Python 是当今机器学习生态系统的核心。凭借其简洁的编程风格、丰富的库支持以及强大的社区力量,Python 使得快速原型开发和模型构建变得十分容易。从数据预处理到模型部署,Python 能够支持完整的机器学习流程。因此,它既适合初学者,也适合专业人士使用。
 Python 相关工具库
Python 相关工具库
为什么选择 Python 进行机器学习?
- 简洁易读的语法:Python 简洁明了的语法结构使得开发者能够专注于机器学习逻辑的实现,而无需操心复杂的编程细节。
- 丰富的库生态系统:Python 中拥有 NumPy、Pandas、Matplotlib、Scrikit-learn、TensorFlow、PyTorch、Keras 和 SciPy 等众多库,这些库大大简化了数据处理、数据可视化和模型构建的过程。
- 庞大的活跃社区:这个庞大的社区提供了各种教程、Github 上的项目代码、研究资料以及问答服务,从而大大提升了学习和解决问题的效率。
- 灵活且可拓展:Python 能够在同一个生态系统中,用于快速原型开发、科研工作流程、生产系统构建、API 开发以及云部署等各种用途。
机器学习必备的 Python 库
- NumPy:为科学计算提供了高效的数组操作、线性代数运算以及向量化计算功能。
- Pandas:提供 DataFrame 数据结构,有助于高效地执行数据清洗、处理和转换操作。
- Matplotlib:用于创建各种基本的可视化图表,如折线图、条形图、直方图和散点图。
- Scikit-learn:提供了用于分类、回归、聚类、降维和评估的机器学习算法。
- SciPy:通过各种高级工具扩展了 NumPy 的功能,这些工具可用于优化、积分、插值以及各种科学计算。
- TensorFlow 和 Keras:支持在 GPU 上构建和训练深度学习模型,同时具备实际应用部署的功能。
- PyTorch:这是一个基于张量的灵活框架,同时支持 GPU,非常适合用于构建和训练神经网络。
为机器学习安装 Python 环境
在开始学习机器学习之前,你需要一个合适的 Python 环境。对于机器学习任务而言,有两种常用的 Python 环境配置方法。
1. 直接安装 Python
在进入下一步之前,请先在您的系统中安装 Python。
请参阅:如何安装 Python
这样,你就拥有了一个基础的 Python 环境。在此基础上,你可以使用 pip 手动安装 NumPy、Pandas、Matplotlib、TensorFlow 和 scikit-learn 等额外的库。
2. 安装 Anaconda
Anaconda 是一种非常受欢迎的数据科学和机器学习开发工具,因为它预先安装了许多必要的工具。这些工具包括:
- 用于交互式编写和测试机器学习代码的 Jupyter Notebook 工具
- Conda 包管理器,便于安装和环境管理
- 预装了 NumPy、Pandas、Matplotlib 和 scikit-learn 等机器学习库。
请参阅:如何安装 Anaconda
Anaconda 简化了环境设置并避免了依赖问题,使其成为机器学习项目初学者和专业人士的理想选择。
用于机器学习的 Python 数据结构
数据结构使得Python中的机器学习数据能够高效地存储和处理。
- 列表: 用于存储 ML 工作流程中的预测、损失或中间预处理结果等值序列。
- 元组: 存储固定的、不可更改的配置,例如图像形状或模型参数设置。
- 集合: 用于删除重复项并快速检查数据集中的唯一类别或类标签。
- 字典: 帮助映射类名到 ID、超参数和模型配置等关系。
- NumPy 数组: 高效存储数值数据,并执行对机器学习算法至关重要的快速向量化操作。
Python数据处理
数据预处理是机器学习中的关键步骤,因为它能确保模型训练获得干净、一致且有意义的数据。
- 处理缺失值: 使用统计方法或向前/向后填充来填充或删除缺失条目。
- 处理异常值: 使用 IQR 或 Z 分数检测异常值,并根据领域需求进行处理。
- 分类数据编码: 使用标签编码、独热编码或目标编码将类别转换为数字。
- 特征缩放: 对特征进行归一化或标准化,以确保模型训练的稳定性和平衡性。
- 处理不平衡数据: 使用 SMOTE、过采样或欠采样来平衡不均匀的类别分布。
- 使用 Pandas 进行数据处理: Pandas 可以高效地简化数据集的清理、过滤、合并和组织。
探索性数据分析(EDA)
探索性数据分析(EDA)是机器学习中的一个重要步骤,它有助于在模型构建之前识别数据集中的模式、关系和异常情况。
常用EDA技术
- 汇总统计信息用于了解数据的集中趋势和离散程度。
- 分布分析用于检验特征的分布情况
- 利用相关性热图研究数值特征之间的关系
- 用于可视化特征交互的配对图
- 使用箱线图检测异常值和各类别之间的差异
Python机器学习工作流程
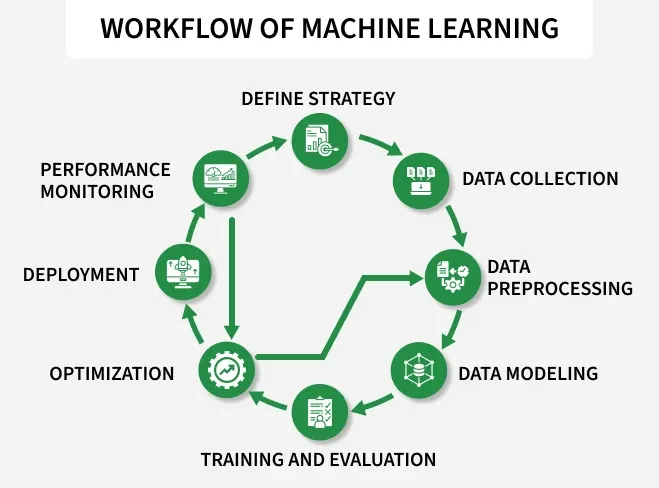 工作流程
工作流程
机器学习项目遵循结构化的生命周期,每个阶段都为下一个阶段奠定基础。图中所示的工作流程可以映射到以下步骤:
- 明确战略: 理解问题、业务目标以及解决问题的方法。
- 数据收集: 从数据库、API、传感器或公共来源收集高质量数据。
- 数据预处理: 通过处理缺失值、修复异常值、编码类别和缩放特征来清理数据。
- 数据建模: 选择合适的机器学习算法并准备模型结构。
- 训练和评估: 训练模型并使用准确率、F1 分数或 RMSE 等指标评估性能。
- 优化: 调整超参数并改进特征以提高性能。
- 部署: 将训练好的模型集成到应用程序、API 或云系统中。
- 监测: 跟踪模型在实际使用中的准确性、漂移和延迟。
- 重新训练: 使用新数据更新模型,以保持其长期准确性。
Python 提供从开始到结束的流畅工作流程。随着你不断学习,Python 仍将是一个可靠且灵活的工具,用于解决现实世界中的机器学习问题。