Redis 哨兵模式:给 Redis 配上 7x24 小时的值班保安
主从复制只是让 Redis 有了备胎,但备胎转正需要有人来决策------哨兵就是那个发号施令的人
上期我们聊了主从复制,你已经学会了如何让一台 Redis Master 带着一群小弟(Slave)干活。但你有没有想过一个问题:万一 Master 挂了怎么办?
bash
# 凌晨 3 点,Master 突然宕机
# 所有写请求全部失败
# 你必须手动执行:
redis-cli -p 6380 REPLICAOF NO ONE # 把 Slave 提升为 Master
# 然后修改所有应用的配置,指向新的 Master
# 整个过程可能需要 10-30 分钟在互联网时代,10 分钟的不可用 = 巨额损失 + 用户流失。
哨兵(Sentinel) 就是为了解决这个问题而生的------它能自动 完成故障检测、选举新 Master、通知客户端,整个过程在秒级完成。
一、 哨兵是什么?
1.1 一句话定义
哨兵是 Redis 官方提供的高可用解决方案:它是一个独立运行的进程,负责监控 Redis 主从集群的健康状况,并在 Master 故障时自动完成故障转移(Failover)。
1.2 哨兵能做什么?
| 功能 | 说明 |
|---|---|
| 监控 | 定时检查 Master 和 Slave 是否存活 |
| 通知 | 节点宕机时,通过 API 通知系统管理员或其他程序 |
| 自动故障转移 | Master 挂了,自动把某个 Slave 提升为新 Master,其他 Slave 指向新 Master |
| 配置中心 | 客户端连接哨兵,哨兵告诉你当前 Master 是谁(客户端不需要硬编码 IP) |
1.3 架构图
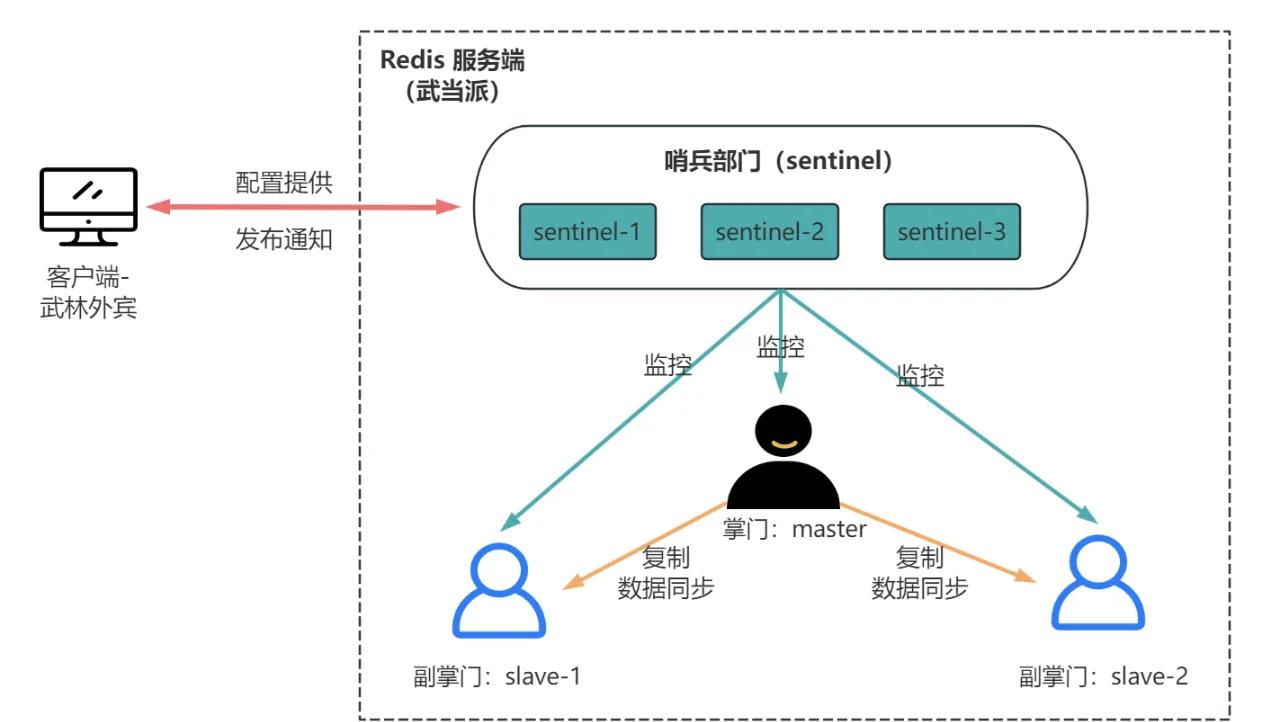
核心要点:
- 哨兵至少 3 个(且奇数个),防止"脑裂"
- 哨兵和 Redis 节点可以部署在同一台机器,但建议分开
- 哨兵集群互相通信,共同决策
二、 哨兵的三个核心任务
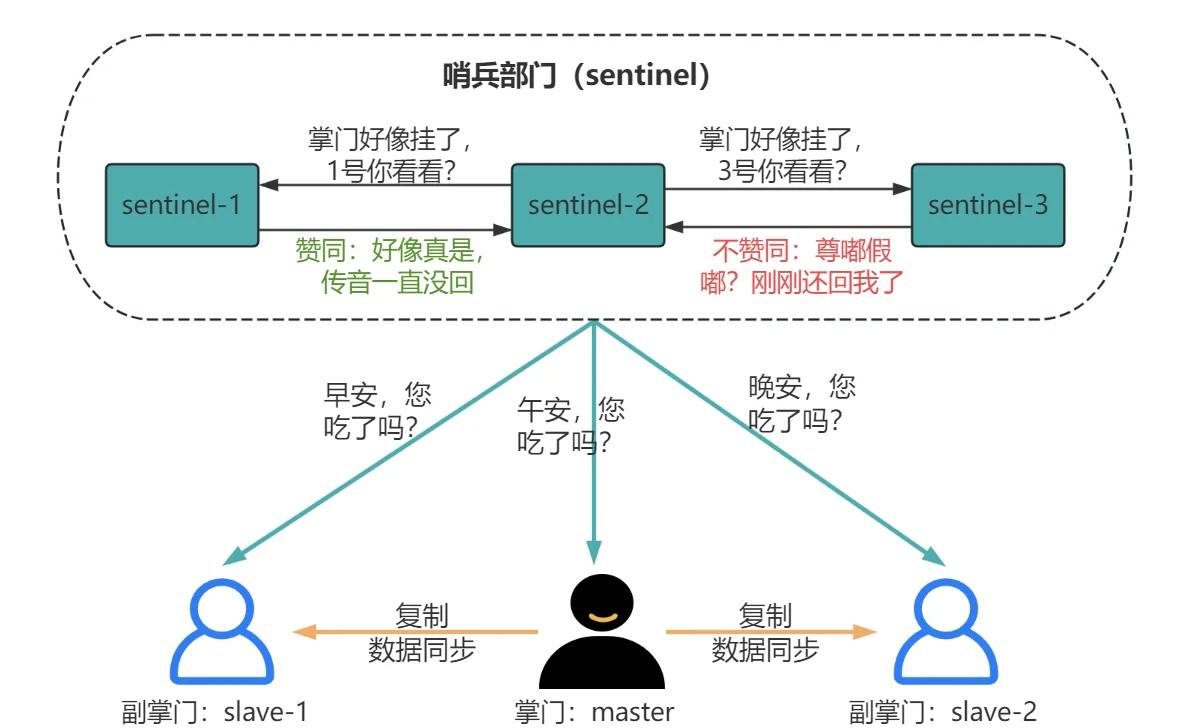
2.1 监控:心跳检测 + 主观下线
哨兵每隔 1 秒向 Master、Slave、其他 Sentinel 发送 PING 命令。
bash
# 哨兵内部执行(你不需要手动敲)
PING <redis_instance>- 如果 PONG 回复正常 → 节点在线
- 如果超过
down-after-milliseconds(默认 30 秒)没收到回复 → 标记为 SDOWN(主观下线)
主观下线(Subjective Down,SDOWN):一个哨兵觉得某个节点挂了。
2.2 确认:客观下线
单个哨兵认为 Master 挂了不够,因为可能只是网络问题(该哨兵自己网络不通)。
当足够多 的哨兵(达到 quorum 数量)都认为 Master 挂了,就会标记为 ODOWN(客观下线)。
客观下线条件
Sentinel1: "Master 好像挂了" → 投票给 ODOWN
Sentinel2: "Master 确实挂了" → 投票给 ODOWN
Sentinel3: "Master 还活着" → 不投票
quorum = 2 → 达到 2 票 → 触发客观下线
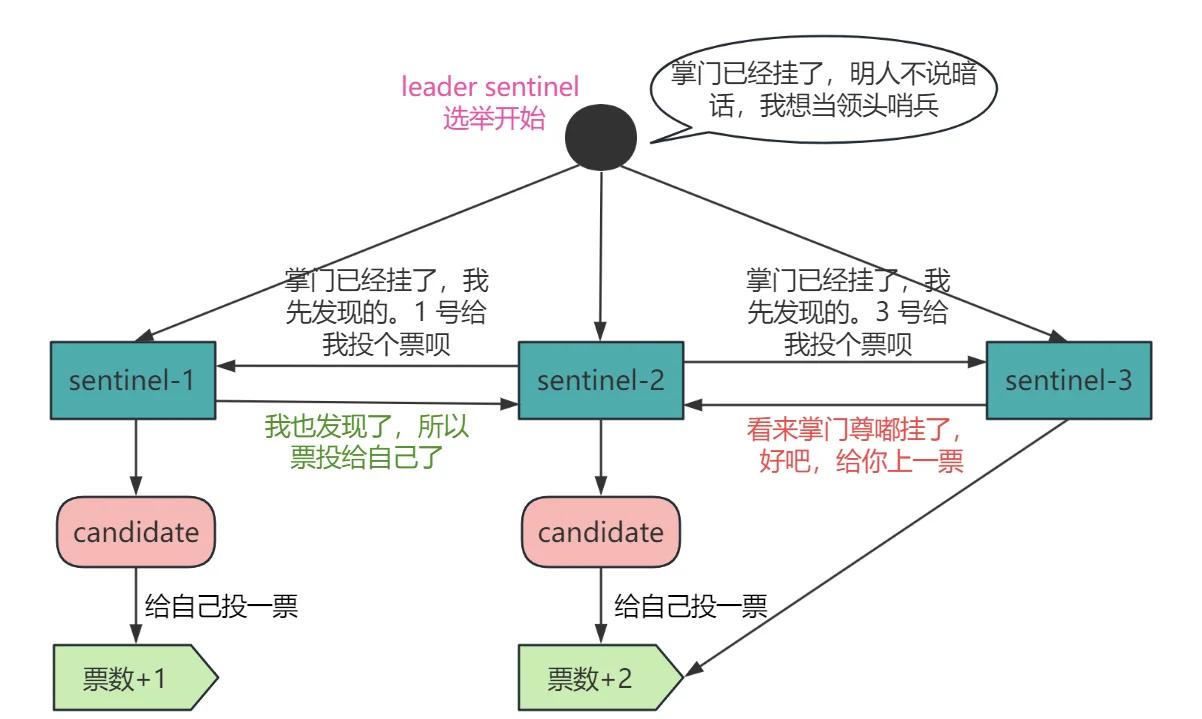
2.3 故障转移:选举新 Master
当 Master 被标记为 ODOWN 后,哨兵集群开始选举领导者(Leader Sentinel),由领导者执行故障转移。
2.3.1 领导者选举(Raft 算法变种)
bash
# 每个 Sentinel 都可以发起选举请求
# 获得半数以上(并且 >= quorum)投票的 Sentinel 成为 Leader为什么哨兵需要奇数个:3 个哨兵,最多挂 1 个仍能正常工作;2 个哨兵,挂 1 个就选不出 Leader。
2.3.2 选哪个 Slave 当新 Master?
Leader Sentinel 从所有 Slave 中筛选:
筛选条件:
- 在线的 Slave
- 排除超过
down-after-milliseconds * 10没响应的(网络太差) - 排除优先级
replica-priority = 0的(永不被选为 Master)
打分排序 (分数越高越优先):
-
优先级 (
replica-priority,值越小越优先,默认 100) -
复制偏移量 (offset 越大,数据越新,越优先)
-
Run ID(如果前面都一样,选 Run ID 最小的)
yaml
# 示例
Slave1: replica-priority=100, offset=50000
Slave2: replica-priority=90, offset=48000 # 优先级更高,当选
Slave3: replica-priority=100, offset=51000 # 数据更新,当选2.3.3 执行故障转移
Leader Sentinel 执行以下操作:
bash
# 1. 把选中的 Slave 提升为 Master
redis-cli -p 6380 REPLICAOF NO ONE
# 2. 让其他 Slave 指向新 Master
redis-cli -p 6381 REPLICAOF new_master_ip 6379
# 3. 更新哨兵配置
# 4. 通知客户端 Master 已变更整个过程耗时:通常 10-30 秒。
三、 环境搭建:3 个哨兵 + 1 主 2 从
3.1 架构规划
| 角色 | IP | 端口 | 说明 |
|---|---|---|---|
| Master | 127.0.0.1 | 6379 | 主节点 |
| Slave1 | 127.0.0.1 | 6380 | 从节点 |
| Slave2 | 127.0.0.1 | 6381 | 从节点 |
| Sentinel1 | 127.0.0.1 | 26379 | 哨兵 1 |
| Sentinel2 | 127.0.0.1 | 26380 | 哨兵 2 |
| Sentinel3 | 127.0.0.1 | 26381 | 哨兵 3 |
3.2 配置 Redis 主从(回顾)
conf
# redis-6379.conf(Master)
port 6379
daemonize yes
pidfile /var/run/redis-6379.pid
logfile /var/log/redis-6379.log
dir /var/lib/redis-6379
requirepass master_password
masterauth master_password
conf
# redis-6380.conf(Slave1)
port 6380
daemonize yes
pidfile /var/run/redis-6380.pid
logfile /var/log/redis-6380.log
dir /var/lib/redis-6380
requirepass master_password
masterauth master_password
replicaof 127.0.0.1 6379
conf
# redis-6381.conf(Slave2)
port 6381
daemonize yes
pidfile /var/run/redis-6381.pid
logfile /var/log/redis-6381.log
dir /var/lib/redis-6381
requirepass master_password
masterauth master_password
replicaof 127.0.0.1 63793.3 配置哨兵
创建 sentinel-26379.conf:
conf
# 哨兵监听端口
port 26379
daemonize yes
pidfile /var/run/sentinel-26379.pid
logfile /var/log/sentinel-26379.log
dir /var/lib/sentinel-26379
# 监控 Master(名字:mymaster,IP:端口,quorum:2)
# quorum = 2 表示至少 2 个哨兵同意,才标记客观下线
sentinel monitor mymaster 127.0.0.1 6379 2
# Master 密码
sentinel auth-pass mymaster master_password
# 主观下线时间(毫秒,默认 30 秒)
sentinel down-after-milliseconds mymaster 30000
# 故障转移超时(默认 3 分钟)
sentinel failover-timeout mymaster 180000
# 同时有多少个 Slave 同步新 Master(1 = 串行,降低压力)
sentinel parallel-syncs mymaster 1同样配置 sentinel-26380.conf 和 sentinel-26381.conf(只改端口)。
3.4 启动集群
bash
# 1. 启动 Redis 实例
redis-server redis-6379.conf
redis-server redis-6380.conf
redis-server redis-6381.conf
# 2. 启动哨兵(两种方式)
redis-sentinel sentinel-26379.conf
# 或者
redis-server sentinel-26379.conf --sentinel
# 3. 检查哨兵状态
redis-cli -p 26379 INFO Sentinel输出示例:
bash
# Sentinel
sentinel_masters:1
sentinel_tilt:0
sentinel_running_scripts:0
sentinel_scripts_queue_length:0
sentinel_simulate_failure_flags:0
master0:name=mymaster,status=ok,address=127.0.0.1:6379,slaves=2,sentinels=33.5 测试故障转移
bash
# 1. 模拟 Master 宕机
redis-cli -p 6379 DEBUG SLEEP 60 # 或者直接 kill
# 2. 观察哨兵日志(tail -f /var/log/sentinel-26379.log)
# 你会看到类似输出:
# +sdown master mymaster 127.0.0.1 6379
# +odown master mymaster 127.0.0.1 6379 #quorum 2/2
# +new-epoch 1
# +try-failover master mymaster 127.0.0.1 6379
# +vote-for-leader <哨兵 ID> 1
# +elected-leader master mymaster 127.0.0.1 6379
# +failover-state-select-slave master mymaster 127.0.0.1 6379
# +selected-slave slave 127.0.0.1:6380
# +failover-state-send-slaveof-noone slave 127.0.0.1:6380
# +failover-state-wait-promotion
# +promoted-slave slave 127.0.0.1:6380
# +failover-state-reconf-slaves
# +slave-reconf-sent slave 127.0.0.1:6381
# +slave-reconf-inprog slave 127.0.0.1:6381
# +slave-reconf-done slave 127.0.0.1:6381
# +failover-end master mymaster 127.0.0.1 6379
# 3. 检查新 Master(应该是 6380 或 6381)
redis-cli -p 6380 INFO replication
# 你会看到 role:master四、 核心配置参数详解
4.1 哨兵配置文件
conf
# 监控配置
sentinel monitor <master-name> <ip> <port> <quorum>
# quorum:至少多少个哨兵同意,才判定客观下线(不是选举所需的票数)
# 密码
sentinel auth-pass <master-name> <password>
# 主观下线时间(毫秒)
sentinel down-after-milliseconds <master-name> <milliseconds>
# 默认 30000(30 秒),网络不稳定可调大
# 故障转移超时(毫秒)
sentinel failover-timeout <master-name> <milliseconds>
# 默认 180000(3 分钟),超时后认为故障转移失败
# 并行同步数量
sentinel parallel-syncs <master-name> <num>
# 故障转移后,允许几个 Slave 同时同步新 Master
# 设置为 1 可避免网络 IO 飙升
# 通知脚本(故障转移时执行)
sentinel notification-script <master-name> <script-path>
# 客户端重新配置脚本(可选)
sentinel client-reconfig-script <master-name> <script-path>4.2 哨兵参数调优建议
| 场景 | down-after-milliseconds | failover-timeout | parallel-syncs |
|---|---|---|---|
| 内网高速稳定 | 10000(10 秒) | 60000(1 分钟) | 1 |
| 外网/跨国 | 60000(60 秒) | 180000(3 分钟) | 1 |
| 业务要求高可用 | 5000(5 秒) | 30000(30 秒) | 2 |
五、 哨兵的工作原理(深入)
5.1 三个定时任务
每个哨兵每秒钟执行以下任务:
任务 1:每 1 秒
向 Master、Slave、其他 Sentinel 发送 PING
任务 2:每 2 秒
通过 Master 的 sentinel :hello 频道广播自己的信息
内容:Sentinel IP、端口、Run ID、Master 配置版本号等
任务 3:每 10 秒
向所有 Slave 发送 INFO 命令,获取最新的 Slave 列表
5.2 主观下线 vs 客观下线
时间轴:
T0: Sentinel1 发送 PING → 无响应
T0+30s: 仍无响应 → 标记 SDOWN(主观下线)
T0+30s: Sentinel1 询问其他 Sentinel:"Master 挂了,你们觉得呢?"
Sentinel2: "我也没收到 PONG" → 同意
Sentinel3: "我的 PING 正常" → 不同意
T0+30s: 达到 quorum=2 → 标记 ODOWN(客观下线)
T0+30s: 开始故障转移
关键点:
- SDOWN 是单节点判断
- ODOWN 是集群共识,才触发故障转移
quorum可以设为小于哨兵数量,但不能大于哨兵数量
5.3 配置纪元(Configuration Epoch)
类似于 Raft 的 Term,每次故障转移都会递增。
初始状态:epoch = 0
第一次故障转移:epoch = 1
新的 Master 配置:epoch = 1 的配置
第二次故障转移:epoch = 2
新的 Master 配置:epoch = 2 的配置
作用:
- 哨兵通过 epoch 判断哪个配置是最新的
- 防止"脑裂":旧 Master 恢复后,发现自己的 epoch 落后,会自动降级为 Slave
六、 客户端连接哨兵
6.1 传统方式(硬编码 Master IP)------ 不推荐
python
# ❌ 错误做法
import redis
r = redis.Redis(host='192.168.1.100', port=6379, password='xxx')
r.set('key', 'value')
# Master 挂了就完了6.2 哨兵方式(客户端询问哨兵)------ 推荐
python
# ✅ 正确做法
from redis.sentinel import Sentinel
# 连接哨兵集群
sentinel = Sentinel([('127.0.0.1', 26379),
('127.0.0.1', 26380),
('127.0.0.1', 26381)],
sentinel_kwargs={'password': 'sentinel_password'})
# 获取 Master 连接(写操作)
master = sentinel.master_for('mymaster',
socket_timeout=0.1,
password='master_password')
# 获取 Slave 连接(读操作,轮询)
slave = sentinel.slave_for('mymaster',
socket_timeout=0.1,
password='master_password')
# 写
master.set('name', 'Redis Sentinel')
# 读
value = slave.get('name')
print(value)Java(Jedis)示例:
java
import redis.clients.jedis.JedisSentinelPool;
Set<String> sentinels = new HashSet<>();
sentinels.add("127.0.0.1:26379");
sentinels.add("127.0.0.1:26380");
sentinels.add("127.0.0.1:26381");
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels, "master_password");
try (Jedis jedis = pool.getResource()) {
jedis.set("name", "Redis Sentinel");
String value = jedis.get("name");
}
pool.close();七、 常见问题与解决方案
7.1 脑裂(Split-Brain)
场景:网络分区导致哨兵集群分裂,选出两个不同的 Master。
Redis 的防护:
- 哨兵使用多数派决策(至少 N/2+1 个节点同意)
- 旧 Master 恢复后,发现自己的 epoch 落后,自动降级为 Slave
虽然不会双写,但可能丢数据:旧 Master 恢复前的写操作,如果没同步到新 Master,会永久丢失。
解决方案 :配置 min-slaves-to-write:
conf
# 在 Master 上配置(实际需要在每个 Master 候选上配置)
min-slaves-to-write 1
min-slaves-max-lag 10
# 如果 Slave 数量 < 1 或延迟 > 10s,Master 拒绝写入7.2 哨兵数量为什么是奇数?
| 哨兵数量 | 最大故障数 | 能否正常工作 | 能否选举 |
|---|---|---|---|
| 1 | 0 | ❌ 挂一个全挂 | ❌ |
| 2 | 1 | ❌ 挂一个后剩 1 个,无法达到多数(需要 2 票) | ❌ |
| 3 | 1 | ✅ 挂一个剩 2 个,可选举 | ✅ |
| 4 | 1 | ✅ 挂一个剩 3 个,但浪费资源 | ✅ |
| 5 | 2 | ✅ 可容忍 2 个故障 | ✅ |
结论:3 或 5 个哨兵最经济。永远不要用偶数。
7.3 哨兵和 Redis 部署在一起的风险
yaml
# 不推荐:所有哨兵和 Redis 在同一台机器
Machine1: Master + Sentinel1
Machine2: Slave1 + Sentinel2
Machine3: Slave2 + Sentinel3
# 问题:Machine1 宕机 → Master + Sentinel1 同时挂
# 还剩 2 个哨兵,仍可选举(如果 quorum=2)
yaml
# 推荐:哨兵独立部署(但成本高)
Machine1: Master
Machine2: Slave1
Machine3: Slave2
Machine4: Sentinel1
Machine5: Sentinel2
Machine6: Sentinel3折中方案 :哨兵和 Redis 混部,但保证每个哨兵在不同机器,且 quorum = 哨兵数量 / 2 + 1。
7.4 故障转移后,旧 Master 恢复怎么办?
旧 Master 重新上线后,发现自己有了新的配置(epoch 更大),会自动降级为 Slave,并同步新 Master 的数据。
bash
# 旧 Master 日志会显示:
# MASTER MODE enabled (user request from 'id=...')
# 然后收到 SLAVEOF 命令,变为从库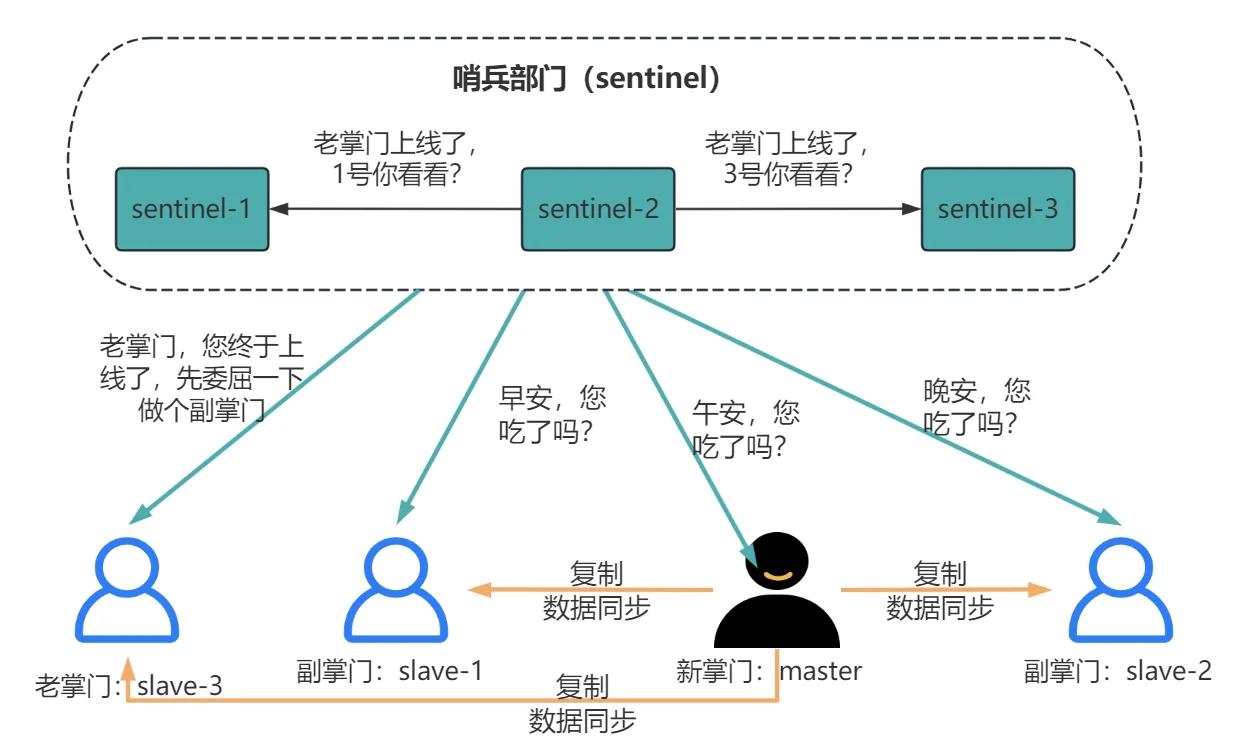
八、 生产环境最佳实践
8.1 推荐配置
conf
# sentinel.conf(所有哨兵统一)
# 监控配置
sentinel monitor mymaster 192.168.1.100 6379 2
sentinel auth-pass mymaster your_strong_password
# 时间配置(内网高速)
sentinel down-after-milliseconds mymaster 10000 # 10 秒
sentinel failover-timeout mymaster 60000 # 1 分钟
# 并行同步数量
sentinel parallel-syncs mymaster 1
# 通知脚本(钉钉/企业微信/邮件)
sentinel notification-script mymaster /opt/scripts/alert.sh8.2 监控告警
bash
# 定期检查哨兵状态
redis-cli -p 26379 SENTINEL master mymaster
# 输出包括:
# - num-slaves
# - num-other-sentinels
# - flags(master_down 等)
# 关键告警指标
# 1. Master 切换次数 > 0 → 可能网络不稳定
# 2. num-other-sentinels < 2 → 哨兵掉线
# 3. flags 包含 s_down 或 o_down → 立即处理8.3 备份哨兵配置
bash
# 哨兵的配置是动态更新的(故障转移后自动修改)
# 建议定期备份
cp /etc/redis/sentinel.conf /backup/sentinel.conf.$(date +%Y%m%d)九、 哨兵 vs 其他方案
| 方案 | 自动故障转移 | 数据分片 | 适用场景 |
|---|---|---|---|
| 主从复制 | ❌ 手动 | ❌ | 小型应用,可接受手动切换 |
| 哨兵 | ✅ | ❌ | 中型应用,高可用需求,数据量 < 单机内存 |
| 集群 | ✅(内置) | ✅ | 大型应用,数据量 > 单机内存 |
选型建议:
- 数据量 < 16GB,高可用需求 → 哨兵
- 数据量 > 16GB,需要水平扩展 → Redis Cluster(下期讲解)
十、 面试高频题
Q1:哨兵的作用是什么?
A:监控、通知、自动故障转移、配置中心。确保 Redis 集群在主节点故障时能自动恢复。
Q2:哨兵集群至少需要几个?为什么?
A:至少 3 个,并且是奇数。因为哨兵需要选举 Leader 来执行故障转移,需要超过半数的哨兵同意。2 个哨兵挂 1 个后就无法达成多数,3 个哨兵可以容忍挂 1 个。
Q3:主观下线和客观下线的区别?
A:主观下线(SDOWN)是单个哨兵认为 Master 挂了;客观下线(ODOWN)是 quorum 个哨兵都认为 Master 挂了,此时才会触发故障转移。
Q4:故障转移时,怎么选择新 Master?
A:按优先级筛选:
- 优先级最高(
replica-priority最小) - 复制偏移量最大(数据最新)
- Run ID 最小(保底)
Q5:哨兵模式下,客户端怎么连接?
A:客户端连接哨兵集群,询问当前 Master 的 IP 和端口,然后连接 Master。写操作走 Master,读操作可以走 Slave。
Q6:故障转移期间,数据会丢失吗?
A:可能丢失。因为 Redis 主从复制是异步的,Master 宕机时,部分数据可能还没同步到 Slave。可以通过 min-slaves-to-write 降低丢失概率,但会牺牲可用性。
十一、 总结
哨兵是 Redis 从"单机玩具"走向"生产可用"的关键一步:
| 阶段 | 可用性 | 运维成本 | 数据容量 |
|---|---|---|---|
| 单机 | 低(单点故障) | 低 | 受限于内存 |
| 主从复制 | 中(手动切换) | 中 | 受限于 Master 内存 |
| 哨兵 | 高(自动切换) | 中 | 受限于 Master 内存 |
| 集群 | 高 + 水平扩展 | 高 | 近乎无限 |
哨兵模式适合谁:
- 需要高可用,但数据量能放进单机内存(< 32GB)
- 读多写少,需要读写分离
- 不想自己实现故障检测和切换
最后的叮嘱:
- 生产环境哨兵数量 = 3 或 5,不要用偶数
- 不要把所有哨兵和 Redis 放在同一台机器
- 配置
min-slaves-to-write防止脑裂丢数据 - 客户端必须连接哨兵,不要硬编码 Master IP
下一期预告:Redis Cluster 集群------突破单机内存上限,轻松存储 TB 级数据。
哨兵站岗,高可用有保障。下期见!