目录
[一、HTTP 协议概述](#一、HTTP 协议概述)
[二、认识 URL](#二、认识 URL)
[三、urlencode 和 urldecode(了解)](#三、urlencode 和 urldecode(了解))
[四、HTTP 协议请求与响应格式](#四、HTTP 协议请求与响应格式)
[核心问题拆解:HTTP 请求怎么指定资源?服务器资源存在哪里?](#核心问题拆解:HTTP 请求怎么指定资源?服务器资源存在哪里?)
[1. 客户端(浏览器):用「URI 路径」告诉服务器 "我要什么"](#1. 客户端(浏览器):用「URI 路径」告诉服务器 “我要什么”)
[2. 服务器端:资源存在「Web 根目录(webroot)」里(核心误区纠正)](#2. 服务器端:资源存在「Web 根目录(webroot)」里(核心误区纠正))
[关键公式:真实文件路径 = webroot + URI 路径](#关键公式:真实文件路径 = webroot + URI 路径)
[为什么不能用 Linux 根目录?](#为什么不能用 Linux 根目录?)
[3. 特殊情况:请求根路径/(首页)的处理](#3. 特殊情况:请求根路径/(首页)的处理)
[HTTP 请求的本质](#HTTP 请求的本质)
[五、HTTP 的方法](#五、HTTP 的方法)
[1. GET 方法(重点)](#1. GET 方法(重点))
[2. POST 方法(重点)](#2. POST 方法(重点))
[GET vs POST 核心区别(校招高频考点)](#GET vs POST 核心区别(校招高频考点))
[3. PUT 方法(不常用)](#3. PUT 方法(不常用))
[4. HEAD 方法](#4. HEAD 方法)
[5. DELETE 方法(不常用)](#5. DELETE 方法(不常用))
[6. OPTIONS 方法](#6. OPTIONS 方法)
[六、HTTP 的状态码](#六、HTTP 的状态码)
[七、HTTP 常见 Header](#七、HTTP 常见 Header)
[1. 通用 Header(请求和响应均可使用)](#1. 通用 Header(请求和响应均可使用))
[2. 请求 Header(客户端发送给服务器)](#2. 请求 Header(客户端发送给服务器))
[3. 响应 Header(服务器发送给客户端)](#3. 响应 Header(服务器发送给客户端))
[重点:Connection 报头详解](#重点:Connection 报头详解)
[8.1PC 互联网时代「浏览器大战」脉络](#8.1PC 互联网时代「浏览器大战」脉络)
[8.2GET 和 POST 核心区别](#8.2GET 和 POST 核心区别)
[8.3Fiddler 抓包原理](#8.3Fiddler 抓包原理)
[8.4HTTP 不安全 → HTTPS 加密(后面有详谈)](#8.4HTTP 不安全 → HTTPS 加密(后面有详谈))
[8.5HTTP 两种重定向](#8.5HTTP 两种重定向)
[8.5.1客户端驱动的 3xx 重定向(外部跳转)](#8.5.1客户端驱动的 3xx 重定向(外部跳转))
[1. 核心原理](#1. 核心原理)
[2. 常见 3xx 状态码分类与应用场景](#2. 常见 3xx 状态码分类与应用场景)
[3. 实现示例(C++ 伪代码)](#3. 实现示例(C++ 伪代码))
[8.5.2服务器内部的 404 资源替换(内部重定向)](#8.5.2服务器内部的 404 资源替换(内部重定向))
[1. 核心原理](#1. 核心原理)
[2. 关键特性与价值](#2. 关键特性与价值)
[3. 代码中MakeResponse实现逻辑](#3. 代码中MakeResponse实现逻辑)
[8.6长短连接(短连接 HTTP/1.0、长连接 HTTP/1.1)](#8.6长短连接(短连接 HTTP/1.0、长连接 HTTP/1.1))
[1. 短连接:HTTP/1.0 默认(Connection: close)](#1. 短连接:HTTP/1.0 默认(Connection: close))
[2. 长连接:HTTP/1.1 默认(Connection: keep-alive)](#2. 长连接:HTTP/1.1 默认(Connection: keep-alive))
[8.7Cookie & Session](#8.7Cookie & Session)
[1. Cookie 是什么](#1. Cookie 是什么)
[Cookie 工作流程](#Cookie 工作流程)
[❌ Cookie 致命缺点](#❌ Cookie 致命缺点)
[2. Session:弥补 Cookie 安全缺陷(服务端存数据)](#2. Session:弥补 Cookie 安全缺陷(服务端存数据))
[✅ 安全优势](#✅ 安全优势)
[3. Cookie 与 Session 关系总结](#3. Cookie 与 Session 关系总结)
[9.1前言:为什么 HTTP 必须升级成 HTTPS?](#9.1前言:为什么 HTTP 必须升级成 HTTPS?)
[1. 对称加密(AES/DES)](#1. 对称加密(AES/DES))
[2. 非对称加密(RSA)](#2. 非对称加密(RSA))
[3. Hash 摘要 + 数字签名(MD5/SHA256)](#3. Hash 摘要 + 数字签名(MD5/SHA256))
[9.3五大加密方案迭代(附 ASCII 流程图,由坑到最优)](#9.3五大加密方案迭代(附 ASCII 流程图,由坑到最优))
[方案 1:仅使用【对称加密】](#方案 1:仅使用【对称加密】)
[方案 2:仅单向非对称加密(服务端独有公私钥)](#方案 2:仅单向非对称加密(服务端独有公私钥))
[方案 3:客户端 + 服务端双向非对称加密](#方案 3:客户端 + 服务端双向非对称加密)
[方案 4:非对称 + 对称混合加密(HTTPS 雏形,仍有中间人漏洞)](#方案 4:非对称 + 对称混合加密(HTTPS 雏形,仍有中间人漏洞))
[实现逻辑(HTTPS 主流思路沿用至今)](#实现逻辑(HTTPS 主流思路沿用至今))
[致命漏洞:中间人劫持公钥(MITM 中间人攻击)](#致命漏洞:中间人劫持公钥(MITM 中间人攻击))
[方案 5:混合加密 + CA 数字证书(最终 HTTPS 正式方案,完美闭环)](#方案 5:混合加密 + CA 数字证书(最终 HTTPS 正式方案,完美闭环))
[方案 5 优势](#方案 5 优势)
[9.4HTTPS 完整握手流程总结(三次密钥分工)](#9.4HTTPS 完整握手流程总结(三次密钥分工))

一、HTTP 协议概述
HTTP 是一种基于请求 - 响应模型的无状态应用层协议,默认基于 TCP/IP 传输层协议实现(HTTP/3.0 除外,基于 QUIC)。它定义了客户端(如浏览器、App)与服务器之间通信的格式和规则,核心特点可概括为:
- 请求 - 响应模型:客户端主动发起请求,服务器被动响应,通信过程完全由客户端驱动。
- 无状态:协议本身不存储任何请求 / 响应的上下文信息,每个请求都是独立的(后续通过 Cookie、Session 等机制实现会话保持)。
- 可扩展性强:通过 Header 字段可灵活扩展功能(如缓存控制、认证、跨域等),适配从网页浏览到 API 调用的各类场景。
HTTP 的设计初衷是传输超文本(HTML),如今已发展为通用的应用层协议,支撑着绝大多数互联网服务的通信交互。

二、认识 URL
URL(Uniform Resource Locator,统一资源定位符)是 HTTP 请求中用于定位资源的地址,我们常说的 "网址" 就是 URL 的典型形式。一个标准的 URL 结构如下:
scheme://host:port/path?query#fragment各部分含义:
- scheme(协议) :指定通信协议,如
http://、https://(HTTP 的加密版本,基于 TLS/SSL)。 - host(主机) :服务器的域名或 IP 地址,如
www.example.com、192.168.1.1。 - port(端口) :服务器的服务端口,HTTP 默认端口为
80,HTTPS 默认端口为443(URL 中可省略默认端口)。 - path(路径) :服务器上资源的具体路径,如
/index.html、/api/user。 - query(查询参数) :以
?开头的键值对参数,用于向服务器传递数据,格式为key1=value1&key2=value2。 - fragment(片段) :以
#开头的锚点,用于定位页面内的资源(仅客户端使用,不会发送给服务器)。
举个例子:https://api.example.com:443/user/info?id=123&name=test#profile
- 协议:
https - 主机:
api.example.com - 端口:
443(默认端口可省略,此处仅作示例) - 路径:
/user/info - 查询参数:
id=123&name=test - 片段:
#profile
三、urlencode 和 urldecode(了解)
URL 中部分字符具有特殊含义(如?、&、=),若查询参数中包含这些特殊字符,或中文、空格等非 ASCII 字符,会导致 URL 解析错误。此时需要通过urlencode(URL 编码)对参数进行转义,服务器收到后再通过urldecode(URL 解码)还原原始数据。
编码规则
URL 编码的核心是将非安全字符转换为%加两位十六进制数的形式,规则如下:
- 字母、数字和部分特殊字符(
-、_、.、*)无需编码。 - 空格通常编码为
+或%20(不同场景存在差异,如表单提交中为+,URL 路径中为%20)。 - 其他字符(如中文、
?、&、=、/等)按 UTF-8 编码为字节,再将每个字节转换为%XX形式。
示例
原始参数:name=张三&msg=hello world!编码后:name=%E5%BC%A0%E4%B8%89&msg=hello+world%21
- "张三" 的 UTF-8 编码为
E5 BC A0 E4 B8 89,因此编码为%E5%BC%A0%E4%B8%89。 - 空格编码为
+,感叹号!编码为%21。
在实际开发中,浏览器、HTTP 客户端库(如requests、curl)会自动完成 URL 编码,无需手动处理,但了解其原理有助于排查参数传递相关的问题(如中文乱码、特殊字符丢失)。
四、HTTP 协议请求与响应格式
HTTP 通信由 ** 请求(Request)和响应(Response)** 两部分组成,两者均遵循固定的文本格式,分为起始行、请求 / 响应头、空行、消息体(可选)四部分。
4.1HTTP请求
- 请求行 :格式为
方法 URL 协议版本,如GET /index.html HTTP/1.1。 - 请求头 :以键值对形式传递请求的附加信息,每行格式为
Key: Value,如Host: www.example.com、User-Agent: Mozilla/5.0。 - 空行 :用
\r\n表示,分隔请求头和请求体,是 HTTP 格式的必要组成部分。 - 请求体:仅部分方法(如 POST、PUT)存在,用于传递客户端向服务器发送的数据(如表单数据、JSON)。

基本前面学习的内容我们这里先架构处⼀个基本的HTTP服务器,然后用浏览器进行验证
cpp
//Http.hpp
#pragma once
#include "./LOG/TcpServer.hpp"
#include <memory>
#include "./LOG/Socket.hpp"
#include <string>
#include "./LOG/InetAddr.hpp"
#include "./LOG/util.hpp"
#include <iostream>
#include <sstream>
#include <unordered_map>
using namespace SocketModule;
using namespace cqwlog;
const std::string gspace = " ";
const std::string glinespace = "\r\n";
const std::string glinesep = ": ";
const std::string webroot = "./wwwroot";
const std::string homepage = "index.html";
class HttpRequest
{
public:
HttpRequest()
{
}
std::string Serialize()
{
return std::string();
}
bool Deserialize(std::string &reqstr)
{
return true;
}
~HttpRequest()
{
}
private:
std::string _method;
std::string _uri;
std::string _version;
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
};
class HttpResponse
{
public:
HttpResponse()
:_blankline(glinespace)
{
}
std::string Serialize()
{
std::string status_line = _version + gspace + std::to_string(_code) + gspace + _desc + glinespace;
std::string resp_header;
for (auto &header : _headers)
{
std::string line = header.first + glinesep + header.second + glinespace;
resp_header += line;
}
return status_line + resp_header + _blankline + _text;
}
bool Deserialize(std::string &reqstr)
{
return true;
}
~HttpResponse()
{
}
public:
std::string _version;
int _code; // 404
std::string _desc; // "Not Found"
std::unordered_map<std::string, std::string> _headers;
std::string _blankline;
std::string _text;
};
class Http
{
public:
Http(uint16_t port)
:tsvp(std::make_unique<TcpServer>(port))
{
}
void HandLerHttpRquest(std::shared_ptr<Socket> &sock, InetAddr &client)
{
#ifdef DEBUG
#define DEBUG
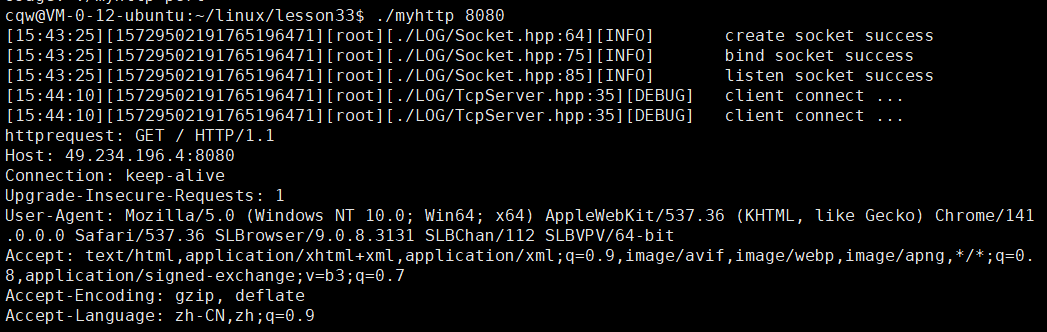
std::string httprequest;
sock->Recv(&httprequest);
std::cout << "httprequest: " << httprequest << std::endl;
HttpResponse resp;
resp._version = "HTTP/1.1";
resp._code = 200;
resp._desc = "OK";
resp._text = R"(<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Hello World</title>
</head>
<body>
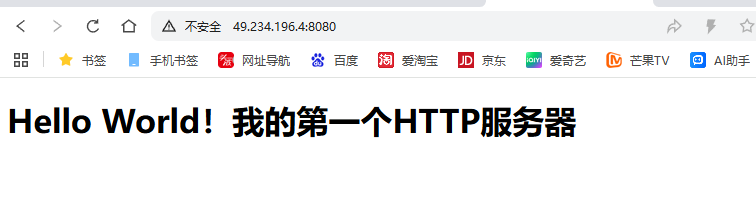
<h1>Hello World!我的第一个HTTP服务器</h1>
</body>
</html>
)";
std::string response_str = resp.Serialize();
sock->Send(response_str);
#endif
}
void Start()
{
tsvp->Start([this](std::shared_ptr<Socket> &sock, InetAddr &client){
this->HandLerHttpRquest(sock, client);
});
}
private:
std::unique_ptr<TcpServer> tsvp;
};
cpp
//Main.cc
#include "Http.hpp"
// http port
int main(int argc, char *argv[])
{
if(argc != 2)
{
std::cout << "Usage: " << argv[0] << " port" << std::endl;
exit(USAGE_ERR);
}
uint16_t port = std::stoi(argv[1]);
std::unique_ptr<Http> httpsvr = std::make_unique<Http>(port);
httpsvr->Start();
return 0;
}现象:
4.2补充URI
核心问题拆解:HTTP 请求怎么指定资源?服务器资源存在哪里?
1. 客户端(浏览器):用「URI 路径」告诉服务器 "我要什么"
浏览器发起 HTTP 请求时,会在请求行 里带上URI(统一资源标识符),格式是:
GET /a/b/c.html HTTP/1.1- 这里的
/a/b/c.html就是 URI,它是客户端请求的「逻辑资源路径」,不是服务器上的真实文件路径。 - 对应你浏览器地址栏的 URL:
http://IP:端口/a/b/c.html,/a/b/c.html就是 URI。
2. 服务器端:资源存在「Web 根目录(webroot)」里(核心误区纠正)
强调:资源不是存在 Linux 根目录,而是存在你给服务器指定的「Web 根目录」里,比如代码里的./wwwroot。
关键公式:真实文件路径 = webroot + URI 路径
服务器收到 URI 后,会把它和webroot拼接,得到文件的真实路径
为什么不能用 Linux 根目录?
如果把 webroot 设为/,客户端就能通过 URI 访问服务器上所有文件(比如/etc/passwd),会造成严重的安全问题(目录穿越攻击)。
3. 特殊情况:请求根路径/(首页)的处理
当客户端请求/(也就是访问根目录,比如http://IP:端口/),服务器不会直接去./wwwroot/目录找文件,而是会自动拼接默认首页文件名 (通常是index.html或index.htm):
真实文件路径 = webroot + '/' + index.html → ./wwwroot/index.html这就是我们平时说的 "网站首页",用户不用手动输入/index.html,服务器会自动帮你处理。
HTTP 请求的本质
HTTP 请求的本质,就是客户端请求服务器 Web 根目录(./wwwroot)下,和 URI 路径对应的文件资源。
完整流程:
- 浏览器发请求:
GET /a/b/c.html HTTP/1.1 - 服务器拿到 URI
/a/b/c.html,和webroot拼接,得到真实路径./wwwroot/a/b/c.html - 服务器去这个路径找文件:
- 找到文件:读取文件内容,放到 HTTP 响应的 body 里返回给客户端
- 找不到文件:返回
404 Not Found
- 浏览器收到响应,把 HTML/CSS/JS 内容渲染成网页
我们基于上面的知识再次修改我们的代码
4.3HTTP响应
- 响应行 :格式为
协议版本 状态码 状态描述,如HTTP/1.1 200 OK。 - 响应头 :以键值对形式传递服务器的附加信息,如
Content-Type: text/html、Server: Nginx/1.21.6。 - 空行:分隔响应头和响应体。
- 响应体:服务器返回给客户端的资源数据(如 HTML 页面、JSON 数据、文件内容)。

我们基于上面的知识再次修改我们的代码
五、HTTP 的方法
HTTP 方法(Method)定义了客户端对服务器资源的操作意图,是请求行的核心组成部分。RFC 标准定义了多种 HTTP 方法,其中最常用的是 GET 和 POST,其余方法在 RESTful API 设计中较为常见。
1. GET 方法(重点)
GET 是 HTTP 中最常用的方法,用于向服务器请求获取资源,核心特点如下:
- 语义:获取服务器上的指定资源(如页面、图片、接口数据)。
- 参数传递 :数据通过 URL 的查询参数传递(如
/api/user?id=123),数据会暴露在 URL 中,存在安全隐患。 - 无请求体:GET 请求通常不包含请求体,部分服务器支持但不推荐(HTTP 标准未禁止,但可能被代理服务器丢弃)。
- 可缓存:GET 请求的响应可被浏览器、代理服务器缓存,提升重复请求的性能。
- 幂等性:多次相同的 GET 请求,服务器返回的结果一致(副作用为 0,仅读取资源)。
应用场景:页面浏览、接口查询、静态资源加载(图片、CSS、JS)。
2. POST 方法(重点)
POST 方法用于向服务器提交数据,请求服务器处理(如创建、修改资源),是 API 接口中最常用的写操作方法,核心特点如下:
- 语义:向服务器提交数据,请求其进行处理(如提交表单、上传文件、创建数据)。
- 参数传递:数据通过请求体传递(如表单数据、JSON、XML),数据不会直接暴露在 URL 中,相对更安全。
- 有请求体 :POST 请求必须包含请求体,且请求头需通过
Content-Type指定数据格式(如application/x-www-form-urlencoded、application/json、multipart/form-data)。 - 不可缓存 :POST 请求的响应默认不被缓存(除非响应头明确设置
Cache-Control)。 - 非幂等性:多次相同的 POST 请求可能导致服务器状态变化(如重复提交订单会创建多个订单)。
应用场景:表单提交、用户注册、数据创建、文件上传、API 接口写操作。
GET vs POST 核心区别(校招高频考点)
表格
| 特性 | GET | POST |
|---|---|---|
| 语义 | 获取资源 | 提交数据 / 处理资源 |
| 参数位置 | URL 查询参数 | 请求体 |
| 数据长度限制 | 受 URL 长度限制(浏览器通常限制在 2KB~8KB) | 无理论长度限制(服务器可配置限制) |
| 安全性 | 数据暴露在 URL 中,不安全 | 数据在请求体中,相对安全(仍需 HTTPS 加密) |
| 缓存性 | 可缓存 | 默认不缓存 |
| 幂等性 | 幂等 | 非幂等 |
| 书签 / 历史记录 | 可被保存为书签、记录在历史中 | 不会被保存 |
3. PUT 方法(不常用)
PUT 方法用于向服务器上传资源,或替换指定 URL 的资源,核心特点:
- 语义:替换服务器上的指定资源(若资源不存在则创建,存在则覆盖)。
- 幂等性:多次相同的 PUT 请求结果一致(如重复上传同一文件,最终服务器上只有一份)。
- 应用场景:文件上传、资源全量更新(如 RESTful API 中更新用户信息)。
4. HEAD 方法
HEAD 方法与 GET 方法几乎完全相同,区别在于服务器仅返回响应头,不返回响应体,核心用途:
- 检查资源是否存在(如通过响应码判断资源是否存在,无需下载整个资源)。
- 获取资源的元信息(如文件大小、修改时间,通过
Content-Length、Last-Modified响应头)。 - 测试服务器是否正常响应(减少带宽消耗)。
5. DELETE 方法(不常用)
DELETE 方法用于请求服务器删除指定 URL 的资源,核心特点:
- 语义:删除服务器上的指定资源。
- 幂等性:多次相同的 DELETE 请求,资源最终会被删除(重复删除同一资源结果一致,如第一次删除成功,第二次返回 404)。
- 应用场景:RESTful API 中删除数据(如删除用户、删除订单)。
6. OPTIONS 方法
OPTIONS 方法用于查询服务器支持的 HTTP 方法,核心用途:
- 跨域预检请求(CORS)中,浏览器会先发送 OPTIONS 请求,询问服务器是否允许跨域请求,以及支持的方法、头信息。
- 服务器响应中通过
Allow头返回支持的方法列表(如Allow: GET, POST, PUT, DELETE)。
六、HTTP 的状态码
HTTP 状态码是服务器响应行中的三位数字,用于表示请求的处理结果,是客户端判断请求是否成功的核心依据。状态码分为 5 大类,校招中需重点掌握常见状态码的含义和场景:
表格
| 类别 | 范围 | 含义 | 常见状态码 |
|---|---|---|---|
| 1xx | 100-199 | 信息性状态码,表示请求已接收,需继续处理 | 100(Continue:客户端可继续发送请求体) |
| 2xx | 200-299 | 成功状态码,表示请求已被服务器成功处理 | 200(OK:请求成功)201(Created:资源创建成功,常用于 POST/PUT)204(No Content:请求成功但无响应体,常用于 DELETE) |
| 3xx | 300-399 | 重定向状态码,表示客户端需进一步操作以完成请求 | 301(Moved Permanently:永久重定向,资源已永久迁移)302(Found:临时重定向,资源临时迁移)304(Not Modified:资源未修改,可使用缓存副本) |
| 4xx | 400-499 | 客户端错误状态码,表示请求存在问题,服务器无法处理 | 400(Bad Request:请求格式错误)401(Unauthorized:未授权,需登录 / 认证)403(Forbidden:服务器拒绝访问,权限不足)404(Not Found:资源不存在)405(Method Not Allowed:请求方法不被服务器支持)409(Conflict:请求与服务器状态冲突,如重复创建资源) |
| 5xx | 500-599 | 服务器错误状态码,表示服务器处理请求时发生错误 | 500(Internal Server Error:服务器内部错误)502(Bad Gateway:网关错误,服务器作为代理时收到无效响应)503(Service Unavailable:服务器暂时不可用,如过载、维护)504(Gateway Timeout:网关超时,服务器未及时收到上游响应) |
校招高频考点:
- 区分 301 和 302 的区别(永久 vs 临时,浏览器是否缓存重定向)。
- 304 的使用场景(缓存机制,减少不必要的资源传输)。
- 401 和 403 的区别(未认证 vs 无权限)。
- 500 和 502 的区别(服务器自身错误 vs 网关 / 代理错误)。
七、HTTP 常见 Header
HTTP Header 是请求 / 响应中以键值对形式存在的附加信息,用于传递元数据、控制行为。校招和后端开发中,部分 Header 是高频考点,以下为核心 Header 分类及常见字段:
1. 通用 Header(请求和响应均可使用)
Connection:控制连接的持久化,常见值:keep-alive:开启长连接(HTTP/1.1 默认开启),TCP 连接可复用,减少握手开销。close:关闭长连接,请求完成后立即断开 TCP 连接。
Date:服务器生成响应的时间。Cache-Control:控制缓存行为,如no-cache(强制验证缓存)、max-age=3600(缓存有效期 1 小时)。
2. 请求 Header(客户端发送给服务器)
Host:请求的目标主机和端口(HTTP/1.1 强制要求,用于区分同一 IP 上的多个虚拟主机)。User-Agent:客户端的标识信息(如浏览器类型、版本、操作系统),服务器可根据该字段适配不同客户端的响应。Accept:客户端可接受的响应数据类型(如text/html、application/json),服务器据此返回合适格式的数据。Accept-Language:客户端可接受的语言(如zh-CN,zh;q=0.8),服务器据此返回本地化内容。Content-Type:请求体的数据格式(POST/PUT 请求必须设置),常见值:application/x-www-form-urlencoded:表单数据格式(默认)。application/json:JSON 格式数据(API 接口常用)。multipart/form-data:文件上传格式(支持二进制数据)。
Cookie:客户端存储的 Cookie 数据,随请求发送给服务器,用于会话保持。Authorization:认证信息(如 Bearer Token、Basic Auth),用于 API 接口的权限验证。
3. 响应 Header(服务器发送给客户端)
Server:服务器的软件信息(如Nginx/1.21.6、Apache/2.4.54)。Content-Type:响应体的数据格式,如text/html; charset=utf-8、application/json; charset=utf-8。Content-Length:响应体的长度(字节数),客户端据此判断数据是否接收完整。Set-Cookie:服务器向客户端设置 Cookie,格式为key=value; expires=xxx; path=/。Location:重定向的目标 URL(3xx 状态码时使用,如 301/302 响应中)。Access-Control-Allow-Origin:跨域资源共享(CORS)相关,指定允许访问的域名。
重点:Connection 报头详解
Connection是 HTTP/1.1 中控制连接复用的核心 Header,直接影响性能:
- HTTP/1.0 时代:默认短连接,每个请求都需建立 TCP 连接,响应完成后立即断开,频繁请求会导致大量 TCP 握手开销。
- HTTP/1.1 时代 :默认开启
Connection: keep-alive,TCP 连接可被复用,同一连接可发送多个请求 - 响应,减少握手次数和延迟。 - 长连接的工作机制 :服务器会设置超时时间(如 Nginx 的
keepalive_timeout),若连接在超时时间内无请求,服务器会主动断开连接,避免资源浪费。 - 手动关闭长连接 :客户端可在请求头中设置
Connection: close,强制服务器在响应完成后断开连接。
八、重点学习
8.1PC 互联网时代「浏览器大战」脉络
- 时代背景:PC 上网时代,浏览器是互联网流量入口 用户想要上网必须打开浏览器,浏览器是所有互联网流量的第一道关口,绑定广告、生态、流量变现,所以浏览器距离商业利益极近。
- IE 靠微软预装垄断早期市场 微软在 Windows 系统里预装 IE 浏览器(系统捆绑软件),免费绑定装机,靠着系统装机量干掉了网景 Netscape,拿下早期浏览器市场主导权。
- 利益催生浏览器技术割据 巨大商业利益下,各家厂商闭门自研私有内核(IE、火狐、Safari),各自私有技术、标准不统一、互不兼容,行业混战(浏览器大战)。
- Chrome 凭开源破局 Chrome 依托开源 Chromium 项目免费开放内核,慢慢迭代优化,最终成为如今全球主流浏览器,现在绝大多数浏览器都是基于 Chrome 开源内核二次开发。
8.2GET 和 POST 核心区别
1.GET
- 用途:获取静态网页、图片、css/js 这类资源(查询数据,不修改服务器数据)
- 传参方式:参数拼接在URL (URI) 末尾,浏览器地址栏明文可见
- 限制:URL 长度受浏览器 / 服务器限制,不能传递超大数据
2.POST
- 用途:提交表单数据(登录、注册、上传文件),修改服务器资源
- 传参方式:参数放在HTTP 请求正文 Body,不在 URL 里,地址栏看不到参数
- 优势:没有 URL 长度限制,可以传输大容量数据(文件、长表单)
误区重点:
POST 只是不在地址栏显示参数,不代表加密安全,GET/POST 的 HTTP 报文全是明文,抓包软件都能扒出参数。
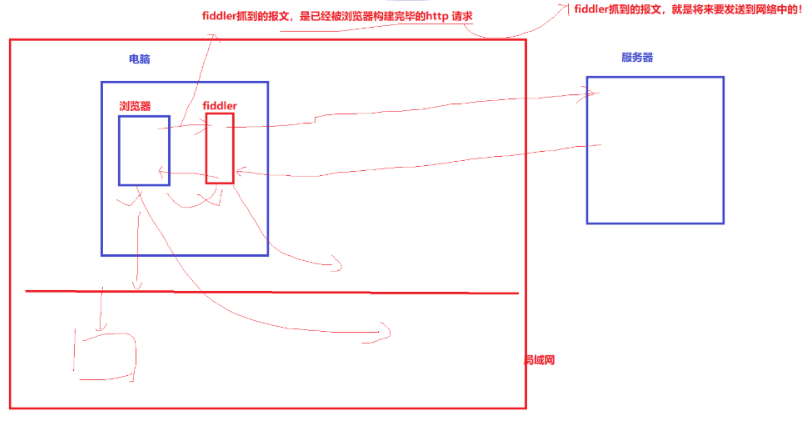
8.3Fiddler 抓包原理
- Fiddler 本质是 HTTP 代理 :浏览器设置代理指向 Fiddler,数据流路径:
浏览器 → Fiddler抓包工具 → 公网 → 目标服务器 - 图里关键:Fiddler 抓到的报文 = 浏览器组装完毕、马上要发往网络的原始 HTTP 数据浏览器拼完完整 HTTP 请求,先丢给 Fiddler,Fiddler 留存副本(抓包),再把原报文转发给服务器;服务器响应原路返回,Fiddler 同样捕获响应报文。
- 结论:HTTP 全明文传输,局域网 / 传输链路都能抓包窃取账号、密码、表单数据。
8.4HTTP 不安全 → HTTPS 加密(后面有详谈)
- 问题:原生 HTTP 无论 GET/POST 都是明文裸奔,Fiddler/Wireshark 抓包直接查看全部报文内容,账号密码极易泄露。
- 解决方案:HTTPS 协议 在 HTTP 与 TCP 之间嵌套 SSL/TLS 加密层,所有请求 / 响应报文全部加密传输,就算被抓包,抓包软件只能拿到密文乱码,无法解析明文数据,实现传输安全。
精简总结
- GET 拼 URL 传参、适合查资源;POST 放 Body 传参、适合提交大数据;二者 HTTP 下都明文、都不安全。
- Fiddler 靠代理劫持浏览器全部 HTTP 明文数据,直观证明 HTTP 裸奔漏洞。
- 想要传输安全,必须用 HTTPS 对整段报文加密。
8.5HTTP 两种重定向
8.5.1客户端驱动的 3xx 重定向(外部跳转)
这是 HTTP 标准定义的重定向机制,由服务器返回3xx 状态码 和Location 响应头,浏览器自动发起新请求到新地址MDN Web Docs。
1. 核心原理
浏览器 → 服务器请求旧URL → 服务器返回3xx + Location: 新URL → 浏览器自动请求新URL → 服务器返回新资源- 浏览器地址栏会改变为新 URL
- 产生两次完整 HTTP 请求(客户端 - 服务器往返)
- 属于跨 URL / 跨站点跳转,可指向外部域名
2. 常见 3xx 状态码分类与应用场景
| 状态码 | 名称 | 语义 | 典型场景 | 浏览器 / SEO 行为 |
|---|---|---|---|---|
| 301 | Moved Permanently | 永久重定向 | 域名迁移、页面永久删除 | 浏览器缓存新 URL,搜索引擎转移权重 |
| 302 | Found | 临时重定向 | 维护期间临时跳转、A/B 测试 | 不缓存,每次请求都查原 URL |
| 303 | See Other | 临时重定向(强制 GET) | POST 提交后跳转结果页 | 无论原方法,新请求用 GETW3C |
| 307 | Temporary Redirect | 临时重定向(保留方法) | API 临时迁移 | 严格保留原 HTTP 方法 |
| 308 | Permanent Redirect | 永久重定向(保留方法) | API 永久迁移 | 严格保留原 HTTP 方法 |
3. 实现示例(C++ 伪代码)
void MakeRedirectResponse(HttpResponse& res, const string& newUrl, int code = 302) {
res.SetCode(code); // 设置3xx状态码
res.SetHeader("Location", newUrl); // 告诉浏览器新地址
res.SetBody("Redirecting to " + newUrl); // 可选提示文本
res._version = "HTTP/1.1"; // 确保HTTP版本正确设置
}8.5.2服务器内部的 404 资源替换(内部重定向)
这是你MakeResponse函数正在实现的逻辑:不触发浏览器跳转,仅在服务器内部替换响应内容,属于 "伪重定向" 或 "资源映射"。
1. 核心原理
浏览器 → 服务器请求不存在的URL → 服务器读取失败 → 服务器返回404状态码 + 自定义404.html内容 → 浏览器显示自定义页面- 浏览器地址栏保持不变(仍显示原错误 URL)
- 仅产生一次 HTTP 请求(无额外往返)
- 属于站内资源替换,只能指向服务器本地文件
2. 关键特性与价值
- 用户体验优化:避免浏览器默认空白 404 错误页,提供友好引导
- 品牌一致性:保持网站视觉风格,增强用户信任
- SEO 友好:正确返回 404 状态码,告知搜索引擎资源不存在,避免误判
- 服务器可控:完全在服务端处理,不依赖客户端行为
3. 代码中MakeResponse实现逻辑
HttpResponse HttpResponse::MakeResponse(const string& path) {
HttpResponse res;
string content;
// 1. 尝试读取请求文件
if (!ReadFileContent(path, content)) {
// 2. 读取失败 → 触发404内部重定向
res.SetCode(404); // 关键:必须设置404状态码
ReadFileContent("wwwroot/404.html", content); // 读取自定义404页面
} else {
res.SetCode(200);
}
// 3. 组装响应
res.SetBody(content);
res.SetHeader("Content-Length", to_string(content.size()));
res._version = "HTTP/1.1"; // 务必设置正确的HTTP版本
return res;
}8.5.3两种重定向的核心区别对比表
| 对比维度 | 3xx 客户端重定向 | 404 服务器内部重定向 |
|---|---|---|
| 状态码 | 301/302/303/307/308 | 404 Not Found |
| Location 头 | 必须提供(指向新 URL) | 不需要 |
| 地址栏变化 | 会改变为新 URL | 保持原 URL 不变 |
| 请求次数 | 两次(原请求 + 新请求) | 一次 |
| 跳转范围 | 可跨域 / 跨站点 | 仅限服务器内部资源 |
| 浏览器行为 | 自动发起新请求 | 仅显示响应内容,无跳转 |
| 典型场景 | 域名迁移、页面搬家 | 自定义 404 错误页面 |
| 实现位置 | 服务器响应阶段触发客户端行为 | 服务器内部资源替换 |
8.5.4总结
HTTP 的两种重定向解决不同问题:
- 3xx 客户端重定向:解决 "资源不在此地址,去新地址找" 的问题,是跨 URL 的导航机制
- 404 服务器内部重定向:解决 "资源不存在,提供友好替代内容" 的问题,是站内体验优化手段
8.6长短连接(短连接 HTTP/1.0、长连接 HTTP/1.1)
1. 短连接:HTTP/1.0 默认(Connection: close)
TCP建立连接 → 1次HTTP请求+响应 → TCP立刻关闭
一张网页多个资源(html + 多张图片)就要重复 N 次 TCP 握手 + 断开 。例:页面 1 个 html+3 张图片 → 4 次 TCP 连接、4 次请求,板书:网页资源少、请求多、开销巨大,早期网速差特别浪费带宽。
- 请求头标识:Connection: close,服务器响应完立刻断套接字。
2. 长连接:HTTP/1.1 默认(Connection: keep-alive)
流程
只建立 1 次 TCP 连接,在一条链路里连续收发多次 Request/Response,空闲超时后才断开。
- 客户端请求头带Connection: keep-alive,服务器识别后开启长连接,同一条 TCP 通道持续处理后续浏览器自动发起的资源请求;
- 优势:省去反复三次握手 / 四次挥手开销,网页多资源只用 1 条 TCP,大幅提升加载速度(板书:当年网络差,长连接是重大优化);
- 关闭:客户端主动**
Connection:close**或服务器超时闲置自动断开。
关键细节
- HTTP1.1 默认长连接,不用手动加 keep-alive 也生效;
- 长连接必须依靠
Content-Length:用来标记单条响应体字节大小,服务端读完一个完整报文再处理下一个请求(对应你代码:必须读到完整请求报文再解析,不能半截解析)
8.7Cookie & Session
1. Cookie 是什么
HTTP 是无状态协议:服务器每次收到请求,默认不知道 "这个客户端之前是谁、登没登录",所以诞生 Cookie 做会话标记。
Cookie 工作流程
- 用户首次登录(账号密码提交 POST),服务器验证成功,在响应头添加
Set-Cookie: key=value,下发给浏览器; - 浏览器收到 Set-Cookie,本地磁盘 / 内存保存 cookie 文件;
- 之后每次访问同域名网站,浏览器自动在请求头带上
Cookie: xxx=xxx,服务器读取 cookie 识别用户身份,免重复登录。
❌ Cookie 致命缺点
Cookie明文存在浏览器本地:
- 木马、恶意程序可以直接窃取本地 Cookie 文件,拿到账号密码;
- HTTP 明文抓包(Fiddler)能直接抓取请求头里的 Cookie 数据,泄露隐私。
2. Session:弥补 Cookie 安全缺陷(服务端存数据)
核心思想:
用户隐私数据(账号、密码)全部保存在服务器内存 / 文件里,浏览器只存一串随机唯一的 SessionID(一串乱码字符串)。
- 用户首次登录成功 → 服务端生成唯一
session_id=随机串,用户信息绑定这个 ID 存在服务端; - 响应头
Set-Cookie:sessionid=xxxx,浏览器只在 Cookie 存这个无意义随机 ID; - 后续请求浏览器自动带
Cookie:sessionid=xxx,服务器拿 ID 去服务端查表,找到对应用户信息。
✅ 安全优势
就算 Cookie 被窃取,黑客只拿到一串 sessionid:
- 黑客拿 sessionid 只能临时冒用登录;
- 用户隐私(账号密码)全程存在服务器,不在客户端落地,不会泄露原始密码;
- 服务器可主动销毁 session(用户退出、超时过期),立刻作废登录权限。
3. Cookie 与 Session 关系总结
- Cookie 是客户端存储方案(不安全),Session 是服务端存储方案(安全);
- Session 依托 Cookie 实现:浏览器靠 Cookie 携带 session_id,是业界标准会话管理方案;
- 无 Cookie 浏览器(禁用 Cookie):URL 拼接 session_id 实现会话(备选方案)。
九、详谈https协议
9.1前言:为什么 HTTP 必须升级成 HTTPS?
原生 HTTP全明文传输,所有请求、账号密码、下载链接在网络链路(路由器、运营商、公共 WiFi)裸奔,带来两大致命风险:
- 数据被窃取:Fiddler/Wireshark 抓包就能拿到登录账号、支付密码;
- 内容被恶意篡改(运营商劫持):比如用户点击「天天动听 APP 下载」,运营商中途拦截 HTTP 响应,把下载链接偷偷替换成 QQ 浏览器安装包,用户被动下载无关软件牟利。
为解决明文漏洞,工程师先后迭代5 套加密方案,从纯对称→纯非对称→混合加密→引入 CA 证书,最终落地现在的 HTTPS(HTTP+SSL/TLS 加密层)。
在看 5 套方案前,先吃透三大密码学基础(HTTPS 底层基石)。
9.2前置三大密码基础知识
1. 对称加密(AES/DES)
同一个密钥,既能加密明文,又能解密密文,加密速度极快 。举例:明文1234 ^ 密钥8888= 密文;密文再次异或同一个密钥还原原文。
优点:运算高效,适合大批量网页数据加密;缺点:密钥如果明文传输,被截获直接全破。
2. 非对称加密(RSA)
成对密钥:公钥(Public)+ 私钥(Private)
- 公钥全网公开(像门外挂的锁,任何人可取);私钥服务器独自保管(唯一开锁钥匙);
- 公钥加密的数据,只能用对应私钥解密;私钥加密数据,仅能用公钥解密;
优点:密钥不用秘密传输,解决密钥分发难题;缺点:数学运算复杂,加密速度极慢,不适合整页 HTML 大数据加密。
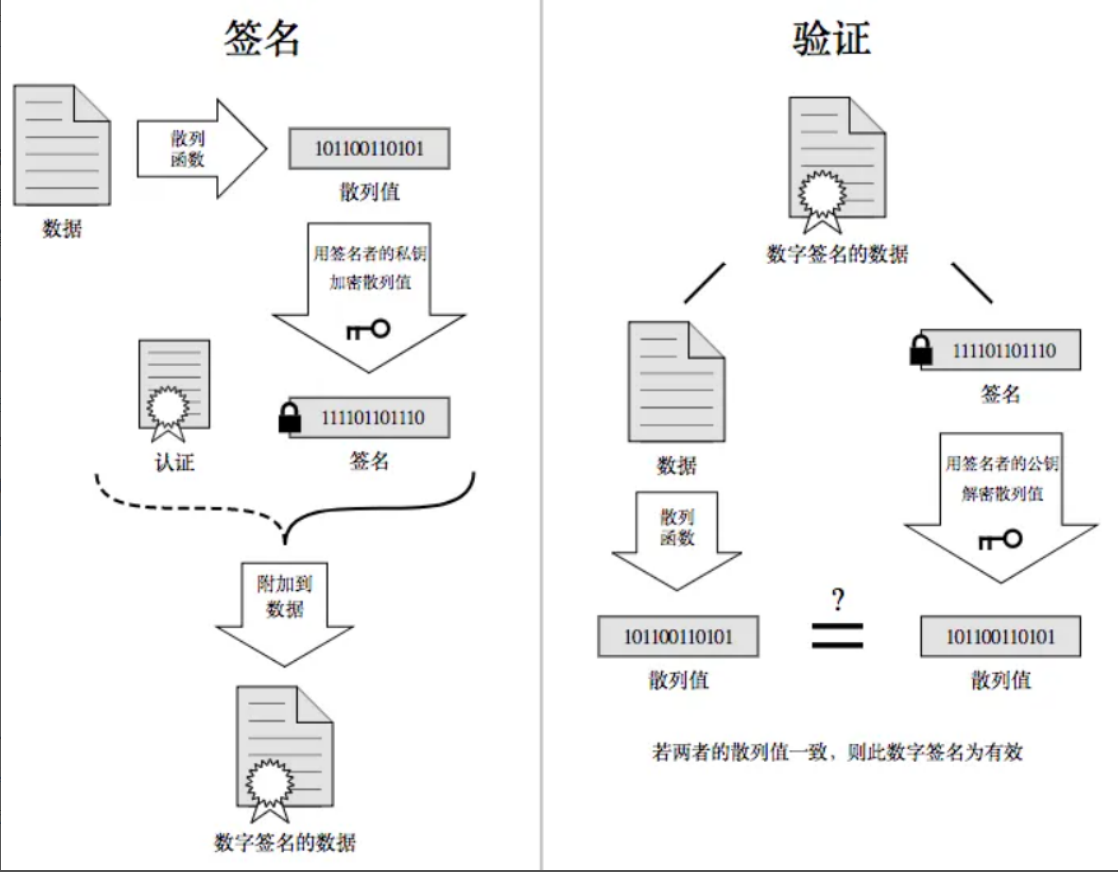
3. Hash 摘要 + 数字签名(MD5/SHA256)
- Hash:任意长度原文→固定长度摘要,原文改 1 个字符,摘要巨变、不可逆(不能通过摘要反推原文),用来校验文件是否被篡改;
- 数字签名:原文 Hash 生成摘要→CA 机构用自己私钥加密摘要 = 签名,和原文打包成证书,客户端用 CA 公钥解密签名,对比本地 Hash 值,不一致 = 内容被篡改。
9.3五大加密方案迭代(附 ASCII 流程图,由坑到最优)
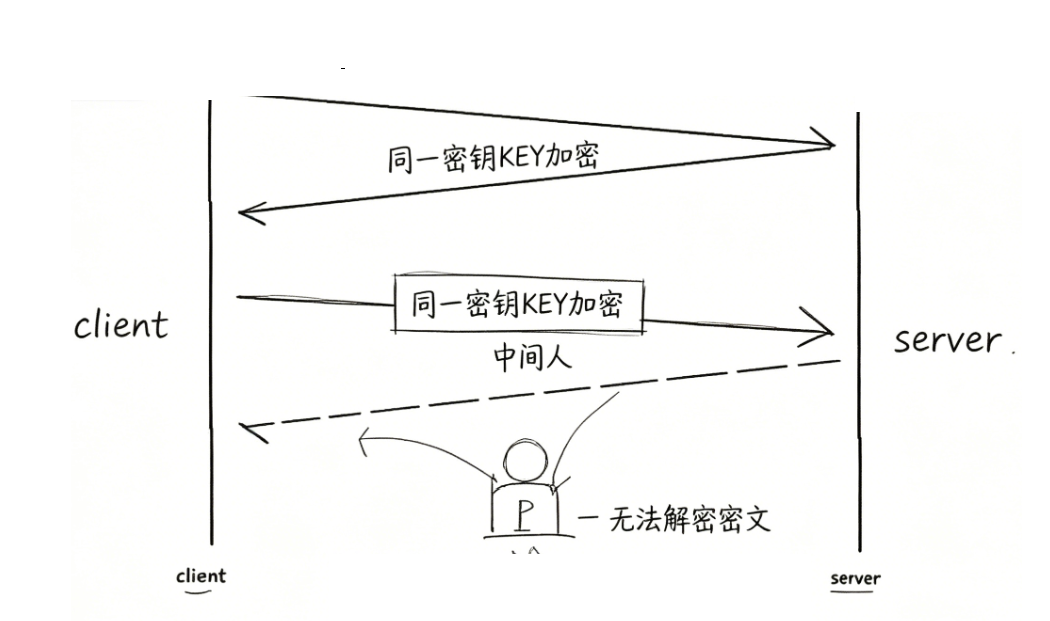
方案 1:仅使用【对称加密】
实现逻辑
客户端和服务器提前约定统一密钥,后续所有 HTTP 数据全部用 Key 加密传输,中间人抓到密文无密钥无法解密。
致命缺点
- 密钥协商无解:首次通信如果明文传密钥,中间人截获密钥,后续加密全部作废;
- 海量客户端难维护 :服务器对接成千上万个用户,每个客户端不能共用同一个密钥(密钥极易泄露),需要为每个用户单独生成、存储密钥,运维成本爆炸。
- 但是如果直接把密钥明文传输,那么⿊客也就能获得密钥了,此时后续的加密操作就形同虚设了。因此密钥的传输也必须加密传输!但是要想对密钥进行对称加密,就仍然需要先协商确定⼀个"密钥的密钥"。这就成了"先有鸡还是先有蛋"的问题了。此时密钥的传输再用对称加密就行不通了。
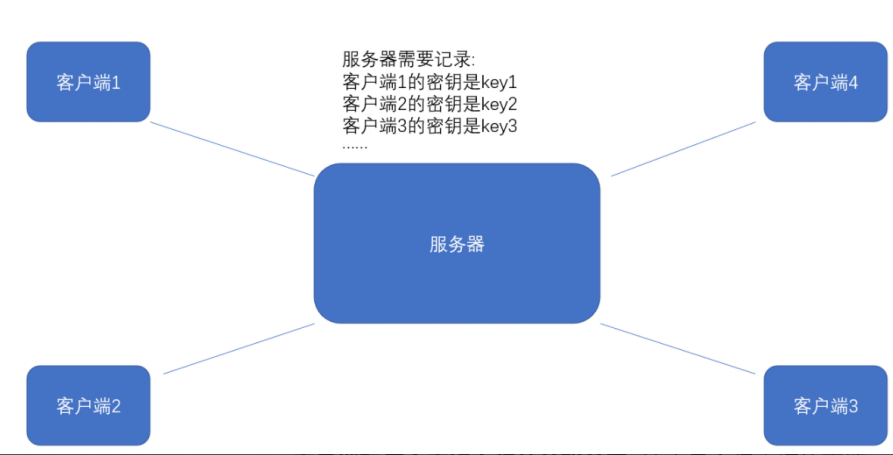
结论:方案 1 无法落地商用。
方案 2:仅单向非对称加密(服务端独有公私钥)
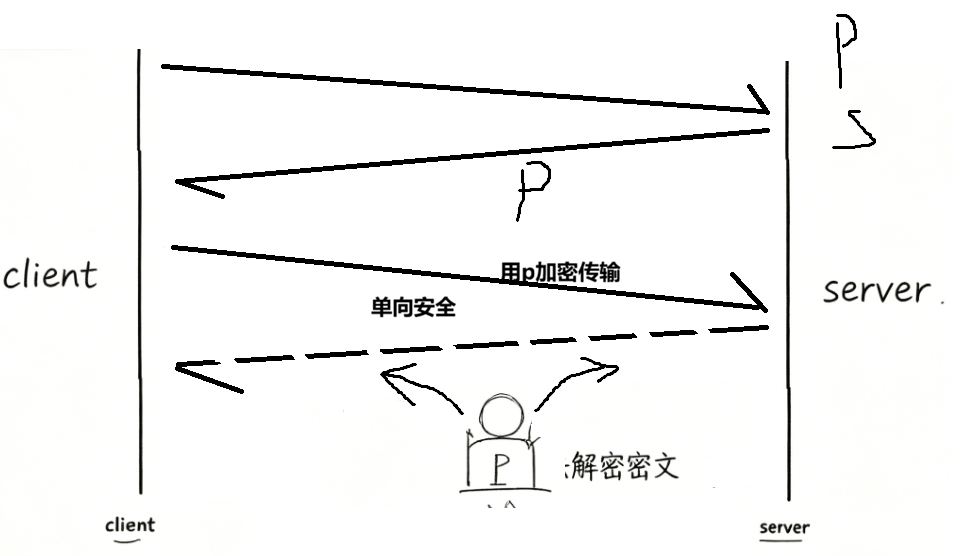
实现逻辑
- 服务器生成
公钥S、私钥S',公钥明文发给所有客户端; - 客户端发请求:用公钥 S 加密,中间人拿到密文无私钥无法解密;
- 服务器私钥解密后返回明文网页数据。
致命缺点
下行响应全程明文! 服务器回传给客户端的 HTML、数据没加密,中间人直接抓取响应内容,请求安全但响应裸奔。
结论:单向非对称只保上行,下行不安全。
方案 3:客户端 + 服务端双向非对称加密
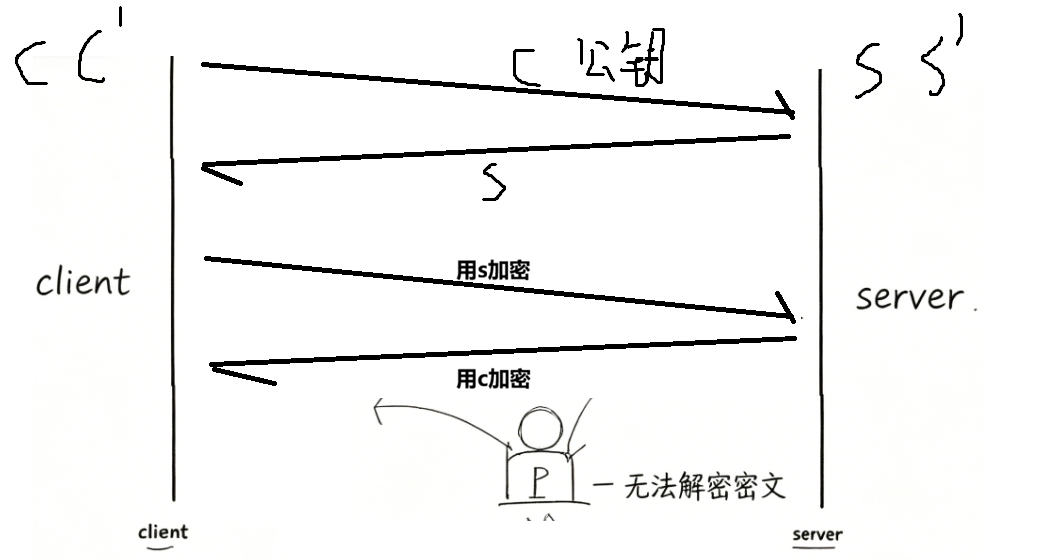
实现逻辑
客户端、服务器各自生成一套 RSA 密钥,通信前明文互换公钥,发数据时统一用对方公钥加密。
两大硬伤
- 性能崩盘:非对称加密运算极慢,整个网页 HTML、图片全用 RSA 加密,页面加载卡顿;
- 中间人仍可劫持公钥:交换公钥阶段中间人替换公钥,后续数据全部可控。
结论:安全勉强达标,但性能完全不适合网页场景。
方案 4:非对称 + 对称混合加密(HTTPS 雏形,仍有中间人漏洞)

实现逻辑(HTTPS 主流思路沿用至今)
- 握手阶段只用非对称:客户端随机生成一次性会话密钥 R,用服务器公钥加密后传输,保证 R 不会被中间人窃取;
- 业务传输全用对称加密:拿到 R 后,后续所有 HTTP 数据靠高效的对称加密传输,兼顾安全和性能。
致命漏洞:中间人劫持公钥(MITM 中间人攻击)
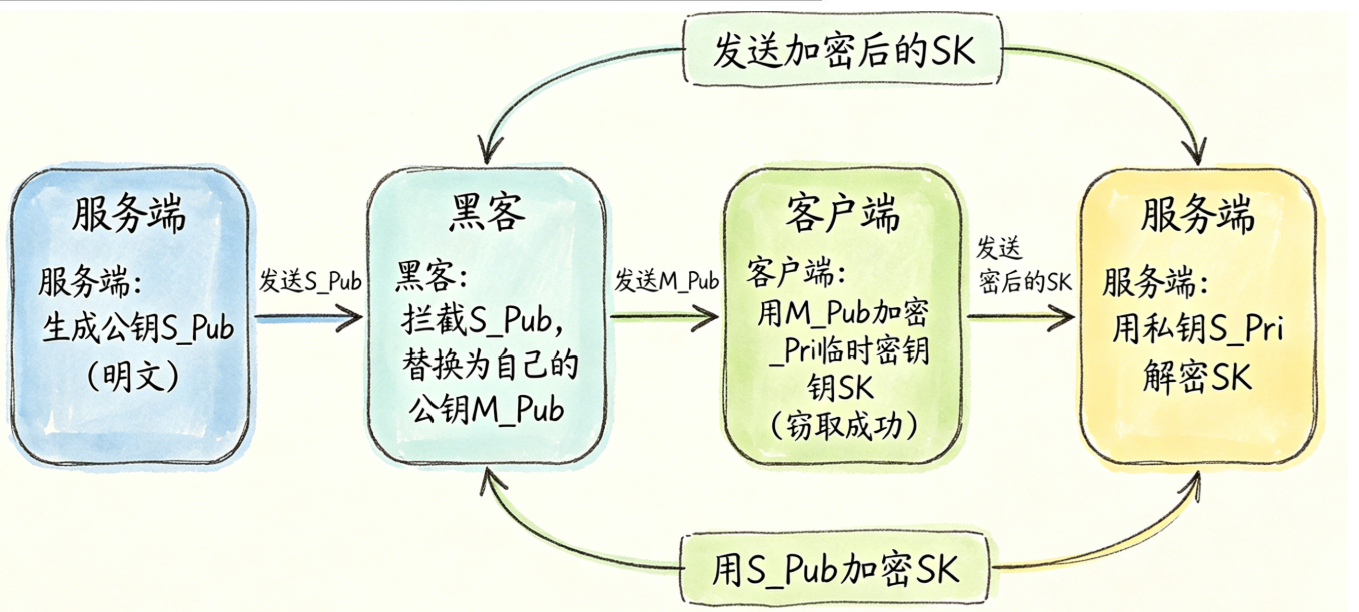
漏洞本质:客户端无法验证收到的公钥是不是目标网站的,中间人中途换掉公钥即可全量破密。
结论:混合加密解决性能,但缺少身份校验,防不住中间人掉包公钥。
方案 5:混合加密 + CA 数字证书(最终 HTTPS 正式方案,完美闭环)
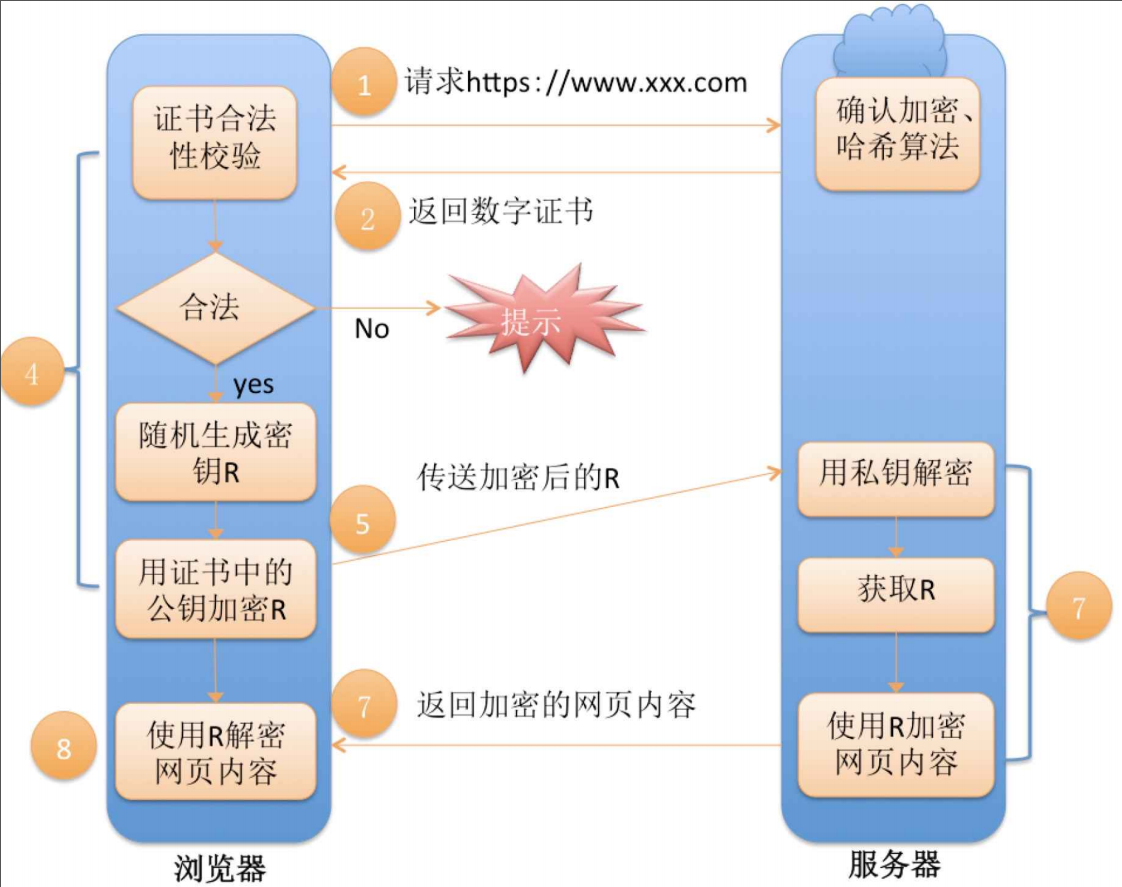
证书防篡改原理
- CA 机构持有自己专属私钥:给网站证书原文做 Hash,CA 私钥加密摘要 = 数字签名,打包进证书;
- 客户端操作系统 / 浏览器预装全球可信 CA 的公钥;
- 校验:客户端用 CA 公钥解密证书签名得到原始摘要,本地重新计算证书 Hash,两值一致 = 证书没被篡改;
- 中间人无法伪造合法证书:没有 CA 私钥,篡改证书后签名无法匹配,浏览器直接拒绝连接。
方案 5 优势
- 性能:业务数据对称加密,速度快;
- 安全:CA 证书杜绝公钥掉包,彻底防御中间人劫持,解决运营商 HTTP 篡改问题。
方案 5 = 现行标准 HTTPS 完整实现
9.4HTTPS 完整握手流程总结(三次密钥分工)
HTTPS 整个通信存在三组密钥,各司其职:
- CA 非对称密钥(验证书):操作系统内置 CA 公钥,校验服务器证书真伪,保证网站公钥可信;
- 网站非对称密钥(协商会话密钥):服务器公私钥,加密传输客户端随机生成的临时对称密钥 R;
- 临时会话对称密钥 R(业务加密):全量 HTTP 请求 / 响应数据加密,HTTPS 真正的数据加密钥匙。
9.5延伸:浏览器小细节
- 地址栏绿色小锁 = HTTPS 证书校验成功;红色警告 = 证书过期 / 伪造;
- Fiddler 抓 HTTPS 需要手动安装根证书:安装后 Fiddler 变成可信 CA,才能解密 HTTPS 报文(中间人合法落地场景);
- 80 端口 = HTTP,443 端口 = HTTPS。
9.6结尾总结
HTTPS 不是凭空设计,是工程师从「对称→非对称→混合→CA 证书」踩坑迭代 5 套方案后的最优解:
- 对称负责大数据加密(效率);
- 非对称负责安全分发会话密钥(防密钥明文泄露);
- CA 证书负责身份认证(防中间人替换公钥)。
一句话记 HTTPS:CA 验身份,非对称传密钥,对称传数据 。