文章目录
-
- 每日一句正能量
- 一、为什么单模态感知不够?
- 二、三种模态的物理本质
-
- [2.1 视觉:光子的统计推断](#2.1 视觉:光子的统计推断)
- [2.2 触觉:形变的力学响应](#2.2 触觉:形变的力学响应)
- [2.3 力觉:动量的时间积分](#2.3 力觉:动量的时间积分)
- 三、融合架构:从早期融合到晚期融合
-
- [3.1 早期融合(数据级融合)](#3.1 早期融合(数据级融合))
- [3.2 中期融合(特征级融合)](#3.2 中期融合(特征级融合))
- [3.3 晚期融合(决策级融合)](#3.3 晚期融合(决策级融合))
- 四、核心挑战:对齐与不确定性
-
- [4.1 时间对齐:三种模态的"心跳"不同步](#4.1 时间对齐:三种模态的"心跳"不同步)
- [4.2 空间对齐:不同坐标系的"巴别塔"](#4.2 空间对齐:不同坐标系的"巴别塔")
- [4.3 不确定性量化:知道"不知道"比知道更重要](#4.3 不确定性量化:知道"不知道"比知道更重要)
- 五、实战:多模态抓取网络
- 六、前沿进展:2024-2026年的突破
-
- [6.1 神经辐射场(NeRF)+ 触觉:可微分物理感知](#6.1 神经辐射场(NeRF)+ 触觉:可微分物理感知)
- [6.2 大模型时代的多模态融合](#6.2 大模型时代的多模态融合)
- [6.3 事件相机 + 触觉:微秒级同步](#6.3 事件相机 + 触觉:微秒级同步)
- 七、未解难题
- 八、结语

每日一句正能量
生活再平凡,也是独属于你的限量版。
不要用"别人活出的精彩"来衡量自己的日常。一碗自己做的面、一个安静的午后、一次没有目的散步,这些看似普通的事,因为"你"是唯一的体验者,所以就是不可复制的。珍贵不在于惊艳,在于真实。
人类闭上眼睛也能握住一杯水,因为指尖的触觉和手腕的力觉在代替视觉工作。机器人要做到这一点,需要解决一个比单模态感知困难十倍的问题。
一、为什么单模态感知不够?
2019年,MIT的机器人实验室发生了一次著名的失败:一台配备高精度RGB-D相机的机械臂,在抓取一个透明玻璃杯时,连续七次失败。相机无法正确估计玻璃表面的深度------光线穿透、反射、折射让视觉算法彻底失效。
工程师临时给机械臂加装了一个六维力传感器,问题迎刃而解:当机械爪接触到杯壁的瞬间,力反馈告诉机器人"我已经碰到了",视觉的盲区被触觉和力觉填补。
这个案例揭示了一个根本事实:真实世界的感知是冗余的、互补的、跨模态的。
| 模态 | 优势 | 致命盲区 |
|---|---|---|
| 视觉 | 远距离、高带宽、语义丰富 | 透明/反光/遮挡/黑暗环境 |
| 触觉 | 接触细节、材质纹理、局部形变 | 仅限接触区域、无距离信息 |
| 力觉 | 动态交互、负载估计、柔顺控制 | 无法识别物体类别 |
单一模态的机器人,就像只有一只感官的人类------能在特定场景工作,但永远无法应对真实世界的复杂性。
二、三种模态的物理本质

2.1 视觉:光子的统计推断
视觉传感器(相机、激光雷达)测量的是电磁辐射。RGB相机记录可见光波段的强度分布,深度相机(结构光/ToF)测量光子的飞行时间或相位差。
视觉感知的数学本质:
I(x,y,λ) = ∫ L(x,y,λ,θ,φ) * R(θ,φ) dΩ
其中 L 是入射光,R 是反射率,Ω 是立体角关键挑战 :视觉是间接测量------我们看到的是光,不是物体本身。透明物体的折射、镜面的反射、黑暗中的噪声,都是光子传播过程中的失真。
2.2 触觉:形变的力学响应
触觉传感器测量的是接触界面的力学分布。根据原理不同,分为:
| 类型 | 原理 | 代表产品 | 分辨率 |
|---|---|---|---|
| 电阻式 | 导电聚合物形变改变电阻 | Tekscan FlexiForce | 低 |
| 电容式 | 介电层形变改变电容 | SynTouch BioTac | 中 |
| 光学式 | 弹性体内部光场畸变 | GelSight | 高(可达微米级) |
| 压阻式 | 半导体压阻效应 | 定制MEMS | 极高 |
GelSight的巧妙设计 :在弹性体表面涂覆一层反光膜,内部嵌入微型相机。当物体接触表面时,弹性体形变导致反光图案变化,通过光度立体法重建接触表面的三维微观形貌。
2.3 力觉:动量的时间积分
力/力矩传感器(F/T Sensor)测量的是广义力 ------包括三个方向的力和三个方向的力矩。最常见的实现是应变片电桥:
应变片原理:
弹性体受力形变 → 应变片电阻变化 → 惠斯通电桥输出电压 → 标定力/力矩六维力传感器的核心难点在于解耦:如何从一个弹性体的形变中,分离出Fx、Fy、Fz、Mx、My、Mz六个独立分量。这需要精密的结构设计和标定算法。
三、融合架构:从早期融合到晚期融合
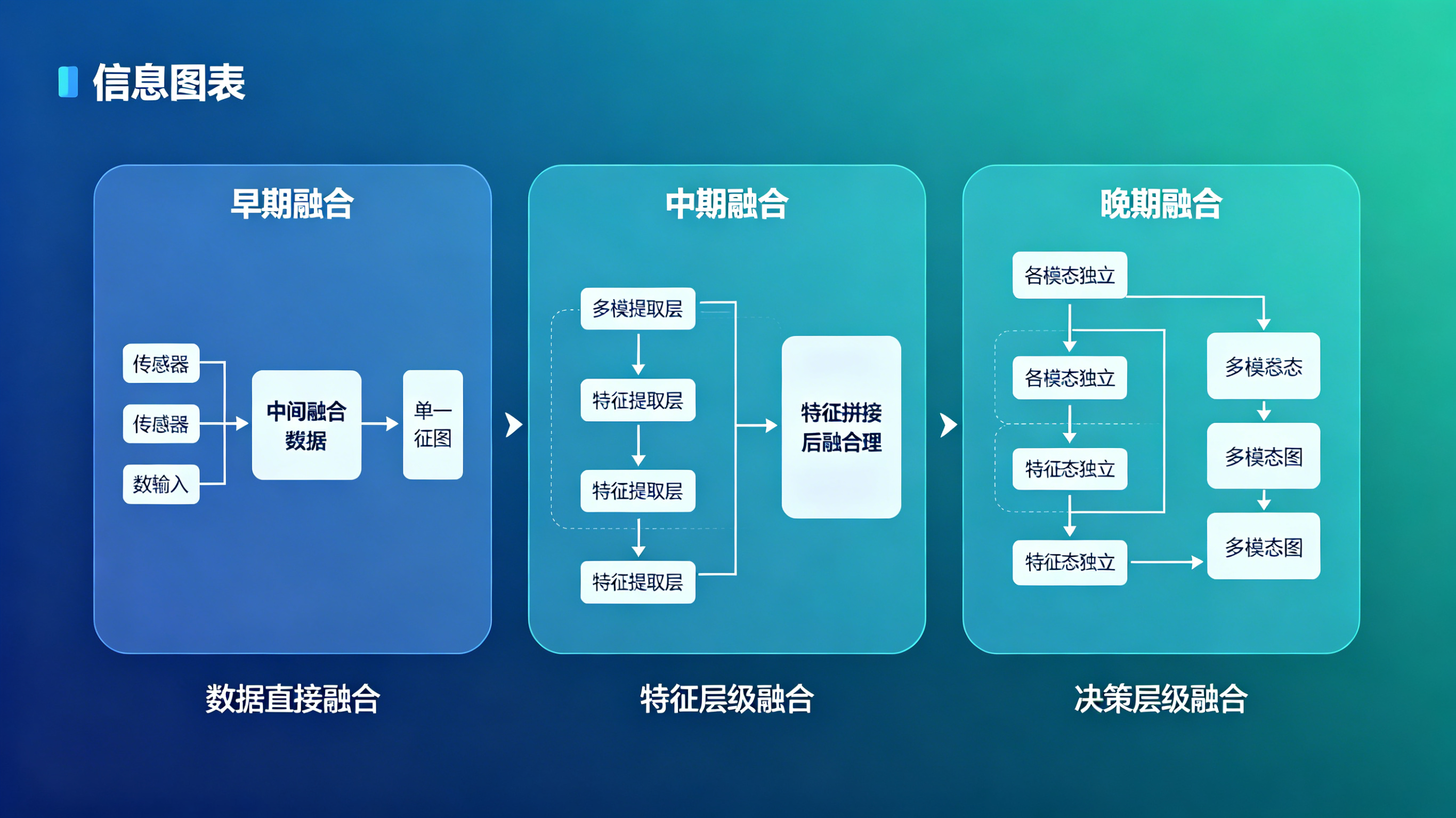
多模态融合不是简单地把三个传感器的数据拼接在一起。根据融合发生的阶段,分为三种架构:
3.1 早期融合(数据级融合)
视觉图像 (640×480×3) ──┐
触觉图像 (128×128×3) ──┼→ [拼接] → 联合特征提取 → 决策
力觉向量 (6×1) ────────┘优点:信息损失最小,网络可以自动学习跨模态关联。
缺点:维度灾难,不同模态的采样频率、空间分辨率、数值范围差异巨大,直接拼接效果差。
适用场景:模态间时空对齐容易的任务(如同步采集的固定视角相机+触觉)。
3.2 中期融合(特征级融合)
视觉图像 → CNN → 视觉特征 (512-d) ──┐
触觉图像 → CNN → 触觉特征 (256-d) ──┼→ [注意力机制] → 联合表征 → 决策
力觉向量 → MLP → 力觉特征 (128-d) ──┘优点:各模态独立编码,可以处理不同频率和分辨率;注意力机制实现自适应加权。
缺点:需要设计模态间的对齐机制(时间对齐、空间对齐)。
代表工作 :2023年Google的RT-2,使用Transformer统一处理视觉token和语言token,动作作为输出生成。
3.3 晚期融合(决策级融合)
视觉图像 → 视觉网络 → 视觉决策 (抓取点概率分布) ──┐
触觉信号 → 触觉网络 → 接触状态判断 ────────────────┼→ [贝叶斯/投票] → 最终动作
力觉信号 → 力控网络 → 力/位混合控制指令 ────────────┘优点:模块化强,各模态可以独立开发和验证;系统鲁棒性高(某一模态失效时 graceful degradation)。
缺点:信息损失大,高层决策可能丢失低层特征中的关键关联。
适用场景:工业系统(需要模块化、可解释、可审计)。
四、核心挑战:对齐与不确定性
4.1 时间对齐:三种模态的"心跳"不同步
| 模态 | 典型频率 | 延迟 |
|---|---|---|
| 视觉(RGB相机) | 30-60 Hz | 10-33 ms |
| 触觉(GelSight) | 60-120 Hz | 5-15 ms |
| 力觉(ATI传感器) | 1-10 kHz | 0.1-1 ms |
问题:当机器人以1m/s速度移动时,30ms的视觉延迟意味着3cm的位置误差------足以让抓取失败。
解决方案:
- 硬件同步:使用PTP(Precision Time Protocol)或硬件触发线,强制所有传感器在同一时刻采样
- 时间戳插值:以最高频率(力觉)为基准,对视觉和触觉数据进行线性插值
- 状态估计器:使用卡尔曼滤波或粒子滤波,融合历史观测预测当前状态
python
"""
多模态时间对齐:以力觉为基准的插值同步
"""
import numpy as np
from scipy.interpolate import interp1d
class MultiModalSynchronizer:
def __init__(self, buffer_size=1000):
self.visual_buffer = [] # (timestamp, image)
self.tactile_buffer = [] # (timestamp, tactile_image)
self.force_buffer = [] # (timestamp, force_vector)
self.buffer_size = buffer_size
def add_visual(self, timestamp, image):
self.visual_buffer.append((timestamp, image))
self._trim_buffer(self.visual_buffer)
def add_tactile(self, timestamp, tactile):
self.tactile_buffer.append((timestamp, tactile))
self._trim_buffer(self.tactile_buffer)
def add_force(self, timestamp, force):
self.force_buffer.append((timestamp, force))
self._trim_buffer(self.force_buffer)
def _trim_buffer(self, buffer):
if len(buffer) > self.buffer_size:
buffer.pop(0)
def get_synced_observation(self, target_time):
"""
获取target_time时刻的同步观测
策略:视觉和触觉插值到力觉时间戳
"""
# 提取时间序列
v_times = np.array([t for t, _ in self.visual_buffer])
v_data = np.array([d for _, d in self.visual_buffer])
t_times = np.array([t for t, _ in self.tactile_buffer])
t_data = np.array([d for _, d in self.tactile_buffer])
f_times = np.array([t for t, _ in self.force_buffer])
f_data = np.array([d for _, d in self.force_buffer])
# 找到最接近target_time的力觉数据
f_idx = np.argmin(np.abs(f_times - target_time))
force = f_data[f_idx]
# 视觉插值
if target_time < v_times[0] or target_time > v_times[-1]:
visual = v_data[0] if target_time < v_times[0] else v_data[-1]
else:
interp_v = interp1d(v_times, v_data, axis=0, kind='linear')
visual = interp_v(target_time)
# 触觉插值
if target_time < t_times[0] or target_time > t_times[-1]:
tactile = t_data[0] if target_time < t_times[0] else t_data[-1]
else:
interp_t = interp1d(t_times, t_data, axis=0, kind='linear')
tactile = interp_t(target_time)
return {
'timestamp': target_time,
'visual': visual,
'tactile': tactile,
'force': force
}
# 使用示例
sync = MultiModalSynchronizer()
# 模拟异步数据流
import time
start_time = time.time()
# 力觉高频采样
for i in range(100):
sync.add_force(start_time + i*0.001, np.random.randn(6))
# 视觉低频采样
for i in range(10):
sync.add_visual(start_time + i*0.033, np.random.randn(480, 640, 3))
# 触觉中频采样
for i in range(20):
sync.add_tactile(start_time + i*0.016, np.random.randn(128, 128, 3))
# 获取同步观测
obs = sync.get_synced_observation(start_time + 0.05)
print(f"同步观测时间戳: {obs['timestamp']:.3f}s")
print(f"视觉形状: {obs['visual'].shape}")
print(f"触觉形状: {obs['tactile'].shape}")
print(f"力觉形状: {obs['force'].shape}")4.2 空间对齐:不同坐标系的"巴别塔"
视觉在相机坐标系 中感知,触觉在指尖局部坐标系 中感知,力觉在腕部/基座坐标系中感知。融合前必须统一到一个参考系。
坐标系转换链:
视觉点云 (相机坐标系)
↓ T_camera^world
世界坐标系
↓ T_world^gripper
机械爪坐标系
↓ T_gripper^tactile
触觉传感器坐标系
↓ T_tactile^contact
接触点局部坐标系关键问题:标定误差会累积。相机外参标定误差1mm,经过机械臂运动学传递后,可能导致指尖位置误差5mm以上。
解决方案:
- 手眼标定:使用ArUco/AprilTag棋盘格,精确估计相机与机械臂基座的相对位姿
- 在线标定:利用接触反馈修正视觉估计("我看到杯子在这里,但触觉告诉我实际偏左2mm")
- 联合优化:将标定参数纳入端到端学习,让网络自动补偿系统误差
4.3 不确定性量化:知道"不知道"比知道更重要
每个模态的测量都有噪声和盲区。融合时必须量化不确定性:
贝叶斯融合框架:
P(state | visual, tactile, force) ∝ P(visual | state) * P(tactile | state) * P(force | state) * P(state)
其中每个似然项 P(modality | state) 都包含该模态的不确定性实际实现:
- 视觉:使用MC Dropout或深度集成,估计深度估计的方差
- 触觉:根据接触面积和压力分布,估计形变重建的置信度
- 力觉:根据信噪比和校准矩阵的条件数,估计力/力矩的协方差
五、实战:多模态抓取网络
以下是一个简化的视觉-触觉-力觉融合抓取网络,使用PyTorch实现。
python
"""
多模态感知融合网络:视觉-触觉-力觉联合编码
架构:三模态独立编码 → 跨模态注意力融合 → 抓取位姿预测
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class VisualEncoder(nn.Module):
"""
视觉编码器:ResNet-18 backbone,输出视觉特征
输入:RGB-D图像 (B, 4, 224, 224)
输出:视觉特征 (B, 512)
"""
def __init__(self):
super().__init__()
# 修改首层接受4通道(RGB+Depth)
self.conv1 = nn.Conv2d(4, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 简化的ResNet blocks
self.layer1 = self._make_layer(64, 64, 2)
self.layer2 = self._make_layer(64, 128, 2, stride=2)
self.layer3 = self._make_layer(128, 256, 2, stride=2)
self.layer4 = self._make_layer(256, 512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
def _make_layer(self, in_ch, out_ch, blocks, stride=1):
layers = []
layers.append(nn.Conv2d(in_ch, out_ch, 3, stride=stride, padding=1, bias=False))
layers.append(nn.BatchNorm2d(out_ch))
layers.append(nn.ReLU(inplace=True))
for _ in range(1, blocks):
layers.append(nn.Conv2d(out_ch, out_ch, 3, padding=1, bias=False))
layers.append(nn.BatchNorm2d(out_ch))
layers.append(nn.ReLU(inplace=True))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
class TactileEncoder(nn.Module):
"""
触觉编码器:处理GelSight类触觉图像
输入:触觉图像 (B, 3, 128, 128) - 法向图/深度图/mask
输出:触觉特征 (B, 256)
"""
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(128, 256, 3, stride=2, padding=1)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.pool(x)
return torch.flatten(x, 1)
class ForceEncoder(nn.Module):
"""
力觉编码器:处理六维力/力矩信号
输入:力/力矩向量 (B, 6) + 历史序列 (B, T, 6)
输出:力觉特征 (B, 128)
"""
def __init__(self, history_len=10):
super().__init__()
self.history_len = history_len
# 时序编码:1D卷积提取局部动态
self.temporal_conv = nn.Conv1d(6, 32, kernel_size=3, padding=1)
# 当前状态编码
self.state_fc = nn.Sequential(
nn.Linear(6, 64),
nn.ReLU(),
nn.Linear(64, 64)
)
# 融合
self.fusion = nn.Sequential(
nn.Linear(32 + 64, 128),
nn.ReLU(),
nn.Linear(128, 128)
)
def forward(self, force_current, force_history):
"""
force_current: (B, 6)
force_history: (B, T, 6)
"""
# 时序特征
fh = force_history.transpose(1, 2) # (B, 6, T)
fh = F.relu(self.temporal_conv(fh))
fh = F.adaptive_avg_pool1d(fh, 1).squeeze(-1) # (B, 32)
# 当前状态特征
fc = self.state_fc(force_current) # (B, 64)
# 融合
fused = torch.cat([fh, fc], dim=-1)
return self.fusion(fused)
class CrossModalAttention(nn.Module):
"""
跨模态注意力:实现视觉-触觉-力觉的特征交互
核心思想:每个模态作为Query,其他模态作为Key/Value
"""
def __init__(self, dim_v=512, dim_t=256, dim_f=128, dim_out=256):
super().__init__()
# 投影到统一维度
self.proj_v = nn.Linear(dim_v, dim_out)
self.proj_t = nn.Linear(dim_t, dim_out)
self.proj_f = nn.Linear(dim_f, dim_out)
# 多模态注意力
self.attn = nn.MultiheadAttention(dim_out, num_heads=8, batch_first=True)
# 输出融合
self.output_fc = nn.Sequential(
nn.Linear(dim_out * 3, dim_out),
nn.ReLU(),
nn.Linear(dim_out, dim_out)
)
def forward(self, feat_v, feat_t, feat_f):
"""
feat_v: (B, 512) 视觉
feat_t: (B, 256) 触觉
feat_f: (B, 128) 力觉
"""
# 投影
v = self.proj_v(feat_v).unsqueeze(1) # (B, 1, D)
t = self.proj_t(feat_t).unsqueeze(1) # (B, 1, D)
f = self.proj_f(feat_f).unsqueeze(1) # (B, 1, D)
# 拼接为序列
multi_modal = torch.cat([v, t, f], dim=1) # (B, 3, D)
# 自注意力:模态间交互
attn_out, _ = self.attn(multi_modal, multi_modal, multi_modal)
# 展平并融合
attn_out = attn_out.reshape(attn_out.size(0), -1) # (B, 3*D)
return self.output_fc(attn_out)
class MultiModalGraspNet(nn.Module):
"""
多模态抓取网络:端到端预测抓取位姿
输出:抓取点 (x,y,z) + 抓取方向 (qx,qy,qz,qw) + 开合宽度 + 置信度
"""
def __init__(self):
super().__init__()
self.visual_enc = VisualEncoder()
self.tactile_enc = TactileEncoder()
self.force_enc = ForceEncoder(history_len=10)
self.cross_attn = CrossModalAttention(dim_v=512, dim_t=256, dim_f=128, dim_out=256)
# 抓取预测头
self.grasp_head = nn.Sequential(
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 128),
nn.ReLU()
)
# 多任务输出
self.position_pred = nn.Linear(128, 3) # 抓取位置
self.orientation_pred = nn.Linear(128, 4) # 四元数(需归一化)
self.width_pred = nn.Linear(128, 1) # 开合宽度
self.confidence_pred = nn.Linear(128, 1) # 置信度
def forward(self, visual, tactile, force_current, force_history):
"""
visual: (B, 4, 224, 224) RGB-D
tactile: (B, 3, 128, 128) 触觉图像
force_current: (B, 6) 当前力/力矩
force_history: (B, 10, 6) 历史力/力矩序列
"""
# 独立编码
feat_v = self.visual_enc(visual)
feat_t = self.tactile_enc(tactile)
feat_f = self.force_enc(force_current, force_history)
# 跨模态融合
fused = self.cross_attn(feat_v, feat_t, feat_f)
# 抓取预测
features = self.grasp_head(fused)
position = self.position_pred(features)
orientation = F.normalize(self.orientation_pred(features), dim=-1) # 单位四元数
width = torch.sigmoid(self.width_pred(features)) * 0.1 # 0-10cm
confidence = torch.sigmoid(self.confidence_pred(features))
return {
'position': position,
'orientation': orientation,
'width': width,
'confidence': confidence
}
# 测试网络
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MultiModalGraspNet().to(device)
# 模拟输入
batch_size = 4
visual = torch.randn(batch_size, 4, 224, 224).to(device)
tactile = torch.randn(batch_size, 3, 128, 128).to(device)
force_current = torch.randn(batch_size, 6).to(device)
force_history = torch.randn(batch_size, 10, 6).to(device)
# 前向传播
output = model(visual, tactile, force_current, force_history)
print("多模态抓取网络输出:")
print(f" 抓取位置: {output['position'].shape}")
print(f" 抓取方向: {output['orientation'].shape}")
print(f" 开合宽度: {output['width'].shape}")
print(f" 置信度: {output['confidence'].shape}")
# 计算参数量
total_params = sum(p.numel() for p in model.parameters())
print(f"\n总参数量: {total_params:,} ({total_params/1e6:.2f}M)")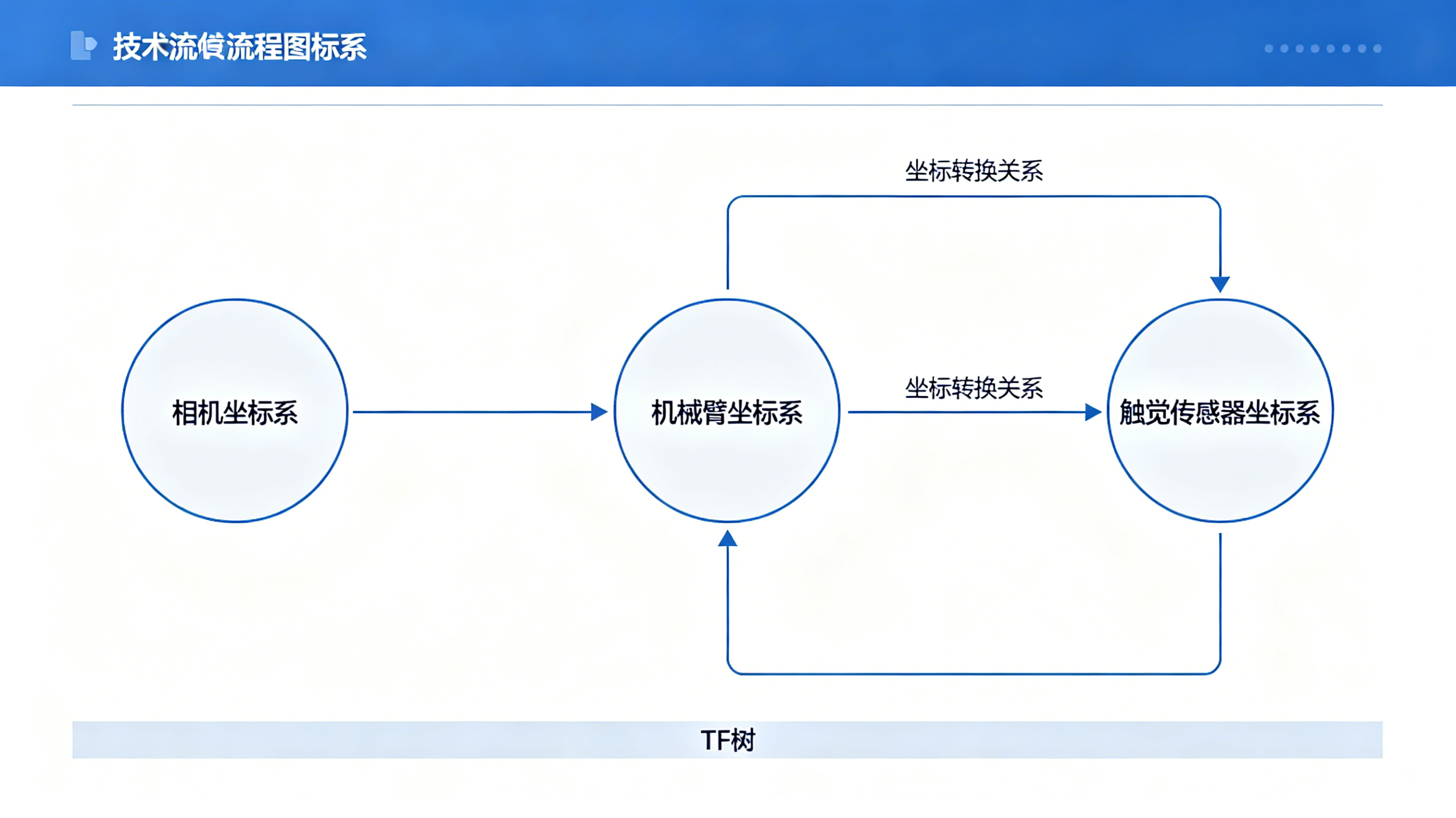
六、前沿进展:2024-2026年的突破
6.1 神经辐射场(NeRF)+ 触觉:可微分物理感知
2024年,MIT CSAIL提出Tactile-NeRF:将GelSight的触觉图像作为约束,优化NeRF的密度场。结果是------机器人不仅能"看到"物体外观,还能"摸到"内部结构。
Tactile-NeRF的核心思想:
视觉NeRF: 优化密度场 σ(x) 匹配多视角RGB
触觉约束: 在接触点处,密度场梯度应与触觉形变一致
联合优化: min ||I_render - I_real||² + λ||∇σ(x_contact) - tactile_normal||²6.2 大模型时代的多模态融合
2025年,Google的RT-H 和智源的GEAR 展示了新范式:不再设计专门的融合网络,而是将视觉、触觉、力觉统一token化,输入到Transformer中自注意力融合。
RT-H的输入表示:
[VIS] v₁ v₂ ... vₙ [TAC] t₁ t₂ ... tₘ [FOR] f₁ f₂ ... fₖ [ACT] a₁ a₂ ... aₗ
其中 [VIS]/[TAC]/[FOR]/[ACT] 是模态标识token
所有token在同一嵌入空间中,通过自注意力自动学习跨模态关联优势:无需手工设计融合架构,模型自动发现最优关联模式。
6.3 事件相机 + 触觉:微秒级同步
传统相机的帧率限制(30-60Hz)是动态操作瓶颈。2025年,苏黎世联邦理工(ETH)将事件相机 (Event Camera,微秒级时间分辨率)与触觉融合,实现了高速滑动检测------机器人能感知手指划过物体表面时的微小振动。
七、未解难题
- 模态缺失的鲁棒性:当某一模态完全失效(如黑暗环境中视觉丢失),系统能否 graceful degradation?
- 因果推断:触觉反馈是由视觉预测的动作引起的,还是环境独立变化的?如何区分?
- 主动感知 :人类会主动移动手指探索未知物体。机器人如何学习最优感知策略,而非被动接收?
- 跨本体迁移:在A机器人上学习的多模态融合模型,能否迁移到B机器人(不同传感器配置)?
八、结语
多模态感知融合是具身智能的基础设施。没有它,机器人永远是"独眼龙"------能看到但摸不着,或摸得着但看不见。
从早期的简单拼接,到基于注意力的自适应融合,再到大模型时代的统一表征,融合架构在进化。但核心挑战始终不变:时间对齐、空间对齐、不确定性量化。
未来的突破可能来自两个方向:
- 硬件:新型传感器(如事件相机、光学触觉皮肤)降低对齐难度
- 算法:世界模型内嵌物理约束,让融合从"统计关联"升级为"因果推理"
当机器人能像人类一样,自然地整合视觉、触觉和力觉时,它将真正理解"抓握"不仅是位置控制,而是与物理世界的对话。
转载自:https://blog.csdn.net/u014727709/article/details/161726518
欢迎 👍点赞✍评论⭐收藏,欢迎指正