
✅ 示例动作包括:
nothing,left,main,right(共四个离散动作)
3. 状态与动作的编码方式

- 状态 sss :由8个数字构成的列表,包含以下信息:
- x,yx, yx,y: 当前位置坐标
- x˙,y˙\dot{x}, \dot{y}x˙,y˙: x 和 y 方向的速度
- θ\thetaθ: 航天器角度
- θ˙\dot{\theta}θ˙: 角速度
- LR: 左右腿着地位置(可能用于判断是否安全着陆)
- 动作 aaa :使用 one-hot 编码表示:
- 若动作是第一个动作(如"无动作"),则编码为
[1, 0, 0, 0] - 若是第二个动作(如"左"),则编码为
[0, 1, 0, 0]
- 若动作是第一个动作(如"无动作"),则编码为
- 合并后的输入向量 x⃗=s;a\vec{x} = s; ax =s;a 共有 12 维(8维状态 + 4维动作编码)。
📝 截图中显示:
[S] [a]表示输入是状态和动作的拼接。
4. 贝尔曼方程的推导与应用

-
贝尔曼方程(Bellman Equation)是强化学习的核心公式之一:
Q(s,a)=R(s)+γmaxa′Q(s′,a′) Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a') Q(s,a)=R(s)+γa′maxQ(s′,a′)
- Q(s,a)Q(s,a)Q(s,a): 当前状态动作对的值函数
- R(s)R(s)R(s): 执行动作后获得的即时奖励
- γ\gammaγ: 折扣因子(通常 0<γ<10 < \gamma < 10<γ<1)
- s′s's′: 下一状态
- a′a'a′: 下一时刻可能的动作
🔍 解释:
- 左边 Q(s,a)Q(s,a)Q(s,a) 是我们要学习的目标函数
- 右边分为两部分:
- 即时奖励 R(s)R(s)R(s)
- 加上未来最大可能回报的折扣值
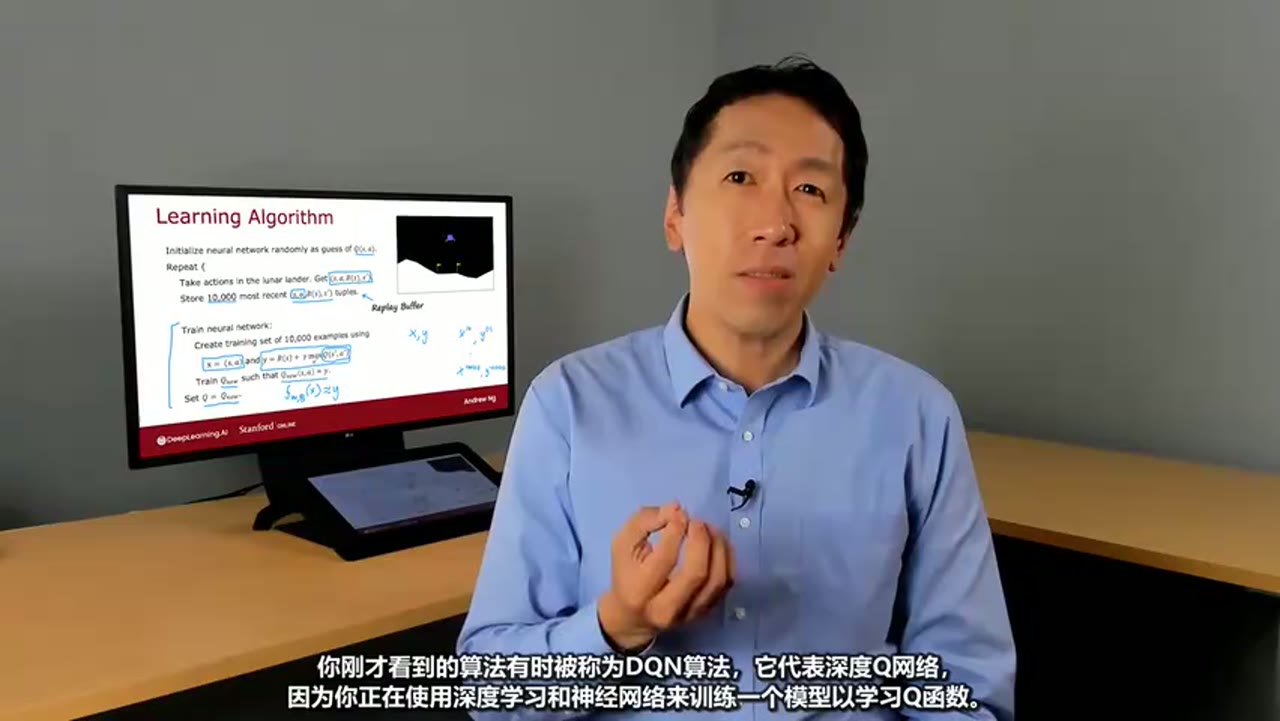
5. 从强化学习到监督学习的转化

- 将强化学习问题转化为监督学习 问题:
- 定义输入 x=(s,a)x = (s, a)x=(s,a)
- 定义标签 y=R(s)+γmaxa′Q(s′,a′)y = R(s) + \gamma \max_{a'} Q(s', a')y=R(s)+γmaxa′Q(s′,a′)
- 训练神经网络 fw,b(x)f_{w,b}(x)fw,b(x) 来拟合 yyy
数学表达式:
fw,b(x)≈y f_{w,b}(x) \approx y fw,b(x)≈y
- 这样就可以使用标准的监督学习方法(如梯度下降)来训练神经网络。
✅ 关键思想:虽然没有真实标签,但我们可以通过贝尔曼方程构造"伪标签" yyy。
6. 训练数据的生成机制
-
每次在环境中执行一次操作,可以获得一组观测数据:
(s(i),a(i),R(s(i)),s′(i)) (s^{(i)}, a^{(i)}, R(s^{(i)}), s'^{(i)}) (s(i),a(i),R(s(i)),s′(i))
-
利用这些数据可以构造训练样本 (x,y)(x, y)(x,y):
- x=s(i);a(i)x = s\^{(i)}; a\^{(i)}x=s(i);a(i)
- y=R(s(i))+γmaxa′Q(s′(i),a′)y = R(s^{(i)}) + \gamma \max_{a'} Q(s'^{(i)}, a')y=R(s(i))+γmaxa′Q(s′(i),a′)
💡 说明:
- 多次交互会生成多个这样的样本
- 每个样本都可用于训练神经网络
- 最终目标是让网络输出 Q(s,a)Q(s,a)Q(s,a) 接近贝尔曼方程右侧的值
TIP 重点总结
| 编号 | 知识点 | 一句话解释 |
|---|---|---|
| 1 | 状态-动作值函数 Q(s,a)Q(s,a)Q(s,a) | 表示在状态 sss 下执行动作 aaa 的长期期望回报 |
| 2 | 神经网络输入结构 | 将状态 sss 和动作 aaa 拼接成12维向量作为输入 |
| 3 | one-hot 编码动作 | 用4维向量表示4个离散动作,实现动作的数值化 |
| 4 | 贝尔曼方程 | Q(s,a)=R(s)+γmaxa′Q(s′,a′)Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a')Q(s,a)=R(s)+γmaxa′Q(s′,a′),用于构建训练目标 |
| 5 | 监督学习视角 | 将强化学习转化为 f(x)≈yf(x) \approx yf(x)≈y 的回归问题 |
| 6 | 训练样本生成 | 通过环境交互获取 (s,a,R,s′)(s,a,R,s')(s,a,R,s′),再用贝尔曼方程计算 yyy |
Q 思考题
- 为什么不能直接用查表法存储 Q(s,a)Q(s,a)Q(s,a)?在连续状态空间中该如何解决?
- 如何理解"将强化学习转化为监督学习"这一过程?其背后的数学依据是什么?
- 如果动作空间是连续的(例如推力大小),应该如何修改当前模型?
- 在训练过程中,我们使用的 yyy 是基于当前 QQQ 函数的估计值,这会导致什么潜在问题?如何缓解?
PIN 学习建议
-
复习建议:
- 回顾第2门课中的神经网络基础(尤其是回归任务)
- 理解贝尔曼方程的物理意义:当前价值 = 即时奖励 + 未来最优价值
- 实践动手:尝试在简单环境中(如CartPole)实现一个类似的Q网络
-
延伸阅读方向:
- DQN(Deep Q-Network)论文:Mnih et al., "Human-level control through deep reinforcement learning"
- TD-learning(时序差分学习)原理
- Target Network 与 Experience Replay 的作用(将在后续章节介绍)
-
推荐练习:
- 使用Python实现一个简单的Q网络,输入状态和动作,输出Q值
- 手动计算几个样本的贝尔曼目标 yyy
- 尝试画出 x→yx \to yx→y 的训练数据示意图
📌 提示:本节内容是深度强化学习的基础,掌握好这个"从贝尔曼方程到监督学习"的转换逻辑,对于后续理解DQN、DDPG等算法至关重要。
AI自检修正
以下为AI自动检查发现的潜在问题,请人工确认:
-
错误 原文: Q(s,a)=R(s)+γmaxa′Q(s′,a′)Q(s,a) = R(s) + \gamma \max_{a'} Q(s', a')Q(s,a)=R(s)+γmaxa′Q(s′,a′) → 应改为: Q(s,a)=R(s,a)+γmaxa′Q(s′,a′)Q(s,a) = R(s, a) + \gamma \max_{a'} Q(s', a')Q(s,a)=R(s,a)+γmaxa′Q(s′,a′)
- 解释:即时奖励 RRR 不仅取决于状态 sss,还取决于动作 aaa。因此,正确的贝尔曼方程应该包含动作 aaa。
-
错误 原文: 定义标签 y=R(s)+γmaxa′Q(s′,a′)y = R(s) + \gamma \max_{a'} Q(s', a')y=R(s)+γmaxa′Q(s′,a′) → 应改为: 定义标签 y=R(s,a)+γmaxa′Q(s′,a′)y = R(s, a) + \gamma \max_{a'} Q(s', a')y=R(s,a)+γmaxa′Q(s′,a′)
- 解释:同样地,在定义监督学习的标签时,即时奖励 RRR 也应包括动作 aaa。
其他部分未发现明显错误。
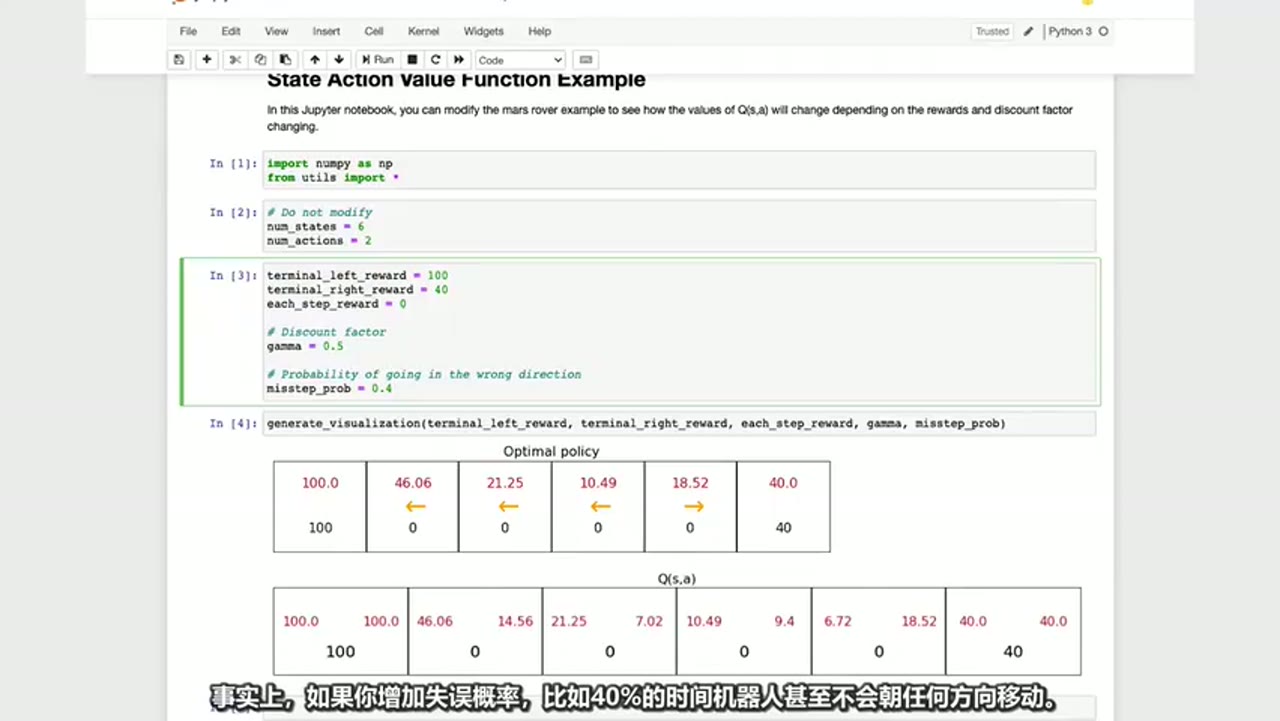
补充截图
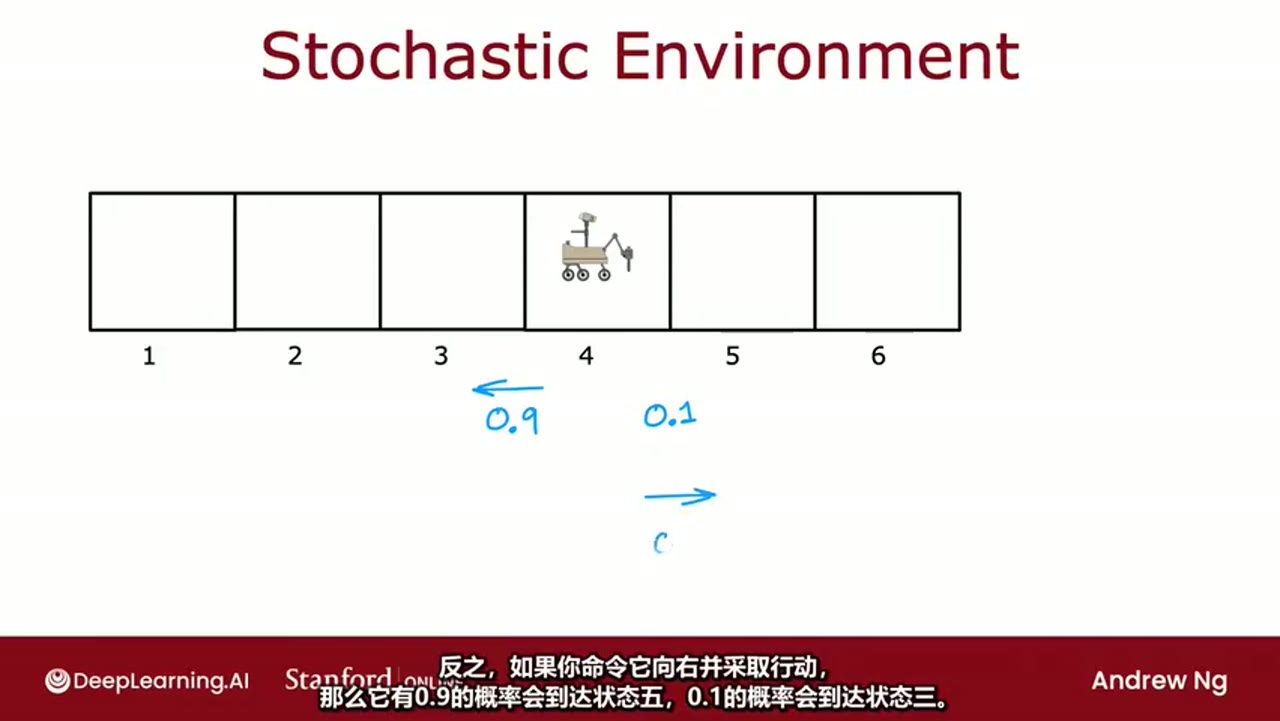
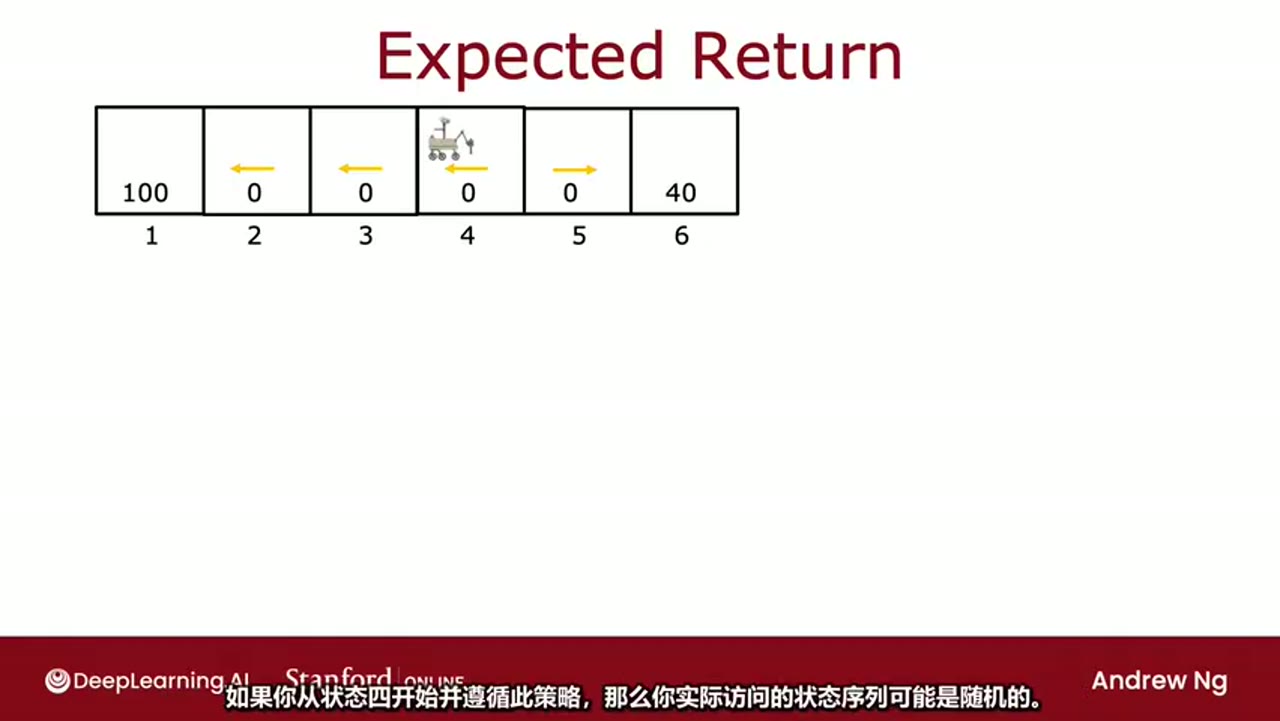
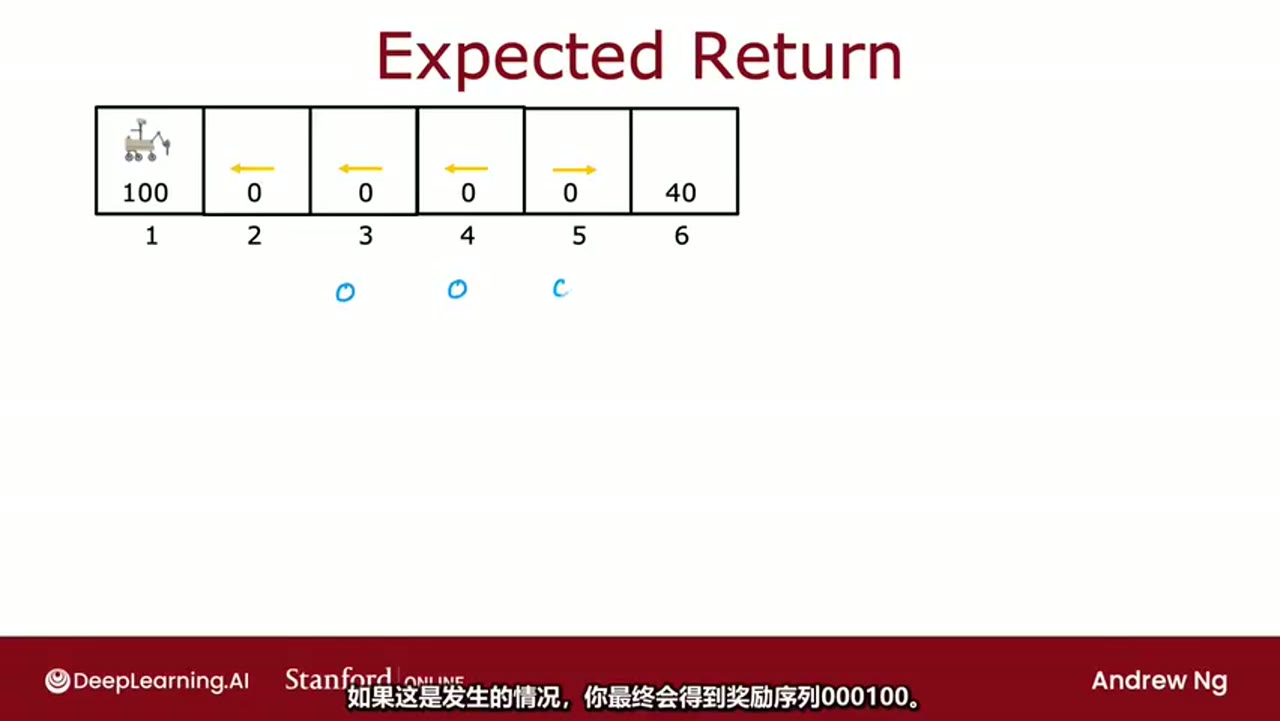
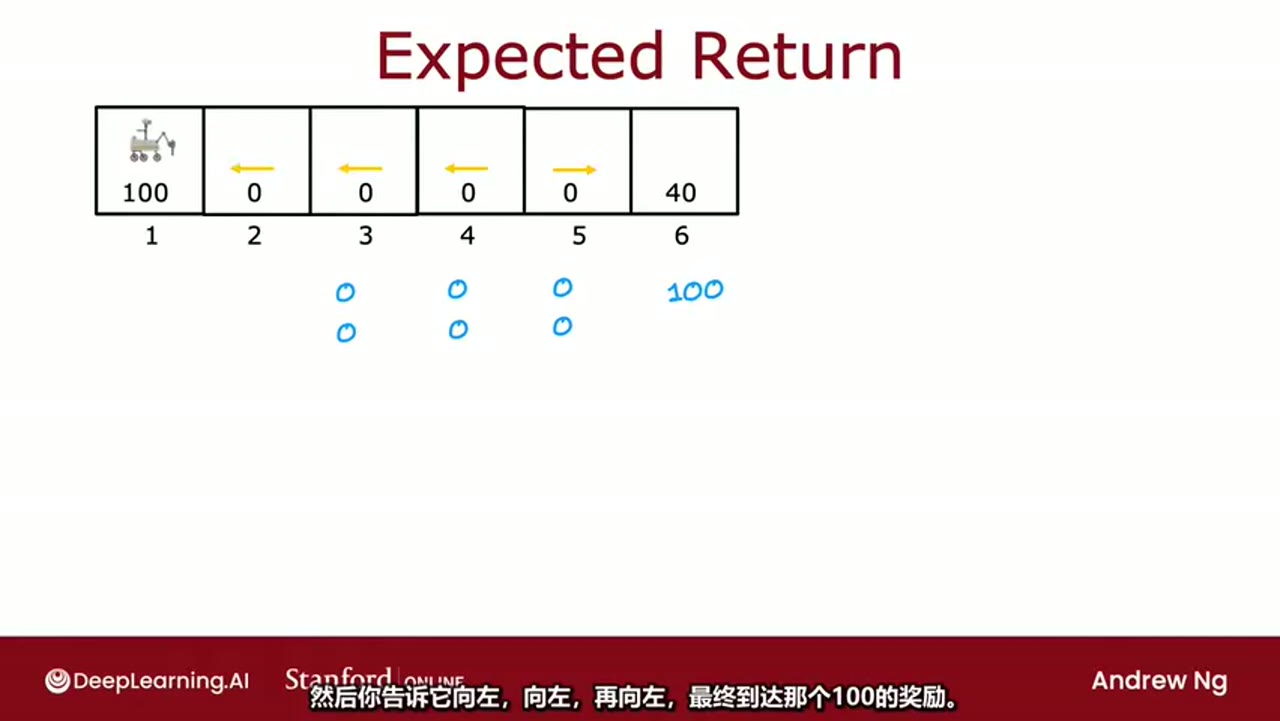




在每一步中,Q都只是某种猜测,
随着时间的推移,他们会变得更好,结果证明这就是实际的Q函数
















一个神经网络架构,它将输入状态和动作,并尝试输出Q函数,即Q(s, a)