摘要 :传统自然语言处理(NLP)任务的开发往往需要机器学习专家耗费数天甚至数周的时间。如今,借助大语言模型(LLM)和精心设计的 Prompt,开发者仅需几分钟即可构建出功能强大的 NLP 系统。本文以
nlp-demo项目为例,深入剖析如何通过模块化架构、Prompt 工程技巧与 DeepSeek 大模型,快速实现情感分析、信息提取、主题推断与文本总结等核心 NLP 能力。
一、项目概览与架构总览
1.1 为什么选择 Prompt 工程做 NLP
传统的 NLP 开发流程通常包括数据收集、数据清洗、特征工程、模型训练、评估调优等多个环节,门槛高、周期长。而基于 LLM 的 Prompt 工程直接通过自然语言指令驱动模型完成推理,核心转变在于:
| 传统方式 | Prompt 工程方式 |
|---|---|
| 需要标注大量训练数据 | 零样本或少样本即可启动 |
| 训练专用模型(数天~数周) | 编写 Prompt(数分钟) |
| 每个任务一个模型 | 一个模型覆盖多种任务 |
| 需要 ML 专业知识 | 自然语言描述即可 |
1.2 项目架构图
本项目采用 ES Module 模块化架构,将 LLM 客户端、推理函数和业务入口清晰分离:
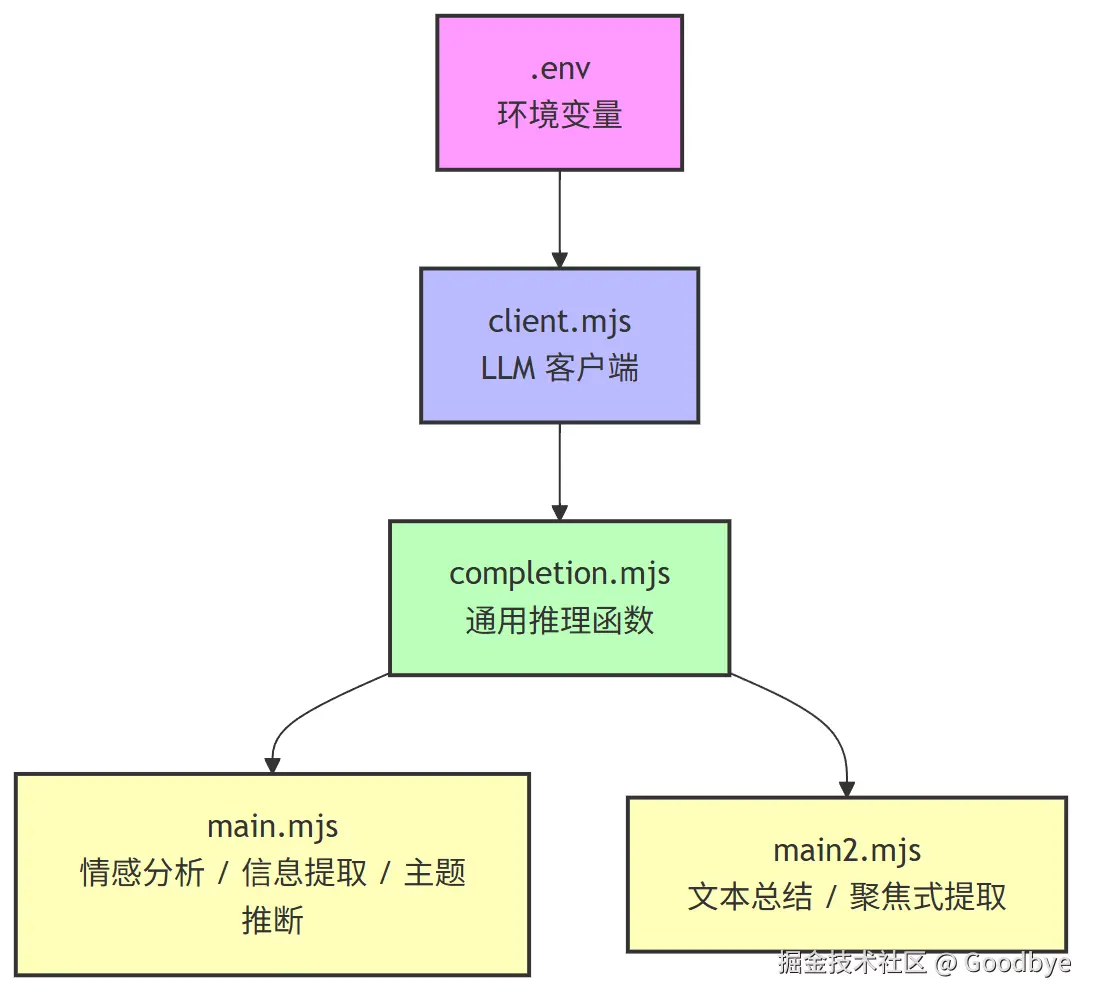
架构核心思想 :单向依赖,逐层抽象。底层不感知上层,上层通过 import 引入下层能力。
1.3 项目文件结构
bash
nlp-demo/
├── .env # API 密钥与模型配置
├── package.json # 项目元信息与依赖声明
├── pnpm-lock.yaml # 依赖锁定文件
├── client.mjs # LLM 客户端模块(底层)
├── completion.mjs # 通用推理函数(中间层)
├── main.mjs # NLP 任务入口 1(上层)
├── main2.mjs # NLP 任务入口 2(上层)
└── readme.md # 项目说明二、模块化设计:ES6 语法基石
在深入 NLP 任务之前,先理解支撑项目模块化的 ES6 关键特性。正如 readme.md 中所言:
"ES6 是 JavaScript 在 2015 年推出的新版本,变化比较大,目标是让 JS 成为一个企业级大型项目开发语言。"
2.1 let / const:块级作用域
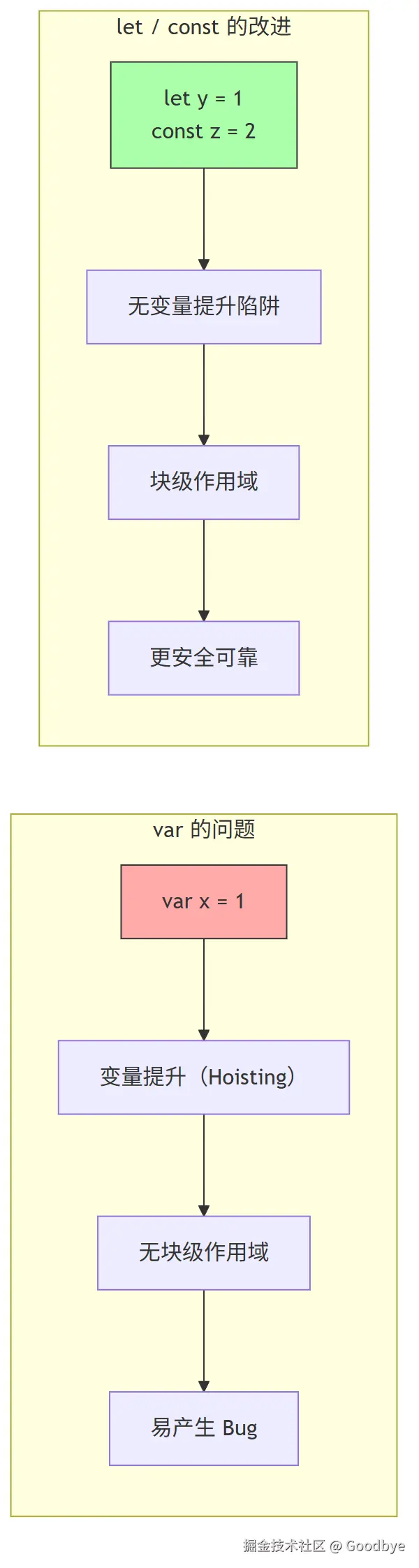
关键规则:
let和const不可重复声明const声明的简单数据类型不可重新赋值const声明的复杂数据类型(对象/数组)可以修改内部属性,但不可改变其指向的内存地址
2.2 解构赋值(Destructuring)
解构赋值是本项目中大量使用的语法糖,从对象或数组中直接提取值到变量中:
javascript
// 对象解构 --- 简洁提取属性
let { name, city } = { name: "李四", city: "上海" };
// 等价于:
// let name = obj.name;
// let city = obj.city;
// 数组解构 + rest 运算符
let [coach, ...players] = ['范甘迪', '姚明', '麦迪', '穆托姆博', '弗朗西斯'];
console.log(coach); // '范甘迪'
console.log(players); // ['姚明', '麦迪', '穆托姆博', '弗朗西斯']为什么解构比点运算符性能更好? 解构一次性将属性值复制到局部变量,后续访问无需反复查找原型链,引擎优化空间更大。
2.3 ESM 模块化
本项目使用 ES Module 语法代替传统的 CommonJS:
export default:每个模块只能有一个默认导出(如client.mjs导出client实例)export(命名导出) :可以导出多个(如completion.mjs导出getCompletion和genImage)import ... from:按需引入,支持解构式导入
三、核心组件深度解析
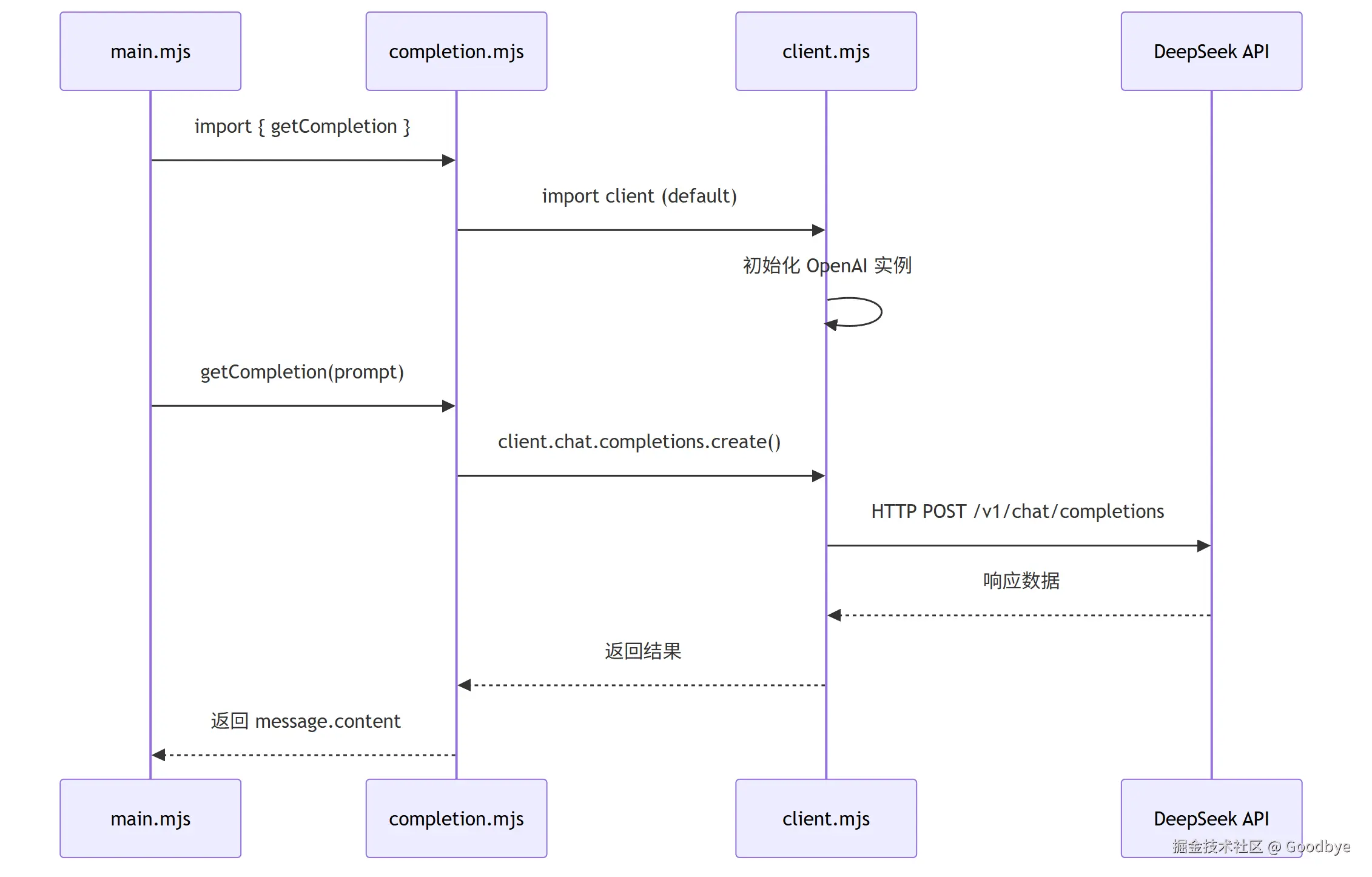
3.1 client.mjs --- LLM 客户端封装
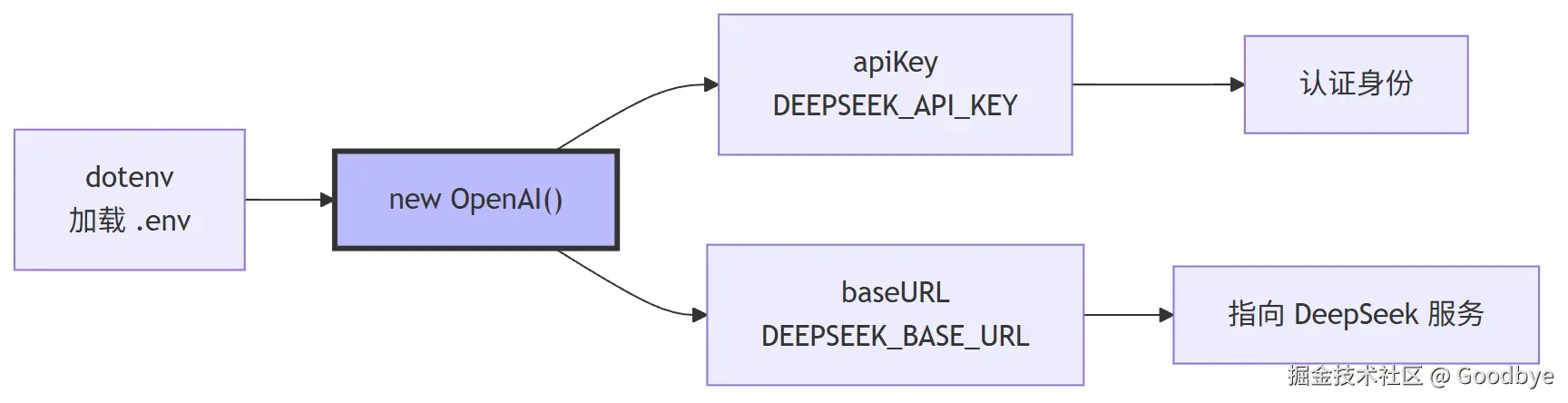
代码解读(client.mjs):
javascript
import { OpenAI } from 'openai';
import dotenv from 'dotenv';
dotenv.config(); // 加载 .env 文件中的环境变量
const client = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY, // DeepSeek API 密钥
baseURL: process.env.DEEPSEEK_BASE_URL // https://api.deepseek.com/v1
});
export default client; // 默认导出,全局唯一实例设计要点:
- 使用 OpenAI 兼容 SDK,与 DeepSeek 服务无缝对接(DeepSeek 提供了与 OpenAI API 兼容的接口格式)
dotenv.config()在模块顶层执行,确保环境变量在使用前加载- 单例模式:整个项目共享一个
client实例,避免重复初始化连接
3.2 completion.mjs --- 通用推理函数
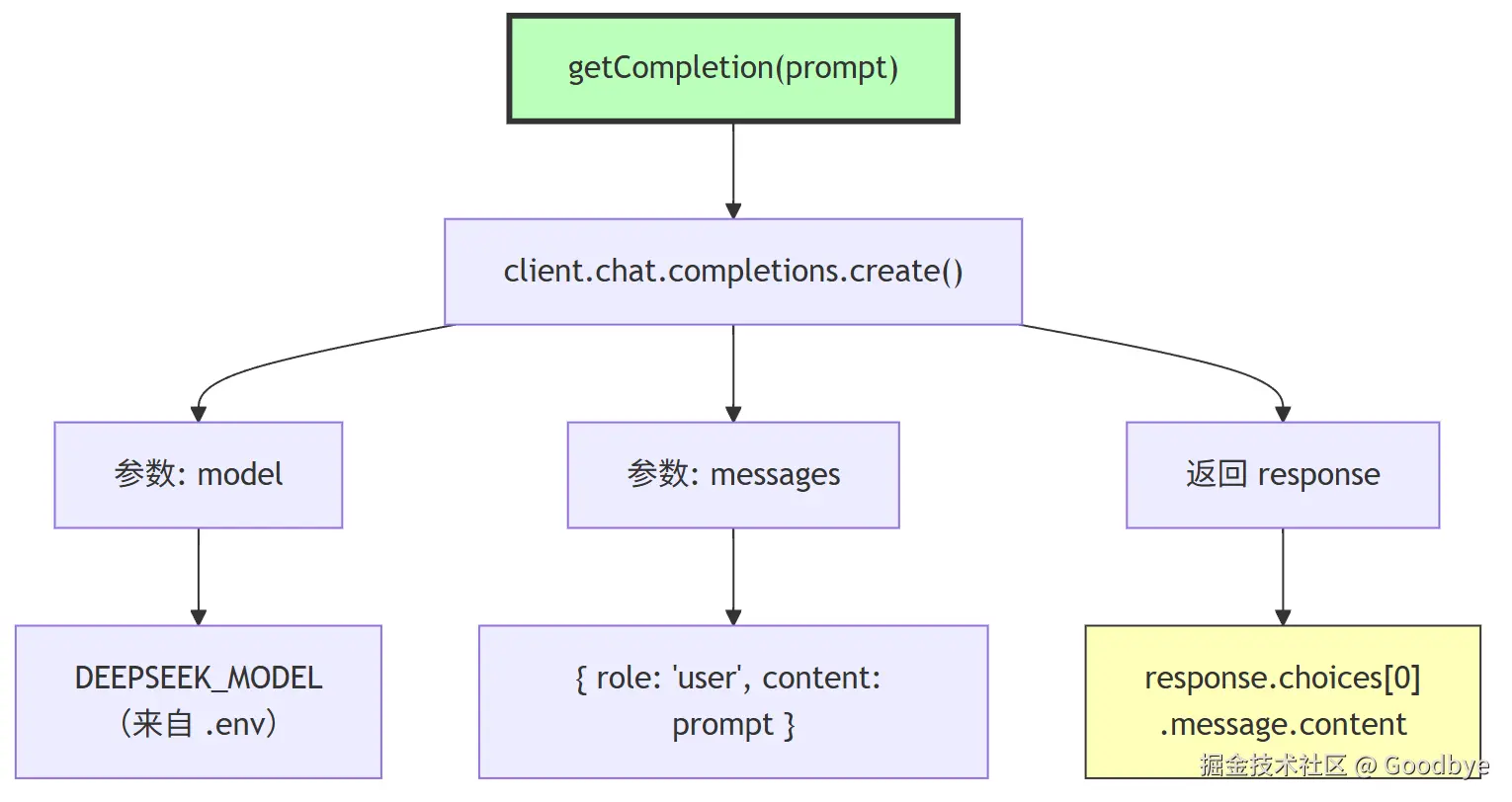
代码解读(completion.mjs):
javascript
import client from './client.mjs';
export async function getCompletion(prompt) {
const response = await client.chat.completions.create({
model: process.env.DEEPSEEK_MODEL, // deepseek-v4-flash
messages: [{ role: 'user', content: prompt }]
});
return response.choices[0].message.content;
}
export async function genImage(prompt) {
// 预留:图像生成接口
}设计要点:
- 将 "发送请求 → 获取回复" 封装为单一函数,上层调用者只需关心 Prompt 内容
- 返回
choices[0].message.content直接是文本内容,消除了上层解析 JSON 的需要 genImage作为扩展点,展示了模块的可扩展性
3.3 .env --- 环境配置分离
ini
DEEPSEEK_API_KEY=sk-xxx...
DEEPSEEK_BASE_URL=https://api.deepseek.com/v1
DEEPSEEK_MODEL=deepseek-v4-flash为什么将配置外置?
- 🔒 安全性 :API Key 不入库,
.env加入.gitignore - 🔄 可切换性:更换模型或服务商只需修改环境变量,无需改代码
- 🚀 部署友好:不同环境(开发/测试/生产)可使用不同配置
四、NLP 任务实战
这是本文的核心章节。我们将逐一剖析四种 NLP 任务的 Prompt 设计与实现。
4.1 情感分析(Sentiment Analysis)
业务价值:电商评论情感分析可用于客服预警、产品质检、舆情监控等场景。
4.1.1 基础情感分类
在 main.mjs 中,我们首先尝试对一条中文产品评论做情感分类:
javascript
const lamp_review_zh = `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,
他们很快就给我寄来了缺失的零件!
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`;Prompt 演进过程:
| 阶段 | Prompt 设计 | 特点 |
|---|---|---|
| V1 基础版 | 以下用三个反引号分隔的产品评论的情感是什么? |
开放式,回答不可控 |
| V2 约束版 | 用一个单词回答:正面 或 负面 |
约束输出格式,结果可预期 |
| V3 定向版 | 以下产品评论是否表达愤怒?给出是或否的答案 |
针对特定情感维度 |
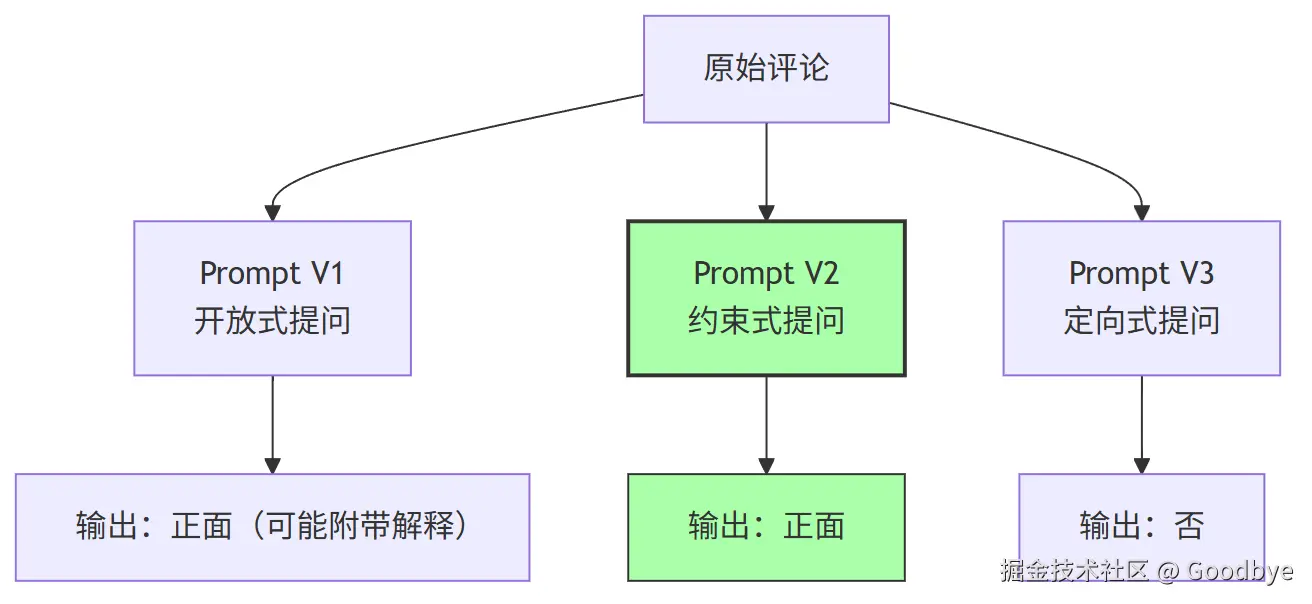
💡 关键技巧 :通过
用一个单词回答这样的格式约束,可以极大提升输出的一致性和可解析性。
4.1.2 复合信息提取
更高级的做法是一次性提取多个维度的信息:
javascript
Prompt 设计:
从以下评论文本识别以下项目:
- 情绪(正面或负面)
- 是否表达了愤怒?(是或否)
- 评论者购买的商品
- 制造该物品的公司
将您的响应格式化为 JSON 对象,以 "sentiment"、"anger"、"product"、"brand" 为键。
将 anger 格式化为布尔值。
如果信息不存在,请使用 "未知" 作为值。输出的结构化 JSON 可以直接被下游程序消费:
json
{
"sentiment": "正面",
"anger": false,
"product": "卧室灯",
"brand": "Lumina"
}4.2 信息提取(Information Extraction)
信息提取的目标是从非结构化文本中抽取结构化字段。本项目中展示了一个关键模式:
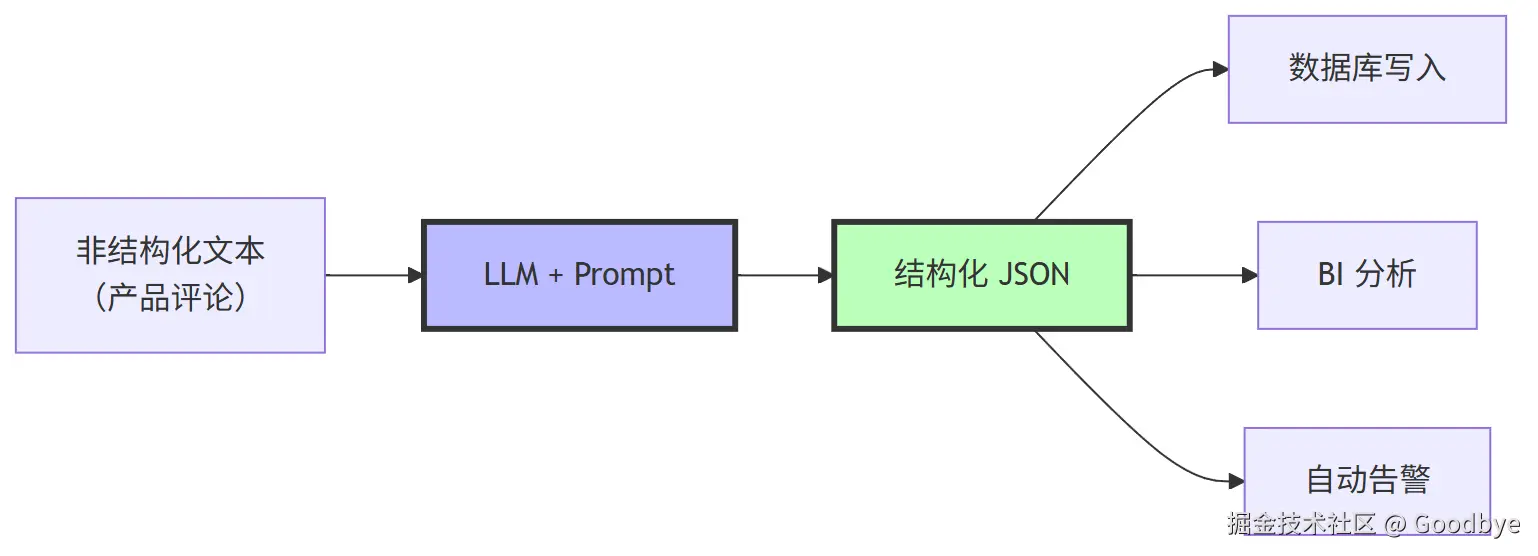
Prompt 设计要点:
javascript
从以下评论文本识别以下项目:
- 评论者购买的商品
- 制造该商品的公司
将你的响应格式以 "物品(product)" 和 "品牌(brand)" 为键的 JSON 对象。
如果信息不存在,请使用 **未知** 作为值。三个关键技巧:
- 明确输出键名(中文+英文对照,消除歧义)
- 规定缺省值 (
"未知"--- 避免模型胡编乱造) - 使用分隔符(三个反引号包裹文本,防止注入攻击)
4.3 主题推断(Topic Inference)
主题推断用于从长文本中自动识别讨论的核心话题。在 main.mjs 中,我们使用了一段关于政府部门的调查新闻:
javascript
const story_zh = `
在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。
调查结果显示,NASA 是最受欢迎的部门,满意度为 95%。
...
调查还显示,社会保障管理局的满意度最低,只有 45%的员工表示他们对工作满意。
`;Prompt 设计:
bash
确定以下给定文本中讨论的五个主题。
每个主题用一到两个单词概括。
输出时用逗号分隔。
给定文本:${story_zh}预期输出示例:NASA, 员工满意度, 政府调查, 公共部门, 社会保障管理局
在 main2.mjs 中进一步展示了主题判断模式------给一个候选主题列表,让模型判断每个主题是否在文本中被讨论:
判断主题列表中的每一项是否是给定文本中的一个话题。
以列表的形式给出答案,每个主题用 0 或 1。
主题列表:美国航天局, 地方政府, 工程, 员工满意度, 联邦政府输出示例:[1, 0, 0, 1, 1]

两种模式的选择:开放发现适合探索性分析("这篇文章讲了什么");候选判断适合监控场景("这篇文章是否涉及我们关心的 N 个话题")。
4.4 文本总结(Text Summarization)
文本总结是最实用的 NLP 能力之一,可帮助行政、编辑、管理层快速从长文本中提取关键信息。
在 main2.mjs 中,使用一条熊猫公仔的产品评论作为示例:
javascript
const prod_review_zh = `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`;文本总结的三种聚焦模式
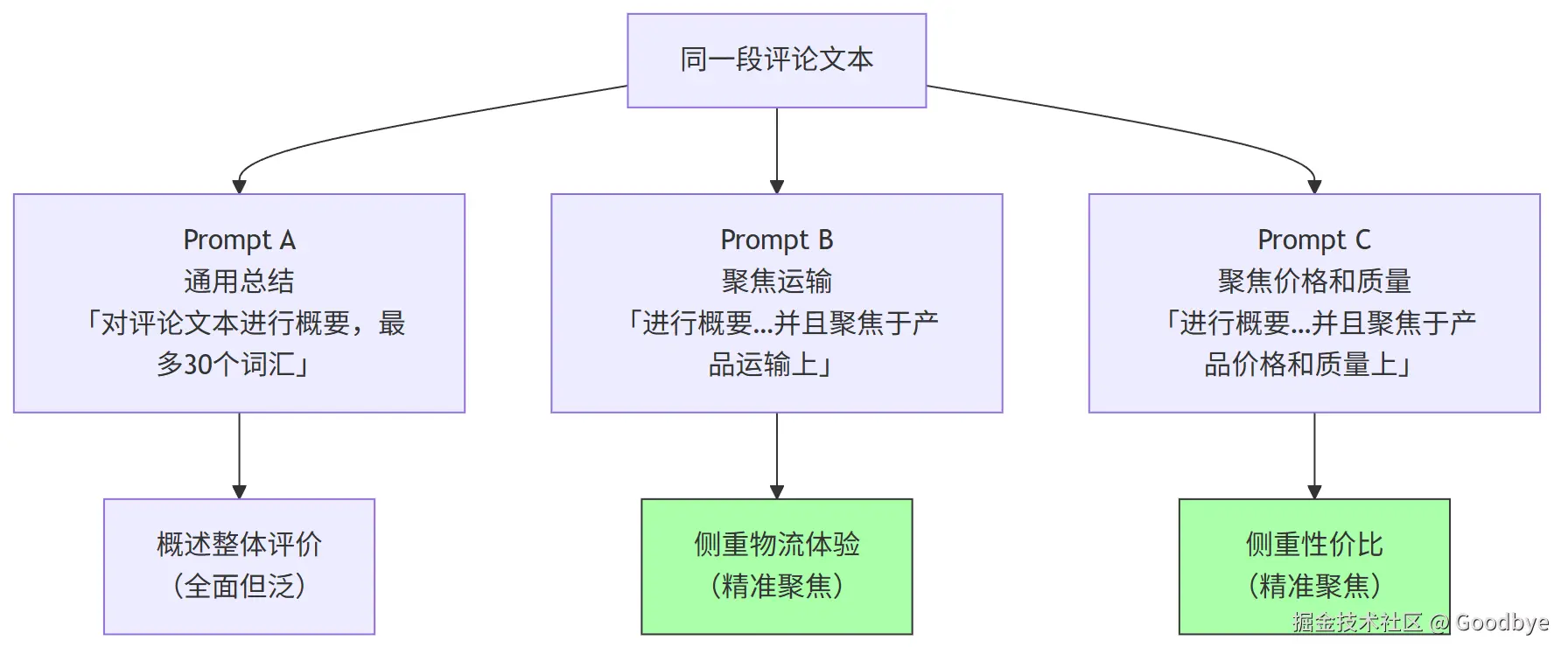
三种 Prompt 对比:
| 聚焦维度 | Prompt 关键指令 | 适用场景 |
|---|---|---|
| 通用总结 | 概要,最多30个词汇 |
快速浏览概况 |
| 聚焦运输 | 概要...聚焦于产品运输上 |
物流部门质检 |
| 聚焦价格和质量 | 概要...聚焦于产品价格和质量上 |
产品部门评估 |
批量处理多条评论
在 main2.mjs 末尾,展示了如何对 4 条不同类型产品的评论(公仔、灯具、牙刷、搅拌机)进行批量总结:
javascript
const reviews = [review_1, review_2, review_3, review_4];
for (let review of reviews) {
const prompt = `
你的任务是从电子商务网站上的产品评论中提取相关信息。
请对三个反引号之间的文本进行概括,最多20个字符。
评论文本:\`\`\`${review}\`\`\`
`;
const response = await getCompletion(prompt);
console.log(response, '\n');
}五、Prompt 工程核心技巧总结
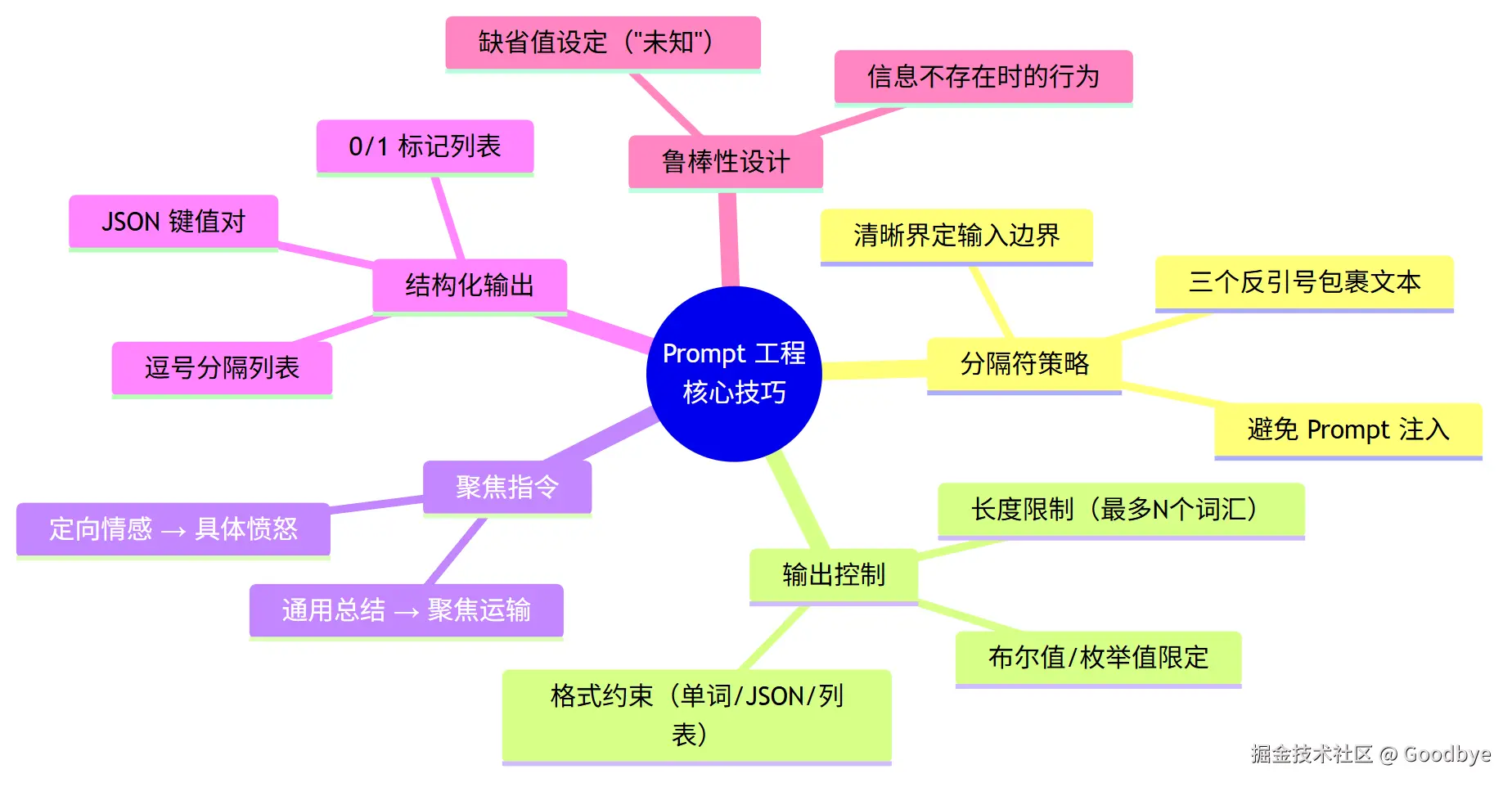
通过以上四个 NLP 任务的实战,我们可以归纳出以下 Prompt 工程的关键技巧:
5.1 技巧全景图
5.2 技巧详解
① 分隔符(Delimiters)
r
评论文本:\`\`\`${user_input}\`\`\`使用三个反引号(或其他清晰的分隔符如 ---、XML 标签)包裹用户输入:
- 防止用户输入中的恶意指令覆盖系统指令(Prompt Injection 防御)
- 让模型清晰分辨"指令"和"数据"
② 输出格式控制
从宽松到严格的输出控制谱系:
arduino
宽松 ←------------------------------------------------------------------------------------→ 严格
"情感是什么?" "用一个单词回答" "以JSON格式输出" "以{key:value}格式,布尔值"
(自由文本) (词级约束) (结构化) (精确 Schema)③ 聚焦式 Prompt
同一段文本,不同的聚焦指令得出完全不同的总结:
聚焦运输 → 强调物流速度、包装完整性
聚焦价格 → 强调性价比、价格波动
聚焦质量 → 强调产品材质、做工细节这对于企业中对不同部门(物流部、产品部、客服部)提供定制化信息非常有价值。
④ 鲁棒性兜底
markdown
如果信息不存在,请使用 **未知** 作为值。这条指令防止模型在信息缺失时"自由发挥",确保了输出的一致性和可解析性。
六、技术栈与依赖
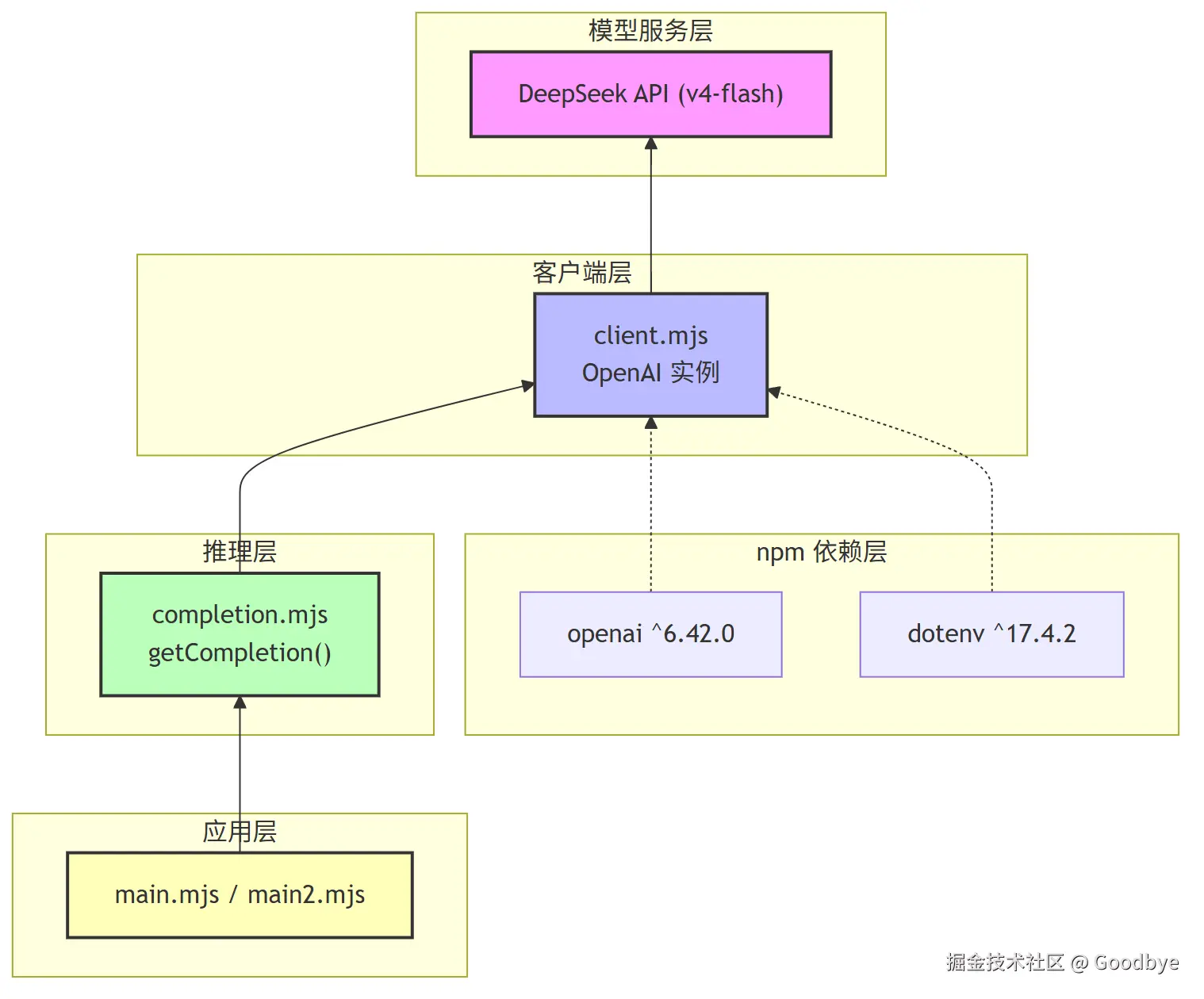
| 组件 | 版本 | 作用 |
|---|---|---|
openai |
^6.42.0 | OpenAI 兼容 SDK,用于调用 DeepSeek API |
dotenv |
^17.4.2 | 从 .env 文件加载环境变量 |
| DeepSeek v4-flash | - | 提供推理能力的大语言模型 |
| Node.js | - | 运行时环境 |
七、总结与展望
核心收获
- 模块化架构 是工程化的基石------
client→completion→main的分层设计让代码可维护、可复用 - Prompt 即代码------Prompt 的质量直接决定了 NLP 系统的输出质量,需要像写代码一样精心设计和迭代
- 从几天到几分钟------借助 LLM,构建 NLP 系统的门槛从机器学习专家降低到任何会写自然语言的开发者
可扩展方向
🚀 下一步 :有了这个基础框架,你可以轻松添加更多 NLP 任务------如命名实体识别(NER)、文本翻译、代码生成、对话系统等。所有任务共享同一个
getCompletion函数,唯一变化的是 Prompt 的内容和结构。